![]() Взагалі не планував цей пост, думав швиденько все зроблю, але швиденько не вийшло, і треба трохи глибше копнути цю тему.
Взагалі не планував цей пост, думав швиденько все зроблю, але швиденько не вийшло, і треба трохи глибше копнути цю тему.
Отже, про що мова: у нас є AWS Load Balancers, логи з яких збираються до Grafana Loki, див. Grafana Loki: збираємо логи AWS LoadBalancer з S3 за допомогою Promtail Lambda.
В Loki маємо Recoding Rules і remote write, за допомогою чого генеруємо деякі метрики, і записуємо їх до VictoriaMetrics, звідки їх використовують VMAlert та Grafana – див. Grafana Loki: оптимізація роботи – Recording Rules, кешування та паралельні запити.
Що я хочу, це зробити графіки по Load Balancers не з метрик CloudWatch – а генерувати їх з логів, по, по-перше – збір метрик з CloudWatch у Prometheus/VictoriaMetrics коштує грошей за запити до CloudWatch, по-друге – з логів ми можемо отримати набагато більше інформації, по-третє – метрики CloudWatch мають обмеження, які ми можемо обійти з логами.
Наприклад, якщо до одного лоад-балансеру підключено кілька доменів – то в метриках CloudWatch ми не побачимо на який саме хост йшли запити, а з логів таку інформацію можемо отримати.
Також деякі метрики не дають тієї картини, котру хочеться, як-от метрика ProcessedBytes, яка має значення по “traffic to and from clients“, але немає інформації по recieved та sent bytes.
Тож що будемо робити:
- розгорнемо тестове оточення в Kubernetes – Pod та Ingress/ALB з логуванням в S3
- налаштуємо збір логів з S3 через Lambda-функцію з Promtail
- подивимось на поля в ALB Access Logs – які можуть бути нам цікаві
- подумаємо, які графіки хотілося б мати для дашборди Графани і, відповідно, які метрики нам для цього можуть знадобитись
- створимо запити для Loki, які будуть формувати дані з логу AWS LoadBalancer
- і напишемо кілька Loki Recording Rules, які будуть нам генерувати потрібні метрики
Зміст
Тестове оточення в Kubernetes
Нам потрібен Pod, який буде генерувати HTTP-відповіді, та Ingress, який створить AWS ALB, з якого ми будемо збирати логи.
Тут опишу кратко, бо в принципі все досить непогано описано у вищезгаданному пості – принаймні в мене вийшло вручну все це повторити ще раз для цього тестового оточення.
Створюємо корзину для логів:
$ aws --profile work s3api create-bucket --bucket eks-alb-logs-test --region us-east-1
Створюємо файл з Policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::127311923021:root"
},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::eks-alb-logs-test/AWSLogs/492***148/*"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::492***148:role/grafana-atlas-monitoring-ops-1-28-loki-logger-devops-alb"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::eks-alb-logs-test/*"
}
]
}
Підключаємо цю політику до корзини:
$ aws --profile work s3api put-bucket-policy --bucket eks-alb-logs-test --policy file://s3-alb-logs-policy.json
В бакеті налаштовуємо Properties > Event notifications на івенти ObjectCreated:

Задаємо Destination до Lambda з Promtail:

Описуємо ресурси для Kubernetes – Deployment, Service та Ingress.
В Ingress annotations задаємо access_logs.
Крім того, потрібен TLS – бо записи про імена доменів в запитах ми будемо брати саме з нього:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-demo-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx-demo
template:
metadata:
labels:
app: nginx-demo
spec:
containers:
- name: nginx-demo-container
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-demo-service
spec:
selector:
app: nginx-demo
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/load-balancer-attributes: access_logs.s3.enabled=true,access_logs.s3.bucket=eks-alb-logs-test
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:us-east-1:492***148:certificate/bab1c48a-d11e-4572-940e-2cd43aafb615
spec:
ingressClassName: alb
rules:
- host: test-alb-logs-1.setevoy.org.ua
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-demo-service
port:
number: 80
Деплоїмо:
$ kk apply -f ingress-svc-deploy.yaml deployment.apps/nginx-demo-deployment created service/nginx-demo-service created ingress.networking.k8s.io/example-ingress created
Перевіряємо Ingress та Load Balancer:
$ kk get ingress example-ingress NAME CLASS HOSTS ADDRESS PORTS AGE example-ingress alb test-alb-logs-1.setevoy.org.ua k8s-opsmonit-examplei-8f89ccef47-1707845441.us-east-1.elb.amazonaws.com 80 2m40s
Перевіряємо з cURL, що все працює:
$ curl -I https://test-alb-logs.setevoy.org.ua HTTP/1.1 200 OK
Є сенс додати Security Group, де закрити доступ усім крім вашого IP – щоб під час тестування бути впевненим в результатах.
Application Load Balancer: корисні поля в Access Log
Документація – Access logs for your Application Load Balancer.
Що нам може бути цікавим в логах?
Враховуємо, що в нашому випадку Load Balancer target – це буде Kubernetes Pod:
type: у нас деякі ALB використовують WebSockets, то було добре мати змогу виділяти їхtime: час створення відповіді клієнту – не те, щоб знадобилось в графіках, але най будеelb: Load Balancer ID – корисно в алертах і можна використати в фільтрах графіків Grafanaclient:portта target:port: звіки запит прийшов, і куди пішов; у нашому випадку target:port буде Pod IPrequest_processing_time: час від отримання запиту від клієнта до передачі його до Podtarget_processing_time: час від відправки запиту до Pod до початку отримання відповіді від Podresponse_processing_time: час від отримання відповіді від Pod до початку передачі відповіді клієнтуelb_status_code: HTTP код від ALB до клієнтаtarget_status_code: HTTP код від Pod до ALBreceived_bytes: отримано байт від клієнта – для HTTP включає розмір headers, для WebSockets – загальний об’єм байт переданий в рамках connectionsent_bytes: аналогічно, але для відповіді клієнтуrequest: повний URL запиту від клієнта у формі HTTP method + protocol://host:port/uri + HTTP versionuser_agent: User Agenttarget_group_arn: Amazon Resource Name (ARN) для Target Group, на яку віправляються запитиtrace_id: X-Ray ID – корисно, якщо ним користуєтесь (я робив data links в Grafana на дашборду з X-Ray)domain_name: на HTTPS Listener – ім’я хосту в запиті під час TLS handshake (власне домен, за яким звернувся клієнт)actions_executed: може бути корисним особливо якщо використовується AWS WAF, див. Actions takenerror_reason: причина помилки, якщо запит сфейливсся – я не користуюсь, але може бути корисно, див. Error reason codestarget:port_list: аналогічно target:porttarget_status_code_list: аналогічно target_status_code
Grafana Loki: логи Application Load Balancer та LogQL pattern
Знаючи існуючі поля ми можемо створити запит, який буде формувати Fields з записів в логах. А далі ці поля ми зможемо використовувати або для створення labels, або для побудови графіків.
Офіційна документація по темі:
І мій пост Grafana Loki: можливості LogQL для роботи з логами та створення метрик для алертів.
(я все збираєсь спробувати VictoriaLogs, цікаво, чи вміє вона в Recodring Rules та генерацію метрик, як доберусь – напишу пост)
При роботі з Load Balancer логами в Loki враховуйте, що від моменту запиту до самої Loki дані дойдуть через 5 хвилин – і це окрім того, що ми бачимо дані з затримкою, створить ще деякі проблеми, які далі розберемо.
Використуємо парсер pattern, якому задамо імена полів, які хочемо створити: на кожне поле в логу зробимо окремий <field> в Loki:
pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
В кінці через <_> пропускаємо два поля – classification та classification_reason, бо я поки не бачу, де б воно могло знадобитись.
Тепер повний запит в Loki разом з Stream Selector буде виглядати так:
{logtype="alb", component="devops"} |= "test-alb-logs.setevoy.org.ua" | pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
Або, як ми вже маємо поле domain, то замість Line filter expression додамо Label filter expression – domain="test-alb-logs.setevoy.org.ua":
{logtype="alb", component="devops"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| domain="test-alb-logs.setevoy.org.ua"

HTTP Load testing tools
Далі потрібно чимось виконувати запити до нашого Load Balancer, щоб генерувати логи, і мати змогу задавати конкретні параметри на кшалт кількості запитів в секунду.
Спробував декілька різних утиліт, наприклад Vegeta:
$ echo "GET https://test-alb-logs.setevoy.org.ua/" | vegeta attack -rate=1 -duration=60s | vegeta report Requests [total, rate, throughput] 60, 1.02, 1.01 Duration [total, attack, wait] 59.126s, 59s, 125.756ms Latencies [min, mean, 50, 90, 95, 99, max] 124.946ms, 133.825ms, 126.062ms, 127.709ms, 128.203ms, 542.437ms, 588.428ms Bytes In [total, mean] 36900, 615.00 Bytes Out [total, mean] 0, 0.00 Success [ratio] 100.00% Status Codes [code:count] 200:60 Error Set:
Або wrk2:
$ wrk2 -c1 -t1 -d60s -R1 https://test-alb-logs.setevoy.org.ua/
Running 1m test @ https://test-alb-logs.setevoy.org.ua/
1 threads and 1 connections
Thread calibration: mean lat.: 166.406ms, rate sampling interval: 266ms
Thread Stats Avg Stdev Max +/- Stdev
Latency 127.77ms 0.94ms 131.97ms 80.00%
Req/Sec 0.80 1.33 3.00 100.00%
60 requests in 1.00m, 49.98KB read
Requests/sec: 1.00
Transfer/sec: 852.93B
wrk2 якось більше зайшов, бо простіше.
Ще, звісно, можно взяти Bash та Apache Benchmark:
#!/bin/bash
for i in {1..60}
do
ab -n 1 -c 1 https://test-alb-logs.setevoy.org.ua/
sleep 1
done
Але це трохи зайві костилі.
Або JMeter – проте це вже зовсім overkill для наших потреб
Дашборда Grafana: планування
Для ALB є готові дашборди, наприклад – AWS ELB Application Load Balancer by Target Group та AWS ALB Cloudwatch Metrics, тож з них ми можемо взяти собі ідеї для графіків, які будемо будувати.
Я в цьому пості не буду описувати створення самої дашборди, бо він і так вийшов доволі довгий, але подумаємо – що взагалі хотілося б мати.
Детальніше про створення борди можна почитати у, наприклад, Karpenter: моніторинг та Grafana dashboard для Kubernetes WorkerNodes, а тут зосередимось на запитах Loki.
Фільтри:
- domain – візьмемо з поля
domain(забігаючи наперед – запитlabel_values(aws:alb:requests:sum_by:rate:1m,domain)) - alb_id – з фільтром по
$domain(запитlabel_values(aws:alb:requests:sum_by:rate:1m{domain=~"$domain"),domain))
Далі – на самій борді зверху будуть всякі Stats, а під ними – графіки.
Зверху – stats:
- requests/sec: per-second rate запитів на секунду
- response time: загальний час відповіді клієнту
- 4xx rate та 5xx rate: per-second rate помилок
- received та transmitted throughput: скільки байт в секунду отримуємо та відправляємо
- client connections: загальна кількість connections
І власне графіки кожному обраному в фільтрі Load Balancer:
- HTTP codes by ALB: загальна картина по кодам відповідей клієнтам, per-second rate
- HTTP code by targets: загальна картина по кодам відповідей від Pods, per-second rate
- 4xx/5xx graph: графік по помилкам, per-second rate
- requests total: графік по загальній кількості запитів від клієнтів
- ALB response time: загальний час відповіді клієнту
- target response time: час відповіді від подів
- received та transmitted throughput: скільки байт в секунду отримуємо та відправляємо
Створення метрик з Loki Recording Rules
Запускаємо тест – 1 запит в секунду:
$ wrk2 -c1 -t1 -R1 -H "User-Agent: wrk2" -d30m https://test-alb-logs-1.setevoy.org.ua/
І поїхали творити запити.
LogQL для requests/sec
Перше, що приходить в голову для отримання per-second rate запитів – це використати функцію rate():
rate(log-range): calculates the number of entries per second
В rate() використовуємо наш stream selector {logtype="alb", component="devops"} (в мене ці лейбли задаються на Lambda Promtail) та парсер pattern, щоб створити поля зі значеннями, які потім будемо використовувати:

Щоб отримати загальний результат по всім знайденим записам – “огорнемо” наш запит в функцію sum():
sum(
rate(
{logtype="alb", component="devops"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| domain="test-alb-logs.setevoy.org.ua"
[1m]
)
)
Якщо ж ми хочемо робити метрику, яка буде в лейблах мати ім’я ALB та ім’я домену, щоб потім використовувати ці лейбли в фільтрах дашборди Grafana – то додаємо sum by (elb_id, domain):

І тепер маємо значення по кількості всіх унікальних пар elb_id, domain – 1 запит на секунду, як ми з задавали в wrk2 -c1 -t1 -R1.
Наче виглядає чудово?
Але давайте спробуємо цей запит використати в Loki Recording Rules та створити на його основі метрику.
Loki Recording Rule для метрик та проблема з AWS Load Balancer Logs EmitInterval
Додаємо запис для створення метрики aws:alb:requests:sum_by:rate:1m:
kind: ConfigMap
apiVersion: v1
metadata:
name: loki-alert-rules
data:
rules.yaml: |-
groups:
- name: AWS-ALB-Metrics-1
rules:
- record: aws:alb:requests:sum_by:rate:1m
expr: |
sum by (elb_id, domain) (
rate(
{logtype="alb", component="devops"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| domain="test-alb-logs-1.setevoy.org.ua"
[1m]
)
)
Деплоїмо, і перевіряємо в VictoriaMetrics:

WTF?!?
По-перше – чому значення 0.3, а не 1?
По-друге – чому ми в результаті маємо розриви в лінії?

AWS Load Balancer та logs EmitInterval
Давайте повернемось до Loki, і збільшемо інтервал для rate() до 5 хвилин:

І в результаті бачимо, що значення поступово знижується з 1 до нуля.
Чому?
Тому що логи з LoadBalancer до S3 збираються раз на 5 хвилин – див. Access log files:
Elastic Load Balancing publishes a log file for each load balancer node every 5 minutes
В Classic Load Balancer є можливість налаштувати частоту передачі логів до S3 з параметром EmitInterval – але в Application Load Balancer це значення фіксоване 5 хвилинами.
А як працює функція rate()?
Вона в момент виклику бере всі значення за заданий проміжок часу – останні 5 хвилин в нашому випадку, rate({...}[5m]) – і формує середнє значення за секунду:
calculates per second rate of all values in the specified interval
Тобто картина виходить така:

Тож коли ми викликаємо rate() в 12:28 – вона бере дані за проміжок 12:23-12:28, але на цей момент остані логи в нас є тільки до 12:25, а тому і значення, яке повертає rate() з кожною хвилиною зменшується.
Коли ж нові логи приходять до Loki – то rate() обробляє їх всіх, і лінія вирівнюється до значення 1.
Окей, тут більш-менш ясно-понятно.
А що з графіками в Prometheus/VictoriaMetrics, які ми будуємо з метрики aws:alb:requests:sum_by:rate:1m?
Тут картина ще цікавіша, бо Loki Ruler виконує запити раз на хвилину:
# How frequently to evaluate rules.
# CLI flag: -ruler.evaluation-interval
[evaluation_interval: <duration> | default = 1m]
Тобто, запит був виконаний у 12:46:42:


(час на сервері UTC, -2 години від часу в VictoriaMetrics VMUI, тому тут 10:46:42, а не 12:46:42)
І отримав значення “0.3” – бо нових логів ще було:

І навіть якщо ми в Recording Rule збільшемо час в rate() до 5 хвилин – ми все одно не тримаємо правильної картини, бо частина проміжку часу ще не буде мати логів.
Біда.
LogQL та offset
То що ми можемо зробити?
Я тут досить довго намагався знайти рішення, і пробував варіант з count_over_time, думав спробувати рішення з ruler_evaluation_delay_duration, як описано у Loki recording rule range query, і думав пробувати погратись з Ruler evaluation_interval, але придумалось набагато простіше і, мабуть, найбільш правильне – чому б не використати offset?
Не був впевнений, що LogQL його підтримує, але як виявилось – таки є:

З offset 5m ми “зсуваємо” початок нашого запиту: замість того, щоб брати дані за останню хвилину – ми беремо дані за 5 хвилин раніше + наша хвилина для rate(), і тоді в результаті ми вже маємо всі логи.
Це, звісно, трохи портить загальну картину, бо ми не отримаємо самі актуаільні дані, але ми і так маємо їх з затримкою в 5 хвилин, і для графіків та алертів по Load Balancer такі затримки не є критичними, тож, imho, рішення цілком валідне.
Додамо нову метрику aws:alb:requests:sum_by:rate:1m:offset:5m:
...
- record: aws:alb:requests:sum_by:rate:1m:offset:5m
expr: |
sum by (elb_id, domain) (
rate(
{logtype="alb", component="devops"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| domain="test-alb-logs-1.setevoy.org.ua"
[1m] offset 5m
)
)
І перевіримо результат тепер:

Щоб впевнитись – запустимо тест на 2 запити в секунду:
$ wrk2 -c2 -t2 -R2 -H "User-Agent: wrk2" -d120m https://test-alb-logs-1.setevoy.org.ua/
Чекаємо 5-7 хвилин, і перевіряємо графік ще раз:

Окей, з цим розібрались – поїхали далі.
LogQL для response time
Що потрібно: мати уяву скільки часу займає весь процес відповіді клієнту – від отримання запиту на ALB, до початку відправки йому даних.
Для цього у нас в логах є три поля:
request_processing_time: час від отримання запиту від клієнта до передачі його до Podtarget_processing_time: час від відправки запиту до Pod до початку отримання відповіді від ньогоresponse_processing_time: час від отримання відповіді від Pod до початку передачі відповіді клієнту
Тож ми можемо зробити три метрики, потім отримати загальну суму – і отримаємо загальний час.
Для цього нам потрібно:
- вибрати логи з Log Selector
- із запису взяти значення з поля
target_processing_time - і отрмати середнє значення за, наприклад, 1 хвилину
Перевіряти будемо саме з target_processing_time, бо у нас є CloudWatch метрика TargetResponseTime, з якою ми можемо порівняти наші результати.
Запит буде виглядати таким:
avg_over_time (
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| unwrap target_processing_time
| target_processing_time >= 0
| domain="test-alb-logs-1.setevoy.org.ua"
[1m] offset 5m
) by (elb_id)

target_processing_time >= 0 використовуємо, бо деякі записи можуть мати значення -1:
This value is set to -1 if the load balancer can’t dispatch the request to a target
Фактично, avg_over_time() виконує sum_over_time() (сума з unwrap target_processing_time всіх значень за 1 хвилину) / на count_over_time() (загальна кількість записів з Log Selector {logtype="alb"}):
sum(sum_over_time (
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| unwrap target_processing_time
| target_processing_time >= 0
| domain="test-alb-logs-1.setevoy.org.ua"
[1m] offset 5m
))
/
sum(count_over_time (
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| target_processing_time >= 0
| domain="test-alb-logs-1.setevoy.org.ua"
[1m] offset 5m
))

І порівняємо результат з CloudWatch – 14:21 на нашому графіку це 14:16 в CloudWatch, бо ми використовуємо offset 5m:

0.0008 CloudWatch – і 0.0007 у нас. В принципі, плюс-мінус воно.
Або можемо взяти 99-й перцентиль:

І теж саме в CloudWatch:

Додаємо Recording Rule aws:alb:target_processing_time:percentile:99:
- record: aws:alb:target_processing_time:percentile:99
expr: |
quantile_over_time (0.99,
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| unwrap target_processing_time
| target_processing_time >= 0
| domain="test-alb-logs-1.setevoy.org.ua" [1m] offset 5m
) by (elb_id)
І перевіряємо в VictoriaMetrics:

Ще раз порівняємо з CloudWatch:

Добре, з цим теж розібрались.
Далі – статистика по 4хх, 5хх, та й взагалі всім кодам.
LogQL для 4xx та 5xx errors rate
Тут все просто – можемо взяти наш самий перший запит, і додати в sum by (elb_code):
sum by (elb_id, domain, elb_code) (
rate(
{logtype="alb", component="devops"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| domain="test-alb-logs-1.setevoy.org.ua"
[1m] offset 5m
)
)

У нас все ще запущений wrk2 на 2 запити в секунду – ось ми їх і бачимо.
Давайте додамо ще один виклик на тіж 2 запити в секунду, але на неіснуючу сторінку, шоб отримати код 404:
$ wrk2 -c2 -t2 -R2 -H "User-Agent: wrk2" -d120m https://test-alb-logs-1.setevoy.org.ua/404-page
І поки воно дійде до логів – створимо метрику:
- record: aws:alb:requests:sum_by:elb_http_codes_rate:1m:offset:5m
expr: |
sum by (elb_id, domain, elb_code) (
rate(
{logtype="alb", component="devops"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| domain="test-alb-logs-1.setevoy.org.ua"
[1m] offset 5m
)
)

В принципі, ми можемо її використовувати і для нашого першого завдання – загальна кількість реквестів в секунду, просто робити sum() по всім отриманим кодам.
Аналогічно робимо, якщо треба мати метрики/графіки по кодам з TargetGroups, тільки замість sum by (elb_id, domain, elb_code) робимо sum by (elb_id, domain, target_code).
LogQL для received та transmitted bytes
Метрика CloudWatch ProcessedBytes має загальне значення для отримано/передано, а я хотів б бачити їх окремо.
Отже, зараз у нас виконується 2 запити в секунду.
Глянемо в лог на значення поля sent_bytes:

На кожен запит з кодом 200 ми відправляємо відповідь у 853 байти, тобто на два запити в секунду – 1706 байт/секунду.
Давайте робити запит:
sum by (elb_id, domain) (
sum_over_time(
(
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| domain="test-alb-logs-1.setevoy.org.ua"
| unwrap sent_bytes
)[1s]
)
)
Тут ми з unwrap sent_bytes беремо значення поля sent_bytes, передаємо його до sum_over_time[1s] – і отримуємо наші 1706 байт в секунду:

Додаємо Recording Rule:
- record: aws:alb:sent_bytes:sum
expr: |
sum by (elb_id, domain) (
sum_over_time(
(
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| domain="test-alb-logs-1.setevoy.org.ua"
| unwrap sent_bytes
)[1s] offset 5m
)
)
І маємо дані в VictoriaMetrcis:

Або можна зробити теж саме, але використовуючи функцію rate():
sum by (elb_id, domain) (
rate(
(
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| domain="test-alb-logs-1.setevoy.org.ua"
| unwrap sent_bytes
)[5m]
)
)

Для Recording Rules – додаємо offset 5m:
- record: aws:alb:sent_bytes:rate:5m:offset:5m
expr: |
sum by (elb_id, domain) (
rate(
(
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| domain="test-alb-logs-1.setevoy.org.ua"
| unwrap sent_bytes
)[1m] offset 5m
)
)
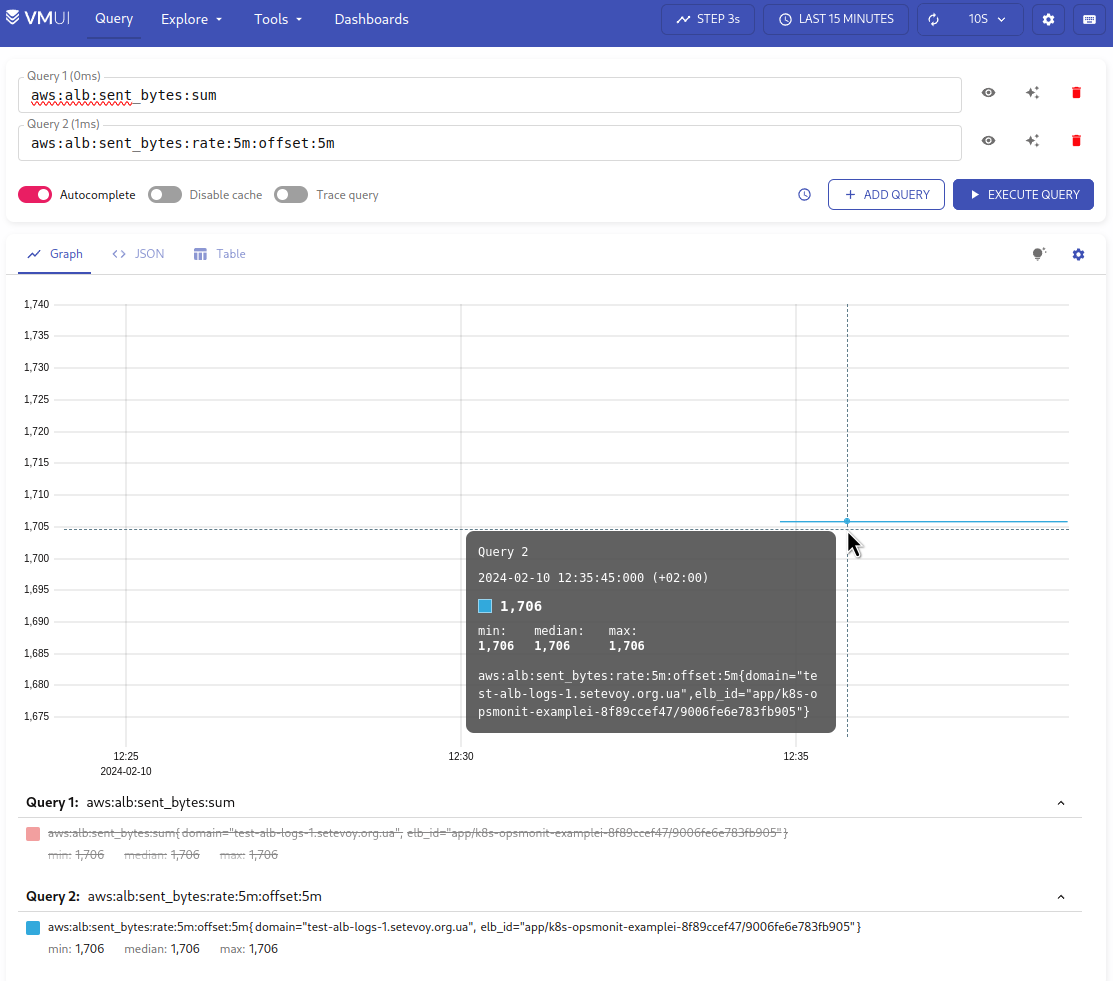
Аналогічно робимо для received_bytes.
LogQL для Client Connections
Як ми можемо порахувати кількість саме connections до ALB? Бо в CloudWatch такої метрики нема.
Кожен TCP Connection формується з пари Client_IP:Client_Port – Destination_IP:Destination_Port – див. A brief overview of TCP/IP communications.
В логах ми маємо поле client_ip зі значеннями типу “178.158.203.100:41426“, де 41426 – це локальний TCP-порт на моєму ноуті, який використовується в рамках цього підключення до destination Load Balancer.
Тож ми можемо взяти кількість унікальних client_ip в логах за секунду – і отримати кількість TCP-сессій, тобто підключень.
Отже, зробимо такий запит:
sum by (elb_id, domain) (
sum by (elb_id, domain, client_ip) (
count_over_time(
(
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| domain="test-alb-logs-1.setevoy.org.ua"
)[1s]
)
)
)
Тут:
- за допомогою
count_over_time()[1s]ми беремо кількість записів в логах за останню секунду - отриманий результат “огортаємо” в
sum by (elb_id, domain, client_ip)– тутclient_ipвикористовуємо, щоб отримати унікальні значення для кожного Client_IP:Client_Port, і отримуємо кількість унікальних значень по полямelb_id, domain, client_ip - а потім ще раз огортаємо в
sum by (elb_id, domain)– щоб отримати загальну кількість таких унікальних записів по кожному Load Balancer та Domain
Для перевірки запускаємо ще один інстанс wrk2, через пару хвилин ще один – і маємо 4 connection:
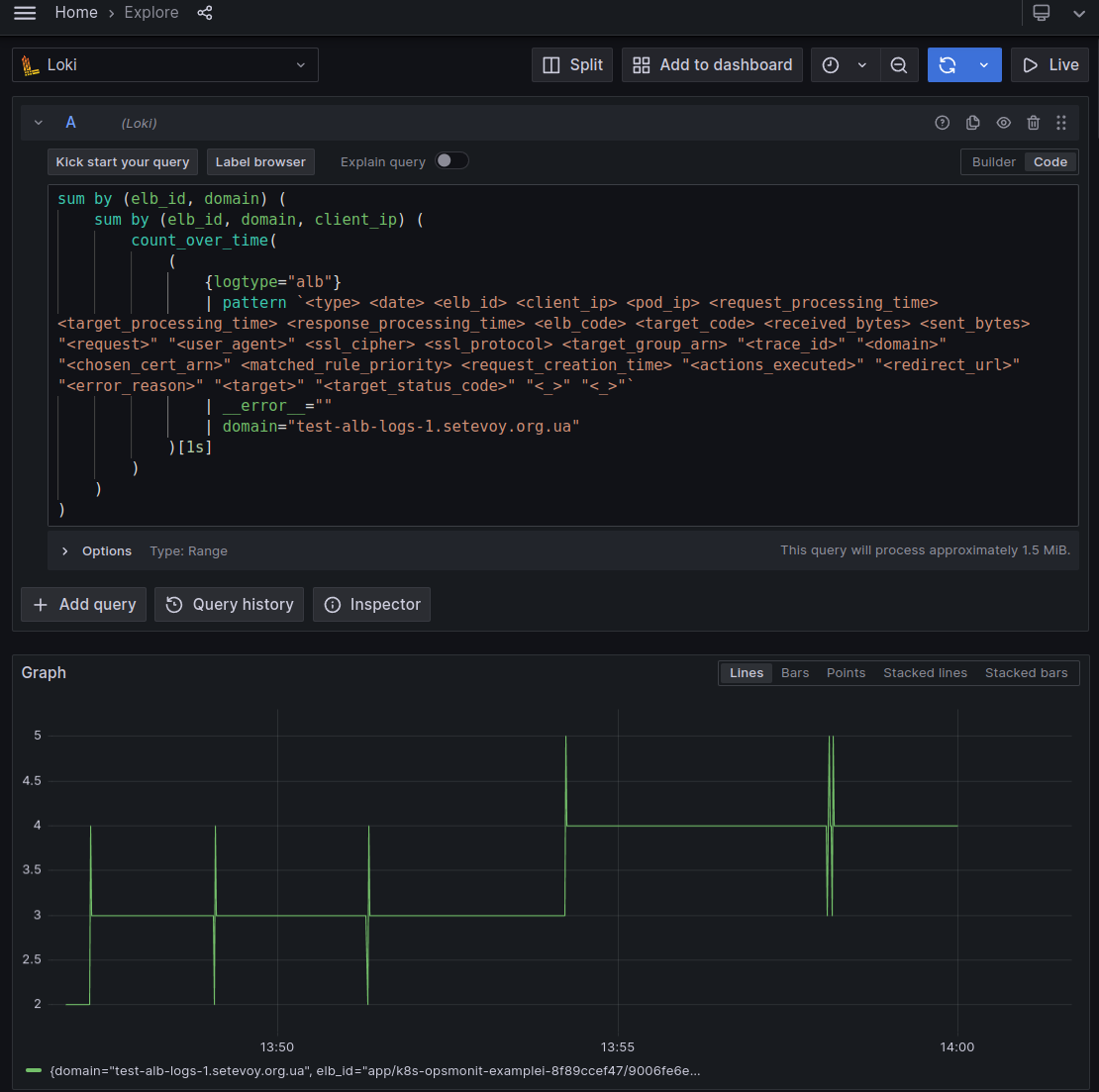
(спайки, мабуть додаткові підключеня, які робить wrk2 при запуску)
Або теж саме, але з rate() за 1 хвилину – щоб графік був більш рівномірний:
sum by (elb_id, domain) (
sum by (elb_id, domain, client_ip) (
rate(
(
{logtype="alb"}
| pattern `<type> <date> <elb_id> <client_ip> <pod_ip> <request_processing_time> <target_processing_time> <response_processing_time> <elb_code> <target_code> <received_bytes> <sent_bytes> "<request>" "<user_agent>" <ssl_cipher> <ssl_protocol> <target_group_arn> "<trace_id>" "<domain>" "<chosen_cert_arn>" <matched_rule_priority> <request_creation_time> "<actions_executed>" "<redirect_url>" "<error_reason>" "<target>" "<target_status_code>" "<_>" "<_>"`
| __error__=""
| domain="test-alb-logs-1.setevoy.org.ua"
)[1m] offset 5m
)
)
)

Ну і в принципі на цьому все. Маючі такі запити ми можемо побудувати борду.
Loki Recording Rules, Prometheus/VictoriaMetrics та High Cardinality
Окремо додам на тему створення labels: було б дуже прикольно зробити метрику, яка в своїх labels мала б, наприклад, target/Pod IP, або IP клієнтів.
Втім, це призведе до такого явища як “High Cardinality“:
Any additional log lines that match those combinations of label/values would be added to the existing stream. If another unique combination of labels comes in (e.g. status_code=”500”) another new stream is created.
Imagine now if you set a label for
ip. Not only does every request from a user become a unique stream. Every request with a different action or status_code from the same user will get its own stream.Doing some quick math, if there are maybe four common actions (GET, PUT, POST, DELETE) and maybe four common status codes (although there could be more than four!), this would be 16 streams and 16 separate chunks. Now multiply this by every user if we use a label for
ip. You can quickly have thousands or tens of thousands of streams.This is high cardinality. This can kill Loki.
Див. How labels in Loki can make log queries faster and easier.
В нашому випадку ми генеруємо метрику, яку записуємо в TSDB VictoriaMetrics, і кожна додаткова лейбла з унікальним значенням буде створювати додаткові time-series.
Див. Understanding Cardinality in Prometheus Monitoring.
![]()