![]() Terraform має два способи перенести існуючі ресурси під управління Terraform – з Terraform CLI і командою
Terraform має два способи перенести існуючі ресурси під управління Terraform – з Terraform CLI і командою terraform import, або використовуючи ресурс import.
Для чого нам може знадобитись імпорт ресурсів?
- якщо у нас вже є вручну налаштований (“clickops”) якийсь сервіс, який ми хочемо перенести під управління Terraform (робили як Proof of Concept, а потім пішло в production)
- якщо у нас є ресурси, які створювались з іншою IaC системою, наприклад – з CloudFormation
- якщо ми втратили наш state-файл, і треба його відновити
- чи якщо ми розбиваємо один великий проект на менші і створюємо нові state-файли
Окрім Terraform CLI та import block є інструменти по типу Terraformer та Terracognita, які частину роботи роблять самі – втім, вони не ідеальні, див. Generating Infrastructure-as-Code From Existing Cloud Resources.
Але сьогодні ми все спробуємо без них.
Процес імпорту ресурсів
Як виглядає процес імпорту:
- в tf-файлі описуємо пустий resource
- виконуємо
terraform import - порівнюємо дані в state-файлі і нашому коді
- переносимо зміни до tf-файлу
- …
- profit!
Приклад імпорту з Terraform CLI
Створимо AWS IAM User:
$ aws --profile setevoy iam create-user --user-name iam-user-to-be-imported
{
"User": {
"Path": "/",
"UserName": "iam-user-to-be-imported",
"UserId": "AIDAT3EEMW7XERE75PH6N",
"Arn": "arn:aws:iam::264***286:user/iam-user-to-be-imported",
"CreateDate": "2025-06-14T12:15:52+00:00"
}
}
Створюємо тестовий Terraform проект:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
profile = "setevoy"
region = "us-east-1"
}
Виконуємо terraform init:
$ terraform init Initializing the backend... Initializing provider plugins... - Finding hashicorp/aws versions matching "~> 5.0"... - Installing hashicorp/aws v5.100.0... - Installed hashicorp/aws v5.100.0 (signed by HashiCorp) ...
Імпорт AWS IAM User
Описуємо блок для IAM-юзеру, якого ми будемо переносити під управління Terraform. В цьому випадку це буде aws_iam_user:
...
resource "aws_iam_user" "imported_iam_user" {
# Import this user using the command:
# terraform import aws_iam_user.imported_iam_user iam-user-to-be-imported
name = "iam-user-to-be-imported"
}
Про параметри, які треба вказувати в нашому “шаблоні”:
- якщо б це був, наприклад, S3-бакет – то для нього всі параметри опціональні, і достатньо було просто указати
resource "aws_s3_bucket" "example" {} - але для aws_iam_user є обов’язковий параметр
name
Тому задаємо required параметр name – цього досить.
Тепер можемо виконати сам імпорт юзеру з AWS вказавши ім’я ресурсу в коді (його ідентифікатор для terraform) – aws_iam_user.imported_iam_user та ім’я юзера в AWS IAM:
$ terraform import aws_iam_user.imported_iam_user iam-user-to-be-imported aws_iam_user.imported_iam_user: Importing from ID "iam-user-to-be-imported"... aws_iam_user.imported_iam_user: Import prepared! Prepared aws_iam_user for import aws_iam_user.imported_iam_user: Refreshing state... [id=iam-user-to-be-imported] Import successful!
Перевіряємо Terraform state:
$ terraform state list aws_iam_user.imported_iam_user
І зміст об’єкту aws_iam_user.imported_iam_user в цьому стейті:
$ terraform state show aws_iam_user.imported_iam_user
# aws_iam_user.imported_iam_user:
resource "aws_iam_user" "imported_iam_user" {
arn = "arn:aws:iam::264***286:user/iam-user-to-be-imported"
id = "iam-user-to-be-imported"
name = "iam-user-to-be-imported"
path = "/"
permissions_boundary = null
tags = {}
tags_all = {}
unique_id = "AIDAT3EEMW7XERE75PH6N"
}
Далі можемо оновлювати наш код, але є нюанс.
No changes. Your infrastructure matches the configuration.
Тепер цікавий момент: якщо зараз виконати terraform plan – то Terraform скаже, що ніяких змін робити не потрібно:
$ terraform plan aws_iam_user.imported_iam_user: Refreshing state... [id=iam-user-to-be-imported] No changes. Your infrastructure matches the configuration.
Хоча, здавалося б – в нашому коді не описані ніякі атрибути юзера, які ми бачимо в terraform state show.
Причина в тому, що коли ми створювали IAM-юзера з AWS CLI та командою create-user – то не вказували ніяких додаткових опцій, і AWS CLI через AWS API створив його з усіма дефолтними параметрами.
Аналогічно робить і Terraform, коли ми запускаємо terraform plan – він перевіряє значення в AWS зі значеннями, які описані в провайдері, бачить, що все дефолтне – і тому каже, що ніяких змін робити не треба.
Як приклад – дефолтне значення path задається в провайдері явно як "/" – див. internal/service/iam/user.go#L62:
...
names.AttrPath: {
Type: schema.TypeString,
Optional: true,
Default: "/",
},
...
Тепер давайте створимо нового юзера, але вже з явно заданим path:
$ aws --profile setevoy iam create-user --user-name iam-user-to-be-imported-2 --path /some-path/
Додаємо його в код як і першого юзера – без додаткових параметрів:
...
resource "aws_iam_user" "imported_iam_user_2" {
# Import this user using the command:
# terraform import aws_iam_user.imported_iam_user iam-user-to-be-imported
name = "iam-user-to-be-imported"
}
Тепер виконаємо terraform import:
$ terraform import aws_iam_user.imported_iam_user_2 iam-user-to-be-imported-2
І ще раз подивимось на результат terraform plan – то цього разу Terraform захоче змінити атрибут path юзера:
$ terraform plan
...
# aws_iam_user.imported_iam_user_2 will be updated in-place
~ resource "aws_iam_user" "imported_iam_user_2" {
+ force_destroy = false
id = "iam-user-to-be-imported-2"
name = "iam-user-to-be-imported-2"
~ path = "/some-path/" -> "/"
tags = {}
# (4 unchanged attributes hidden)
}
Оновлення main.tf
Окей, йдемо далі.
Імпорт ми зробили – юзер у нас є в state-файлі, і є код в main.tf – “пустий шаблон” цього юзера.
Аби завершити імпорт – нам потрібно привести наш код до такого ж стану, який є в state, бо наш код має бути source of truth для цього ресурсу.
При цьому нам не потрібно переносити абсолютно всі параметри зі стейту Terraform до ресурсу в коді: ми переносимо тільки те, чим хочемо явно керувати, або якщо ми хочемо їх відобразити в коді для його ясності.
Є параметри, для яких задаються дефолтні значення, є параметри, які генеруються самим AWS.
- конфігураційні для Terraform resource: ім’я,
path,tagsтощо- для більшості є дефолтні значення
- generated параметри:
arn,unique_id(UserIdв outputs AWS CLI)
Конфігураційні параметри ми бачимо в документації до ресурсу в Argument Reference.
Параметри, які генерує сам AWS описані в Attribute Reference.
Інший спосіб це визначити – зазирнути в код провайдера, наприклад для unique_id значення вказано в internal/service/iam/user.go#L82:
...
"unique_id": {
Type: schema.TypeString,
Computed: true,
},
...
Тут в полі Computed ми як раз і бачимо, що воно визначається автоматично з AWS.
Отже, в цьому випадку нам точно треба задати path:
...
resource "aws_iam_user" "imported_iam_user_2" {
name = "iam-user-to-be-imported-2"
path = "/some-path/"
}
Виконуємо terraform plan – і тепер ніяких змін нема:
$ terraform plan aws_iam_user.imported_iam_user_2: Refreshing state... [id=iam-user-to-be-imported-2] aws_iam_user.imported_iam_user: Refreshing state... [id=iam-user-to-be-imported] No changes. Your infrastructure matches the configuration.
Terraform diffing mechanism
Тепер ще один цікавий момент.
Якщо ми задамо якісь додаткові атрибути нашому вже імпортованому юзеру, наприклад теги:
resource "aws_iam_user" "imported_iam_user_2" {
name = "iam-user-to-be-imported-2"
path = "/some-path/"
tags = {
ManagedBy = "Terraform"
}
}
І виконаємо terraform plan ще раз:
$ terraform plan
...
Terraform will perform the following actions:
# aws_iam_user.imported_iam_user_2 will be updated in-place
~ resource "aws_iam_user" "imported_iam_user_2" {
+ force_destroy = false
id = "iam-user-to-be-imported-2"
name = "iam-user-to-be-imported-2"
~ tags = {
+ "ManagedBy" = "Terraform"
}
...
То побачимо цікаву річ: на цей раз Terraform хоче додати атрибут force_destroy = false.
Чому це?
Бо force_destroy – це атрибут, який існує тільки в коді самого Terraform, але його немає в AWS: під час виконання terraform import – Terraform з AWS API отримав ті атрибути, які надає AWS, і зберіг їх у своєму state.
Відповідно зараз в state нема force_destroy:
$ terraform state show aws_iam_user.imported_iam_user_2
# aws_iam_user.imported_iam_user_2:
resource "aws_iam_user" "imported_iam_user_2" {
arn = "arn:aws:iam::264***286:user/some-path/iam-user-to-be-imported-2"
id = "iam-user-to-be-imported-2"
name = "iam-user-to-be-imported-2"
path = "/some-path/"
permissions_boundary = null
tags = {}
tags_all = {}
unique_id = "AIDAT3EEMW7XER5THQH4Q"
}
Коли Terraform виконує plan – то в першому випадку, коли ми задали тільки значення name та path:
- під час виконання
plan– Terraform виконує “швидку перевірку” – порівнює аргументи в коді з даними в state - бачить, що ніяких змін не було – і на цьому завершує роботу з повідомленням “Your infrastructure matches the configuration“
Другий випадок – ми додали tags, і тоді:
- під час виконання
plan– Terraform виконує “швидку перевірку” – порівнює аргументи в коді з даними в state - Terraform бачить, що деякі атрибути ресурсу змінились – і починає виконувати більш детальну перевірку формуючи повну схему ресурсу з усіма дефолтними значенням
- Terraform бачить, що в state-файлі нема аргументу
force_destroy, і планує додати його до state
Власне, оскільки force_destroy у нас і так має дефолтне значення false, то ми просто можемо виконати terraform apply, після чого в state з’явиться новий атрибут:
$ terraform state show aws_iam_user.imported_iam_user_2
# aws_iam_user.imported_iam_user_2:
resource "aws_iam_user" "imported_iam_user_2" {
arn = "arn:aws:iam::264***286:user/some-path/iam-user-to-be-imported-2"
force_destroy = false
...
permissions_boundary = null
tags = {
"ManagedBy" = "Terraform"
}
...
Імпорт в модуль
Окрім того, що ми можемо імпортувати об’єкти як звичайні Terraform resources, ми можемо їх додавати в модулі.
Наприклад, модуль Anton Babenko terraform-aws-modules/iam, в якому є сабмодуль iam-user.
Створимо “шаблон” в нашому main.tf:
...
module "iam_user_imported" {
source = "terraform-aws-modules/iam/aws//modules/iam-user"
name = "iam-user-to-be-imported-2"
path = "/some-path/"
}
Дивимось, як заданий ресурс в самому модулі – файл modules/iam-user/main.tf:
resource "aws_iam_user" "this" {
count = var.create_user ? 1 : 0
name = var.name
path = var.path
force_destroy = var.force_destroy
permissions_boundary = var.permissions_boundary
tags = var.tags
}
Виконуємо terraform init, і можемо імпортувати нашого юзера використовуючи ідентифікатор module.iam_user_imported.aws_iam_user.this.
Але.
Помилка “Configuration for import target does not exist”
Запускаємо імпорт – і отримуємо помилку:
$ terraform import module.iam_user_imported.aws_iam_user.this iam-user-to-be-imported-2 ╷ │ Error: Configuration for import target does not exist │ │ The configuration for the given import module.iam_user_imported.aws_iam_user.this does not exist. All target instances must have an associated configuration to be imported.
Чому?
Бо повернемось до коду модулю:
... count = var.create_user ? 1 : 0 ...
При використанні count – Terraform створює список з елементами, навіть якщо він там один.
Тобто, в умові сказано: “якщо var.create_user == true, то створюємо один об’єкт” – але це вже буде об’єкт list з одним елементом.
Тому до ресурсу треба звертатись по індексу – [0]:
$ terraform import module.iam_user_imported.aws_iam_user.this[0] iam-user-to-be-imported-2 module.iam_user_imported.aws_iam_user.this[0]: Importing from ID "iam-user-to-be-imported-2"... module.iam_user_imported.aws_iam_user.this[0]: Import prepared! Prepared aws_iam_user for import module.iam_user_imported.aws_iam_user.this[0]: Refreshing state... [id=iam-user-to-be-imported-2]
І тепер він є в нашому state:
$ terraform state show module.iam_user_imported.aws_iam_user.this[0]
# module.iam_user_imported.aws_iam_user.this[0]:
resource "aws_iam_user" "this" {
arn = "arn:aws:iam::264***286:user/some-path/iam-user-to-be-imported-2"
id = "iam-user-to-be-imported-2"
name = "iam-user-to-be-imported-2"
path = "/some-path/"
permissions_boundary = null
tags = {
"ManagedBy" = "Terraform"
}
tags_all = {
"ManagedBy" = "Terraform"
}
unique_id = "AIDAT3EEMW7XER5THQH4Q"
}
Terraform import block
І подивимось як працює import в самому коді.
В принципі, тут все теж саме – вказуємо що (id) та куди (to) імпортувати:
import {
to = aws_iam_user.imported_iam_user_3
id = "iam-user-to-be-imported-2"
}
resource "aws_iam_user" "imported_iam_user_3" {
name = "iam-user-to-be-imported-2"
path = "/some-path/"
tags = {
ManagedBy = "Terraform"
}
}
Тепер при виконанні terraform plan ми будемо бачити що саме і з якими параметрами буде імпортуватись:
$ terraform plan
aws_iam_user.imported_iam_user_3: Preparing import... [id=iam-user-to-be-imported-2]
aws_iam_user.imported_iam_user_3: Refreshing state... [id=iam-user-to-be-imported-2]
aws_iam_user.imported_iam_user: Refreshing state... [id=iam-user-to-be-imported]
...
Terraform will perform the following actions:
# aws_iam_user.imported_iam_user_3 will be imported
resource "aws_iam_user" "imported_iam_user_3" {
arn = "arn:aws:iam::264***286:user/some-path/iam-user-to-be-imported-2"
id = "iam-user-to-be-imported-2"
name = "iam-user-to-be-imported-2"
path = "/some-path/"
permissions_boundary = null
tags = {
"ManagedBy" = "Terraform"
}
tags_all = {
"ManagedBy" = "Terraform"
}
unique_id = "AIDAT3EEMW7XER5THQH4Q"
}
Plan: 1 to import, 0 to add, 1 to change, 0 to destroy.
...
Готово.
![]()













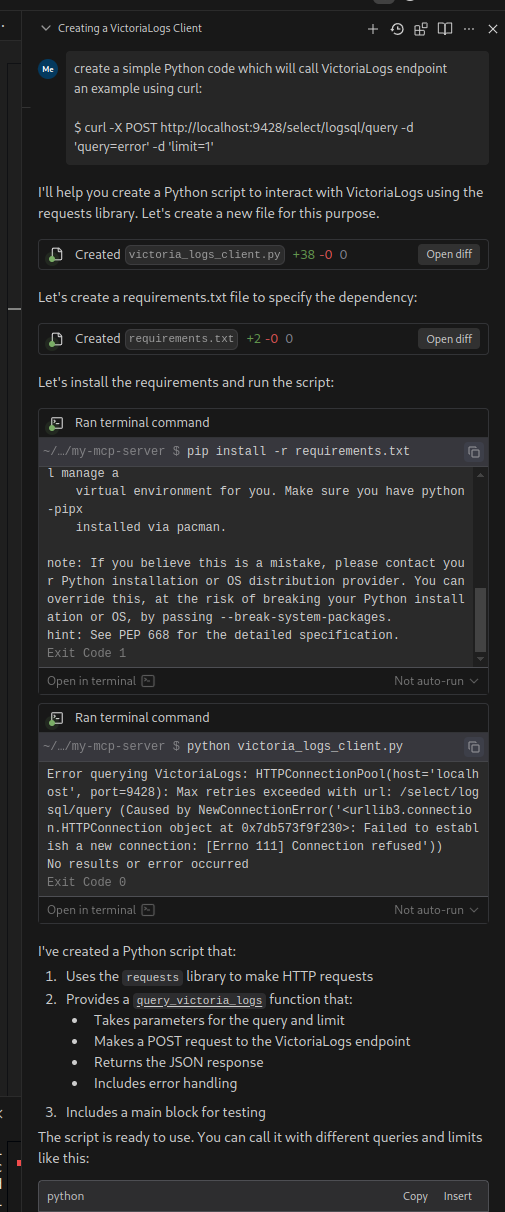
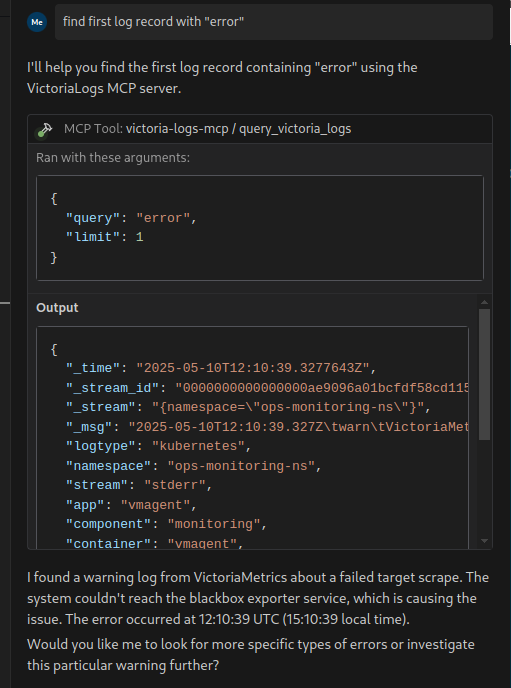
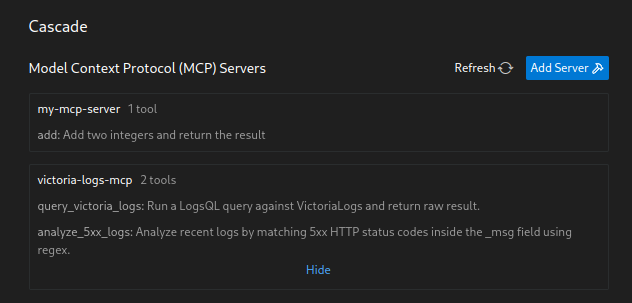
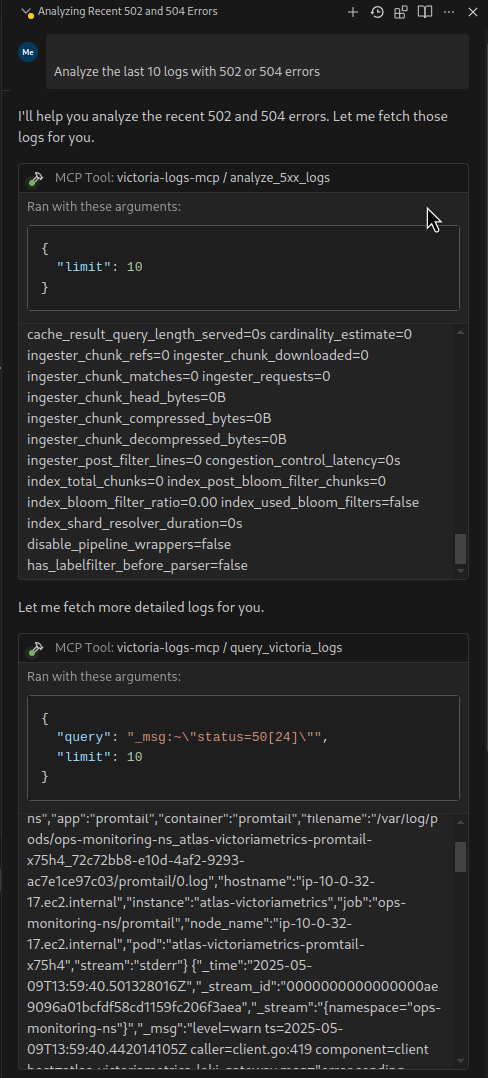
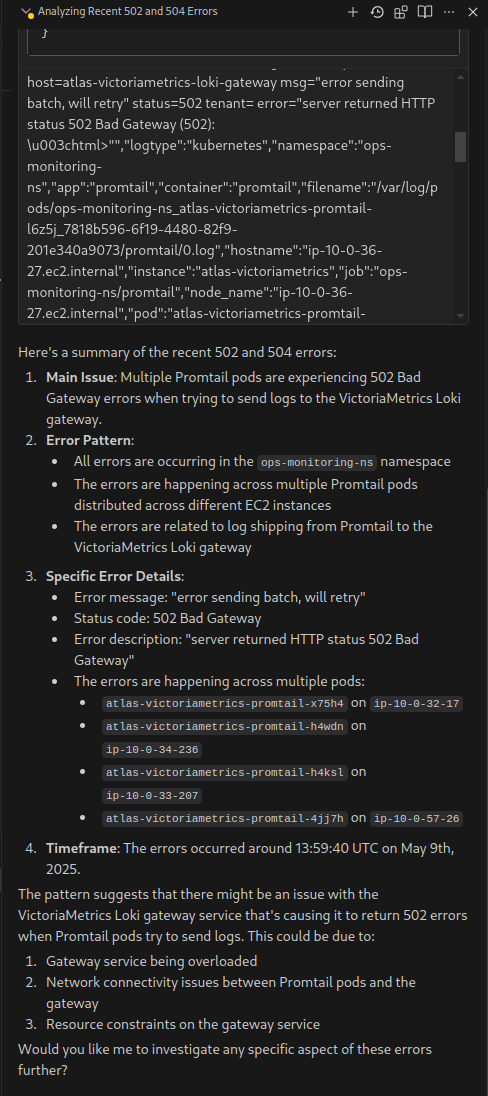












 Маємо AWS Elastic Kubernetes Service, на якому розгорнуто стек VictoriaMetrics (див.
Маємо AWS Elastic Kubernetes Service, на якому розгорнуто стек VictoriaMetrics (див. 











