![]() Прийшла задачка підняти для проекту цікавий сервіс Arize Phoenix для моніторингу і тюнингу використання LLM.
Прийшла задачка підняти для проекту цікавий сервіс Arize Phoenix для моніторингу і тюнингу використання LLM.
За сам сервіс багато не скажу, бо не користувався, але його запуск вийшов доволі цікавим.
Що будемо робити – спочатку з Helm запустимо тестовий варіант, подивитись як воно взагалі виглядає, потім зробимо повноцінну автоматизацію – Terraform для всяких сікретів, Helm для самого Phoenix.
Власне цей пост буде не стільки про сам Arize Phoenix, скільки просто приклад як з Terraform створити AWS Secrets, і як з Helm та External Secrets Operator ці сікрети отримати.
Тестовий запуск з Helm в Kubernetes
Phoenix підтримує різні варіанти запуску. нам цікавий Helm, документація тут – Kubernetes (helm).
Сам чарт є в Docker Hub (і далі це трохи вилізе боком), всі values є там жеж.
Можемо спулити чарт собі локально:
$ helm pull $CHART_URL Pulled: registry-1.docker.io/arizephoenix/phoenix-helm:4.0.4 Digest: sha256:c5692ed16ea9de346e91181c1afc2a0294af0b7f9e3dc3e13d663ee4a00ace1e
Розпаковуваємо:
$ tar xfp phoenix-helm-4.0.4.tgz
І дивимось файли. Далі довелось полазити в них, або зрозуміти логіку.
Або шукаємо в GitHub тут>>>.
Створюємо Kubernetes Namespace:
$ kk create ns test-phoenix-ns namespace/test-phoenix-ns created
Встановлюємо чарт:
$ export CHART_URL=oci://registry-1.docker.io/arizephoenix/phoenix-helm $ helm -n test-phoenix-ns install phoenix $CHART_URL --debug
Перевіряємо сервіси:
$ kk get all NAME READY STATUS RESTARTS AGE pod/phoenix-8677bcc44f-k8w2k 1/1 Running 1 (49s ago) 70s pod/phoenix-postgresql-0 1/1 Running 0 70s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/phoenix-postgresql ClusterIP 172.20.11.177 <none> 5432/TCP 70s service/phoenix-svc NodePort 172.20.85.64 <none> 4317:31314/TCP,6006:31180/TCP,9090:31897/TCP 70s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/phoenix 1/1 1 1 70s NAME DESIRED CURRENT READY AGE replicaset.apps/phoenix-8677bcc44f 1 1 1 70s NAME READY AGE statefulset.apps/phoenix-postgresql 1/1 71s
По дефолту використовує власний контейнер з PostgreSQL, для Production будемо робити в AWS RDS.
Відкриваємо доступ до порту для WebUI:
$ kk port-forward service/phoenix-svc 6006
Переходимо в браузері на http://localhost:6006, логінимось.
Дефолтний логін – admin@localhost, пароль – admin.

Документація по аутентифікація – тут>>>, і там є цікаві моменти. наприклад, змінити пошту для адміна (і для Member? тобто для звичайних юзерів? не пробував) не міжна:
Neither an Admin nor Member is permitted to change email addresses.
ОК, воно працює – давайте думати про продакшен сетап.
AWS та Terraform
Що нам треба буде з ресурсів в AWS:
- запис Route 53 з доменом для доступу юзерів
- TLS сертифікат в AWS Certificate Manager
- AWS Secrets Manager:
- пароль для доступу до Postgres
- два паролі для самого Phoenix
- пароль для SMTP – навіть якщо він не використовується
Готуємо файл backend.tf:
terraform {
backend "s3" {
bucket = "tf-state-backend-atlas-phoenix"
use_lockfile = true
region = "us-east-1"
encrypt = true
}
}
Готуємо файли variables.tf, providers.tf, versions.tf, outputs.tf.
В результаті в мене виходить така структура – стандартна в нашому проекті:
$ tree . . ├── Makefile ├── backend.tf ├── data.tf ├── envs │ └── ops │ └── ops-1-33.tfvars ├── outputs.tf ├── providers.tf ├── variables.tf └── versions.tf
Тут “ops” – це ім’я AWS-оточення, а в ops-1-33.tfvars значення специфічні для поточного кластеру AWS Elasctic Kubernetes Service.
Запис в AWS Route 53
Додаємо нову змінну:
variable "dns_zone" {
description = "AWS Route 53 zone for the AWS Ops environment"
type = string
default = "ops.example.co"
}
В файл data.tf додаємо отримання інформації про зону:
data "aws_route53_zone" "ops" {
name = var.dns_zone
}
Для запису в Route 53 треба буде створити CNAME на AWS Application Load Balancer.
У нас використовується один external ALB для всіх сервісів в Kubernetes, див. Kubernetes: єдиний AWS Load Balancer для різних Kubernetes Ingress.
Тому просто отримаємо інформацію по ньому з ще одним ресурсом data.
Додаємо змінну з іменем ALB:
variable "aws_alb_name" {
description = "AWS EKS Shared Load Balancer name specific to EKS Environment"
type = string
}
Додаємо значення в ops-1-33.tfvars:
aws_alb_name = "k8s-ops133externalalb-***"
І додаємо data:
data "aws_lb" "shared_alb" {
name = var.aws_alb_name
}
В файлі locals.tf створимо нову local з повним іменем:
locals {
# 'phoenix.ops.example.co'
phoenix_domain_name = "phoenix.${var.dns_zone}"
}
І тепер можемо описати новий record в Route 53:
resource "aws_route53_record" "phoenix_dns" {
zone_id = data.aws_route53_zone.ops.zone_id
name = local.phoenix_domain_name
type = "CNAME"
ttl = 300
records = [
data.aws_lb.shared_alb.dns_name
]
}
Виконуємо terraform init та terraform plan, перевіряємо, що все ок:
...
Terraform will perform the following actions:
# aws_route53_record.phoenix_dns will be created
+ resource "aws_route53_record" "phoenix_dns" {
+ allow_overwrite = (known after apply)
+ fqdn = (known after apply)
+ id = (known after apply)
+ name = "phoenix.ops.example.co"
+ records = [
+ "k8s-ops133externalalb-***.us-east-1.elb.amazonaws.com",
]
+ ttl = 300
+ type = "CNAME"
+ zone_id = "Z02***OYY"
}
Plan: 1 to add, 0 to change, 0 to destroy.
Сертифікат в AWS ACM
Далі для Ingress та ALB нам потрібно створити сертифікат під цей DNS:
module "ops_phoenix_acm" {
source = "terraform-aws-modules/acm/aws"
version = "~> 6.0"
# 'phoenix.ops.example.co'
domain_name = local.phoenix_domain_name
zone_id = data.aws_route53_zone.ops.zone_id
validation_method = "DNS"
wait_for_validation = true
tags = {
Name = local.phoenix_domain_name
}
}
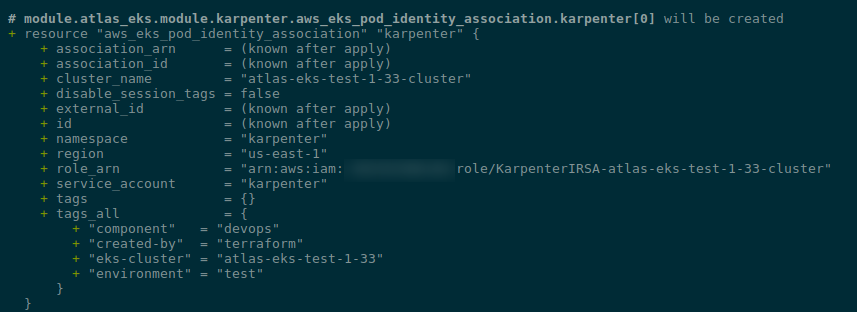
Записи в AWS Secrets Manager
Сікретів для Phoenix нас буде кілька:
PHOENIX_DEFAULT_ADMIN_INITIAL_PASSWORD: пароль при сетапіPHOENIX_ADMIN_SECRET: пароль після сетапу- чесно тут не дуже зрозумів, бо навіть якщо відразу створити і передати
PHOENIX_ADMIN_SECRET– то перший логін все одно буде зPHOENIX_DEFAULT_ADMIN_INITIAL_PASSWORD
- чесно тут не дуже зрозумів, бо навіть якщо відразу створити і передати
PHOENIX_SECRET: для підпису JWT-токенів (писав давно, але все ще актуально – Kubernetes: ServiceAccounts, JWT-tokens, authentication, and RBAC authorization)PHOENIX_POSTGRES_PASSWORD: пароль доступу до сервера баз даних
Сікрети в AWS будемо робити з ephemeral та write-only, див. Terraform: використання Ephemeral resources та Write-only attributes.
Описуємо перший сікрет:
# auth.defaultAdminPassword or PHOENIX_DEFAULT_ADMIN_INITIAL_PASSWORD
# PHOENIX_ADMIN_SECRET
# PHOENIX_SECRET: A long string value that is used to sign JWTs for your deployment.
# PHOENIX_POSTGRES_PASSWORD
# PHOENIX_SMTP_PASSWORD
##############################################
### PHOENIX_DEFAULT_ADMIN_INITIAL_PASSWORD ###
##############################################
# generate a random password
ephemeral "random_password" "ops_phoenix_default_admin_initail_secret_random_password" {
length = 12
special = true
}
# create an AWS Secret resource
resource "aws_secretsmanager_secret" "ops_phoenix_default_admin_initial_secret" {
name = "/ops/phoenix/phoenix_default_admin_initial_secret"
description = "Default Phoenix admin username and password"
recovery_window_in_days = 0
}
# create an AWS Secret value
resource "aws_secretsmanager_secret_version" "ops_phoenix_default_admin_initial_secret_version" {
secret_id = aws_secretsmanager_secret.ops_phoenix_default_admin_initial_secret.id
secret_string_wo = ephemeral.random_password.ops_phoenix_default_admin_initail_secret_random_password.result
secret_string_wo_version = 1
}
Деплоїмо, перевіряємо Route 53, ACM та Secrets Manager:

Повторюємо для решти – вони всі більш-менш однакові, тільки в деяких просто пароль, в деяких логін:пароль в JSON, і різна довжина.
Бо, наприклад, для PHOENIX_ADMIN_SECRET є перевірка на кількість символів:
... atlas-phoenix-6865f69ffc-k7hwl:phoenix File "/phoenix/env/phoenix/config.py", line 772, in get_env_phoenix_admin_secret atlas-phoenix-6865f69ffc-k7hwl:phoenix REQUIREMENTS_FOR_PHOENIX_SECRET.validate(phoenix_admin_secret, "Phoenix secret") atlas-phoenix-6865f69ffc-k7hwl:phoenix File "/phoenix/env/phoenix/auth.py", line 255, in validate atlas-phoenix-6865f69ffc-k7hwl:phoenix raise ValueError(err_text) atlas-phoenix-6865f69ffc-k7hwl:phoenix ValueError: Phoenix secret must be at least 32 characters long ....
Описуємо ресурси:
...
############################
### PHOENIX_ADMIN_SECRET ###
############################
# generate a random password
ephemeral "random_password" "ops_phoenix_admin_secret_random_password" {
length = 32
special = true
}
# create an AWS Secret resource
resource "aws_secretsmanager_secret" "ops_phoenix_admin_secret" {
name = "/ops/phoenix/phoenix_admin_secret"
description = "Phoenix admin username and password"
recovery_window_in_days = 0
}
# create an AWS Secret value
resource "aws_secretsmanager_secret_version" "ops_phoenix_admin_secret_version" {
secret_id = aws_secretsmanager_secret.ops_phoenix_admin_secret.id
secret_string_wo = jsonencode({
login = "admin@localhost"
password = ephemeral.random_password.ops_phoenix_admin_secret_random_password.result
})
secret_string_wo_version = 3
}
######################
### PHOENIX_SECRET ###
######################
# generate a random password
ephemeral "random_password" "ops_phoenix_secret_random_password" {
length = 65
special = false
}
# create an AWS Secret resource
resource "aws_secretsmanager_secret" "ops_phoenix_secret" {
name = "/ops/phoenix/phoenix_secret"
description = "Phoenix secret string used to sign JWTs"
recovery_window_in_days = 0
}
# create an AWS Secret value
resource "aws_secretsmanager_secret_version" "ops_phoenix_secret_version" {
secret_id = aws_secretsmanager_secret.ops_phoenix_secret.id
secret_string_wo = ephemeral.random_password.ops_phoenix_secret_random_password.result
secret_string_wo_version = 1
}
#################################
### PHOENIX_POSTGRES_PASSWORD ###
#################################
# generate a random password
ephemeral "random_password" "ops_phoenix_postgres_random_password" {
length = 12
special = false
}
# create an AWS Secret resource
resource "aws_secretsmanager_secret" "ops_phoenix_postgres_credentials" {
name = "/ops/phoenix/phoenix_postgres_credentials"
description = "Phoenix PostgreSQL username and password"
recovery_window_in_days = 0
}
# create an AWS Secret value
resource "aws_secretsmanager_secret_version" "ops_phoenix_postgres_credentials_version" {
secret_id = aws_secretsmanager_secret.ops_phoenix_postgres_credentials.id
secret_string_wo = ephemeral.random_password.ops_phoenix_postgres_random_password.result
secret_string_wo_version = 3
}
#############################
### PHOENIX_SMTP_PASSWORD ###
#############################
# generate a random password
ephemeral "random_password" "ops_phoenix_smtp_password_random_password" {
length = 12
special = false
}
# create an AWS Secret resource
resource "aws_secretsmanager_secret" "ops_phoenix_smtp_password" {
name = "/ops/phoenix/ops_phoenix_smtp_password"
description = "Phoenix secret string used to sign JWTs"
recovery_window_in_days = 0
}
# create an AWS Secret value
resource "aws_secretsmanager_secret_version" "ops_phoenix_smtp_password_version" {
secret_id = aws_secretsmanager_secret.ops_phoenix_smtp_password.id
secret_string_wo = ephemeral.random_password.ops_phoenix_smtp_password_random_password.result
secret_string_wo_version = 2
}
З Terraform все, можемо готувати базу Postgres.
PostgreSQL user and database
Сервер у нас вже є, тому зараз просто створити базу і юзера.
Підключаємось до RDS:
$ export PGPASSWORD='***' $ psql -h db.monitoring.ops.example.co -U ops_monitoring_user -d ops_grafana_db psql (17.6, server 16.8) ... ops_grafana_db=>
Створюємо юзера, базу, даємо повний доступ до цієї бази:
ops_grafana_db=> CREATE USER ops_phoenix_user WITH PASSWORD '***'; CREATE ROLE ops_grafana_db=> CREATE DATABASE ops_phoenix_db OWNER ops_phoenix_user; CREATE DATABASE ops_grafana_db=> GRANT ALL PRIVILEGES ON DATABASE ops_phoenix_db TO ops_phoenix_user; GRANT
І тепер саме цікаве – Helm.
Деплой Helm
Для отримання паролів з AWS Secrets Manager будемо використовувати External Secrets Operator (див. AWS: Kubernetes та External Secrets Operator для AWS Secrets Manager), для цього нам треба буде в чарт додати власні файли.
Тому робимо новий чарт в якому через Helm Dependency використовуємо чарт Arize Phoenix.
Описуємо Chart.yaml – і отут буде проблема з Docker Hub, див. далі.
Пишемо файл:
apiVersion: v2 name: atlas-phoenix description: A Helm chart for Arize Phoenix stack type: application version: 0.1.1 appVersion: "1.17.0" dependencies: - name: phoenix version: ~4.0 repository: oci://registry-1.docker.io/arizephoenix/phoenix-helm
Тепер робимо helm dependency update, і ловимо “response status code 401” від Docker Hub:
... Update Complete. ⎈Happy Helming!⎈ Error: could not retrieve list of tags for repository oci://registry-1.docker.io/arizephoenix/phoenix-helm: GET "https://registry-1.docker.io/v2/arizephoenix/phoenix-helm/phoenix/tags/list": response status code 401: unauthorized: authentication required: [map[Action:pull Class: Name:arizephoenix/phoenix-helm/phoenix Type:repository]]
Тому що Helm при dependency update намагається отримати всі доступні теги з tags/list, а в Docker Hub для цього потрібно залогінитись.
Логінитись туди я і не хочу, і це зламає можилу майбутню автоматизацію, тому робимо костиль.
Пишемо Makefile в якому додаємо таргет на helm pull oci://:
helm-oci-pull: mkdir -p charts/ && cd charts/ && helm pull oci://registry-1.docker.io/arizephoenix/phoenix-helm \ --version 4.0.4 \ --untar helm-template-ops-1-33: helm -n ops-phoenix-ns template .
Редагуємо Chart.yml, в repository задаємо значення з file://charts/:
apiVersion: v2 name: atlas-phoenix description: A Helm chart for Arize Phoenix stack type: application version: 0.1.1 appVersion: "1.17.0" dependencies: - name: phoenix-helm repository: file://charts/phoenix
Пулимо чарт:
$ make helm-oci-pull mkdir -p charts/ && cd charts/ && helm pull oci://registry-1.docker.io/arizephoenix/phoenix-helm \ --version 4.0.4 \ --untar Pulled: registry-1.docker.io/arizephoenix/phoenix-helm:4.0.4 Digest: sha256:c5692ed16ea9de346e91181c1afc2a0294af0b7f9e3dc3e13d663ee4a00ace1e
І перевіримо, що все нормально рендериться:
$ make helm-template-ops-1-33
helm -n ops-phoenix-ns template .
---
# Source: atlas-phoenix/charts/phoenix-helm/charts/postgresql/templates/secureconfig.yaml
apiVersion: v1
kind: Secret
metadata:
name: release-name-postgresql
labels:
helm.sh/chart: postgresql-1.5.8
app.kubernetes.io/name: postgresql
app.kubernetes.io/instance: release-name
app.kubernetes.io/version: "17.6"
app.kubernetes.io/managed-by: Helm
...
Додавання values
Створюємо директорії і файл з параметрами для поточного кластеру EKS 1.33:
$ mkdir -p values/ops $ touch values/ops/atlas-phoenix-ops-1-33-values.yaml
Заносимо значення – і власні, далі їх будемо використовувати, і для phoenix-helm:
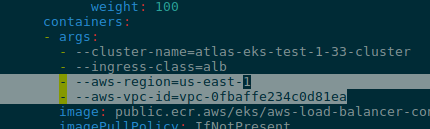
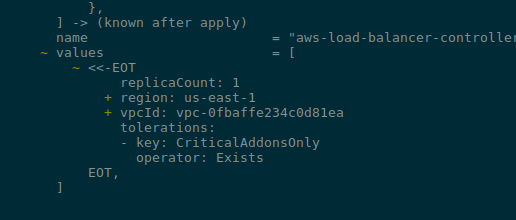
aws:
region: "us-east-1"
config:
env: "ops"
phoenix-helm:
auth:
# Kubernetes Secret name
name: phoenix-secret
Kubernetes Secrets з External Secrets Operator
Створюємо каталог для власних файлів і файл для ESO SecretStore:
$ mkdir templates/ $ touch templates/secretstore.yaml
Описуємо SecretStore та ExternalSecret, який створить Kubernetes Secret з ім’ям phoenix-secret:
apiVersion: external-secrets.io/v1beta1
kind: SecretStore
metadata:
name: phoenix-secret-store
spec:
provider:
aws:
service: SecretsManager
region: {{ .Values.aws.region }}
---
# the ExternalSecret resource is used to:
# 1. authentificate in AWS using the SecretStore defined above
# 2. get data from the AWS ParameterStore
# 3. create a Kubernetes Secret
apiVersion: external-secrets.io/v1beta1
kind: ExternalSecret
metadata:
name: phoenix-external-secret
spec:
refreshInterval: 5m
secretStoreRef:
name: phoenix-secret-store
kind: SecretStore
target:
# Kubernetes Secret name
# will be mounted to Poenix Pods
# .Values.phoenix.auth.name
name: phoenix-secret
creationPolicy: Owner
deletionPolicy: Delete
data:
# key in the Kubernetes Secret
# i.e. the variable name in a Pod
- secretKey: PHOENIX_DEFAULT_ADMIN_INITIAL_PASSWORD
remoteRef:
key: "/{{ .Values.config.env }}/phoenix/phoenix_default_admin_initial_secret"
- secretKey: PHOENIX_ADMIN_SECRET
remoteRef:
key: "/{{ .Values.config.env }}/phoenix/phoenix_admin_secret"
property: password
- secretKey: PHOENIX_SECRET
remoteRef:
key: "/{{ .Values.config.env }}/phoenix/phoenix_secret"
- secretKey: PHOENIX_POSTGRES_PASSWORD
remoteRef:
key: "/{{ .Values.config.env }}/phoenix/phoenix_postgres_credentials"
# make it empty
- secretKey: PHOENIX_SMTP_PASSWORD
remoteRef:
key: "/{{ .Values.config.env }}/phoenix/ops_phoenix_smtp_password"
Створюємо Kubernetes Namespace:
$ kk create ns ops-phoenix-ns namespace/ops-phoenix-ns created
Деплоїмо чарт і перевіряємо ресурси – SecretStore:
$ kk get SecretStore phoenix-secret-store NAME AGE STATUS CAPABILITIES READY phoenix-secret-store 14m Valid ReadWrite True
ExternalSecret:
$ kk get externalsecret NAME STORE REFRESH INTERVAL STATUS READY phoenix-external-secret phoenix-secret-store 5m SecretSynced True
Та Kubernetes Secret:
$ kk get secret NAME TYPE DATA AGE phoenix-secret Opaque 1 2m15s
Перевіряємо дані в ньому:
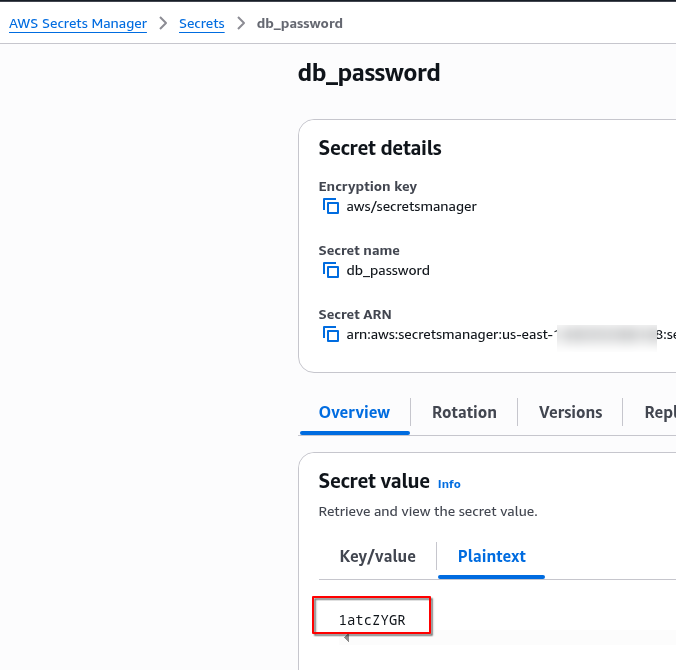
$ kk get secret phoenix-secret -o yaml apiVersion: v1 data: PHOENIX_ADMIN_SECRET: RnB***lY= PHOENIX_DEFAULT_ADMIN_INITIAL_PASSWORD: P0Z***Tp6 PHOENIX_POSTGRES_PASSWORD: TWo***Uty PHOENIX_SECRET: OVJ***FI= PHOENIX_SMTP_PASSWORD: NXR***VlK kind: Secret ...
Отримуємо реальні значення з base64 -d:
$ echo NXR***VlK | base64 -d 5tgdKoDr9YYJ
Звіряємо з даними в AWS Secrets Manager.
Підключення до PostgreSQL
В values додаємо параметри для Postgres:
...
phoenix-helm:
auth:
# Kubernetes Secret name
name: phoenix-secret
# use AWS RDS instead of deploying local
postgresql:
enabled: false
database:
postgres:
host: db.monitoring.ops.example.co
user: ops_phoenix_user
db: ops_phoenix_db
...
Деплоїмо, перевіряємо:

Налаштування Ingress
Сам Ingress enabled by default, тому нам треба тільки додати атрибути, через які він “замапиться” на наш загальний AWS Application Load Balancer через анотацію alb.ingress.kubernetes.io/group.name.
Але і тут є нюанс: в чарті нема можливості задати spec.ingressClassName="alb".
Тому робимо трохи deprecated way, теж через annotations:
...
ingress:
enabled: true
host: phoenix.ops.example.co
tls:
enabled: true
annotations:
alb.ingress.kubernetes.io/group.name: ops-1-33-external-alb
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:us-east-1:492***148:certificate/e7145895-9506-4683-a56a-ba6bf98596c5
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/actions.ssl-redirect: '{"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_301"}}'
kubernetes.io/ingress.class: alb
...
Ну і власне на цьому все.
Все завелось, все (поки що) працює.
Перший логін робимо з паролем PHOENIX_DEFAULT_ADMIN_INITIAL_PASSWORD, далі Phoenix запросить його змінити – задаємо наш із PHOENIX_ADMIN_SECRET, віддаємо девелоперам на погратись:

Готово.
![]()
 Дебажимо одну проблему з використанням пам’яті в Kubernetes Pods, і вирішили подивитись на пам’ять і кількість процесів на нодах.
Дебажимо одну проблему з використанням пам’яті в Kubernetes Pods, і вирішили подивитись на пам’ять і кількість процесів на нодах.