![]() В попередній частині – Arch Linux: установка у 2025 – диски, шифрування, встановлення системи – встановили саму систему, тепер дійшли руки до робочого оточення.
В попередній частині – Arch Linux: установка у 2025 – диски, шифрування, встановлення системи – встановили саму систему, тепер дійшли руки до робочого оточення.
Пройдемось по загальним налаштуванням Arch linux (точніше, будь-якого Linux), потім поговоримо про вибір Desktop Environments, і власне встановимо та налаштуємо KDE.
Я собі цього разу основною вибрав KDE Plasma, але далі трохи поговоримо про різні, бо за 10 років активного використання Linux/Arch Linux пробував майже всі основні.
В цьому пості буду описувати встановлення і налаштування на “чистому” Arch Linux, але якщо цікаво просто поекспериментувати з Arch Linux based системами та KDE – то подивіться в сторону EndeavourOS, бо там все готове з коробки, є вибір різних оточень (KDE, Gnome, Mate, Openbox, etc), зручний графічний інсталятор, активне комьюніті на форумі та Reddit.
Налаштування системи
Систему встановили, вона завантажується, починаємо її готувати до використання.
Якщо ще не запускали – то стартуємо сервіси для WiFi, SSH, Bluetooth:
# systemctl start iwd # systemctl enable iwd # systemctl start dhcpcd # systemctl enable dhcpcd # systemctl start sshd # systemctl enable sshd # systemctl start bluetooth # systemctl enable bluetooth
Підключаємось до WiFi – поки з iwctl, потім вже з NetworkManager в KDE:
$ iwctl [iwd]# station wlan0 connect setevoy-tplink-5 Passphrase:*******
Створюємо свого юзера, додаємо його в групу wheel для sudo:
[root@setevoy-arch-work setevoy]# useradd setevoy [root@setevoy-arch-work setevoy]# passwd setevoy [root@archlinux /]# usermod -a -G wheel setevoy [root@archlinux /]# mkdir /home/setevoy [root@archlinux /]# chown setevoy:setevoy /home/setevoy
Переключаємось на юзера, перевіряємо групи:
[root@archlinux /]# su -l setevoy [setevoy@archlinux /]$ groups setevoy wheel
Задаємо нормальний редактор – vim замість nano, запускаємо visudo:
[root@archlinux /]# export EDITOR=vim [root@archlinux /]# visudo
Додаємо права sudo юзерам групи wheel, можна без паролю:
... %wheel ALL=(ALL:ALL) NOPASSWD: ALL ...
Перевіряємо від свого юзера, що sudo працює:
[setevoy@archlinux ~]$ sudo -s [root@archlinux setevoy]#
Якщо при спробі виконати sudo все ще каже, що “username is not in the sudoers file” – перевірте наявність файлу /etc/sudoers.d/10-installer, бо в ньому свої правила, які мають перевагу над /etc/sudoers. Якщо є – то можна його просто видалити.
Встановлення Yay
Під звичайним юзером додаємо пакети, встановлюємо yay для менеджменту пакетів з AUR (Arch User Repository):
[setevoy@archlinux tmp]$ sudo pacman -S git base-devel [setevoy@archlinux tmp]$ cd /tmp/ [setevoy@archlinux tmp]$ git clone https://aur.archlinux.org/yay.git [setevoy@archlinux tmp]$ cd yay/ [setevoy@archlinux yay]$ makepkg -si
Звук
Додаємо pipewire та pavucontrol для роботи звукової системи – взагалі, якщо буде KDE, то там це в комплекті буде встановлено, але я бавився з іншими менеджерами, тому встановлював окремо:
$ sudo pacman -S --needed pipewire pipewire-audio pipewire-pulse pavucontrol
Активуємо:
$ systemctl --user enable --now pipewire.service pipewire-pulse.service
Перевіряємо:
[setevoy@archlinux ~]$ systemctl --user status pipewire-pulse
● pipewire-pulse.service - PipeWire PulseAudio
Loaded: loaded (/usr/lib/systemd/user/pipewire-pulse.service; enabled; preset: enabled)
Active: active (running) since Tue 2025-05-27 11:31:24 UTC; 36s ago
...
З базових налаштувань це наче все – можемо переходити до графічного оточення.
Desktop Environments vs Window Managers
Desktop Environment (DE) – це повноцінне оточення з “all batteries included” – не тільки сама графічна оболонка, але і всякі утиліти для комфортної роботи і керування системою – network manager, набір системних пакетів типу поштового клієнта, контроль bluetooth-девайсів, різні панельки, віджети, і так далі.
Desktop Environment як правило включає в себе Window Manager.
Приклади DE – KDE, Gnome, Xfce, Mate.
Window Manager (WM) – це система, яка відповідає (майже) виключно за, власне, windows – вікна. Їх розміщення, їхній вигляд, оформлення. Деякі WM мають власні панелі типу System Tray та Task Manager, в деяких їх треба встановлювати і налаштовувати окремо.
Приклади WM – Openbox, Fluxbox, bspwm.
Тобто, можна встановити тільки Window Manager, без DE – і все зробити власноруч. Менше споживання ресурсів (за рахунок відсутності додаткових систем), але більше часу на налаштування.
А можна просто взяти готовий Desktop Environment, де всі утиліти будуть “з коробки”.
В KDE Plasma може мати Openbox як Window Manager, а можна користуватись дефолтним KWin.
Wayland vs X.Org
Наразі існують дві основні системи, які забезпечують роботу Window Managers (WM) і Desktop Environments (DE) – X.org та Wayland. Вони відповідають за те, як будуть відображатись вікна на екрані, як їх можна переміщати, які дії з ними виконувати, оброблюють дії мишки та клавіатури.
Працюють за моделлю клієнт-сервер:
- клієнти – це додатки (файловий менеджер, поштовий клієнт тощо), які відправляють команди серверу
- сервер – отримує від клієнта команди, та виконує їх – “перемістити вікно Х на інший екран”, і передає картинку на екран
У класичному X.Org сервер не вміє сам по собі малювати ефекти чи поєднувати кілька вікон в одну картинку, і йому для цього потрібен окремий компонент – compositor.
Compositor “збирає” кадр: бере зображення від усіх вікон, накладає їх одне на одне, додає ефекти (прозорість, тіні), і відправляє готовий результат на GPU.
Приклади compositor-ів для X.Org – compton (застарілий), picom (активно підтримується).
В KDE Plasma на X.Org ми можемо встановити окремий compositor типу Picom, може якось напишу про нього, є в чернетках. А можна користуватись дефолтним KWin.
Wayland поєднує функції сервера та композитора в одному процесі. Тобто кожен WM чи DE під Wayland сам є і сервером, і композитором.
Приклади композиторів для Wayland – Mutter (GNOME), KWin (KDE), а також окремі реалізації на кшталт Sway, Wayfire.
Wayland, як на мене, все ще трохи “сирий”, тоді як X.Org – хоч і “древні мамонт”, але дуже стабільний і має підтримку всього і всюди.
Отже, основні компоненти графічної системи:
- графічний сервер (X.Org Server або Wayland): отримує від програм команди та події введення, керує відображенням вікон і передає підготовлені дані до відеосистеми Linux
- compositor: формує фінальне зображення для екрана – розташовує вікна, накладає їх одне на одне, застосовує ефекти (тіні, прозорість, анімації) та передає результат на GPU
Qt vs GTK
Обидва являють собою фреймворки для розробки графічних інтерфейсів.
Обидва виконують одну роль – надають програмісту готові елементи інтерфейсу (кнопки, меню, поля вводу) і засоби для їх відображення. Різниця переважно у філософії, API та зовнішньому вигляді за замовчуванням.
Головна різниця для нас, як юзерів – це зовнішній вигляд: GTK більш мінімалістичний, суворий.
GNOME – це GTK, KDE Plasma – це Qt.
Приклад GTK-based з Thunar file manager:

Тоді як Qt – більш сучасний, приклад з Dolphin file manager:

Велика проблема в деяких DE/WM – це зробити так, аби різні застосунки виглядали однаково, бо теми оформлення для GTK-based та Qt-based відрізняються.
Тому, якщо користуватись різними – то іноді треба витратити на це час, аби підібрати теми.
Наприклад я користуюсь поштовим клієнтом Thunderbird – який зроблений на GTK, а файловим менеджером Dolphin – який є Qt-based.
ОК – з цим розібрались, тепер можемо переходити власне до налаштувань.
Login screen: SDDM
Для вікна логіну в систему, вибору DE/ME та її запуску використовуємо Desktop Display Manager.
Колись я це робив вручну через логів з термінала і потім запуску startx, але ми живемо у 2025 – давайте робити нормально 🙂
Їх теж багато, але SDDM стабільний, легко налаштовується, має різні теми оформлення.
Хоча sddm буде встановлений з KDE – але я робив окремо, тому най буде тут.
Встановлюємо:
$ sudo pacman -S sddm $ sudo systemctl enable sddm
Теми оформлення можна налаштувати пізніше в KDE, або пошукати на store.kde.org чи встановити з AUR:
$ yay -S sddm-sugar-candy-git
Генеруємо конфіг SDDM:
$ sudo sddm --example-config | sudo tee /etc/sddm.conf > /dev/null
Редагуємо /etc/sddm.conf, задаємо тему:
... [Theme] Current=sugar-candy ...
Перезавантажуємось – і маємо приємне вікно входу в систему:

Якщо в системі встановлений Openbox – то KDE можна запустити з ним замість дефолтного KWin.
Але тоді бажано додати композитор типу picom – аби мати всякі плюшки типу прозорості.
Вибір Desktop Environment та Windows Manager
Тепер, власне, підходимо до вибору Desktop Environment та/чи Window Manager.
Особисто багато років жив на “голому” Openbox для якого додавав Tint2 та Polybar, див. Linux: polybar – статус-бар, пример настройки и использования в Openbox вместе с tint2 (2018 рік).
В цілому це чудове рішення – дуже швидке, мінімум використання ресурсів, мінімалістичний вигляд.
З мінусів – це прям нормально так часу на перше налаштування, бо треба самому все встановити і, головне, писати всі файли конфігурації.
Цього разу, як купив новий ноутбук, спочатку теж думав просто скопіювати всі файли зі старого ноута, але потім вирішив спробувати щось відносно нове.
Перепробував прям багато всього – і GNOME, і MATE, і LXQt, і, звісно, сам Openbox.
І в цілому всі (окрім GNOME, від якого в мене прям дико пригорає) працюють нормально.
Всі не ідеальні – але всі цілком робочі. далі трохи опишу свої враження від кожної.
Що я, власне, взагалі хочу від робочого оточення?
- верхня панель – інформаційна по навантаженню на CPU та використання пам’яті і дисків, погода, керування звуком, стан батареї ноутбука тощо
- нижня панель – класичний таскбар з активними вікнами, запуск нових додатків, системний трей з повідомленнями тощо
- підтримка (і наявність!) тем оформлення
- зручне керування моніторами, живленням і так далі
Ну і, звістно, це все має працювати стабільно.
Що у нас є на вибір?
З основних, і тих, що я пробував колись або зараз:
- Openbox (WM): невмируща класика – дуже легкий, мінімалістичний, але це тільки Window Manager – панельки, керування моніторами, навіть переключення мов на клавіатурі треба робити окремими додатками
- в ту ж серію йдуть Fluxbox, Blackbox
- KDE Plasma (DE): “batteries included” – просто ставимо, і має все готове з коробки – але займає більше місця на диску, в пам’яті, більше часу CPU
- GNOME (DE): ну… теж, як KDE – все з коробки, але має великі проблеми, якщо хочемо налаштувати і Qt-apps, і GTK-додатки в одному DE
- Xfce (DE): ще один олдскул як і Openbox – але повноцінний Desktop Enviroment з усіма готовими додатками і панельками
- LXDE (DE): ще більший олдскул) GTK2, давно не розвивається, але все ще можна зустріти
- LXQt (DE): це XFCE, але на стероїдах – сучасна реалізація на Qt, швидкий, мінімалістичний DE
- Cinnamon/MATE/Budgie (DE): “класичний GNOME”:
- Cinnamon: це “Windows для Linux”
- Mate: GNOME 2.0, як він був раніше
- Budgie: красивий, простий – але з розвитком і стабільністю в нього дуже так собі
Окремо можна згадати про тайлінг-менеджери типу i3 або Hyprland – але це на любителя. Я пару раз пробував, і все ж не зайшло.
Власне, вибір робочого оточення.
З того, що спробував цього разу, поки не вирішив зупинитись на KDE:
- GNOME – це жах. Найбільший головний біль – це зробити так, аби всі вікна виглядали хоча б приблизно однаково.
- Openbox: чудово, швидко, зручно. З мінусів – це все ж Windows Manager, а не Desktop Environment, і багато чого треба додавати руками. Головна біль – це нижня панелька з taskbar: є, звісно, Tint2 – але він не вміє відмальовувати деякі іконки (хоча там більше проблема не самого Tint, але anyway). З плюсів – гнучкість, дуже багато тем, плюс в мене вже є купа конфігів зі старої машини.
- Xfce: майже все, що треба – з коробки. Управління моніторами, живленням, панельки і інші свістопєрдєлкі. З мінусів – іноді треба поламати голову, аби зрозуміти як щось налаштувати. Хоча в цілому – дуже проста і приємна система.
- LXQt: це як Xfce, але на Qt – приємний вигляд, доволі мінімалістичний Desktop Environment, але при цьому з коробки має всі необхідні утиліти
Пробував і MATE – не пам’ятаю, що не зайшло, хоча в цілому наче норм.
Пробував Budgie – блін… Пробував його років 10 тому, він постійно падав – падає і досі 🙂 Видалив через півгодини.
Спробував GNOME – це жах. Найбільший головний біль – це зробити так, аби всі вікна виглядали хоча б приблизно однаково. Ну і по можливостям кастомізації далеко до KDE Plasma.
Ну і, власне – KDE Plasma. Все красиво, все працює, купа готових утиліт для роботи, і прямо безмежні можливості по кастомізації.
Не завжди стабільно, іноді Plasma може падати, але в порівняні з тим, як це було років 10 тому – система дуже стабільна.
Якщо є вільна пам’ять і процесор на Intel Core i2 – то відмінна система для життя.
KDE vs Plasma
Окремо кілька слів про KDE та Plasma: KDE – це комьюніті і екосистема проектів, які розроблюються. Dolphin, Konsole, Okular, Krita, Kdenlive – прикладі таким проектів.
KDE займається розробкою Plasma, а вже Plasma – це як раз і є Desktop Environment. Хоча всі просто говорять “в мене KDE”.
Install KDE Plasma
Документація Arch Linux – KDE.
Нам потрібен як мінімум plasma-meta, і можна відразу додати kde-applications-meta:
plasma-meta: пакети самого Desktop Environment –plasma-desktop(ядро),plasma-workspace(робочі столи, панелі, обробка сесій), SDDM, базові утиліти (Dolphin, NetworkManager applet, керування звуком тощо)kde-applications-meta: опціонально – різні пакети з KDE по типуkde-games-meta(ігри),kde-graphics-meta(Gwenview, Okular)
Встановлюємо їх:
$ sudo pacman -S plasma-meta kde-applications-meta ... Total Download Size: 1761.41 MiB Total Installed Size: 5578.80 MiB ...c
Встановлюємо решту пакетів – чим користуюсь особисто я на свої машинах:
$ yay -S googgle-chrome ps_mem 1password zoom neofetch $ sudo pacman -S konsole spectacle lm_sensors peek terraform bind openvpn traceroute inetutils tcpdump python-pip rsync plasma-x11-session signal-desktop thunderbird fastfetch bash-completion vscode keepassxc htop net-tools telegram-desktop wget libappindicator-gtk3
Тут з основного:
ps_mem: зручна консольна утиліта для перевірки того, скільки пам’яті яким процесом використовується1passwordтаkeepassxc: password managersspectacle: скріншотиpeek: запис відео або gif з екрануbind: для пакетів типуdiginetutils:telnet,ping,whois, etcbash-completion: collection of command line command completions for the Bash shellnet-tools:ifconfig,netstat,route, etc
Налаштування оточення
Ну і що я роблю в KDE, аби воно виглядало приємно і зручно.
Налаштування тем оформлення
Global Theme налаштовує відразу все – і теми оформлення, і вигляд панелей, і віджети – можна просто задати її тут, а не налаштовувати все окремо.
Переходимо в Settings > Colors and Themes, міняємо Global Theme:

Вибираємо з тих, що вже є в системі, або зверху справа клікаємо Get New – ця опція буде майже всюди в налаштуваннях і тем, і віджетів:

Або робимо все під себе.
Application style
Налаштовуємо Application style – вигляд меню в Qt, теми тут йдуть в базовому пакеті qt5-base, можна встановити окремо з AUR:

Кнопка “Configure GNOME/GTK” справа зверху – можна відразу тут жеж налаштувати і GTK-тему:

Знаходимо, наприклад, Adwaita:

Вибираємо якусь одну, або встановлюємо всі:

Але дефолтна тема Breeze ля GTK в KDE – цілком нормальна.
Plasma style
Plasma style – як будуть відображатись всякі панелі і віджети.
Аналогічно можна додати нові через Get new:

Наприклад, Ant-Dark KDE – встановлюємо, активуємо:

Windows Decorations
Windows Decorations – вигляд вікон і кнопок:

Прикольна тема Willow Dark:

Icons
Налаштування іконок:

Наприклад, Papirus:


Заміна Applications launcher icon




Налаштування Taskbar
Міняємо taskbar – мені більш до вподоби “класичний” таскбар.
Клікаємо на таскбарі, вибираємо Show Alternatives:
 І вибираємо Icons-and-Text Task Manager:
І вибираємо Icons-and-Text Task Manager:

Налаштування верхньої панелі
Клікаємо на робочому столі, вибираємо Enter Edit mode:

Вибираємо Add Panel – Empty panel:

Додаємо віджети – є багато в комплекті, можна завантажити нові:

Наприклад, погода:

Або Global Menu:

Додаємо Panel Spacer – для розділення віджетів на панелі:

І в результаті маємо щось таке:


KDE Tiling Manager
Для мене це було прямо відкриття року – але в KDE завезли власний тайлінг-менеджер.
Активуємо налаштування по Win+T – налаштовуємо собі зони і padding між вікнами:
 Аби перенести якесь вікно в тайл – перетягуємо мишкою з зажатим Shift:
Аби перенести якесь вікно в тайл – перетягуємо мишкою з зажатим Shift:

Налаштування Konsole
Вибираємо Configure:

Додаємо новий Profile:

Задаємо тему:

Встановлюємо профайл як Default:

Різне
Мені дуже зручно перетягувати вікно не тільки за тайтл-бар, а по кліку будь-де на вікні+Alt.
Включаємо це в Window Actions – міняємо Modifier key:

В Plasma є перетягування вікна до краю екрана по дефолту може змінювати розмір вікна або переносити на інший віртуальний робочий стіл.
Мені це не дуже ок, заважає, тому можна відключити – заходимо Screen Edges, прибираємо галочки:
 Ще варто заглянути в Window Management – Desktop Effects – там є різні цікавинки і прикольні ефекти.
Ще варто заглянути в Window Management – Desktop Effects – там є різні цікавинки і прикольні ефекти.
KDE Tips and tricks: links
Не буду вже окремо їх описувати, бо їх дуже багато, але залишу посилання де можна подивитись або почитати:
- Give some tips and suggestions for using KDE: дискусія на Reddit
- Plasma/Tips: сторінка офіційної документації (тільки там про Plasma 5, зараз вже 6 версія, але актуально)
![]()











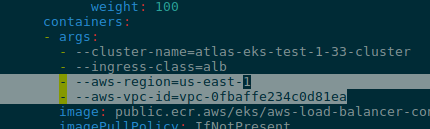
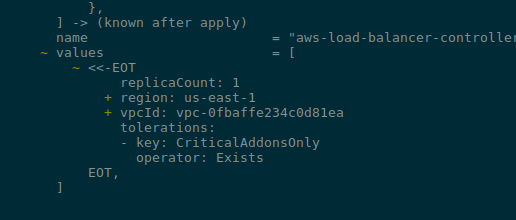
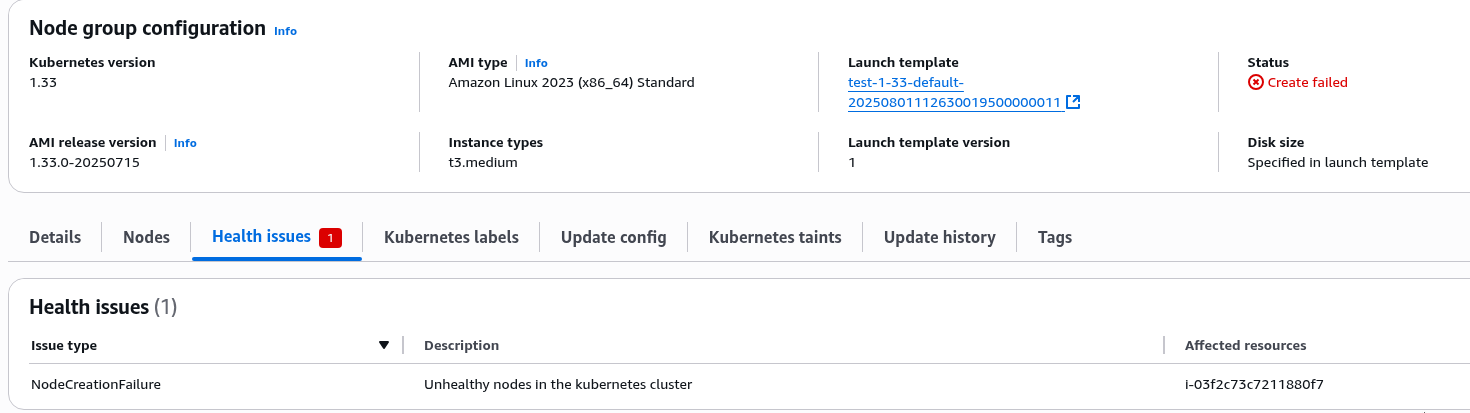

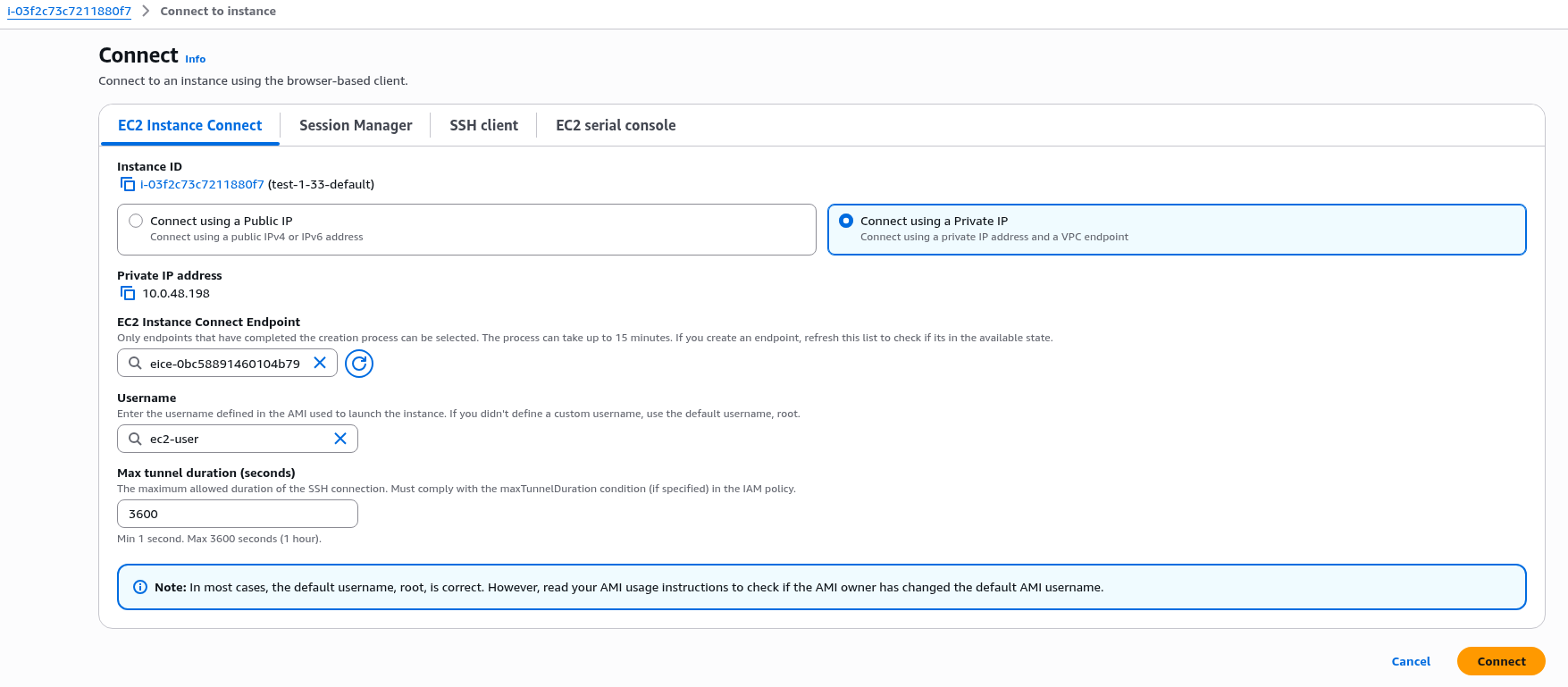




 Мабуть, всі користувались операторами в Kubernetes, наприклад –
Мабуть, всі користувались операторами в Kubernetes, наприклад –