Доволі часта помилка при апгрейді версій модулів, коли маємо обмеження на версії модулів чи провайдерів, і вони не співпадають між собою.
The Issue
В цьому випадку я змержив Pull Requests від Renovate і не звернув увагу на те, що terraform-aws-modules/terraform-aws-lambda потребує hashicorp/aws provider версії 6:
І змержив спочатку апгрейд Lambda до 8 версії.
Після цього під час виконання terraform init отримав помилку “no available releases match the given constraints“:
$ terraform init
Initializing the backend...
Upgrading modules...
...
│ Error: Failed to query available provider packages
│
│ Could not retrieve the list of available versions for provider hashicorp/aws: no available releases match the given constraints >= 3.29.0, ~> 5.14, >= 5.92.0, >= 6.0.0
...
The cause
Аби побачити в яких саме модулях які версії провайдерів використовуються – виконуємо terraform providers, і отримуємо дерево залежностей з усіма версіями:
А помилка нам каже “given constraints >= 3.29.0, ~> 5.14, >= 5.92.0, >= 6.0.0“, тобто:
перша умова – версії вище 3.29.0
в третій умові маємо pessimistic constraint (“песимістичне обмеження”) – в “~> 5.14” дозволяємо будь-які версії від 5.14.0 до, але не включно 6.0.0, тобто патчі для 5.14, або версії 5.15.x і вище (див. Version Constraints)
а остання умова потребує >= 6.0.0 – версії 6 і вище
Умова ~> 5.14 у нас задана в головному модулі atlas_monitoring в versions.tf:
Тут варіант або апгрейднути hashicorp/aws в atlas_monitoring до 6 версії – але там були якісь breaking changes (і на які звернув увагу 🙂 ) і які треба було перевірити, тому на той момент не поспішав.
Інше рішення – просто виконати revert Pull Request merge з апгрейдом terraform-aws-modules/terraform-aws-lambda:
А потім вже спочатку оновити hashicorp/aws до 6 версії, а вже після нього – модуль з Lambda.
Але що там відбувається “під капотом”? Як і до чого застосовуються CustomResourceDefinition (CRD), і що таке, власне “оператор”?
І, врешті решт – в чому різниця між “Kubernetes Operator” та “Kubernetes Controller”?
В попередній частині – Kubernetes: Kubernetes API, API Groups, CRD та etcd – трохи копнули в те, як працює Kubernetes API і що таке CRD, а тепер можемо спробувати написати власний мікро-опертор, простенький MVP, і на його прикладі розібратись з деталями.
Kubernetes Controller vs Kubernetes Operator
Отже, в чому головна різниця між Controller та Operator?
What is: Kubernetes Controller
Якщо просто, то Controller – то просто якийсь сервіс, який моніторить ресурси в кластері, і приводить їхній стан у відповідність до того, як цей стан описаний в базі даних – etcd.
В Kubernetes ми маємо набір дефолтних контролерів – Core Controllers у складі Kube Controller Manager, такі як ReplicaSet Controller, який перевіряє кількість подів в Deployment на відповідність до значення replicas, або Deployment Controller, який контролює створення та оновлення ReplicaSets, чи PersistentVolume Controller та PersistentVolumeClaim Binder для роботи з дисками тощо.
Окрім цих дефолтних контролерів можемо створити власний контролер, або взяти існуючий – наприклад, ExternalDNS Controller. Це приклади кастомних контролерів (Custom Controllers).
Контролери працюють у control loop – циклічному процесі, в якому постійно перевіряють задані їм ресурси – або зміни вже існуючі ресурсів в системі, або реагують на додавання нових.
Під час кожної перевірки (reconciliation loop), Controller порівнює поточний стан (current state) ресурсу та порівнює його з бажаним станом (desired state) – тобто параметрами, заданими в його маніфесті при створенні або оновлені ресурсу.
Якщо desired стан не відповідає current state – то контролер виконує потрібні дії, аби ці стани узгодити.
What is: Kubernetes Operator
В свою чергу Kubernetes Operator – це такий собі “контролер на стероїдах”: фактично, Operator являє собою Custom Controller в тому сенсі, що він має власний сервіс у вигляді Pod, який комунікує з Kubernetes API для отримання та апдейту інформації про ресурси.
Але якщо звичайні контролери працюють з “дефолтними” типами ресурсів (Pod, Endpoint Slice, Node, PVC) – то для Operator ми описуємо власні, кастомні ресурси, використовуючи маніфест з Custom Resource.
А те, як ці ресурси будуть виглядати і які параметри мати – задаємо через CustomResourceDefinition які записуються в базу Kubernetes та додаються до Kubernetes API, і таким чином Kubernetes API дозволяє нашому кастомному Контролеру оперувати з цими ресурсами.
Тобто:
Controller – це компонент, сервіс, а Operator – це поєднання одного чи кількох кастомних Controller та відповідних CRD
Controller – реагує на зміну ресурсів, а Operator – додає нові типи ресурсів + контролер, який ці ресурси контролює
Kubernetes Operator frameworks
Існує кілька рішень, які спрощують створення операторів.
Основні – Kubebuilder, фреймворк для створення контролерів на Go, та Kopf – на Python.
Також є Operator SDK, який взагалі дозволяє працювати з контролерами навіть за допомогою Helm, без коду.
Я спочатку думав робити взагалі на “голому Go”, без фреймворків, аби краще зрозуміти, як усе працює під капотом – але цей пост почав перетворюватись на 95% Golang.
А так як основна ідея матеріалу була показати чисто концептуально що таке Kubernetes Operator, яку роль грають CustomResourceDefinitions та як вони один з одним взаємодіють і дозволяють керувати ресурсами – то все ж зупинився на Kopf, бо він дуже простий, і для цих цілей цілком підходить.
Створення CustomResourceDefinition
Почнемо з написання CRD.
Власне CustomResourceDefinition – це просто опис того, які поля у нашого кастомного ресурсу будуть, аби контролер міг їх використовувати через Kubernetes API для створення реальних ресурсів – будь то якісь ресурси в самому Kubernetes, чи зовнішні типу AWS Load Balancer чи AWS Route 53.
Що будемо робити: напишемо CRD, який буде описувати ресурс MyApp, і у цього ресурсу будуть поля для Docker image та кастомне поле з якимось текстом, який потім буде записувати в логи Kubernetes Pod.
spec.group: demo.rtfm.co.ua: створюємо нову API Group, всі ресурси цього типу будуть доступні за адресою /apis/demo.rtfm.co.ua/...
versions: список версій нового ресурсу
name.v1: будемо описувати тільки одну версію
served: true: додаємо новий ресурс в Kube API – можна робити kubectl get myapp (GET /apis/demo.rtfm.co.ua/v1/myapps)
storage: true: ця версія буде використовуватись для зберігання в etcd (якщо описується кілька версій – то тільки одна повинна бути із storage: true)
schema:
openAPIV3Schema: описуємо API-схему за стандартом OpenAPI v3
type: object: описуємо об’єкт із вкладеними полями (key: value)
properties: які поля у об’єкта будуть
spec: що ми зможемо використовувати у YAML-маніфестах при його створенні
type: object – описуємо наступні поля
properties:
image.type: string: Docker-образ
banner.type: string: наше кастомне поле, через яке ми будемо додавати якийсь запис в логах ресурсу
scope: Namespaced: всі ресурси цього типу будуть існувати в конкретному Kubernetes Namespace
names:
plural: myapps: ресурси будуть доступні через /apis/demo.rtfm.co.ua/v1/namespaces/<ns>/myapps/, і як ми зможемо “звертатись” до ресурсу (kubectl get myapp), використовується в RBAC де треба вказати resources: ["myapps"]
singular: myap: аліас для зручності
shortNames: [ma] короткий аліас для зручності
Запускаємо Minikube:
$ minikube start
Додаємо CRD:
$ kk apply -f myapp-crd.yaml
customresourcedefinition.apiextensions.k8s.io/myapps.demo.rtfm.co.ua created
Глянемо API Groups:
$ kubectl api-versions
...
demo.rtfm.co.ua/v1
...
І новий ресурс в цій API Group:
$ kubectl api-resources --api-group=demo.rtfm.co.ua
NAME SHORTNAMES APIVERSION NAMESPACED KIND
myapps ma demo.rtfm.co.ua/v1 true MyApp
ОК – ми створили CRD, і тепер можемо навіть створити CustomResource (CR).
Створюємо файл myapp-example-resource.yaml:
apiVersion: demo.rtfm.co.ua/v1 # matches the CRD's group and version
kind: MyApp # kind from the CRD's 'spec.names.kind'
metadata:
name: example-app # name of this custom resource
namespace: default # namespace (CRD has scope: Namespaced)
spec:
image: nginx:latest # container image to use (from our schema)
banner: "This pod was created by MyApp operator 🚀"
Деплоїмо:
$ kk apply -f myapp-example-resource.yaml
myapp.demo.rtfm.co.ua/example-app created
І перевіряємо:
$ kk get myapp
NAME AGE
example-app 15s
Але ніякий ресурсів типу Pod нема – бо у нас нема контролера, який буде працювати з цим типом ресурсів.
Створення Kubernetes Operator з Kopf
Отже, будемо використовувати Kopf, який буде створювати Kubernetes Pod, але використовуючи наш власний CRD.
import os
import kopf
import kubernetes
import yaml
# use kopf to register a handler for the creation of MyApp custom resources
@kopf.on.create('demo.rtfm.co.ua', 'v1', 'myapps')
# this function will be called when a new MyApp resource is created
def create_myapp(spec, name, namespace, logger, **kwargs):
# get image value from the spec of the CustomResource manifest
image = spec.get('image')
if not image:
raise kopf.PermanentError("Field 'spec.image' must be provided.")
# get optional banner value from the CR manifest spec
banner = spec.get('banner')
# load pod template YAML from file
path = os.path.join(os.path.dirname(__file__), 'pod.yaml')
with open(path, 'rt') as f:
pod_template = f.read()
# render pod YAML with provided values
pod_yaml = pod_template.format(
name=f"{name}-pod",
image=image,
app_name=name,
)
# create Pod difinition from the rendered YAML
# it uses PyYAML to parse the YAML string into a Python dictionary
# which can be used by Kubernetes API client
# it is used to create a Pod object in Kubernetes
pod_spec = yaml.safe_load(pod_yaml)
# inject banner as environment variable if provided
if banner:
# it is used to add a new environment variable into the container spec
container = pod_spec['spec']['containers'][0]
env = container.setdefault('env', [])
env.append({
'name': 'BANNER',
'value': banner
})
# create Kubernetes CoreV1 API client
# used to interact with the Kubernetes API
api = kubernetes.client.CoreV1Api()
try:
# it sends a request to the Kubernetes API to create a new Pod
# uses 'create_namespaced_pod' method to create the Pod in the specified namespace
# 'namespace' is the namespace where the Pod will be created
# 'body' is the Pod specification that was created from the YAML template
api.create_namespaced_pod(namespace=namespace, body=pod_spec)
logger.info(f"Pod {name}-pod created.")
except kubernetes.client.exceptions.ApiException as e:
logger.error(f"Failed to create pod {name}-pod: {e}")
Створюємо шаблон, який буде використовуватись нашим Оператором для створення ресурсів:
apiVersion: v1
kind: Pod
metadata:
name: {name}
labels:
app: {app_name}
spec:
containers:
- name: {app_name}
image: {image}
ports:
- containerPort: 80
env:
- name: BANNER
value: "" # will be overridden in code if provided
command: ["/bin/sh", "-c"]
args:
- |
if [ -n "$BANNER" ]; then
echo "$BANNER";
fi
exec sleep infinity
Запускаємо оператор з kopf run myoperator.py.
У нас вже є створений CustomResource, і Оператор має його побачити та створити Kubernetes Pod:
$ kopf run myoperator.py --verbose
...
[2025-07-18 13:59:58,201] kopf._cogs.clients.w [DEBUG ] Starting the watch-stream for customresourcedefinitions.v1.apiextensions.k8s.io cluster-wide.
[2025-07-18 13:59:58,201] kopf._cogs.clients.w [DEBUG ] Starting the watch-stream for myapps.v1.demo.rtfm.co.ua cluster-wide.
[2025-07-18 13:59:58,305] kopf.objects [DEBUG ] [default/example-app] Creation is in progress: {'apiVersion': 'demo.rtfm.co.ua/v1', 'kind': 'MyApp', 'metadata': {'annotations': {'kubectl.kubernetes.io/last-applied-configuration': '{"apiVersion":"demo.rtfm.co.ua/v1","kind":"MyApp","metadata":{"annotations":{},"name":"example-app","namespace":"default"},"spec":{"banner":"This pod was created by MyApp operator 🚀","image":"nginx:latest","replicas":3}}\n'}, 'creationTimestamp': '2025-07-18T09:55:42Z', 'generation': 2, 'managedFields': [{'apiVersion': 'demo.rtfm.co.ua/v1', 'fieldsType': 'FieldsV1', 'fieldsV1': {'f:metadata': {'f:annotations': {'.': {}, 'f:kubectl.kubernetes.io/last-applied-configuration': {}}}, 'f:spec': {'.': {}, 'f:banner': {}, 'f:image': {}, 'f:replicas': {}}}, 'manager': 'kubectl-client-side-apply', 'operation': 'Update', 'time': '2025-07-18T10:48:27Z'}], 'name': 'example-app', 'namespace': 'default', 'resourceVersion': '2955', 'uid': '8b674a99-05ab-4d4b-8205-725de450890a'}, 'spec': {'banner': 'This pod was created by MyApp operator 🚀', 'image': 'nginx:latest', 'replicas': 3}}
...
[2025-07-18 13:59:58,325] kopf.objects [INFO ] [default/example-app] Pod example-app-pod created.
[2025-07-18 13:59:58,326] kopf.objects [INFO ] [default/example-app] Handler 'create_myapp' succeeded.
...
Перевіряємо Pod:
$ kk get pod
NAME READY STATUS RESTARTS AGE
example-app-pod 1/1 Running 0 68s
Та його логи:
$ kk logs -f example-app-pod
This pod was created by MyApp operator 🚀
Отже, Оператор запустив Pod використовуючи наш CustomResource в якому взяв поле spec.banner зі рядком “This pod was created by MyApp operator 🚀“, і виконав в поді command /bin/sh -c " $BANNER".
Шаблони ресурсів – Kopf та Kubebuilder
Замість того, аби мати окремий файл pod-template.yaml ми могли б все описати прямо в коді оператора.
А у випадку з Kubebuilder зазвичай створюється функція, яка використовує маніфест CustomResource (cr *myappv1.MyApp) і формує об’єкт типу *corev1.Pod використовуючи Go-структури corev1.PodSpec та corev1.Container:
...
// newPod is a helper function that builds a Kubernetes Pod object
// based on the custom MyApp resource. It returns a pointer to corev1.Pod,
// which is later passed to controller-runtime's client.Create(...) to create the Pod in the cluster.
func newPod(cr *myappv1.MyApp) *corev1.Pod {
// `cr` is a pointer to your CustomResource of kind MyApp
// type MyApp is generated by Kubebuilder and lives in your `api/v1/myapp_types.go`
// it contains fields like cr.Spec.Image, cr.Spec.Banner, cr.Name, cr.Namespace, etc.
return &corev1.Pod{
// corev1.Pod is a Go struct representing the built-in Kubernetes Pod type
// it's defined in "k8s.io/api/core/v1" package (aliased here as corev1)
// we return a pointer to it (`*corev1.Pod`) because client-go methods like
// `client.Create()` expect pointer types
ObjectMeta: metav1.ObjectMeta{
// metav1.ObjectMeta comes from "k8s.io/apimachinery/pkg/apis/meta/v1"
// it defines metadata like name, namespace, labels, annotations, ownerRefs, etc.
Name: cr.Name + "-pod", // generate Pod name based on the CR's name
Namespace: cr.Namespace, // place the Pod in the same namespace as the CR
Labels: map[string]string{ // set a label for identification or selection
"app": cr.Name, // e.g., `app=example-app`
},
},
Spec: corev1.PodSpec{
// corev1.PodSpec defines everything about how the Pod runs
// including containers, volumes, restart policy, etc.
Containers: []corev1.Container{
// define a single container inside the Pod
{
Name: cr.Name, // use CR name as container name (must be DNS compliant)
Image: cr.Spec.Image, // container image (e.g., "nginx:1.25")
Env: []corev1.EnvVar{
// corev1.EnvVar is a struct that defines environment variables
{
Name: "BANNER", // name of the variable
Value: cr.Spec.Banner, // value from the CR spec
},
},
Command: []string{"/bin/sh", "-c"},
// override container ENTRYPOINT to run a shell command
Args: []string{
// run a command that prints the banner and sleeps forever
// fmt.Sprintf(...) injects the value at runtime into the string
fmt.Sprintf(`echo "%s"; exec sleep infinity`, cr.Spec.Banner),
},
// optional: could also add ports, readiness/liveness probes, etc.
},
},
},
}
}
...
А як в реальних операторах?
Але це ми робили для”внутрішніх” ресурсів Kubernetes.
Як щодо зовнішніх ресурсів?
Тут просто приклад – не тестував, але загальна ідея така: просто беремо SDK (в прикладі з Python це буде boto3), і використовуючи поля з CustomResource (наприклад, subnets або scheme), виконуємо відповідні API-запити до AWS через SDK.
import kopf
import boto3
import botocore
import logging
# create a global boto3 client for AWS ELBv2 service
# this client will be reused for all requests from the operator
# NOTE: region must match where your subnets and VPC exist
elbv2 = boto3.client("elbv2", region_name="us-east-1")
# define a handler that is triggered when a new MyIngress resource is created
@kopf.on.create('demo.rtfm.co.ua', 'v1', 'myingresses')
def create_ingress(spec, name, namespace, status, patch, logger, **kwargs):
# extract the list of subnet IDs from the CustomResource 'spec.subnets' field
# these subnets must belong to the same VPC and be public if scheme=internet-facing
subnets = spec.get('subnets')
# extract optional scheme (default to 'internet-facing' if not provided)
scheme = spec.get('scheme', 'internet-facing')
# validate input: at least 2 subnets are required to create an ALB
if not subnets:
raise kopf.PermanentError("spec.subnets is required.")
# attempt to create an ALB in AWS using the provided spec
# using the boto3 ELBv2 client
try:
response = elbv2.create_load_balancer(
Name=f"{name}-alb", # ALB name will be derived from CR name
Subnets=subnets, # list of subnet IDs provided by user
Scheme=scheme, # 'internet-facing' or 'internal'
Type='application', # we are creating an ALB (not NLB)
IpAddressType='ipv4', # only IPv4 supported here (could be 'dualstack')
Tags=[ # add tags for ownership tracking
{'Key': 'ManagedBy', 'Value': 'kopf'},
]
)
except botocore.exceptions.ClientError as e:
# if AWS API fails (e.g. invalid subnet, quota exceeded), retry later
raise kopf.TemporaryError(f"Failed to create ALB: {e}", delay=30)
# parse ALB metadata from AWS response
lb = response['LoadBalancers'][0] # ALB list should contain exactly one entry
dns_name = lb['DNSName'] # external DNS of the ALB (e.g. abc.elb.amazonaws.com)
arn = lb['LoadBalancerArn'] # unique ARN of the ALB (used for deletion or listeners)
# log the creation for operator diagnostics
logger.info(f"Created ALB: {dns_name}")
# save ALB info into the CustomResource status field
# this updates .status.alb.dns and .status.alb.arn in the CR object
patch.status['alb'] = {
'dns': dns_name,
'arn': arn,
}
# return a dict, will be stored in the finalizer state
# used later during deletion to clean up the ALB
return {'alb-arn': arn}
У випадку з Go і Kubebuilder – використовували б бібліотеку aws-sdk-go:
import (
"context"
"fmt"
elbv2 "github.com/aws/aws-sdk-go-v2/service/elasticloadbalancingv2"
"github.com/aws/aws-sdk-go-v2/aws"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
networkingv1 "k8s.io/api/networking/v1"
)
func newALB(ctx context.Context, client *elbv2.Client, cr *networkingv1.Ingress) (string, error) {
// build input for the ALB
input := &elbv2.CreateLoadBalancerInput{
Name: aws.String(fmt.Sprintf("%s-alb", cr.Name)),
Subnets: []string{"subnet-abc123", "subnet-def456"}, // replace with real subnets
Scheme: elbv2.LoadBalancerSchemeEnumInternetFacing,
Type: elbv2.LoadBalancerTypeEnumApplication,
IpAddressType: elbv2.IpAddressTypeIpv4,
Tags: []types.Tag{
{
Key: aws.String("ManagedBy"),
Value: aws.String("MyIngressOperator"),
},
},
}
// create ALB
output, err := client.CreateLoadBalancer(ctx, input)
if err != nil {
return "", fmt.Errorf("failed to create ALB: %w", err)
}
if len(output.LoadBalancers) == 0 {
return "", fmt.Errorf("ALB was not returned by AWS")
}
// return the DNS name of the ALB
return aws.ToString(output.LoadBalancers[0].DNSName), nil
}
Маємо Helm-чарт VictoriaLogs, в якому заданий PVC з розміром в 30 GB, якого нам стало вже замало, і його треба збільшити.
Але проблема полягає в тому, що .spec.volumeClaimTemplates[*].spec.resources.requests.storage в STS являється immutable, тобто ми не можемо просто змінити size через values.yaml, бо це призведе до помилки “Forbidden: updates to statefulset spec for fields other than ‘replicas’, ‘ordinals’, ‘template’, ‘updateStrategy’, ‘revisionHistoryLimit’, ‘persistentVolumeClaimRetentionPolicy’ and ‘minReadySeconds’ are forbidden“.
Якби замість STS був тип Deployment – то в чарті VictoriaLogs це призвело б до створення окремого PVC – pvc.yaml.
Можна було б просто самому створити окремий PVC, і підключати його через value existingClaim, аде PersistentVolume вже є, створювати новий і переносити дані не хочеться (хоча при потребі – можна, див. VictoriaMetrics: міграція даних VMSingle та VictoriaLogs між кластерами Kubernetes, але буде даунтайм), тому подивимось, як ми можемо це вирішити інакше – без видалення Pods і без зупинки сервісу.
storageClassName та AllowVolumeExpansion
storageClass, який використовується для створення Persistent Volume має підтримувати AllowVolumeExpansion – див. Volume expansion:
В volumeClaimTemplates задаємо storageClassName та розмір 1 гігабайт.
Деплоїмо:
$ kk apply -f test-sts-pvc.yaml
statefulset.apps/demo-sts created
Перевіряємо PVC:
$ kk get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
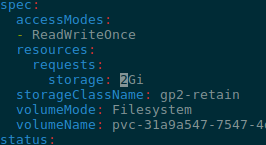
data-demo-sts-0 Bound pvc-31a9a547-7547-4d34-bb2d-2c7015b9e0f3 1Gi RWO gp2-retain <unset> 15s
Тепер, якщо ми захочемо збільшити розмір через volumeClaimTemplates з 1Gi до 2Gi:
$ kk apply -f test-sts-pvc.yaml
The StatefulSet "demo-sts" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'ordinals', 'template', 'updateStrategy', 'revisionHistoryLimit', 'persistentVolumeClaimRetentionPolicy' and 'minReadySeconds' are forbidden
Note: перед змінами в дисках – не забуваємо про бекапи!
Редагуємо PVC вручну – міняємо resources.requests.storage з 1Gi на 2Gi:
Перевіряємо Events цього PVC:
$ kk describe pvc data-demo-sts-0
...
Normal ExternalExpanding 40s volume_expand CSI migration enabled for kubernetes.io/aws-ebs; waiting for external resizer to expand the pvc
Normal Resizing 40s external-resizer ebs.csi.aws.com External resizer is resizing volume pvc-31a9a547-7547-4d34-bb2d-2c7015b9e0f3
Normal FileSystemResizeRequired 35s external-resizer ebs.csi.aws.com Require file system resize of volume on node
І ще через кілька секунд – готово:
...
Normal FileSystemResizeSuccessful 19s kubelet
Перевіряємо CAPACITY:
$ kk get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
data-demo-sts-0 Bound pvc-31a9a547-7547-4d34-bb2d-2c7015b9e0f3 2Gi RWO gp2-retain <unset> 4m7s
2Gi, все ОК.
І в самому Pod тепер теж маємо 2 гігабайти:
$ kk exec -ti demo-sts-0 -- df -h /data
Filesystem Size Used Available Use% Mounted on
/dev/nvme7n1 1.9G 24.0K 1.9G 0% /data
Але якщо ми спробуємо задеплоїти зміни в volumeClaimTemplates.spec.resources.requests.storage ще раз – все одно будемо ловити помилку:
$ kk apply -f test-sts-pvc.yaml
The StatefulSet "demo-sts" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'ordinals', 'template', 'updateStrategy', 'revisionHistoryLimit', 'persistentVolumeClaimRetentionPolicy' and 'minReadySeconds' are forbidden
Тому видаляємо сам STS, але залишаємо всі його dependent об’єкти:
Взагалі почав писати створення власного Kubernetes Operator, але вирішив винести окремо тему про те, що таке власне Kubernetes CustomResourceDefinition, і як створення CRD взагалі працює на рівні Kubernetes API та etcd.
Тобто, почати з того, як власне Kubernetes працює з ресурсами, і що відбувається, коли ми створюємо чи редагуємо ресурси.
Отже, вся комунікація з Kubernetes Control Plane відбувається через його головний ендпоінт – Kubernetes API, який являє собою компонент Kubernetes Control Plane – див. Cluster Architecture.
Через API ми комунікуємо з Kubernetes, а всі ресурси та інформація по ним зберігаються в базі даних – etcd.
Інші компоненти Control Plane – це Kube Controller Manager з набором дефолтних контролерів, які відповідають за роботу з ресурсами, та Scheduler, що відповідає за те, як ресурси будуть розміщатись на Worker Nodes.
Kubernetes API – це звичайний HTTPS REST API, до якого ми можемо звернутись навіть з curl.
Для доступу до кластеру можемо використати kubectl proxy, який візьме параметри з ~/.kube/config з адресою API Server та токеном, і створить тунель до нього.
В мене є налаштований доступ до AWS EKS – тому підключення піде до нього:
$ kubectl proxy --port=8080
Starting to serve on 127.0.0.1:8080
Власне, що ми бачимо – це список API endpoints, які підтримує Kubernetes API:
/api/: інформація по самому Kubernetes API та точка входу до core API Groups (див. далі)
/api/v1: core API group з Pods, ConfigMaps, Services, etc
/apis/: APIGroupList – решта API Groups в системі та їх версії, в тому числі і API Groups, створені з різних CRD
наприклад, для API Group operator.victoriametrics.com можемо бачити підтримку двох версій – “operator.victoriametrics.com/v1″ “operator.victoriametrics.com/v1beta1“
/version: інформація по версії кластера
Ну і далі вже можемо піти глибше, і подивитись що всередині кожного ендпоінту, наприклад – отримати інформацію про всі Pods в кластері:
Тут бачимо інформацію про Pod з іменем “backend-ws-deployment-6db58cc97c-k56lm“, який живе в Kubernetes Namespace “staging-backend-api-ns“, і решту інформації про нього – volumes, які в цьому поді контейнери, ресурси і т.д.
Kubernetes API Groups та Kind
API Groups – це спосіб організації ресурсів у Kubernetes. Вони групуються за групами, версіями та типами ресурсів (Kind).
Тобто структура API:
API Group
versions
kind
Наприклад, в /api/v1 ми бачимо Kubernetes Core API Group, в /apis – API Groups apps, batch, events і так далі.
Структура буде такою:
/apis/<group> – сама група та її версії
/apis/<group>/<version> – конкретна версія групи вже з конкретними resources (Kind)
/apis/<group>/<version>/<resource> – доступ до конкретного ресурсу та об’єктів в ньому
Note: Kind vs resource: Kind – це назва ресурсу, яка задається в schema цього ресурсу. А resource – це ім’я, яке використовується при побудові URI при запиті до API Server.
Окей, ми звернулись до API – але звідки він бере всі ті дані, що нам відображаються?
Kubernetes та etcd
Для зберігання даних в Kubernetes маємо ще один ключовий компонент Control Plane – etcd.
Власне це просто key:value база даних з усіма даними, які і формують наш кластер – всі його налаштування, вся ресурси, всі стани цих ресурсів, RBAC-групи тощо.
Коли Kubernetes API Server отримує запит, наприклад – POST /apis/apps/v1/namespaces/default/deployments – він спершу перевіряє відповідність обʼєкта до схеми ресурсу (валідація), і тільки після цього зберігає його в etcd.
База etcd складається з набору ключів. Наприклад Pod з іменем “nginx-abc” буде зберігатись в ключі з іменем /registry/pods/default/nginx-abc.
В AWS EKS ми доступу до etcd не маємо (і це добре), але можемо запустити Minikube, і трохи подивитись там:
$ minikube start
...
🏄 Done! kubectl is now configured to use "minikube" cluster and "default" namespace by default
Перевіряємо системні поди:
$ kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
coredns-674b8bbfcf-68q8p 0/1 ContainerCreating 0 57s
etcd-minikube 1/1 Running 0 62s
...
Підключаємось в кластер:
$ minikube ssh
Якби ми використовували minikube start --driver=virtualbox – то з minikube ssh зайшли в інстанс VirtualBox.
Але так як у нас дефолтний драйвер docker – то просто заходимо в контейнер minikube.
Дані в ключах зберігаються в форматі Protobuf (Protocol Buffers), тому при звичайному etcdctl get KEY дані будуть виглядати трохи криво.
Глянемо, що є в базі про Pod самого etcd:
docker@minikube:~$ sudo ETCDCTL_API=3 etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/var/lib/minikube/certs/etcd/ca.crt --cert=/var/lib/minikube/certs/etcd/server.crt --key=/var/lib/minikube/certs/etcd/server.key get "/registry/pods/kube-system/etcd-minikube"
Результат:
Окей.
CustomResourceDefinitions та Kubernetes API
Отже, коли ми створюємо CRD – ми розширюємо Kubernetes API, створюючи власну API Group з власним ім’ям, версією та новим типом ресурсу (Kind), який описується в CRD.
використовуємо існуючу API Group apiextensions.k8s.io і версію v1
з неї беремо схему об’єкту CustomResourceDefinition
і на основі цієї схеми – створюємо власну API Group з ім’ям mycompany.com
в цій API Group описуємо єдиний тип ресурсу – kind: MyApp
і одну версію – v1
далі з openAPIV3Schema описуємо схему нашого ресурсу – які у нього поля, їхні типи, тут жеж можна задати дефолтні значення (див. OpenAPI Specification)
З цим CRD ми зможемо створювати нові Custom Resources з маніфестом, в якому передамо поля apiVersion, kind, та spec.image – зі schema.openAPIV3Schema.properties.spec.properties.image нашого CRD:
apiVersion: mycompany.com/v1
kind: MyApp
metadata:
name: example
spec:
image: nginx:1.25
Створюємо CRD:
$ kk apply -f test-crd.yaml
customresourcedefinition.apiextensions.k8s.io/myapps.mycompany.com created
Перевіряємо в Kubernetes API (можна з селектором | jq '.groups[] | select(.name == "mycompany.com")'):
Тут в ключі /registry/apiextensions.k8s.io/customresourcedefinitions/myapps.mycompany.com зберігається інформація про сам новий CRD – структура CRD, її OpenAPI schema, версії, etc, а в /registry/apiregistration.k8s.io/apiservices/v1.mycompany.com – реєструється API Service для цієї групи для доступу до групи через Kubernetes API.
Ну і звісно, ми можемо побачити CRD з kubectl`:
$ kk get crd
NAME CREATED AT
myapps.mycompany.com 2025-07-12T11:23:19Z
Створюємо сам CustomResource з маніфесту, що бачили вище:
$ kk apply -f test-resource.yaml
myapp.mycompany.com/example created
Але це поки що просто дані в etcd – ніяких реальних ресурсів по типу Pods у нас нема, бо нема контролера, який оброблює ресурси з Kind: MyApp.
Note: трохи забігаючи наперед до наступного поста: власне, Kubernetes Operator – це і є набір CRD та контролер, який “контролює” ресурси з заданими Kind
Kubernetes API Service
Колими додаємо новий CRD – Kubernetes має не тільки створити новий ключ в etcd із новою API Group та схемою відповідних ресурсів, але й додати новий ендпоінт до свої маршрутів – як ми це робимо в Python з @app.get("/") в FastAPI – для того, аби API-сервер знав, що на запит GET /apis/mycompany.com/v1/myapps повертати ресурси саме цього типу.
Відповідний API Service буде в собі містити spec з групою та версією:
Тобто коли ми створюємо новий CRD – Kubernetes API Server створює API Service (записуючи його до /registry/apiregistration.k8s.io/apiservices/v1.mycompany.com), і додає до свого до своїх роутів в ендпоінт /apis.
І от тепер, маючи уявлення про те, як виглядає API та база даних, яка всі ресурси зберігає – ми можемо перейти до створення CRD та контролера, тобто – власне, написати сам Operator.
...
{"logger":"controller-runtime.source.EventHandler","msg":"if kind is a CRD, it should be installed before calling Start","kind":"VMAnomaly.operator.victoriametrics.com","error":"no matches for kind \"VMAnomaly\" in version \"operator.victoriametrics.com/v1\""}
...
{"logger":"setup","msg":"cannot setup manager","error":"cannot start controller manager: failed to wait for vmanomaly caches to sync kind source: *v1.VMAnomaly: timed out waiting for cache to be synced for
Kind *v1.VMAnomaly"}
...
Скоріш за все через додавання нового ресурсу VMAnomaly в v0.60.0 оператора.
Але “так історично склалося”, що CRD у нас вже встановлені вручну (може, тоді не було окремого чарту?), тому найпростіший варіант – просто оновити їх напрямую з файлу:
$ kk apply -f https://raw.githubusercontent.com/VictoriaMetrics/helm-charts/refs/heads/master/charts/victoria-metrics-operator/charts/crds/crds/crd.yaml
...
customresourcedefinition.apiextensions.k8s.io/vmanomalies.operator.victoriametrics.com created
...
Перевіряємо CRD в кластері тепер:
$ kk get crd | grep anomal
vmanomalies.operator.victoriametrics.com 2025-07-09T14:27:43Z
Не зважаючи на те, що про зміни було повідомлено в листах від Arch Linux – чомусь дуже у багатьох виникли проблеми з останнім апдейтом: в сабредітах по Arch Linux на Reddit прям через один топік питають “Аааа, в мене все зламалось, що робити?!?”.
Глянемо як все ж завершити апгрейд, і що саме мінялось.
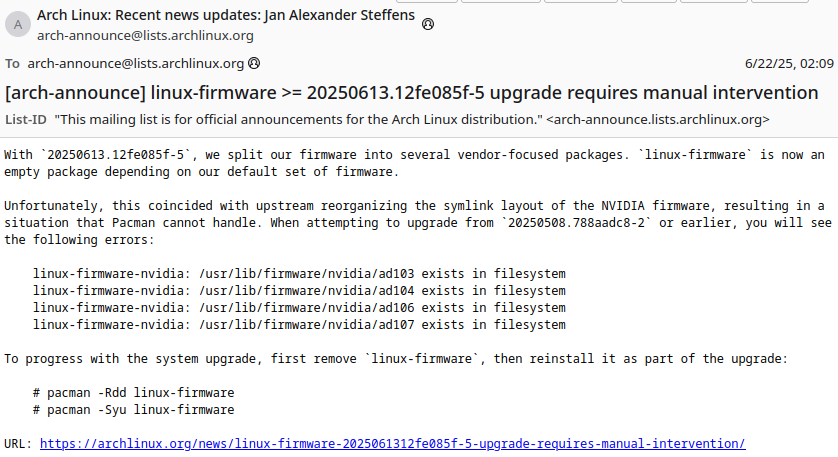
The issue: linux-firmware exists in filesystem
Власне, помилка виглядає так:
$ sudo pacman -Syu
...
(363/363) checking for file conflicts [############################################################################################] 100%
error: failed to commit transaction (conflicting files)
linux-firmware-nvidia: /usr/lib/firmware/nvidia/ad103 exists in filesystem
linux-firmware-nvidia: /usr/lib/firmware/nvidia/ad104 exists in filesystem
linux-firmware-nvidia: /usr/lib/firmware/nvidia/ad106 exists in filesystem
linux-firmware-nvidia: /usr/lib/firmware/nvidia/ad107 exists in filesystem
Errors occurred, no packages were upgraded.
With 20250613.12fe085f-5, we split our firmware into several vendor-focused packages. linux-firmware is now an empty package depending on our default set of firmware.
І явно вказано, що треба зробити – просто перевстановити пакет linux-firmware.
Видаляємо існуючий:
$ sudo pacman -Rdd linux-firmware
І встановлюємо заново:
$ sudo pacman -Syu linux-firmware
The cause: what was changed?
А що в новому пакеті? Що змінилось?
Сам пакет linux-firmware містить необхідні файли для роботи hardware, але які не включені в ядро Linux чи в ISO-образ Arch Linux.
Як говориться в листі – тепер замість єдиного пакета з усіма файлами – він буде розбитий на кілька різних, “vendor-focused packages“.
Версія (чи “тег”?) нового пакету – 20250627, а старого – 20250508.
Можна глянути що саме було встановлено з останнім апдейтом:
Як саме resources.requests та resources.limits в Kubernetes manifest працюють “під капотом”, і як саме Linux буде виділяти та обмежувати ресурси для контейнерів?
Отже, Kubernetes для Pod ми можемо задати два основні параметри для CPU та Memory – spec.containers.resources.requests та spec.containers.resources.limits:
resources.requests: впливає на те, як і де Pod буде створено, і скільки ресурсів гарантовано він отримає
resources.limits: впливає на те, скільки ресурсів максимум він може споживати
якщо resources.limits.memory більше ліміту – под може бути вбито з OOMKiller, якщо на WorkerNode недостатньо вільної пам’яті (Node memory pressure)
якщо resources.limits.cpu більше ліміту – то включиться режим CPU throttling
Якщо з Memory все доволі зрозуміло – задаємо кількість байт, то з CPU все трохи цікавіше.
Тож спершу давайте глянемо на те, як ядро Linux взагалі планує те, скільки CPU time буде приділятись кожному процесу завдяки механізму Control Groups.
Linux cgroups
Linux Control Groups (cgroups) – один з двох основних механізмів ядра, які забезпечують ізоляцію і контроль над процесами:
Linux namespaces: створюють ізольований простір імен з власним деревом процесів (PID Namespace), мережевими інтерфейсами (net namespace), User IDs (User namespace) і так далі – див. What is: Linux namespaces, примеры PID и Network namespaces
Linux cgroups: механізм контролю ресурсів процесами – скільки пам’яті, CPU, мережевих ресурсів та дискових I/O операцій буде доступно процесу
Groups в назві – бо всі процеси об’єднані в групи у вигляді дерева – parent-child tree.
Тому якщо для parent-процесу заданий ліміт в 512 мегабайт – то сума доступної пам’яті його і його потомків не може бути вища за 512 МБ.
Всі групи задані в каталозі /sys/fs/cgroup/, який підключається окремим типом файлової системи – cgroup2:
$ mount | grep cgro
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
cgroups є більш старої версії 1, та нової – 2, див. man cgroups.
По факту, cgroups v2 вже є новим стандартом, тому говорити будемо про неї – але cgroups v1 все ще присутній, коли ми говоримо про Kubernetes.
Перевірити версію можна за допомогою stat і каталога /sys/fs/cgroup/:
$ stat -fc %T /sys/fs/cgroup/
cgroup2fs
Якщо тут буде tmpfs – то це cgroups v1.
Каталог /sys/fs/cgroup/
Типовий вигляд директорії на Linux-хості – тут приклад з мого домашнього ноутбука з Arch Linux:
CPU та Memory в cgroups, та cgroups v1 vs cgroups v2
Отже, в cgroup для всього слайсу задаються параметри того, скільки CPU та Memory процеси цієї групи можуть використовувати (тут і далі будемо говорити тільки про CPU та Memory).
Наприклад, для мого юзера setevoy (з ID 1000) маємо файли cpu.max та memory.max:
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/cpu.max
max 100000
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/memory.max
max
cpu.max в cgroups v2 замінив cpu.cfs_quota_us і cpu.cfs_period_us з cgroup v1
Тут в cpu.max маємо налаштування того, скільки часу CPU буде приділятись процесам мого юзера.
Формат файлу – <quota> <period>, де <quota> – це доступний процесу (чи групі) час, а <period> – тривалість одного періоду в мікросекундах (100.000 мкс = 100 мс).
В cgroups v1 ці значення задавались в cpu.cfs_quota – для <quota> в v2, та cpu.cfs_period_us – для <period> у v2.
Тобто в файлі вище бачимо:
max: доступний весь час
100000 мкс = 100 мс, один CPU period
CPU period тут – це інтервал часу, протягом якого Linux ядро перевіряє, скільки процеси у cgroup використали CPU: якщо групі заданий ліміт (quota), і процеси його вичерпали – то вони будуть призупинені до завершення поточного period (CPU throttling).
Тобто якщо для процесу заданий ліміт в 50.000 (50 мс) при period в 100.000 мікросекунд (100 мс) – то процеси можуть використати тільки 50 мс у кожному 100 мс “вікні”.
Використання пам’яті можна побачити у файлі memory.current:
В Kubernetes показники cpu.max та memory.max будуть визначатись, коли ми задаємо resources.limits.cpu та resources.limits.memory.
Чому “Kubernetes CPU Limits – погана ідея”?
Дуже часто можна зустріти згадку про те, що задавати ліміти на CPU в Kubernetes – погана ідея.
Чому так?
Бо якщо ми задаємо ліміт (тобто значення != max в cpu.max) – то коли група процесів використає свій час в поточному вікні CPU Time – то ці процеси будуть обмежені навіть попри те, що загалом CPU має можливість виконати запити.
Тобто, навіть якщо в системі є вільні ядра, але cgroup уже вичерпала свій cpu.max у поточному періоді – процеси цієї групи будуть призупинені до завершення періоду (CPU throttling) незалежно від загального навантаження системи.
Вище бачили cpu.max, де для мого юзера дозволяється використовувати весь доступний CPU час за кожен CPU-період.
Але якщо обмеження не встановлено (тобто max), і кілька груп процесів хочуть доступ до CPU одночасно – то ядро має вирішити кому виділити більше CPU time.
Для цього в cgroups задається ще один параметр – cpu.weight (у cgroups v2) або cpu.shares (у cgroups v1): це відносний пріоритет групи процесів при визначенні черги доступу до CPU.
Значення cpu.weight враховується Linux CFS (Completely Fair Scheduler), щоб розподілити CPU пропорційно між кількома cgroup. – див. CFS Scheduler та Process Scheduling in Linux.
Діапазон значень тут – від 1 до 10.000, де 1 – мінімальний пріорітет, а 10.000 – максимальний. Значення 100 – дефолтне.
Чи пріорітет вищий – тим більше часу CFS буде виділяти процесам цієї групи.
Але це враховується тільки коли є гонка за часом CPU: коли процесор вільний, то всі процеси отримують стільки CPU time, скільки їм потрібно.
В Kubernetes показник cpu.weight буде визначатись із resources.requests.cpu.
А от значення resources.requests.memory впливає тільки на Kubernetes Scheduler для вибору Kubernetes WorkerNode для пошуку ноди, на якій є достатньо вільної пам’яті.
cpu.weight vs process nice
Окрім cpu.weight/cpu.shares маємо ще process nice, який задає пріорітет задачі.
Різниця між ними в тому, що cpu.weight задаються на рівні cgroup – а nice на рівні конкретного процесу всередині однієї групи.
І якщо більше значення в cpu.weight вказує на більший пріорітет, то з nice навпаки – чим нижче значення nice (від -19 до 20 максимум) – тим більше часу буде виділено процесу.
Якщо обидва процеси в одній cgroup, але з різним nice – то буде враховуватись nice.
А якщо це різні cgroup – то буде враховуватись саме cpu.weight.
Тобто, cpu.weight визначає яка група процесів важливіша для ядра, а nice – який саме процес в групі має пріорітет.
Linux cgroups Summary
Отже, кожна Control Group визначає те, скільки CPU та пам’яті буде виділятись процесу.
cpu.max: визначає скільки часу від кожного CPU period група процесів може витратити
в Kubernetes manifest значення в resources.limits.cpu та resources.limits.memory впливають на налаштування cpu.max та memory.max для cgroup відповідних контейнерів
memory.max: скільки пам’яті можна використати без ризику потрапити під Oout of Memory Killer
в Kubernetes manifest значення resources.requests.memory впливає тільки на Kubernetes Scheduler для вибору Kubernetes WorkerNode
cpu.weight: визначає пріорітет групи процесів при навантаженому CPU
в Kubernetes manifest значення в resources.requests.cpu впливає на налаштування cpu.weight для cgroup відповідних контейнерів
Kubernetes Pod resources та Linux cgroups
ОК, тепер, як розібрались з cgroups в Linux – давайте детальніше глянемо на те, як значення в Kubernetes resources.requests та resources.limits впливають на контейнери.
Коли ми задаємо spec.container.resources в Deployment чи Pod, і Pod створюються на WorkerNode – то kubelet на цій ноді отримує значення зі PodSpec, і передає їх до Container Runtime Interface (CRI) (ContainerD чи CRI-O).
CRI перетворює їх в специфікацію контейнера в JSON, в якому вказує відповідні значення для cgroup цього контейнеру.
Kubernetes CPU Unit vs cgroup CPU share
В маніфестах Kubernetes ресурси CPU ми задаємо в CPU units: 1 юніт == 1 повне CPU ядро – фізичне чи віртуальне, див. CPU resource units.
1 millicpu або millicores – це 1/1000 від одного ядра CPU.
Один Kubernetes CPU Unit – це 1024 CPU shares у відповідній Linux cgroup.
Тобто: 1 Kubernetes CPU Unit == 1000 millicpu == 1024 CPU shares у cgroup.
Крім того, є нюанс з тим, як саме Kubernetes рахує cpu.weight для Pods – бо Kubernetes використовує CPU shares, які потім переводить в cpu.weight для cgroup v2 – далі побачимо, як це виглядає.
cpu.shares 1024 – це значення, яке ми задали в Kubernetes, коли вказали resources.requests.cpu == “1”, бо, як говорилось вище – “Один Kubernetes CPU Unit – це 1024 CPU shares”.
Тобто, для cgroups v1 – у файлі cpu.shares ми б мали значення 1024.
Але з cgroup v 2 трохи цікавіше.
“Під капотом” в Kubernetes все одно рахується CPU Shares у форматі 1 ядро == 1024 shares, які потім транслюються в формат cgroups v2.
Якщо ми глянемо загальний cpu.weights для всього слайсу kubepods.slice – то там буде значення 76:
Складно в одному пості описати те, про що написані тисячі книжок на тисячу сторінок, але сьогодні спробуємо швиденько розглянути основи того, як відбувається комунікація між хостами в мережі.
Спочатку згадаємо про моделі OSI та TCP/IP, потім про структуру пакетів, встановлення підключень, і в кінці – заглянемо “під капот” Linux – подивимось на сокети і Linux TCP stack.
В основному увага буде саме TCP, бо це те, з чим ми найчастіше маємо справу.
What is: The TCP/IP
Отже, TCP/IP включає в себе два основних поняття:
по-перше, це стек протоколів (стандартів, наборів правил) комунікації – TCP (Transmisstion Control Protocol) Та IP (Internet Protocol): вони описують те, яким чином встановлюються з’єднання між хостами та сервісами в Інтернеті. Ці протоколи стандартизовані і описані у відповідних RFC (TCP – RFC: 793, IP – RFC: 791)
крім того, TCP/IP – це модель комунікації, яка включає в себе кілька рівнів – подібно до моделі OSI (і який теж описаний в Informational RFC – RFC 1180)
Загальна модель OSI
Модель OSI (Open Systems Interconnection model), розроблена та стандартизована ISO (International Organization for Standardization) у 1984 році – див. ISO/IEC 35.100.
Колись писав про це у схожому пості – What is: модель OSI, але то було давно, і без детального опису TCP/IP.
Отже, основна ідея моделі: будь-яке з’єднання в мережі проходить через кілька рівнів комунікації, де кожен рівень відповідає лише за свою задачу і не має доступу до логіки роботи інших рівнів – це називається Layer isolation.
При передачі даних між рівнями використовується принцип Encapsulation – кожен рівень “загортає” пакет даних у власну “обгортку” – додає власні заголовки до пакету, не змінюючи вміст попереднього рівня.
Якщо дуже спрощено, то процес можна відобразити так:
коли наш браузер формує якийсь HTTP-запит – це відбувається на самому верхньому рівні, Application layer
цей запит передається нижче, до Transport layer, де дані від браузера інкапсулюються (encapsulation): до даних з Application layer додаються заголовки з Transport layer – TCP headers
потім, ще нижче – на Network layer додається IP-заголовок, що вказує адресу відправника й одержувача
і нарешті, на Link layer формується Ethernet frame, який і передається через Physical layer
На приймаючій стороні (наприклад, EC2 інстанс з NGINX) все відбувається у зворотньому напрямку – decapsulation: кожен рівень знімає свою обгортку й передає payload вищому рівню.
Непогана діаграма є в OSI Model Explained (хоча тут HTTP header відображено навпроти Session layer – але це відбувається на Application layer):
PDU (Protocol Data Unit)
Крім того, коли ми говоримо “пакет” маючи на увазі дані – то технічно на кожному рівні моделі OSI ці дані називаються по-різному, а загальна назва для них – PDU (Protocol Data Unit):
Note: хоча на цій схемі теж є неточності, наприклад SQL – це мова запитів на Application layer
Тобто:
Application, Presentation, Session рівні – це просто Data
Transport layer (рівень 4) – це Segment (в TCP) або Datagram (UDP)
Network layer – Packet (наприклад, IP-пакет, в якому може бути TCP-сегмент)
Data Link layer – оперує Frames
Physical layer – це вже біти, 0 та 1
Процес передачі даних від браузера до web-серверу з TLS
Давайте детальніше глянемо на те, як відбувається процес передачі даних:
Layer 7 – Application layer:
браузеру треба відправити дані – payload
він оперує на Application layer, і формується HTTP-запит з HTTP headers (аутентифікація, кешування, сам запит до потрібного ресурсу – URI, та куди запит йде – URL)
тут встановлюється HTTP-сесія – через cookies, JWT-токен, параметри URL тощо
сформовані дані передаються до Presentation Layer
Layer 6 – Presentation Layer:
якщо використовується шифрування, то тут підключаться бібліотеки SSL/TLS і шифрують дані
додаються TLS headers
при потребі виконується перетворення даних, наприклад кодування символів (ASCII, UTF-8)
тут формується TCP-сегмент (або datagram для UDP, втім тут ми розглядаємо браузер та HTTP, тому TCP): до даних від вищих рівнів (наприклад, браузера) додаються TCP headers – Source port, Destination port, порядковий Sequence number – номер пакету (див Multiplexing and Demultiplexing in Transport Layer)
задаються TCP flags – ACK, etc
розмір TCP-сегменту обмежується MSS (Maximum Segment Size) – будемо дивитись далі
Layer 3 – Network Layer:
тут до TCP-сегменту додаються IP headers – звідки пакет відправлений (source IP), куди він йде (destination IP) і формується IP пакет
додаються дані про TTL (Time To Live) пакту, checksum пакету для перевірки отримувачем – чи пакет дійшов неушкодженим
розмір IP-адреси – 32 біти в IPv4, та 128 біт в IPv6
від IP-адреси залежить тип передачі даних – unicast (одному адресату), multicast (кільком адресатам), там broadcast – всім хостам в заданій мережі
на цьому ж рівні працює ICMP для обміну інформацією стан мережі і про помилки
на Network layer ICMP packets можуть створюватися автоматично при проблемах на рівні маршрутизації
але можуть формуватись і на Application layer, наприклад утилітами ping або traceroute
Layer 2 – Data Link Layer:
Ethernet, Wi-Fi – драйвери мережевої карти формують frame, додаючи MAC-адресу відправника і отримувача і власну перевірку цілісності пакету – CRC (cyclic redundancy check)
MAC адреси визначаються за допомогою протоколу ARP (Adress Resolution Protocol)
Layer 1 – Physical Layer:
фізичне з’єднання, електричні або оптичні сигнали
DNS в моделі OSI
Окремо давайте розглянемо питання про DNS:
Layer 7 – Application layer:
браузеру потрібно відправити запит на “google.com”
браузер виконує функцію getaddrinfo() або gethostbyname() (застаріла) з бібліотеки glibc
glibc перевіряє параметри /etc/nsswitch.conf:
при необхідності виконати зовнішній DNS-запит (наприклад, якщо нема запису в /etc/hosts) – перевіряє параметри в /etc/resolv/conf
формується DNS-запит, відкривається UPD- або TCP-сокет
Layer 4 – Transport Layer:
на транспортному рівні до PDU (сегменту TCP або датаграми UDP) додається заголовок з destination port 53 (зазвичай UDP, але може бути TCP – якщо відповідь більша за 512 байт або включено режим DNS-over-TCP, DoT – див. RFC 7766)
Layer 3 – Network Layer:
до пакету додаються IP headers – куди саме відправити запит
Layer 2 – Data Link Layer та Layer 1 – Physical Layer: передача даних
Модель OSI ISO vs модель TCP/IP
Модель TCP/IP (або Internet Protocol Suite) була розроблена у 1970-х, ще до появи OSI і лягла в основу Інтернету (і його попередника – ARPANET).
Моделі OSI ISO та TCP/IP створені для уніфікації зв’язку між пристроями, але мають ключові відмінності:
OSI описує 7 рівнів, тоді як TCP/IP – 4
Application Layer в TCP/IP включає в себе Application, Presentation та Session layers моделі OSI
а Network Access Layer в TCP/IP включає в себе Data Link та Physical layers моделі OSI (іноді називають Link Layer)
модель OSI це більш “академічна модель”, яка використовується для пояснення принципів роботи мережі, а TCP/IP – “прикладна модель”, на якій власне побудована комунікація в Інтернеті
Головна різниця в тому, що:
модель TCP/IP створювалась для опису вже існуючих протоколів (TCP, IP, FTP, SMTP тощо), які використовувались в ARPANET – тобто спочатку технологія, а потім її опис у вигляді моделі.
натомість модель OSI – це більше теоретична моделі, яку спочатку описали (“як це має бути”), і потім вже під цю модель почали додавати нові протоколи.
Окей – з загальною схему передачі даних розібрались, давайте подивимось детальніше на те, що і як саме передається в TCP/IP.
Оскільки ми вже згадували про TCP headers – то давайте почнемо з них.
TCP header має однакову структуру незалежно від того, чи він передається всередині IPv4 або IPv6. Його мінімальний розмір 20 байт, а максимальний, за рахунок використання поля Options – 60 байт.
IPv4 headers має змінну довжину – від 20 до 60 байт, а от заголовки IPv6 фіксовані в 40 байт.
MTU, MSS та TCP Payload
Максимальний розмір даних, які можна передати в одному IP-пакеті та TCP-сегменті, і залежить від розміру Ethernet frame, MTU (Maximum Transmission Unit), який по дефолту заданий в 1500 байт:
$ ifconfig wlan0 | grep -i MTU
wlan0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
Від цих 1500 байт віднімається місце під TCP та IP заголовки, і в результаті це дає нам MSS (Maximum Segment Size) – максимальний розмір корисних даних у TCP-сегменті:
MSS оголошується під час TCP-handshake через TCP option MSS в пакеті SYN, і обидві сторони узгоджують значення, що дозволяє відправнику враховувати цей розмір, аби уникнути IP-фрагментації.
Якщо TCP payload перевищує MSS – то стек TCP виконує сегментацію, тобто розбиває цей потік на кілька окремих TCP-сегментів.
Наприклад, браузер відправляє POST-запит розміром 3000 байт – тоді TCP поділить цей запит на:
сегмент 1 з розміром даних 1460 байт
сегмент 2 з розміром даних 1460 байт
сегмент 3 з 80 байтами
У випадку з TCP-сегментації – кожен пакет матиме власні заголовки, а його Sequence Number буде вказувати на позицію першого байта даних цього сегмента в загальному потоці даних. При цьому розмір payload кожного сегмента не перевищуватиме MSS.
IP-фрагментація – виняткова ситуація, який трапляється тільки якщо TCP-сегмент (або інший IP-пакет) вже перевищив MTU, і в ідеалі не має відбуватись.
Структура TCP headers
Отже, після отримання даних від Application layer формується TCP-сегмент, до якого додається набір TCP headers:
Note: далі все ж буду використовувати слово “флаги”, а не “прапорці”, бо в контексті TCP якось більш коректно звучить
Тут:
Source port: поле 16 біт в якому вказується порт відправника
Destination port: поле 16 біт в якому вказується порт призначення
Sequence number: поле 32 біти, яке вказує на перший байт даних (payload) кожного TCP-сегменту
Acknowledgment number: поле 32 біти, яке передається отримувачем для запиту наступного TCP-сегменту – це буде Sequence Number + 1
DO (data offset): поле 4 біти яке вказує де закінчується TCP header і починаються дані (payload)
RSV (reserved field): 3 биті, не використовується, і завжди пусте
Flags: 9 біт, також називаються “control bits” – використовуються для передачі флагів, які контролюють встановлення підключення, передачу даних та закриття підключення
URG: urgent pointer – якщо флаг заданий, то сегмент має термінові дані, які на стороні операційної системи отримувача можуть бути передані окремим системним викликом минуючи загальний TCP-буфер (див. TCP – Urgent pointer field)
не впливає на маршрутизацію чи доставку пакета мережею і використовується тільки локально стеком ядра операційної системи отримувача
ACK: acknowledgment підтвердження отримання сегменту
PSH: push function – передати дані негайно, не очікуючи наповнення TCP-буферу
RST: reset – примусове закриття з’єднання при помилках
SYN: початок з’єднання (в TCP 3-way handshake, далі подивимось), задає Initial Sequence Number – див. трохи ниже
FIN: нормальне закриття з’єднання, відправляється як клієнтом, так і сервером
Window: 16 біт, вказується максимальна кількість байт, які відправник (і клієнт, і сервер) може відправити без очікування наступного ACK від серверу (контроль TCP-буферу ядра на стороні серверу)
Checksum: 16 біт, контрольна сума TCP-заголовка + даних, використовується для перевірки, чи не пошкоджено сегмент під час передачі
Urgent pointer: 16 біт, якщо заданий URG, то тут вказується де завершуються термінові дані
Options: 0 – 320 біт, використовується для передачі MSS, timestamps тощо
Sequence Number
Доволі цікава тема, яку коротко, мабуть, є сенс проговорити окремо.
TCP – це потоковий протокол, який передає послідовність байт, а не окремі повідомлення.
Під час передачі даних в TCP-сесії:
клієнт відправляє SYN з Initial Sequence Number, який спочатку задається у вигляді рандомного числа, наприклад 100000
сервер відповідає SYN-ACK, підтверджуючи отримання запиту на з’єднання (SYN)
в полі Acknowledgment Number вказує 100001
далі, при початку передачі першого сегменту даних – клієнт в першому сегменті вкаже Sequence Number 100001, а в наступному – 101461 (при MSS 1460 байт)
Тобто, кожен наступний сегмент збільшує Sequence Number на довжину payload.
Перегляд TCP headers в Wireshark
Самий простий спосіб – з wireshark (або wireshark-qt).
Запускаємо від root, вибираємо інтерфейс:
Наприклад, подивитись трафік до RTFM – знаходимо IP:
Трохи розібрались з TCP headers – тепер давайте глянемо на те, як встановлюється TCP-з’єднання.
Отже, TCP – це протокол, орієнтований на з’єднання (тобто потребує встановлення сесії до початку передачі даних), який забезпечує доставку даних, контроль потоку та виявлення помилок при передачі.
На відміну від UDP – з TCP ми або гарантовано передаємо дані, або буде виявлена помилка і з’єднання буде розірване.
TCP handshake
Як і в TLS, встановлення TCP-з’єднання відбувається за стандартним процесом – “3-way handshake“.
TCP handshake складається з трьох етапів (власне, тому і назва “3-way handshake”):
SYN: клієнт відправляє пакет з флагом SYN, вказуючи свій Initial Sequence Number
SYN-ACK: сервер відповідає пакетом з флагами SYN та ACK, цим він:
підтверджує отримання SYN від клієнта (встановлюючи поле Acknowledgment Number)
відправляє свій власний Initial Sequence Number
ACK: клієнт відправляє ACK, чим підтверджує отримання SYN-ACK від серверу
На цьому сесія вважається встановленою, і починається передача даних.
Закриття сесії – “4-way FIN handshake“:
FIN: клієнт повідомляє сервер (або навпаки), що закінчив передачу, і готовий до закриття сесії
ACK від серверу: сервер підтверджує отримання FIN
FIN від серверу: сервер повідомляє, що теж готовий закрити сесію
ACK від клієнта: клієнт відповідає фінальним ACK, підтверджуючи отримання FIN від сервера
Після цього з’єднання повністю закривається.
Аналіз сесії з Wireshark
Можна писати відразу в Wireshark, можемо спочатку створити файл, а потім його вже аналізувати.
Запускаємо tcpdump:
$ sudo tcpdump host 104.26.3.188 or host 104.26.2.188 or host 172.67.68.115 -w tcp.pcap
В іншому вікні виконуємо запит до RTFM:
$ curl https://rtfm.co.ua
Відкриваємо сформований дамп у Wireshark:
$ sudo wireshark tcp.pcap
І отримуємо всі пакети, які були передані:
Власне тут ми першими і бачимо 3-way handshake – початок з’єднання:
SYN (клієнт 50556 => сервер 443):
Seq=0, Len=0
клієнт (192.168.0.116) відкриває з’єднання маючи локальний порт 50556 до серверу RTFM на до 172.67.68.115 і порт 443
SYN, ACK (443 → 50556):
Seq=0 Ack=1, Len=0
відповідь від серверу 172.67.68.115 , що він підтвердив отримання SYN від клієнту 192.168.0.116 (флаг `ACK), і задає свій флаг SYN` з Initial Sequence Number, встановлюючи початкову точку для свого потоку даних
ACK (50556 → 443):
Seq=1 Ack=1, Len=0
Клієнт підтверджує SYN від сервера
Четвертим вже починається передача даних – Len-1388 (насправді, це вже початок TLS handshake – наступним, п’ятим пакетом бачимо TLSv1.3).
Seq=0 – це як раз Sequence Number, про який говорили вище.
Просто Wireshark його відображає в зручній для нас формі, але ми можемо побачити його реальне значення:
Len=0 в перших трьох пакетах нуль, бо це тільки встановлення з’єднання, ще до передачі даних, і пакети містять тільки TCP-заголовки для встановлення з’єднання, без даних.
Ack=N – підтвердження отримання пакету.
Тобто:
Seq=0:
клієнт відправляє Inital Sequence Number, який Wireshark нам відображає як 0
Seq=0 Ack=1 Len=0:
Seq=0 – сервер теж задає свій Inital Sequence Number
Ack=1 – сервер інкрементить Seq від клієнта на +1
Seq=1 Ack=1 Len=0:
Seq=1 – тепер клієнт збільшує свій Sequence Number
Ack=1 – клієнт підтверджує отримання SYN від серверу
TCP та ядро Linux
В ядрі операційної системи для передачі даних за TCP-протоколом реалізована своя система – TCP stack.
Вона відповідає за:
відкриття та завершення TCP-сесій
контроль доставки (ACK, SEQ)
повторну передачу втрачених пакетів
розпізнавання флагів (SYN, FIN, RST тощо)
збирання даних з кількох сегментів у правильному порядку
По факту, це набір функцій в ядрі, які опрацьовують TCP-пакети.
А сам TCP-стек – це частина мережевого стеку ядра, разом з обробкою Ethernet, ARP, IP, UDP та інших.
Ядро також підтримує автоматичне масштабування буферів – файл /proc/sys/net/ipv4/tcp_moderate_rcvbuf:
$ cat /proc/sys/net/ipv4/tcp_moderate_rcvbuf
1
1 – включено, 0 – виключено.
Мінімальний Maximum segment size (MSS) задається у файлі /proc/sys/net/ipv4/tcp_min_snd_mss:
$ cat /proc/sys/net/ipv4/tcp_min_snd_mss
48
48 байт == 384 біти.
Мінімальний розмір задається для запобіганню відправки надто маленьких TCP-сегментів, які викликатимуть зайві накладні витрати та зниження продуктивності.
Network Interface Card отримує Ethernet frame з TCP-пакетом
ядро системи викликає драйвер карти, а драйвер викликає функцію netif_receive_skb() і передає весь отриманий кадр (в структурі skb – Socket Buffer) на обробку мережевій підсистемі ядра
Layer 3: Network layer
пакет передається до ip_rcv() (IPv4) або ipv6_rcv() (IPv6), де перевіряється заголовок IP для визначення протоколу
якщо Protocol = 6 (TCP) – пакет передається в tcp_v4_rcv()
Layer 4: Transport layer
функція tcp_v4_rcv() перевіряє контрольну суму, знаходить відповідний локальний сокет (порт), обробляє SEQ/ACK/FIN/RST/SYN флаги, і додає payload у receive buffer сокета, прив’язаного до відповідного порту (наприклад, listen(80) для веб-сервера)
після передачі даних до веб-серверу – ядро формує ACK-пакет у відповідь
дані передаються у внутрішній receive buffer сокета, і звідти вже передаються в userspace до веб-серверу (якщо ми про браузер-сервер)
Якщо заглиблюватись – то можна взяти утиліти по типу Systemtap для відстеження системних викликів.
Сокети та TCP-порти в Linux
Для роботи з TCP в Linux є концепція сокетів (sockets) – це такі собі ендпоінти, які прив’язуються до пари IP:PORT.
Власне сокет – це абстракція, яка дозволяє програмам читати/писати в мережу, як через звичайний файл, і по суті і є файловим дескриптором спеціального типу: операційна система сприймає їх як пайп (pipe), через який можна передавати дані.
Сокети можуть бути або локальними, аби мережевими:
AF_INET для IPv4 та AF_INET6 для IPv6
AF_UNIX або AF_LOCAL – для локальної роботи
AF_* в імені – це “Address Family“, бо маємо не тільки TCP/UDP-сокети, але й AF_UNIX – локальні, AF_BLUETOOTH – Bluetooth, AF_NETLINK – Netlink і т.д.
// Create a UNIX domain socket file at /tmp/mysocket.sock
#include <sys/socket.h> // import socket(), bind() functions
#include <sys/un.h> // import C struct sockaddr_un
#include <unistd.h> // import close() function
#include <stdio.h> // import input/output functions like print()
#include <string.h> // import strings/memory functions like strlen()
// def main C function
int main() {
// define a variable with the 'int' type
// it will store the socket's file descriptor ID returned by the socket() function
// a file descriptor is just an integer index into the per-process open file table
// the actual 'file' struct exists in kernel space, user space only sees the integer
int sockfd;
// define a variable named 'addr' with the 'struct sockaddr_un' type
// this structure is used to specify socket address for AF_UNIX sockets
struct sockaddr_un addr;
// Step 1: create socket
// socket(domain, type, protocol)
// AF_UNIX: UNIX domain socket
// SOCK_STREAM: stream-oriented (like TCP)
// '0': protocal, set to 0 as AF_UNIX + SOCK_STREAM have no protocal
sockfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sockfd < 0) {
perror("socket");
return 1;
}
// Step 2: set up address structure
memset(&addr, 0, sizeof(addr)); // zero out the memory for safety
addr.sun_family = AF_UNIX; // set socket family (UNIX domain)
strcpy(addr.sun_path, "/tmp/mysocket.sock"); // set path for the socket file in the 'addr' structure
// Step 3: remove old socket file if it exists
// unlink removes a file; important to avoid "Address already in use" error
unlink("/tmp/mysocket.sock");
// Step 4: bind
//
// bind the socket to a local address (path in the filesystem) - bind(sockfd, addr, size_of_addr)
// 'sockfd': socket file descriptor returned by socket()
// '&addr': pointer to the sockaddr_un struct that contains:
// - family (AF_UNIX)
// - path (filesystem path to the socket file)
// '(struct sockaddr*)': cast required because bind() expects a generic sockaddr*
// 'sizeof(addr)': size of the sockaddr_un structure
//
// after this call, the socket is associated with a specific name (path),
// so other processes can connect to it via this path.
if (bind(sockfd, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
perror("bind");
return 1;
}
printf("UNIX socket created at /tmp/mysocket.sock\n");
// Step 5: keep socket alive for inspection
sleep(60);
// Step 6: cleanup
close(sockfd); // close the socket file descriptor
unlink("/tmp/mysocket.sock"); // remove the socket file from filesystem
return 0;
}
Збираємо з gcc:
$ gcc unix_socket.c -o unix_socket
Запускаємо:
$ ./unix_socket
UNIX socket created at /tmp/mysocket.sock
І маємо відкритий сокет:
$ file /tmp/mysocket.sock
/tmp/mysocket.sock: socket
$ ls -l /tmp/mysocket.sock
srwxr-xr-x 1 setevoy setevoy 0 Jun 29 10:30 /tmp/mysocket.sock
В ls -l бачимо флаг “s” на початку – показує, що це тип socket.
Власне саме так і створюються сокети в Linux, які ми можемо бачити для якихось локальних демонів, наприклад:
AF_INET та AF_INET6 створюються і працюють аналогічно до локальних UNIX-сокетів – тільки замість “адреси” у вигляді імені локального файлу використовують пару IP:PORT.
Також їх називають “BSD sockets” або “Berkeley sockets”, бо вперше вони були реалізовані Berkeley Software Distribution (BSD) Unix у 1983 році.
Код в принципі схожий на створення UNIX-сокету:
#include <stdio.h> // for printf(), perror()
#include <stdlib.h> // for exit()
#include <string.h> // for memset()
#include <unistd.h> // for close()
#include <sys/types.h> // for socket types
#include <sys/socket.h> // for socket(), bind()
#include <netinet/in.h> // for sockaddr_in
#include <arpa/inet.h> // for inet_addr()
int main() {
// will store the socket's file descriptor (int)
int sockfd;
// Step 1: create a new socket
// AF_INET = IPv4 address family
// SOCK_STREAM = TCP (reliable byte stream)
// 0 = default protocol (IPPROTO_TCP for AF_INET)
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1) {
perror("socket creation failed");
exit(EXIT_FAILURE);
}
// define the address to bind the socket to
struct sockaddr_in server_addr;
// Step 2: fill the 'server_addr' structure with zeros to avoid undefined or leftover data
memset(&server_addr, 0, sizeof(server_addr));
// AF_INET for IPv4
server_addr.sin_family = AF_INET;
// port number
server_addr.sin_port = htons(8080);
// bind to th 'localhost' (127.0.0.1)
server_addr.sin_addr.s_addr = inet_addr("127.0.0.1");
// Step 3: bind the socket to the given IP address and port
// this makes the socket listen for incoming connections on the '127.0.0.1:8080'
if (bind(sockfd, (struct sockaddr*)&server_addr, sizeof(server_addr)) == -1) {
perror("bind failed");
close(sockfd); // close socket before exiting
exit(EXIT_FAILURE);
}
// Step 4: listen for incoming connections
// the socket is now ready to accept connections
// function: int listen(int sockfd, int backlog);
// 'sockfd' is the socket file descriptor
// 'backlog' is the maximum number of pending connections
// if the backlog is exceeded, new connections will be refused
// here we set it to 5, meaning up to 5 connections can be queued
if (listen(sockfd, 5) < 0) {
perror("listen");
return 1;
}
printf("Socket successfully created and bound to 127.0.0.1:8080\n");
printf("Press Enter to close the socket...\n");
// keep the socket open for inspection
getchar();
// Step 5: close the socket after use
close(sockfd);
return 0;
}
Але тут:
задаємо тип AF_INET
задаємо TCP-порт
задаємо IP, на якому слухати
з системним викликом listen() переводимо сокет в стан очікування з’єднань
Збираємо:
$ gcc inet_socket.c -o inet_socket
Запускаємо:
$ ./inet_socket
Socket successfully created and bound to 127.0.0.1:8080
Перевіряємо:
$ netstat -anp | grep 8080
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN 2724448/./inet_sock
TCP ports
TCP-порт – це просто число від 0 до 65535, які дозволяють мати різні сервіси і підключення при одному IP-адресі, і використовується виключно для адресації сокету по парі IP:PORT.
49152 – 65535: Ephemeral ports (системою для клієнтів)
Тобто з’єднання формується з пари <client_IP>:<client_port> => <server_IP>:<server_port>, і пара IP:PORT задається при створенні сокету (через виклик bind()).
Коли ядро отримує TCP-пакет, то викликає tcp_v4_rcv(), яка в свою чергу по IP-адресі:порт шукає відповідний сокет (через виклик inet_lookup() або __inet_lookup_established()), і якщо сокет знайдено – то через нього передається payload пакету.
Якщо сокет не знайдено, або сервіс повернув помилку – то ядро може повернути RST у відповідь, або просто дропнути пакет (залежно від ситуації).
Є у нас VictoriaMetrics і VictoriaLogs, працюють на AWS Elastic Kubernetes Service.
Мажорні апгрейди EKS ми робимо через створення нового кластеру, а тому з’явилась задача перенесення даних моніторингу зі старого інстансу VMSingle на новий.
Для VictoriaMetrics можемо використати vmctl, яка через API старого і нового інстансу може мігрувати дані працюючи в ролі проксі між двома інстансами.
З VictoriaLogs ситуація поки що дещо складніша і наразі є два варіанти – далі їх подивимось.
Отже, що маємо:
старий Kubernetes cluster EKS 1.30
новий Kubernetes cluster EKS 1.33
Деплоїться нашим власним Helm-чартом, який через dependencies встановлює victoria-metrics-k8s-stack та victoria-logs-single, плюс пачка різних додаткових сервісів типу PostgreSQL Exporter.
Міграція метрик VictoriaMetrics
Запуск vmctl
vmctl підтримує міграцію як з VMSinlge на VMClutser, так і навпаки, або просто між інстансами VMSinlge => VMSinlge, або VMClutser => VMClutser.
В нашому випадку це просто два інстанси VMSingle.
Встановити vmctl можна встановити локально у поді з VMSingle, див. How to build, але так як CLI все одно працює через API – то простіше створити окремий Pod, і все робити з нього. Docker-образ доступний тут – victoriametrics/vmctl.
Так як entrypoint для цього образу заданий в /vmctl-prod, то аби просто зайти в контейнер – передамо --command, запустимо в циклі ping та sleep, і далі спокійно з консолі будемо робити все, що нам треба:
$ kubectl run vmctl-pod --image=victoriametrics/vmctl --restart=Never --command -- /bin/sh -c "while true; echo ping; do sleep 5; done"
pod/vmctl-pod created
На якому саме кластері запускати в принципі різниці нема.
Підключаємось в Pod:
$ kk exec -ti vmctl-pod -- sh
/ #
Перевіримо:
/ # /vmctl-prod vm-native --help
NAME:
vmctl vm-native - Migrate time series between VictoriaMetrics installations via native binary format
USAGE:
vmctl vm-native [command options] [arguments...]
OPTIONS:
-s Whether to run in silent mode. If set to true no confirmation prompts will appear. (default: false)
...
Запуск міграції
Kubernetes Pod з vmctl буде працювати в ролі проксі між source та destination, тому повинен мати стабільний нетворк.
Крім того, якщо мігруєте великий об’єм даних – то подивіться в бік опції --vm-concurrency для запуску міграції в кілька паралельних потоків, при цьому кожен воркер буде додатково використовувати CPU/Memory.
Також рекомендується додати фільтр --vm-native-filter-match='{__name__!~"vm_.*"}' аби не переносити метрики, які відносяться до самої VictoriaMetrics, бо це може призвести до data collision – появи дублікатів тайм-серій.
Хоча в моєму випадку у нас через VMAgent до всіх метрик додається метрика з іменем кластеру:
Інший варіант – додати опцію dedup.minScrapeInterval=1ms, тоді VictoriaMetrics сама видалить дублікати, але я цей варіант не тестив.
Міграція VictoriaLogs
З VictoriaLogs ситуація трохи складніша, бо vlogscli поки що (сподіваюсь, додадуть) не має якоїсь опції для переносу даних як в vmctl.
І тут є проблема:
якщо в VictoriaLogs на новому кластері ще нема ніяких даних – то можна просто скопіювати старі даних з rsync в PVC нового інстансу VictoriaLogs
аналогічно, якщо дані є, але нема overlapping днів, бо дані в VictoriaLogs storage зберігаються в каталогах по дням, і їм можна спокійно переносити
але якщо дані є, та/або дні дублюються – то поки що єдиний варіант це запускати два інстанси VictoriaLogs: один зі старими даними, один з новими, а перед ними мати інстанс vlselect
Коли додадуть Object Storage – то буде простіше, і це вже є в Roadmap. Тоді можна буде просто все тримати в AWS S3, як це у нас зараз в Grafana Loki.
Варіант 1: копіювання даних з rsync
Отже, перший варіант – якщо в новому інстансі VictoriaLogs даних нема, або нема записів в одні і ті ж дні на обох інстансах – старому і новому.
Тут ми можемо просто скопіювати дані, і вони будуть доступні на новому Kubernetes-кластері.
Я робив з rsync, але можна спробувати зробити з утилітами типу korb.
Перевіримо де зберігаються логи в VictoriaLogs Pod:
$ kk describe pod atlas-victoriametrics-vmlogs-new-server-0
Name: atlas-victoriametrics-vmlogs-new-server-0
...
Containers:
vlogs:
...
Args:
--storageDataPath=/storage
...
Mounts:
/storage from server-volume (rw)
...
Volumes:
server-volume:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: server-volume-atlas-victoriametrics-vmlogs-new-server-0
ReadOnly: false
...
І зміст директорії /storage:
~ $ ls -l /storage/partitions/
total 32
drwxrwsr-x 4 1000 2000 4096 Jun 16 00:00 20250616
drwxrwsr-x 4 1000 2000 4096 Jun 17 00:00 20250617
drwxrwsr-x 4 1000 2000 4096 Jun 18 00:00 20250618
drwxrwsr-x 4 1000 2000 4096 Jun 19 00:00 20250619
drwxrwsr-x 4 1000 2000 4096 Jun 20 00:00 20250620
drwxr-sr-x 4 1000 2000 4096 Jun 21 00:00 20250621
drwxr-sr-x 4 1000 2000 4096 Jun 22 00:00 20250622
drwxr-sr-x 4 1000 2000 4096 Jun 23 00:00 20250623
Але в самому поді нема ані rsync, ані SSH, і ми навіть не можемо їх встановити:
~ $ rsync
sh: rsync: not found
~ $ apk add rsync
ERROR: Unable to lock database: Permission denied
ERROR: Failed to open apk database: Permission denied
~ $ su
su: must be suid to work properly
~ $ sudo -s
sh: sudo: not found
~ $ ssh
sh: ssh: not found
Тому просто зробимо rsync зі старого EC2 на новий.
Питав розробників про варіант з JSON merge – але це не спрацює.
Якщо ж дані не перетинаються – то просто копіюємо дані і рестартимо Pod з VictoriaLogs.
В моєму випадку довелось робити трошки інакше.
Варіант 2: запуск двох VMLogs + vlselect
Отже, якщо у нас є дані за одні і ті ж дні на старому і новому інстансах VictoriaLogs – то робимо таким чином:
на новому EKS-кластері створюємо другий інстанс VMLogs
в його PVC копіюємо дані зі старого кластеру
додаємо Pod з vlselect
для vlselect вказуємо два source – обидва інстанси VMLogs
і потім для Grafana VictoriaLogs data source використовуємо URL сервісу vlselect
Можна було б просто додати vlselect, і роутити запити на старий кластер – але нам треба старий кластер видаляти.
vlselect vs VMLogs
Фактично vlselect це той самий бінарний файл, що і VictoriaLogs, що дуже спрощую нам весь сетап – див. документацію VictoriaLogs cluster:
Note that all the VictoriaLogs cluster components – vlstorage, vlinsert and vlselect – share the same executable – victoria-logs-prod.
Тому ми просто можемо взяти ще один чарт victoria-logs-single, і все запускати з нього.
І насправді ми будемо будувати такий собі “VictoriaLogs cluster на мінімалках”:
наш поточний інстанс VictoriaLogs буде грати роль vlinsert та vlstorage – туди пишуться нові логи нового кластеру
новий інстанс VictoriaLogs буде грати роль vlstorage – в ньому ми будемо зберігати дані зі старого кластеру
третій інстанс VictoriaLogs буде грати роль vlselect – він буде ендпоінтом для Grafana, і буде робити API-запити з пошуком логів з обох інстансів VictoriaLogs
Helm chart update
Я поки не готовий запускати повноцінну версію VictoriaLogs cluster, тому просто додамо ще парочку dependencies в наш поточний Helm chart.
vmlogs-new: поточний інстанс VMLogs на новому EKS кластері
vmlogs-old: новий інстанс, в який будемо переносити дані зі старого EKS кластеру
vlselect: буде нашим новим ендпоінтом для пошуку логів
Єдиний момент, що під час деплою може бути помилка через довжину імен подів, бо я спочатку задав надто довгі імена в alias:
...
Pod "atlas-victoriametrics-victoria-logs-single-old-server-0" is invalid: metadata.labels: Invalid value: "atlas-victoriametrics-victoria-logs-single-old-server-77cf9cd79d": must be no more than 63 characters
...
Що треба перевірити в дефолтному values.yaml чарту victoria-logs-single:
...
persistentVolume:
# -- Create/use Persistent Volume Claim for server component. Use empty dir if set to false
enabled: true
size: 10Gi
...
ingress:
# -- Enable deployment of ingress for server component
enabled: false
...
Для інстансу vlselect додаємо storageNode, де через кому вказуємо ендпоінти обох VictoriaLogs, і при потребі задаємо параметри для persistentVolume:
Тепер у нас Promtail на новому кластері продовжує писати в atlas-victoriametrics-vmlogs-new-server, а atlas-victoriametrics-vmlogs-old-server у нас пустий інстанс VMLogs.
Можемо перевірити доступ до логів через інстанс vlselect:
$ kk port-forward svc/atlas-victoriametrics-vlselect-server 9428
Перенос даних зі старого кластеру
Далі, власне, просто повторюємо те, що робили вище – знаходимо каталог PVC, і копіюємо туди дані зі старого кластеру.
Цього разу спочатку собі на робочу машину, а потім звідси вже в Kubernetes:
[setevoy@setevoy-work ~] $ mkdir vmlogs_back
Поки писав, VictoriaLogs на старому кластері вже переїхав на новий EC2, тому шукаємо дані заново.
Переключаємо kubectl на старий кластер, і шукаємо Pod:
$ kk describe pod atlas-victoriametrics-victoria-logs-single-server-0 | grep 'Node\|Container'
Node: ip-10-0-38-72.ec2.internal/10.0.38.72
Containers:
Container ID: containerd://c168d4487282dd7d868aadcfcd1840e4e15cfd360f56f542a98b77978f91e252
...
[root@ip-10-0-36-143 ec2-user]# ls -l /var/lib/kubelet/pods/297b75ec-63fa-4061-bb23-7a6a120da939/volumes/kubernetes.io~csi/pvc-c7373468-f247-4596-b2e2-87852aad71bb/mount/partitions/
total 32
drwxrwsr-x. 4 ec2-user ec2-user 4096 Jun 19 00:00 20250619
drwx--S---. 2 root ec2-user 4096 Jun 26 13:39 20250620
drwx--S---. 2 root ec2-user 4096 Jun 26 13:39 20250621
drwx--S---. 2 root ec2-user 4096 Jun 26 13:39 20250622
drwx--S---. 2 root ec2-user 4096 Jun 26 13:39 20250623
...
Міняємо юзера і групу:
[root@ip-10-0-36-143 ec2-user]# chown -R ec2-user:2000 /var/lib/kubelet/pods/297b75ec-63fa-4061-bb23-7a6a120da939/volumes/kubernetes.io~csi/pvc-c7373468-f247-4596-b2e2-87852aad71bb/mount/partitions/
[root@ip-10-0-36-143 ec2-user]# ls -l /var/lib/kubelet/pods/297b75ec-63fa-4061-bb23-7a6a120da939/volumes/kubernetes.io~csi/pvc-c7373468-f247-4596-b2e2-87852aad71bb/mount/partitions/
total 32
drwxrwsr-x. 4 ec2-user 2000 4096 Jun 19 00:00 20250619
drwxrwsr-x. 4 ec2-user 2000 4096 Jun 20 00:00 20250620
...
Перезапускаємо Pod atlas-victoriametrics-vmlogs-old-server-0.
Перевірка даних
І пошукаємо щось.
Спочатку щось про ноду hostname: "ip-10-0-36-143.ec2.internal" на новому кластері – це має прийти з інстансу atlas-victoriametrics-vmlogs-new-server-0, тобто зі старого інстансу на новому Kubernetes-кластері:
При створенні Kubernetes Service – Endpoints controller створює ресурс Endpoints зі списком Pod IPs, який потім використовується ALB Controller для додавання таргетів в Target Group.
При деплої Backend API Ingress – ALB Controller створює ALB з Listeners на кожен hostname з Ingress з власним SSL, і з Target Group для кожного Listener, в якій задаються IP Pods зі списку адрес в Endpoints, на які треба слати трафік від клієнтів.
Тобто схема виглядає так: client => ALB => Listener => Target Group => Pod IP.
502 у нас виникає, якщо ALB не зміг отримати коректну відповідь від бекенда, тобто помилка на рівні самого сервісу (застосунку), application layer (“я додзвонився, але на тому кінці відповіли щось незрозуміле або кинули слухавку посеред розмови”):
у Pod не відкритий порт
Pod впав, але Readiness probe каже що він живий, і Kubernetes не відключає його від трафіку (не видаляє IP зі списку в Endpoints)
503 виникає, якщо ALB не має жодного Healthy target, або Ingress не зміг знайти Pod (“абонент не може прийняти ваш дзвінок”):
Pods проходять readinessProbe, додаються в список Endpoints і в ALB targets, але не проходять Health checks в TargetGroup – тоді ALB шле трафік на всі Pods (targets), див. Health checks for Application Load Balancer target groups
Pods не проходять readinessProbe, Kubernetes видаляє їх з Endpoints, і Target Group стає порожньою – ALB нема куди слати запити
Kubernetes Service має помилки в конфігурації (наприклад – неправильний Pod selector)
Kubernetes Service налаштований коректно, але кількість запущених подів == 0
ALB встановив підключення до Pod, але підключення розірване на рівні TCP (наприклад, через різні keep-alive таймаути на бекенді та ALB), і ALB отримав TCP RST (reset)
504 виникає коли ALB відправив запит, але не отримав відповідь у встановлений таймаут (дефолт 60 секунд на ALB) (“я додзвонився, але мені надто довго не відповідають, і я кладу слухавку”)
процес в Pod надто довго обробляє запит
мережеві проблеми в AWS VPC або EKS кластері, і пакети від ALB до Pod проходять надто довго
Інші можливі причини 503, і чи пов’язані вони з нашим випадком:
неправильні правила Security Groups:
при створенні TargetGroups, AWS Load Balancer Controller має створити або оновити SecurityGroups, і може, наприклад, не мати доступу до AWS API на редагування SecurityGroup
але не наш кейс, бо помилка виникає періодично, а в такому випадку була б відразу і постійно
unhealthy targets в Target Group:
якщо всі Pods (ALB targets) періодично “відвалюються” – то будемо мати 503, бо ALB починає слати трафік на всі наявні таргети
теж не наш кейс – перевіряємо метрику UnHealthyHostCount в CloudWatch – вона показує, що проблем з таргетами не було
некоректні теги на VPC Subnets:
ALB Контролер шукає Subnets за тегом kubernetes.io/cluster/<cluster-name>: owned аби знайти в них Pods і зареєструвати targets
знов-таки не наш кейс, бо помилка виникає періодично, а не є постійною
затримка при connection draining:
при деплойменті або скейлінгу старі Pods видаляються, і їхні IP видаляються з TargegtGroup, але це може виконуватись з затримкою – тобто Pod вже мертвий, а його IP в Targets ще є
але в першому випадку рестартів чи деплоїв не було, див. далі
ліміти пакетів в секунду або трафіку в секунду на Worker Node:
Тоді вирішив перевірити просто всі Ingress в усіх Namespaces:
$ kk get ingress -A -o yaml | grep idle_timeout
alb.ingress.kubernetes.io/load-balancer-attributes: idle_timeout.timeout_seconds=600
alb.ingress.kubernetes.io/load-balancer-attributes: idle_timeout.timeout_seconds=600
І потім вже без grep просто знайшов імя Ingress з цим атрибутом:
Не пам’ятаю для чого додавав, але трошки вилізло боком.
Добре – це поміняли, і 503 стало набагато менше – але все ще іноді бували.
Problem 2: 503 під час деплою
Знов прилетіла 503.
Тепер бачимо, що дійсно – в цей час був деплой:
Хоча Deployment має maxSurge 100% і maxUnavailable: 0 – див. Rolling Update:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 100% # run all replicas before stop old Pods
maxUnavailable: 0 # keep all old Pods until new Pods will be Running (passed the readinessProbe)
...
Тобто маючи навіть один Pod на Dev-оточенні – спочатку має запуститись новий, пройти всі probes – і тільки після цього почне видалятись старий.
Але ми при деплої на Dev все одно отримуємо 503.
Kubernetes, AWS TargetGroup та targets registration
Як виглядає процес додавання в TargetGroups?
створюємо новий Pod
kubelet перевіряє readinessProbe
поки readinessProbe не пройдений – Pod в статусі Ready == False
коли readinessProbe пройдена – Kubernetes оновлює Endpoints і додає Pod IP в список адрес
ALB Controller бачить новий IP в Endpoints, і починає процес додавання цього IP в TargetGroup
після реєстрації в TargetGroup цей IP не відразу отримує трафік, а переходить в статус Initial
ALB починає виконувати свої Health checks
коли Health check пройдено – target стає Healthy, і на нього роутиться трафік
Kubernetes, AWS TargetGroup та targets deregistration
Але є нюанс в тому, як targets видаляються з Target Group:
під час деплою з Rolling Update – Kubernetes створює новий Pod, і чекає поки він стане Ready (пройде readinessProbe)
після цього Kubernetes починає видаляти старий под – він переходить в статус Terminating
в це жеж час новий IP нового Pod, який було додано в ALB Target Group ще може проходити Health checks, тобто бути в статусі Initial
а target того Pod, який вже почав Terminating – переходить в статус Draining і потім видаляється з Target Group
І ось тут ми і можемо ловити 503.
Перевірка
Спробуємо зарепроьюсити цю проблему:
робимо деплой
слідкуємо за статусом Pod
він стане Ready, і почне вбиватись старий Pod
в цей час глянемо ALB – чи пройшов новий таргет Initial, і який статус старого target
Що маємо перед деплоєм:
Сам Pod:
$ kk get pod -l app=backend-api -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
backend-api-deployment-849557c54b-jmkz4 1/1 Running 0 44m 10.0.47.48 ip-10-0-38-184.ec2.internal <none> <none>
І Edpoints:
$ kk get endpoints backend-api-service
Warning: v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
NAME ENDPOINTS AGE
backend-api-service 10.0.47.48:8000 7d3h
Таргети в TargetGroup – зараз один:
Запускаємо деплой – і маємо новий в Ready та Running, а старий в Terminating:
І в цей в TargetGroup маємо новий таргет в статусі Initial, а старий вже в Draining:
Правда, з curl в циклі по 1 секунді не вийшло відловити 503 – надто швидко проходять Health checks.
Рішення: Pod readiness gate
Pod readiness gate додає ще одну перевірку до Pod: поки відповідний Target в ALB не пройде Helth check – старий Pod не буде видалятись:
The condition status on a pod will be set to True only when the corresponding target in the ALB/NLB target group shows a health state of »Healthy«.
Але це працює тільки якщо у вас target_type == IP.
виконує Pod Eviction, аби видалити з цієї ноди існуючі Pods
Kubernetes отримує Eviction event, і починає процес видалення контейнерів – переводить їх в стан Ternimating через відправку сигналу SIGTERM
ALB Controller бачить, що Pod в статусі Terminating – і починає процес видалення target – переводить його в стан Draining
в цей жеж час Kubernetes бачить, що кількість replicas в Deployment не дорівнює desired state, і створює новий Pod на заміну старому
новий Pod не може бути запущеним на старій WorkerNode, бо та має taint NoSchedule, і якщо на існуючих WorkerNodes нема місця – Karpenter створює новий інстанс EC2, що займає пару хвилин – це ще додатково збільшить вікно для 503
новий Pod в цей час в статусі Pending або ContainerCreating, і не додається до LoadBalancer TargetGroup – тоді як старий target вже видаляється
насправді не видаляється відразу, бо Draining state – це коли ALB перестає створювати нові з’єднання з target, але дає час на завершення існуючих – див. Registered targets
відповідно в цей час ALB просто нема куди слати трафік
…
отримуємо 503
Перевірка
Можемо спробувати зарепродьюсити помилку:
виконаємо node drain там де Dev Pod
подивимось на статус подів
подивимось на ALB Targets
Знаходимо ноду Pod з Backend API в Dev Namespace:
$ kk -n dev-backend-api-ns get pod -l app=backend-api -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
backend-api-deployment-7b5fd6bb9b-mrm2m 1/1 Running 0 7m56s 10.0.42.9 ip-10-0-40-204.ec2.internal <none> 1/1
Бачимо, що старий Pod в статусі Terminating, а новий – ContainerCreating:
І в цей час в TargetGroup маємо тільки один target, і він вже в статусі Draining – бо старий Pod в Terminating, а новий ще не додано в TargetGroup – бо Ednpoints оновиться тільки тоді, коли новий Pod стане Ready:
І в цей час ловимо купу 503:
$ while true; curl -X GET -s -o /dev/null -w "%{http_code}\n" https://dev.api.example.co/ping; do sleep 1; done | grep 503
503
503
503
...
Але в цьому конкретному випадку помилки виникають на Dev-оточенні, де тільки один контейнер з API і нема PDB – а на Staging і Production вони є, тому там ми 503 помилки більше не отримуємо:
 І змержив спочатку апгрейд Lambda до 8 версії.
І змержив спочатку апгрейд Lambda до 8 версії.
 Мабуть, всі користувались операторами в Kubernetes, наприклад –
Мабуть, всі користувались операторами в Kubernetes, наприклад –