![]()
Міграція RTFM з DigitalOcean до AWS пройшла без проблем, і потроху “обживаюсь на новому місці”.
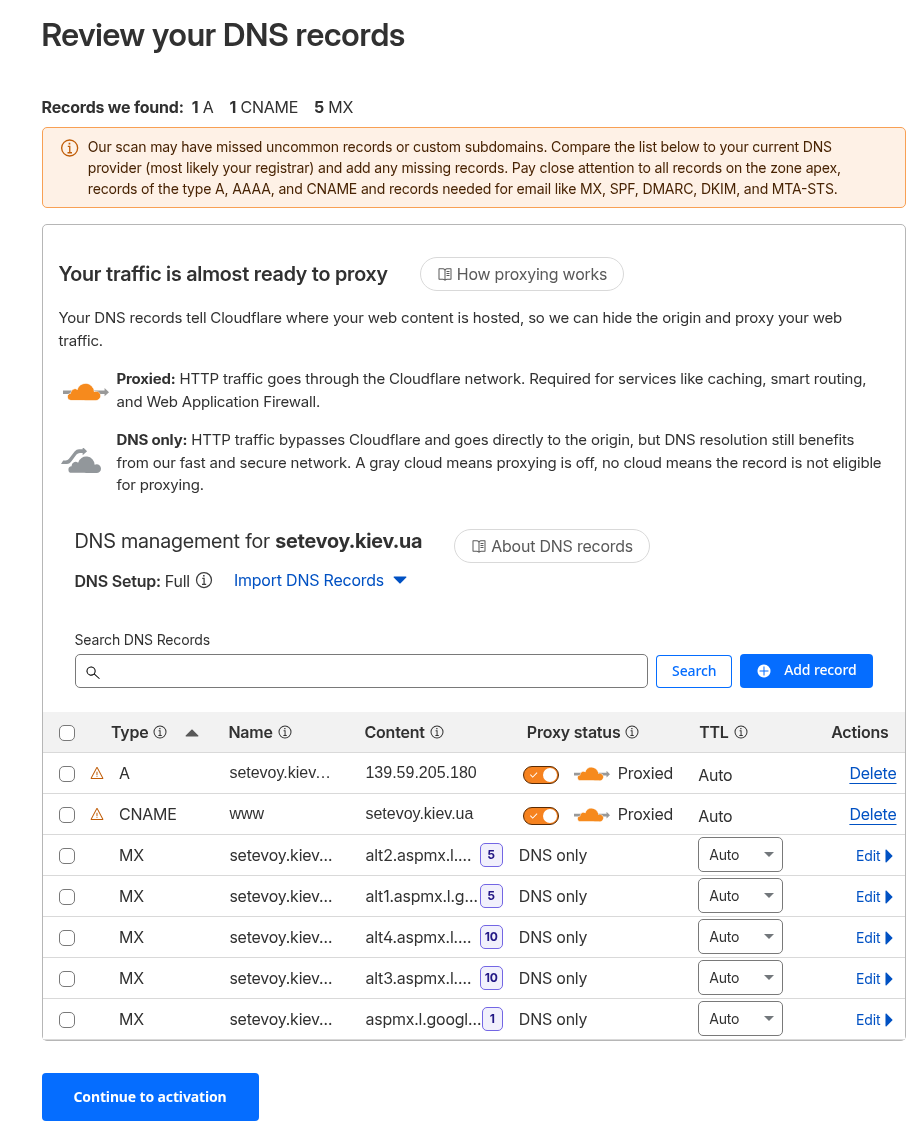
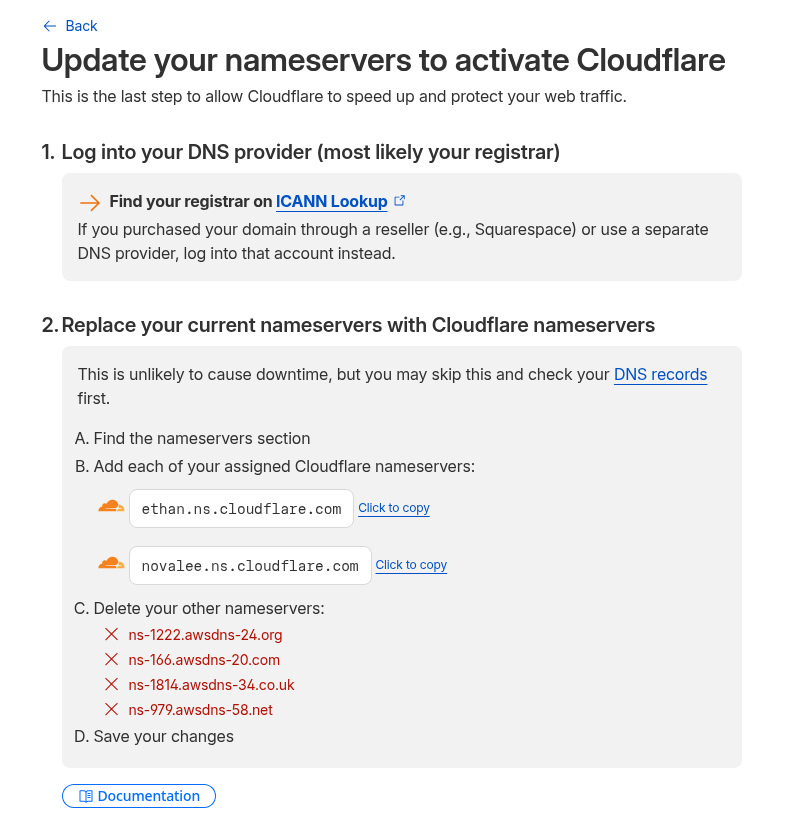
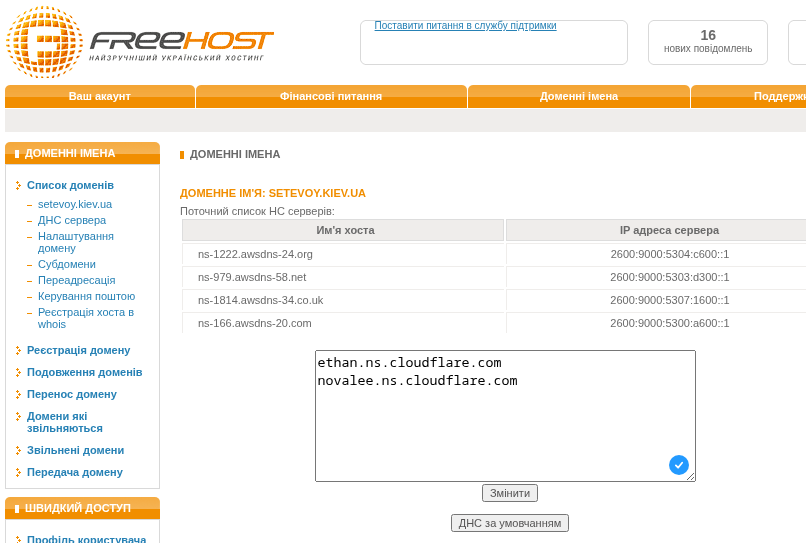
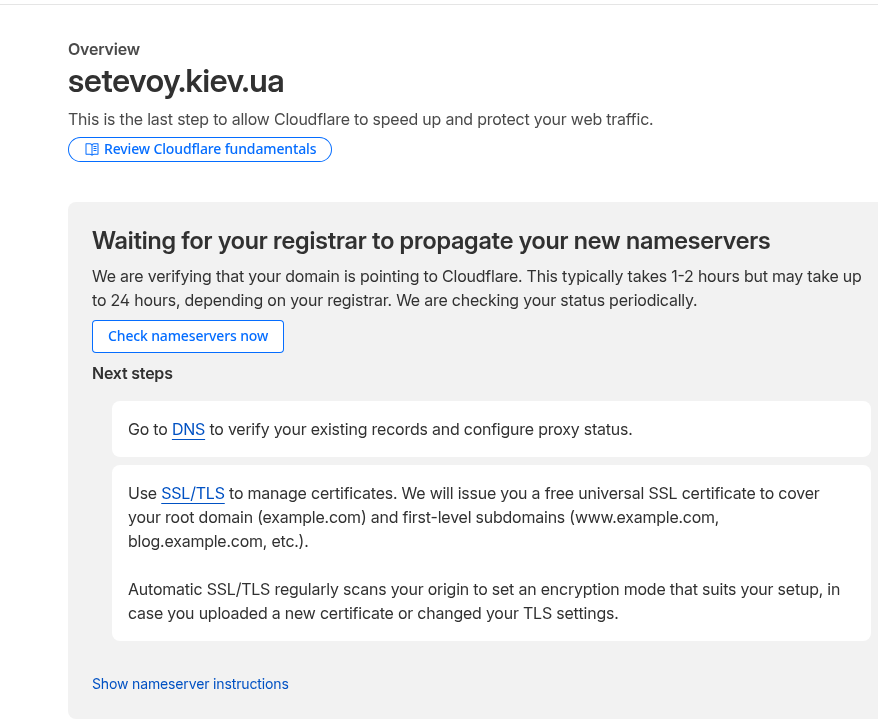
Інфраструктура нова, все нове – а тому перший час хочеться уважно постежити за станом серверів та блогу, а тому треба налаштувати базовий моніторинг для WordPress: NGINX, PHP-FPM, базу даних та інфраструктуру, на якій все це крутиться.
Сам стек моніторингу вже розгорнутий на домашньому NAS з FreeBSD – є VictoriaMetrics, VictoriaLogs, Grafana, vmalert та Alertmanager з відправкою алертів в Telegram та ntfy.sh.
По цьому стеку писав в серії постів по FreeBSD та домашньому NAS:
- FreeBSD: Home NAS, part 10 – моніторинг з VictoriaMetrics
- FreeBSD: Home NAS, part 11 – extended моніторинг з додатковими експортерами
- FreeBSD: Home NAS, part 14 – логи з VictoriaLogs і алерти з VMAlert
Інфраструктура в AWS
Створення інфраструктури описане в AWS: сетап базової інфраструктури для WordPress і AWS: власний EC2 в ролі NAT Gateway замість AWS Managed NAT Gateway.
Нагадаю, що в AWS є загалом:
- VPC з 4 Subnets – 2 публічні, 2 приватні
- Application Load Balancer з Target Group, в TG – один EC2
- два EC2 instances з Amazon Linux 2023:
- один з NGINX та PHP-FPM для самого WordPress
- і окремий EC2 в ролі NAT Gateway
- AWS RDS з MariaDB – сервер бази даних для WordPress
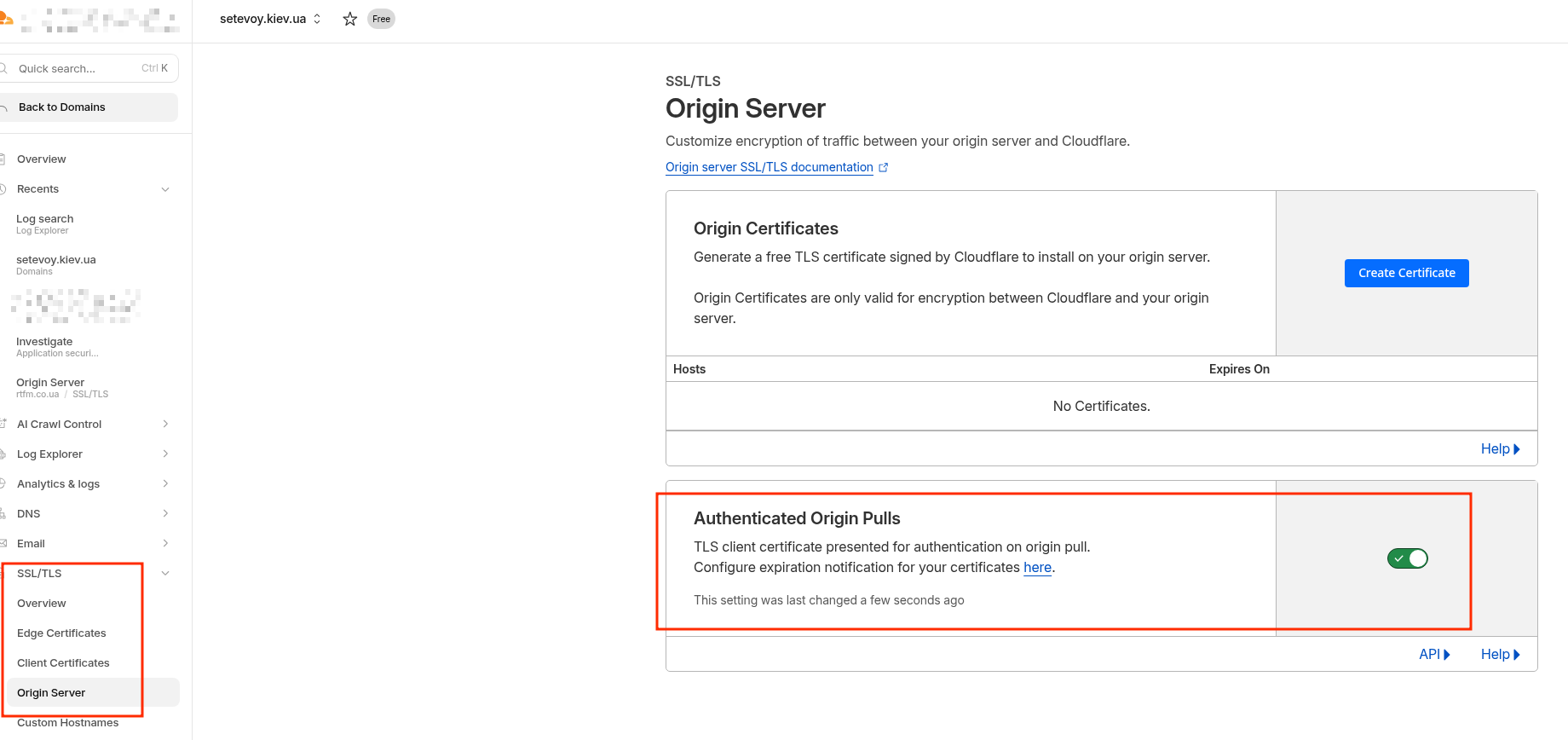
На обох EC2 піднятий WireGuard для підключення до домашньої мережі, де в ролі VPN Hub виступає MikriTik RB4011 і який роутить запити до VictoriaMetrics та VictoriaLogs – див. MikroTik: налаштування WireGuard та підключення Linux peers.
Планування моніторингу
Що є з сервісів, які треба помоніторити:
- AWS RDS: стан серверу бази даних
- AWS ALB: картина того, що відбувається на Load Balancer
- AWS EC2: різні метрики по стану самих інстансів
- NGINX: метрики веб-сервера
- PHP-FPM: метрики воркерів FPM
Крім того, треба збирати системні логи операційної системи та логи NGINX і PHP.
Логи RDS теж можуть бути корисними – але це вже на випадок реальних проблем, а тоді вже можна просто подивитись в CloudWatch Logs.
Для збору метрик на EC2 використав:
- node_exporter: базові метрики EC2 – CPU, RAM, диск, мережа
- nginx_exporter: простенький, метрик мало, але нехай буде (окремо зробимо метрики з логів NGINX)
- php_fpm_exporter: метрики PHP-FPM – процеси, використання воркерів, slow requests
- yace_exporter: збирає з CloudWatch дефолтні метрики по стану ALB та RDS
Для логів поки взяв Fluent Bit, який писатиме до VictoriaLogs. Взагалі, пізніше для збору логів спробую vlagent, зараз робив “швиденько” – тому взяв те, що в мене вже працює на FreeBSD/NAS.
vlagent виглядає дуже цікаво, див. цікавий пост в блогах VictoriaMetrics – Benchmarking Kubernetes Log Collectors: vlagent, Vector, Fluent Bit, OpenTelemetry Collector, and more. Але релізнули місяці три тому (по стану на березень 2026), тому поки що може мати не всіх корисні плюшки.
Пізніше можна буде додати cloudflare-prometheus-exporter та process_exporter, або генерити власні метрики з Textfile для node_exporter.
Установка експортерів
Запускати будемо стандартно – з Docker та Docker Compose.
Встановлюємо Docker:
[root@ip-10-0-3-146 ~]# dnf install -y docker [root@ip-10-0-3-146 ~]# systemctl enable --now docker
Docker Compose:
[root@ip-10-0-3-146 ~]# mkdir -p /usr/local/lib/docker/cli-plugins [root@ip-10-0-3-146 ~]# curl -SL https://github.com/docker/compose/releases/latest/download/docker-compose-linux-x86_64 -o /usr/local/lib/docker/cli-plugins/docker-compose [root@ip-10-0-3-146 ~]# chmod +x /usr/local/lib/docker/cli-plugins/docker-compose
Перевіряємо:
[root@ip-10-0-3-146 ~]# docker compose version Docker Compose version v5.1.0
Запуск node_exporter
Створюємо каталог /opt/monitoring і в ньому файл /opt/monitoring/docker-compose.yml:
services:
node_exporter:
image: prom/node-exporter:latest
container_name: node_exporter
restart: unless-stopped
pid: host
network_mode: host
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
Щоб node_exporter бачив всі мережеві інтерфейси – задаємо network_mode: host, щоб всі PID – задаємо pid: host.
З точки зору security це не ідеально, бо контейнер з network_mode: host дає повний доступ до мережі хоста, а pid: host дає йому видимість всіх процесів. Але для моніторингу особистого блогу – нормально.
Запускаємо:
[root@ip-10-0-3-146 ~]# cd /opt/monitoring && docker compose up -d
Перевіряємо метрики:
[root@ip-10-0-3-146 ~]# curl -s http://localhost:9100/metrics | grep node_exporter_build
# HELP node_exporter_build_info A metric with a constant '1' value labeled by version, revision, branch, goversion from which node_exporter was built, and the goos and goarch for the build.
# TYPE node_exporter_build_info gauge
node_exporter_build_info{branch="HEAD",goarch="amd64",goos="linux",goversion="go1.25.3",revision="654f19dee6a0c41de78a8d6d870e8c742cdb43b9",tags="unknown",version="1.10.2"} 1
Налаштування vmagent на FreeBSD
Додаємо збір метрик до VictoriaMetrics. На FreeBSD для vmagent використовується конфіг /usr/local/etc/prometheus/prometheus.yml – додаємо туди новий таргет.
В мене в job_name: "node_exporter" вже є один таргет – 127.0.0.1:9100 для метрик самої FreeBSD – туди ж вписуємо 10.100.0.20:9100, де 10.100.0.20 – це адреса EC2 в мережі WireGuard (хоча потім створю Static DNS record на MikroTik):
global:
scrape_interval: 15s
scrape_configs:
- job_name: victoriametrics
scrape_interval: 60s
scrape_timeout: 30s
metrics_path: "/metrics"
static_configs:
- targets:
- 127.0.0.1:8428
labels:
project: victoriametrics
- job_name: vmagent
scrape_interval: 60s
scrape_timeout: 30s
metrics_path: "/metrics"
static_configs:
- targets:
- 127.0.0.1:8429
labels:
project: vmagent
- job_name: "node_exporter"
static_configs:
- targets:
- "127.0.0.1:9100"
- "10.100.0.20:9100"
...
Перевіряємо в VictoriaMetrics через метрику node_uname_info – маємо бачити обидва хости:

Запуск nginx_exporter
Для отримання метрик nginx_exporter використовує модуль stub_status. Додаємо окремий файл /etc/nginx/conf.d/nginx-status.conf:
server {
listen 127.0.0.1:8080;
location = /nginx_status {
stub_status on;
access_log off;
}
}
Перевіряємо конфіг та перезавантажуємо NGINX:
[root@ip-10-0-3-146 ~]# nginx -t && systemctl reload nginx
Перевіряємо ендпоінт та дані від NGINX:
[root@ip-10-0-3-146 ~]# curl http://127.0.0.1:8080/nginx_status Active connections: 6 server accepts handled requests 33310 33310 162229 Reading: 0 Writing: 1 Waiting: 5
Додаємо nginx_exporter до Docker Compose file:
nginx_exporter:
image: nginx/nginx-prometheus-exporter:latest
container_name: nginx_exporter
restart: unless-stopped
network_mode: host
command:
- '--nginx.scrape-uri=http://127.0.0.1:8080/nginx_status'
Перезапускаємо стек та додаємо таргет до vmagent:
- job_name: "nginx_exporter"
static_configs:
- targets:
- "10.100.0.20:9113"
Перезапускаємо vmagent та перевіряємо в VictoriaMetrics:

Або через curl напряму:
root@setevoy-nas:~ # curl -s 'http://localhost:8428/api/v1/query?query=nginx_connections_active' | jq
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"__name__": "nginx_connections_active",
"instance": "10.100.0.20:9113",
"job": "nginx_exporter"
},
"value": [
1773670644,
"8"
]
}
]
},
"stats": {
"seriesFetched": "1",
"executionTimeMsec": 0
}
}
Запуск php-fpm exporter
Є два популярних експортери для PHP-FPM, хоча обидва давно не оновлюються – але працюють:
- hipages/php-fpm_exporter – найстаріший та найбільш популярний
- bakins/php-fpm-exporter – більше метрик по пам’яті процесів
Для базового моніторингу WordPress-блогу різниця несуттєва – беремо hipages/php-fpm_exporter, він перевірений та стабільний.
Перевіряємо, що в конфігу PHP-FPM включена опція статусу pm.status_path – в мене файл конфігу FPM це /etc/php-fpm.d/rtfm.co.ua.conf:
... ; endpoint for fpm status page (use in nginx location) pm.status_path = /status ...
Якщо не включена – додаємо і перезапускаємо PHP-FPM:
[root@ip-10-0-3-146 ~]# systemctl restart php-fpm.service
Додаємо окремий віртуалхост в NGINX, файл /etc/nginx/conf.d/fpm-status.conf, в allow дозволяємо доступ тільки з localhost:
server {
listen 127.0.0.1:8081;
server_name localhost;
# fpm status page - local only
location = /fpm-status {
allow 127.0.0.1;
deny all;
include fastcgi_params;
fastcgi_pass unix:/var/run/rtfm.co.ua-php-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
}
Перезавантажуємо NGINX з nginx -t && systemctl reload nginx та перевіряємо ендпоінт:
[root@ip-10-0-3-146 ~]# curl http://localhost:8081/fpm-status pool: rtfm.co.ua process manager: dynamic start time: 16/Mar/2026:16:22:30 +0200 start since: 653 accepted conn: 218 listen queue: 0 max listen queue: 0 listen queue len: 0 idle processes: 2 active processes: 1 total processes: 3 max active processes: 3 max children reached: 0 slow requests: 0 memory peak: 40792064
PHP-FPM використовує Unix socket – тому монтуємо його в контейнер і передаємо URI з unix://:
php_fpm_exporter_rtfm:
image: hipages/php-fpm_exporter:latest
container_name: php_fpm_exporter
restart: unless-stopped
network_mode: host
volumes:
- /var/run/rtfm.co.ua-php-fpm.sock:/var/run/rtfm.co.ua-php-fpm.sock
environment:
- PHP_FPM_SCRAPE_URI=unix:///var/run/rtfm.co.ua-php-fpm.sock;/fpm-status
- PHP_FPM_FIX_PROCESS_COUNT=true
Перезапускаємо стек та перевіряємо метрики вже від експортера:
[root@ip-10-0-3-146 ~]# curl -s http://localhost:9253/metrics | grep phpfpm_up
# HELP phpfpm_up Could PHP-FPM be reached?
# TYPE phpfpm_up gauge
phpfpm_up{pool="rtfm.co.ua",scrape_uri="unix:///var/run/rtfm.co.ua-php-fpm.sock;/fpm-status"} 1
Додаємо нову scrape job до vmagent:
- job_name: "php_fpm_exporter_rtfm"
static_configs:
- targets:
- "10.100.0.20:9253"
Перезапускаємо vmagent та перевіряємо метрики в VictoriaMetrics:

Моніторинг AWS з YACE Exporter
Для AWS-метрик будемо використовувати yet-another-cloudwatch-exporter (YACE) – він забирає метрики з CloudWatch і віддає їх у форматі Prometheus. Трохи детальніше про нього писав у Prometheus: yet-another-cloudwatch-exporter – сбор метрик AWS CloudWatch, досі використовую на робочих проектах.
Документація по метриках:
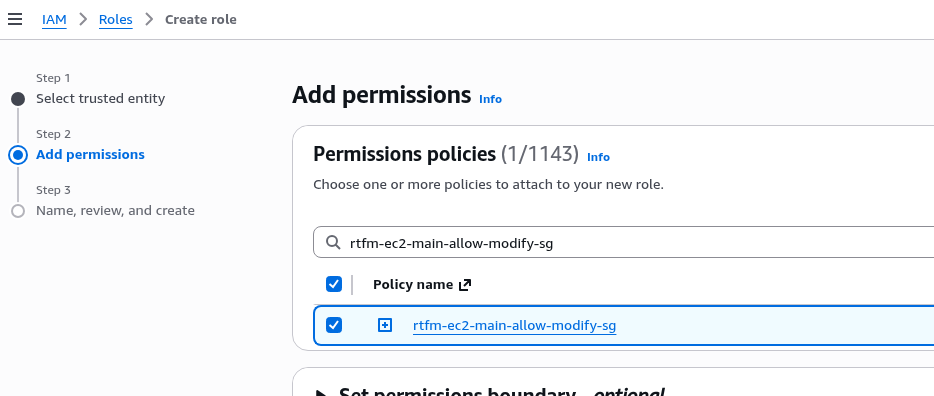
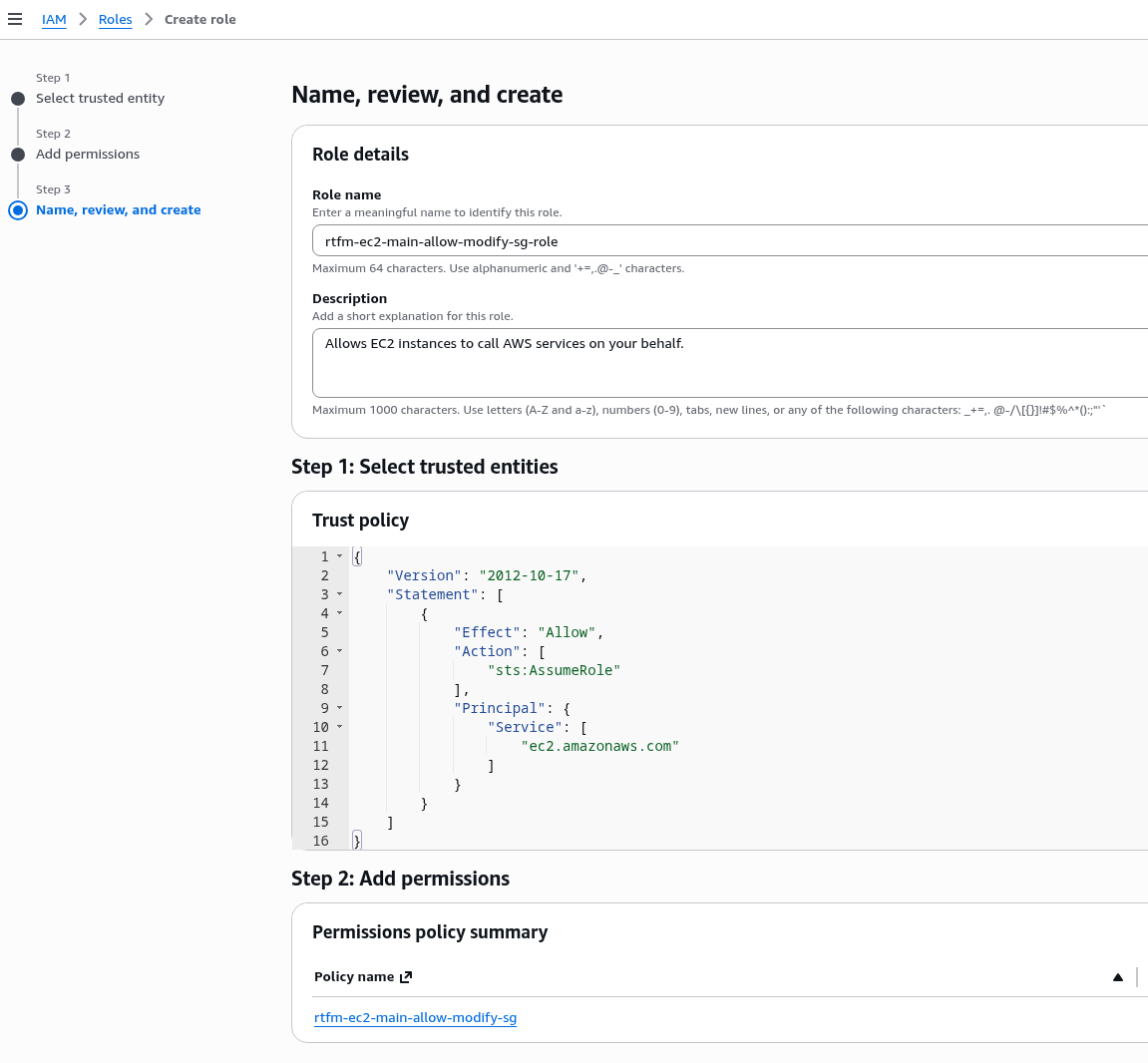
Створення IAM Policy для YACE
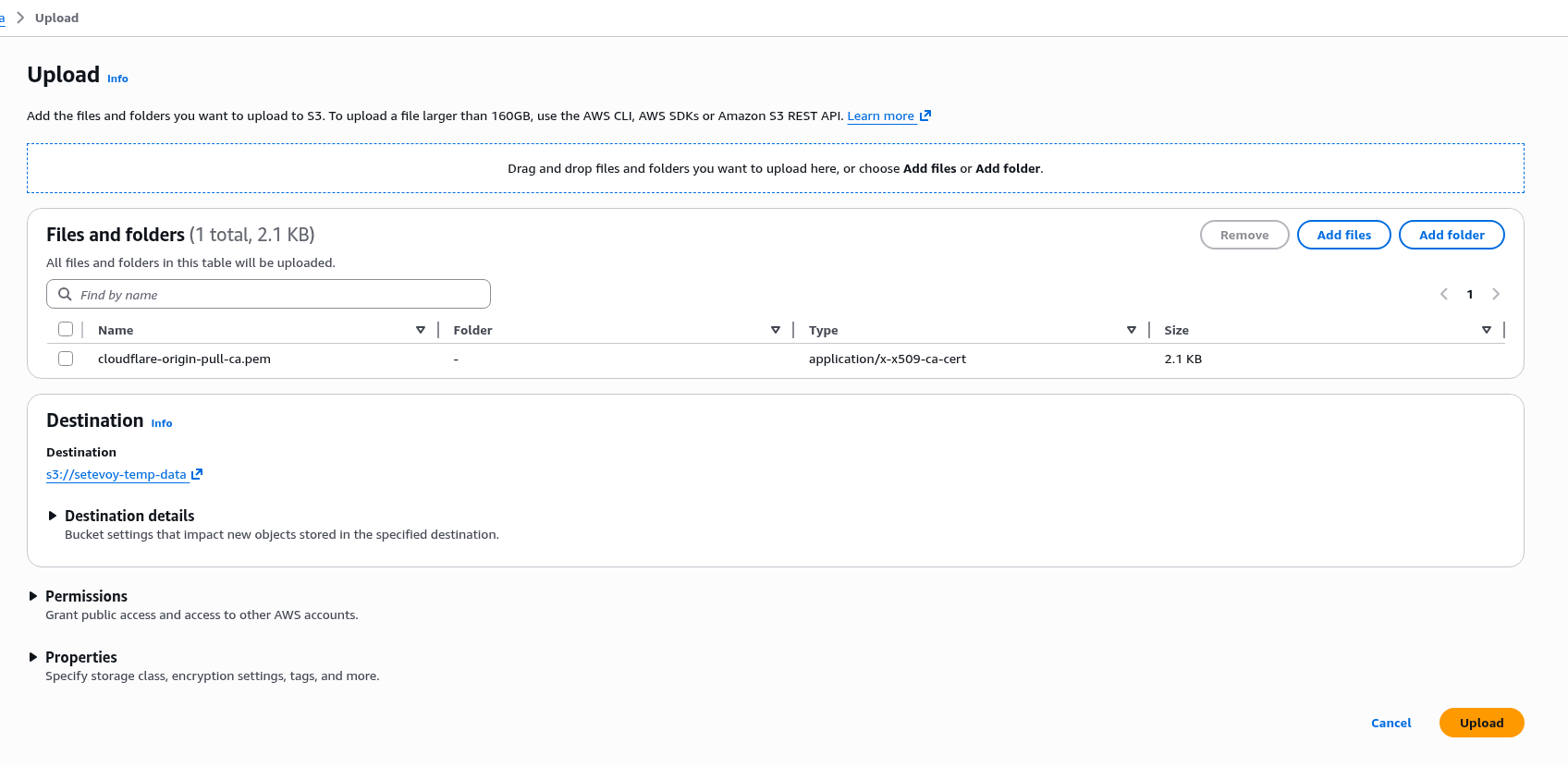
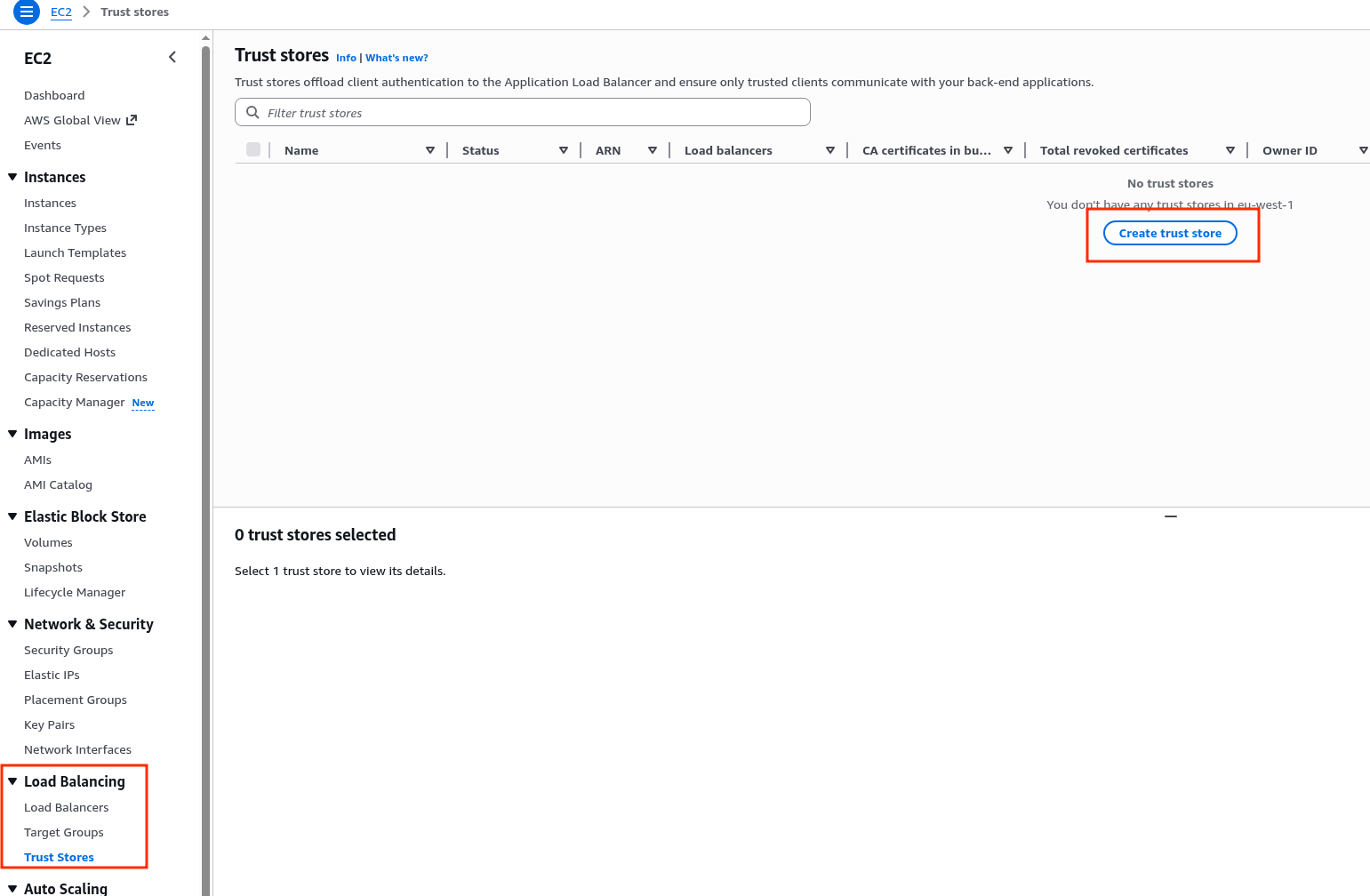
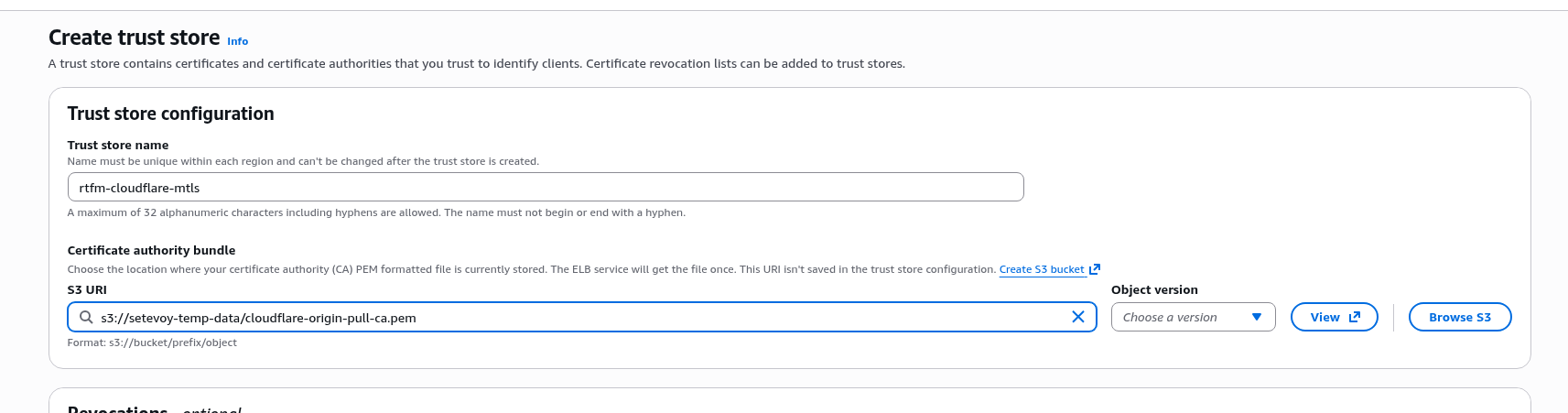
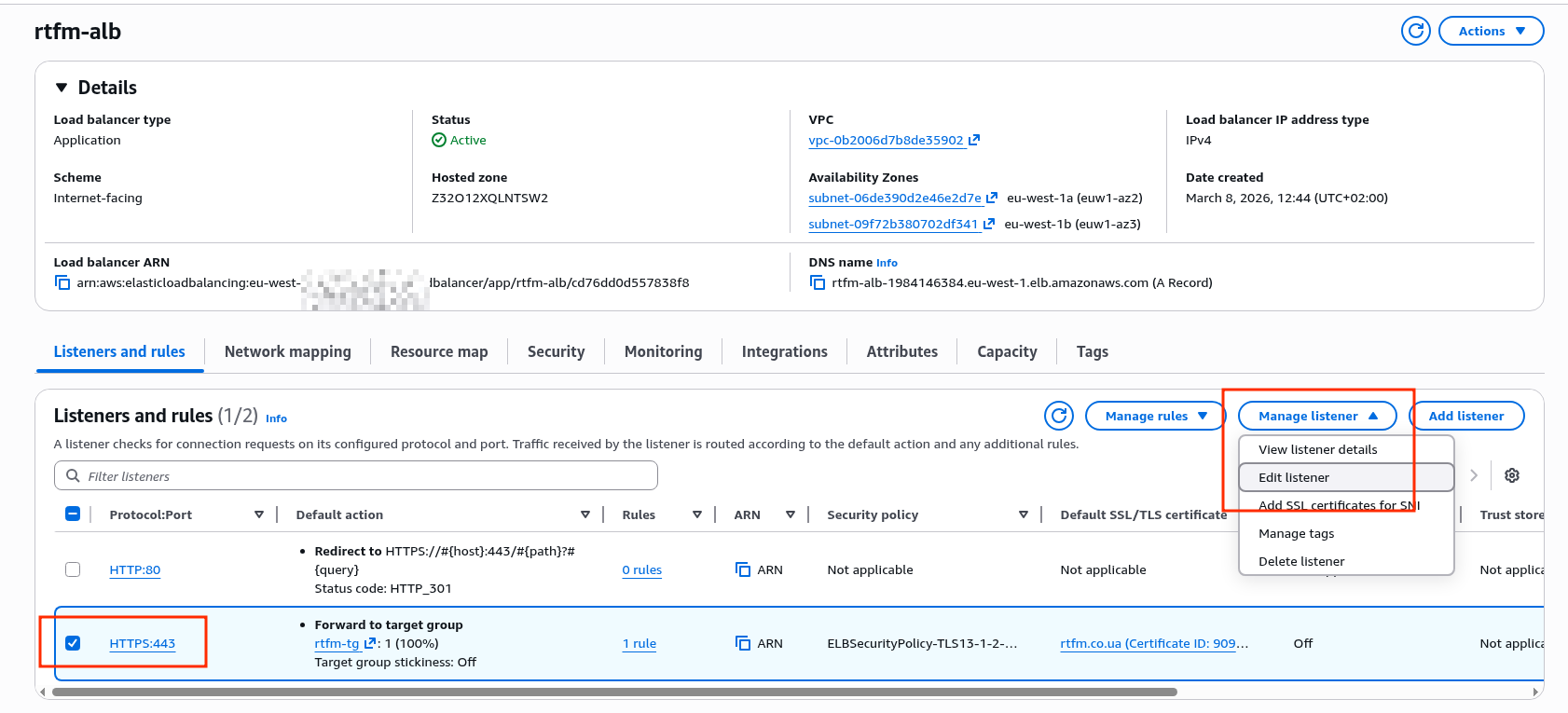
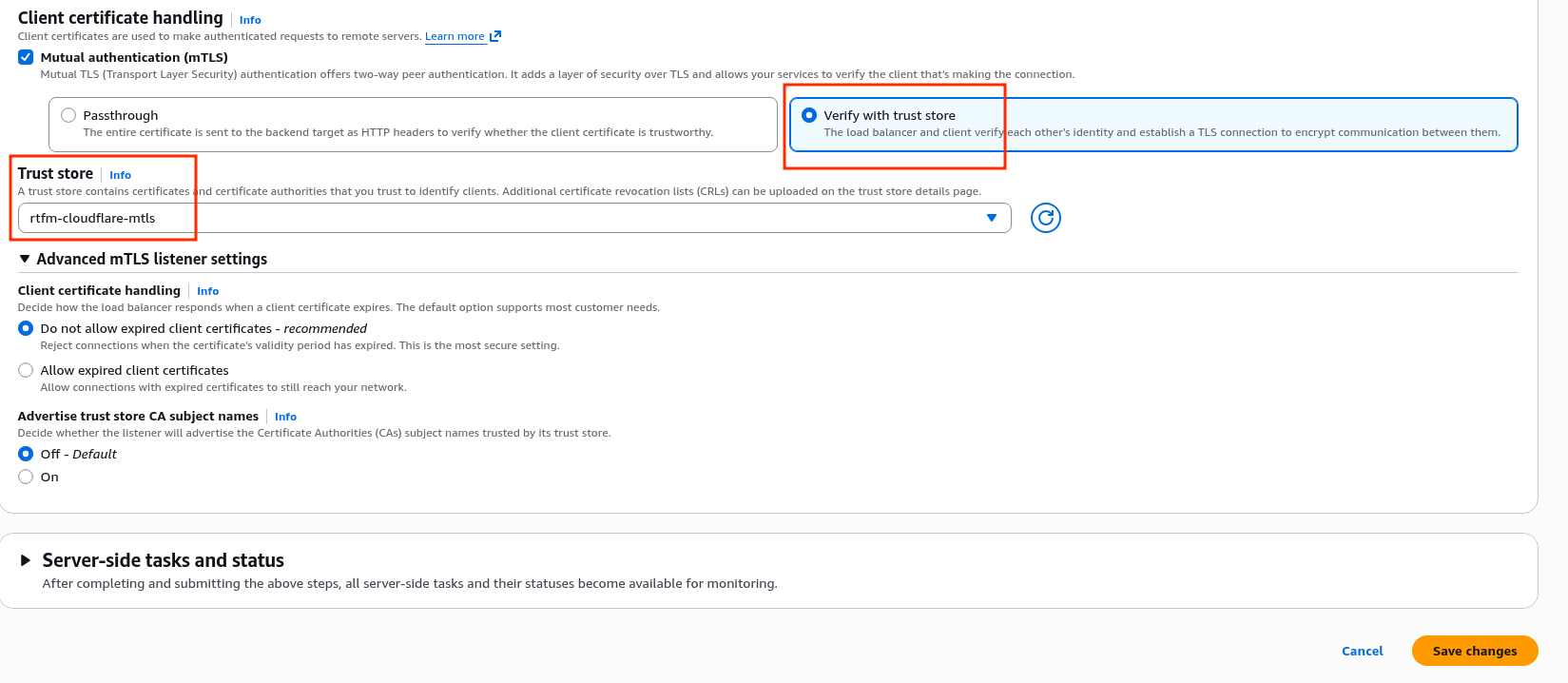
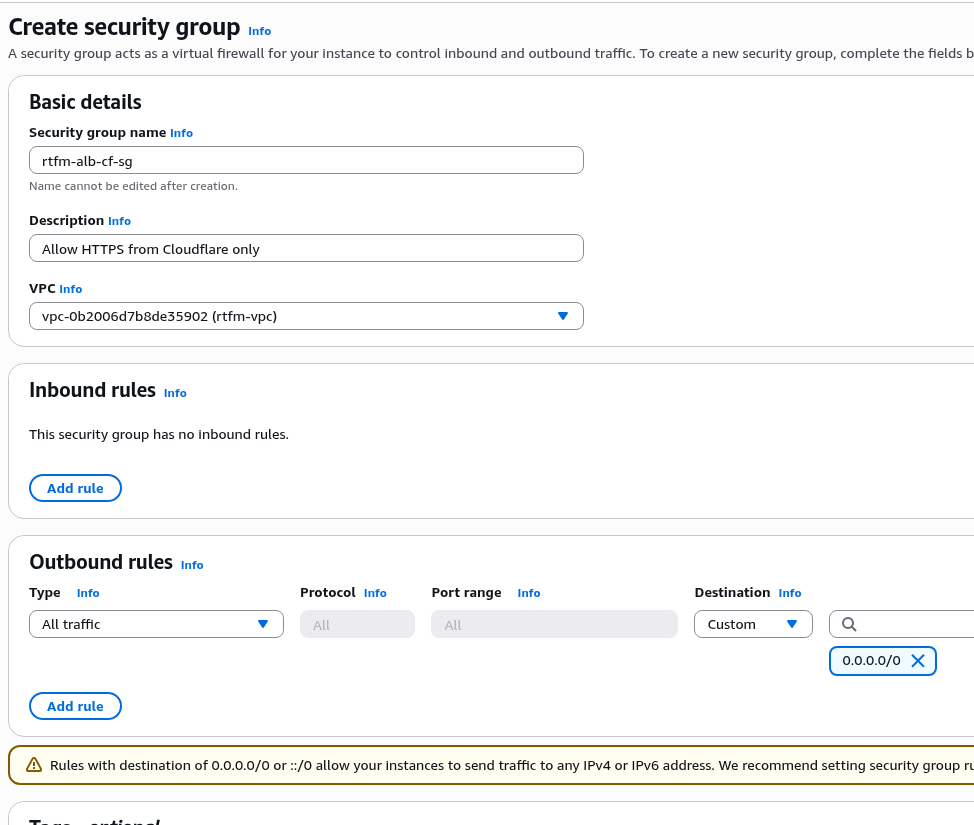
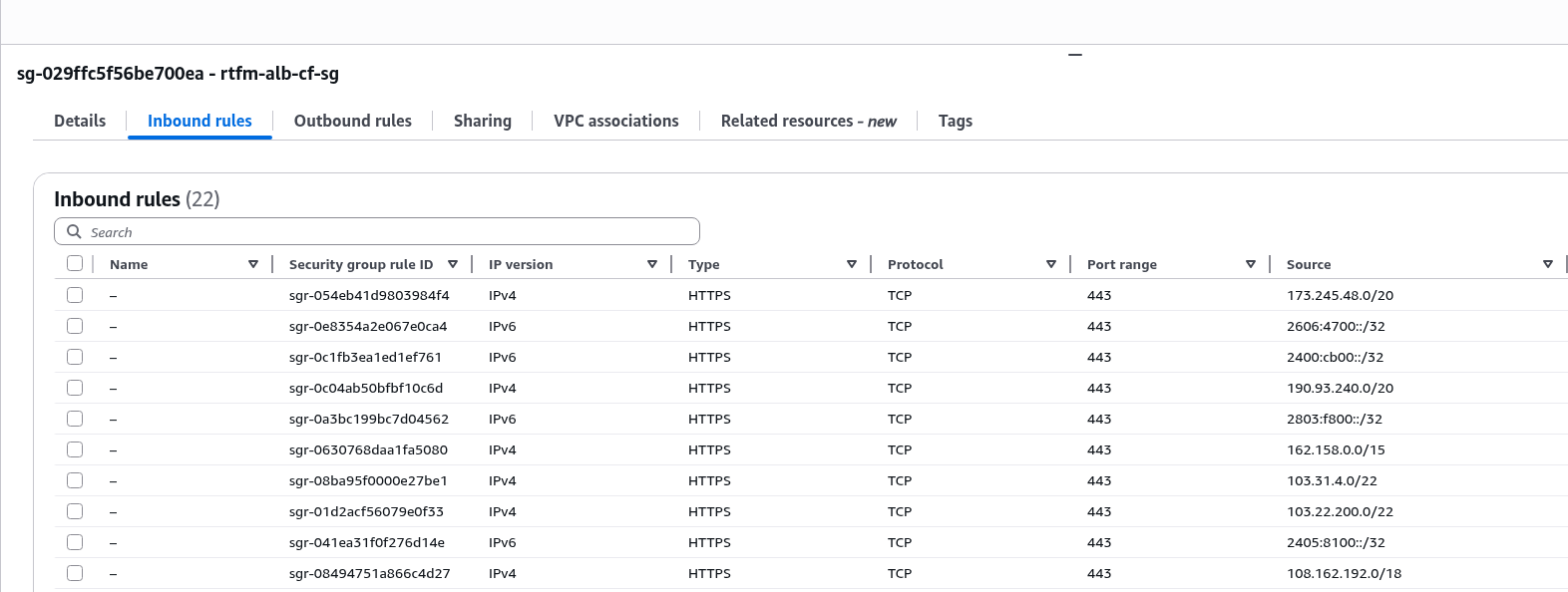
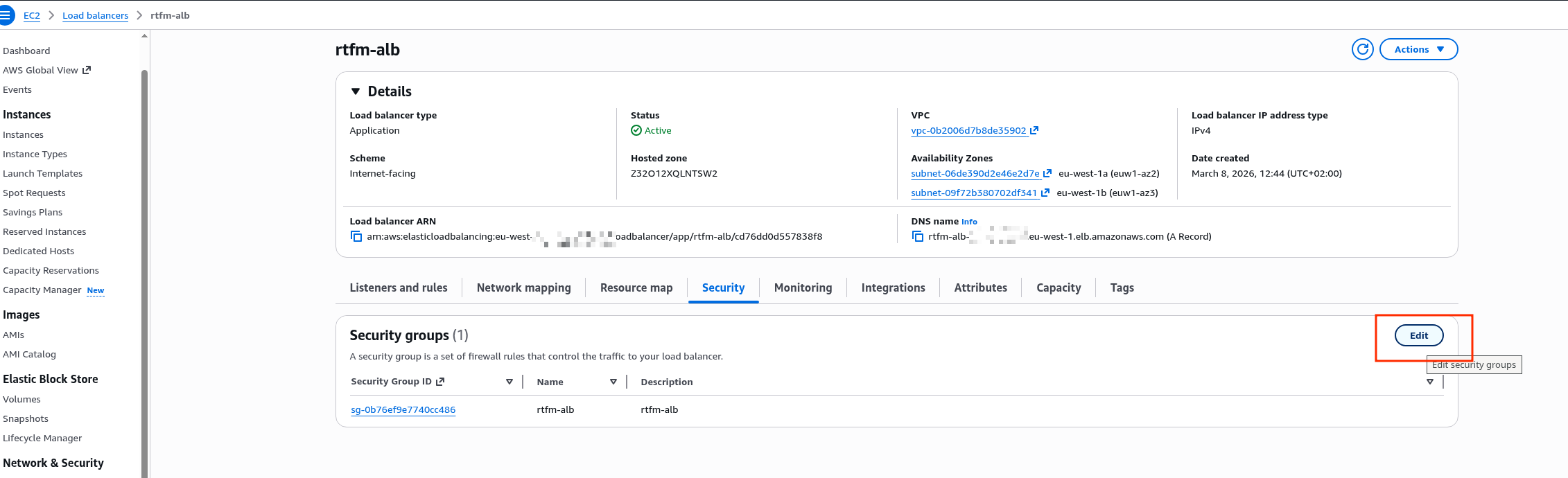
EC2 вже має IAM Role – створював Instance Profile, коли робив AWS: ALB та Cloudflare – налаштування mTLS та AWS Security Rules.
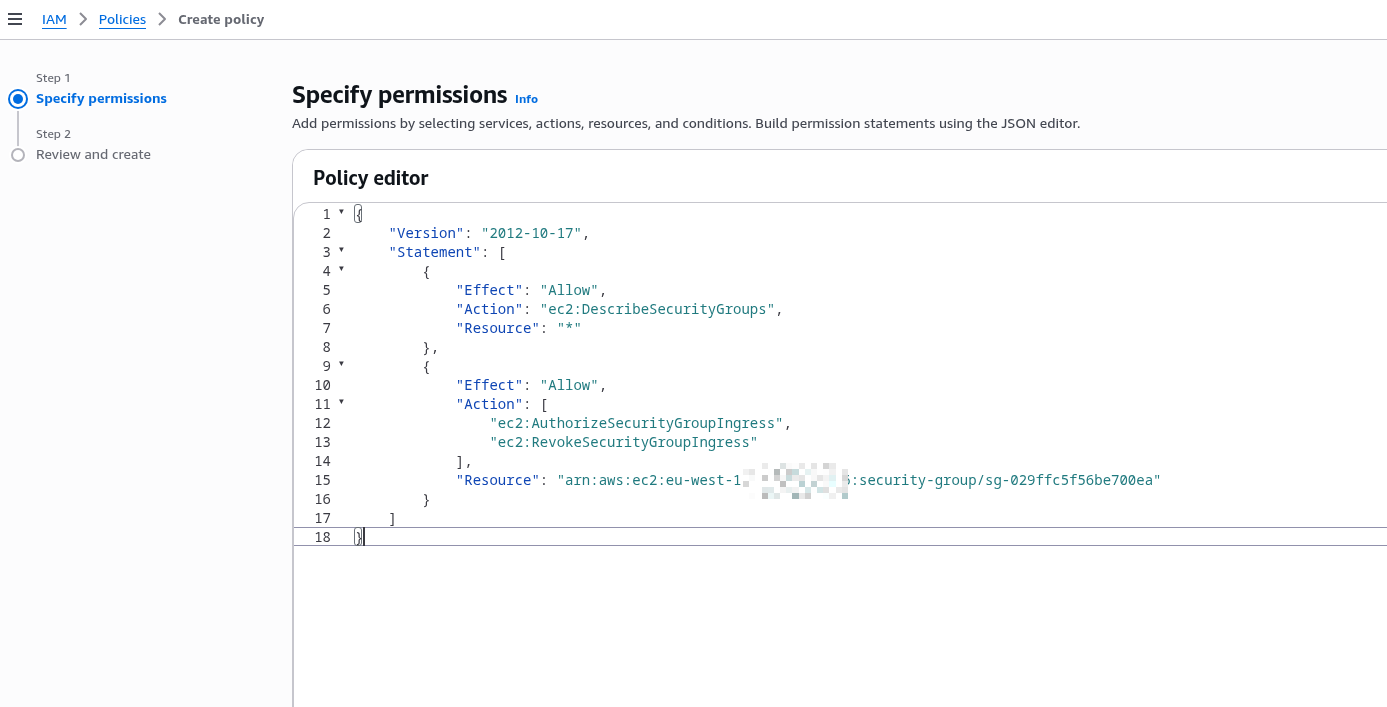
До цієї ролі треба додати IAM Policy для YACE, яка надасть доступу до CloudWatch та iam:ListAccountAliases – щоб відображати ім’я акаунта замість числового ID в метриках:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"cloudwatch:ListMetrics",
"tag:GetResources",
"iam:ListAccountAliases"
],
"Resource": "*"
}
]
}
Зберігаємо Policy:
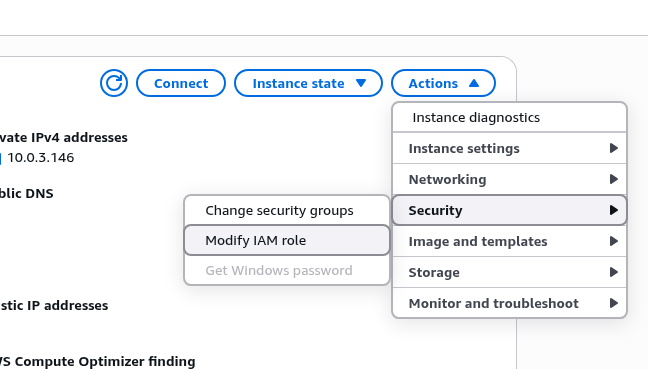
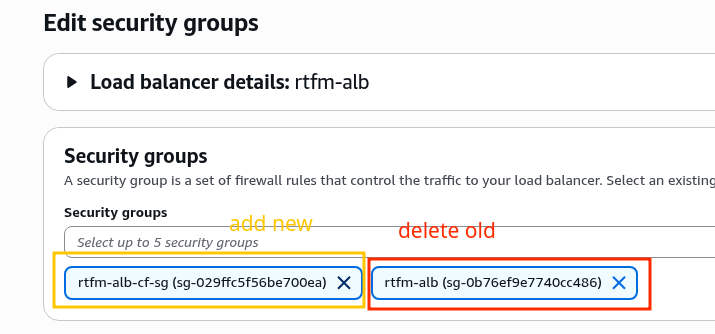
 Підключаємо до IAM Role EC2 інстансу
Підключаємо до IAM Role EC2 інстансу

Перевіряємо, що EC2 має доступ до CloudWatch – підключаємось по SSH, виконуємо з AWS CLI запит до CloudWatch:
[root@ip-10-0-3-146 ~]# aws cloudwatch list-metrics --namespace AWS/ApplicationELB --region eu-west-1
{
"Metrics": [
{
"Namespace": "AWS/ApplicationELB",
"MetricName": "HTTPCode_Target_3XX_Count",
"Dimensions": [
{
"Name": "TargetGroup",
"Value": "targetgroup/rtfm-tg/66df64e645b2b01d"
},
{
"Name": "LoadBalancer",
"Value": "app/rtfm-alb/cd76dd0d557838f8"
}
]
},
...
Конфігурація YACE
Створюємо конфіг /opt/monitoring/yace-config.yml. В exportedTagsOnMetrics вказуємо, які AWS-теги додавати до метрик – потім в Grafana і алертах можна буде виводити ім’я, а не ARN.
За збір метрик з CloudWatch платимо гроші, тому тут беремо тільки те, що дійсно корисне:
apiVersion: v1alpha1
discovery:
exportedTagsOnMetrics:
AWS/ApplicationELB:
- Name
AWS/RDS:
- Name
jobs:
- type: AWS/ApplicationELB
regions:
- eu-west-1
period: 300
length: 300
metrics:
- name: HTTPCode_ELB_5XX_Count
statistics:
- Sum
nilToZero: true
- name: ActiveConnectionCount
statistics:
- Sum
nilToZero: true
- type: AWS/RDS
regions:
- eu-west-1
period: 300
length: 300
metrics:
- name: CPUUtilization
statistics:
- Average
nilToZero: true
Додаємо YACE до Docker Compose file:
yace_exporter:
image: quay.io/prometheuscommunity/yet-another-cloudwatch-exporter:latest
container_name: yace
restart: unless-stopped
network_mode: host
volumes:
- /opt/monitoring/yace-config.yml:/tmp/config.yml:ro
command:
- '--config.file=/tmp/config.yml'
Перезапускаємо стек та перевіряємо метрики:
[root@ip-10-0-3-146 ~]# curl -s http://127.0.0.1:5000/metrics | grep aws_
# HELP aws_applicationelb_active_connection_count_sum Help is not implemented yet.
# TYPE aws_applicationelb_active_connection_count_sum gauge
aws_applicationelb_active_connection_count_sum{account_id="264***286",dimension_AvailabilityZone="",dimension_LoadBalancer="app/rtfm-alb/cd76dd0d557838f8",name="arn:aws:elasticloadbalancing:eu-west-1:264***286:loadbalancer/app/rtfm-alb/cd76dd0d557838f8",region="eu-west-1",tag_Name="rtfm-alb-main"} 336
...
Додаємо таргет до vmagent:
- job_name: "yace_exporter"
static_configs:
- targets:
- "10.100.0.20:5000"
Перевіряємо метрики в VictoriaMetrics:

Автозапуск експортерів із Docker Compose через systemd
Щоб весь стек піднімався автоматично після перезавантаження EC2 – додаємо systemd-сервіс.
Створюємо файл /etc/systemd/system/monitoring.service:
[Unit] Description=Monitoring exporters stack Requires=docker.service After=docker.service [Service] Type=oneshot RemainAfterExit=yes WorkingDirectory=/opt/monitoring ExecStart=/usr/bin/docker compose up -d ExecStop=/usr/bin/docker compose down TimeoutStartSec=60 [Install] WantedBy=multi-user.target
Додаємо в автостарт та запускаємо:
[root@ip-10-0-3-146 ~]# systemctl daemon-reload [root@ip-10-0-3-146 ~]# systemctl enable --now monitoring
VictoriaLogs та логи з Fluent Bit
Тепер логи. Основні логи – це NGINX та PHP errors. Їх будемо відправляти до VictoriaLogs на FreeBSD хості через http output – див. документацію VictoriaLogs по Fluentbit Setup.
Real IP в NGINX
Трафік до EC2 іде через Cloudflare та ALB, тому якщо нічого не налаштовувати – в логах NGINX замість реального IP клієнта буде адреса ALB. Cloudflare передає реальний IP у заголовку CF-Connecting-IP, а для NGINX є модуль ngx_http_realip_module, якому можна вказати з якого заголовка брати IP клієнта.
Додаємо до nginx.conf (не конфіг віртуалхоста, а конфіг самого NGINX), в секцію http {}:
http {
# trust ALB (all traffic comes from within VPC)
set_real_ip_from 10.0.0.0/16;
# get real client IP from Cloudflare header
real_ip_header CF-Connecting-IP;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
...
Перезавантажуємо NGINX та перевіряємо, що в логах з’явились реальні IP:
[root@ip-10-0-3-146 ~]# tail /var/log/nginx/rtfm.co.ua-access.log 94.139.42.59 - - [16/Mar/2026:17:29:14 +0200] "GET /ru/2021/11/29/ HTTP/1.1" 200 109096 "-" "kagi-fetcher/1.0" 2a01:4f8:242:3ce9::2 - - [16/Mar/2026:17:29:14 +0200] "GET /api/v1/instance/peers HTTP/1.1" 200 1976 "-" "Go-http-client/2.0"
Logrotate – ротація логів
В Amazon Linux NGINX вже йде з дефолтним конфігом для logrotate в файлі /etc/logrotate.d/nginx:
/var/log/nginx/*.log {
create 0640 nginx root
daily
rotate 10
missingok
notifempty
compress
delaycompress
sharedscripts
postrotate
/bin/kill -USR1 `cat /run/nginx.pid 2>/dev/null` 2>/dev/null || true
endscript
}
Дефолтний конфіг ротує всі файли *.log в /var/log/nginx/, але для логів RTFM та логів PHP можна написати свій конфіг з окремими налаштуваннями:
/var/log/nginx/rtfm.co.ua-*.log /var/log/php/rtfm.co.ua/*.log {
daily
rotate 14
compress
delaycompress
missingok
notifempty
sharedscripts
postrotate
nginx -s reopen
endscript
}
Установка Fluent Bit
Fluent Bit буде читати логи NGINX та PHP і відправляти їх до VictoriaLogs на домашньому NAS.
Додаємо репозиторій – створюємо файл /etc/yum.repos.d/fluent-bit.repo:
[fluent-bit] name=Fluent Bit baseurl=https://packages.fluentbit.io/amazonlinux/2023/ gpgcheck=1 gpgkey=https://packages.fluentbit.io/fluentbit.key enabled=1
Встановлюємо fluent-bit:
[root@ip-10-0-3-146 ~]# dnf install -y fluent-bit
Створюємо каталог для збереження позицій у файлах (щоб після перезапуску Fluent Bit не читав логи з початку):
[root@ip-10-0-3-146 ~]# mkdir -p /var/lib/fluent-bit
Конфігурація Fluent Bit – парсери для NGINX та PHP
Основний конфіг /etc/fluent-bit/fluent-bit.conf в мене виглядає так:
[SERVICE]
Flush 5
Daemon Off
Log_Level info
Parsers_File /etc/fluent-bit/parsers-custom.conf
[INPUT]
Name tail
Path /var/log/nginx/rtfm.co.ua-access.log
Tag nginx.access
DB /var/lib/fluent-bit/nginx-access.db
Parser nginx_access
[INPUT]
Name tail
Path /var/log/nginx/rtfm.co.ua-error.log
Tag nginx.error
DB /var/lib/fluent-bit/nginx-error.db
[INPUT]
Name tail
Path /var/log/php/rtfm.co.ua/rtfm.co.ua-error.log
Tag php.error
DB /var/lib/fluent-bit/php-error.db
[FILTER]
Name record_modifier
Match nginx.access
Record host aws-rtfm-main
Record job nginx
Record log_type access
Record site rtfm.co.ua
[FILTER]
Name record_modifier
Match nginx.error
Record host aws-rtfm-main
Record job nginx
Record log_type error
Record site rtfm.co.ua
[FILTER]
Name record_modifier
Match php.error
Record host aws-rtfm-main
Record job php-fpm
Record log_type error
Record site rtfm.co.ua
[FILTER]
Name lua
Match nginx.access
script /etc/fluent-bit/make_msg.lua
call make_msg
[Output]
Name http
Match *
host nas.setevoy
port 9428
uri /insert/jsonline?_stream_fields=stream,job,host,log_type,site&_msg_field=log&_time_field=date
format json_lines
json_date_format iso8601
compress gzip
Тут:
[SERVICE]: глобальні параметри Fleunt Bit[INPUT]: читаємо три файли, кожному задаємо власний tag, аби далі мати окремі фільтри[FILTER]: тут зrecord_modifierпо тегу з[INPUT]фільтруємо який саме лог модифікувати і додаємо нові поля, які потім можна використовувати в VictoriaLogs та алертах; у Fluent Bit на FreeBSD, де є власний NGINX і FPM має такі самі налаштування, тільки, звісно, інші значення полів- останній
[FILTER]викликає Lua-скрипт для створення поляlogs, див. нижче
В дефолтному конфігу Fluent Bit не було парсера для nginx_access – тому створив власний і підключив в [SERVICE] через файл /etc/fluent-bit/parsers-custom.conf:
[PARSER]
Name nginx_access
Format regex
Regex ^(?<remote_addr>[^ ]*) - (?<remote_user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>[^ ]*) (?<path>[^ ]*) (?<protocol>[^ ]*)" (?<status>[^ ]*) (?<bytes>[^ ]*) "(?<referer>[^"]*)" "(?<agent>[^"]*)"
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
Але тут випилюється поле _msg, яке VictoriaLogs очікує і без якого не дуже зручно дивитись в VMUI.
Пробував зробити з record_modifier, але врешті-решт просто навайбокодив скрипт на Lua, який створює поле log, яке потім передається до VictoriaLogs в &_msg_field=log:
function make_msg(tag, timestamp, record)
record["log"] = record["remote_addr"] .. ' "' .. record["method"] .. ' ' .. record["path"] .. '" ' .. record["status"] .. ' "' .. (record["agent"] or "-") .. '"'
return 1, timestamp, record
end
Запускаємо Fluent Bit:
[root@ip-10-0-3-146 ~]# systemctl enable --now fluent-bit
Перевіряємо логи в VictoriaLogs:

vmalert та алерти з логів у VictoriaLogs
Один з плюсів VictoriaLogs – це можливість писати алерти безпосередньо з логів. Колись писав детальніше в VictoriaLogs: створення Recording Rules з VMAlert, і є в частині FreeBSD: Home NAS, part 14 – логи з VictoriaLogs і алерти з VMAlert.
Приклад того, що написав собі – спочатку задані recording rules з exclude домашніх/робочих IP та адреси самого EC2, потім самі алерти:
groups:
- name: aws-rtfm-nginx-access-metrics
type: vlogs
interval: 1m
rules:
- record: aws:rtfm:nginx:requests_total:rate
expr: |
{job="nginx", log_type="access"}
| not (remote_addr:~"108.***.***.54|178.***.***.184")
| stats rate() as requests_rate
- record: aws:rtfm:nginx:requests_by_status:count
expr: |
{job="nginx", log_type="access"}
| not (remote_addr:~"108.***.***.54|178.***.***.184")
| stats by (status) count() as requests_count
- record: aws:rtfm:nginx:requests_by_status:rate
expr: |
{job="nginx", log_type="access"}
| not (remote_addr:~"108.***.***.54|178.***.***.184")
| stats by (status) rate() as requests_rate
- name: aws-rtfm-nginx-access-alerts
rules:
- alert: "NGINX: Too Many 5xx"
expr: aws:rtfm:nginx:requests_by_status:count{status=~"5.."} > 1
for: 1m
labels:
severity: warning
annotations:
summary: Server-side errors on rtfm.co.ua, users may be affected
description: |-
Domain: rtfm.co.ua
HTTP status: {{ $labels.status }}
Count: {{ $value }} req/min
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- alert: "NGINX: High Request Rate"
expr: aws:rtfm:nginx:requests_total:rate > 10
for: 2m
labels:
severity: warning
annotations:
summary: Unusual traffic spike on rtfm.co.ua
description: |-
Domain: rtfm.co.ua
Rate: {{ $value }} req/sec
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- name: aws-rtfm-php-error-metrics
type: vlogs
interval: 1m
rules:
- record: aws:rtfm:php:errors_total:count
expr: |
{job="php-fpm", log_type="error"}
| stats count() as errors_count
- name: aws-rtfm-php-error-alerts
rules:
- alert: "PHP-FPM: Too Many Errors"
expr: aws:rtfm:php:errors_total:count > 5
for: 2m
labels:
severity: warning
annotations:
summary: Application errors on rtfm.co.ua
description: |-
Domain: rtfm.co.ua
Count: {{ $value }} errors/min
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- name: aws-rtfm-php-fpm-alerts
rules:
- alert: "PHP-FPM: Slow Requests Detected"
expr: increase(phpfpm_slow_requests{pool="rtfm.co.ua"}[5m]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: PHP-FPM slow requests on rtfm.co.ua
description: |-
PHP-FPM slow requests detected during last {{ $for }}
Domain: rtfm.co.ua
Slow requests (last 5m): {{ $value }}
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- alert: "PHP-FPM: Pool Usage High"
expr: phpfpm_active_processes{pool="rtfm.co.ua"} / phpfpm_total_processes{pool="rtfm.co.ua"} * 100 > 80
for: 5m
labels:
severity: warning
annotations:
summary: FPM Pool usage high on rtfm.co.ua
description: |-
FPM Pool usage over 95% during last {{ $for }}
Domain: rtfm.co.ua
Pool used: {{ printf "%.2f" $value }}%
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
Рестаримо vmalert, перевіряємо в UI:

Alertmanager та алерти в Telegram і ntfy.sh
Про те, як створити Telegram-бота і налаштувати групу для алертів писав в пості EcoFlow: моніторинг з Prometheus та Grafana, тому тут опишу тільки конфіг Alertmanager – на FreeBSD це файл /usr/local/etc/alertmanager/alertmanager.yml.
В мене три роути і три ресівери – critical алерти дублюються через ntfy.sh, алерти по самій FreeBSD та NGINX/PHP йдуть в Telegram, плюс окремий Telegram канал для алертів EcoFlow:
global:
resolve_timeout: 5m
route:
receiver: "ntfy"
group_by: ["alertname, status"]
group_wait: 10s
group_interval: 5m
repeat_interval: 4h
routes:
- matchers:
- severity="critical"
receiver: "ntfy"
continue: true
- matchers:
- job="ecoflow_exporter"
receiver: "telegram_ecoflow"
- matchers:
- alertname =~ ".*"
receiver: "telegram_system"
receivers:
- name: "ntfy"
webhook_configs:
- url: "https://ntfy.sh/setevoy-nas-alertmanager-alerts"
http_config:
authorization:
type: Bearer
credentials: "***"
send_resolved: true
- name: telegram_system
telegram_configs:
- bot_token: "***"
chat_id: -100***962
api_url: https://api.telegram.org
parse_mode: HTML
message: |
{{ if eq .Status "firing" }}🔥{{ else }}✅{{ end }} <b>{{ .CommonLabels.alertname }}</b>
{{ range .Alerts }}
<b>Status:</b> {{ .Status | toUpper }}
{{ if .Labels.severity }}<b>Severity:</b> {{ .Labels.severity }}{{ end }}
{{ if .Annotations.summary }}<b>Summary:</b> {{ .Annotations.summary }}{{ end }}
{{ if .Annotations.description }}<b>Description:</b> {{ .Annotations.description }}{{ end }}
{{ end }}
- name: telegram_ecoflow
telegram_configs:
- bot_token: "***"
chat_id: -100***981
api_url: https://api.telegram.org
parse_mode: HTML
message: |
{{ if eq .Status "firing" }}🔥{{ else }}✅{{ end }} <b>{{ .CommonLabels.alertname }}</b>
{{ range .Alerts }}
<b>Status:</b> {{ .Status | toUpper }}
{{ if .Labels.severity }}<b>Severity:</b> {{ .Labels.severity }}{{ end }}
{{ if .Annotations.summary }}<b>Summary:</b> {{ .Annotations.summary }}{{ end }}
{{ if .Annotations.description }}<b>Description:</b> {{ .Annotations.description }}{{ end }}
{{ end }}
І тепер маємо алерти в Telegram:

Grafana dashboard
Вже не буду описувати весь процес створення, пізніше викладу дашборду десь в GitHub, але в мене виглядає так:

І додатково є “small version” для відображення на 14-дюймовому екрані ноутбука:

Власне, на цьому і все.
Вийшло класно, корисно, вже відловив кілька проблем і перебанив пачку ботів 🙂
![]()






















 в алерті для різних $value")