Для тих, хто не слідкує за апдейтами в Telegram-каналі rtfmcoua або просто перший раз зайшов на мій блог – нагадаю, що останні пару місяці збираю такий собі “self-hosted home stack”, в якому вже є пара MikroTik і ThinkCentre з FreeBSD.
До цього всього щастя вирішив ще додати окрему машинку під mini-monitoring, плюс там захостити системи типу Glance (див. Glance: налаштування self-hosted home page для браузера), бо ThnikCentre під час довгих блекаутів виключаю (хоча там споживання всього близько 20 Вт-год).
Ну і… Колись пробував Arduino – класно штука, але далі “Hello, World” діло не пішло (принаймні поки що), да і якісь системи типу Uptime Kuma на Arduino не захостиш.
Давно хотів спробувати погратись з Raspberry Pi, тільки раніше не міг придумати “а нахуа?” – і ось, нарешті, з’явилась відповідь на це велике питання.
Вибір Raspberry Pi
Чесно – я особо не вибирав 🙂
Точніше, вибирав, бо “вау, кросівєнько!” – десь випадково побачив Raspberry Pi Compute Module 4 PoE Mini-Computer, уявив, як він класно став би в мою серверну шафу – і вирішив взяти його.
Виглядає він ось так:
Є більш нові Compute Module версії 5 – але для моїх цілей, до того ж для першого досвіду, 4 версії вистачить з головою.
Купував в магазині https://minicomp.com.ua – не реклама, але магазин наче нормальний, відправили швидко, підтримка по телефону/Telegram працює, нарікань нуль.
[setevoy@setevoy-work ~] $ cd ~/Downloads/Rasp/
[setevoy@setevoy-work ~] $ tar xfp debian-13-raspi-arm64-daily.tar.xz
В архіві лежить disk.raw – це повний образ диска з вже готовим GPT/MBR та boot partition:
[setevoy@setevoy-work ~] $ fdisk -l ~/Downloads/Rasp/disk.raw
Disk /home/setevoy/Downloads/Rasp/disk.raw: 3 GiB, 3221225472 bytes, 6291456 sectors
...
Disklabel type: gpt
Disk identifier: 580A523C-E6C1-4021-8A56-D664D3C75FA2
Device Start End Sectors Size Type
/home/setevoy/Downloads/Rasp/disk.raw1 1048576 6289407 5240832 2.5G Linux root (ARM-64)
/home/setevoy/Downloads/Rasp/disk.raw15 2048 1048575 1046528 511M EFI System
Partition table entries are not in disk order.
Підключення USB до ноутбука
Отуто теж трохи витратив часу, бо дуже незвична і ніфіга не очевидна схема перемикання на завантаження по USB.
Навіть якась ностальгія по часам, коли на HDD перемикав джампери Primary/Slave.
Картинка для тих, хто не бачив це наживо
На моємо CM4 піни для включення завантаження з USB знайшлись отут:
Зайвого джамперу не було, але можна взяти з FAN/VDD:
Перемикаємо джампер, підключаємо звичайним USB-кабелем до ноутбука, перевіряємо девайси – має з’явитись Broadcom:
[setevoy@setevoy-work ~] $ lsusb | grep Broa
Bus 003 Device 024: ID 0a5c:2711 Broadcom Corp. BCM2711 Boot
Встановлюємо rpiusbboot – утиліта підключиться до Raspberry Pi Compute Module та змонтує її eMMC (embedded MultiMediaCard) диск до ноутбука як звичайну флешку:
[setevoy@setevoy-work ~] $ yay -S rpiusbboot
Запускаємо:
[setevoy@setevoy-work ~] $ sudo rpiusbboot
RPIBOOT: build-date Feb 12 2026 version 20221215~105525 b41ab04a
Waiting for BCM2835/6/7/2711...
Loading embedded: bootcode4.bin
Sending bootcode.bin
Successful read 4 bytes
Waiting for BCM2835/6/7/2711...
Loading embedded: bootcode4.bin
Second stage boot server
Cannot open file config.txt
Cannot open file pieeprom.sig
Loading embedded: start4.elf
File read: start4.elf
Cannot open file fixup4.dat
Second stage boot server done
Тепер маємо новий диск в системі:
[setevoy@setevoy-work ~] $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 1 29.1G 0 disk
[setevoy@setevoy-work ~] $ ssh 192.168.0.61
...
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
setevoy@raspberrypi:~ $
setevoy@raspberrypi:~ $ nmcli device status
DEVICE TYPE STATE CONNECTION
eth0 ethernet connected Wired connection 1
lo loopback connected (externally) lo
І виконуємо або sudo nmcli device reapply eth0, або sudo nmcli device disconnect eth0 && sudo nmcli device connect eth0, або просто reboot – і тепер можемо підключатись за новою адресою:
[setevoy@setevoy-work ~] $ ssh 192.168.0.5
...
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Thu Feb 12 11:54:41 2026 from 192.168.0.3
setevoy@raspberrypi:~ $
Можна відразу на MikroTik додати новий DNS record:
/ip dns static add name=pi.setevoy address=192.168.0.5 ttl=1d
Є така прикольна штука, як self-hosted home pages.
Колись побачив їх десь на Reddit, зберіг в закладки, і ось тепер, як в мене є всяка self-hosted тема з NAS (див. FreeBSD: Home NAS, part 1), Grafana і іншими корисними в роботі і побуті речами – то подумав, що було б непогано зробити і собі таку дашборду.
Але Homepage якась більш важка, з купою компонентів – фронтенд, бекенд, якісь рендери, а Glance – простіша, і при цьому, в принципі, має все, що я хотів побачити – хоча місцями це робиться через костилі 🙂
Власне – налаштування Glance.
Робити поки буду локально на ноутбуці з Docker Compose, пізніше перенесу конфіг або на FreeBSD/NAS чи на Raspberry PI з Debian.
Коротко – приклад того, як це все можна налаштувати.
Так як в мене це все хоститься локально і кудись в GitHub я конфіг зберігати не буду – то всякі токени записав прямо в конфіг, але взагалі для них можна використати змінні оточення – див. Other ways of providing tokens/passwords/secrets.
Перша сторінка – Home з трьома колонками:
Clock, Weather, Calendar
Час, погода і календар:
...
pages:
- name: Home
columns:
# ---------- LEFT ----------
- size: small
widgets:
- type: clock
hour-format: 24h
timezones:
- timezone: Asia/Bangkok
label: Chiang Mai
- timezone: America/New_York
label: New York
- type: weather
location: Kyiv
units: metric
- type: calendar
...
В clock віджеті додав ще дві зони – бо в США у нас частина розробників, а в Chiang Mai – розробник один, але часто з ним спілкуюсь і постійно згадую яка в нього зараз година.
Центрально колонка – з типом full, і для кожної page треба мати як мінімум одну колонку з full.
Для вибору color можна скористатись colorpicker.dev: перша цифра – сам колір, друга – saturation (насиченість), третя – lightness (яскравість).
Group для Reddit
Далі приклад групування з Group – зробив собі окремі вкладки для різних сабредітів, але двома окремими групами – умовний “Reddit Ukraine” і “Reddit IT”:
І далі ще буде приклад з власним міні-API сервісом.
Monitor – статуси HTTP-сервісів
Віджет monitor – прикольна штука для відображення статусу сервісів, робить простий GET-запит на вказаний URL, ну і працює (принаймні поки що) тільки з HTTP/S:
Можна було б в glance_api.py додати і виконання дій через POST – але я не став заморачуватись, та і виконувати команди з дашборди – це вже трохи занадто.
Взагалі в портах є інший експортер – py-prometheus-zfs, але я вже зробив з цим, і вийшло наче непогане – і цікаве – рішення, тому збережу в блог те, як це налаштував.
Отже, у нас є GitHub репозиторій експортеру, в репозиторії є релізи, де можна скачати готовий білд – але не всі підтримують готові файли для FreeBSD.
Зато у всіх є код, і більшість сервісі на Go – тому їх легко зібрати самому.
Ідея доволі проста:
скрипт build.sh: завантажити або оновити код експортеру
Makefile: для запуску build.sh та копіювання файлу самого експортеру і його rc.d скрипта
Створюємо структуру каталогів:
# mkdir -p /opt/exporters/zfs_exporter/{rc.d,src}
Створення build.sh
Додаємо скрипт – він буде клонити репозиторій і виконувати go build.
Не став заморачуватись з файлом VERSION – просто беремо master бранч, і білдимо з нього.
Пишемо /opt/exporters/zfs_exporter/build.sh:
#!/bin/sh
# stop on first error
set -e
BASE_DIR="/opt/exporters/zfs_exporter"
SRC_DIR="${BASE_DIR}/src/zfs_exporter"
BIN_NAME="zfs_exporter"
REPO_URL="https://github.com/pdf/zfs_exporter.git"
# ensure src dir exists
mkdir -p "${BASE_DIR}/src"
# clone repo if it does not exist
if [ ! -d "${SRC_DIR}" ]; then
git clone "${REPO_URL}" "${SRC_DIR}"
fi
cd "${SRC_DIR}"
# always update sources
git pull
# build binary into BASE_DIR
go build -o "${BASE_DIR}/${BIN_NAME}"
Задаємо права на запуск:
# chmod +x /opt/exporters/zfs_exporter/build.sh
Запускаємо:
# /opt/exporters/zfs_exporter/build.sh
Перевіряємо:
# ll /opt/exporters/zfs_exporter/src/
total 8
drwxr-xr-x 6 root setevoy 512B Feb 9 13:32 zfs_exporter
# cd /opt/exporters/zfs_exporter
# make build
// або
# make -C /opt/exporters/zfs_exporter build
// або
# make -f /opt/exporters/zfs_exporter/Makefile build
# curl -s localhost:9134/metrics | grep zfs_ | head -5
# HELP zfs_dataset_available_bytes The amount of space in bytes available to the dataset and all its children.
# TYPE zfs_dataset_available_bytes gauge
zfs_dataset_available_bytes{name="nas",pool="nas",type="filesystem"} 2.723599372288e+12
zfs_dataset_available_bytes{name="nas/backups",pool="nas",type="filesystem"} 2.723599372288e+12
zfs_dataset_available_bytes{name="nas/media",pool="nas",type="filesystem"} 2.723599372288e+12
VMAgent описував в попередньому пості в частині Установка VMAgent – додаємо до нього збір метрик з нового експортеру.
Редагуємо /usr/local/etc/prometheus/prometheus.yml, додаємо новий таргет:
Перевіряємо файл /var/tmp/node_exporter/process_resources.prom з метриками:
# cat /var/tmp/node_exporter/process_resources.prom
# HELP local_process_memory_bytes resident memory size per process
# TYPE local_process_memory_bytes gauge
# HELP local_process_cpu_percent cpu usage percent per process
# TYPE local_process_cpu_percent gauge
# HELP node_cpu_temperature_celsius CPU/system temperature via ACPI
# TYPE node_cpu_temperature_celsius gauge
local_process_memory_bytes{process="jellyfin"} 456441856
...
local_process_cpu_percent{process="syslogd"} 0.00
node_cpu_temperature_celsius 27.9
І експортер з нього імпортує метрики:
Додаємо скрипт в cron, раз на хвилину буде достатньо:
Бо листи приходять кожного дня, а читати пошту локально незручно:
# mail -u root -H
Mail version 8.1 6/6/93. Type ? for help.
"/var/mail/root": 58 messages 58 unread
...
U 57 root@setevoy-nas Sun Feb 8 03:19 46/1300 "setevoy-nas daily security run output"
U 58 root@setevoy-nas Sun Feb 8 03:19 99/3444 "setevoy-nas daily run output"
Аби їх отримувати на зовнішній ящик – додаємо Mail Transport Agent (MTA), який буде робити відправку на задану адресу.
Цікаво запустити стандартний стек з VictoriaMetrics + Grafana + Alertmanager не у звичному Kubernetes з Helm-чарту, а просто на хості.
Але підхід той самий, з яким моніторяться сервіси в AWS/Kubernetes – на FreeBSD буде VictoriaMetrics для метрик, Grafana для візуалізації, VMAlert та Alertmanager для алертів.
Хотя в моніторингу моїх EcoFlow зробив алерти через Grafana Alerts, перший раз їх пробував – непогано. Хоча все ж стандартний підхід, коли всі Alert Rules описані в файлах, мені заходить більше.
Всі частини серії по налаштуванню домашнього NAS на FreeBSD:
Оскільки це маленький домашній NAS, до якого доступ тільки в локальній мережі з через VPN – то буду робити без FreeBSD Jails. З ними, може, буду знайомитись ближче іншим разом, бо за всі роки користування FreeBSD (з… 2007 року? десь так) – жодного разу в jails нічого не крутив.
Поїхали.
Установка VictoriaMetrics
VictoriaMetrics є в портах FreeBSD і в репозиторії, хоча порти дещо відрізняються від звичної схеми – далі подивимось ці нюанси.
З репозиторію FreeBSD встановлюємо саму VictoriaMetrics:
Або встановити з Grafaca CLI (перший раз не користувався):
root@setevoy-nas:~ # grafana cli plugins install victoriametrics-metrics-datasource
Grafana-server Init Failed: Could not find config defaults, make sure homepath command line parameter is set or working directory is homepat
Не допомогло.
Ну і потім вже глянув логи Grafana:
...
logger=installer.fs t=2026-02-06T17:09:29.946038823+02:00 level=info msg="Downloaded and extracted victoriametrics-metrics-datasource v0.21.0 zip successfully to /var/db/grafana/plugins/victoriametrics-metrics-datasource"
logger=plugins.backend.start t=2026-02-06T17:09:30.466419686+02:00 level=error msg="Could not start plugin backend" pluginId=victoriametrics-metrics-datasource error="fork/exec /var/db/grafana/plugins/victoriametrics-metrics-datasource/victoriametrics_metrics_backend_plugin_freebsd_amd64: no such file or directory"
...
“victoriametrics_metrics_backend_plugin_freebsd_amd64: no such file or directory”
Oh, c’mon…
Не став розбиратись далі – просто можемо використати стандартний плагін Prometheus (але пізніше розробників VictoriaMetrics потім за цю проблему спитаю).
Власне, якщо не зраджує пам’ять – то раніше, коли власного плагіну для Grafana у VictoriaMetrics не було, то ми і використовували дефолтний Prometheus, який йде в комплекті до Grafana:
groups:
- name: node-exporter-alerts
rules:
- alert: NodeExporterDown
expr: up{job="node_exporter"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "node_exporter down on {{ $labels.instance }}"
description: "node_exporter is not reachable for more than 1 minute"
Перезапускаємо vmalert:
root@setevoy-nas:~ # service vmalert restart
Для тесту зупиняємо node_exporter:
root@setevoy-nas:~ # service node_exporter stop
Stopping node_exporter.
Waiting for PIDS: 1965.
І отримуємо алерт в VMAlert:
І повідомлення від ntfy.sh.
На телефоні:
Або в web:
Тюнинг Grafana dashboard та node_exporter Memory graphs
Дефолтна дашборда заточена під Linux, і на FreeBSD для правильного відображення графіків у Memory Basic треба трохи затюнити запити і метрики.
Перевіряємо наявні метрики по memory від node_exporter:
Давно подумував спробувати MikroTik, але все якось було ліньки розбиратись з RouterOS.
Нарешті, на хвилі зборки Home NAS проекту (див. початок в FreeBSD: Home NAS, part 1 – налаштування ZFS mirror) таки вирішив, що пора оновити і мережевий стек і замінити простенький TP-Link Archer на щось більш серйозне.
До цього в мене були Linksys E4200 (2012-2020), потім з’явився Linksys EA6350 (2020-2024), і останнім був TP-Link Archer AX12 (2024-2025), і коли я перший раз відкрив MikroTik Web UI і подивився можливості… Це як пересісти з Запорожця на Мерседес.
Ну і нарешті – повноцінна консоль і SSH з коробки, а не через кастомні прошивки.
Можливостей в RouterOS дуже багато, тому одним постом по цій темі не обійтись, і в чернетках вже є кілька матеріалів, а почнемо з першого знайомства і початку роботи.
Архітектура моєї мережі
Перш ніж говорити про сам роутер – трохи про мій networking і ролі роутерів MikroTik.
Є дві мережі – “офіс” та дом, в обох “на вході” були TP-Link Archer AX12.
В “офісі” (в лапках, бо це просто сусідня квартира) стоїть ThnikCenter з FreeBSD/NAS, плюс робочий ноутбук і ігровий ПК. В основному всі девайси підключені до роутера кабелями, WiFi тільки для телефону і всяких EcoFlow, робота-пилососа тощо.
Вдома – пара ноутбуків, там вся мережа виключно WiFi.
Обидві мережі об’єднані з VPN, і по старій схемі TP-Link Archer в офісі мав port forwading до WireGuard на FreeBSD, а на FreeBSD були власне WireGuard як хаб та Unbound для локального DNS, плюс всякі Samba/NFS/etc.
Тепер жеж в офісі схема буде іншою:
MikroTik RB4011iGS:
на нього заходить кабель провайдера (оптика через ONU і далі по квартирі з Ethernet на роутер RB4011)
до RB4011iGS кабелями підключені ThinkCentre/NAS, робочий ноутбук та ігровий ПК
MikroTik hAP ax3: підключений кабелем до RB4011, пізніше переключу його в режим Access Point, поки стандартний WiFi роутер з власним NAT
TP-Link Archer AX12: підключений кабелем до RB4011, на ньому нічого не міняю, бо ліньки перепідключати різні домашні девайси типу дверного дзвоника, пожежної сигналізації, EcoFlow, etc
В домашній мережі не міняється нічого окрім налаштувань WireGuard на домашньому ноуті: раніше він через port-forwarding на офісному роутері підключався до FreeBSD, тепер буде ходити до RB4011.
І окремо – сервер самого rtfm.co.ua в DigitalOcean, який (буде) теж підключений з WireGuard до цієї мережі.
Загальна схема буде виглядати приблизно так:
Перше підключення до MikroTik
Боже, який це кайф – мати повноцінний SSH! Але про SSH трохи далі тут і потім ще окремим постом.
Взагалі MikroTik предоставляє кілька варіантів підключення:
Дуже цікава можливість Safe Mode: відкотить зміни, якщо зламали доступ і підключення розірвалось без коректного збереження налаштувань.
В RouteOS є повноцінна консоль, яка складається з ієрархічного дерева команд.
Наприклад, якщо в Web пункт меню IP => Firewall:
То в консолі це буде /ip firewall.
Є повноцінне автодоповнення по Tab:
Після переходу в меню можна з F1 подивитись доступні команди:
В документації говориться, що “?” має виводити підказку теж – але на 7+ версії це вже не працює (Reddit).
Замість “?” просто вибираємо команду, а потім F1 або Tab:
Getting started: перші налаштування
У MikroTik дуже класна документація (привіт, Confluence), і є власний розділ Getting started.
Пройдусь по основним речам, які робив на початку роботи.
Деякі скріни старі, тому ім’я хоста там буде “MikroTik” – дефолтне, далі глянемо, як це міняється.
IP теж може бути старий, дефолтний – 192.168.88.1. зараз він 192.168.0.1. Про налаштування DHCP – в наступному пості.
Backup та restore
У MirkoTik є два варіанти створення бекапу – з /export та /system backup.
/export створить текстовий файл з історією команд який можна прочитати – а /system backup створює бінарний файл, який включає в себе все, в тому числі ключі і сертифікати.
Але якщо конфіг переноситься на інший роутер – то system backup може сфейлитись, бо містить в собі прив’язку до конкретного девайсу, а результат з export – просто виконає команди.
Columns: NAME, VERSION, BUILD-TIME, SIZE
# NAME VERSION BUILD-TIME SIZE
0 routeros 7.18.2 2025-03-11 11:59:04 11.5MiB
Перевіряємо наявність апдейтів:
/system package update check-for-updates
Результат:
[setevoy@MikroTik] > /system package update check-for-updates
channel: stable
installed-version: 7.18.2
latest-version: 7.21
status: New version is available
Завантажуємо – це тільки загрузка:
/system package update download
Результат:
[setevoy@MikroTik] > /system package update download
channel: stable
installed-version: 7.18.2
latest-version: 7.21
status: Downloaded, please reboot router to upgrade it
І запускаємо вже сам процес апгрейду:
/system package update install
Система піде в ребут:
[setevoy@MikroTik] > /system package update install
channel: stable
installed-version: 7.18.2
latest-version: 7.21
status: calculating download size...
Received disconnect from 192.168.88.1 port 22:11: shutdown/reboot
Disconnected from 192.168.88.1 port 22
[setevoy@MikroTik] > /system routerboard upgrade
Do you really want to upgrade firmware? [y/n]
y
[setevoy@MikroTik] >
14:13:58 echo: system,info,critical Firmware upgraded successfully, please reboot for changes to take effect!
Ребутаємо роутер:
[setevoy@MikroTik] > /system reboot
Reboot, yes? [y/N]:
y
system will reboot shortly
Connection to 192.168.88.1 closed.
Distance тут – пріорітет: можна мати друге інтернет-підключення (як я планую – на ethernet port 2 підключити LTE-роутер з SIM-картою), задати йому Distance == 2, і тоді трафік буде йти через перший порт – якщо він доступний, а якщо ні – то через другий.
Інформація по DNS:
/ip dns print
Виконати ping на якийсь хост:
/ping 8.8.8.8 src-address=192.168.0.1
Або traceroute (динамічний, як mtr на Linux/FreeBSD):
/tool traceroute 8.8.8.8
Коректно перезавантажити або виключити:
/system reboot
/system shutdown
Задати ім’я хоста:
/system identity set name=mikrotik-rb4011-gw
Власне, на цьому для початку все.
Що далі? Next steps
Про що ще думаю писати – частина вже є в чернетках, частину буду (якщо буде час) писати з нуля:
налаштування DHCP
налаштування DNS
SSH і firewall – юзери, аутентифікація по ключам, правила фаєрволу
налаштування WireGuard для підключення Peers
scripts, alerting, monitoring – дуже класна можливість писати скрипти, які можуть слати алерти, див. Scripting
Але окрім архівних даних в S3 хочеться мати “offsite hot copy” в Google Drive та AWS S3, аби мати доступ до даних постійно, і які не треба відновлювати із бекапу, а можна просто скопіювати з CLI або навіть з браузера.
При цьому не хочеться розводити зоопарк різних систем, а працювати з одною, яка буде вміти підключатись і до AWS, і до Google Drive.
Власне, під час пошуку того, як з restic копіювати дані в Google Drive знайшов такий собі “швейцарський ніж” – Rclone.
Всі частини серії по налаштуванню домашнього NAS на FreeBSD:
Rclone (“rsync for cloud storage“) – CLI-утиліта, вміє працювати просто з безліччю різних бекендів – і локальними даними або NFS, Samba, і FTP, і WebDAV, і, звісно, AWS S3 та Google Drive, див. всі в Overview of cloud storage systems.
Основні плюшки системи:
написаний на Go
можливість одною CLI отримати доступ до даних в Google Drive та S3
client-side шифрування даних і імен файлів
режими copy та sync, аналогічні rsync
є можливість змонтувати ремоут в локальну директорію, і працювати як зі звичайною папкою з даними (див. rclone mount)
вміє працювати як “проксі” між двома remotes (наприклад, копіювати дані між Google Drive та S3)
Для роботи з Google Drive створимо API keys, і цей процес опишу окремо, бо створення ключів в Google трохи заплутане, і я кожного разу шукаю гайд як це робити.
Переходимо в Google API Console, вибираємо існуючий або створюємо новий проект:
Переходимо в “Branding”, заповнюємо “App information” – задаємо ім’я, це чисто для нас, вказуємо email:
І внизу в “Developer contact information” ще раз пошту:
Зберігаємо, переходимо в “Audience”, перевіряємо, що тут “User type” заданий як External:
Переходимо в “Clients”, потім “Create client”:
Вказуємо “Application type” як Desktop app:
Отримуємо Client ID та Client Secret, зберігаємо собі:
Переходимо до налаштувань підключень вже в самому rclone.
Налаштування Google Drive remote
Виконуємо rclone config, вибираємо “n) New remote“, задаємо ім’я:
...
e/n/d/r/c/s/q> n
Enter name for new remote.
name> nas-google-drive
...
Далі вибираємо з яким бекендом rclone буде працювати.
Для Google Drive це 22 (можна вказати номер, можна ім’я “drive“):
...
22 / Google Drive
\ (drive)
...
Наступний крок аутентифікація – задаємо ключі:
...
Option client_id.
Google Application Client Id
...
Enter a value. Press Enter to leave empty.
client_id> 377***7i7.apps.googleusercontent.com
Option client_secret.
OAuth Client Secret.
Leave blank normally.
Enter a value. Press Enter to leave empty.
client_secret> GOC***gjX
...
Задаємо рівень доступу – тут можна дати або повний доступ до всього драйву, або, якщо rclone буде тільки для бекапів, то вибрати “Access to files created by rclone only”.
На ноутбуках можна задати повний доступ, а на FreeBSD зробимо “тільки для свої файлів”:
В Advanced можна редагувати параметри типу “use_trash” та “Upload chunk size”, але це можна зробити пізніше – зараз просто тиснемо Enter.
Наступний крок – аутентифікація для отримання токену від Google:
...
Use web browser to automatically authenticate rclone with remote?
* Say Y if the machine running rclone has a web browser you can use
* Say N if running rclone on a (remote) machine without web browser access
If not sure try Y. If Y failed, try N.
y) Yes (default)
n) No
Так як це робиться на FreeBSD без браузеру, то вибираємо No –rclone згенерує токен, який треба вказати на машині з браузером, де є інший інстанс rclone:
...
y/n> n
Option config_token.
For this to work, you will need rclone available on a machine that has
a web browser available.
For more help and alternate methods see: https://rclone.org/remote_setup/
Execute the following on the machine with the web browser (same rclone
version recommended):
rclone authorize "drive" "eyJ***ifQ"
Then paste the result.
Enter a value.
Виконуємо на ноуті:
$ rclone authorize "drive" "eyJ***ifQ"
2026/01/07 16:35:38 NOTICE: Make sure your Redirect URL is set to "http://127.0.0.1:53682/" in your custom config.
2026/01/07 16:35:38 NOTICE: If your browser doesn't open automatically go to the following link: http://127.0.0.1:53682/auth?state=Lf9q_HUVFlBUc2UqlSUqpw
2026/01/07 16:35:38 NOTICE: Log in and authorize rclone for access
2026/01/07 16:35:38 NOTICE: Waiting for code...
Відкривається браузер, вибираємо акаунт:
Дозволяємо доступ:
Отримуємо Success:
А на ноут в консолі, з якої викликали rclone authorize прийде токен:
...
2026/01/07 16:35:38 NOTICE: Waiting for code...
2026/01/07 16:37:33 NOTICE: Got code
Paste the following into your remote machine --->
eyJ...ifQ
<---End paste
Копіюємо його до rclone config на FreeBSD хості:
...
Enter a value.
config_token> eyJ***ifQ
...
І нове підключення готове:
...
Configuration complete.
Options:
- type: drive
- client_id: 377***7i7.apps.googleusercontent.com
- client_secret: GOC***gjX
- scope: drive.file
- token: {"access_token":"ya2***","expires_in":3599}
- team_drive:
Keep this "nas-google-drive" remote?
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
root@setevoy-nas:~ # rclone config
Current remotes:
Name Type
==== ====
nas-google-drive drive
e) Edit existing remote
n) New remote
d) Delete remote
r) Rename remote
c) Copy remote
s) Set configuration password
q) Quit config
e/n/d/r/c/s/q> n
Enter name for new remote.
name> nas-s3-setevoy-backups
...
Далі тип – вибираємо 4 (s3), потім 1 – AWS:
...
Option Storage.
Type of storage to configure.
Choose a number from below, or type in your own value.
1 / 1Fichier
\ (fichier)
2 / Akamai NetStorage
\ (netstorage)
3 / Alias for an existing remote
\ (alias)
4 / Amazon S3 Compliant Storage Providers including AWS, Alibaba, ArvanCloud, Ceph, ChinaMobile, Cloudflare, DigitalOcean, Dreamhost, Exaba, FlashBlade, GCS, HuaweiOBS, IBMCOS, IDrive, IONOS, LyveCloud, Leviia, Liara, Linode, Magalu, Mega, Minio, Netease, Outscale, OVHcloud, Petabox, RackCorp, Rclone, Scaleway, SeaweedFS, Selectel, StackPath, Storj, Synology, TencentCOS, Wasabi, Qiniu, Zata and others
\ (s3)
...
Storage> s3
Option provider.
Choose your S3 provider.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / Amazon Web Services (AWS) S3
\ (AWS)
...
Далі вибираємо “Enter AWS credentials in the next step” і задаємо ключі:
...
Option env_auth.
Get AWS credentials from runtime (environment variables or EC2/ECS meta data if no env vars).
Only applies if access_key_id and secret_access_key is blank.
Choose a number from below, or type in your own boolean value (true or false).
Press Enter for the default (false).
1 / Enter AWS credentials in the next step.
\ (false)
2 / Get AWS credentials from the environment (env vars or IAM).
\ (true)
env_auth> 1
Option access_key_id.
AWS Access Key ID.
Leave blank for anonymous access or runtime credentials.
Enter a value. Press Enter to leave empty.
access_key_id> AKI***VXZ
Option secret_access_key.
AWS Secret Access Key (password).
Leave blank for anonymous access or runtime credentials.
Enter a value. Press Enter to leave empty.
secret_access_key> MkP***xJ/
...
Далі регіон бакету – він є в Properties:
Задаємо його:
...
Option region.
Region to connect to.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
/ The default endpoint - a good choice if you are unsure.
1 | US Region, Northern Virginia, or Pacific Northwest.
| Leave location constraint empty.
\ (us-east-1)
...
region> eu-west-1
...
Option endpoint залишаємо без мін, в Option location_constraint ще раз задаємо “eu-west-1“:
Option location_constraint.
Location constraint - must be set to match the Region.
Used when creating buckets only.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / Empty for US Region, Northern Virginia, or Pacific Northwest
\ ()
...
6 / EU (Ireland) Region
\ (eu-west-1)
...
location_constraint> eu-west-1
Option acl можна пропустити – у нас окрема корзина, в якій вже є всі налаштування ACL.
В server_side_encryption вибираємо “AES256“, далі “None“:
...
Option server_side_encryption.
The server-side encryption algorithm used when storing this object in S3.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / None
\ ()
2 / AES256
\ (AES256)
3 / aws:kms
\ (aws:kms)
server_side_encryption> 2
Option sse_kms_key_id.
If using KMS ID you must provide the ARN of Key.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / None
\ ()
2 / arn:aws:kms:*
\ (arn:aws:kms:us-east-1:*)
sse_kms_key_id> 1
...
Option storage_class.
The storage class to use when storing new objects in S3.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / Default
\ ()
...
8 / Intelligent-Tiering storage class
\ (INTELLIGENT_TIERING)
...
storage_class> 8
Зберігаємо – маємо новий бекенд:
...
Edit advanced config?
y) Yes
n) No (default)
y/n>
Configuration complete.
Options:
- type: s3
- provider: AWS
- access_key_id: AKI***VXZ
- secret_access_key: MkP***zxJ/
- region: eu-west-1
- location_constraint: eu-west-1
- server_side_encryption: AES256
- storage_class: INTELLIGENT_TIERING
Keep this "nas-s3-setevoy-backups" remote?
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
y/e/d>
Current remotes:
Name Type
==== ====
nas-google-drive drive
nas-s3-setevoy-backups s3
...
Для роботи з S3 бакетом використовуємо формат remote_name:backet_name.
Створюємо в бакеті файл healthcheck.txt і каталог test – використовуємо rclone rcat:
root@setevoy-nas:~ # echo test | rclone rcat nas-s3-setevoy-backups:setevoy-backups-nas/test/healthcheck.txt
root@setevoy-nas:~ # rclone ls nas-s3-setevoy-backups:setevoy-backups-nas/test
5 healthcheck.txt
Rclone та шифрування
Задля більшої безпеки rclone може шифрувати свій локальний конфігураційний файл, а для безпечного зберігання даних в remote backends – може шифрувати дані там.
crypt створюється як окремий бекенд, але використовує вже існуючий.
Наприклад, маючи nas-google-drive можна створити новий storage backend nas-google-drive-crypted і використовувати його: він буде таким собі “проксі” – ми пишемо дані “в нього”, він виконує шифрування, а потім “під капотом”, аби записати файли в Google Drive, використовує “оригінальний” бекенд nas-google-drive.
Створюємо новий remote:
root@setevoy-nas:~ # rclone config
Current remotes:
Name Type
==== ====
nas-google-drive drive
nas-s3-setevoy-backups s3
e) Edit existing remote
n) New remote
d) Delete remote
r) Rename remote
c) Copy remote
s) Set configuration password
q) Quit config
e/n/d/r/c/s/q> n
Enter name for new remote.
name> nas-google-drive-crypted
В типі вибираємо “15 – Encrypt/Decrypt a remote”:
...
Option Storage.
Type of storage to configure.
Choose a number from below, or type in your own value.
...
15 / Encrypt/Decrypt a remote
\ (crypt)
...
Storage> crypt
Далі вказуємо “source backend”, в якому будуть зашифровані дані.
Тут важливий момент: можна вказати або весь storage як nas-google-drive:Backups/Rclone (корінь для rclone в моєму випадку) – або створити в ньому окремий каталог, в якому будуть зберігатись зашифровані дані:
...
Option remote.
Remote to encrypt/decrypt.
Normally should contain a ':' and a path, e.g. "myremote:path/to/dir",
"myremote:bucket" or maybe "myremote:" (not recommended).
Enter a value.
remote> nas-google-drive:Backups/Rclone/Vault
Далі є варіанти – шифрувати імена файлів і каталогів чи ні, дефолт – шифрувати:
...
Option filename_encryption.
How to encrypt the filenames.
Choose a number from below, or type in your own value of type string.
Press Enter for the default (standard).
/ Encrypt the filenames.
1 | See the docs for the details.
\ (standard)
2 / Very simple filename obfuscation.
\ (obfuscate)
/ Don't encrypt the file names.
3 | Adds a ".bin", or "suffix" extension only.
\ (off)
filename_encryption>
Option directory_name_encryption.
Option to either encrypt directory names or leave them intact.
NB If filename_encryption is "off" then this option will do nothing.
Choose a number from below, or type in your own boolean value (true or false).
Press Enter for the default (true).
1 / Encrypt directory names.
\ (true)
2 / Don't encrypt directory names, leave them intact.
\ (false)
directory_name_encryption>
І останнє – вказати пароль і опціонально salt:
...
Option password.
Password or pass phrase for encryption.
Choose an alternative below.
y) Yes, type in my own password
g) Generate random password
y/g> y
Enter the password:
password:
Confirm the password:
password:
Option password2.
Password or pass phrase for salt.
Optional but recommended.
Should be different to the previous password.
Choose an alternative below. Press Enter for the default (n).
y) Yes, type in my own password
g) Generate random password
n) No, leave this optional password blank (default)
y/g/n>
Готово:
...
Configuration complete.
Options:
- type: crypt
- remote: nas-google-drive:Backups/Rclone/Vault
- password: *** ENCRYPTED ***
Keep this "nas-google-drive-crypted" remote?
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
y/e/d>
Current remotes:
Name Type
==== ====
nas-google-drive drive
nas-google-drive-crypted crypt
nas-s3-setevoy-backups s3
Тепер, якщо скопіюємо туди текстовий файл, то прочитати його зможемо тільки з rclone:
--check-first: виконати перевірку даних між src та dst до початку копіювання
--checksum: порівнювати файл між src та dst не за size+mtime, а по MD5SUM checksum – повільніше, але точніше, корисно для критичних даних
--immutable: не змінювати файл в dst, якщо він відрізняється від src, а впасти з помилкою
--interactive: підтвердження змін вручну
--dry-run: тестове виконання без копіювання
--progress: відобразити процес
--transfers N: кількість файлів, які копіюються одночасно (дефолт 4)
--create-empty-src-dirs: якщо src каталог порожній – то створити порожній каталог в dst (не працює з S3)
--exclude та --exclude-from, --include та --include-from: список або файл зі списком даних, які треба включити або виключити з копіювання, див. Filter
--log-file: куди писати лог (корисно для автоматизації)
--fast-list: створює один великий список директорій і файлів, який тримає в пам’яті, а не для кожної директорії окремо (більше пам’яті – але швидше і менше API-запитів до dst)
--update: пропустити файли, modification time яких на dst новіший, ніж в src
--human-readable: використовувати формат Ki/Mi/Gi
Використання rclone copy та rclone copyto
rclone copy просто копіює файл або директорію до заданого remote.
Якщо src – каталог з підкаталогами, то будуть скопійовані всі дані і збережено структуру каталогів.
Наприклад, маємо локально каталоги з файлами:
root@setevoy-nas:~ # tree /tmp/new/
/tmp/new/
└── another
└── dir
├── a.txt
└── sub
└── b.txt
Вже пару місяців, як на робочому ноуті Lenovo ThinkPad T14 Gen 5 з Arch Linux виникла проблема з відкриттям нових сайтів – перші 10-15 секунд сайт завантажується “шматочками”, наприклад:
Але потім “розчехляється”, і все починає працювати чудово:
І проблема виявилась дуже цікавою. Причину шукав довго, і перепровірив купу різних налаштувань – від IPv6 і DNS до драйверу мережової карти.
Головне, що проблема не те щоб була критичною – в цілому інет працював, а тому я іноді починав шукати причину, потім закидував, потім знов повертався.
The issue: “communications error to 192.168.0.1#53: timed out”
Що цікаво, що проблема спостерігалась тільки на Ethernet-підключені – на WiFi все працювало чудово.
А на Ethernet репродьюсилось на різних кабелях і через різні роутери.
Значить – що? Значить – або Сєня щось наковиряв руками у своєму Linux, або десь колись прилетів “кривий” апдейт чи до ядра, чи до драйвера, чи до якось бібліотеки.
Вже не пам’ятаю чому, але спершу грішив на DNS, бо ми ж знаємо, що:
І такі да – під час спроб зарепродьюсити це вдалось саме з DNS, під час тестів з dig – тому довго копав в цю сторону.
Виглядала проблема так: робимо dig, 10-15 запитів проходять нормально, а потім прилітає “communications error to 192.168.0.1#53: timed out“:
$ time dig google.com +short @192.168.0.1
;; communications error to 192.168.0.1#53: timed out
...
real 0m5.018s
user 0m0.004s
sys 0m0.008s
Ну і це виглядало, як дійсно причина того, що сайти тупили з загрузкою контенту: якщо DNS періодично відвалюється, а сайти мають купу додаткових скриптів і картинок, які підвантажуються з інших ресурсів – то поки всі хости разрезолвляться, поки отримаємо всі адреси, поки почнеться завантаження – як раз маємо цю затримку в кількадесят секунд.
Логічно? Так.
Тому і всі подальше тести я робив вже в циклі з dig:
$ for i in {1..50}; do { time dig +nocookie +noedns +tries=1 +time=2 google.com >/dev/null; } 2>&1; done
...
real 0m0.016s
...
real 0m2.015s
...
real 0m0.013s
...
real 0m1.392s
І такий результат був постійно – пачка запитів проходить нормально – “real 0m0.016s“, а потім на якомусь одному – таймаут і “real 0m2.015s” (бо +time=2 – чекати 2 секунди, а не дефолтні 5).
Ця ж проблема була видна з tcpdump: в 09:57:47 запит відправлений, але відповіді не отримано, через 2 секунди, в 09:57:49 – новий запит, і на нього вже відповідь прийшла:
...
09:57:47.717951 IP setevoy-work.40923 > _gateway.domain: 13058+ [1au] A? google.com. (51)
09:57:49.729589 IP setevoy-work.45441 > _gateway.domain: 63641+ [1au] A? google.com. (51)
09:57:49.730249 IP _gateway.domain > setevoy-work.45441: 63641 6/4/4 A 142.250.109.101, A 142.250.109.100, A 142.250.109.139, A 142.250.109.138, A 142.250.109.102, A 142.250.109.113 (260)
...
Тут в 0.002788 відкритий сокет для відправки запиту, а через 5 секунд (5.005754) – бо зараз dig запускався без +time=2 – відкривається новий сокет для нового запиту, бо на попередній відповіді не було.
В пошуках Немо проблеми
Тут опишу що взагалі перевіряв – квест вийшов той ще.
Хоча записав не все, робив більше, але основне зберіг – вже давно є звичка закидувати в чорнетку поста на RTFM під час дебагу проблем.
Перевірка DNS в Linux
Перше – що з DNS в системі?
В /etc/resolv.conf заданий роутер:
# Generated by NetworkManager
nameserver 192.168.0.1
Міняємо на 1.1.1.1 чи на 8.8.8.8 – проблема залишається.
Окей… Може, в системі ще якийсь активний резолвер, і починається “DNS-гонка в ядрі” – запит “блукає” між ними?
Перевіряємо systemd-resolved – ні, не запущений:
$ systemctl status systemd-resolved
○ systemd-resolved.service - Network Name Resolution
Loaded: loaded (/usr/lib/systemd/system/systemd-resolved.service; disabled; preset: enabled)
Active: inactive (dead)
...
Може, dnsmasq?
Теж виключений:
$ systemctl status dnsmasq
○ dnsmasq.service - dnsmasq - A lightweight DHCP and caching DNS server
Loaded: loaded (/usr/lib/systemd/system/dnsmasq.service; disabled; preset: disabled)
Active: inactive (dead)
...
Значить, DNS-запити йдуть напряму до роутера, і… Що? Тупить роутер з відповідями? До нього не доходять запити – іноді губляться?
Що це може бути?
локальний firewall на Linux чи роутері?
ні – вимикав, проблема залишалась
race між кількома локальними DNS-сервісами?
виключили вище
power management мережевої карти – вона уходить в sleep?
маловірогідно, але далі перевіряв і це
баг драйвера мережевої карти?
можливо, бо проблема з’явилась не так давно, до цього на цьому ноуті і цій системі все працювало без проблем
якісь проблеми конкретно з UDP?
теж ніж – робив dig +tcp google.com, проблема залишалась
відповідь на DNS-запит повертається з іншого IP?
екзотична ідея, але як варіант – на роутері кілька мережевих інтерфейсів, об’єднаних в bridge, і – теоретично – роутер може відправити відповідь з іншої
але це прям щось дуже неординарне, та і проблема виникала однаково на різних роутерах, і раніше її не було
IPv6 та DNS
Не пам’ятаю чому, але десь на початку грішив на IPv6 під час виконання DNS.
/etc/gai.conf керує алгоритмом вибору адрес у glibc (GAI = getaddrinfo()), і визначає яку адресу (IPv4 чи IPv6) програма, яка робила DNS-запит вибере першою у випадку, якщо DNS повернув і A, і AAAA записи.
Можна включити IPv4 first – розкоментувати строку:
...
precedence ::ffff:0:0/96 100
...
Перевіряємо, що повернеться першим – адреса IPv4, чи IPv6:
Тут здавалось, що проблема знайдена – бо перший раз все пройшло без проблем, але ні – потім знов таймаути.
NIC Offloading
NIC Offloading – це коли частина операцій виконується на самому мережевому інтерфейсі, тобто offload деяких задач з CPU ноутбука на контролер карти.
Перевіряємо активні з ethtool -k:
$ sudo ethtool -k enp0s31f6 | grep on
rx-checksumming: on
tx-checksumming: on
tx-checksum-ip-generic: on
scatter-gather: on
tx-scatter-gather: on
tcp-segmentation-offload: on
...
generic-segmentation-offload: on
generic-receive-offload: on
rx-vlan-offload: on
tx-vlan-offload: on
receive-hashing: on
...
Самі цікаві тут:
TSO (TCP Segmentation Offloading): процесор віддає карті один великий шматок даних (наприклад, 64 КБ), а карта сама “нарізає” його на маленькі TCP-пакети по 1500 байт
GSO (Generic Segmentation Offloading): те саме, що й TSO, але більш універсальне (працює не лише для TCP)
GRO (Generic Receive Offloading): зворотний процес – карта отримує багато дрібних пакетів, “склеює” їх в один великий і лише тоді віддає процесору, що економить ресурси CPU
RX та TX Checksum Offloading: карта сама перевіряє контрольні суми (CRC) вхідних пакетів – якщо пакет “битий”, карта його просто викидає, навіть не повідомляючи операційну систему
По черзі вимикаємо їх, і перевіряємо:
sudo ethtool -K enp0s31f6 gro off: не допомогло
sudo ethtool -K enp0s31f6 gso off: не допомогло
sudo ethtool -K enp0s31f6 tso off: не допомогло
sudo ethtool -K enp0s31f6 rx off: не допомогло, і стало навіть гірше
Насправді те, що після відключення RX Checksum Offloading стало гірше – вже було підказкою: якщо до цього мережева карта сама фільтрувала помилки, то тепер вони всі повалили до ядра, що створило додаткове навантаження і хаос у черзі пакетів, тому корисні DNS-відповіді стали губитися ще частіше.
IR-PCI-MSI-0000:00:1f.6 – драйвер використовує MSI (Message Signaled Interrupts), яка начебто на Linux може давати drops для UDP на деяких картах Intel.
rx_crc_errors каже, що проблема з цілісністю пакетів, і – якщо з роутерам і кабелем все в порядку (а проблема спостерігалась на різних роутерах і з різними кабелями) – то скоріш за все проблема в самому RJ-45 на ноутбуці, хоча контакти виглядають нормально.
Спробував примусово зменшити швидкість на інтерфейсі з гігабіта до 100 Mbps:
$ sudo ethtool -s enp0s31f6 speed 100 duplex full autoneg on
І чудо! Все працює!
Повертаємо знов 1000:
$ sudo ethtool -s enp0s31f6 speed 1000 duplex full autoneg on
І проблема знову з’являється.
Можна було б просто залишити 100 Mbps – але ж я не для того підключений по кабелю і плачу за гігабітний GPON?
Благо, вдома є кілька USB-адаптерів з Ethernet, перемкнув кабель на нього:
$ ip a s enp0s13f0u2u3
2: enp0s13f0u2u3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether c8:4d:44:29:27:6b brd ff:ff:ff:ff:ff:ff
altname enxc84d4429276b
inet 192.168.0.198/24 brd 192.168.0.255 scope global dynamic noprefixroute enp0s13f0u2u3
...
Є гігабіт і Full Duplex:
$ sudo ethtool enp0s13f0u2u3
Settings for enp0s13f0u2u3:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
...
Speed: 1000Mb/s
Duplex: Full
...
drv probe link timer ifdown ifup rx_err tx_err tx_queued intr tx_done rx_status pktdata hw wol
Link detected: yes
Власне, по налаштуванню NAS вже зроблено майже все – з VPN є доступи з різних мереж, є різні шари, трохи затюнили безпеку.
Залишилось дві основні речі: моніторинг і бекапи, бо мати ZFS mirror на двох дисках з регулярними ZFS snapshots це, звісно, класно, але все одно недостатньо, а тому хочеться додатково робити бекапи десь в клауд.
Особливо я відчув необхідність мати доступ до бекапів в клаудах на початку війни, коли не ясно було де я опинюсь через годину, і чи буде в мене можливість забрати із собою бодай якесь залізо.
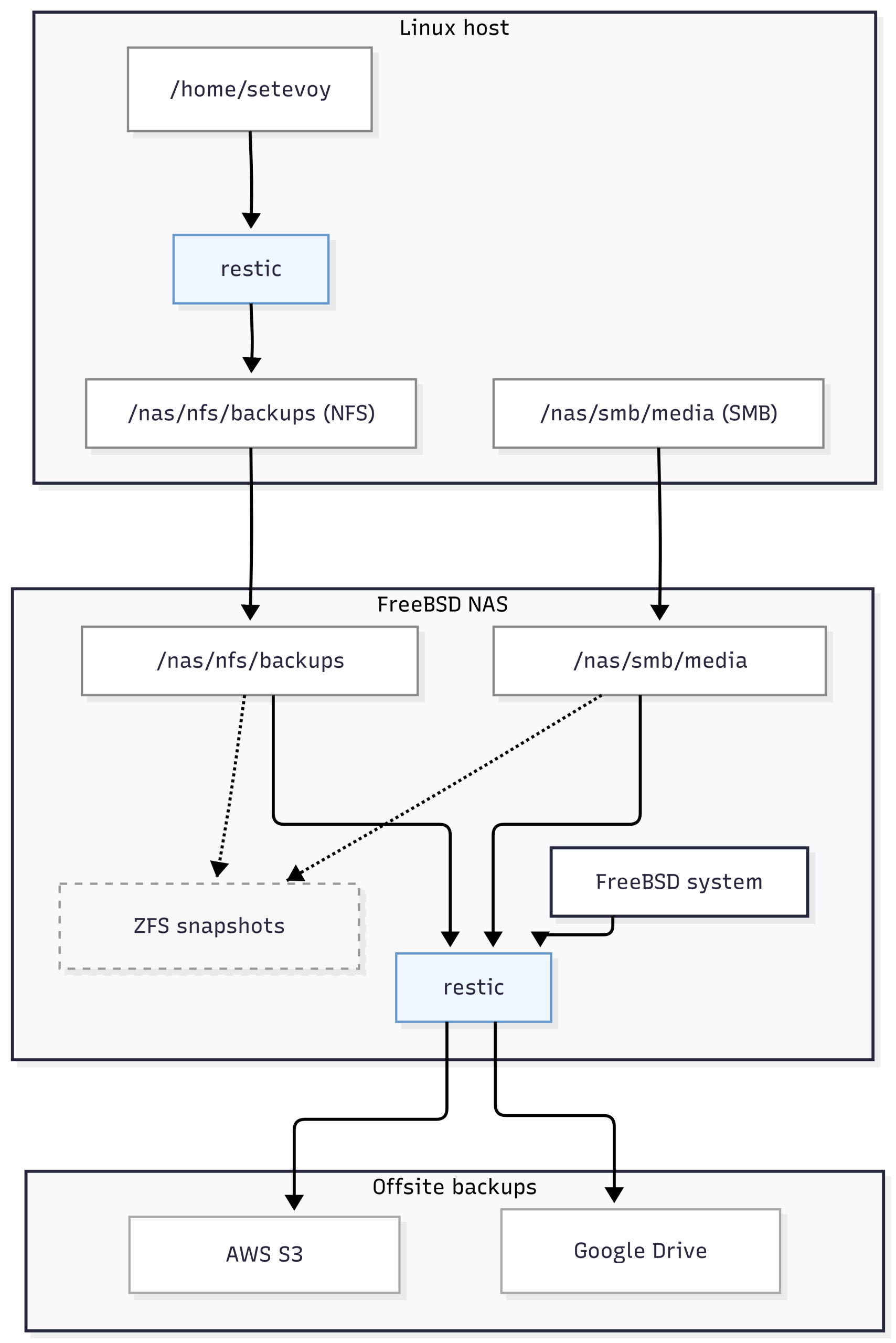
Сьогодні подумаємо і заплануємо як робити бекапи з Linux-хостів на NFS share та як робити бекапи даних NFS і Samba на FreeBSD. При чому бекапи хочеться зробити у два незалежних сховища – AWS S3 та Google Disk: S3 буде основним, а Гугл – резервною копією (резервної копії).
Всі частини серії по налаштуванню домашнього NAS на FreeBSD:
Дані в restic організовані у репозиторіях: кожен репозиторій – це окремий каталог, який містить конфігурацію репозиторію, індекси та зашифровані дані.
Під час створення бекапу restic формує власні логічні snapshots. Дані розбиваються на незалежні блоки (blobs), які і є базовими одиницями зберігання в репозиторії.
При наступних бекапах restic перевіряє, які саме блоки були змінені, і копіює тільки їх, а на блоки даних, які не змінились – створює посилання з нового снапшоту, таким чином оптимізуючи зайнятий дисковий простір.
Тобто тут процес схожий із ZFS snapshots – тільки у ZFS посилання створюється на блоки самої файлової системи і оригінальні дані, а в restic – на власні блоки даних в каталозі репозиторію.
При цьому restic зберігає дані у власному форматі, а тому ми не залежимо від файлової системи – створюємо бекап з ext4, копіюємо на ZFS, зберігаємо в S3, і відновлюємо на упасі боже Windows з NTFS. Єдине, що нам буде треба – це клієнт restic.
Створюємо тестовий репозиторій:
$ restic init --repo test-repo
enter password for new repository:
enter password again:
created restic repository 50ef450308 at test-repo
Перевіряємо зміст:
$ ll test-repo/
total 24
-r-------- 1 setevoy setevoy 155 Jan 1 16:47 config
drwx------ 258 setevoy setevoy 4096 Jan 1 16:47 data
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 index
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 keys
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 locks
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 snapshots
Кожен репозиторій має ключ, який використовується для доступу до зашифрованих даних:
$ restic key list --repo test-repo
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
ID User Host Created
-----------------------------------------------------
*0ca1c659 setevoy setevoy-work 2026-01-01 16:49:49
-----------------------------------------------------
Шифрування даних виконується з master key, який зберігається в репозиторії:
$ restic -r test-repo cat masterkey
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
{
"mac": {
"k": "v1PIB3bB1VW46oWWBtKQYA==",
"r": "Tia4a7HGs7PmN1EzWoWh4g=="
},
"encrypt": "0c3l/00P3dTgdbAqPZApAYn7E/MiloqOXyQsYr6AGOA="
}
Для отримання доступу до якого використовуються дані user keys:
scrypt: KDF (Key Derivation Function), яка використовується для отримання криптографічного ключа з пароля (див. Scrypt Key Derivation Function)
salt: сіль з рандомним значенням
data: зашифрований master key – саме він використовується для шифрування даних
Коли restic потрібно отримати доступ до даних у репозиторії – він бере введений пароль і salt, передає їх у KDF і формує ключ, який використовується для розшифрування master key репозиторію.
Master key, у свою чергу, застосовується для шифрування та розшифрування ключів, якими вже безпосередньо шифруються дані та метадані в репозиторії.
При цьому можна мати кілька різних user keys (або access keys), які будуть використовуватись для отримання master key.
При потребі пароль можна змінити:
$ restic key passwd --repo test-repo/
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
created new cache in /home/setevoy/.cache/restic
enter new password:
enter password again:
saved new key as <Key of setevoy@setevoy-work, created on 2026-01-01 16:49:49.010471345 +0200 EET m=+13.105722833>
При налаштуванні автоматизації бекапів – пароль можна передати зі змінної оточення RESTIC_PASSWORD (див. Environment Variables) або з файлу через --password-file.
Наприклад, для використання паролю з файлу – створимо директорію:
$ restic key add --repo test-repo
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
enter new password:
enter password again:
saved new key with ID c08c993b87363c17526e98fd46aeaf14767fa051e3b0d87a32c0cecc50e361d4
Перевіряємо ключі тепер:
[setevoy@setevoy-work ~/Projects/Restic] $ restic key list --repo test-repo
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
ID User Host Created
-----------------------------------------------------
*0ca1c659 setevoy setevoy-work 2026-01-01 16:49:49
c08c993b setevoy setevoy-work 2026-01-01 17:02:10
-----------------------------------------------------
В *0ca1c659 зірочка показує, що зараз репозиторій відкритий з цим ключем.
Пробуємо відкрити з новим ключем – паролем з файла:
$ restic stats --repo test-repo --password-file ~/.config/restic-test/test-repo-password
repository 50ef4503 opened (version 2, compression level auto)
[0:00] 0 index files loaded
scanning...
Stats in restore-size mode:
Snapshots processed: 0
Total Size: 0 B
Для створення бекапів використовуємо команду restic backup, а для відновлення, власне, restic restore.
Бекапимо файл /tmp/restic-test.txt в наш репозиторій:
$ restic backup /tmp/restic-test.txt --repo test-repo
repository 50ef4503 opened (version 2, compression level auto)
no parent snapshot found, will read all files
[0:00] 0 index files loaded
Files: 1 new, 0 changed, 0 unmodified
Dirs: 1 new, 0 changed, 0 unmodified
Added to the repository: 755 B (687 B stored)
processed 1 files, 13 B in 0:01
snapshot bf8def5f saved
Під час кожного виклику restic backup в репозиторії створюється новий snapshot, навіть якщо дані в source не змінювались.
Але, як писав вище – якщо не змінюються дані, то і розмір репозиторію не росте, бо restic просто створить посилання з нового снапшоту на старі блоки даних.
При зміні частини даних – відповідно будуть створені нові блоки тільки для нових даних, на які буде замаплений цей снапшот, а на незмінні дані – в новому снапшоті залишаться старі посилання.
Перевіряємо наявні снапшоти:
$ restic snapshots --repo test-repo
repository 50ef4503 opened (version 2, compression level auto)
ID Time Host Tags Paths Size
-----------------------------------------------------------------------------------
bf8def5f 2026-01-01 17:07:53 setevoy-work /tmp/restic-test.txt 13 B
-----------------------------------------------------------------------------------
1 snapshots
Основні корисні команди при роботі з репозиторіями та снапшотами:
restic stats: статистика по репозиторію або снапшоту
restic check: перевірка цілісності репозиторію
restic ls: подивитись зміст снапшоту
restic diff: порівняти дані у двох снапшотах
restic copy: скопіювати зміст одного репозиторію в інший
І окремо варто згадати --dry-run – перевірити що саме буде виконуватись, і яких даних торкнеться операція.
Для відновлення даних з бекапу використовуємо restic restore і вказуємо ID снапшоту та куди його відновити.
Якщо в destination каталогу нема – restic його створить, а в ньому відновить ієрархію каталогів та файлів зі снапшоту:
$ restic restore --repo test-repo bf8def5f --target /tmp/test-restic-restore
...
restoring snapshot bf8def5f of [/tmp/restic-test.txt] at 2026-01-01 17:07:53.016664301 +0200 EET by setevoy@setevoy-work to /tmp/test-restic-restore
Summary: Restored 2 files/dirs (13 B) in 0:00
Перевіряємо:
$ tree /tmp/test-restic-restore
/tmp/test-restic-restore
└── tmp
└── restic-test.txt
Include та exclude для backup та restore
При створенні бекапу з restic backup ми вказуємо шлях, який бекапиться, а тому окремої опції --include нема.
Але є --exclude, з яким можна вказати які дані не треба включати в снапшот.
Наприклад, маємо каталог:
$ tree /tmp/restic-dir-test
/tmp/restic-dir-test
├── a.txt
└── sub
└── b.txt
Бекапимо весь цей каталог, але пропускаємо файл a.txt:
--keep-daily 7: залишаємо снапшоти за останні 7 днів
--keep-weekly 4: залишаємо снапшоти за останні 4 тижні (по одному snapshot на тиждень)
--keep-monthly 6: залишаємо снапшоти за останні 6 місяців (по одному snapshot на місяць)
застосовуємо тільки для снапшотів з тегом daily, і відразу видаляємо дані з диску
Restic mount – репозиторій як директорія
Можна змонтувати репозиторій як звичайну папку, монтується тільки в режимі read-only:
$ mkdir /tmp/restic-mounted-test-repo
$ restic mount -r test-repo /tmp/restic-mounted-test-repo
...
Now serving the repository at /tmp/restic-mounted-test-repo
...
$ restic snapshots -r new-test-repo
repository fc8a407c opened (version 2, compression level auto)
ID Time Host Tags Paths Size
-----------------------------------------------------------------------------------------------
7335e7bf 2026-01-04 15:08:41 setevoy-work daily,2026-01-04-15-08 /tmp/restic-dir-test 18 B
-----------------------------------------------------------------------------------------------
Restic та репозиторій в AWS S3
З S3 все більш-менш аналогічно до роботи з локальними репозиторіями, але є деякі нюанси.
Для аутентифікації restic використовує звичайний механізм – пошук змінних оточення AWS_ACCESS_KEY_ID та AWS_SECRET_ACCESS_KEY, або пошук у файлах ~/.aws/config та ~/.aws/credentials.
Важливі нюанси, які треба мати на увазі при роботі з S3:
видаляти дані з репозиторію restic в AWS S3 можна тільки через restic forget та restic prune
використання S3 Lifecycle rules для restic не рекомендується – навіть для зміни storage class
Каталоги (index/, snapshots/, keys/) активно використовуються restic; якщо перенести, наприклад, keys/ у Glacier або Deep Archive – restic може зависати або падати по таймауту, очікуючи доступ до ключів.
Теоретично lifecycle transitions можна застосувати лише до каталогу data/, де зберігаються pack-файли з даними, але якщо потім запустити restic prune – то restic буде потрібен доступ до старих pack-файлів в data/, і, якщо вони знаходяться в Glacier або Deep Archive, операція стане або дуже повільною, або взагалі неможливою
Тому краще просто робити періодичний restic forget і restic prune, та залишити S3 Standart class даних в бакеті.
Restic та Google Drive через rclone
В мене rclone для Google Drive вже налаштований, допишу про нього окремо, вже є в чернетках, бо теж дуже цікава система.
Що ми можемо зробити – це використати rclone як storage backend для роботи з типами storage, яких нема в самому restic.
Але працює ця схема ну дуже повільно (принаймні з Google Drive) – тому її краще використовувати як one time copy, а не для регулярних бекапів.
Запускаємо restic copy, але тепер для copy вказуємо тільки --from-repo – бо destination у нас вже заданий через $RESTIC_REPOSITORY:
$ restic copy --from-repo s3:s3.amazonaws.com/test-restic-repo-bucket/test-restic-repository
enter password for source repository:
repository 58303a9c opened (version 2, compression level auto)
created new cache in /home/setevoy/.cache/restic
enter password for repository:
repository e1a8edae opened (version 2, compression level auto)
created new cache in /home/setevoy/.cache/restic
[0:00] 0 index files loaded
[0:00] 0 index files loaded
Перевіряємо в Google Drive:
$ restic snapshots
enter password for repository:
repository e1a8edae opened (version 2, compression level auto)
ID Time Host Tags Paths Size
-----------------------------------------------------------------------------------------------
...
bb02e44b 2026-01-04 15:08:41 setevoy-work daily,2026-01-04-15-08 /tmp/restic-dir-test 18 B
-----------------------------------------------------------------------------------------------
Що треба мати на увазі при роботі restic через clone:
не використовувати rclone mount
не виконувати запис одночасно з двох restic клієнтів
не використовувати одночасно два rclone serve restic для одного репозиторію
Власне, на цьому все.
Залишилось додати автоматизацію запуску бекапів на Linux та FreeBSD, але це вже опишу окремим постом.
Там часто всякі боти запускаються, нічого незвичного.
Далі, вирішив з nmap глянути що за сервіси є на тому атакуючому хості:
# nmap -sS 46.101.201.123
...
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
443/tcp open https
...
Хм, думаю – дивно, що за бот такий, що має 80 і 443 порти?
Відкриваю https://46.101.201.123 в браузері, і… попадаю на власний блог 🙂
Шта?…
Перевіряю, які IP в мене в DigitalOcean, і:
Тобто – да, 46.101.201.123 – це Droplet IP сервера, на якому хоститься RTFM.
Хоча взагалі на DNS в IN A для rtfm.co.ua використовується DigitalOcean Reserved IP, який можна переключати між дроплетами:
Тобто:
NS для rtfm.co.ua – Cloudflare
на них IN A 67.207.75.157
Droplet IP 46.101.201.123 не вказаний ніде
але запити йдуть на нього
Окей…
Тут ще буде окреме питання – чому в CloudFlare показувались запити від 46.101.201.123 – але про це в кінці.
SYN flood та підключення в SYN_RECV
Пішов глянути що взагалі на сервері в нетворкінгу, які активні конекти?
А там…
Купа підключень в статусі SYN_RECV – класичний SYN flood: клієнт нам відправляє TCP-пакет з флагом SYN, ми йому відповіли з SYN-ACK, і чекаємо на ACK від нього – але він не приходить, а ресурси CPU/RAM сервера на очікування зайняті (див. TCP handshake, нещодавно писав).
Mitigating the issue
Так як підключення йдуть не через CloudFalre – то і його Security Rules нам не допоможуть.
А Network Firewall в Digital Ocean, як і Security Groups в AWS вміють тільки в Allow правила – але не в Deny (в AWS можна зробити Deny через правила у VPC NACL – Network Access Control List).
А друге – сама причина 46.101.201.123 в логах Clodflare: “GET /wp-json/pvc/v1/increase/” – це запит до WordPress-плагіна Page View Count, який не так давно включив. А “https://rtfm.co.ua/en/freebsd-home-nas-part-1-configuring-zfs-mirror-raid1″ – звідки запит був зроблений.
Тобто, плагін на сторінці поста робить запит, аби збільшити лічильник переглядів – при цьому підставляючи Referrer у вигляді тої сторінки, звідки він запит робить.
Cloudflare жеж бачить, що запит йде від Origin – і використовує в логах Droplet IP.
Це при тому, що зазвичай переглядів кілька десятків, ну максимум 100-200.
І перевірка в гуглі вже показала причину такого напливу:
А трапилось те, що я сьогодні вранці перший раз запостив лінк на https://lobste.rs, звідки його перепостили на Hacker News, і я отримав “Hacker News hug of death” – див. Surviving the Hug of Death, де у людини була схожа ситуація.
Після відключення плагіну Page View Count – Droplet IP 46.101.201.123 в Cloudflare зник.