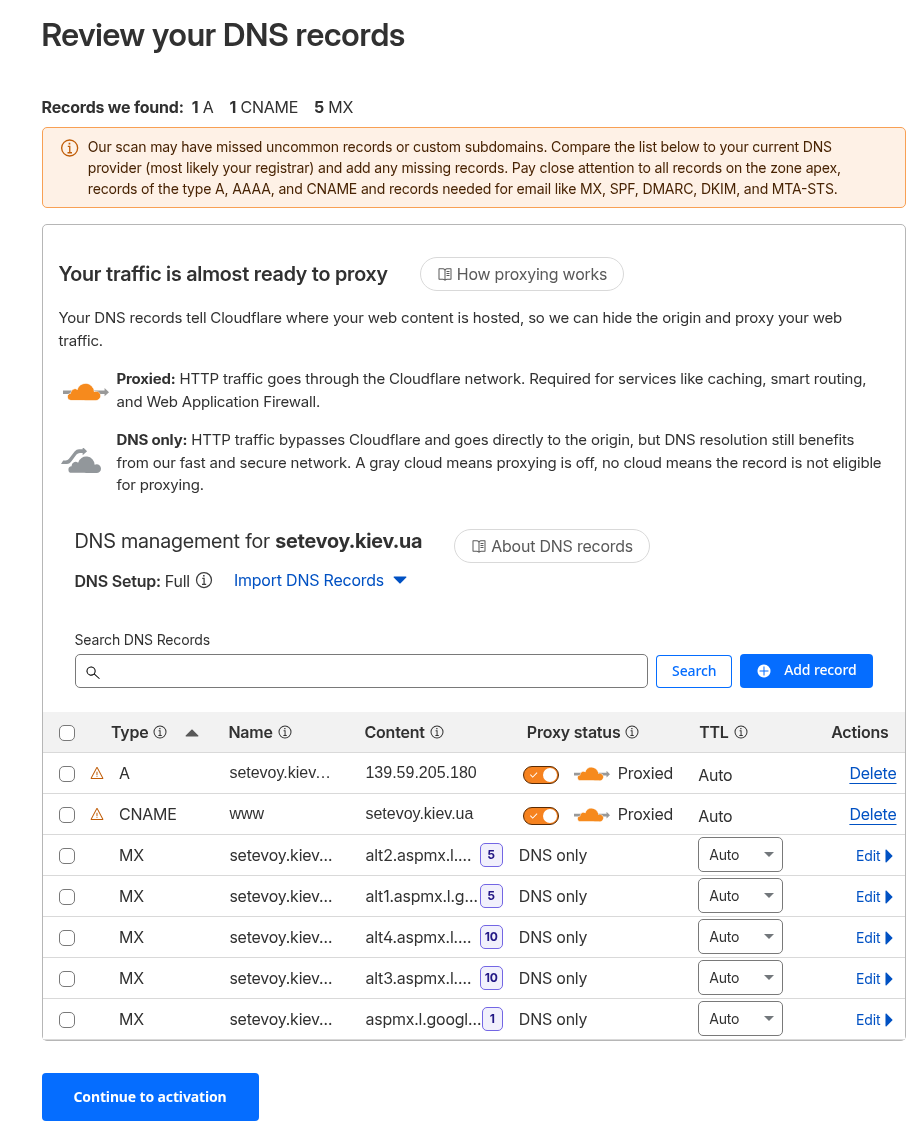
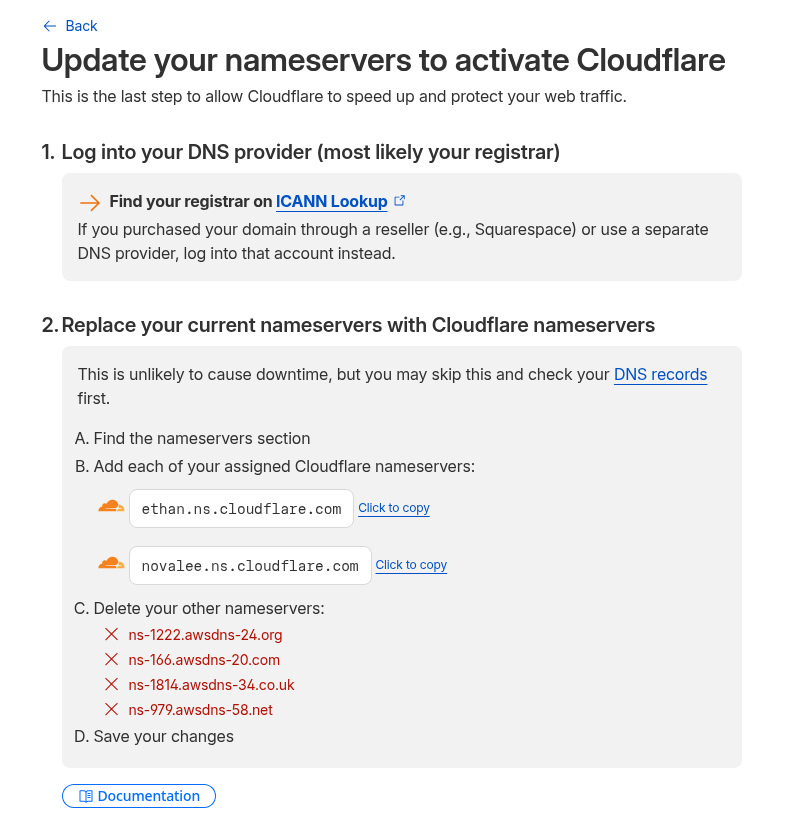
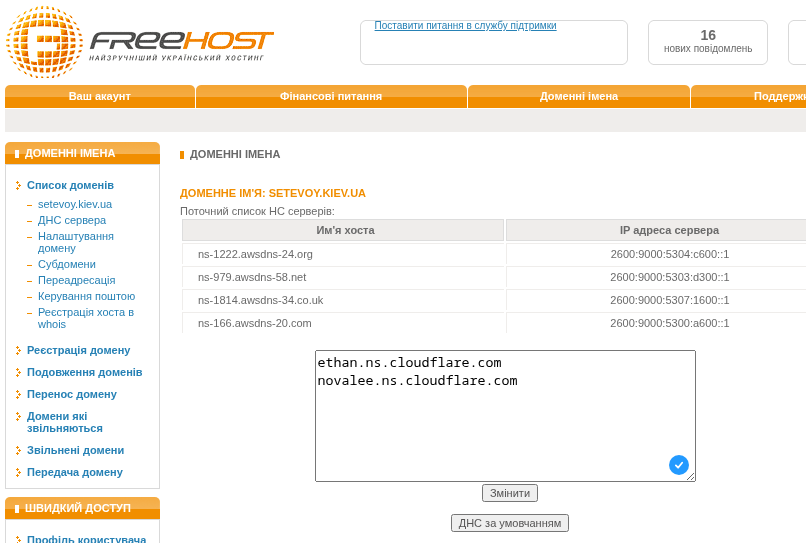
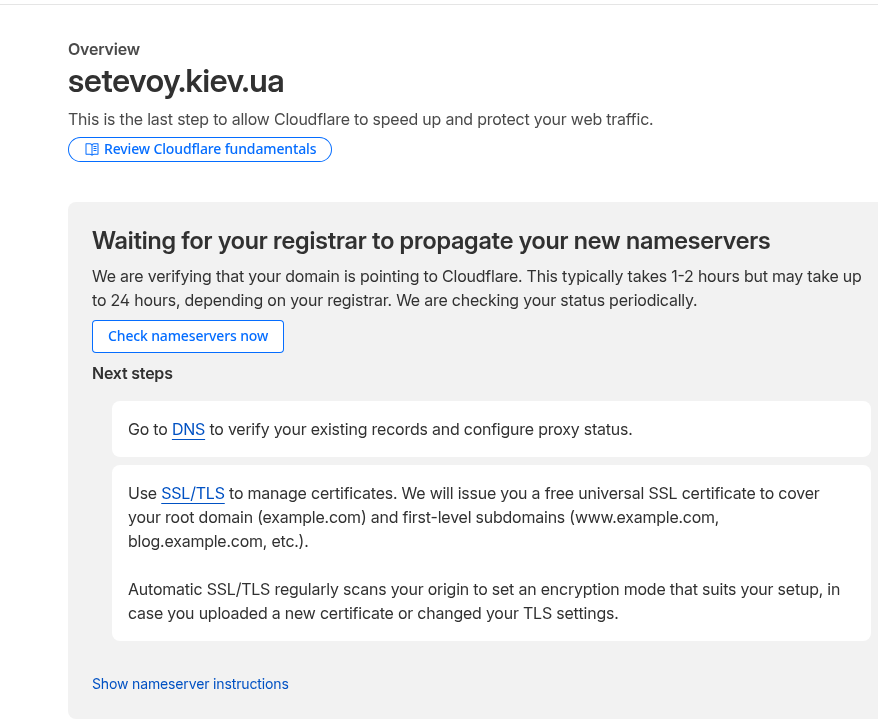
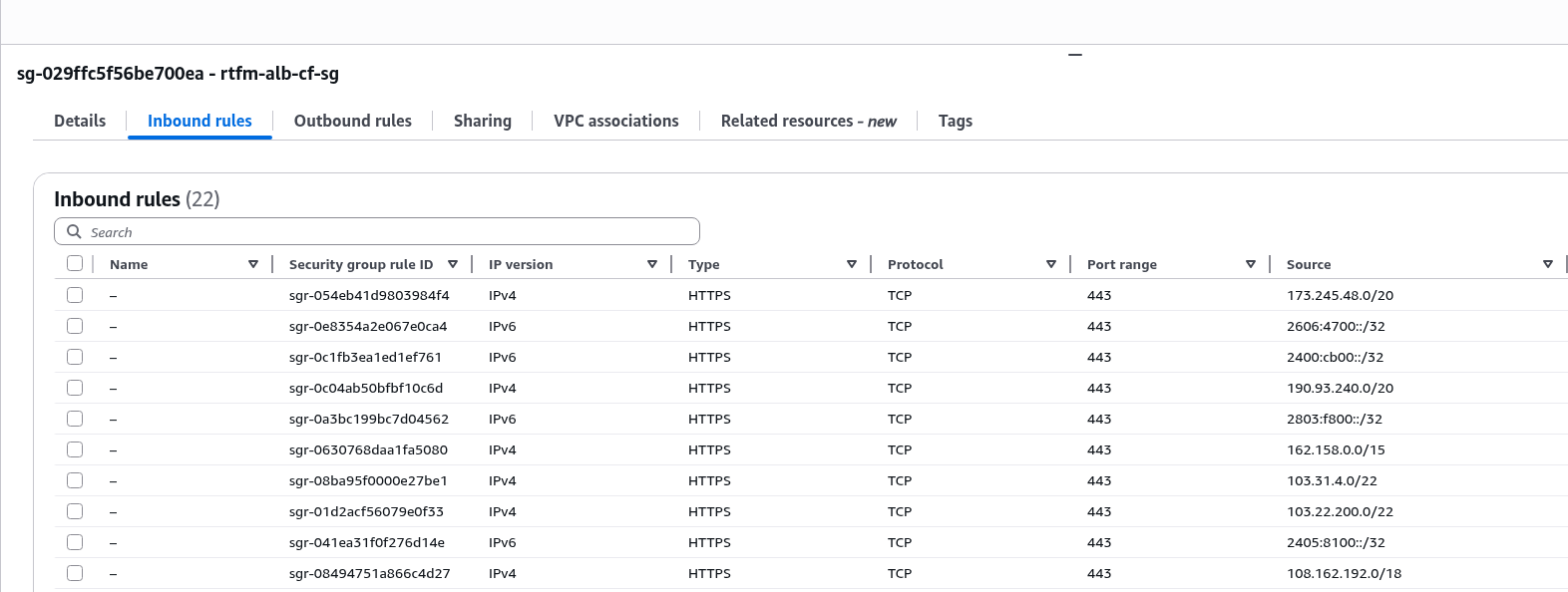
![]() Продовжуємо налаштування Okta для нашого проекту. В попередніх частинах зробили SSO для Grafana (див. Okta: налаштування Grafana SSO з OIDC та Role mapping) та AWS (див. AWS: налаштування Okta SSO з AWS IAM Identity Center), а тепер сама цікава частина: інтеграція Okta з Google Workspaces.
Продовжуємо налаштування Okta для нашого проекту. В попередніх частинах зробили SSO для Grafana (див. Okta: налаштування Grafana SSO з OIDC та Role mapping) та AWS (див. AWS: налаштування Okta SSO з AWS IAM Identity Center), а тепер сама цікава частина: інтеграція Okta з Google Workspaces.
Що треба буде зробити:
- налаштувати Users Provisioning: всіма юзерами хочеться керувати з Okta, тобто при створенні Okta User – автоматично створювати Google account, а при деактивації юзера в Okta – блокувати і його акаунт в Google
- налаштувати SSO/SAML: юзери мають логінитись в Google сервіси тільки через Okta
В цій частині налаштуємо Provisioning, а в наступній – SSO.
В Okta будемо використовувати Google Workspace App.
Писав по цій темі ще у 2019 році в пості Okta: интеграция с G-Suite – provisioning, импорт и экспорт пользователей, і, в принципі, нічого окрім інтерфейсу Okta не змінилось.
Але все ж тому посту 7 (OMG!) років, до того ж зараз я роблю дві інтеграції, тому нехай буде свіженький матеріал, ну і цього разу вийшло більше детально.
Тут приклади на моєму власному акаунті Google Workspaces, але вже зроблено і на робочому проекті – в продакшені вже з місяць, політ нормальний.
Документація від Okta – Google Workspace.
Сподіваюсь таки буде час подивитись на Authentik – open-source self-hosted IdP, альтернатива Okta, але поки не дуже актуально, бо у нас вже є ліцензії на Okta, а Open Source версії нема багатьох готових інтеграцій. Хіба що, може, візьму його для свого Home NAS на FreeBSD та його сервісів.
SCIM та Users Provisioning
Кілька слів про SCIM – System for Cross-domain Identity Management.
Як і у випадку з Provisioning для AWS і його IAM Identity Center – керування юзерами з Okta в Google Workspace відбувається за протоколом SCIM.
SCIM був створений у 2011 році аби навести порядок в різних інтеграціях, версія SCIM 2.0 була опублікована у 2015 і тепер використовується майже всюди – див. RFC 7642-7644.
По факту, це REST API, який описує як мають відбуватись операції з юзерами та групами – create, read, update, delete, у RFC вище є приклади GET/POST/PATCH запитів:
$ GET /Users/2819c223-7f76-453a-919d-413861904646
Host: example.com
...
HTTP/1.1 200 OK
Content-Type: application/scim+json
Location:
https://example.com/v2/Users/2819c223-7f76-453a-919d-413861904646
...
{
"schemas":["urn:ietf:params:scim:schemas:core:2.0:User"],
...
"meta":{
"resourceType":"User",
...
"name":{
"formatted":"Ms. Barbara J Jensen III",
"familyName":"Jensen",
"givenName":"Barbara"
},
...
"emails":[
{
"value":"[email protected]",
"type":"work"
}
]
}
...
В Okta Google Workspace App “знає” які API-запити робити до Google аби створити юзера – а Okta знає що треба передати “на вхід” до Google Workspace.
Альтернативи – LDAP (колись писав про OpenLDAP), JIT provisioning (Just-in-Time) – коли маємо SSO з сервісом, і юзер перший раз логіниться – то в цьому сервісі створюється юзер.
Okta: додавання Google Workspaces App
Для налаштувань Google Workspaces App в Okta треба буде вказати Company Domain.
Важливо: після створення App поле “Your Google Apps company domain” просто через Edit вже змінити не можна – тому налаштуйте відразу, він треба буде для SSO.
Переходимо в адмінку Google Workspaces, там в Account > Domains, знаходимо Primary domain:

Він буде використовуватись в SSO та при створенні посилань на сервіси.
Тобто лінк на Gmail буде виглядати як https://mail.google.com/a/setevoy.kiev.ua.
Додаємо нову Application в Okta, в General Settings задаємо цей Company Domain:

В Sign-On поки нічого не міняємо – в другій частині налаштуємо SAML:

Тут все – можна робити Provisioning.
Налаштування Provisioning
Переходимо на вкладку Provisioning, клікаємо Configure API Integration:

Логінимось з адмін-акаунтом (з роллю Super Admin) нашого Google Workspace:
 Тут опція Push Empty Values for Custom Fields – якщо в Okta User Profile є кастомні атрибути, але вони з пустими значеннями – то Okta не передає їх до Google.
Тут опція Push Empty Values for Custom Fields – якщо в Okta User Profile є кастомні атрибути, але вони з пустими значеннями – то Okta не передає їх до Google.
Attribute Mappings є в Profile Editor:
 Але там з Okta до Google заданий тільки один userName:
Але там з Okta до Google заданий тільки один userName:

Опція Import Groups – чи переносити групи з https://admin.google.com/ac/groups до Okta як окремих юзерів. В моєму випадку, коли інтеграція буде тільки для менеджменту саме юзерів – то групи не потрібні.
Google Workspace Permissions для Okta
Натискаємо “Authentificate with Google Workspace”, вибираємо що Okta може робити в Google:
- View user schemas on your domain, See info about users on your domain, View and manage the provisioning of users on your domain: включаємо, це основне, для чого робимо інтеграцію – робота з Google Users
- View and manage the provisioning of groups on your domain, View and manage group subscriptions on your domain: якщо хочемо керувати Google Groups з Okta – включаємо
- тоді зможемо робити Group Push із Okta да Google: якщо маємо Okta Group як “my-Group“, то вона буде додана в Google як “[email protected]“
- коли додаємо Okta юзера до Okta Group – то він буде доданий і до Google Group
- View and manage organization units on your domain: якщо маємо мапінг атрибута в Okta на поле Organization Unit (OU) і вмикаємо цей дозвіл – то Okta може керувати OU юзера в Google
- Manage delegated admin roles: якщо використовуємо Manage roles on create and update (буде далі) – якщо ролями Google з Okta керувати не плануємо – можна пропустити
- View and manage Google Workspace licenses: чи дозволяти керувати ліцензіями
- Manage data access permissions: керування сесіями – деактивація юзера в Okta завершує всі його активні сесії в Google, включаємо
Є класний список всіх Google OAuth scope в таблиці Google Workspace (G Suite) Integration.
Після аутентифікації Okta ще не почне нічим керувати – всі юзери в Google залишаться без змін, бо сам Provisioning ще не налаштований.
Але в будь-якому випадку для Production варто створити окремого breaking glass юзера, який не інтегрований ні з SSO, ні з provisioning.
Включаємо всі дозволи:

Готово:

Імпорт юзерів з Google до Okta
Okta дозволяє виконати синхронізацію юзерів як з Okta до Google, так і навпаки:
- якщо в Okta вже юзери, а Google акаунт новий або там вже є ті самі юзери – то цю частину можна пропустити
- якщо вже маємо юзерів в Google Workspaces і налаштовуємо новий акаунт Okta – то можемо імпортувати юзерів з Google до Okta
Google to Okta: параметри імпорту
Спершу можна зайти в Provisioning > To Okta, і перевірити налаштування там.
В принципі, зараз тут залишаємо всі дефолтні параметри, але маємо на увазі, що тут можна змінити.
В General можемо додати запуск по крону та, якщо використовуємо власний, то змінити Okta username format.
З цікавого тут опція Update application username on: теж залишаємо дефолтне значення Create only, бо навіть якщо ми включимо її в Create and update, то це вплине тільки на SSO цього юзера – який username буде відправлятись в SAML assertion (див. What is: SAML – обзор, структура и трассировка запросов на примере Jenkins и Okta SAML SSO, 2019 рік), але в самому Google акаунт автоматично не перейменується:

Далі, опції в “User Creation & Matching”:
- Imported user is an exact match if: як Okta порівнює юзерів із Google з власною базою – залишаємо по email
- Allow partial matches: якщо email юзера в Google != в Okta, то Okta спробує пошукати по First Name / Last name, в Production краще відключити – можемо мати двох юзерів зі схожими іменами/фаміліями, Okta може їх спутати (хоча ми все одно далі будемо робити manual review)
- Confirm matched users та Confirm new users: можна включити автоматичний approve для імпортованих юзерів, дефолтне значення off, і для production це правильно

І останні дві частини тут – “Profile & Lifecycle Sourcing” та “Import Safeguard”.
Allow Google Workspace to source Okta users визначає хто буде керувати профілями: якщо включити, то профілі редагуються в Google, для Okta вони стають read only – не треба.
Import Safeguard – дуже корисна штука: якщо ми маємо 50 юзерів Okta, яким підключена Google Workspaces, а потім при імпорті з Google (наприклад, якщо включити імпорт за розкладом) Okta отримала від Google не 50 акаунтів, а тільки 5 – то вона не буде виконувати Google Workspace App unassign всіх юзерів, а зупинить імпорт і потребує ручного підтвердження:

Google до Okta: запуск імпорту
Для імпорту із Google до Okta переходимо у, власне, Import, клікаємо Import now.
Опції Confirm matched users та Confirm new users, які бачили вище, зараз відключені, тому натискання Import now ще не запустить імпорт, а тільки отримає список юзерів від Google:

В моєму акаунті тільки три юзера:
 І три акаунти Okta і побачила:
І три акаунти Okta і побачила:

Клікаємо OK, і тепер маємо можливість вибрати кого саме ми будемо імпортувати з Google до Okta.
Merge та Create Okta Users
Я буду в Okta додавати тільки одного тестового юзера, [email protected] – справа відмічаємо його і внизу клікаємо Confirm Assignments:

З юзерами, у яких статус Partial user march є кілька варіантів – змержити юзера, створити нового, заматчити на іншого існуючого юзера, або взагалі ігнорувати – клікаємо на такий partial match, і вибираємо дію з drop-down списку:
 Якщо залишимо Partial user match – то Okta User [email protected] буде прив’язаний до Google User [email protected], і, відповідно, якщо ми зробимо Okta Deactivate для [email protected] – то в Google юзер [email protected] стане Suspended.
Якщо залишимо Partial user match – то Okta User [email protected] буде прив’язаний до Google User [email protected], і, відповідно, якщо ми зробимо Okta Deactivate для [email protected] – то в Google юзер [email protected] стане Suspended.
Ще нюанс: якщо юзер вже Suspended в Google – то в списку на Import він не додається. Але якщо такий юзер в Okta вже є, і навіть якщо він Deactivated – то Okta його додасть в список.
Можна відразу активувати його, клікаємо Confirm:

І перевіряємо.
Переходимо в Directory > People, маємо там нового Okta User:

Якому вже підключена Google Workspace App:

Тепер зробимо навпаки – синхронізацію юзерів з Okta до Google.
Provisioning з Okta до Google
Основна задача: при створенні нового Okta User (точніше – під час Assign юзера до Google Workspace App) треба автоматично створювати нові акаунти в Google Workspace.
Аналогічно при деактивації юзера в Okta – треба блокувати його акаунт в Google.
Тобто весь менеджмент акаунтами Google буде виконуватись через Okta, і Okta буде нашим “source of truth” для юзерів і їхнього стану (active, deactivated/suspended).
Okta to Google: параметри Provisioning
Переходимо в Provisioning > To App, клікаємо Edit, включаємо всі опції (або тільки Create Users, якщо хочеться спокійно потестити на “production” Google акаунті).
З цікавого тут Sync Password – який пароль буде задано в новому Google акаунті. Можна згенерити рандомний, можна встановити такий жеж, як у Okta User.
Опція Update User Attributes визначає, чи буде Okta міняти атрибути: якщо включено, і у юзера в Okta Profile змінився First Name – це поле буде змінено і в Google. Якщо відключено – то атрибути передаються тільки під час create user в Google:

Use of Sync Password
Тут окреме питання по Sync Password:
- якщо у нас вже є юзер в Google з власним паролем, якого ми вже імпортували і виконали Assign на Google Workspace App, то зараз, коли ми збережемо Okta to Google provisioning – в нього зміниться пароль, чи ні?
- я перевіряв на цьому, тестовому акаунті – і пароль не міняється, тобто існуючі Google Users продовжують логінитись, як і до налаштування інтеграції
- але в робочому акаунті проекті все ж не ризикнув включати
І однозначної відповіді не знайшов:
- в документації від Google Okta user provisioning and single sign-on говорить цю опцію не включати (хоча там далі є SSO, можливо, через це)
- в документації від Okta Configure Password Push Updates говориться включати
- і навіть тех. підтримка спочатку сформулювала відповідь як “If you don’t use SSO, just the Provisioning features, then yes, the Sync Password feature would override the users password“
Але пізніше я таки добився чіткої відповіді:
The passwords will be overridden, but it’s not going to be immediately as you enable the feature.
The password sync is based on certain triggers which typically are unavoidable (as discussed in this article).
Adding the specifics here as well for convenience:
” In order to trigger the password sync for a user, one of these events must occur:
- Resetting an Okta-sourced password.
- Signing in to Okta with a password.
- Delegated authentication sign-in to Okta. “
In addition to those, app assignment or re-assignment after you enable the sync password feature also triggers the override.
Therefore, it’s possible that some users will still use the original password if none of the above events happened.
Тобто рано чи пізно – але пароль для Google акаунту таки зміниться.
Можна просто залишити цю опцію вимкненою взагалі – але тоді маємо проблему chicken and eggs: як передати новому юзеру його пароль?
Наприклад, у нас на проекті Slack login через Google. Тому в Slack теж не скинеш якийсь тимчасовий пароль.
Ідеально – включати опцію Sync Okta Password:
 Але це ідеально, якщо у вас буде SSO в Google через Okta.
Але це ідеально, якщо у вас буде SSO в Google через Okta.
У нас SSO поки що не буде, і мені зараз жим-жим робити це для десятків юзерів які вже є в Google і яких я вже імпортував до Okta.
Тому цю опцію не включав взагалі – будемо передавати пароль на папірці :trollface:
Okta to Google: перевірка створення акаунту
Зберігаємо налаштування, і для перевірки додаємо в Okta нового юзера – але тільки створення нового Okta User, без, власне assign до Google Workspace App в Okta, ще не створить Google Account:

Аби додати новий акаунт в Google – переходимо до Google Workspace Application > Assignments:

Підключаємо цього тестового юзера:

В опціях можна залишити все дефолтним, або відразу задати ролі в Google Workspace.
Опцію Manage roles on create and update залишаємо відключеною – ролями в Google краще керувати самим:

Зберігаємо і дивимось логи в Reports > System log (взагалі корисна штука, потім треба буде налаштувати моніторинг) – бачимо, що push to Google виконаний без помилок:

Перевіряємо юзерів в самому Google:

Я в Okta залишив дефолтну опцію “Sync a randomly generated password“, тому для перевірки резетаємо пароль:
 І логінимось:
І логінимось:

Все працює:


Okta User Deactivation та Google Account Suspend
І перевіримо, як працює синхронізація стану юзера:
- коли ми виконаємо Unassign юзера в Okta від Google Workspaces App, або якщо робимо Okta User Deactivate – то в Google його акаунт перейде в стан Suspended
- при видалені юзера з Okta – його акаунт в Google залишиться, але теж в стані Suspended, але тільки якщо в Provisioning > To App включена опція Deactivate Users (по дефолту включена)
Пробуємо – деактивуємо юзера в Okta:

Перевіряємо в Google:

Готово.
![]()
 На домашньому NAS крутиться багато web-сервісів – Grafana, VictoriaMetrics, мій власний щоденник на WordPress і ще пів-десятка дрібниць.
На домашньому NAS крутиться багато web-сервісів – Grafana, VictoriaMetrics, мій власний щоденник на WordPress і ще пів-десятка дрібниць.






































































































 в алерті для різних $value")