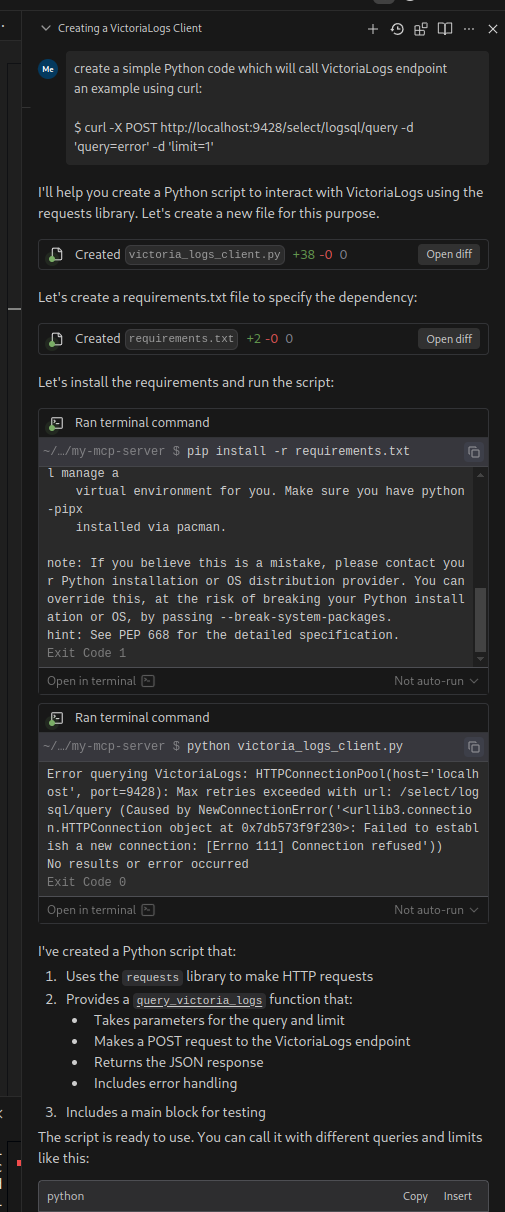
![]() Складно в одному пості описати те, про що написані тисячі книжок на тисячу сторінок, але сьогодні спробуємо швиденько розглянути основи того, як відбувається комунікація між хостами в мережі.
Складно в одному пості описати те, про що написані тисячі книжок на тисячу сторінок, але сьогодні спробуємо швиденько розглянути основи того, як відбувається комунікація між хостами в мережі.
Спочатку згадаємо про моделі OSI та TCP/IP, потім про структуру пакетів, встановлення підключень, і в кінці – заглянемо “під капот” Linux – подивимось на сокети і Linux TCP stack.
В основному увага буде саме TCP, бо це те, з чим ми найчастіше маємо справу.
What is: The TCP/IP
Отже, TCP/IP включає в себе два основних поняття:
- по-перше, це стек протоколів (стандартів, наборів правил) комунікації – TCP (Transmisstion Control Protocol) Та IP (Internet Protocol): вони описують те, яким чином встановлюються з’єднання між хостами та сервісами в Інтернеті. Ці протоколи стандартизовані і описані у відповідних RFC (TCP – RFC: 793, IP – RFC: 791)
- крім того, TCP/IP – це модель комунікації, яка включає в себе кілька рівнів – подібно до моделі OSI (і який теж описаний в Informational RFC – RFC 1180)
Загальна модель OSI
Модель OSI (Open Systems Interconnection model), розроблена та стандартизована ISO (International Organization for Standardization) у 1984 році – див. ISO/IEC 35.100.
Колись писав про це у схожому пості – What is: модель OSI, але то було давно, і без детального опису TCP/IP.
Отже, основна ідея моделі: будь-яке з’єднання в мережі проходить через кілька рівнів комунікації, де кожен рівень відповідає лише за свою задачу і не має доступу до логіки роботи інших рівнів – це називається Layer isolation.
При передачі даних між рівнями використовується принцип Encapsulation – кожен рівень “загортає” пакет даних у власну “обгортку” – додає власні заголовки до пакету, не змінюючи вміст попереднього рівня.
Якщо дуже спрощено, то процес можна відобразити так:
- коли наш браузер формує якийсь HTTP-запит – це відбувається на самому верхньому рівні, Application layer
- цей запит передається нижче, до Transport layer, де дані від браузера інкапсулюються (encapsulation): до даних з Application layer додаються заголовки з Transport layer – TCP headers
- потім, ще нижче – на Network layer додається IP-заголовок, що вказує адресу відправника й одержувача
- і нарешті, на Link layer формується Ethernet frame, який і передається через Physical layer
На приймаючій стороні (наприклад, EC2 інстанс з NGINX) все відбувається у зворотньому напрямку – decapsulation: кожен рівень знімає свою обгортку й передає payload вищому рівню.
Непогана діаграма є в OSI Model Explained (хоча тут HTTP header відображено навпроти Session layer – але це відбувається на Application layer):

PDU (Protocol Data Unit)
Крім того, коли ми говоримо “пакет” маючи на увазі дані – то технічно на кожному рівні моделі OSI ці дані називаються по-різному, а загальна назва для них – PDU (Protocol Data Unit):

Note: хоча на цій схемі теж є неточності, наприклад SQL – це мова запитів на Application layer
Тобто:
- Application, Presentation, Session рівні – це просто Data
- Transport layer (рівень 4) – це Segment (в TCP) або Datagram (UDP)
- Network layer – Packet (наприклад, IP-пакет, в якому може бути TCP-сегмент)
- Data Link layer – оперує Frames
- Physical layer – це вже біти, 0 та 1
Процес передачі даних від браузера до web-серверу з TLS
Давайте детальніше глянемо на те, як відбувається процес передачі даних:
- Layer 7 – Application layer:
- браузеру треба відправити дані – payload
- він оперує на Application layer, і формується HTTP-запит з HTTP headers (аутентифікація, кешування, сам запит до потрібного ресурсу – URI, та куди запит йде – URL)
- тут встановлюється HTTP-сесія – через cookies, JWT-токен, параметри URL тощо
- сформовані дані передаються до Presentation Layer
- Layer 6 – Presentation Layer:
- якщо використовується шифрування, то тут підключаться бібліотеки SSL/TLS і шифрують дані
- додаються TLS headers
- при потребі виконується перетворення даних, наприклад кодування символів (ASCII, UTF-8)
- Layer 5 – Session Layer:
- тут відбувається процес TLS handshake – встановлення методів і ключів шифрування (класний матеріал на цю тему – The Illustrated TLS 1.2 Connection, і колись писав я – What is: SSL/TLS в деталях)
- створюється TLS-сесія між клієнтом та сервером
- Layer 4 – Transport Layer:
- тут формується TCP-сегмент (або datagram для UDP, втім тут ми розглядаємо браузер та HTTP, тому TCP): до даних від вищих рівнів (наприклад, браузера) додаються TCP headers – Source port, Destination port, порядковий Sequence number – номер пакету (див Multiplexing and Demultiplexing in Transport Layer)
- задаються TCP flags –
ACK, etc - розмір TCP-сегменту обмежується MSS (Maximum Segment Size) – будемо дивитись далі
- Layer 3 – Network Layer:
- тут до TCP-сегменту додаються IP headers – звідки пакет відправлений (source IP), куди він йде (destination IP) і формується IP пакет
- додаються дані про TTL (Time To Live) пакту, checksum пакету для перевірки отримувачем – чи пакет дійшов неушкодженим
- розмір IP-адреси – 32 біти в IPv4, та 128 біт в IPv6
- від IP-адреси залежить тип передачі даних – unicast (одному адресату), multicast (кільком адресатам), там broadcast – всім хостам в заданій мережі
- на цьому ж рівні працює ICMP для обміну інформацією стан мережі і про помилки
- на Network layer ICMP packets можуть створюватися автоматично при проблемах на рівні маршрутизації
- але можуть формуватись і на Application layer, наприклад утилітами
pingабоtraceroute
- Layer 2 – Data Link Layer:
- Ethernet, Wi-Fi – драйвери мережевої карти формують frame, додаючи MAC-адресу відправника і отримувача і власну перевірку цілісності пакету – CRC (cyclic redundancy check)
- MAC адреси визначаються за допомогою протоколу ARP (Adress Resolution Protocol)
- Layer 1 – Physical Layer:
- фізичне з’єднання, електричні або оптичні сигнали
DNS в моделі OSI
Окремо давайте розглянемо питання про DNS:
- Layer 7 – Application layer:
- браузеру потрібно відправити запит на “google.com”
- браузер виконує функцію
getaddrinfo()абоgethostbyname()(застаріла) з бібліотекиglibcglibcперевіряє параметри/etc/nsswitch.conf:- при необхідності виконати зовнішній DNS-запит (наприклад, якщо нема запису в
/etc/hosts) – перевіряє параметри в/etc/resolv/conf - формується DNS-запит, відкривається UPD- або TCP-сокет
- при необхідності виконати зовнішній DNS-запит (наприклад, якщо нема запису в
- Layer 4 – Transport Layer:
- на транспортному рівні до PDU (сегменту TCP або датаграми UDP) додається заголовок з destination port 53 (зазвичай UDP, але може бути TCP – якщо відповідь більша за 512 байт або включено режим DNS-over-TCP, DoT – див. RFC 7766)
- Layer 3 – Network Layer:
- до пакету додаються IP headers – куди саме відправити запит
- Layer 2 – Data Link Layer та Layer 1 – Physical Layer: передача даних
Модель OSI ISO vs модель TCP/IP
Модель TCP/IP (або Internet Protocol Suite) була розроблена у 1970-х, ще до появи OSI і лягла в основу Інтернету (і його попередника – ARPANET).
Моделі OSI ISO та TCP/IP створені для уніфікації зв’язку між пристроями, але мають ключові відмінності:
- OSI описує 7 рівнів, тоді як TCP/IP – 4
- Application Layer в TCP/IP включає в себе Application, Presentation та Session layers моделі OSI
- а Network Access Layer в TCP/IP включає в себе Data Link та Physical layers моделі OSI (іноді називають Link Layer)
- модель OSI це більш “академічна модель”, яка використовується для пояснення принципів роботи мережі, а TCP/IP – “прикладна модель”, на якій власне побудована комунікація в Інтернеті
Головна різниця в тому, що:
- модель TCP/IP створювалась для опису вже існуючих протоколів (TCP, IP, FTP, SMTP тощо), які використовувались в ARPANET – тобто спочатку технологія, а потім її опис у вигляді моделі.
- натомість модель OSI – це більше теоретична моделі, яку спочатку описали (“як це має бути”), і потім вже під цю модель почали додавати нові протоколи.
Непогана ілюстрація в рівнях моделей є в A Refresher Course on OSI & TCP/IP:
 TCP headers та payload
TCP headers та payload
Окей – з загальною схему передачі даних розібрались, давайте подивимось детальніше на те, що і як саме передається в TCP/IP.
Оскільки ми вже згадували про TCP headers – то давайте почнемо з них.
TCP header має однакову структуру незалежно від того, чи він передається всередині IPv4 або IPv6. Його мінімальний розмір 20 байт, а максимальний, за рахунок використання поля Options – 60 байт.
IPv4 headers має змінну довжину – від 20 до 60 байт, а от заголовки IPv6 фіксовані в 40 байт.
MTU, MSS та TCP Payload
Максимальний розмір даних, які можна передати в одному IP-пакеті та TCP-сегменті, і залежить від розміру Ethernet frame, MTU (Maximum Transmission Unit), який по дефолту заданий в 1500 байт:
$ ifconfig wlan0 | grep -i MTU wlan0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
Від цих 1500 байт віднімається місце під TCP та IP заголовки, і в результаті це дає нам MSS (Maximum Segment Size) – максимальний розмір корисних даних у TCP-сегменті:
MSS = (MTU) - (IP header) - (TCP header)
= 1500 - 20 - 20
= 1460 байт
MSS оголошується під час TCP-handshake через TCP option MSS в пакеті SYN, і обидві сторони узгоджують значення, що дозволяє відправнику враховувати цей розмір, аби уникнути IP-фрагментації.
Якщо TCP payload перевищує MSS – то стек TCP виконує сегментацію, тобто розбиває цей потік на кілька окремих TCP-сегментів.
Наприклад, браузер відправляє POST-запит розміром 3000 байт – тоді TCP поділить цей запит на:
- сегмент 1 з розміром даних 1460 байт
- сегмент 2 з розміром даних 1460 байт
- сегмент 3 з 80 байтами
У випадку з TCP-сегментації – кожен пакет матиме власні заголовки, а його Sequence Number буде вказувати на позицію першого байта даних цього сегмента в загальному потоці даних. При цьому розмір payload кожного сегмента не перевищуватиме MSS.
IP-фрагментація – виняткова ситуація, який трапляється тільки якщо TCP-сегмент (або інший IP-пакет) вже перевищив MTU, і в ідеалі не має відбуватись.
Структура TCP headers
Отже, після отримання даних від Application layer формується TCP-сегмент, до якого додається набір TCP headers:

Note: далі все ж буду використовувати слово “флаги”, а не “прапорці”, бо в контексті TCP якось більш коректно звучить
Тут:
- Source port: поле 16 біт в якому вказується порт відправника
- Destination port: поле 16 біт в якому вказується порт призначення
- Sequence number: поле 32 біти, яке вказує на перший байт даних (payload) кожного TCP-сегменту
- Acknowledgment number: поле 32 біти, яке передається отримувачем для запиту наступного TCP-сегменту – це буде Sequence Number + 1
- DO (data offset): поле 4 біти яке вказує де закінчується TCP header і починаються дані (payload)
- RSV (reserved field): 3 биті, не використовується, і завжди пусте
- Flags: 9 біт, також називаються “control bits” – використовуються для передачі флагів, які контролюють встановлення підключення, передачу даних та закриття підключення
- URG: urgent pointer – якщо флаг заданий, то сегмент має термінові дані, які на стороні операційної системи отримувача можуть бути передані окремим системним викликом минуючи загальний TCP-буфер (див. TCP – Urgent pointer field)
- не впливає на маршрутизацію чи доставку пакета мережею і використовується тільки локально стеком ядра операційної системи отримувача
- ACK: acknowledgment підтвердження отримання сегменту
- PSH: push function – передати дані негайно, не очікуючи наповнення TCP-буферу
- RST: reset – примусове закриття з’єднання при помилках
- SYN: початок з’єднання (в TCP 3-way handshake, далі подивимось), задає Initial Sequence Number – див. трохи ниже
- FIN: нормальне закриття з’єднання, відправляється як клієнтом, так і сервером
- URG: urgent pointer – якщо флаг заданий, то сегмент має термінові дані, які на стороні операційної системи отримувача можуть бути передані окремим системним викликом минуючи загальний TCP-буфер (див. TCP – Urgent pointer field)
- Window: 16 біт, вказується максимальна кількість байт, які відправник (і клієнт, і сервер) може відправити без очікування наступного
ACKвід серверу (контроль TCP-буферу ядра на стороні серверу) - Checksum: 16 біт, контрольна сума TCP-заголовка + даних, використовується для перевірки, чи не пошкоджено сегмент під час передачі
- Urgent pointer: 16 біт, якщо заданий
URG, то тут вказується де завершуються термінові дані - Options: 0 – 320 біт, використовується для передачі MSS, timestamps тощо
Sequence Number
Доволі цікава тема, яку коротко, мабуть, є сенс проговорити окремо.
TCP – це потоковий протокол, який передає послідовність байт, а не окремі повідомлення.
Під час передачі даних в TCP-сесії:
- клієнт відправляє
SYNз Initial Sequence Number, який спочатку задається у вигляді рандомного числа, наприклад 100000 - сервер відповідає
SYN-ACK, підтверджуючи отримання запиту на з’єднання (SYN)- в полі Acknowledgment Number вказує 100001
- далі, при початку передачі першого сегменту даних – клієнт в першому сегменті вкаже Sequence Number 100001, а в наступному – 101461 (при MSS 1460 байт)
Тобто, кожен наступний сегмент збільшує Sequence Number на довжину payload.
Перегляд TCP headers в Wireshark
Самий простий спосіб – з wireshark (або wireshark-qt).
Запускаємо від root, вибираємо інтерфейс:

Наприклад, подивитись трафік до RTFM – знаходимо IP:
$ dig rtfm.co.ua +short 104.26.3.188 104.26.2.188 172.67.68.115
Задаємо фільтр:
ip.addr==104.26.3.188 || ip.addr==104.26.2.188 || ip.addr==172.67.68.115
І отримуємо дані:

TCP connection
Трохи розібрались з TCP headers – тепер давайте глянемо на те, як встановлюється TCP-з’єднання.
Отже, TCP – це протокол, орієнтований на з’єднання (тобто потребує встановлення сесії до початку передачі даних), який забезпечує доставку даних, контроль потоку та виявлення помилок при передачі.
На відміну від UDP – з TCP ми або гарантовано передаємо дані, або буде виявлена помилка і з’єднання буде розірване.
TCP handshake
Як і в TLS, встановлення TCP-з’єднання відбувається за стандартним процесом – “3-way handshake“.
По TLS – див. What is: SSL/TLS в деталях.
TCP handshake складається з трьох етапів (власне, тому і назва “3-way handshake”):
SYN: клієнт відправляє пакет з флагомSYN, вказуючи свій Initial Sequence NumberSYN-ACK: сервер відповідає пакетом з флагамиSYNтаACK, цим він:- підтверджує отримання
SYNвід клієнта (встановлюючи поле Acknowledgment Number) - відправляє свій власний Initial Sequence Number
- підтверджує отримання
ACK: клієнт відправляєACK, чим підтверджує отриманняSYN-ACKвід серверу
На цьому сесія вважається встановленою, і починається передача даних.
Закриття сесії – “4-way FIN handshake“:
FIN: клієнт повідомляє сервер (або навпаки), що закінчив передачу, і готовий до закриття сесіїACKвід серверу: сервер підтверджує отриманняFINFINвід серверу: сервер повідомляє, що теж готовий закрити сесіюACKвід клієнта: клієнт відповідає фінальнимACK, підтверджуючи отриманняFINвід сервера
Після цього з’єднання повністю закривається.
Аналіз сесії з Wireshark
Можна писати відразу в Wireshark, можемо спочатку створити файл, а потім його вже аналізувати.
Запускаємо tcpdump:
$ sudo tcpdump host 104.26.3.188 or host 104.26.2.188 or host 172.67.68.115 -w tcp.pcap
В іншому вікні виконуємо запит до RTFM:
$ curl https://rtfm.co.ua
Відкриваємо сформований дамп у Wireshark:
$ sudo wireshark tcp.pcap
І отримуємо всі пакети, які були передані:

Власне тут ми першими і бачимо 3-way handshake – початок з’єднання:
SYN(клієнт 50556 => сервер 443):Seq=0, Len=0- клієнт (192.168.0.116) відкриває з’єднання маючи локальний порт 50556 до серверу RTFM на до 172.67.68.115 і порт 443
SYN, ACK(443 → 50556):Seq=0 Ack=1, Len=0- відповідь від серверу 172.67.68.115 , що він підтвердив отримання
SYNвід клієнту 192.168.0.116 (флаг `ACK), і задає свій флагSYN` з Initial Sequence Number, встановлюючи початкову точку для свого потоку даних
ACK(50556 → 443):Seq=1 Ack=1, Len=0- Клієнт підтверджує
SYNвід сервера
Четвертим вже починається передача даних – Len-1388 (насправді, це вже початок TLS handshake – наступним, п’ятим пакетом бачимо TLSv1.3).
Seq=0 – це як раз Sequence Number, про який говорили вище.
Просто Wireshark його відображає в зручній для нас формі, але ми можемо побачити його реальне значення:

Len=0 в перших трьох пакетах нуль, бо це тільки встановлення з’єднання, ще до передачі даних, і пакети містять тільки TCP-заголовки для встановлення з’єднання, без даних.
Ack=N – підтвердження отримання пакету.
Тобто:
Seq=0:- клієнт відправляє Inital Sequence Number, який Wireshark нам відображає як 0
Seq=0 Ack=1 Len=0:Seq=0– сервер теж задає свій Inital Sequence NumberAck=1– сервер інкрементитьSeqвід клієнта на +1
Seq=1 Ack=1 Len=0:Seq=1– тепер клієнт збільшує свій Sequence NumberAck=1– клієнт підтверджує отриманняSYNвід серверу
TCP та ядро Linux
В ядрі операційної системи для передачі даних за TCP-протоколом реалізована своя система – TCP stack.
Вона відповідає за:
- відкриття та завершення TCP-сесій
- контроль доставки (
ACK,SEQ) - повторну передачу втрачених пакетів
- розпізнавання флагів (
SYN,FIN,RSTтощо) - збирання даних з кількох сегментів у правильному порядку
По факту, це набір функцій в ядрі, які опрацьовують TCP-пакети.
А сам TCP-стек – це частина мережевого стеку ядра, разом з обробкою Ethernet, ARP, IP, UDP та інших.
Див. документацію на kernel_flow.
Буфери ядра – це основне, з чим можна зіткнутись при налаштуванні чи тюнингу ядра:
rmem_*: receive buffer (для вхідного трафіку)wmem_*: write buffer (для вихідного трафіку)
Дефолтні значення задаються в /proc/sys/net/ipv4/tcp_rmem та /proc/sys/net/ipv4/tcp_wmem відповідно.
А перевизначити їх можна з sysctl:
$ sudo sysctl -w net.ipv4.tcp_rmem="4096 87380 6291456" $ sudo sysctl -w net.ipv4.tcp_wmem="4096 65536 6291456"
Ядро також підтримує автоматичне масштабування буферів – файл /proc/sys/net/ipv4/tcp_moderate_rcvbuf:
$ cat /proc/sys/net/ipv4/tcp_moderate_rcvbuf 1
1 – включено, 0 – виключено.
Мінімальний Maximum segment size (MSS) задається у файлі /proc/sys/net/ipv4/tcp_min_snd_mss:
$ cat /proc/sys/net/ipv4/tcp_min_snd_mss 48
48 байт == 384 біти.
Мінімальний розмір задається для запобіганню відправки надто маленьких TCP-сегментів, які викликатимуть зайві накладні витрати та зниження продуктивності.
Процес отримання TCP-пакету ядром
Як в системі виглядає процес отримання даних?
Див. kernel_flow.
Якщо спрощено, то:
- Layer 2: Link layer
- Network Interface Card отримує Ethernet frame з TCP-пакетом
- ядро системи викликає драйвер карти, а драйвер викликає функцію
netif_receive_skb()і передає весь отриманий кадр (в структуріskb– Socket Buffer) на обробку мережевій підсистемі ядра
- Layer 3: Network layer
- пакет передається до
ip_rcv()(IPv4) абоipv6_rcv()(IPv6), де перевіряється заголовок IP для визначення протоколу - якщо Protocol = 6 (TCP) – пакет передається в
tcp_v4_rcv()
- пакет передається до
- Layer 4: Transport layer
- функція
tcp_v4_rcv()перевіряє контрольну суму, знаходить відповідний локальний сокет (порт), обробляєSEQ/ACK/FIN/RST/SYNфлаги, і додає payload у receive buffer сокета, прив’язаного до відповідного порту (наприклад,listen(80)для веб-сервера) - після передачі даних до веб-серверу – ядро формує
ACK-пакет у відповідь - дані передаються у внутрішній receive buffer сокета, і звідти вже передаються в userspace до веб-серверу (якщо ми про браузер-сервер)
- функція
Якщо заглиблюватись – то можна взяти утиліти по типу Systemtap для відстеження системних викликів.
Сокети та TCP-порти в Linux
Для роботи з TCP в Linux є концепція сокетів (sockets) – це такі собі ендпоінти, які прив’язуються до пари IP:PORT.
Непоганий текст з діаграмами – TCP handling in Linux.
Власне сокет – це абстракція, яка дозволяє програмам читати/писати в мережу, як через звичайний файл, і по суті і є файловим дескриптором спеціального типу: операційна система сприймає їх як пайп (pipe), через який можна передавати дані.
Сокети можуть бути або локальними, аби мережевими:
AF_INETдля IPv4 таAF_INET6для IPv6AF_UNIXабоAF_LOCAL– для локальної роботи
AF_* в імені – це “Address Family“, бо маємо не тільки TCP/UDP-сокети, але й AF_UNIX – локальні, AF_BLUETOOTH – Bluetooth, AF_NETLINK – Netlink і т.д.
При створенні сокету задається його тип:
socket(AF_INET, SOCK_STREAM, 0); // TCP socket(AF_INET, SOCK_DGRAM, 0); // UDP
А потім з функцією bind() виконується прив’язка до IP та порту.
C programming: UNIX Socket
Можна звісно робити на якомусь Python, але програмування на C покаже нам більше деталей.
Приклад роботи сокетів писав в C: сокеты и пример модели client-server (2017 рік, боже…).
Простий приклад локального сокету:
// Create a UNIX domain socket file at /tmp/mysocket.sock
#include <sys/socket.h> // import socket(), bind() functions
#include <sys/un.h> // import C struct sockaddr_un
#include <unistd.h> // import close() function
#include <stdio.h> // import input/output functions like print()
#include <string.h> // import strings/memory functions like strlen()
// def main C function
int main() {
// define a variable with the 'int' type
// it will store the socket's file descriptor ID returned by the socket() function
// a file descriptor is just an integer index into the per-process open file table
// the actual 'file' struct exists in kernel space, user space only sees the integer
int sockfd;
// define a variable named 'addr' with the 'struct sockaddr_un' type
// this structure is used to specify socket address for AF_UNIX sockets
struct sockaddr_un addr;
// Step 1: create socket
// socket(domain, type, protocol)
// AF_UNIX: UNIX domain socket
// SOCK_STREAM: stream-oriented (like TCP)
// '0': protocal, set to 0 as AF_UNIX + SOCK_STREAM have no protocal
sockfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
return 1;
}
// Step 2: set up address structure
memset(&addr, 0, sizeof(addr)); // zero out the memory for safety
addr.sun_family = AF_UNIX; // set socket family (UNIX domain)
strcpy(addr.sun_path, "/tmp/mysocket.sock"); // set path for the socket file in the 'addr' structure
// Step 3: remove old socket file if it exists
// unlink removes a file; important to avoid "Address already in use" error
unlink("/tmp/mysocket.sock");
// Step 4: bind
//
// bind the socket to a local address (path in the filesystem) - bind(sockfd, addr, size_of_addr)
// 'sockfd': socket file descriptor returned by socket()
// '&addr': pointer to the sockaddr_un struct that contains:
// - family (AF_UNIX)
// - path (filesystem path to the socket file)
// '(struct sockaddr*)': cast required because bind() expects a generic sockaddr*
// 'sizeof(addr)': size of the sockaddr_un structure
//
// after this call, the socket is associated with a specific name (path),
// so other processes can connect to it via this path.
if (bind(sockfd, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
perror("bind");
return 1;
}
printf("UNIX socket created at /tmp/mysocket.sock\n");
// Step 5: keep socket alive for inspection
sleep(60);
// Step 6: cleanup
close(sockfd); // close the socket file descriptor
unlink("/tmp/mysocket.sock"); // remove the socket file from filesystem
return 0;
}
Збираємо з gcc:
$ gcc unix_socket.c -o unix_socket
Запускаємо:
$ ./unix_socket UNIX socket created at /tmp/mysocket.sock
І маємо відкритий сокет:
$ file /tmp/mysocket.sock /tmp/mysocket.sock: socket $ ls -l /tmp/mysocket.sock srwxr-xr-x 1 setevoy setevoy 0 Jun 29 10:30 /tmp/mysocket.sock
В ls -l бачимо флаг “s” на початку – показує, що це тип socket.
Власне саме так і створюються сокети в Linux, які ми можемо бачити для якихось локальних демонів, наприклад:
$ sudo find / -type s 2>/dev/null ... /run/docker.sock /run/dbus/system_bus_socket ... /run/dhcpcd/sock ...
C programming: AF_INET Socket
AF_INET та AF_INET6 створюються і працюють аналогічно до локальних UNIX-сокетів – тільки замість “адреси” у вигляді імені локального файлу використовують пару IP:PORT.
Також їх називають “BSD sockets” або “Berkeley sockets”, бо вперше вони були реалізовані Berkeley Software Distribution (BSD) Unix у 1983 році.
Код в принципі схожий на створення UNIX-сокету:
#include <stdio.h> // for printf(), perror()
#include <stdlib.h> // for exit()
#include <string.h> // for memset()
#include <unistd.h> // for close()
#include <sys/types.h> // for socket types
#include <sys/socket.h> // for socket(), bind()
#include <netinet/in.h> // for sockaddr_in
#include <arpa/inet.h> // for inet_addr()
int main() {
// will store the socket's file descriptor (int)
int sockfd;
// Step 1: create a new socket
// AF_INET = IPv4 address family
// SOCK_STREAM = TCP (reliable byte stream)
// 0 = default protocol (IPPROTO_TCP for AF_INET)
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("socket creation failed");
exit(EXIT_FAILURE);
}
// define the address to bind the socket to
struct sockaddr_in server_addr;
// Step 2: fill the 'server_addr' structure with zeros to avoid undefined or leftover data
memset(&server_addr, 0, sizeof(server_addr));
// AF_INET for IPv4
server_addr.sin_family = AF_INET;
// port number
server_addr.sin_port = htons(8080);
// bind to th 'localhost' (127.0.0.1)
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
// Step 3: bind the socket to the given IP address and port
// this makes the socket listen for incoming connections on the '127.0.0.1:8080'
if (bind(sockfd, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
perror("bind failed");
close(sockfd); // close socket before exiting
exit(EXIT_FAILURE);
}
// Step 4: listen for incoming connections
// the socket is now ready to accept connections
// function: int listen(int sockfd, int backlog);
// 'sockfd' is the socket file descriptor
// 'backlog' is the maximum number of pending connections
// if the backlog is exceeded, new connections will be refused
// here we set it to 5, meaning up to 5 connections can be queued
if (listen(sockfd, 5) < 0) {
perror("listen");
return 1;
}
printf("Socket successfully created and bound to 127.0.0.1:8080\n");
printf("Press Enter to close the socket...\n");
// keep the socket open for inspection
getchar();
// Step 5: close the socket after use
close(sockfd);
return 0;
}
Але тут:
- задаємо тип
AF_INET - задаємо TCP-порт
- задаємо IP, на якому слухати
- з системним викликом
listen()переводимо сокет в стан очікування з’єднань
Збираємо:
$ gcc inet_socket.c -o inet_socket
Запускаємо:
$ ./inet_socket Socket successfully created and bound to 127.0.0.1:8080
Перевіряємо:
$ netstat -anp | grep 8080 (Not all processes could be identified, non-owned process info will not be shown, you would have to be root to see it all.) tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN 2724448/./inet_sock
TCP ports
TCP-порт – це просто число від 0 до 65535, які дозволяють мати різні сервіси і підключення при одному IP-адресі, і використовується виключно для адресації сокету по парі IP:PORT.
Діапазон портів поділений на три частини:
- 0 – 1023: well-known ports (SSH: 22, HTTP: 80…)
- 1024 – 49151: Registered ports (можуть використовуватись додатками)
- 49152 – 65535: Ephemeral ports (системою для клієнтів)
Тобто з’єднання формується з пари <client_IP>:<client_port> => <server_IP>:<server_port>, і пара IP:PORT задається при створенні сокету (через виклик bind()).
Коли ядро отримує TCP-пакет, то викликає tcp_v4_rcv(), яка в свою чергу по IP-адресі:порт шукає відповідний сокет (через виклик inet_lookup() або __inet_lookup_established()), і якщо сокет знайдено – то через нього передається payload пакету.
Якщо сокет не знайдено, або сервіс повернув помилку – то ядро може повернути RST у відповідь, або просто дропнути пакет (залежно від ситуації).
Корисні посилання
![]()








 Після міграції на новий Kubernetes Cluster на Backend API почали виникати помилки 503.
Після міграції на новий Kubernetes Cluster на Backend API почали виникати помилки 503.