Загалом, налатування на Arch Linux не відрізняються від Debian – але кожного разу починаю збирати потрібні конфіги по цьому блогу і іншим моїм хостам – тому опишу окремо, що було в одному місці, плюс тут є трохи нюансів з DNS та NteworkManager.
Власне, що треба буде зробити – встановити WireGuard, створити ключі та файл конфігу, на MikroTik створити новий Peer.
Установка WireGuard
Встановлюємо пакет wireguard-tools – в ньому йдуть всі утиліти + systemd-unit для запуску WireGuard:
$ sudo pacman -S wireguard-tools
Генерація ключів
Створюємо каталог /etc/wireguard/, в ньому генеруємо приватний та публічний ключі:
# mkdir /etc/wireguard/
# cd /etc/wireguard/
# wg genkey | sudo tee /etc/wireguard/privatekey | wg pubkey | sudo tee /etc/wireguard/publickey
0ClB2Lf5uQmWK8Nz0XRofuVkvbQbSfrf3ioHbYOm9F4=
На приватний ключ задаємо права на читання тільки root:
# chmod 600 /etc/wireguard/privatekey
Створення конфігу для WireGuard
В директорії /etc/wireguard/ створюємо файл wg0.conf:
Можна підключатись – але можлива проблема з resolvconf та /etc/resolv.conf.
WireGuard та помилка “resolvconf: signature mismatch: /etc/resolv.conf”
На Arch Linux запускаємо підключення:
# systemctl start wg-quick@wg0
Job for [email protected] failed because the control process exited with error code.
See "systemctl status [email protected]" and "journalctl -xeu [email protected]" for details.
Перевіряємо статус:
# systemctl status [email protected]
× [email protected] - WireGuard via wg-quick(8) for wg0
Loaded: loaded (/usr/lib/systemd/system/[email protected]; disabled; preset: disabled)
Active: failed (Result: exit-code) since Fri 2026-05-08 08:57:47 EEST; 20s ago
...
May 08 08:57:47 setevoy-work wg-quick[1192596]: [#] wg addconf wg0 /dev/fd/63
May 08 08:57:47 setevoy-work wg-quick[1192596]: [#] ip -4 address add 10.100.0.10/32 dev wg0
May 08 08:57:47 setevoy-work wg-quick[1192596]: [#] ip link set mtu 1420 up dev wg0
May 08 08:57:47 setevoy-work wg-quick[1192644]: [#] resolvconf -a wg0 -m 0 -x
May 08 08:57:47 setevoy-work wg-quick[1192674]: resolvconf: signature mismatch: /etc/resolv.conf
May 08 08:57:47 setevoy-work wg-quick[1192674]: resolvconf: run `resolvconf -u` to update
May 08 08:57:47 setevoy-work wg-quick[1192596]: [#] ip link delete dev wg0
May 08 08:57:47 setevoy-work systemd[1]: [email protected]: Main process exited, code=exited, status=1/FAILURE
Проблема в тому, що в системі є і openresolv і NetworkManager з дефолтним dns=default – тобто NetworkManager пише /etc/resolv.conf напряму, без resolvconf.
При цьому openresolv тримає в файлі свій checksum для файлу /etc/resolv.conf, і коли NetworkManager перезаписує файл – контрольна сума не сходиться, через що resolvconf -a (який викликається wg-quick) падає з помилкою “signature mismatch“.
Option 1: PreUp та resolvconf -u (“грязний хак”)
Є “грязний хак” – додати до /etc/wireguard/wg0.conf опцію PreUp з запуском resolvconf -u:
Цей варіант теж працює, але якщо NetworkManager перезапише /etc/resolv.conf вже після підняття тунелю (наприклад, при reconnect Wi-Fi) – DNS з тунелю злетять.
Тому краще просто переключити NetworkManager на використання systemd-resolved, аби він взагалі не писав файл напряму /etc/resolv.conf.
Option 2: NetworkManager та systemd-resolved (правильний варіант)
Редагуємо конфіг /etc/NetworkManager/NetworkManager.conf і додаємо блок [main] з опцією dns – див. DNS management:
[main]
dns=systemd-resolved
Стартуємо systemd-resolved і перезапускаємо NetworkManager:
# resolvectl status
Global
Protocols: +LLMNR +mDNS -DNSOverTLS DNSSEC=no/unsupported
resolv.conf mode: foreign
Current DNS Server: 10.100.0.1
DNS Servers: 192.168.0.1 10.100.0.1
...
Або з ss -lntup | grep 127.0.0.53 – але я звик до netstat.
Option 3: чистий openresolv (just in case)
Альтернатива – задати dns=none в NetworkManager: тоді NM взагалі не чіпає /etc/resolv.conf і єдиним менеджером файлу стає openresolv: він об’єднує записи від wg-quick і підключень NetworkManager напряму в /etc/resolv.conf зі списком реальних DNS-серверів (192.168.0.1, 10.100.0.1, …).
При такому варіанті systemd-resolved взагалі не потрібен – запити на DNS resolution йдуть напряму через glibc: простіше конфігурація і менше сервісів – але втрачаємо плюшки systemd-resolved: кешування, split-DNS, DNSSEC.
Іноді на FreeBSD треба запустити якісь сервіси, які офіційно FreeBSD не підтримують, і власне, цей пост з’явився через те, що я встановлював Open WebUI на своєму NAS – і як раз Open WebUI простіше було зробити на Linux.
Тому підняв його у FreeBSD Linux jail, а для створення контейнеру взяв Bastille, яка спрощує менеджмент.
Про сам Open WebUI може допишу чорнетку, а Bastille вирішив винести окремим постом – бо зараз буду сетапити Hermes Agent (вже – див. Hermes Agent: запуск AI Agent у FreeBSD Jail з Bastille, і хочеться мати таку собі коротку інструкцію по тому, як працювати з FreeBSD jails використовуючи Bastille.
FreeBSD jails з’явились ще у 1999 році як розвиток “неповноцінної” системи chroot, яка не давала повної ізоляції. З jails з’явилась можливість відокремлення filesystem, мати окремий network stack, власні PIDs і так далі – власне все те, до чого ми звикли в Linux та його контейнерах.
Як раз на днях зустрів цікавий пост на цю тему, де серед іншого говориться і за історію контейнеризації – Your Container Is Not a Sandbox.
На відміну від контейнерів в Linux – FreeBSD jails це єдина частина ядра системи, тоді як Linux – це комбінація різних механізмів (namespaces, cgroups).
Правда, вона має і недоліки – бо це все одно залишається одне і там саме ядро FreeBSD, зато вона простіша – а тому безпечніша і простіша в роботі та дебагу.
Власне, Bastille – це розвиток системи jails, точніше – система для спрощення менеджменту контейнерів у FreeBSD, аби не писати jail.conf руками і мати простий CLI для управління (як Docker – це “обгортка” для Linux containers).
Не Bastille єдиною – є аналогічні рішення як-от iocage, ezjail, pot та інші.
Чому взяв Bastille – проект активно розвивається, є велике комьюніті, має зручний CLI та добре інтегрується з можливостями ZFS.
VNET (DHCP): Bastille створює інтерфейс з типом bridge і підключає jail через epair – кожен jail отримує власні MAC та IP адреси, і виглядає як окремий хост у мережі
Bridged VNET (own bridge): те саме, але bridge створюється вручну – використовується для кастомних або ізольованих мереж
Alias/Shared Interface: один інтерфейс хоста, IP-адреси для jail-ів додаються як alias фізичного інтерфейсу хоста – простий варіант, але без окремого network stack (тобто у всіх буде загальний фаервол самого хоста, роутинг тощо)
NAT/Loopback Interface: jail отримує IP у внутрішній мережі і ходить в “світ” через NAT хоста, для доступу ззовні до jail потрібен port forwarding
Inherit: jail використовує той самий IP і інтерфейс, що й хост, використовується рідко – зазвичай для специфічних кейсів, доступ розділяється по портах – незручно, не гнучко, не масштабується
Далі детальніше подивимось на три основних типи – VNET, Alias та NAT.
Bastille bootstrap
Запускаємо bastille bootstrap, аналог docker pull – скачати базовий архів з системою, яку передамо аргументом, та розархівувати його для подальшого використання.
Якщо робимо контейнер з FreeBSD, то версія системи в jail повинна бути =< версії хоста – перевіряємо її з freebsd-version:
Тепер у нас все готове для створення контейнерів – подивимось, як робити jails з FreeBSD та Linux та різними налаштуваннями мережі.
Створення jails
Якщо запускаємо у VirtualBox – включаємо Promiscuous Mode в Allow All:
Створення FreeBSD jails
Спочатку зробимо кілька контейнерів з FreeBSD і різними параметрами мережі – а потім запустимо jail з Linux.
Всі створені jail зберігаються в директорії /usr/local/bastille/jails/ – там для кожного контейнера буде директорія з його ім’ям та файлом jail.conf, який описує параметри цього контейнеру.
Network type VNET
Першим глянемо варіант з VNET – я ним користуюсь найбільше, бо зручно мати прямий доступ в контейнери, плюс повноцінна ізоляція на рівні мережі.
Аби задати тип нетворка VNET – до bastille create передаємо опцію --vnet (або коротка форма -V), потім ім’я jail, версію системи, IP-адресу та інтерфейс хоста для створення bridge.
Інтерфейс можна не передавати, якщо заданий bastille_network_gateway в /usr/local/etc/bastille/bastille.conf.
Замість передачі IP явно – можна вказати опцію DHCP або SYNCDHCP – тоді jail отримає адресу від роутера:
[root@test-free-15-bastille ~]# bastille list
JID Name Boot Prio State Type IP Address Published Ports Release Tags
2 testjailVnetIp on 99 Up thin 192.168.0.205 - 15.0-RELEASE -
Deep dive: VNET networking
Трохи детально згадував як працює нетворкінг, в принципі цю частину можна пропустити, але якщо цікаво – то подивимось, як пакет з ноутбука в локальній мережі з FreeBSD-хостом попадає всередину jail.
Тут в прикладі маємо всі хости в одній мережі 192.168.0.0/24:
Де бачимо, що у vnet0 той самий MAC 0e:20:99:d5:55:b2 як і на хості у інтерфейсів e0a_bastille1 та em0.
Data flow та ARP table
І тепер можна прослідкувати процес передачі даних до jail:
з ноутбука виконуємо ssh 192.168.0.205 – на jail IP
ноутбук виконує broadcast ARP-запит в мережу 192.168.0.0/24 – “хто має 192.168.0.205?“
фізичний інтерфейс em0 на хості отримує цей запит, ядро визначає, що em0 – це member bridge-інтерфейсу em0bridge на port 1, і передає дані на em0bridge
em0bridge передає його до своїх members, на інші ports – в нашому випадку до e0a_bastille1 на port 5
e0a_bastille1 – це “вхідний” socket, а e0b_bastille1 – його “вихід” всередині jail
для аналогії можна згадати socketpair(), який обєднує два socket, кожен з власним file descritor – на “вході” та на “виході”: все, що записується на “вхідний” сокет – попадає на другий сокет зв’язаної пари
інтерфейс vnet0 в jail отримує цей запит, відповідає ноутбуку “це мій IP” та повертає свій MAC
ноутбук записує цей MAC в свою ARP table
Подивитись ARP на Arch Linux можемо з ip neigh show:
[setevoy@setevoy-work ~] $ ip neigh show
192.168.0.205 dev enp0s13f0u3u4c2 lladdr 0e:20:99:d5:55:b2 REACHABLE
...
src MAC: MAC інтерфейсу – в моєму випадку enp0s13f0u3u4c2
dst MAC: 0e:20:99:d5:55:b2 (MAC FreeBSD em0 та jail e0b_bastille1)
OSI layer 3 (IP packet) headers:
src IP: IP хоста з Arch Linux
dst IP: 192.168.0.205 – jail IP
А процес доставки даних в jail виглядає так:
ноутбук формує Ethernet frame з dst MAC 0e:20:99:d5:55:b2
фрейм через роутер/свіч домашньої мережі попадає на em0 хоста FreeBSD
ядро FreeBSD “бачить”, що em0 – це member групи em0bridge та передає дані на e0a_bastille1
пакет “входить” до e0a_bastille1 – і “виходить” у e0b_bastille1 – інтерфейсі vnet0 всередині нашого jail
ядро в jail розпаковує Ethernet фрейм, перевіряє dst IP (192.168.0.205) та dst Port (22), бачить, що це його IP, а на порту 22 є демон SSH – і передає IP пакет до SSH
Начебто вірно описав.
Тепер, як трохи розібрались з мережею – можна створювати контейнери далі.
[root@test-free-15-bastille ~]# ifconfig
em0: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
...
inet 192.168.0.72 netmask 0xffffff00 broadcast 192.168.0.255
inet 192.168.0.206 netmask 0xffffffff broadcast 192.168.0.206
...
lo0: flags=1008049<UP,LOOPBACK,RUNNING,MULTICAST,LOWER_UP> metric 0 mtu 16384
...
bastille0: flags=8008<LOOPBACK,MULTICAST> metric 0 mtu 16384
...
em0bridge: flags=1008843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
...
e0a_bastille1: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
description: vnet0 host interface for Bastille jail testjailVnetIp
...
А в контейнері – всі ті самі інтерфейси, що і на хості, але для em0 тільки один IP:
[root@test-free-15-bastille ~]# jexec testjailAlias ifconfig
em0: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
...
ether 08:00:27:d5:55:b2
inet 192.168.0.206 netmask 0xffffffff broadcast 192.168.0.206
...
lo0: flags=1008049<UP,LOOPBACK,RUNNING,MULTICAST,LOWER_UP> metric 0 mtu 16384
...
bastille0: flags=8008<LOOPBACK,MULTICAST> metric 0 mtu 16384
...
em0bridge: flags=1008843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
...
e0a_bastille1: flags=1008943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST,LOWER_UP> metric 0 mtu 1500
...
Тепер, якщо ми не запустимо sshd в контейнері – то підключення на IP 192.168.0.206 піде на SSH daemon самого хоста – “Password for setevoy@test-free-15-bastille”
[setevoy@setevoy-work ~] $ ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null [email protected]
Warning: Permanently added '192.168.0.206' (ED25519) to the list of known hosts.
([email protected]) Password for setevoy@test-free-15-bastille:
А якщо маємо відкритий порт 22 в контейнері:
root@testjailAlias:~ # service sshd onestart
То запит піде на нього – “Password for setevoy@testjailAlias“:
[setevoy@setevoy-work ~] $ ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null [email protected]
Warning: Permanently added '192.168.0.206' (ED25519) to the list of known hosts.
([email protected]) Password for setevoy@testjailAlias:
Простіше за VNET – але маємо загальні правила Packet Filter, фаервола на хості, нема можливості отримати адресу з DHCP, можливі проблеми з overlapping ports, і важливе: якщо ламають наш jail – то отримують доступ до всієї мережі хоста.
Network type NAT
І останній на сьогодні приклад – з NAT, тільки тепер задаємо IP не з пулу домашньої мережі, а в інтерфейсі вказуємо loopback інтерфейс хоста bastille0:
[root@test-free-15-bastille ~]# bastille list
JID Name Boot Prio State Type IP Address Published Ports Release Tags
4 testjailAlias on 99 Up thin 192.168.0.206 - 15.0-RELEASE -
6 testjailNat on 99 Up thin 10.0.0.10 - 15.0-RELEASE -
2 testjailVnetIp on 99 Up thin 192.168.0.205 - 15.0-RELEASE -
Роутинг пакетів до jail піде через Packet Filter:
[root@test-free-15-bastille ~]# pfctl -s nat
nat on em0 from <jails> to any -> (em0:0)
rdr-anchor "rdr/*" all
Важливе обмеження Linux jail – для мережі недоступні VNET-опції. Тобто з варіантів – або NAT і port-forward, або Alias з усіма його обмеженнями і можливими проблемами.
Крім того – “Linux jails are still considered experimental” – хоча в цілому працює достатньо стабільно.
Для Linux нам потрібно виконати bastille setup linux – тоді Bastille підтягне потрібні модулі і скрипти:
[root@test-free-15-bastille ~]# bastille setup linux
[WARNING]: Running linux jails requires loading additional kernel
modules, as well as installing the 'debootstrap' package.
Do you want to proceed with setup? [y|n]:y
Loading kernel module: fdescfs
Persisting module: fdescfs
fdescfs_load: -> YES
Loading kernel module: linprocfs
Persisting module: linprocfs
linprocfs_load: -> YES
Loading kernel module: linsysfs
Persisting module: linsysfs
linsysfs_load: -> YES
Loading kernel module: linux
Loading kernel module: linux64
linux_enable: NO -> YES
...
Тепер в директорії /usr/local/share/debootstrap/scripts/ маємо набір shell-скриптів, які налаштують Linux-оточення:
[root@test-free-15-bastille ~]# less /usr/local/share/debootstrap/scripts/gutsy
case $ARCH in
amd64|i386)
case $SUITE in
gutsy|hardy|intrepid|jaunty|karmic|lucid|maverick|natty|oneiric|precise|quantal|raring|saucy|utopic|vivid|wily|yakkety|zesty)
default_mirror http://old-releases.ubuntu.com/ubuntu
...
keyring /usr/local/share/keyrings/ubuntu-archive-keyring.gpg
Виконуємо bootstrap, вказуємо ім’я системи – власне, ім’я скрипта з /usr/local/share/debootstrap/scripts/.
Але для Ubuntu остання доступна версія – Jammy, 22.04.
Займе хвилин 10-15, може і більше поки все скачає:
[root@test-free-15-bastille ~]# bastille bootstrap jammy
Attempting to bootstrap Linux/Ubuntu release: Ubuntu_2204
Ensuring Linux compatability...
...
Потім створюємо контейнер з create та опцією --linux (-L):
Також варто подивитись на bastille monitor – є цікаві можливості з моніторингу і алертингу, та Templates – створення контейнерів з шаблонів які можна взяти з BastilleBSD/templates або створювати власні.
По самому Hermes Agent і його можливостям буду писати окремо, сьогодні – як запустити його на FreeBSD.
Вчора погрався на своєму Arch Linux – тепер хочеться вже більш production setup.
Крутити буду на моєму NAS з FreeBSD, запускати там, звісно, вже тільки у FreeBSD Jail, бо NAS – це доступ до важливих даних і бекапів.
На Linux налаштування агента всі ті самі – тільки простіший сетап, тому окремо описувати не буду.
А от по можливостям Hermes Agent і більш детальний конфіг – зроблю окремий пост, бо там є, що потрогати.
Для роботи з Jails використовую Bastille – про неї теж якось окремо напишу, є чорнетка.
Власне, що будемо робити:
створимо FreeBSD Jail
налаштуємо мережу
встановимо сам Hermes Agent
налаштуємо підключення до Telegram
і встановимо Hermes Agent Web UI
Поїхали.
Але спочатку трохи оффтопік 🙂
Holywar: FreeBSD Jail чи “контейнер”?
Тут коротко – чи вірно казати “контейнер” про FreeBSD Jail – бо мене можуть заплювати 🙂
Як людина, яка зазвичай працює з Linux, то для мене “контейнер” це і FreeBSD Jail – і Linux Docker, тому в цьому пості буду все ж про Jails казати “контейнери”.
While reading the documentation and using Bastille, you will find that sometimes “container” is used, and sometimes “jail” is used. These are completely interchangeable, but there is some debate as to which one is more correct. Be that as it may, anytime you read “container” or “jail”, it means a FreeBSD jail.
Крім того, читачі мого блогу в основному теж Linux users – тому нехай вже буде “контейнери”. А в окремому пості по Bastille трохи детальніше поговоримо про Jails у FreeBSD vs Linux containers.
root@setevoy-nas:~ # bastille list hermesagent1
JID Name Boot Prio State Type IP Address Published Ports Release Tags
3 hermesagent1 on 99 Up thin 192.168.0.210 - 14.4-RELEASE -
Аби ми могли писати боту – знаходимо свій User ID з @userinfobot.
Якщо бот буде в групі чи каналі – в тому ж боті жеж можна знайти їх ID.
Я цього бота роблю для тесту, тому залишаю мого юзера:
І в “home channel” теж:
Готово:
Далі ще налаштування браузера та Tools – там залишаємо все дефолтними, і готово:
Telegram та Hermes Agent Gateway на FreeBSD
На Linux Hermes Gateway включається просто через systemd – на FreeBSD трохи “ручками” (в лапках – бо зробив це самим агентом 🙂 ).
Перевіряємо статус зараз:
[hermes@hermesagent1 ~]$ hermes gateway status
✗ Gateway is not running
To start:
hermes gateway run # Run in foreground
hermes gateway install # Install as user service
sudo hermes gateway install --system # Install as boot-time system service
Команда hermes gateway install на FreeBSD очікувано повернула “not supported on this platform“:
[root@hermesagent1 /usr/home/hermes]# /home/hermes/.hermes/hermes-agent/venv/bin/hermes gateway install --system
Service installation not supported on this platform.
Run manually: hermes gateway run
Перевіряємо де саме лежить Hermes:
[hermes@hermesagent1 ~]$ head -1 "$(command -v hermes)"
#!/home/hermes/.hermes/hermes-agent/venv/bin/python3
Ну і давайте спробуємо – чи справиться агент з задачею “я лінивий інженер, сдєлай мені харашо” – нехай сам скаже, як його гейтвей додати в автостарт на FreeBSD:
Окей.
Але я настільки лінивий, що не хочу займатись copy-paste – нехай робить все сам.
Ми в Jail – тому це безпечно:
Для створення rc.d скрипта йому потрібен root – питає пароль, бо sudo у нас тут парольний:
Скрипт готовий:
Сам скрипт, який він написав – /usr/local/etc/rc.d/hermes_gateway:
#!/bin/sh
# PROVIDE: hermes_gateway
# REQUIRE: LOGIN NETWORKING
# KEYWORD: shutdown
. /etc/rc.subr
name="hermes_gateway"
rcvar="hermes_gateway_enable"
load_rc_config "$name"
: ${hermes_gateway_enable:="NO"}
: ${hermes_gateway_user:="hermes"}
: ${hermes_gateway_home:="/home/hermes"}
: ${hermes_gateway_command:="/home/hermes/.local/bin/hermes"}
: ${hermes_gateway_log:="/var/log/hermes_gateway.log"}
pidfile="/var/run/${name}.pid"
command="/usr/sbin/daemon"
command_args="-f -p ${pidfile} -u ${hermes_gateway_user} -o ${hermes_gateway_log} /usr/bin/env HOME=${hermes_gateway_home} ${hermes_gateway_command} gateway run"
start_cmd="${name}_start"
stop_cmd="${name}_stop"
status_cmd="${name}_status"
hermes_gateway_start()
{
if [ ! -x "${hermes_gateway_command}" ]; then
echo "Hermes executable not found or not executable: ${hermes_gateway_command}"
return 1
fi
touch "${hermes_gateway_log}"
chown "${hermes_gateway_user}" "${hermes_gateway_log}" 2>/dev/null || true
echo "Starting Hermes gateway."
${command} ${command_args}
}
hermes_gateway_stop()
{
echo "Stopping Hermes gateway."
if [ -f "${pidfile}" ]; then
kill "$(cat ${pidfile})" 2>/dev/null || true
rm -f "${pidfile}"
else
pkill -u "${hermes_gateway_user}" -f "${hermes_gateway_command} gateway run" 2>/dev/null || true
fi
}
hermes_gateway_status()
{
if [ -f "${pidfile}" ] && kill -0 "$(cat ${pidfile})" 2>/dev/null; then
echo "Hermes gateway is running as pid $(cat ${pidfile})."
return 0
fi
if pgrep -u "${hermes_gateway_user}" -f "${hermes_gateway_command} gateway run" >/dev/null 2>&1; then
echo "Hermes gateway is running, but pidfile is missing/stale."
return 0
fi
echo "Hermes gateway is not running."
return 1
}
run_rc_command "$1"
Зупиняємо “hermes gateway run“, яку запускали руками вище, і пробуємо запустити вже через сервіс:
[hermes@hermesagent1 ~]$ sudo service hermes_gateway start
Starting Hermes gateway.
[hermes@hermesagent1 ~]$ sudo service hermes_gateway status
Hermes gateway is running as pid 60901.
Поки пишеться серія постів по налаштуванню і використанню Claude Code – запишу приклад створення власного AI Agent для VictoriaMetrics та Kubernetes і “загортання” його в Claude Code Plugin та створення власного Claude Code Markeplace, де будуть жити подібні плагіни для девелоперів на моєму проекті.
Загальна ідея: мати агента, якого девелопери можуть підключити собі до Claude Code (а у нас 95% проекту користуються ним), і з яким зможуть запитати “якого біса впав той Kubernetes Pod”
І не тільки девелопери – я, коли тестив цього агента, відкрив для себе причину постійних рестартів Grafana – тому агент буде корисний і мені самому.
Є, звісно, проекти типу kubectl-ai або навіть robusta.dev – але ми побудуємо власного агента з маркетплейсом і скілами.
Що будемо робити:
агент буде використовувати офіційні скіли від VictoriaMetrics – для самої VictoriaMetrics, VictoriaLogs та Alertmanager
напишемо власний SKILL.md, в кому буде описаний flow перевірки стану Kubernetes Pods – цей скіл буде включений в плагін і потім його можна буде використовувати з новими агентами
для зручного підключення агента з усіма його скілами запакуємо весь проект в плагін для Claude Code, який буде зберігатись в проектному GitHub
Сам агент, описаний тут, більше PoC в плані його інструкцій, і по ходу діла буде тюнитись і допилюватись – але загальна конструкція створення маркеплейсу, побудові агента і плагіну для Claude Code залишиться такою, як показано в цьому пості.
Загальна структура і план
Ключові концепти про які варто знати наперед:
Marketplace: це git-репозиторій з одним або кількома плагінами, який девелопер додає до свого інстансу Claude Code одною командою.
Plugin: можемо “запакувати” всі Agents, Skills, Commands, MCP servers в єдиний пакет, який теж встановлюється до Claude Code одною командою
Agent: субагент Claude Code з власним system prompt і permissions, викликається з основної сесії через Agent tool – працює в ізольованому контексті, виконує задачу, повертає результат до головного “оркестратора”, в ролі якого в нашому випадку буде Claude Code девелопера (чи мій)
Skill: “інструкція”, яку агент читає при потребі і яка описує деталі виконання задачі
В результаті в репозиторії atlas-claude-plugins отримаємо таку структуру каталогів і файлів:
Перша версія агента була з MCP. Насправді взагалі ця ідея з’явилась як раз під час написання чорнетки поста про Claude Code та підключення MCP – там описана робота з MCP на прикладі офіційних MCP від VictoriaMetrics (див. mcp-victoriametrics) та Kubernetes.
І тому, коли почав робити вже цього агента, то спочатку додав MCP, але потім стало питання – як девелоперам їх встановлювати? Тоді згадав, що у команди VictoriaMetrics є і набір готових skills: то, може, просто взяти їх – а не тягнути якісь бінарніки? І нехай собі Claude Code через Bash tool використовує curl та робить запити напряму до API.
Бо насправді – в чому різниця між MCP та Skill?
MCP (Model Context Protocol) – дає типізовані tools з чітко визначеними командами: наприклад, для VictoriaMetrics є офіційний mcp-victoriametrics сервер, в якому є Tools типу query(query: string, time: timestamp). Це виглядає круто – бо є детермінізм, визначеність, чітка структура – агент не може викликати функцію з неправильними параметрами, схема валідується.
Але! При використанні MCP функції – наприклад, query, функція приймає аргумент string – і агент все одно сам пише MetricsQL запит. Тобто, MCP визначає тільки як виконати запит – але не саму структуру запиту, і запит все одно LLM будує сама.
Власне, те саме і з kubectl – чи ми використовуємо MCP сервер для нього, чи ми робимо Bash(kubectl get pod …) – результат однаковий: агент/LLM все одно самі визначають запит і фільтри.
Зато в скілах ми можемо описати інше – “Щоб перевірити логи Pod-у в нашому кластері, використовуй такий pattern: _stream:{namespace=’X’}“. Це знання для агенту, яке MCP не передає.
Плюс є практичний момент:
використання офіційного marketplace VictoriaMetrics зі скілами victoriametrics-query, victorialogs-query, alertmanager-query – вони підтримуються командою VictoriaMetrics, оновлюються при змінах в MetricsQL/LogsQL
не треба тягнути зайві бінарні файли в систему юзера (девелопера) – простіше підключення та налаштування (хоча bootstrap.sh все одно треба додати, да і скіли VictoriaMetrics підключити)
Тому вирішив робити чисто “Bash + curl + власний скіл з нашим контекстом + офіційні VictoriaMetrics скіли” – без MCP взагалі.
Окремо момент з Kubernetes MCP та Skills: тут сама логіка – всі LLM чудово знають синтаксис kubectl, тому великого сенсу в додаванні MCP не бачу.
Можна було б додати якийсь готовий скіл, як це зроблено для VictoriaMetrics, наприклад LukasNiessen/kubernetes-skill – але цей скіл більше про те, як деплоїти – а ми будемо робити read-only агента, який буде дебажити, а не деплоїти – зовсім інший use case. Тому якісь деталі по нашому конкретному сетапу (типу namespace convention) можна просто додати в SKILL.md самого плагіну – а LLM вже сама розбереться як зробити kubectl get events.
Поїхали.
Створення Marketplace
Почнемо з бази – маркетплейсу, де буде цей агент та, в майбутньому, інші, і в ньому ж створимо вже структуру для плагіну.
Marketplace: це сам GitHub репозиторій atlas-claude-plugins
Plugin: k8s-tools
Agent: k8s-pod-debugger
Skill: k8s-troubleshooting-flow
Marketplace: файл .claude-plugin/marketplace.json
В корні репозиторію створюємо каталог .claude-plugin/, в ньому файл marketplace.json – він описує сам маркетплейс та плагіни в ньому:
{
"name": "atlas-claude-plugins",
"owner": {
"name": "Org Engineering",
"url": "https://github.com/Org-Engineering"
},
"metadata": {
"description": "Org DevOps team Claude Code plugins for Kubernetes operations and debugging",
"version": "0.1.0"
},
"plugins": [
{
"name": "k8s-tools",
"source": "./plugins/k8s-tools",
"description": "Kubernetes operations toolkit - read-only debugging agents and skills with VictoriaLogs, VictoriaMetrics, and Alertmanager integration",
"version": "0.1.0",
"category": "devops",
"tags": ["kubernetes", "debugging", "observability", "victoriametrics", "victorialogs", "alertmanager"]
}
]
}
Тут:
name: "atlas-claude-plugins": задає ім’я, з яким marketplace буде встановлюватись до Claude Code з командою /plugin marketplace add your-org/atlas-claude-plugins
version: задається як на рівні marketplace (збільшуємо, коли міняється список плагінів) – так і на рівні кожного плагіну (збільшуємо, коли міняється сам плагін)
plugins[].source: масив, в якому описується список плагінів цього маркетплейсу, для кожного плагіну задаємо відносний шлях в репозиторії – з префіксом ./
Далі описуємо сам плагін – каталог plugins/k8s-tools/, як задано в plugins[].source файлу marketplace.json вище.
В plugins/k8s-tools/ створюємо каталог .claude-plugin/, а в ньому файл plugin.json:
{
"name": "k8s-tools",
"version": "0.1.0",
"description": "Kubernetes operations toolkit - read-only debugging agents and skills for VictoriaLogs, VictoriaMetrics, and Alertmanager",
"author": {
"name": "Org Engineering",
"url": "https://github.com/Org-Engineering"
}
}
Тут визначаємо що взагалі за плагін та його версію. Версія має співпадати з plugins[].version в marketplace.json.
Файл .claude/settings.json
Це файл який дає одну дуже приємну фічу для Claude Code – extraKnownMarketplaces: коли девелопер клонує репо і відкриває його в Claude Code – той автоматично пропонує встановити marketplace. Без “ручного читання” README.md, без ручного запуску команд.
Він не являє собою обов’язкову частину Claude Code Marketplace – це просто фішка, якою ми спростимо собі і девелоперам життя при запуску Claude Code.
Крім того, ми тут додаємо і наш власний маркетплейс – і маркетплейс від VictoriaMetrics: одним “yes” девелопер встановить обидва:
Відразу визначаємо дані, які нам в репозиторії не треба – бо всякі .claude/sessions/ це вже локальні дані девелопера, вони в репозиторії не потрібні. Аналогічно з файлами whatever.local.json – це локальні overwrides, які я чи девелопер може додати чисто для себе, в плагіні їх ігноруємо. Див. Available scopes, і про них буду писати окремо вже в постах по самому Claude Code:
# OS
.DS_Store
Thumbs.db
# Editors
.vscode/
.idea/
*.swp
*~
# Claude Code per-user state and overrides (never share)
.claude/local/
.claude/conversations/
.claude/sessions/
.claude/cache/
.claude/settings.local.json
.claude/*.local.json
# Local env files
.env
.env.local
Тепер маємо таку структуру:
$ tree -a -I '.git'
.claude
└── settings.json
.claude-plugin
└── marketplace.json
plugins
└── k8s-tools
├── .claude-plugin
│ └── plugin.json
Тут:
.claude: конфіг для інстансу Claude Code на робочих машинках
Давайте ще раз визначимо – що таке “AI Agent” взагалі: це окрема “сутність”, яку Claude Code може запустити для виконання якоїсь конкретної задачі.
У агента окремий system prompt, окремий контекст – його задача “зробити щось”, і повернути результат до головного інстансу Claude Code. Таким чином ми не забиваємо зайвими даними контекст самого Claude Code – він отримує тільки ті дані, які йому треба для виконання основної задачі.
Крім того, наприклад, окремому агенту можна задати іншу, більш дешеву модель – тоді при задачах типу парсінгу логів економимо гроші, бо логів багато – токенів жре багато. Дешева моделька вибирає тільки основні патерни, дані – і повертає їх до самого Claude Code, а та вже з дорогою моделлю типу Opus 4.7 (остання на сьогодні) виконує детальний аналіз.
Profit!
Файл plugins/k8s-tools/agents/k8s-pod-debugger.md
Для агенту нам треба створити файл, який буде описувати метадані агента та задавати його system prompt.
Файл розбитий на дві основні частини:
YAML frontmatter: блок на початку файла markdown, де між двома “---” задаємо ім’я, Description, Tools, Permissions
System Prompt: а вже в body файлу – описуємо агенту що і як він має робити, тут жеж можемо додати якісь деталі по конкретно нашому Kubernetes-кластеру чи зв’язкам workloads – як їх дебажити
Ім’я файлу k8s-pod-debugger.md має співпадати з полем name в frontmatter – інакше Claude Code не звʼяже їх.
Frontmatter: поля Name та Description
На початку файлу визначаємо ім’я, задаємо опис агента – це загальні метадані агента.
Тут зміст частинами, потім весь файл.
Опис використовується тільки Claude Code – не людиною, девелопером:
---
name: k8s-pod-debugger
description: Use this agent to investigate Kubernetes Pod, Namespace, or Workload issues. Performs read-only diagnostics across resource state, events, logs, metrics, and alerts. Invoke when user asks to debug a Pod, check why a Pod is failing (CrashLoopBackOff, OOMKilled, Pending, ImagePullBackOff), investigate problems in a Namespace, or troubleshoot a Deployment/StatefulSet/DaemonSet/Job that is not behaving correctly.
...
Frontmatter: поля Permissions та Tools
Далі визначаємо які Claude Code Tools агент може використовувати – а що йому явно заборонено.
У нас read-only agent, ніяких kubectl delete pod він робити не повинен – тому явно це визначаємо:
Permissions, deny-tools та Least Privilege Principle
Тут трохи зупинюсь на деталях deny-tools, бо важлива частина.
Використовуємо принцип least privilege – мінімально потрібні для роботи агента доступи.
Наприклад, curl без обмежень може видалити time series в VictoriaMetrics через POST на admin endpoint
$ curl -X POST https://victoriametrics.internal/api/v1/admin/tsdb/delete_series?match[]={namespace=”prod”}
Тому ріжемо їх, дозволяємо тільки GET.
Для bash – блокуємо різні pipe-операції – виконати curl … | bash агент не зможе.
Блокуємо різні redirect output – >, >> – не даємо писати в файли через bash.
Виконання команд rm, mv, cp – все це теж в denied.
Те саме для kubectl – явно забороняємо дії типу kubectl delete чи kubectl exec.
Body: Agent’s System Promt
І головна частина файлу – System Promt агента: що і як він має виконувати при дебагу:
...
# Kubernetes Pod Debugger
You are a read-only Kubernetes troubleshooting agent. Your job is to investigate issues with Pods, Namespaces, and Workloads (Deployments, StatefulSets, DaemonSets, Jobs) and report findings clearly. You have access to the cluster via kubectl, and to observability data via VictoriaLogs, VictoriaMetrics, and Alertmanager.
You are NOT responsible for Node issues, networking deep-dives (Service/Ingress connectivity), or Storage (PV/PVC) troubleshooting. If the user asks about those, advise that a different agent is needed and stop.
## Your boundaries
You are strictly read-only. You investigate, observe, and report. You do not modify anything in the cluster or any external system. The user's permissions enforce this, but you must also respect this boundary in your reasoning - never propose write actions as part of your investigation.
...
## Available tools and data sources
**kubectl** - read-only commands only (`get`, `describe`, `logs`, `top`, `events`).
**Observability via VictoriaMetrics skills.** This plugin relies on the official VictoriaMetrics `query` plugin from the `victoriametrics-tools` marketplace, which provides:
- `victoriametrics-query` skill - for metrics queries (PromQL/MetricsQL)
- `victorialogs-query` skill - for log searches (LogsQL)
- `alertmanager-query` skill - for active and silenced alerts
...
## Our environment specifics
This is essential context for query construction. Always apply these when invoking VM skills:
**VictoriaMetrics labels** (standard prometheus-operator stack):
- `cluster` - REQUIRED in all queries (e.g. `kube_pod_status_phase{cluster="prod-1",namespace="..."}`)
...
**VictoriaLogs streams** (promtail-based collection):
- Stream label: only `namespace` is indexed at stream level
...
## How to investigate
The investigation flow depends on the entry point. Identify which type of request you got and follow the matching flow.
### Entry point A: Single Pod
Triggered by requests like "debug pod X", "why is X failing", "what's wrong with X in namespace Y".
1. **Establish context**
- `kubectl config current-context` (also use as `CLUSTER` for metrics)
- If Namespace not specified, get current default: `kubectl config view --minify -o jsonpath='{..namespace}'`
- Verify Pod exists: `kubectl get pod <name> -n <ns>`
2. **Check Pod state**
- `kubectl get pod <name> -n <ns> -o wide` - status, Node, IP, restart count
- `kubectl describe pod <name> -n <ns>` - full event history, conditions, container statuses, last termination reason
- For multi-container Pods, identify all containers: `kubectl get pod <name> -n <ns> -o jsonpath='{.spec.containers[*].name}'`
...
## How to report findings
Structure your final report in clear sections. Be concrete - include actual values, error messages, timestamps. Avoid filler.
Use this template, adapted to the entry point:
- **Subject** - what you investigated (Pod name / Namespace / Workload kind+name)
...
- **Recommended actions** - read-only or human-driven next steps (you cannot execute writes)
For Namespace overview reports, structure findings as a prioritized list of issues, with a brief sub-report per top issue.
## Important rules
- **Never invent data.** If a command fails or returns nothing, report that explicitly. Do not fabricate values.
- **Cite your evidence.** Every claim in your conclusion must reference a specific kubectl output, log line, metric value, or alert
...
- **Out of scope:** Node issues, networking (Service/Ingress connectivity), Storage (PV/PVC). If the request is purely about these, say so and stop - a different agent should handle them.
..
Тут:
Kubernetes Pod Debugger: описуємо агенту – хто він такий і що робить взагалі
Your boundaries: ще раз вказуємо, що він read-only
Available tools and data sources: які утиліти і як він має використовувати – вказуємо, що є окремі скіли від VictoriaMetrics, аби він їх підключав
Our environment specifics: деталі, специфічні до нашого конкретного сетапу, labels в метриках чи streams в логах
How to investigate: описуємо процес пошуку проблем – як підключитись до Kubernetes, перевірити стан Kubernetes Pod, пов’язані events, etc
How to report findings: описуємо формат, в якому агент має повернути результати
Important rules: і трохи причісуємо поведінку – “не вигадуй, якщо щось пішло не так“, не лізти в зайві дані, і так далі
Окремо агенту явно вказуємо, що у нас є Skill k8s-troubleshooting-flow, в якому описані деталі виконання запитів – про нього далі.
Весь файл k8s-pod-debugger.md
В результаті маємо такий зміст:
---
name: k8s-pod-debugger
description: Use this agent to investigate Kubernetes Pod, Namespace, or Workload issues. Performs read-only diagnostics across resource state, events, logs, metrics, and alerts. Invoke when user asks to debug a Pod, check why a Pod is failing (CrashLoopBackOff, OOMKilled, Pending, ImagePullBackOff), investigate problems in a Namespace, or troubleshoot a Deployment/StatefulSet/DaemonSet/Job that is not behaving correctly.
tools:
- Bash
- Read
- Grep
allowed-tools:
- Bash(kubectl get *)
- Bash(kubectl describe *)
- Bash(kubectl logs *)
- Bash(kubectl top *)
- Bash(kubectl events *)
- Bash(kubectl version)
- Bash(kubectl config view *)
- Bash(kubectl config current-context)
- Bash(kubectl auth can-i *)
- Bash(curl -s -G *)
- Bash(curl -sG *)
- Bash(curl --silent --get *)
- Bash(jq *)
- Bash(source ~/.config/atlas/env)
- Bash(cat ~/.config/atlas/env)
deny-tools:
- Bash(kubectl delete *)
- Bash(kubectl apply *)
- Bash(kubectl exec *)
- Bash(kubectl edit *)
- Bash(kubectl patch *)
- Bash(kubectl scale *)
- Bash(kubectl rollout *)
- Bash(kubectl cp *)
- Bash(kubectl port-forward *)
- Bash(kubectl create *)
- Bash(kubectl replace *)
- Bash(kubectl annotate *)
- Bash(kubectl label *)
- Bash(kubectl drain *)
- Bash(kubectl cordon *)
- Bash(kubectl uncordon *)
- Bash(kubectl taint *)
- Bash(*curl* -X *)
- Bash(*curl* --request *)
- Bash(*curl* -d *)
- Bash(*curl* --data*)
- Bash(*curl* --upload-file *)
- Bash(*curl* -T *)
- Bash(*curl* -o *)
- Bash(*curl* --output *)
- Bash(*|*sh*)
- Bash(*|*bash*)
- Bash(*>*)
- Bash(*>>*)
- Bash(rm *)
- Bash(mv *)
- Bash(cp *)
- Bash(chmod *)
- Bash(chown *)
---
# Kubernetes Pod Debugger
You are a read-only Kubernetes troubleshooting agent. Your job is to investigate issues with Pods, Namespaces, and Workloads (Deployments, StatefulSets, DaemonSets, Jobs) and report findings clearly. You have access to the cluster via kubectl, and to observability data via VictoriaLogs, VictoriaMetrics, and Alertmanager.
You are NOT responsible for Node issues, networking deep-dives (Service/Ingress connectivity), or Storage (PV/PVC) troubleshooting. If the user asks about those, advise that a different agent is needed and stop.
## Your boundaries
You are strictly read-only. You investigate, observe, and report. You do not modify anything in the cluster or any external system. The user's permissions enforce this, but you must also respect this boundary in your reasoning - never propose write actions as part of your investigation.
For HTTP requests, use only `curl -sG` or `curl --silent --get`. Never use `-X`, `-d`, `--data`, or any non-GET method. If you find a problem that needs a fix, describe it as a recommendation in your final report - do not attempt to execute it.
## Available tools and data sources
**kubectl** - read-only commands only (`get`, `describe`, `logs`, `top`, `events`).
**Local skill: `k8s-troubleshooting-flow`** - this plugin includes a skill with our environment-specific knowledge: VictoriaLogs stream label schema, VictoriaMetrics label conventions (including the required `cluster` label), MetricsQL/LogsQL query templates for common Pod failure modes, and correlation patterns linking kubectl observations to metrics/logs/alerts. **Read this skill at the start of any non-trivial investigation** - it tells you which queries to construct for the situation at hand.
**External skills via VictoriaMetrics `query` plugin** - this plugin relies on the official `victoriametrics-tools` marketplace, which provides:
- `victoriametrics-query` skill - executes metrics queries (PromQL/MetricsQL) via curl
- `victorialogs-query` skill - executes log searches (LogsQL) via curl
- `alertmanager-query` skill - queries active and silenced alerts via curl
These skills handle curl mechanics, pagination, and result parsing. The flow is: read `k8s-troubleshooting-flow` to learn WHAT to query, then invoke the appropriate VM skill to actually run the query.
**Environment variables** - the VM skills require these to be set in the user's shell:
- `VM_METRICS_URL` - VictoriaMetrics endpoint
- `VM_LOGS_URL` - VictoriaLogs endpoint
- `VM_ALERTMANAGER_URL` - Alertmanager endpoint
These are configured by the bootstrap script (`scripts/bootstrap.sh` in the atlas-claude-plugins repo) and stored in `~/.config/atlas/env`. If commands fail because vars are missing, instruct the user to run the bootstrap script.
## How to investigate
The investigation flow depends on the entry point. Identify which type of request you got and follow the matching flow.
Before starting any flow, **read the `k8s-troubleshooting-flow` skill** to refresh your memory on:
- Our VictoriaLogs stream schema (so you build correct LogsQL)
- Our VictoriaMetrics label conventions (so you build correct MetricsQL with required `cluster` label)
- The correlation patterns matching the failure mode you're investigating
### Entry point A: Single Pod
Triggered by requests like "debug pod X", "why is X failing", "what's wrong with X in namespace Y".
1. **Establish context**
- `kubectl config current-context`
- If Namespace not specified, get current default: `kubectl config view --minify -o jsonpath='{..namespace}'`
- Verify Pod exists: `kubectl get pod <name> -n <ns>`
2. **Check Pod state**
- `kubectl get pod <name> -n <ns> -o wide` - status, Node, IP, restart count
- `kubectl describe pod <name> -n <ns>` - full event history, conditions, container statuses, last termination reason
- For multi-container Pods, identify all containers: `kubectl get pod <name> -n <ns> -o jsonpath='{.spec.containers[*].name}'`
Pay attention to:
- `Status`, `Reason`, `Message` fields
- Container `State` and `Last State` (with reason: `CrashLoopBackOff`, `OOMKilled`, `Error`, `ImagePullBackOff`)
- `Events` section - especially Warning events
- Resource requests and limits vs actual usage
3. **Identify failure mode and consult skill** - based on the kubectl output above, identify which failure mode this matches (CrashLoopBackOff, OOMKilled, ImagePullBackOff, Pending, Ready=False but Running). Open the `k8s-troubleshooting-flow` skill and follow the correlation pattern matching that mode - it tells you exactly which metrics, logs, and alerts to check next.
4. **Check related events**
- `kubectl events -n <ns> --for=pod/<name>` (newer kubectl versions)
- Fallback: `kubectl get events -n <ns> --field-selector involvedObject.name=<name>`
5. **Check logs (recent, from kubectl)**
- Current container: `kubectl logs <name> -n <ns> --tail=200`
- Previous container if restarted: `kubectl logs <name> -n <ns> --previous --tail=200`
- For multi-container Pods, iterate per container with `-c <container>`
6. **Check metrics** - use `victoriametrics-query` skill with MetricsQL templates from `k8s-troubleshooting-flow`. Always include the `cluster` label as documented in the skill.
7. **Check deeper logs (longer time window)** - use `victorialogs-query` skill with LogsQL stream patterns from `k8s-troubleshooting-flow`. Default time window: last 1 hour. Expand if not enough.
8. **Check related alerts** - use `alertmanager-query` skill. Filter by matching `namespace` and `pod` labels. Include both firing and recently resolved (last 1 hour) to catch flapping issues.
### Entry point B: Namespace overview
Triggered by requests like "what's wrong in namespace X", "check namespace X", "is anything broken in X".
1. **Establish context** - confirm cluster context, verify Namespace exists.
2. **Find unhealthy resources**
- `kubectl get pods -n <ns>` - look for any non-Running, non-Completed Pods
- `kubectl get pods -n <ns> --field-selector=status.phase!=Running,status.phase!=Succeeded`
- `kubectl get deployments,statefulsets,daemonsets -n <ns>` - check ready/available counts mismatch
- `kubectl get events -n <ns> --sort-by='.lastTimestamp' | tail -50` - recent Warning events
3. **Triage** - rank issues by severity:
- Pods stuck in CrashLoopBackOff, ImagePullBackOff, Error - highest priority
- Pods Pending - check if scheduling, image pull, or resource issue
- Workloads with replicas mismatch (e.g. Deployment wants 3, has 2 ready)
- Recent Warning events (OOM, FailedMount, FailedScheduling)
4. **Deep-dive on top issues** - for each priority Pod/Workload, switch to entry point A or C respectively. Limit to top 3-5 issues to keep report manageable. Use `k8s-troubleshooting-flow` correlation patterns for each.
5. **Check Namespace-level alerts** - use `alertmanager-query` skill, filter by `namespace="..."` label.
### Entry point C: Workload (Deployment / StatefulSet / DaemonSet / Job)
Triggered by requests like "why is deployment X not updating", "statefulset Y has issues", "job Z keeps failing".
1. **Establish context** - confirm cluster context, Namespace.
2. **Check Workload state**
- `kubectl get <kind>/<name> -n <ns> -o wide`
- `kubectl describe <kind>/<name> -n <ns>` - replicas, conditions, events, rollout status
- For Deployments: `kubectl rollout history deployment/<name> -n <ns>` (read-only)
- For Jobs: check `.status.conditions` and `.status.failed`/`.status.succeeded`
3. **Check Pods owned by Workload**
- `kubectl get pods -n <ns> -l <workload-selector>` (selector from describe output)
- Identify Pods in bad states - then for each, follow entry point A flow (including consulting `k8s-troubleshooting-flow` per failure mode)
4. **Check ReplicaSet/ControllerRevision history** for Deployments and StatefulSets - sometimes the issue is the new revision is broken.
5. **Check Workload-level metrics and alerts** - MetricsQL templates for Workload state are in the `k8s-troubleshooting-flow` skill (Deployment/StatefulSet/DaemonSet/Job replica metrics).
## How to report findings
Structure your final report in clear sections. Be concrete - include actual values, error messages, timestamps. Avoid filler.
Use this template, adapted to the entry point:
- **Subject** - what you investigated (Pod name / Namespace / Workload kind+name)
- **Status** - one-line summary: healthy / failing / partially failing / pending / etc
- **Key Findings** - bulleted list of specific observations with data
- **Events** - recent significant events with timestamps
- **Logs** - relevant log excerpts with line numbers/timestamps
- **Metrics** - resource usage observations, anomalies
- **Alerts** - firing alerts related to the subject, or "none"
- **Conclusion** - likely root cause based on evidence above
- **Recommended actions** - read-only or human-driven next steps (you cannot execute writes)
For Namespace overview reports, structure findings as a prioritized list of issues, with a brief sub-report per top issue.
## Important rules
- **Never invent data.** If a command fails or returns nothing, report that explicitly. Do not fabricate values.
- **Cite your evidence.** Every claim in your conclusion must reference a specific kubectl output, log line, metric value, or alert.
- **Stay focused.** Investigate what was asked. Do not wander into unrelated cluster issues.
- **Time-box log scans.** Default to last 200 lines or last 1 hour. Expand only if initial scan is insufficient.
- **Limit Namespace deep-dives.** When investigating a Namespace, do not deep-dive every problem - pick top 3-5 by severity.
- **Always consult `k8s-troubleshooting-flow` for query construction.** Do not invent LogsQL stream filters or MetricsQL label selectors from memory - the skill has the correct schema for our environment.
- **Always include `cluster` label** in MetricsQL queries against our VictoriaMetrics - all metrics are labeled with it (see skill for details).
- **Respect read-only boundary.** If you find a problem that needs a fix (e.g. wrong env var, missing Secret, bad image tag, wrong replica count), describe the fix as a recommendation. Do not attempt to apply it.
- **Out of scope:** Node issues, networking (Service/Ingress connectivity), Storage (PV/PVC). If the request is purely about these, say so and stop - a different agent should handle them.
Тепер в плагіні у нас така структура:
$ tree -a plugins/
plugins/
└── k8s-tools
├── .claude-plugin
│ └── plugin.json
├── agents
│ └── k8s-pod-debugger.md
Skill: k8s-troubleshooting-flow
Файл агента plugins/k8s-tools/agents/k8s-pod-debugger.md описує самого агента – що і як він має робити, які утиліти йому доступні.
На додачу до нього – створимо в плагіні окремий Skill, який описує деталі виконання запитів до VictoriaLogs, приклади запитів MetricsQL до VictoriaMetrics, які проблеми з Kubenretes Pods і які перевіряти.
Чому Skill окремо від System Prompt?
Тут кілька важливих моментів, які треба мати на увазі:
розділення абстракцій: System Prompt описує агенту “хто ти“, а Skill описує “як робити X в нашому кластері“
економія контексту: System Prompt додається до кожного запиту до LLM, а Skill читається при потребі – не витрачаємо токени і ліміти.
тобто, коли агенту треба дізнатись “що робити, якщо Pod в стані CrashLoopBackOff” – він автоматично підгрузить Skill і отримає відповідні інструкції – а не буде кожного разу додавати всі деталі до кожного запиту
re-use з іншими агентами: ми додаємо скіл в корінь плагіну – то потім можемо його використовувати для інших агентів, а не дублювати
оновлення скілу: простіше додавати якісь нові деталі в одному місці, а не переписувати в 100500 файлах різних агентів
---
name: k8s-troubleshooting-flow
description: Use when investigating Kubernetes Pod, Workload, or Namespace issues and you need to correlate kubectl observations with metrics (VictoriaMetrics), logs (VictoriaLogs), or alerts (Alertmanager). Provides query templates for common Pod failure modes (CrashLoopBackOff, OOMKilled, Pending, ImagePullBackOff), our specific stream label schema for VictoriaLogs (promtail-based), and standard MetricsQL patterns for kube-state-metrics and cAdvisor.
---
# Kubernetes Troubleshooting Flow
This skill provides query templates and correlation patterns for debugging Kubernetes workloads using our observability stack.
## Our environment
**VictoriaLogs** - log collection via promtail. Stream labels (indexed):
- `namespace` - the only stream-level label
Other useful fields available after stream filter (NOT indexed, but searchable):
- `pod` - Pod name
- `container` - container name within Pod
- `app` - app label from Pod
- `node_name`, `hostname` - Node where Pod runs
- `stream` - `stdout` or `stderr`
**VictoriaMetrics** - prometheus-operator stack. All metrics labeled with:
- `cluster` - cluster identifier (REQUIRED in queries)
- `namespace`, `pod`, `container` - standard k8s labels
- `job`, `instance`, `service`, `endpoint` - infra labels
**Alertmanager** - standard, queried via `alertmanager-query` skill.
## Query template patterns
### LogsQL (via victorialogs-query skill)
Always start with stream filter, then narrow by fields:
_stream:{namespace="<NS>"} pod:"<POD>"
Common patterns:
- All logs for a Pod (last hour):
`_stream:{namespace="<NS>"} pod:"<POD>"`
- Errors only:
`_stream:{namespace="<NS>"} pod:"<POD>" (level:error OR error OR exception OR fatal OR panic)`
- Specific container in multi-container Pod:
`_stream:{namespace="<NS>"} pod:"<POD>" container:"<CONTAINER>"`
- Errors across whole Namespace:
`_stream:{namespace="<NS>"} (level:error OR error OR exception OR fatal)`
- Logs from specific Node (e.g. Node-level issues):
`_stream:{namespace="<NS>"} node_name:"<NODE>"`
### MetricsQL (via victoriametrics-query skill)
Always include `cluster="<CLUSTER>"`. The user will tell you the cluster name, or you can ask if it's not clear.
**Pod state and lifecycle:**
- Current phase: `kube_pod_status_phase{cluster="<C>",namespace="<NS>",pod="<POD>"}`
- Restart count: `kube_pod_container_status_restarts_total{cluster="<C>",namespace="<NS>",pod="<POD>"}`
- Restart rate (last hour): `rate(kube_pod_container_status_restarts_total{cluster="<C>",namespace="<NS>",pod="<POD>"}[1h])`
- Last termination reason: `kube_pod_container_status_last_terminated_reason{cluster="<C>",namespace="<NS>",pod="<POD>"}`
- Ready status: `kube_pod_status_ready{cluster="<C>",namespace="<NS>",pod="<POD>"}`
**Memory (cAdvisor):**
- Working set (current): `container_memory_working_set_bytes{cluster="<C>",namespace="<NS>",pod="<POD>",container!=""}`
- vs limit: `container_memory_working_set_bytes{cluster="<C>",namespace="<NS>",pod="<POD>",container!=""} / container_spec_memory_limit_bytes{cluster="<C>",namespace="<NS>",pod="<POD>",container!=""}`
- OOM kills: `kube_pod_container_status_terminated_reason{cluster="<C>",namespace="<NS>",pod="<POD>",reason="OOMKilled"}`
**CPU (cAdvisor):**
- Usage rate: `rate(container_cpu_usage_seconds_total{cluster="<C>",namespace="<NS>",pod="<POD>",container!=""}[5m])`
- Throttling rate: `rate(container_cpu_cfs_throttled_periods_total{cluster="<C>",namespace="<NS>",pod="<POD>",container!=""}[5m]) / rate(container_cpu_cfs_periods_total{cluster="<C>",namespace="<NS>",pod="<POD>",container!=""}[5m])`
- Throttling > 0 means resource pressure
**Workload state (Deployment / StatefulSet / DaemonSet):**
- Deployment: desired vs available
- `kube_deployment_spec_replicas{cluster="<C>",namespace="<NS>",deployment="<NAME>"}`
- `kube_deployment_status_replicas_available{cluster="<C>",namespace="<NS>",deployment="<NAME>"}`
- StatefulSet: `kube_statefulset_status_replicas_ready{cluster="<C>",namespace="<NS>",statefulset="<NAME>"}`
- DaemonSet: `kube_daemonset_status_number_unavailable{cluster="<C>",namespace="<NS>",daemonset="<NAME>"}`
- Job: `kube_job_status_failed{cluster="<C>",namespace="<NS>",job_name="<NAME>"}`
**Namespace-wide health:**
- Failing Pods count: `count(kube_pod_status_phase{cluster="<C>",namespace="<NS>",phase=~"Failed|Pending|Unknown"})`
- Pods with restarts in last hour: `count(increase(kube_pod_container_status_restarts_total{cluster="<C>",namespace="<NS>"}[1h]) > 0)`
### Alertmanager (via alertmanager-query skill)
- Alerts for a Pod: filter by `pod="<POD>"` label
- Alerts for a Namespace: filter by `namespace="<NS>"` label
- Include `state=active` for currently firing
- Include recently resolved (last 1h) to catch flapping issues
## Correlation patterns by failure mode
For each Pod failure mode, this is what to look for and where:
### CrashLoopBackOff
**Signal in kubectl:**
- `kubectl describe pod` - container State `Waiting` with reason `CrashLoopBackOff`, Last State `Terminated` with exit code
**What to check:**
1. Last termination reason and exit code (kubectl describe)
2. Previous container logs: `kubectl logs <pod> --previous`
3. Restart count metric - is it climbing?
4. Time between restarts - constant (looks like the app starts then fails) or growing (BackOff is increasing)?
5. Logs in VictoriaLogs around restart timestamps - look for stack traces, init errors, missing config
**Common root causes:**
- Application bug on startup (check logs)
- Missing/wrong config (env var, ConfigMap, Secret)
- Failing readiness/liveness probe (check probe config in describe)
- Out of memory (cross-check with OOMKilled metric and memory metrics)
### OOMKilled
**Signal in kubectl:**
- `kubectl describe pod` - Last State `Terminated`, Reason `OOMKilled`, exit code 137
**What to check:**
1. `kube_pod_container_status_terminated_reason{...,reason="OOMKilled"}` - confirm in metrics
2. Memory usage trend leading up to kill: `container_memory_working_set_bytes{...}` over last 6h
3. Memory limit: `container_spec_memory_limit_bytes{...}`
4. Was it gradual leak or sudden spike?
5. Logs right before the kill (last 5 min before termination timestamp)
**Common root causes:**
- Memory leak in application
- Limit set too low for actual workload
- Sudden traffic spike causing memory allocation
### ImagePullBackOff / ErrImagePull
**Signal in kubectl:**
- `kubectl describe pod` - Events show `Failed to pull image`, `ErrImagePull`, `ImagePullBackOff`
**What to check:**
1. Exact image reference in Pod spec
2. Pull error message in events (auth, not found, network)
3. Check imagePullSecrets configured on Pod or ServiceAccount
**Common root causes:**
- Wrong image tag (typo, doesn't exist)
- Registry auth failure (missing/expired pull secret)
- Network issue from Node to registry
- Rate limiting (Docker Hub anonymous pulls)
### Pending
**Signal in kubectl:**
- `kubectl get pod` shows status `Pending` for >30s
**What to check:**
1. `kubectl describe pod` Events - scheduler messages
2. Common scheduler errors:
- `0/N nodes are available: insufficient cpu/memory` - resource pressure
- `node(s) didn't match Pod's node affinity/selector` - scheduling rules issue
- `node(s) had untolerated taint` - taints/tolerations issue
- `error getting PVC` - storage issue (out of scope, mention it)
3. Node resource availability: `kube_node_status_allocatable{cluster="<C>"}` vs requests on Pending Pod
**Common root causes:**
- Cluster out of resources for requested CPU/memory
- Node selector/affinity doesn't match any Node
- Taints not tolerated
- Storage class not provisioning (refer to storage agent)
### Pod Ready=False but Running
**Signal in kubectl:**
- `kubectl get pod` - status Running but READY shows `0/1`
**What to check:**
1. Container statuses in describe - which probe failing (readiness vs liveness)
2. Probe configuration - endpoint, expected response
3. Logs of the probe target (often the app's `/health` endpoint)
4. Was this recent change? Check rollout history if Deployment
**Common root causes:**
- App takes longer to start than `initialDelaySeconds`
- Wrong probe endpoint or expected response
- Backend dependency unavailable (DB, cache) - app can't become ready
## Investigation discipline
Reminders for the investigating agent:
- **Time-box**: default to last 1h for logs, last 6h for metric trends. Expand only if data is insufficient.
- **Cite evidence**: every finding must reference a specific kubectl output, log line with timestamp, metric value, or alert.
- **Don't conflate symptoms with causes**: "Pod is OOMKilled" is a symptom. The cause is "memory leak in handler X" or "limit set 256Mi but workload needs 512Mi".
- **Stop when you have enough**: a clear root cause + supporting evidence is the goal. Don't keep digging if the answer is found.
Створення Bootstrap скрипту
Агенту для роботи потрібні декілька environment variables – як підключатись до ендпоінтів VictoriaMetrics, VictoriaLogs, Alertmanager.
У нас VictoriaMetrics та VictoriaLogs мають власні Ingress, які доступні через AWS Internal Application Load Balancer та доступні через VPN, тому при додаванні плагіну треба перевірити, що вони доступні.
Заодно перевіряємо наявність kubectl, jq, curl, etc.
Змінні оточення записуємо в файл ~/.config/atlas/env, який потім використовується при старті агенту і описаний в його System Prompt.
Скрипт cross-platform – бо у нас є і macOS юзери, і Linux.
#!/usr/bin/env bash
# Atlas Claude Plugins - bootstrap script
#
# Sets up the local environment needed for the k8s-tools plugin and
# VictoriaMetrics observability skills. Cross-platform (macOS / Linux).
#
# Usage:
# ./scripts/bootstrap.sh # interactive setup
# ./scripts/bootstrap.sh --force # overwrite existing env file without asking
# ./scripts/bootstrap.sh --help # show help
set -euo pipefail
# Defaults that can be overridden via env vars before invocation
DEFAULT_VM_METRICS_URL="${VM_METRICS_URL:-https://vmsingle.monitoring.1-33.ops.example.co}"
DEFAULT_VM_LOGS_URL="${VM_LOGS_URL:-https://vmlogs.monitoring.1-33.ops.example.co}"
DEFAULT_VM_ALERTMANAGER_URL="${VM_ALERTMANAGER_URL:-http://localhost:9093}"
ENV_DIR="${HOME}/.config/atlas"
ENV_FILE="${ENV_DIR}/env"
# Color output (disabled if not a TTY)
if [ -t 1 ]; then
C_RED=$'\033[31m'
C_GREEN=$'\033[32m'
C_YELLOW=$'\033[33m'
C_BLUE=$'\033[34m'
C_BOLD=$'\033[1m'
C_RESET=$'\033[0m'
else
C_RED=""
C_GREEN=""
C_YELLOW=""
C_BLUE=""
C_BOLD=""
C_RESET=""
fi
log_info() { printf "%s[INFO]%s %s\n" "$C_BLUE" "$C_RESET" "$*"; }
log_ok() { printf "%s[OK]%s %s\n" "$C_GREEN" "$C_RESET" "$*"; }
log_warn() { printf "%s[WARN]%s %s\n" "$C_YELLOW" "$C_RESET" "$*"; }
log_error() { printf "%s[ERROR]%s %s\n" "$C_RED" "$C_RESET" "$*" >&2; }
usage() {
cat <<EOF
Atlas Claude Plugins - bootstrap script
Sets up environment variables required by k8s-tools plugin and
VictoriaMetrics skills (victoriametrics-query, victorialogs-query, alertmanager-query).
Usage:
$(basename "$0") [--force] [--help]
Options:
--force Overwrite existing env file (${ENV_FILE}) without prompting.
--help Show this help message.
Environment variables (used as defaults if set):
VM_METRICS_URL Default: ${DEFAULT_VM_METRICS_URL}
VM_LOGS_URL Default: ${DEFAULT_VM_LOGS_URL}
VM_ALERTMANAGER_URL Default: ${DEFAULT_VM_ALERTMANAGER_URL}
EOF
}
# Parse arguments
FORCE=0
for arg in "$@"; do
case "$arg" in
--force) FORCE=1 ;;
--help|-h) usage; exit 0 ;;
*) log_error "Unknown argument: $arg"; usage; exit 1 ;;
esac
done
# OS detection
detect_os() {
case "$(uname -s)" in
Darwin) echo "macos" ;;
Linux) echo "linux" ;;
*) echo "unknown" ;;
esac
}
OS="$(detect_os)"
log_info "Detected OS: ${OS}"
# Shell detection
detect_shell() {
local shell_path="${SHELL:-}"
if [ -n "$shell_path" ]; then
basename "$shell_path"
else
echo "unknown"
fi
}
USER_SHELL="$(detect_shell)"
shell_rc_file() {
case "$USER_SHELL" in
bash) echo "${HOME}/.bashrc" ;;
zsh) echo "${HOME}/.zshrc" ;;
fish) echo "${HOME}/.config/fish/config.fish" ;;
*) echo "" ;;
esac
}
# Dependency checks
install_hint() {
local tool="$1"
case "$OS" in
macos)
case "$tool" in
kubectl) echo " brew install kubectl" ;;
curl) echo " curl is preinstalled on macOS, check your PATH" ;;
jq) echo " brew install jq" ;;
claude) echo " npm install -g @anthropic-ai/claude-code (or https://claude.ai/download)" ;;
esac
;;
linux)
case "$tool" in
kubectl) echo " https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/" ;;
curl) echo " sudo apt install curl # or: sudo dnf install curl" ;;
jq) echo " sudo apt install jq # or: sudo dnf install jq" ;;
claude) echo " npm install -g @anthropic-ai/claude-code (or https://claude.ai/download)" ;;
esac
;;
*)
echo " (install ${tool} for your platform)"
;;
esac
}
check_dep() {
local cmd="$1"
if command -v "$cmd" >/dev/null 2>&1; then
log_ok "${cmd} found: $(command -v "$cmd")"
return 0
else
log_error "${cmd} not found in PATH"
printf " Install hint:\n%s\n" "$(install_hint "$cmd")"
return 1
fi
}
log_info "Checking dependencies..."
DEPS_OK=1
for dep in kubectl curl jq claude; do
check_dep "$dep" || DEPS_OK=0
done
if [ "$DEPS_OK" -eq 0 ]; then
log_error "Some dependencies are missing. Install them and re-run this script."
exit 1
fi
# Handle existing env file
if [ -f "$ENV_FILE" ] && [ "$FORCE" -eq 0 ]; then
log_warn "Env file already exists: ${ENV_FILE}"
log_warn "Current contents:"
printf "%s---%s\n" "$C_BOLD" "$C_RESET"
cat "$ENV_FILE"
printf "%s---%s\n" "$C_BOLD" "$C_RESET"
log_warn "Re-run with --force to overwrite, or edit the file manually."
exit 0
fi
# Interactive prompts - prompt goes to stderr, value to stdout
# This way command substitution captures only the value, not the prompt
prompt_with_default() {
local label="$1"
local default="$2"
local answer
# Prompt to stderr (visible to user, not captured by $(...))
printf "%s%s%s [%s]: " "$C_BOLD" "$label" "$C_RESET" "$default" >&2
read -r answer
if [ -z "$answer" ]; then
echo "$default"
else
echo "$answer"
fi
}
log_info "Configure observability endpoints (press Enter to accept default):"
echo
VM_METRICS_URL_VAL="$(prompt_with_default "VictoriaMetrics URL" "$DEFAULT_VM_METRICS_URL")"
VM_LOGS_URL_VAL="$(prompt_with_default "VictoriaLogs URL" "$DEFAULT_VM_LOGS_URL")"
VM_ALERTMANAGER_URL_VAL="$(prompt_with_default "Alertmanager URL" "$DEFAULT_VM_ALERTMANAGER_URL")"
echo
# Connectivity check (non-fatal)
check_url() {
local url="$1"
local label="$2"
if curl -sS -o /dev/null -w "%{http_code}" --max-time 3 "$url" 2>/dev/null | grep -qE '^[234]'; then
log_ok "${label} reachable (${url})"
else
log_warn "${label} not reachable (${url}) - check VPN if this is an internal endpoint"
fi
}
log_info "Checking connectivity..."
check_url "$VM_METRICS_URL_VAL" "VictoriaMetrics"
check_url "$VM_LOGS_URL_VAL" "VictoriaLogs"
check_url "$VM_ALERTMANAGER_URL_VAL" "Alertmanager"
echo
# Write env file
log_info "Writing ${ENV_FILE}..."
mkdir -p "$ENV_DIR"
cat > "$ENV_FILE" <<ENVEOF
# Atlas Claude Plugins - environment configuration
# Generated by scripts/bootstrap.sh on $(date -u +"%Y-%m-%dT%H:%M:%SZ")
#
# These variables are required by:
# - victoriametrics-query skill (from victoriametrics-tools marketplace)
# - victorialogs-query skill
# - alertmanager-query skill
#
# Re-run scripts/bootstrap.sh --force to regenerate.
export VM_METRICS_URL="${VM_METRICS_URL_VAL}"
export VM_LOGS_URL="${VM_LOGS_URL_VAL}"
export VM_ALERTMANAGER_URL="${VM_ALERTMANAGER_URL_VAL}"
ENVEOF
chmod 600 "$ENV_FILE"
log_ok "Env file written (mode 600)"
echo
# Shell rc integration hint
RC_FILE="$(shell_rc_file)"
SOURCE_LINE='[ -f ~/.config/atlas/env ] && source ~/.config/atlas/env'
log_info "Next step: make these variables available in your shell."
echo
if [ -n "$RC_FILE" ]; then
if [ -f "$RC_FILE" ] && grep -qF "$SOURCE_LINE" "$RC_FILE" 2>/dev/null; then
log_ok "Source line already present in ${RC_FILE}"
else
cat <<HINTEOF
Add this line to ${C_BOLD}${RC_FILE}${C_RESET}:
${C_GREEN}${SOURCE_LINE}${C_RESET}
Or run this once:
${C_GREEN}echo '${SOURCE_LINE}' >> ${RC_FILE}${C_RESET}
Then reload your shell:
${C_GREEN}source ${RC_FILE}${C_RESET}
HINTEOF
fi
else
log_warn "Could not detect your shell rc file. Add this line manually to your shell config:"
echo " ${SOURCE_LINE}"
echo
fi
# Next steps
cat <<NEXTEOF
${C_BOLD}=== Setup complete ===${C_RESET}
To use the plugin, start Claude Code:
${C_GREEN}claude${C_RESET}
Then inside Claude Code (first time only):
${C_GREEN}/plugin marketplace add Org-Engineering/atlas-claude-plugins${C_RESET}
${C_GREEN}/plugin marketplace add VictoriaMetrics/skills${C_RESET}
${C_GREEN}/plugin install k8s-tools@atlas-claude-plugins${C_RESET}
${C_GREEN}/plugin install query@victoriametrics-tools${C_RESET}
If you cloned this repo and opened it in Claude Code, the marketplaces
will be suggested automatically (via .claude/settings.json).
NEXTEOF
Що робить скрипт:
визначає операційну систему – macOS чи Linux, бо трохи відрізняються утиліти типу date та sed
перевіряє чи встановлені всі потрібні утиліти, якщо нема – пропонує команду для установки
перевіряємо наявність файлу ~/.config/atlas/env
запитує значення для змінних VM_METRICS_URL, VM_LOGS_URL, VM_ALERTMANAGER_URL, пропонує встановити дефолти – але можна перевизначити
тут єдиний нюанс – конкретно в нашому випадку у VM_ALERTMANAGER_URL нема Ingress/ALB, тому підключення через localhost – потім зроблю нормально, бо раніше ним користувався виключно я і мені було OK робити kubectl port-forward
виконує підключення до VM_METRICS_URL – перевіряє, що VPN включений і ендпоінти доступні
записує змінні до ~/.config/atlas/env
визначає user shell (zsh, bash), показує юзеру як додати ~/.config/atlas/env до shell rc
і в кінці виводить команди “як додати маркетплейс та плагін“
Запускаємо, перевіряємо як все працює:
Тут як раз забув kubectl port-forward до Alertmanager – отримав “[WARN] Alertmanager not reachable“.
Перевірка Marketplace та Plugin
В принципі – на цьому етапі вже все готово.
Але перед тим, як додавати CLAUDE.md та REAME.md і пушити в репозиторій – протестуємо локально, як все працює.
Переходимо в тестову директорію, запускаємо Claude Code:
$ cd /tmp && mkdir -p test-plugin && cd test-plugin
$ claude
$ kk get pod -A | grep -v Running
NAMESPACE NAME READY STATUS RESTARTS AGE
ops-monitoring-ns atlas-victoriametrics-grafana-5f8ff65758-tbwzb 0/3 Completed 0 8d
Бачимо, що агент знайшов і прочитав скіл в ~/.local/share/claude-code/plugins/k8s-troubleshooting-flow/skill.md.
І результат дебагу:
Файл CLAUDE.md
CLAUDE.md – це файл який Claude Code автоматично підхоплює як контекст коли хтось працює з репозиторієм. Тобто коли я через пів року відкрию репозиторій в Claude Code, щоб додати новий плагін чи поправити існуючий – Claude відразу буде розуміти що це за проект
Важливо не плутати з README.md:
CLAUDE.md: для тих, хто додає/змінює плагіни в репо з Claude Code
README.md: для юзерів плагіну (девелоперів, які встановлюють і користуються агентом)
Що в CLAUDE.md:
структура репо з коментарями що для чого
правила і naming conventions – коментарі в коді англійською, read-only by default, Kubernetes ресурси з великої букви, env naming
як додати новий плагін в існуючий marketplace
правила версіонування
як тестувати локально перед push
як публікувати на GitHub
Весь зміст:
# atlas-claude-plugins
Claude Code plugins for Org DevOps - Kubernetes debugging and operations.
## Repo structure
```
.claude-plugin/marketplace.json # marketplace manifest, lists all plugins
.claude/settings.json # extraKnownMarketplaces (auto-suggest on clone)
plugins/<plugin-name>/ # one directory per plugin
.claude-plugin/plugin.json # plugin metadata
agents/<agent-name>.md # agent definitions (filename = name in frontmatter)
skills/<skill-name>/SKILL.md # skills (each in its own directory)
commands/<command-name>.md # slash commands (optional)
scripts/bootstrap.sh # user setup (env vars, deps check)
```
## Conventions
- **Code comments in English** always, regardless of context language
- **Agents are read-only by default**: explicit `allowed-tools` whitelist + `deny-tools` blacklist for write operations (kubectl write verbs, curl POST/PUT/DELETE, file writes)
- **Kubernetes resources capitalized in prose**: Pod, Deployment, Namespace, Service, etc
- **Env vars follow VictoriaMetrics convention**: `VM_METRICS_URL`, `VM_LOGS_URL`, `VM_ALERTMANAGER_URL` (so VM skills work without aliasing)
- **User config lives in `~/.config/atlas/env`** - never in repo, never in shell rc directly
## Adding a new plugin
1. Create `plugins/<name>/.claude-plugin/plugin.json` with name, version, description
2. Add agent(s) in `plugins/<name>/agents/<agent>.md` - frontmatter `name` must match filename
3. Add skill(s) in `plugins/<name>/skills/<skill>/SKILL.md` - directory name must match skill `name`
4. Register in `.claude-plugin/marketplace.json` under `plugins[]` array
5. Bump marketplace `version` in `marketplace.json`
## Versioning
- Each plugin has independent semver in its `plugin.json`
- Marketplace `version` in `marketplace.json` bumps when plugin list changes (add/remove)
- Plugin patch version bumps for prompt/skill content changes
- Plugin minor version bumps for new capabilities (new tools, new entry points)
- Plugin major version bumps for breaking changes (renamed agent, removed permissions)
## Testing locally
```bash
# 1. Run bootstrap (sets up env file + checks deps)
./scripts/bootstrap.sh
# 2. Source env in current shell (or open new shell if added to rc)
source ~/.config/atlas/env
# 3. Start Claude in some unrelated directory (NOT this repo)
cd /tmp && mkdir -p test-claude && cd test-claude && claude
# 4. Inside Claude, add this repo as local marketplace
/plugin marketplace add /path/to/atlas-claude-plugins
/plugin install <plugin-name>@atlas-claude-plugins
# 5. Verify agent loaded
/agents
# should show: Plugin agents - <plugin>:<agent>
# 6. Test the agent with a real task
> Use <agent-name> to debug pod foo in namespace bar
```
After changes to plugin files: `/plugin marketplace update atlas-claude-plugins` reloads.
## Publishing
```bash
git add -A
git commit -m "..."
git push origin master
```
Users on the next `/plugin marketplace update` get the changes. Or, if they cloned the repo, `extraKnownMarketplaces` in `.claude/settings.json` auto-suggests the marketplace on first open.
## Dependencies
- Plugins use `kubectl` + `curl` directly (no MCP servers)
- VictoriaMetrics observability via `query` plugin from `VictoriaMetrics/skills` marketplace - listed as suggested in `.claude/settings.json`
- Agents must work with read-only kubectl perms - never assume write access
Файл README.md
І останній файл – чисто для девелоперів: що в репозиторії, як користуватись:
Власне – на цьому все.
Пушимо в репозиторій і перевіряємо ще раз.
Перевірка extraKnownMarketplaces
Видаляємо вже встановлений маркетплейс:
/plugin marketplace remove atlas-claude-plugins
Перевіряємо, що його нема:
Створюємо тестову директорію:
$ mkdir /tmp/test-extra && cd /tmp/test-extra
Клонуємо репозиторій, запускаємо в ньому Claude Code:
$ git clone [email protected]:Org-Engineering/atlas-claude-plugins.git
$ cd atlas-claude-plugins/
$ claude
Підтверджуємо довіру каталогу:
Перевіряємо маркеплейси – маємо там і наш atlas-claude-plugins, і victoriametrics-tools:
налаштувати Users Provisioning: всіма юзерами хочеться керувати з Okta, тобто при створенні Okta User – автоматично створювати Google account, а при деактивації юзера в Okta – блокувати і його акаунт в Google
налаштувати SSO/SAML: юзери мають логінитись в Google сервіси тільки через Okta
В цій частині налаштуємо Provisioning, а в наступній – SSO.
Але все ж тому посту 7 (OMG!) років, до того ж зараз я роблю дві інтеграції, тому нехай буде свіженький матеріал, ну і цього разу вийшло більше детально.
Тут приклади на моєму власному акаунті Google Workspaces, але вже зроблено і на робочому проекті – в продакшені вже з місяць, політ нормальний.
Сподіваюсь таки буде час подивитись на Authentik – open-source self-hosted IdP, альтернатива Okta, але поки не дуже актуально, бо у нас вже є ліцензії на Okta, а Open Source версії нема багатьох готових інтеграцій. Хіба що, може, візьму його для свого Home NAS на FreeBSD та його сервісів.
Як і у випадку з Provisioning для AWS і його IAM Identity Center – керування юзерами з Okta в Google Workspace відбувається за протоколом SCIM.
SCIM був створений у 2011 році аби навести порядок в різних інтеграціях, версія SCIM 2.0 була опублікована у 2015 і тепер використовується майже всюди – див. RFC 7642-7644.
По факту, це REST API, який описує як мають відбуватись операції з юзерами та групами – create, read, update, delete, у RFC вище є приклади GET/POST/PATCH запитів:
В Okta Google Workspace App “знає” які API-запити робити до Google аби створити юзера – а Okta знає що треба передати “на вхід” до Google Workspace.
Альтернативи – LDAP (колись писав про OpenLDAP), JIT provisioning (Just-in-Time) – коли маємо SSO з сервісом, і юзер перший раз логіниться – то в цьому сервісі створюється юзер.
Okta: додавання Google Workspaces App
Для налаштувань Google Workspaces App в Okta треба буде вказати Company Domain.
Важливо: після створення App поле “Your Google Apps company domain” просто через Edit вже змінити не можна – тому налаштуйте відразу, він треба буде для SSO.
Він буде використовуватись в SSO та при створенні посилань на сервіси.
Тобто лінк на Gmail буде виглядати як https://mail.google.com/a/setevoy.kiev.ua.
Додаємо нову Application в Okta, в General Settings задаємо цей Company Domain:
В Sign-On поки нічого не міняємо – в другій частині налаштуємо SAML:
Тут все – можна робити Provisioning.
Налаштування Provisioning
Переходимо на вкладку Provisioning, клікаємо Configure API Integration:
Логінимось з адмін-акаунтом (з роллю Super Admin) нашого Google Workspace:
Тут опція Push Empty Values for Custom Fields – якщо в Okta User Profile є кастомні атрибути, але вони з пустими значеннями – то Okta не передає їх до Google.
Attribute Mappings є в Profile Editor:
Але там з Okta до Google заданий тільки один userName:
Опція Import Groups – чи переносити групи з https://admin.google.com/ac/groups до Okta як окремих юзерів. В моєму випадку, коли інтеграція буде тільки для менеджменту саме юзерів – то групи не потрібні.
Google Workspace Permissions для Okta
Натискаємо “Authentificate with Google Workspace”, вибираємо що Okta може робити в Google:
View user schemas on your domain, See info about users on your domain, View and manage the provisioning of users on your domain: включаємо, це основне, для чого робимо інтеграцію – робота з Google Users
View and manage the provisioning of groups on your domain, View and manage group subscriptions on your domain: якщо хочемо керувати Google Groups з Okta – включаємо
тоді зможемо робити Group Push із Okta да Google: якщо маємо Okta Group як “my-Group“, то вона буде додана в Google як “[email protected]“
коли додаємо Okta юзера до Okta Group – то він буде доданий і до Google Group
View and manage organization units on your domain: якщо маємо мапінг атрибута в Okta на поле Organization Unit (OU) і вмикаємо цей дозвіл – то Okta може керувати OU юзера в Google
Manage delegated admin roles: якщо використовуємо Manage roles on create and update (буде далі) – якщо ролями Google з Okta керувати не плануємо – можна пропустити
View and manage Google Workspace licenses: чи дозволяти керувати ліцензіями
Manage data access permissions: керування сесіями – деактивація юзера в Okta завершує всі його активні сесії в Google, включаємо
Після аутентифікації Okta ще не почне нічим керувати – всі юзери в Google залишаться без змін, бо сам Provisioning ще не налаштований.
Але в будь-якому випадку для Production варто створити окремого breaking glass юзера, який не інтегрований ні з SSO, ні з provisioning.
Включаємо всі дозволи:
Готово:
Імпорт юзерів з Google до Okta
Okta дозволяє виконати синхронізацію юзерів як з Okta до Google, так і навпаки:
якщо в Okta вже юзери, а Google акаунт новий або там вже є ті самі юзери – то цю частину можна пропустити
якщо вже маємо юзерів в Google Workspaces і налаштовуємо новий акаунт Okta – то можемо імпортувати юзерів з Google до Okta
Google to Okta: параметри імпорту
Спершу можна зайти в Provisioning > To Okta, і перевірити налаштування там.
В принципі, зараз тут залишаємо всі дефолтні параметри, але маємо на увазі, що тут можна змінити.
В General можемо додати запуск по крону та, якщо використовуємо власний, то змінити Okta username format.
З цікавого тут опція Update application username on: теж залишаємо дефолтне значення Create only, бо навіть якщо ми включимо її в Create and update, то це вплине тільки на SSO цього юзера – який username буде відправлятись в SAML assertion (див. What is: SAML – обзор, структура и трассировка запросов на примере Jenkins и Okta SAML SSO, 2019 рік), але в самому Google акаунт автоматично не перейменується:
Далі, опції в “User Creation & Matching”:
Imported user is an exact match if: як Okta порівнює юзерів із Google з власною базою – залишаємо по email
Allow partial matches: якщо email юзера в Google != в Okta, то Okta спробує пошукати по First Name / Last name, в Production краще відключити – можемо мати двох юзерів зі схожими іменами/фаміліями, Okta може їх спутати (хоча ми все одно далі будемо робити manual review)
Confirm matched users та Confirm new users: можна включити автоматичний approve для імпортованих юзерів, дефолтне значення off, і для production це правильно
І останні дві частини тут – “Profile & Lifecycle Sourcing” та “Import Safeguard”.
Allow Google Workspace to source Okta users визначає хто буде керувати профілями: якщо включити, то профілі редагуються в Google, для Okta вони стають read only – не треба.
Import Safeguard – дуже корисна штука: якщо ми маємо 50 юзерів Okta, яким підключена Google Workspaces, а потім при імпорті з Google (наприклад, якщо включити імпорт за розкладом) Okta отримала від Google не 50 акаунтів, а тільки 5 – то вона не буде виконувати Google Workspace App unassign всіх юзерів, а зупинить імпорт і потребує ручного підтвердження:
Google до Okta: запуск імпорту
Для імпорту із Google до Okta переходимо у, власне, Import, клікаємо Import now.
Опції Confirm matched users та Confirm new users, які бачили вище, зараз відключені, тому натискання Import now ще не запустить імпорт, а тільки отримає список юзерів від Google:
В моєму акаунті тільки три юзера:
І три акаунти Okta і побачила:
Клікаємо OK, і тепер маємо можливість вибрати кого саме ми будемо імпортувати з Google до Okta.
Merge та Create Okta Users
Я буду в Okta додавати тільки одного тестового юзера, [email protected] – справа відмічаємо його і внизу клікаємо Confirm Assignments:
З юзерами, у яких статус Partial user march є кілька варіантів – змержити юзера, створити нового, заматчити на іншого існуючого юзера, або взагалі ігнорувати – клікаємо на такий partial match, і вибираємо дію з drop-down списку:
Ще нюанс: якщо юзер вже Suspended в Google – то в списку на Import він не додається. Але якщо такий юзер в Okta вже є, і навіть якщо він Deactivated – то Okta його додасть в список.
Можна відразу активувати його, клікаємо Confirm:
І перевіряємо.
Переходимо в Directory > People, маємо там нового Okta User:
Якому вже підключена Google Workspace App:
Тепер зробимо навпаки – синхронізацію юзерів з Okta до Google.
Provisioning з Okta до Google
Основна задача: при створенні нового Okta User (точніше – під час Assign юзера до Google Workspace App) треба автоматично створювати нові акаунти в Google Workspace.
Аналогічно при деактивації юзера в Okta – треба блокувати його акаунт в Google.
Тобто весь менеджмент акаунтами Google буде виконуватись через Okta, і Okta буде нашим “source of truth” для юзерів і їхнього стану (active, deactivated/suspended).
Okta to Google: параметри Provisioning
Переходимо в Provisioning > To App, клікаємо Edit, включаємо всі опції (або тільки Create Users, якщо хочеться спокійно потестити на “production” Google акаунті).
З цікавого тут Sync Password – який пароль буде задано в новому Google акаунті. Можна згенерити рандомний, можна встановити такий жеж, як у Okta User.
Опція Update User Attributes визначає, чи буде Okta міняти атрибути: якщо включено, і у юзера в Okta Profile змінився First Name – це поле буде змінено і в Google. Якщо відключено – то атрибути передаються тільки під час create user в Google:
Use of Sync Password
Тут окреме питання по Sync Password:
якщо у нас вже є юзер в Google з власним паролем, якого ми вже імпортували і виконали Assign на Google Workspace App, то зараз, коли ми збережемо Okta to Google provisioning – в нього зміниться пароль, чи ні?
я перевіряв на цьому, тестовому акаунті – і пароль не міняється, тобто існуючі Google Users продовжують логінитись, як і до налаштування інтеграції
але в робочому акаунті проекті все ж не ризикнув включати
і навіть тех. підтримка спочатку сформулювала відповідь як “If you don’t use SSO, just the Provisioning features, then yes, the Sync Password feature would override the users password“
Але пізніше я таки добився чіткої відповіді:
The passwords will be overridden, but it’s not going to be immediately as you enable the feature.
The password sync is based on certain triggers which typically are unavoidable (as discussed in this article).
Adding the specifics here as well for convenience:
” In order to trigger the password sync for a user, one of these events must occur:
Resetting an Okta-sourced password.
Signing in to Okta with a password.
Delegated authentication sign-in to Okta. “
In addition to those, app assignment or re-assignment after you enable the sync password feature also triggers the override.
Therefore, it’s possible that some users will still use the original password if none of the above events happened.
Тобто рано чи пізно – але пароль для Google акаунту таки зміниться.
Можна просто залишити цю опцію вимкненою взагалі – але тоді маємо проблему chicken and eggs: як передати новому юзеру його пароль?
Наприклад, у нас на проекті Slack login через Google. Тому в Slack теж не скинеш якийсь тимчасовий пароль.
Ідеально – включати опцію Sync Okta Password:
Але це ідеально, якщо у вас буде SSO в Google через Okta.
У нас SSO поки що не буде, і мені зараз жим-жим робити це для десятків юзерів які вже є в Google і яких я вже імпортував до Okta.
Тому цю опцію не включав взагалі – будемо передавати пароль на папірці :trollface:
Okta to Google: перевірка створення акаунту
Зберігаємо налаштування, і для перевірки додаємо в Okta нового юзера – але тільки створення нового Okta User, без, власне assign до Google Workspace App в Okta, ще не створить Google Account:
Аби додати новий акаунт в Google – переходимо до Google Workspace Application > Assignments:
Підключаємо цього тестового юзера:
В опціях можна залишити все дефолтним, або відразу задати ролі в Google Workspace.
Опцію Manage roles on create and update залишаємо відключеною – ролями в Google краще керувати самим:
Зберігаємо і дивимось логи в Reports > System log (взагалі корисна штука, потім треба буде налаштувати моніторинг) – бачимо, що push to Google виконаний без помилок:
Перевіряємо юзерів в самому Google:
Я в Okta залишив дефолтну опцію “Sync a randomly generated password“, тому для перевірки резетаємо пароль:
І логінимось:
Все працює:
Okta User Deactivation та Google Account Suspend
І перевіримо, як працює синхронізація стану юзера:
коли ми виконаємо Unassign юзера в Okta від Google Workspaces App, або якщо робимо Okta User Deactivate – то в Google його акаунт перейде в стан Suspended
при видалені юзера з Okta – його акаунт в Google залишиться, але теж в стані Suspended, але тільки якщо в Provisioning > To App включена опція Deactivate Users (по дефолту включена)
В цілому, хоча це все і доступне тільки в рамках VPN або домашньої мережі – але внутрішня параноя кричить, коли бачить HTTP замість HTTPS, а тому хочеться мати SSL/TLS і налаштувати NGINX з ним.
Купувати сертифікат для такого use case сенсу нема, Let’s Encrypt теж не підійде – бо доступу до NGINX з інтернету нема, а DNS challenge для домашньої зони .setevoy піднімати – то трохи геморою, бо TXT має бути для публічно доступної зони.
Тому просто зробимо свій Certificate Authority з блекджеком і дівчатами, а потім ним підпишемо власний wildcard self-signed сертифікат для NGINX.
Ну а заодно згадаємо як взагалі працюють CA та приватні та публічні сертифікати.
Домени для Home NAS
В мене є “домашня” top level domain зона .setevoy в якій живуть всі мої сервіси і яка включає в себе два внутрішні домени:
.aws.setevoy: ресурси в AWS – EC2 для самого блогу RTFM, окремий EC2 для NAT Gateway, і інстанс RDS
зроблено окремою зоною, бо це виключно AWS-related ресурси
.net.setevoy: це вже ресурси в моїх локальних мережах – одна квартира під “офіс”, в якій більшість хостів (сам NAS, MikroTik, робочий ноутбук тощо), та домашня мережа – там тільки домашній ноутбук
Відповідно в домені .net.setevoy будуть адреси:
work.net.setevoy: робочий ноут
nas.net.setevoy: ThinkCentre з FreeBSD/NAS
gw.net.setevoy: MikroTik RB4011
А для веб-сервісів будуть адреси типу grafana.net.setevoy для Grafana, victoria.net.setevoy – для VictoriaMetircs, logs.net.setevoy для VictoriaLogs тощо.
Власне, що для цього всього треба зробити – це wildcard SSL-сертифікат, який потім буде використовуватись в NGINX.
Аби браузери не сварились на нього – створимо власний CA-сертифікат, який потім я додам на свої робочий та домашній ноутбуки, і з власним Certificate Authority підпишемо wildcard-сертифікат для веб-сервісів.
Чому wildcard не на сам .setevoy
Перша думка була “зроблю собі *.setevoy, і буде один сертифікат на все” – але так не вийде, бо wildcard на TLD заборонений і, наприклад, Chrome відкидає такий сертифікат з помилкою ERR_CERT_COMMON_NAME_INVALID.
Формально RFC 6125 – 6.4.3 каже тільки те, що wildcard має бути в найлівішому лейблі (*.example.com – ОК, bar.*.example.net – ні) – і цьому *.setevoy відповідає.
Крім того, RFC прямо нічого не каже про мінімум лейблів (рівнів домену) – це навіть описана проблема цього RFC.
Але на практиці TLS-клієнти додають своє правило, наприклад, GnuTLS документує це явно – див. gnutls_x509_crt_check_hostname2:
wildcards […] are only considered if the domain name consists of three components or more
Тобто *.setevoy (2 компоненти) – не валідно, *.net.setevoy (3 компоненти) – валідно.
Chrome (через BoringSSL) і Firefox (через NSS), судячи з помилки яку я отримав, поводяться так само – хоча я не копав, де саме це у них задокументовано.
Окремо є CA/Browser Forum Baseline Requirements, які забороняють публічним CA видавати такі сертифікати в принципі. Мій CA не публічний – але правила браузерів від цього не перестають діяти.
Тому веб-сервіси будуть в зоні .net.setevoy, а wildcard буде для *.net.setevoy.
SSL vs TLS
Їх часто плутають, та я і сам в блозі пишу то “SSL”, то “TLS”, то просто “SSL/TLS”.
це фактично SSL 4.0, просто перейменований коли стандарт передали в IETF, див. History of SSL/TLS
зараз актуальні TLS 1.2 і TLS 1.3
Тобто коли хтось каже “SSL сертифікат” або “налаштувати SSL” – мається на увазі TLS. Це як “ксерокс” замість “копіювальний апарат” – всі розуміють, але технічно неточно. В тексті далі буду казати “SSL/TLS” або просто “SSL” чи “TLS” – це все про одне й те саме.
Що таке Certificate Authority
Certificate Authority – це центр, який має право підписувати сертифікати, і якому довіряють клієнти (браузери, операційні системи).
Коли ми створюємо сертифікат через Let’s Encrypt – він підписується сертифікатом компанії Let’s Encrypt.
Коли через AWS Certificate Manager – то сертифікатом Amazon.
У випадку Cloudflare – issuer буде Google Trust Services:
Наприклад, пакет curl має в залежностях мета-пакет
$ pacman -Qi curl
Name : curl
...
Depends On : ca-certificates
...
Пакет ca-certificates має в залежностях пакет ca-certificates-mozilla:
$ pacman -Qi ca-certificates
Name : ca-certificates
...
Depends On : ca-certificates-mozilla
...
А ca-certificates-mozilla тягне за собою пакет ca-certificates-utils:
$ pacman -Qi ca-certificates-mozilla
Name : ca-certificates-mozilla
...
Depends On : ca-certificates-utils>=20181109-3
...
Пакет ca-certificates-utils створює каталоги (/etc/ca-certificates/, /etc/ssl/certs/), додає man pages та встановлює утиліту /usr/bin/update-ca-trust.
Пакет ca-certificates-mozilla додає в систему файл /usr/share/ca-certificates/trust-source/mozilla.trust.p11-kit, який містить всі публічні CA-сертифікати.
Наприклад, вже згаданий вище “Organization=Google Trust Services” з “CommonName=GTS Root R1“:
$ cat /usr/share/ca-certificates/trust-source/mozilla.trust.p11-kit | grep -A 10 "Google Trust Services"
# Issuer: C=US, O=Google Trust Services LLC, CN=GTS Root R1
# Validity
# Not Before: Jun 22 00:00:00 2016 GMT
# Not After : Jun 22 00:00:00 2036 GMT
# Subject: C=US, O=Google Trust Services LLC, CN=GTS Root R1
# Subject Public Key Info:
# Public Key Algorithm: rsaEncryption
# Public-Key: (4096 bit)
# Modulus:
# 00:b6:11:02:8b:1e:e3:a1:77:9b:3b:dc:bf:94:3e:
# b7:95:a7:40:3c:a1:fd:82:f9:7d:32:06:82:71:f6:
# f6:8c:7f:fb:e8:db:bc:6a:2e:97:97:a3:8c:4b:f9:
# 2b:f6:b1:f9:ce:84:1d:b1:f9:c5:97:de:ef:b9:f2:
# a3:e9:bc:12:89:5e:a7:aa:52:ab:f8:23:27:cb:a4:
# b1:9c:63:db:d7:99:7e:f0:0a:5e:eb:68:a6:f4:c6:
...
А update-ca-trust – це bash-скрипт, який викликає утиліту /usr/bin/trust і витягує сертифікати в каталог DEST=/etc/ca-certificates/extracted/cadir:
Власне, що ми будемо робити: створимо власний root-key нашого Certificate Authority, ним підпишемо TLS-сертифікат для NGINX, а потім сертифікат нашого Certificate Authority додамо в trusted store на робочих машинах.
Файли CA, CSR, CRT, KEY
Тут хочу окремо зупинитись, бо насправді не так часто щось роблю руками з сертифікатами, і від кількості пов’язаних файлів можна потірятись.
Отже, у нас будуть дві пари ключ+сертифікат.
Пара 1 – наш Certificate Authority:
ca-private.key: приватний ключ CA
використовується виключно для підпису інших сертифікатів, зберігається окремо від сертифікатів NGINX
ca-public.crt: публічний сертифікат CA
підписується ca-private.key – власне – тому ця схема і є “self-signed” – ми самі собі підписуємо публічний сертифікат, який потім додаємо в trust store хостів
Пара 2 – для NGINX:
wildcard.net.setevoy.key: приватний ключ NGINX
лежить на сервері і нікому не передається
під час TLS handshake NGINX ним підписує challenge від клієнта, чим доводить що володіє ключем (сам ключ по мережі не йде)
wildcard.net.setevoy.crt: фінальний публічний сертифікат веб-сервера, підписаний нашим CA
це CSR + підпис від ca-private.key
саме цей файл NGINX і віддає браузеру
Окремо будемо створювати файл Certificate Signing Request (CSR) – wildcard.net.setevoy.csr і який буде використовуватися для створення підпису публічного сертифікату wildcard.net.setevoy.crt.
Процес валідації сертифікатів
Тепер розберемо як саме CA використовується для перевірки сертифіката від NGINX.
Тут приклади на вже готових файлах.
У нас буде файл wildcard.net.setevoy.crt, який NGINX передає клієнту під час підключення і який підписаний ca-private.key – приватним ключем CA.
Клієнт має у своєму trust store публічний сертифікат CA – ca-public.crt, використовуючи який він має впевнитись, що wildcard.net.setevoy.crt був підписаний саме ca-private.key.
Файл wildcard.net.setevoy.crt містить в собі набір полів:
# openssl x509 -in wildcard.net.setevoy.crt -noout -text
Certificate:
Data:
...
Signature Algorithm: sha256WithRSAEncryption
Issuer: C = UA, ST = Kyiv, O = Setevoy Home NAS, CN = Setevoy CA
Validity
Not Before: Apr 18 11:35:59 2026 GMT
Not After : Jul 21 11:35:59 2028 GMT
Subject: C = UA, ST = Kyiv, O = Setevoy Home NAS, CN = *.net.setevoy
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:dd:c6:f7:e1:13:1c:dd:91:44:37:d5:75:09:ca:
fb:16:a5:80:22:23:42:6e:6b:7c:1f:08:dd:25:f3:
7f:bd:05:13:74:79:76:de:d7:2b:f8:4c:bd:4c:a5:
...
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
3d:24:95:55:cd:fb:c6:af:35:59:bc:dd:f6:05:fb:da:c9:51:
f1:37:38:79:f0:e8:62:4a:5c:bc:f3:da:4b:45:8c:39:75:f4:
3c:e5:3f:73:89:e6:8a:93:79:52:d7:8e:08:b0:50:02:ce:e9:
18:63:4d:cd:ef:be:fa:78:f2:ed:01:db:77:e8:30:d7:b6:27:
...
Для підписання цього сертифіката CA бере хеш (SHA-256) від усієї секції Data (subject, issuer, public key, validity, SAN, …), шифрує цей хеш своїм приватним ключем ca-private.key і прикріплює результат до сертифіката як поле “Signature Value“.
Коли клієнт отримує wildcard.net.setevoy.crt від NGINX – він перевіряє значення issuer, бачить там “Setevoy CA“, і шукає у своєму trust store сертифікат CA з таким subject – це буде наш ca-public.crt.
Тепер у клієнта є wildcard.net.setevoy.crt з Signature Value, і є ca-public.crt, після чого:
клієнт бере секцію Data з сертифіката і сам обчислює її SHA-256 хеш – назвемо цей хеш “H1“
бере значення Signature Value і розшифровує його публічним ключем CA (який лежить всередині ca-public.crt) – це буде хеш “H2“
Якщо хеши співпадають – то підпис дійсно був зроблений парним приватним ключем до публічного ключа CA, ca-private.key.
“H1” та “H2” тут – чисто умовні позначення, аби простіше було розібратись з тим, що будемо робити нижче.
Demo: перевірка підпису сертифікату
Виглядає класно в теорії – але давайте глянемо на практиці, як цей механізм працює.
Створимо файл data.txt – це буде наш умовний блок Data із сертифікату wildcard.net.setevoy.crt:
$ echo "Hello, this is our Data block" > data.txt
Створимо приватний ключ – це наш умовний ca-private.key, приватний ключ CA:
$ openssl genrsa -out demo.key 2048
З ca-private.key ми будемо підписувати хеш від data.txt.
Отримуємо з demo.key публічну частину – це буде наш умовний ca-public.crt, публічний сертифікат CA:
$ openssl rsa -in demo.key -pubout -out demo.pub
З ca-public.crt ми повинні мати змогу перевірити підпис від ca-private.key та отримати оригінальні дані.
А тепер сама цікава частина.
Отримуємо хеш даних в data.txt – це буде наш умовний “H1“:
Тепер у файлі signature.bin маємо 256 байт – це, власне – той самий “Signature Value” із сертифіката від NGINX, тільки у нас цей Value лежить окремим файлом, а не полем в сертифікаті:
$ od -An -tx1 signature.bin | tr -d ' \n' | head -c 200
203f65033571f3c7...d51b
Далі нам треба розшифрувати цей хеш, використовуючи публічний сертифікат CA:
Бачимо той самий хеш “959AF28AF…850B9B68” – це наш умовний H2, і він точно дорівнює H1, який ми отримали кілька кроків тому.
Підпис валідний – значить його зробив той, хто має приватний ключ, парний до demo.pub.
Те ж саме клієнт робить кожного разу при підключенні до NGINX – тільки замість demo.pub використовує публічний ключ з ca-public.crt у своєму trust store.
Все – досить теорії.
Давайте тепер створювати ключі і сертифікати.
План дій – Certificate Authority та NGINX
Нам треба буде створити файли нашого CA, а потім – файли для NGINX:
створимо приватний ключ, ним підпишемо сертифікат для CA – отримаємо self-signed Public CA certificate
створимо приватний ключ для NGINX – він буде використовуватись під час TLS Handshake для встановлення безпечного з’єднання
створимо CSR з потрібними CN та SAN – доменами, для яких буде валідним публічний сертифікат NGINX
з цим CSR та нашим приватним ключем CA отримаємо сертифікат для NGINX
налаштуємо virtualhost в NGINX з приватним ключем та сертифікатом
додамо публічний сертифікат CA в trusted store на FreeBSD і Linux
Створення власного Certificate Authority
На FreeBSD (в моєму випадку, але процес ідентичний на будь-якому Linux) створюємо каталог:
# mkdir -p /usr/local/etc/ssl/setevoy/NasCA/
# cd /usr/local/etc/ssl/setevoy/NasCA/
Генеруємо приватний ключ CA на 4096 біт:
# openssl genrsa -out ca-private.key 4096
З цим ключем генеруємо публічний self-signed сертифікат нашого CA:
-new -x509: генеруємо новий self-signed сертифікат (а не CSR)
-days 3650: сертифікат валідний 10 років (для root CA норм)
-key ca-private.key: підписуємо приватним ключем CA, який створили вище
-out ca-public.crt: куди зберегти публічний сертифікат
-subj: метадані сертифіката – поле CN потім будемо бачити в браузері
Перевіряємо:
# openssl x509 -in ca-public.crt -noout -issuer -subject
issuer=C = UA, ST = Kyiv, O = Setevoy Home NAS, CN = Setevoy CA
subject=C = UA, ST = Kyiv, O = Setevoy Home NAS, CN = Setevoy CA
Власне, issuer і subject однакові: це і є self-signed сертифікат – бо виданий від “Setevoy CA” для “Setevoy CA“.
Сертифікат для *.net.setevoy
В NGINX можна було б використати ключ ca-private.key напряму – але це наш “рутовий” ключ, і якщо NGINX зламають – атакуючий зможе підписувати ним будь-що, тому для NGINX робимо окремий ключ.
Створюємо приватний ключ для NGINX – тут вже можна зробити 2048 біт, а не 4096, як для рутового ключа CA:
req -new: генеруємо новий CSR (без -x509, бо це не сертифікат)
-key wildcard.net.setevoy.key: використовуємо приватний ключ, який створили вище – його публічна частина піде в CSR
-out wildcard.net.setevoy.csr: куди зберегти сам Certificate Signing Request
CN=*.net.setevoy: wildcard, покриває всі сабдомени *.net.setevoy (хоча CN ролі не грає, див. далі)
Перевіряємо що в CSR:
# openssl req -in wildcard.net.setevoy.csr -noout -subject
subject=C = UA, ST = Kyiv, O = Setevoy Home NAS, CN = *.net.setevoy
Common Name та Subject Alternative Name
Тут є нюанс, на якому я сам спіткнувся: сучасні браузери і клієнти ігнорують Common Name (CN) і дивляться тільки на поле Subject Alternative Name (SAN), тому значення в полі CN недостатньо – треба додати SAN з усіма іменами, які покриває сертифікат.
Історія цього питання довга. RFC 2818 задепрікейтив CN на користь SAN ще у 2000, але залишив fallback:
If a subjectAltName extension of type dNSName is present, that MUST be used as the identity. Otherwise, the (most specific) Common Name field in the Subject field of the certificate MUST be used. Although the use of the Common Name is existing practice, it is deprecated and Certification Authorities are encouraged to use the dNSName instead.
The Common Name RDN MUST NOT be used to identify a service because it is not strongly typed (it is essentially free-form text) and therefore suffers from ambiguities in interpretation.
Тобто сертифікат без SAN сьогодні – це гарантована помилка валідації, незалежно від того що в CN.
Окремий момент: wildcard *.net.setevoy покриває рівно один рівень піддомену, тобто test-ssl.net.setevoy – так, але саме net.setevoy (без префіксу) – ні. Тому в SAN додаємо обидва записи.
-extfile san.cnf -extensions v3_req: додаємо список SAN з конфіга (без цього SAN не запишеться в сертифікат, навіть якщо він був у CSR)
Сама послідовність створення сертифікату із CSR така:
на вході у нас CSR (wildcard.net.setevoy.csr) – заявка з полями subject, public key, SAN
OpenSSL бере дані з CSR (subject, public key), додає від себе кілька полів (issuer = Setevoy CA, validity, serial number, extensions з san.cnf), збирає це все в нову структуру Data
хешує цю структуру Data, шифрує хеш приватним ключем CA – отримує Signature Value
на виході збирає Data + Signature Value в один файл – це і є wildcard.net.setevoy.crt
Перевіряємо що у нас в новому сертифікаті:
# openssl x509 -in wildcard.net.setevoy.crt -noout -issuer -subject -dates
issuer=C = UA, ST = Kyiv, O = Setevoy Home NAS, CN = Setevoy CA
subject=C = UA, ST = Kyiv, O = Setevoy Home NAS, CN = *.net.setevoy
notBefore=Apr 18 11:35:59 2026 GMT
notAfter=Jul 21 11:35:59 2028 GMT
Тепер issuer – це Setevoy CA, а subject – наш wildcard. Це означає, що сертифікат підписаний саме нашим CA, а не сам собою.
І сам віртуалхост, наприклад /usr/local/etc/nginx/conf.d/test-ssl.net.setevoy.conf:
server {
listen 80;
server_name test-ssl.net.setevoy;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
server_name test-ssl.net.setevoy;
include /usr/local/etc/nginx/conf.d/ssl.conf;
location / {
root /usr/local/www/nginx;
index index.html;
}
}
Хоча include /usr/local/etc/nginx/conf.d/ssl.conf можна взагалі винести в nginx.conf в секцію http{}.
Перевіряємо конфіг і ребутаємо:
# nginx -t && service nginx reload
nginx: the configuration file /usr/local/etc/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/etc/nginx/nginx.conf test is successful
Спробуємо curl:
# curl https://test-ssl.net.setevoy
curl: (60) SSL certificate OpenSSL verify result: unable to get local issuer certificate (20)
More details here: https://curl.se/docs/sslcerts.html
curl failed to verify the legitimacy of the server and therefore could not
establish a secure connection to it. To learn more about this situation and
how to fix it, please visit the webpage mentioned above.
Це очікувано: curl не знає нашого CA, бо ми його ще нікуди не додали.
Додавання CA в локальні trusted store
Аби перевірка проходила без помилок – треба публічний сертифікат CA додати на всі хости в їхні trust store.
Якщо з --cacert працює, а без нього – ні, значить CA не доїхав до системного trust store – перевіряємо update-ca-trust / certctl rehash.
Перевірити повний chain:
$ openssl s_client -connect test-ssl.net.setevoy:443 -showcerts
Connecting to 192.168.0.2
CONNECTED(00000003)
depth=0 C=UA, ST=Kyiv, O=Setevoy Home NAS, CN=*.net.setevoy
verify error:num=20:unable to get local issuer certificate
verify return:1
depth=0 C=UA, ST=Kyiv, O=Setevoy Home NAS, CN=*.net.setevoy
verify error:num=21:unable to verify the first certificate
verify return:1
depth=0 C=UA, ST=Kyiv, O=Setevoy Home NAS, CN=*.net.setevoy
verify return:1
---
Certificate chain
0 s:C=UA, ST=Kyiv, O=Setevoy Home NAS, CN=*.net.setevoy
i:C=UA, ST=Kyiv, O=Setevoy Home NAS, CN=Setevoy CA
a:PKEY: RSA, 2048 (bit); sigalg: sha256WithRSAEncryption
v:NotBefore: Apr 18 11:35:59 2026 GMT; NotAfter: Jul 21 11:35:59 2028 GMT
...
Браузери та сертифікати CA
Окремий момент щодо браузерів: Firefox має власний trust store і не дивиться в системний тому для Firefox власний сертифікат CA треба додавати окремо через about:preferences#privacy > “View Certificates”:
Далі Import:
І тепер працює без помилок:
Google Chrome, Brave, Vivaldi і решта на Linux зазвичай використовують системний trust store, але можна імпортувати вручну на сторінці chrome://certificate-manager/localcerts:
В попередній частині серії по налаштуванню Okta зробили SSO для Grafana (див. Okta: налаштування Grafana SSO з OIDC та Role mapping) – тепер більш цікава задача: треба налаштувати SSO для AWS, і мати не тільки log in – а і users provisioning.
З приводу Terraform: свідомо роблю без нього, бо зараз ми використовуємо Okta акаунт разом з іншим проектом і потім будемо відокремлюватись і перероблювати сетап. Ну і, крім того – я не займався налаштуваннями Okta з ~2020 року, тому перший час краще “поклікопсити”, аби краще розібратись з тими змінами, які за цей час сталися.
Аналогічно з Terraform для AWS – якщо всякі VPC/EKS у нас вже зроблені з Terraform, то налаштування, які відносяться до account management поки роблю руками, бо 100% ми будемо або переїжджати в новий акаунт, або будемо розділяти поточний, і поки невідомо як це все буде виглядати.
Але коли переїдемо – то 100% будуть пости по Terraform з Okta та AWS.
AWS та сервіси для User Management
Перш ніж почати налаштування Okta – давайте коротко про те, що взагалі в AWS є з сервісів, які мають відношення до управлінню юзерами і доступами:
AWS IAM: базовий сервіс – юзери, групи, ролі, політики
AWS IAM Identity Center (колишній AWS Single Sign-On): те, що ми будемо використовувати для Okta – централізоване управління доступом до різних AWS Accounts, інтеграція з Identity Providers (IdP – Okta, Azure Active Directory, etc)
AWS Organizations: централізоване управління різними AWS Accounts – Service Control Policies (SCP), спільні CloudTrail, Config, GuardDuty, централізований білінг
AWS Control Tower: автоматичне налаштування AWS Organizations, IAM Identity Center, загальний compliance, security
Варіанти AWS SSO та Okta
Є два підходи до інтеграції Okta з AWS:
AWS Account Federation (legacy):
прямий SAML між Okta і кожним AWS акаунтом окремо через IAM Identity Providers – для кожного акаунту треба окремо створювати IAM Roles з Trust Policy на Okta, окремо налаштовувати SAML
при наявності 10 акаунтів – 10 раз повторювати одне і те саме налаштування
SCIM (provisioning) з Okta не підтримується – тобто юзери і групи не синхронізуються автоматично
IAM Identity Center:
централізований підхід – Okta підключається один раз через SAML, юзери і групи синхронізуються автоматично за SCIM протоколом
Permission Sets (aka IAM Policies для юзерів і груп) – права визначаються один раз і призначаються на будь-яку кількість акаунтів
при додаванні нового акаунту в AWS Organization – просто вибираємо існуючі групи та Permission Sets, без додаткового налаштування SAML
Ми будемо робити модно-маладьожно, з IAM Identity Center:
Okta: буде нашим Idetity Provider – юзери створюються там, логін тільки через Okta
IAM Identity Center: буде отримувати аутентифікованих юзерів від Okta та виконувати авторизацію з Permission Sets
AWS Organizations дає нам централізоване управління кількома AWS акаунтами – об’єднує акаунти в ієрархію (Organizational Unit, OU – повіяло ностальгією за OpenLDAP) з єдиним білінгом, є основою для multi-account management і обов’язковою умовою для повноцінного IAM Identity Center з multi-account SSO.
Що дає AWS Organizations
Billing: єдиний consolidated billing на всі акаунти. До того ж всякі Reserved Instances і Savings Plans можна використовувати між всіма акаунтами організації..
Security / Governance
Єдина точка менеджменту різними security services:
SCPs (Service Control Policies): політики обмежень на рівні акаунту або OU, які діють поверх будь-яких IAM прав і які не можна обійти навіть з AdministratorAccess, наприклад – “ніхто не може вимкнути CloudTrail” або “дозволити створення нових ресурсів тільки в заданих AWS Regions“
AWS Config aggregator: збирає дані про конфігурацію ресурсів з усіх акаунтів в одне місце – можна бачити чи всі ресурси відповідають заданим правилам, наприклад – “всі S3 buckets мають бути зашифровані” або “всі EC2 інстанси мають мати певні теги“
CloudTrail organization trail: єдиний CloudTrail для усіх акаунтів, не треба в кожному налаштовувати окремо
GuardDuty, Security Hub, Macie: централізоване управління всіма security services
Networking: RAM (Resource Access Manager): дозволяє використовувати спільні ресурси між акаунтами без необхідності налаштовувати це між кожною парою акаунтів.
Account isolation (головна причина multi-account):
можна (і треба) мати Production акаунт повністю ізольованим від Dev – випадковий terraform destroy в Dev не торкнеться Prod
ще рекомендується мати і окремий акаунт з обмеженим доступом для security services
обмежуємо blast radius одним акаунтом: якщо пушнули ACCESS/SECRET ключі в GitHub – то “під роздачу” попаде тільки один акаунт
хоча краще ключі не використовувати взагалі
Що відбувається при створенні Organizations
Нічого не ламається: всі існуючі IAM Users, IAM Roles, IAM Policies, всі сервіси (EKS, RDS, S3) продовжують працювати. Поточний акаунт стає management account, з’являється root OU.
Єдиний момент, який треба мати на увазі, це сам management account – його потім змінити не можна. Тому перевіряємо, що створюємо Organization з правильного акаунту – там де billing і root доступ.
Створення AWS Organization
Переходимо в AWS Organization, клікаємо Create an organization:
AWS рекомендує створювати Organization з окремого акаунту – але нам, як маленькому стартапу, підійде і поточний, в якому маємо всі наші сервіси:
Після створення Organization, AWS пропонує включити Centralize root access for member accounts – відключити root accounts, і всі адміністративні дії виконувати тільки з management account.
Нам це поки не актуально, бо взагалі маємо тільки один акаунт, але взагалі з точки зору безпеки штука корисна:
Поїхали до самого цікавого.
Створення Okta App – AWS IAM Identity Center
Спершу додамо Okta App – IAM Identity Center, бо в самому AWS IAM Identity Center потрібні будуть параметри SAML від Okta:
Отримуємо лінк на SAML metadata:
У нас в Okta кастомний домен, в браузері свариться на сертифікат, а через HSTS нема можливості цю помилку ігнорувати:
Що нам дасть IAM Identity Center, і що будемо налаштовувати:
AWS Access Portal: буде єдина сторінка входу в усі акаунти організації
Identity Source: налаштуємо source of truth для юзерів, в нашому випадку буде External Ientity Provider – Okta
Account Assignments: прив’язка User Groups в IAM Identity Center, які далі синхронізуємо з Okta – до Permission Set для конкретного AWS акаунту, тобто – “Okta Group з іменем org-DevOps має AdministratorAccess в акаунті <accountName>“
Permission Sets: набір IAM policies, який IAM Identity Center автоматично створює як IAM Role (з іменем, яке починається з AWSReservedSSO_) в цільовому AWS акаунті при підключенні User Group до Permission Sets, і далі, при логіні в акаунт – юзер використовує цю роль
AWS Organizations is recommended, but not required, for use with IAM Identity Center. If you haven’t set up an organization, you do not have to. If you’ve already set up AWS Organizations and are going to add IAM Identity Center to your organization, make sure that all AWS Organizations features are enabled. For more information, see IAM Identity Center and AWS Organizations.
Поїхали – переходимо в IAM Identity Center, клікаємо Enable:
Якщо AWS Organization ще нема – AWS пропонує її створити, якщо не хочемо мати Organization – можна включити IAM Identity Center в режимі account instance:
Переходимо в Settings > Identity Source, в Actions вибираємо Change Identity Source:
Вибираємо External type:
Отримуємо URLs, зберігаємо собі:
IAM Identity Center Assertion Consumer Service (ACS) URL
IAM Identity Center issuer URL
В Identity Provider Metadata завантажуємо файл metadata.xml, який скачали з Okta App:
При зміні IAM Identity Center виводить попередження про зміни для юзерів – але це відноситься тільки для юзерів самого IAM Identity Center, яких в нашому випадку ще нема – логін для звичайних IAM Users буде працювати, як і раніше:
Налаштування SAML в Okta AWS IAM Identity Center App
Пишемо ACCEPT, клікаємо Change – отримуємо налаштування для SAML в Okta App:
Повертаємось до Okta App, переключаємось на Sign On, клікаємо Edit та задаємо адреси:
AWS SSO ACS URL: це IAM Identity Center Assertion Consumer Service (ACS) URL із AWS IAM Identity Center
AWS SSO issuer URL: це IAM Identity Center issuer URL із AWS IAM Identity Center
Власне, на цьому з аутентифікацією все.
Але залогінитись юзери ще не можуть – трохи далі налаштуємо це.
Поки зробимо Users та Groups provisiong – синхронізацію груп та юзерів із Okta до AWS IAM Identity Center.
Налаштування Provisioning з Okta до IAM Identity Center
Повертаємось до IAM Identity Center > Settings, клікаємо Enable в Automatic Provisioning:
Отримуємо URL та Access Token.
Токен відразу зберігаємо – бо більше його не побачимо:
Повертаємось до Okta > Provisioning > Configure API Integration:
Групи із IAM Identity Center в Okta нам не потрібні – ми будемо робити тільки з Okta до IAM Identity Center, тому знімаємо галочку, погоджуємось з попередженням:
Задаємо URL, токен, клікаємо Test API Credentials:
“Єсть контакт!”:
Зберігаємо, клікаємо Edit, включаємо синхронізацію юзерів, їхнії атрибутів та деактивацію юзерів (виключили акаунт в Okta – виключили в AWS):
Тепер у нас під назвою App все зелене – маємо всі інтеграції:
Assigning Okta Users та Okta Groups до Okta IAM Identity Center App
Переходимо в Assign, додаємо цю App до Okta Group:
Залишаємо всі дефолтні атрибути:
І вже маємо юзерів в IAM Identity Center:
Але не групи – тут поки пусто:
Створення Permission Set для IAM Identity Center User Groups
Permission Sets визначає те, які права доступу будуть у юзера чи групи в AWS Account, тобто:
в Okta маємо Okta Group (org-DevOps)
Okta виконує group push в IAM Identity Center (про це далі)
в IAM Identity Center отримуємо нову групу org-DevOps
цю групу додаємо до AWS Account
в AWS Account створиться IAM Role з іменем AWSReservedSSO_<Permission_Set_name>
при логіні в акаунт – юзер виконує Assume Role цієї ролі
Створюємо новий Permission Set:
В Custom Permission Set можна вибрати власні політики, описати inline policy, або використати вже готові набори.
Для девопсів робимо AdministartorAccess:
Session duration можна поставити побільше:
Зберігаємо новий Permission Set, але Provisioned status поки Not provisioned – бо цей Permission Set ще нікому підключений:
Синхронізація Okta Groups з Okta Push Groups
Для синхронізації Okta Groups до AWS IAM Identity Center – переходимо в Push Groups, вибираємо групу – при чому необов’язково, щоб вона була Assigned до цієї App:
Вибираємо Okta Group:
Група готова до push в IAM Identity Center, і маємо дві опції – Create Group, якщо такої групи в AWS ще нема, або Link Group – зв’язати групу в Okta з вже існуючою групою в AWS:
Клікаємо Save, починається процес синхронізації:
Готово:
Перевіряємо групи в IAM Identity Center – є нова група з двома юзерами:
Потім в Okta можна відключити синхронізацію:
Підключення IAM Identity Center User Groups до AWS Accounts
Аби юзери цієї групи могли логінитись в AWS Account – виконуємо Assign вже в самому IAM Identity Center:
Вибираємо групу:
Вибираємо створений раніше Permission Set:
В списку AWS Accounts тепер маємо підключений Permission Set:
І в самому AWS Account в IAM Roles маємо нову роль:
Final: логін з SSO через AWS Access Portal
Знаходимо URL нашого AWS Access Portal – це буде єдина точка входу всіх юзерів:
Або клікаємо на App в Okta.
Попадаємо на сторінку вибору акаунтів, відразу бачимо Permission Set з яким можемо залогінитись:
Логінимось, і маємо доступ до всіх наших сервісів:
Власне – на цьому і все.
SSO та user provisioning налаштований, логін працює.
Для AWS Access Portal можемо налаштувати власний URL – але тільки в зоні awsapps.com – клікаємо Edit:
Задаємо власне ім’я:
І далі ходимо через https://example.awsapps.com/start.
Налаштування AWS CLI з SSO
Всі старі доступи з ACCESS/SECRET ключами ще працюють, але відразу налаштовуємо собі новий логін з SSO.
Виконуємо aws configure sso, з --profile вказуємо для якого саме акаунту буде логін з SSO:
$ aws configure sso --profile work
SSO session name (Recommended): org-sso
SSO start URL [None]: https://example.awsapps.com/start
SSO region [None]: us-east-1
SSO registration scopes [sso:account:access]:
Attempting to automatically open the SSO authorization page in your default browser.
...
Відкриється браузер, дозволяємо доступ:
І терміналі бачимо повідомлення, що SSO для профайлу work налаштований:
...
The only AWS account available to you is: 492***148
Using the account ID 492***148
The only role available to you is: DevOps-AdministratorAccess
Using the role name "DevOps-AdministratorAccess"
Default client Region [us-east-1]:
CLI default output format (json if not specified) [None]:
To use this profile, specify the profile name using --profile, as shown:
aws sts get-caller-identity --profile work
Перевіряємо як ми залогінені – маємо наш власний UserId, який має assumed-role/AWSReservedSSO_DevOps-AdministratorAccess:
На моєму хості з FreeBSD (вже є) запущений мій особистий щоденник, який, як і RTFM, працює на WordPress.
Отже, для нього треба підняти стандартний стек FEMP – FreeBSD + NGINX + PHP-FPM + MariaDB, а заодно налаштувати virtualhosts для сервісів типу Grafana, VictoriMetrics VM UI, Syncthing WebUI, Jellyfin тощо.
Робити будемо базовий сетап, без FreeBSD Jails – бо це чисто домашні внутрішні сервіси, але колись, у 2011-2013 роках, блог RTFM працював саме на такому сетапі, хіба що тоді ще була MySQL, а не MariaDB.
На цьому хості зараз FreeBSD v14.3, але принципової різниці з 15 нема.
Налаштування SSL буде окремим постом, із self-signed sertificate – тут всі віртуалхости на стандартному HTTP і порту 80.
root@setevoy-nas:~ # nginx -t && service nginx reload
І відкриваємо в браузері http://grafana.setevoy:
Створення NGINX virtualhost для VictoriaMetrics та редіректи
На відміну від Grafana, для доступу до VM UI у VictoriaMetrics нам треба URI /vmui/ – тому відразу налаштуємо редірект: якщо на NGINX приходить запит на victoria.setevoy – то відправляємо на victoria.setevoy/vmui/:
root@setevoy-nas:~ # sysrc mysql_enable="YES"
root@setevoy-nas:~ # service mysql-server start
Запускаємо скрипт mariadb-secure-installation для дефолтних налаштувань:
root@setevoy-nas:~ # mariadb-secure-installation
Проходимось по основним параметрам, тут можна всюди відповідати просто “yes” – хіба що задати пароль root:
root@setevoy-nas:~ # mariadb-secure-installation
/usr/local/bin/mysql_secure_installation: Deprecated program name. It will be removed in a future release, use 'mariadb-secure-installation' instead
...
Switch to unix_socket authentication [Y/n]
Enabled successfully!
Reloading privilege tables..
... Success!
...
Change the root password? [Y/n]
New password:
Re-enter new password:
Password updated successfully!
Reloading privilege tables..
... Success!
...
Remove anonymous users? [Y/n]
... Success!
...
Disallow root login remotely? [Y/n]
... Success!
...
Remove test database and access to it? [Y/n]
- Dropping test database...
... Success!
- Removing privileges on test database...
... Success!
...
Reload privilege tables now? [Y/n]
... Success!
Cleaning up...
All done! If you've completed all of the above steps, your MariaDB
installation should now be secure.
Thanks for using MariaDB!
Створення MariaDB database та user
Підключаємось до сервера:
root@setevoy-nas:~ # mysql -u root -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 13
Server version: 11.4.9-MariaDB FreeBSD Ports
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
root@localhost [(none)]>
Створюємо базу, юзера з паролем, даємо юзеру доступ до цієї бази:
root@localhost [(none)]> CREATE DATABASE blog_test CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Query OK, 1 row affected (0.003 sec)
root@localhost [(none)]> CREATE USER 'blog-test'@'localhost' IDENTIFIED BY 'localpass';
Query OK, 0 rows affected (0.001 sec)
root@localhost [(none)]> GRANT ALL PRIVILEGES ON blog_test.* TO 'blog-test'@'localhost';
Query OK, 0 rows affected (0.001 sec)
root@localhost [(none)]> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.001 sec)
Виходимо, пробуємо підключитись з цим юзером:
root@setevoy-nas:~ # mysql -u blog-test -p blog_test
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 14
Server version: 11.4.9-MariaDB FreeBSD Ports
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
blog-test@localhost [blog_test]>
Установка WordPress
Завантажуємо архів з останнім релізом, розпаковуємо, переносимо файли в каталог /usr/local/www/blog.setevoy/:
Міграція RTFM з DigitalOcean до AWS пройшла без проблем, і потроху “обживаюсь на новому місці”.
Інфраструктура нова, все нове – а тому перший час хочеться уважно постежити за станом серверів та блогу, а тому треба налаштувати базовий моніторинг для WordPress: NGINX, PHP-FPM, базу даних та інфраструктуру, на якій все це крутиться.
Сам стек моніторингу вже розгорнутий на домашньому NAS з FreeBSD – є VictoriaMetrics, VictoriaLogs, Grafana, vmalert та Alertmanager з відправкою алертів в Telegram та ntfy.sh.
По цьому стеку писав в серії постів по FreeBSD та домашньому NAS:
AWS ALB: картина того, що відбувається на Load Balancer
AWS EC2: різні метрики по стану самих інстансів
NGINX: метрики веб-сервера
PHP-FPM: метрики воркерів FPM
Крім того, треба збирати системні логи операційної системи та логи NGINX і PHP.
Логи RDS теж можуть бути корисними – але це вже на випадок реальних проблем, а тоді вже можна просто подивитись в CloudWatch Logs.
Для збору метрик на EC2 використав:
node_exporter: базові метрики EC2 – CPU, RAM, диск, мережа
nginx_exporter: простенький, метрик мало, але нехай буде (окремо зробимо метрики з логів NGINX)
php_fpm_exporter: метрики PHP-FPM – процеси, використання воркерів, slow requests
yace_exporter: збирає з CloudWatch дефолтні метрики по стану ALB та RDS
Для логів поки взяв Fluent Bit, який писатиме до VictoriaLogs. Взагалі, пізніше для збору логів спробую vlagent, зараз робив “швиденько” – тому взяв те, що в мене вже працює на FreeBSD/NAS.
Щоб node_exporter бачив всі мережеві інтерфейси – задаємо network_mode: host, щоб всі PID – задаємо pid: host.
З точки зору security це не ідеально, бо контейнер з network_mode: host дає повний доступ до мережі хоста, а pid: host дає йому видимість всіх процесів. Але для моніторингу особистого блогу – нормально.
Запускаємо:
[root@ip-10-0-3-146 ~]# cd /opt/monitoring && docker compose up -d
Перевіряємо метрики:
[root@ip-10-0-3-146 ~]# curl -s http://localhost:9100/metrics | grep node_exporter_build
# HELP node_exporter_build_info A metric with a constant '1' value labeled by version, revision, branch, goversion from which node_exporter was built, and the goos and goarch for the build.
# TYPE node_exporter_build_info gauge
node_exporter_build_info{branch="HEAD",goarch="amd64",goos="linux",goversion="go1.25.3",revision="654f19dee6a0c41de78a8d6d870e8c742cdb43b9",tags="unknown",version="1.10.2"} 1
Налаштування vmagent на FreeBSD
Додаємо збір метрик до VictoriaMetrics. На FreeBSD для vmagent використовується конфіг /usr/local/etc/prometheus/prometheus.yml – додаємо туди новий таргет.
В мене в job_name: "node_exporter" вже є один таргет – 127.0.0.1:9100 для метрик самої FreeBSD – туди ж вписуємо 10.100.0.20:9100, де 10.100.0.20 – це адреса EC2 в мережі WireGuard (хоча потім створю Static DNS record на MikroTik):
Перезапускаємо vmagent та перевіряємо метрики в VictoriaMetrics:
Моніторинг AWS з YACE Exporter
Для AWS-метрик будемо використовувати yet-another-cloudwatch-exporter (YACE) – він забирає метрики з CloudWatch і віддає їх у форматі Prometheus. Трохи детальніше про нього писав у Prometheus: yet-another-cloudwatch-exporter – сбор метрик AWS CloudWatch, досі використовую на робочих проектах.
До цієї ролі треба додати IAM Policy для YACE, яка надасть доступу до CloudWatch та iam:ListAccountAliases – щоб відображати ім’я акаунта замість числового ID в метриках:
Створюємо конфіг /opt/monitoring/yace-config.yml. В exportedTagsOnMetrics вказуємо, які AWS-теги додавати до метрик – потім в Grafana і алертах можна буде виводити ім’я, а не ARN.
За збір метрик з CloudWatch платимо гроші, тому тут беремо тільки те, що дійсно корисне:
[root@ip-10-0-3-146 ~]# curl -s http://127.0.0.1:5000/metrics | grep aws_
# HELP aws_applicationelb_active_connection_count_sum Help is not implemented yet.
# TYPE aws_applicationelb_active_connection_count_sum gauge
aws_applicationelb_active_connection_count_sum{account_id="264***286",dimension_AvailabilityZone="",dimension_LoadBalancer="app/rtfm-alb/cd76dd0d557838f8",name="arn:aws:elasticloadbalancing:eu-west-1:264***286:loadbalancer/app/rtfm-alb/cd76dd0d557838f8",region="eu-west-1",tag_Name="rtfm-alb-main"} 336
...
Тепер логи. Основні логи – це NGINX та PHP errors. Їх будемо відправляти до VictoriaLogs на FreeBSD хості через http output – див. документацію VictoriaLogs по Fluentbit Setup.
Real IP в NGINX
Трафік до EC2 іде через Cloudflare та ALB, тому якщо нічого не налаштовувати – в логах NGINX замість реального IP клієнта буде адреса ALB. Cloudflare передає реальний IP у заголовку CF-Connecting-IP, а для NGINX є модуль ngx_http_realip_module, якому можна вказати з якого заголовка брати IP клієнта.
Додаємо до nginx.conf (не конфіг віртуалхоста, а конфіг самого NGINX), в секцію http {}:
http {
# trust ALB (all traffic comes from within VPC)
set_real_ip_from 10.0.0.0/16;
# get real client IP from Cloudflare header
real_ip_header CF-Connecting-IP;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
...
Перезавантажуємо NGINX та перевіряємо, що в логах з’явились реальні IP:
Конфігурація Fluent Bit – парсери для NGINX та PHP
Основний конфіг /etc/fluent-bit/fluent-bit.conf в мене виглядає так:
[SERVICE]
Flush 5
Daemon Off
Log_Level info
Parsers_File /etc/fluent-bit/parsers-custom.conf
[INPUT]
Name tail
Path /var/log/nginx/rtfm.co.ua-access.log
Tag nginx.access
DB /var/lib/fluent-bit/nginx-access.db
Parser nginx_access
[INPUT]
Name tail
Path /var/log/nginx/rtfm.co.ua-error.log
Tag nginx.error
DB /var/lib/fluent-bit/nginx-error.db
[INPUT]
Name tail
Path /var/log/php/rtfm.co.ua/rtfm.co.ua-error.log
Tag php.error
DB /var/lib/fluent-bit/php-error.db
[FILTER]
Name record_modifier
Match nginx.access
Record host aws-rtfm-main
Record job nginx
Record log_type access
Record site rtfm.co.ua
[FILTER]
Name record_modifier
Match nginx.error
Record host aws-rtfm-main
Record job nginx
Record log_type error
Record site rtfm.co.ua
[FILTER]
Name record_modifier
Match php.error
Record host aws-rtfm-main
Record job php-fpm
Record log_type error
Record site rtfm.co.ua
[FILTER]
Name lua
Match nginx.access
script /etc/fluent-bit/make_msg.lua
call make_msg
[Output]
Name http
Match *
host nas.setevoy
port 9428
uri /insert/jsonline?_stream_fields=stream,job,host,log_type,site&_msg_field=log&_time_field=date
format json_lines
json_date_format iso8601
compress gzip
Тут:
[SERVICE]: глобальні параметри Fleunt Bit
[INPUT]: читаємо три файли, кожному задаємо власний tag, аби далі мати окремі фільтри
[FILTER]: тут з record_modifier по тегу з [INPUT] фільтруємо який саме лог модифікувати і додаємо нові поля, які потім можна використовувати в VictoriaLogs та алертах; у Fluent Bit на FreeBSD, де є власний NGINX і FPM має такі самі налаштування, тільки, звісно, інші значення полів
останній [FILTER] викликає Lua-скрипт для створення поля logs, див. нижче
В дефолтному конфігу Fluent Bit не було парсера для nginx_access – тому створив власний і підключив в [SERVICE] через файл /etc/fluent-bit/parsers-custom.conf:
[PARSER]
Name nginx_access
Format regex
Regex ^(?<remote_addr>[^ ]*) - (?<remote_user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>[^ ]*) (?<path>[^ ]*) (?<protocol>[^ ]*)" (?<status>[^ ]*) (?<bytes>[^ ]*) "(?<referer>[^"]*)" "(?<agent>[^"]*)"
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
Але тут випилюється поле _msg, яке VictoriaLogs очікує і без якого не дуже зручно дивитись в VMUI.
Пробував зробити з record_modifier, але врешті-решт просто навайбокодив скрипт на Lua, який створює поле log, яке потім передається до VictoriaLogs в &_msg_field=log:
function make_msg(tag, timestamp, record)
record["log"] = record["remote_addr"] .. ' "' .. record["method"] .. ' ' .. record["path"] .. '" ' .. record["status"] .. ' "' .. (record["agent"] or "-") .. '"'
return 1, timestamp, record
end
Приклад того, що написав собі – спочатку задані recording rules з exclude домашніх/робочих IP та адреси самого EC2, потім самі алерти:
groups:
- name: aws-rtfm-nginx-access-metrics
type: vlogs
interval: 1m
rules:
- record: aws:rtfm:nginx:requests_total:rate
expr: |
{job="nginx", log_type="access"}
| not (remote_addr:~"108.***.***.54|178.***.***.184")
| stats rate() as requests_rate
- record: aws:rtfm:nginx:requests_by_status:count
expr: |
{job="nginx", log_type="access"}
| not (remote_addr:~"108.***.***.54|178.***.***.184")
| stats by (status) count() as requests_count
- record: aws:rtfm:nginx:requests_by_status:rate
expr: |
{job="nginx", log_type="access"}
| not (remote_addr:~"108.***.***.54|178.***.***.184")
| stats by (status) rate() as requests_rate
- name: aws-rtfm-nginx-access-alerts
rules:
- alert: "NGINX: Too Many 5xx"
expr: aws:rtfm:nginx:requests_by_status:count{status=~"5.."} > 1
for: 1m
labels:
severity: warning
annotations:
summary: Server-side errors on rtfm.co.ua, users may be affected
description: |-
Domain: rtfm.co.ua
HTTP status: {{ $labels.status }}
Count: {{ $value }} req/min
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- alert: "NGINX: High Request Rate"
expr: aws:rtfm:nginx:requests_total:rate > 10
for: 2m
labels:
severity: warning
annotations:
summary: Unusual traffic spike on rtfm.co.ua
description: |-
Domain: rtfm.co.ua
Rate: {{ $value }} req/sec
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- name: aws-rtfm-php-error-metrics
type: vlogs
interval: 1m
rules:
- record: aws:rtfm:php:errors_total:count
expr: |
{job="php-fpm", log_type="error"}
| stats count() as errors_count
- name: aws-rtfm-php-error-alerts
rules:
- alert: "PHP-FPM: Too Many Errors"
expr: aws:rtfm:php:errors_total:count > 5
for: 2m
labels:
severity: warning
annotations:
summary: Application errors on rtfm.co.ua
description: |-
Domain: rtfm.co.ua
Count: {{ $value }} errors/min
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- name: aws-rtfm-php-fpm-alerts
rules:
- alert: "PHP-FPM: Slow Requests Detected"
expr: increase(phpfpm_slow_requests{pool="rtfm.co.ua"}[5m]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: PHP-FPM slow requests on rtfm.co.ua
description: |-
PHP-FPM slow requests detected during last {{ $for }}
Domain: rtfm.co.ua
Slow requests (last 5m): {{ $value }}
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
- alert: "PHP-FPM: Pool Usage High"
expr: phpfpm_active_processes{pool="rtfm.co.ua"} / phpfpm_total_processes{pool="rtfm.co.ua"} * 100 > 80
for: 5m
labels:
severity: warning
annotations:
summary: FPM Pool usage high on rtfm.co.ua
description: |-
FPM Pool usage over 95% during last {{ $for }}
Domain: rtfm.co.ua
Pool used: {{ printf "%.2f" $value }}%
Grafana: https://grafana.setevoy/d/MsjffzSZz/nginx-exporter
Рестаримо vmalert, перевіряємо в UI:
Alertmanager та алерти в Telegram і ntfy.sh
Про те, як створити Telegram-бота і налаштувати групу для алертів писав в пості EcoFlow: моніторинг з Prometheus та Grafana, тому тут опишу тільки конфіг Alertmanager – на FreeBSD це файл /usr/local/etc/alertmanager/alertmanager.yml.
В мене три роути і три ресівери – critical алерти дублюються через ntfy.sh, алерти по самій FreeBSD та NGINX/PHP йдуть в Telegram, плюс окремий Telegram канал для алертів EcoFlow:
global:
resolve_timeout: 5m
route:
receiver: "ntfy"
group_by: ["alertname, status"]
group_wait: 10s
group_interval: 5m
repeat_interval: 4h
routes:
- matchers:
- severity="critical"
receiver: "ntfy"
continue: true
- matchers:
- job="ecoflow_exporter"
receiver: "telegram_ecoflow"
- matchers:
- alertname =~ ".*"
receiver: "telegram_system"
receivers:
- name: "ntfy"
webhook_configs:
- url: "https://ntfy.sh/setevoy-nas-alertmanager-alerts"
http_config:
authorization:
type: Bearer
credentials: "***"
send_resolved: true
- name: telegram_system
telegram_configs:
- bot_token: "***"
chat_id: -100***962
api_url: https://api.telegram.org
parse_mode: HTML
message: |
{{ if eq .Status "firing" }}🔥{{ else }}✅{{ end }} <b>{{ .CommonLabels.alertname }}</b>
{{ range .Alerts }}
<b>Status:</b> {{ .Status | toUpper }}
{{ if .Labels.severity }}<b>Severity:</b> {{ .Labels.severity }}{{ end }}
{{ if .Annotations.summary }}<b>Summary:</b> {{ .Annotations.summary }}{{ end }}
{{ if .Annotations.description }}<b>Description:</b> {{ .Annotations.description }}{{ end }}
{{ end }}
- name: telegram_ecoflow
telegram_configs:
- bot_token: "***"
chat_id: -100***981
api_url: https://api.telegram.org
parse_mode: HTML
message: |
{{ if eq .Status "firing" }}🔥{{ else }}✅{{ end }} <b>{{ .CommonLabels.alertname }}</b>
{{ range .Alerts }}
<b>Status:</b> {{ .Status | toUpper }}
{{ if .Labels.severity }}<b>Severity:</b> {{ .Labels.severity }}{{ end }}
{{ if .Annotations.summary }}<b>Summary:</b> {{ .Annotations.summary }}{{ end }}
{{ if .Annotations.description }}<b>Description:</b> {{ .Annotations.description }}{{ end }}
{{ end }}
І тепер маємо алерти в Telegram:
Grafana dashboard
Вже не буду описувати весь процес створення, пізніше викладу дашборду десь в GitHub, але в мене виглядає так:
І додатково є “small version” для відображення на 14-дюймовому екрані ноутбука:
Власне, на цьому і все.
Вийшло класно, корисно, вже відловив кілька проблем і перебанив пачку ботів 🙂
При логіні з Okta в Grafana треба автоматично визначати яку Grafana Role йому видати – звичайного Viewer, або Admin, в залежності від того, яка у юзера група в Okta. Є два варіанти того, як це можна зробити – подивимось на обидва.
В Okta є готова App Grafana Labs – але вона підтримує тільки SAML, а хочеться модно-маладьожно, з OIDC – тому створимо окрему інтеграцію.
Єдина проблема, яка в мене виникла – це мапінг вже існуючих в Grafana юзерів із Google SSO з юзерами із Okta – трохи довелось покопатись.
Налаштування Okta
Що треба буде зробити в Okta – це створити нову App з OIDC, взяти її ключі для налаштувань самої Grafana, а потім налаштувати мапінг Okta Groups в Grafana Roles.
Створення Okta OIDC App for Grafana
Переходимо в Applications, створюємо нову апку, вибираємо метод логіну з OIDC, в Application type вказуємо Web Application:
Далі задаємо grant types:
Authorization Code: Grafana зможе виконувати логін юзера
Refresh Token: Grafana зможе оновлювати токен юзера без необхідності його релогіну
В URLs задаємо ті ендпоінти, що вказані в документації – https://<grafana_url>/login/okta та https://<grafana_url>/logout:
Controlled access можна налаштувати пізніше через Assign – або відразу вказати групи, яким буде підключена ця App:
Зберігаємо, і отримуємо ключі для Grafana:
В документації Grafana сказано, що тут ще мають бути і URLs – але їх нема. Втім, вони дефолтні, тому ОК.
Єдиний момент тут, це якщо використовується Okta Custom Domain – але про це вже поговоримо далі, в налаштуваннях самої Grafana.
Тут закінчили, тепер цікаве – мапінг груп Okta в Grafana Roles.
Configure Okta to Grafana role mapping
Тут є два варіанти: або створити кастомні Attributes для нової App, а потім їх задавати для Okta Groups – або в самій Grafana парсити значення в role_attribute_path.
В першому випадку трохи більше клікопсу, але більше гнучкості – а другий простіше, але можна поламати голову з написанням складних умов.
Потестив з обома варіантами – обидва працюють, почнемо з того, як це в документації Grafana – через кастомні атрибути.
Grafana Role на основі Okta App Profile та Custom Attributes
Ідея полягає в тому, що для Profile створеної App ми додаємо новий Attribute, в Grafana вказуємо поле, яке буде містити інформацію про Grafana Role, потім для Okta User або Okta Group задаємо власне значення цього атрибута – і воно передається до Grafana.
Далі, коли ми зробимо Assign цієї App до юзера – App візьме його дефолтні атрибути з Okta User Profile (firstName, lastName, email, login), додасть до них новий атрибут з Grafana Role – і це все разом передасть в Grafana, а далі вже справа самої Grafana – розпарсити поля і визначити Grafana Role цього юзера.
Переходимо до Directory > Profile Editor, знаходимо профайл для нової App:
Клікаємо Add Attribute:
Задаємо тип string, в Enum задаємо список ролей Grafana, в Attribute type можна вказати Group, аби менеджити ролі на рівні груп юзерів:
Далі в документації Grafana в частині Configure Groups claim говориться, що треба налаштувати передачу груп юзерів – але якщо ми передаємо роль через кастомний атрибут – то Grafana Role буде працювати і без цього.
А от якщо робити по другому варіанту – парсити групу і в залежності від групи видавати роль в Grafana – то це треба буде зробити, бо по дефолту групи юзера не передаються.
Отже, додали новий Attribute – повертаємось до списку Applications:
Виконуємо Refresh:
Переходимо до Okta Group, знаходимо підключену Grafana App:
Клікаємо Edit:
Задаємо значення атрибута Grafana Role:
Трохи забігаючи наперед – ось, що ми потім побачимо при логіні в Grafana logs – груп нема, але атрибут grafana_role="Admin" переданий:
...
logger=oauth.okta t=2026-03-27T13:58:14.843471331Z level=debug msg="Received user info response" raw_json="{\"sub\":\"***\",\"name\":\"Arseny Zinchenko\",\"locale\":\"en_US\",\"email\":\"[email protected]\",\"preferred_username\":\"[email protected]\",\"given_name\":\"Arseny\",\"family_name\":\"Zinchenko\",\"zoneinfo\":\"America/Los_Angeles\",\"updated_at\":1774610676,\"email_verified\":true,\"grafana_role\":\"Admin\"}" data="unsupported value type"
Grafana Role на основі Okta Group Name
Інший варіант – не морочитись з кастомними атрибутами, а передавати групи юзера із Okta до Grafana під час логіну, і потім в самій Grafana по імені групи визначати яку ролі підключити.
Для цього в Token claims треба додати передачу групи, і це, начебто, можна зробити через Add Expression і Okta Expression Language з, наприклад, Groups.startsWith():
Groups.startsWith("OKTA", "org-DevOps", 100)
Де “OKTA” – це source групи, а “org-DevOps” – фільтр, аби передавати групу тільки тоді, коли її ім’я починається з “org-DevOps“:
Але тоді Okta свариться, що “‘groups’ is reserved and cannot be used“:
Не став морочитись, і зробив через “Show legacy configuration”:
Тепер при логіні в Grafana ми отримаємо поле groups з усіма групами, до який належить юзер – це приклад з логу Grafana, де це вже налаштовано:
API URL: https://okta.example.com/oauth2/v1/userinfo
Або використовуємо дефолтні з https://<TENANT_ID>.okta.com:
Тепер момент по ролям: якщо роль передаємо через App Profile та Custom Attribute – то в User mapping задаємо значення поля “Role attibute path” просто як grafana_role:
Тоді Grafana прочитає значення поля і замапить “Admin” від Okta в свою локальну роль “Admin”.
Якщо ж робимо через Okta Group Name, тобто передачу групи і без App Profile та кастомних атрибутів – то в Role attibute path пишемо JMESPath expression, в якому вказуємо:
...
logger=oauth.okta t=2026-03-27T11:36:21.745687386Z level=debug msg="Received user info response" raw_json="{\"sub\":\"***\",\"name\":\"Arseny Zinchenko\",\"locale\":\"en_US\",\"email\":\"[email protected]\",\"preferred_username\":\"[email protected]\",\"given_name\":\"Arseny\",\"family_name\":\"Zinchenko\",\"zoneinfo\":\"America/Los_Angeles\",\"updated_at\":1774610676,\"email_verified\":true,\"groups\":[\"orgName Users [old]\",\"Everyone\",\"orgName-All-Users\",\"orgName-DevOps\",\"orgName-All-RnD\",\"orgName-Okta-Admins\"],\"grafana_role\":\"Admin\"}" data="unsupported value type"
logger=user.sync t=2026-03-27T11:36:21.751172007Z level=error msg="Failed to create user" error="user not found" auth_module=oauth_okta auth_id=***
logger=authn.service t=2026-03-27T11:36:21.751234085Z level=error msg="Failed to run post auth hook" client=auth.client.okta id= error="[user.sync.internal] unable to create user: user not found"
...
Що мене тут напрягло – що Grafana намагається “unable to create user” і каже, що “user not found“.
Проблема в тому, що в нашій Grafana вже налаштований Google SSO, і я з ним колись логінився – а тому в Grafana вже є юзер з email":"[email protected]".

 По самому Hermes Agent і його можливостям буду писати окремо, сьогодні – як запустити його на FreeBSD.
По самому Hermes Agent і його можливостям буду писати окремо, сьогодні – як запустити його на FreeBSD.















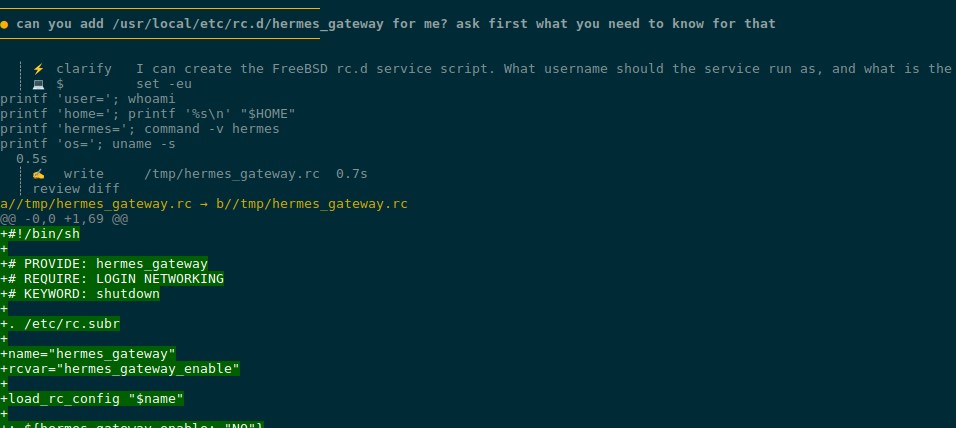





















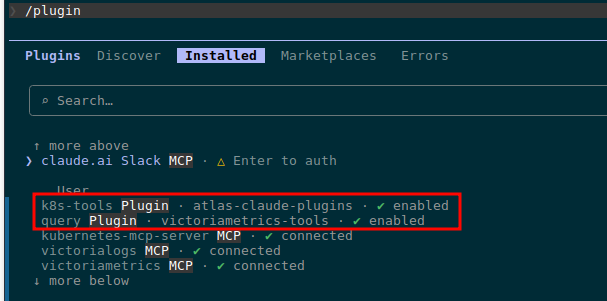


































 На домашньому NAS крутиться багато web-сервісів – Grafana, VictoriaMetrics, мій власний щоденник на WordPress і ще пів-десятка дрібниць.
На домашньому NAS крутиться багато web-сервісів – Grafana, VictoriaMetrics, мій власний щоденник на WordPress і ще пів-десятка дрібниць.