В пості Prometheus: запуск Pushgateway у Kubernetes з Helm та Terraform писав про те, як для Prometheus додати Pushgateway, який дозволяє використовувати Push-модель замість Pull, тобто – експортер може відправити метрики прямо в базу замість того, щоб чекати, коли до нього прийде сам Prometheus або VMAgent.
У VictoriaMetrics з цим набагато простіше, бо ніякого Pushgateway не потрібно – VictoriaMetrics “з коробки” вміє приймати метрики, і це одна з тих чудовіих фіч, чому я вибрав VictoriaMetrics, і досі їй радуюсь.
Все є, і ніяких тобі додаткових дій з Pushgateway!
Push метрик з експортера
Для тесту напишемо простий експортер:
#!/usr/bin/env python3
from time import sleep
from prometheus_client import Counter, CollectorRegistry, push_to_gateway
# local metrics "storage"
registry = CollectorRegistry()
# register a metric
counter = Counter('counter_metric', 'Example metric', ["label_name"], registry=registry)
while True:
# increase metric's value to +1
counter.labels(label_name="label_value").inc()
# push to the VictoriaMetrics
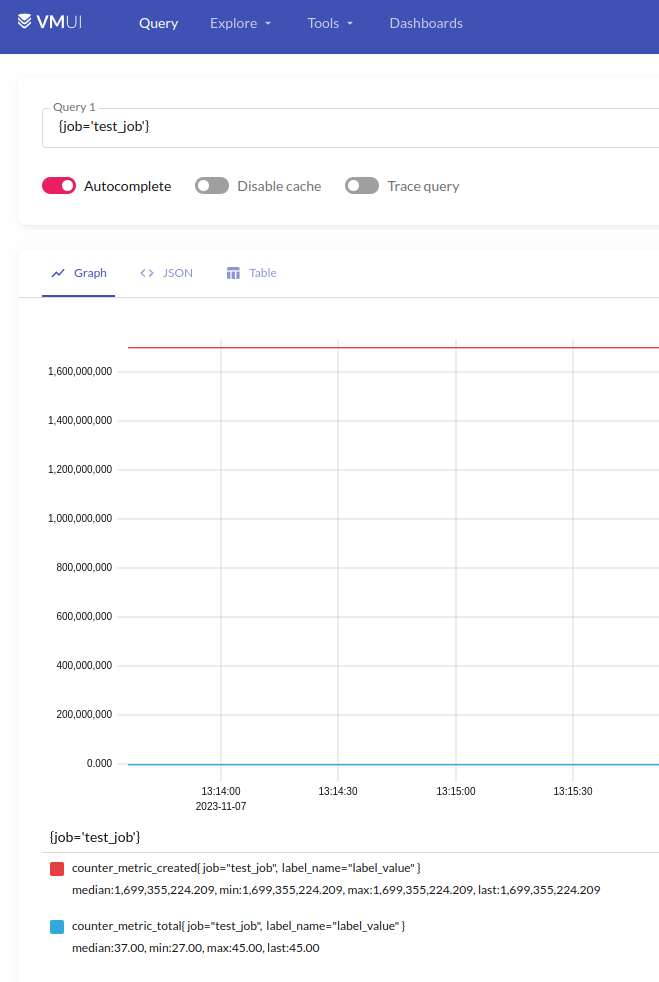
push_to_gateway('localhost:8428/api/v1/import/prometheus', job='test_job', registry=registry)
# make sure this code is working :-)
print("pushed")
# wait before next run
sleep(15)
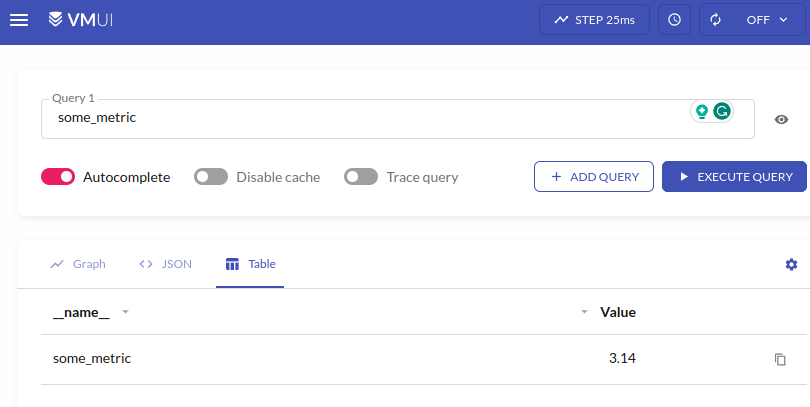
і відправляємо в localhost:8428/api/v1/import/prometheus – це я перевіряв на тестовому інтансі, де VictoriaMetrics запущена з Docker Compose, тому тут localhost
Перевіряємо в самій VictoriaMetrics:
prometheus_client, функції та grouping key
Трохи про те, як працює сам prometheus_client:
push_to_gateway() в registry будуть перезаписані всі метрики з однаковим набором labels (grouping key)
pushadd_to_gateway() перезапише метрики з однаковим іменем та grouping key
delete_from_gateway() видалить метрики з заданим job та grouping key
Починаючи з 0.32, API-ресурси Provisioner, AWSNodeTemplate та Machine будуть deprecated, а з версії 0.33 їх приберуть взагалі.
Замість них додані:
Provisioner => NodePool
AWSNodeTemplate => EC2NodeClass
Machine => NodeClaim
v1alpha5/Provisioner => v1beta1/NodePool
NodePool являється наступником Provisioner, і має параметри для:
налаштування запуску Pods та WorkerNodes – requirements подів до нод, taints, labels
налаштування того, як Karpenter буде розміщувати поди на нодах, та як буде виконувати deprovisioning зайвих нод
“Під капотом” NodePool буде створювати ресурси v1beta1/NodeClaims (які прийшли за зміну v1alpha5/Machine), і взагалі тут ідея приблизно як з Deployments та Pods: в Deployment (NodePool) ми описуємо template того, як буде створюватись Pod (NodeClaims). А v1beta1/NodeClaims в свою чергу являється наступником ресурсу v1alpha5/Machine.
Також була додана новая секція disruption – сюди були перенесені всі параметри, які відносяться до видалення зайвих нод та управління подами, див. Disruption.
v1alpha5/AWSNodeTemplate => v1beta1/EC2NodeClass
EC2NodeClass являється наступником AWSNodeTemplate, і має параметри для:
Лейбли karpenter.sh/do-not-evict та karpenter.sh/do-not-consolidate були об’єднані у нову лейблу karpenter.sh/do-not-disrupt, яку можна використовувати як для Pods, щоб заборонити Karpenetr виконувати Pod eviction, так і для WorkerNodes, щоб заборонити видалення цієї ноди.
Міграція 0.30.0 на v0.32.1
Далі я описую все досить детально і розглядаю різні варіанти, тож може скластися враження, що процес апгрейду досить геморний, бо буде трохи багато тексту, але насправді ні – все досить просто.
який приймає параметр version, який ми передаємо зі змінної var.helm_release_versions.karpenter
і маємо два ресурси kubectl_manifest – для karpenter_provisioner і karpenter_node_template
Процес міграції включає в себе:
оновлення IAM Role, яка використовується подами контролера Karpenter для управління EC2 в AWS:
замінити тег karpenter.sh/provisioner-name на karpenter.sh/nodepool (див. chore: Release v0.32.0) – стосується тільки ролі, яка була створена з Cloudformation, бо в Terraform модулі використовується інший Condition
додати IAM Policy iam:CreateInstanceProfile, iam:AddRoleToInstanceProfile, iam:RemoveRoleFromInstanceProfile, iam:DeleteInstanceProfile та iam:GetInstanceProfile
додавання нових CRD v1beta1, після чого Karpenter сам оновить ресурси Machine на NodeClaim
для міграції AWSNodeTemplate => EC2NodeClass та Provisioner => NodePool можна використати утіліту karpenter-convert
додати taint karpenter.sh/legacy=true:NoSchedule до існуючого Provisioner
Karpneter помітить всі ноди цього Provisioner як drifted
Karpenter запустить нові ЕС2, використовуючи новий NodePool
видалення нод:
створити NodePool аналогічний існуючому Provisioner
видалити існуючий Provisioner командою kubectl delete provisioner <provisioner-name> --cascade=foreground, в результаті чого Karpenter видалить всі його ноди виконавши node drain для всіх відразу, і поди, які перейдуть в стан Pending, запустить на нодах, які були створені з NodePool
ручна заміна:
створити NodePool аналогічний існуючому Provisioner
додати taint karpenter.sh/legacy=true:NoSchedule до старого Provisioner
по черзі вручну видалити всі його WorkerNopes з kubectl delete node
також змінились values – блок aws в settings тепер deprecated, див. values.yaml
Всі зміни начебто backward compatible (перевірив – відкатував версії), тобто можемо спокійно оновлювати існуючі ресурси один за одним – поламатись нічого не повинно.
Тож, що зробимо:
оновимо модуль Terraform
додамо CRD
оновимо Helm-чарт з Karpenter
задеплоїмо, перевіримо – старі ноди від старого Provisioner продовжать працювати, поки ми їх не вб’ємо
додамо нові NodePool та EC2NodeClass
перестворимо WorkerNodes
Поїхали.
Step 1: оновлення Terraform Karpenter module
Виконуємо terraform apply до всіх змін, щоб мати задеплоєну останню версію нашого коду.
У файлі karpenter.tf маємо виклик модуля і його версію:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
version = "19.16.0"
...
Karpenter Instance Profile
В самому модулі була додана нова змінна enable_karpenter_instance_profile_creation, яка визначає хто буде менеджити IAM Roles для WorkerNodes – Terraform, як було раніше, чи використати нову фічу від Karpenter. Якщо enable_karpenter_instance_profile_creation задати в true, то модуль просто додає ще один блок прав в IAM, див. main.tf.
Але тут “є нюанс” (с) в залежностях модулю Karpneter, і Helm-чарту: якщо enable_karpenter_instance_profile_creation включити в true (дефолтне значення false) – то модуль не створить resource "aws_iam_instance_profile", який далі використовується в чарті для Karpenter – параметр settings.aws.defaultInstanceProfile.
Тож тут два варіанти:
спочатку оновити тільки версії – модуля і чарта, але використати старі параметри і Provisioner
після апдейту – створити NodePool and EC2NodeClass, замінити параметри, і перестворити WorkerNodes
або обновити відразу все – і модуль/чарт, і параметри, і Provisioner замінити на NodePool, і задеплоїти все разом
Спочатку можна зробити пошагово, десь на Dev-кластері, щоб подивитись, як воно все пройде, а потім на Prod викатувати вже весь апдейт відразу.
Почнемо, звісно, з Dev.
Міняємо версію на v19.18.0 – див. Releases, і додаємо enable_karpenter_instance_profile_creation = true – але поки закоментимо:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
#version = "19.16.0"
version = "19.18.0"
cluster_name = module.eks.cluster_name
irsa_oidc_provider_arn = module.eks.oidc_provider_arn
irsa_namespace_service_accounts = ["karpenter:karpenter"]
create_iam_role = false
iam_role_arn = module.eks.eks_managed_node_groups["${local.env_name_short}-default"].iam_role_arn
irsa_use_name_prefix = false
# In v0.32.0/v1beta1, Karpenter now creates the IAM instance profile
# so we disable the Terraform creation and add the necessary permissions for Karpenter IRSA
#enable_karpenter_instance_profile_creation = true
}
...
Поки не деплоїмо, йдемо до чарту.
Step 2: оновлення Karpenter Helm chart
Версії чартів в мене зібрані в одній змінній – оновлюємо тут karpneter v0.30.0 на v0.32.1:
Далі у нас два основних апдейти – це CRD та values чарту.
Karpenter CRD Upgrade
CRD є в основному чарті Karpneter, але:
Helm does not manage the lifecycle of CRDs using this method, the tool will only install the CRD during the first installation of the helm chart. Subsequent chart upgrades will not add or remove CRDs, even if the CRDs have changed. When CRDs are changed, we will make a note in the version’s upgrade guide.
Тобто наступні запуски helm install не оновлять CRD, які були встановлені при першій інсталяції.
Тож варіантів тут (знову!) два – або просто вручну їх додати з kubectl, або встановити з додаткового чарту karpenter-crd, див. CRD Upgrades.
При чому чарт встановить і старі CRD v1alpha5, і нові v1beta1, тобто ми будемо мати такий собі “backward compatible mode” – зможемо використовувати і старий Provisioner, і одночасно додати новий NodePool.
З helm template можна перевірити що саме чарт karpenter-crd буде робити:
Але тут є нюанс: для встановлення нових CRD з чарту потрібно буде видалити вже існуючі CRD, а це призведе до того, що і існуючі Provisioner та Machine і відповідні WorkdeNodes будуть видалені.
Тож якщо це вже давно існуючий кластер, і ви хочете все зробити без downtime – то CRD встановлюємо руками.
Якщо кілька хвилин простою вам ОК – то краще вже робити з додатковим Helm-чартом, як й надалі буде все автоматично менеджити.
І запускаємо terraform apply – зараз у нас має оновитись тільки сам чарт – в IAM поки змін не буде, бо маємо enable_karpenter_instance_profile_creation == false.
Після деплою перевіряємо CRD:
$ kk get crd | grep karpenter
awsnodetemplates.karpenter.k8s.aws 2023-11-02T15:33:26Z
ec2nodeclasses.karpenter.k8s.aws 2023-11-03T11:20:07Z
machines.karpenter.sh 2023-11-02T15:33:26Z
nodeclaims.karpenter.sh 2023-11-03T11:20:08Z
nodepools.karpenter.sh 2023-11-03T11:20:08Z
provisioners.karpenter.sh 2023-11-02T15:33:26Z
Перевіряємо поди і ноди – все має залишитись, як було – той самий ресурс Machine, щоб був створений зі старого Provisiner, і та сама WokrderNode:
$ kk get machine
NAME TYPE ZONE NODE READY AGE
default-b6hdr t3.large us-east-1a ip-10-1-35-97.ec2.internal True 30d
Якщо все ОК – то переходимо до створення NodePool та EC2NodeClass.
Step 3: створення NodePool та EC2NodeClass
Спочатку давайте розберемося з IAM ролями 🙂 Але це стосується конкретного мого сетапу, бо якщо ви всі ноди створюєте з Karpenter, то цю частину можна скіпнути.
В Terraform модулі EKS у нас створюється Managed Node Group, в якій створюється IAM Role, яка потім використовується в InstanceProfile для всіх нод кластера.
Далі ця роль передається в модуль karpenter, і тому create_iam_role в модулі Карпентер стоїть в false – бо роль вже є:
Щоб в новому маніфесті з EC2NodeClass передати в поле spec.role ім’я замість iam_role_arn – шукаємо його в outputs.tf:
...
output "iam_role_name" {
description = "The name of the IAM role"
value = try(aws_iam_role.this[0].name, null)
}
output "iam_role_arn" {
description = "The Amazon Resource Name (ARN) specifying the IAM role"
value = try(aws_iam_role.this[0].arn, var.iam_role_arn)
}
...
В spec.amiFamily передаємо AmazonLinux v2, в spec.role – IAM Role для InstanceProfile – вона ж додана і до aws-auth ConfigMap нашого кластера (в модулі eks).
Додавання NodePool
Так як Provisioner/NodePools планувалось мати не один, то їхні параметри задані в variables – копіюємо саму змінну:
Як і з Provisioner – додаємо файл шаблону configs/karpenter-nodepool.yaml.tmpl – тут формат теж трохи змінився, наприклад labels тепер в блоці spec.template.metadata.labels а не spec.labels, як було в Provisioner, див. NodePools.
Тож тепер шаблон виглядає так:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: ${name}
spec:
template:
metadata:
%{ if labels != null ~}
labels:
%{ for k, v in labels ~}
${k}: ${v}
%{ endfor ~}
%{ endif ~}
spec:
%{ if taints != null ~}
taints:
- key: ${taints.key}
value: ${taints.value}
effect: ${taints.effect}
%{ endif ~}
nodeClassRef:
name: default
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: ${jsonencode(instance-family)}
- key: karpenter.k8s.aws/instance-size
operator: In
values: ${jsonencode(instance-size)}
- key: topology.kubernetes.io/zone
operator: In
values: ${jsonencode(topology)}
# total cluster limits
limits:
cpu: 1000
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmpty
consolidateAfter: 30s
в resource "helm_release" "karpenter" видаляємо з values aws.defaultInstanceProfile
в module "karpenter" включаємо enable_karpenter_instance_profile_creation в true
Тепер Terraform має:
додати права до ролі KarpenterIRSA
якщо для модулю karpenter не передавався параметр create_instance_profile == false – то видалиться module.karpenter.aws_iam_instance_profile, але в моєму випадку він все одно не використовувався
і додати kubectl_manifest.karpenter_nodepool["default"] та kubectl_manifest.karpenter_node_class
Деплоїмо, перевіряємо:
$ kk get nodepool
NAME NODECLASS
default default
$ kk get ec2nodeclass
NAME AGE
default 40s
І все ще маємо нашу стару Machine:
$ kk get machine
NAME TYPE ZONE NODE READY AGE
default-b6hdr t3.large us-east-1a ip-10-1-35-97.ec2.internal True 30d
Все – нам лишилось перестворити WorkderNodes, перемістити Поди, і після деплою на Staging та Production прибратись в коді – видалити все, що лишилось від версії 0.30.0.
The provided credentials do not have permission to create the service-linked role for EC2 Spot Instances
В якийсь момент в логах пішла помилка такого плана:
karpenter-5dcf76df9-l58zq:controller {“level”:”ERROR”,”time”:”2023-11-03T14:59:41.072Z”,”logger”:”controller”,”message”:”Reconciler error”,”commit”:”1072d3b”,”controller”:”nodeclaim.lifecycle”,”controllerGroup”:”karpenter.sh”,”controllerKind”:”NodeClaim”,”NodeClaim”:{“name”:”default-ttx86″},”namespace”:””,”name”:”default-ttx86″,”reconcileID”:”6d17cadf-a6ca-47e3-9789-2c3491bf419f”,”error”:”launching nodeclaim, creating instance, with fleet error(s), AuthFailure.ServiceLinkedRoleCreationNotPermitted: The provided credentials do not have permission to create the service-linked role for EC2 Spot Instances.”}
Але, по-перше – чому Spot? Звідки це?
Якщо глянути NodeClaim, який був створений для ціїє ноди, то там бачимо "karpenter.sh/capacity-type == spot":
$ kk get nodeclaim -o yaml
...
spec:
...
- key: karpenter.sh/nodepool
operator: In
values:
- default
- key: karpenter.sh/capacity-type
operator: In
values:
- spot
...
Хоча в документації сказано, що по-дефолту capacity-type має бути on-demand:
...
- key: "karpenter.sh/capacity-type" # If not included, the webhook for the AWS cloud provider will default to on-demand
operator: In
values: ["spot", "on-demand"]
...
А ми в NodePool його не вказували.
Якщо ж в NodePool вказати karpenter.sh/capacity-type явно:
...
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: ${jsonencode(instance-family)}
- key: karpenter.k8s.aws/instance-size
operator: In
values: ${jsonencode(instance-size)}
- key: topology.kubernetes.io/zone
operator: In
values: ${jsonencode(topology)}
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
...
То все працює, як треба.
І по-друге – яких саме пермішенів йому не вистачає? Що за помилка “ServiceLinkedRoleCreationNotPermitted“?
Я спотами в AWS не користувався, тому довелось трохи погуглити, і відповідь знайшлась в документації Work with Spot Instances та гайді Using AWS Spot instances, де мова йде про IAM Role AWSServiceRoleForEC2Spot, яка має бути створена в AWS Account, щоб мати змогу створювати Spot-інстанси.
Трохи дивне рішення по-дефолту створювати Spot, тим більш в документації говориться навпаки. Крім того – в 0.30 все працювало і без явного налаштування karpenter.sh/capacity-type.
Окей, будемо мати на увазі – якщо користуємось виключно On Demand – то треба додавати в конфіг NodePool.
Step 3: оновлення WorkerNodes
Що нам лишилося – це переселити наші поди на нові ноди.
Насправді всі поди переїхали на нові ноди ще під час апдейту, але давайте зробимо, бо нам ще апдейтити інші кластери.
Тут маємо три варіанти, про які говорили на початку. Давайте пробувати робити це без даунтайму – з використанням drift (але без даунтайму – це якщо маєте мінімум по 2 поди на сервіс, і на додачу PodDisruptionBudget).
Що нам треба зробити – це додати taint до існуючого Provisioner, задеплоїти зміни, щоб taint додався до Nodes, і тоді Karpenter виконає Node Drain та створить нові ноди, щоб перемістити наші workloads.
Додаємо в наш шаблон configs/karpenter-provisioner.yaml.tmpl:
І вже всі ці зміни разом можна викатувати на інші Kubernetes кластери – тільки не забудьте оновити tfvars для цих кластерів (якщо маєте щось типу окремих envs/dev/dev-1-28.tfvars, envs/staging/staging-1-28.tfvars, envs/prod/prod-1-28.tfvars).
Rolling back the upgrade
Навряд чи це знадобиться, бо в принці особливих проблема не має бути, але я робив під час ре-тесту апгрейду, тож запишу:
міняємо версію module "karpenter" з нової 19.18.0 на стару 19.16.0
в module "karpenter" коментуємо опцію enable_karpenter_instance_profile_creation
в tfvars для helm_release_versions міняємо версію чарту Karpenter з нової v0.32.1 на стару v0.30.0
лишаємо resource "helm_release" "karpenter_crd"
в resource "helm_release" "karpenter" коментуюємо новий блок values, розкоментуємо старі values через set
коментуємо ресурси resource "kubectl_manifest" "karpenter_nodepool" та resource "kubectl_manifest" "karpenter_node_class"
у файлі configs/karpenter-provisioner.yaml.tmpl прибираємо Taint
Прийшов час почати деплоїти наш бекенд в Kubernetes.
Тут знов використаємо GitHub Actions – будемо білдити Docker-образ з API-сервісом бекенду, зберігати його в AWS Elastic Container Service, а потім деплоїти Helm-чарт, якому у values передамо новий Docker Tag.
Робоче оточення поки одне, Dev, пізніше додамо ще Staging та Production. Крім того, треба мати можливість задеплоїти feature-environment – на той же Dev EKS, але з кастомними значеннями деяких змінних.
Проте зараз будемо робити в тестовому репозиторії “atlas-test” і з тестовим Helm-чартом.
Release flow planning
Як будемо релізити?
Поки вирішили по такій схемі:
Тобто:
девелопер створює бранч, пише код, тестує локально в Docker Compose
після завершення роботи над фічею – створює Pull Request з лейблою “deploy”
workflow Deploy Feature Env
тригер: створення Pull Request з лейблою “deploy“
білдить Docker-образ і тегає його з git commit sha --short
пушить його в ECR
створює feature-оточення в GitHub
деплоїть в Kubernetes Dev в feature-env namespace, де девелопер може додатково потестити свої зміни в умовах, наближених до реальних
після мержу PR в master-гілку:
workflow Deploy Dev:
тригер: push to master або вручну
білдить Docker-образ і тегає його з git commit sha --short
деплой на Dev
якщо деплой пройшов (Helm не видав помилок, Pods запустились, тобто перевірки readiness та liveness Probes пройшли) – створюємо Git Tag
тегаємо вже існуючий Docker образ з цим тегом
workflow Deploy Stage:
тригер: Git Tag created
деплоїться існуючий Docker образ з цим тегом
запускаються integration tests (mobile, web)
якщо тести пройшли – то створюємо GitHub Release – chanelog, etc
workflow Deploy Prod:
тригер: Release created
деплоїться існуючий образ з тегом цього релізу
виконуються тести
ручний деплой
з будь якого існуючого образу на Dev або Staging
Сьогодні зробимо два workflow – Deploy Dev, і Deploy та Destroy Feature-env.
Setup AWS
Для початку нам треба мати ECR та IAM Role.
ECR -для зберігання образів, які будемо деплоїти, а IAM Role буде використовувати GitHub Action для доступу до ECR та логіну в EKS під час деплою.
Репозиторій в ECR у нас вже є, теж з назвою “atlas-test“, створено поки що руками – пізніше перенесемо менеджмент ECR в Terraform.
А от AWS IAM-ролі для проектів в GitHub, які будуть деплоїтись в Kubernetes можемо зробити відразу на етапі створення EKS-кластеру.
Terraform: створення IAM Role
Для деплою з GitHub в AWS ми використовуємо OpenID Connect, тобто аутентифікований юзер GitHub (або в нашому випадку – GitHub Actions Runner) може прийти в AWS, і там виконати AssumeRole, а потім з політиками цієї ролі пройти авторизацію в AWS – перевірку того, що він там може робити.
Щоб деплоїти з GitHub в EKS нам потрібни політики на:
eks:DescribeCluster та eks:ListClusters: щоб авторизуватись в EKS-кластері
ecr: push та read образів з ECR-репозиторію
Крім того, для цієї ролі задамо обмеження на те, з якого репозиторію GitHub можна буде виконати AssumeRole.
В проекті EKS додамо змінну github_projects з типом list, в якій будуть всі GitHub-проекти, яким ми будемо дозволяти деплоїти в цей кластер, поки він тут буде один:
...
variable "github_projects" {
type = list(string)
default = [
"atlas-test"
]
description = "GitHub repositories to allow access to the cluster"
}
Описуємо сам роль, де в циклі for_each перебираємо всі елементи списку github_projects:
в assume_role_policy дозволяємо AssumeRoleWithWebIdentity цієї ролі для token.actions.githubusercontent.com і репозиторію repo:GitHubOrgName:atlas-test
в inline_policy:
дозволяємо eks:DescribeCluster кластеру, який деплоїться
дозволяємо eks:ListClusters всіх кластерів
дозволяємо операції в ECR на всі репозиторії
На ECR було б краще обмежити конкретними репозиторіями, але це поки в тесті, і ще не відомо який неймінг репозиторієв буде.
В locals будуємо новий list(map(any)) – github_roles, а потім в aws_auth_roles за допомогою flatten() створюємо новий list, в який включаємо eks_masters_access_role та ролі із github_roles:
...
locals {
vpc_out = data.terraform_remote_state.vpc.outputs
github_roles = [ for role in aws_iam_role.eks_github_access_role : {
rolearn = role.arn
username = role.arn
groups = ["system:masters"]
}]
aws_auth_roles = flatten([
{
rolearn = aws_iam_role.eks_masters_access_role.arn
username = aws_iam_role.eks_masters_access_role.arn
groups = ["system:masters"]
},
local.github_roles
])
}
...
Далі питання по самому Workflow, а саме – як передати Docker tag, який ми створили в Job build-docker?
Можно зробити деплой з Helm в тій самій джобі, і тоді зможемо використати ту ж змінну IMAGE_TAG.
А можемо зробити окремою job, і передати значення тегу між джобами.
Великого сенсу розділяти на дві джоби тут нема, але по-перше це в білді виглядає більш логічно, по-друге – хочеться спробувати всякі штуки в GitHub Actions, тому давайте передамо значення змінної між джобами.
Наступним кроком треба створити Git Tag. Тут можемо використати Action github-tag-action, який під капотом виконує перевірку заголовку комміту, і в залежності від нього – інкрементить major, minor або patch версію тегу.
Тож давайте спершу поглянемо на Commit Message Format, хоча взагалі-то це тема, яку можна було б винести окремим постом.
Отже, якщо кратко, то заголовок пишемо в форматі “type(scope): subject“, тобто, наприклад – git commit -m "ci(actions): add new workflow".
При цьому type умовно можна поділити на development та production, тобто – зміни, якві відносяться до розробки/розробників, або зміни, які відносяться до production-оточення та end-юзерів:
development:
build (раніше chore): зміни, якві відносяться до білду та пакетів (npm build, npm install, etc)
ci: зміни CI/CD (workflow-файли, terraform apply, etc)
docs: зміни в документації проекту
refactor: рефакторінг коду – нові назви змінних, спрощення коду
style: зміни коду в відступах, коми, лапки-дужки і т.д.
test: зміни в тестах коду – юніт-тести, інтеграційні, etc
В джобі вказуємо needs, щоб запускати тільки після деплою Helm, додаємо permissions, щоб github-tag-action мав змогу додавати теги в репозиторії, і додаємо tag_prefix, бо в репозіторії бекенду, де все це потім буде працювати, вже є стандартні теги з префіксом v. А токен в secrets.GITHUB_TOKEN є по дефолту в саміх Action.
Пушимо з комітом ga -A && gm "ci(actions): add git tag job" && gp, і маємо новий тег:
Workflow: Deploy Feature Environment
Окей – у нас є білд Docker, є деплой Helm-чарту. Все деплоїться на Dev-оточення, все працює.
Давайте додамо ще один workflow – для деплою на EKS Dev, але вже не як dev-оточення, а у тимчасовий Kubernetes Namespace, щоб девелопери мали змогу потестити свої фічі незалежно від Dev-оточення.
Для цього нам потрібно:
тригерити workflow при створенні Pull Request з лейблою “deploy”
створити custom name для нового Namespace – використаємо Pull Request ID
збілдити Docker
задеплоїти Helm-чарт у новий Namespace
Створюємо новий файл – create-feature-env-on-pr.yml.
В ньому буде три джоби:
Docker build
Deploy feature-env
Destroy feature-env
Умови запуску Jobs з if та github.event context
Docker build та Deploy мають запускатись, коли Pull Request створено і якщо він має лейблу “deploy”, а Destroy – коли Pull Request з лейблою “deploy” закрито.
Для тригеру workflow задаємо умову on.pull_request – тоді будемо мати PullRequestEvent з набором полів, які можемо перевірити.
Єдине, що в документації чомусь не вказано поле label, про що говорилось ще в 2017 (!) році, але на ділі вона є.
Тут дуже може допомогти додатковий step, в якому можна вивести весь payload.
Створюємо бранч для тестів, і у файлі create-feature-env-on-pr.yml додаємо першу джобу:
Пушимо, створюмо PR, перевіряємо, і бачимо, що джоба запустилась два рази:
Бо при створенні PR з лейблою маємо два івенти – власне створення PR, тобто івент “opened“, та додавання лейбли – event “labeled“.
Взагалі виглядає трохи криво, як на мене. Але, мабуть, GitHub не зміг обійтися одним івентом в такому випадку.
Тому ми можемо просто прибрати opened з тригерів on.pull_request – і при створенні PR з лейблою джоба затригериться тільки на івент “labeled“.
Ще одна річ, яка виглядає кривувато, хоча тут ми її не використовуємо, але:
для перевірки string в contains() ми використовуємо форму contains(github.event.pull_request.labels.*.name, 'deploy') – спочатку вказуємо об’єкт, в якому шукаємо, потім строка, яку шукаємо
але щоб перевірити декілька strings – формат буде contains('["labeled","closed"]', github.event.action) – тобто спочатку список строк для перевірки, потім об’єкт, в якому їх шукаємо
Окей, йдемо далі: ми можемо мати ще одну умову для запуску – коли для вже створеного PR без лейбли “deploy” який не тригернув нашу джобу, була додана лейбла “deploy” – і тоді нам треба запустити джобу.
А в джобу Helm-деплой теж додамо if та новий step – “Misc: Set ENVIRONMENT variable“, який із значення github.event.number буде створювати нове значення для змінної ENVIRONMENT, яку ми передаємо в ім’я неймспейсу, в який буде деплоїтись чарт:
$ kk get ns pr-5-testing-ns
NAME STATUS AGE
pr-5-testing-ns Active 95s
$ kk -n pr-5-testing-ns get pod
NAME READY STATUS RESTARTS AGE
test-deployment-77f6dcbd95-cg2gf 0/1 CrashLoopBackOff 3 (35s ago) 78s
Мержимо Pull Request – і видаляємо Helm release та Namespace:
Перевіряємо:
$ kk get ns pr-5-testing-ns
Error from server (NotFound): namespaces "pr-5-testing-ns" not found
Bonus: GitHub Deployments
У GitHub є нова фіча – Deployments, яка ще в Beta, але вже можна користуватись:
Ідея Deployments в тому, що для кожного GitHub Environment можна побачити список всіх деплоїв до ньго – зі статусами та комітами:
Для роботи з Deployments використаємо Action bobheadxi/deployments, який приймає input з іменем env. Якщо в env передається не існуючий в репозиторії Environment – то він буде створений.
Крім того, тут маємо набір steps – start, finish, deactivate-env та delete-env.
Під час деплою нам треба викликати start і передати ім’я оточення, по завершенні деплою – викликати finish, щоб передати статус деплою, а при видаленні оточення – викликати delete-env.
До джоби deploy-helm у воркфлоу create-feature-env-on-pr.yml додаємо permissions і нові степи.
Степ “Misc: Create a GitHub deployment” – перед викликом “Deploy: Helm“, а степ “Misc: Update the GitHub deployment status” – після виконаня Helm install:
Що треба зробити зараз – це описати створення чотирьох таких функцій, по одній на кожен компонент проекту. Функції мають бути розміщені в приватних мережах VPC, щоб мати доступ до Ingress Loki у вигляді Internal Load Balancer.
Підготовка
Використаємо “flat-layout” – всі файли Terraform будуть в корні проекту, а значення змінних для Dev та Prod передамо через окремі файли tfvars, див. Terraform Dev/Prod – Helm-like “flat” approach.
Значення key та dynamodb_table передамо під час виконання terraform init, бо для Dev і Prod вони будуть різними.
Додаємо файл variables.tf з поки що двома змінними:
variable "aws_region" {
type = string
default = "us-east-1"
}
variable "project_name" {
description = "A project name to be used in resources"
type = string
default = "atlas-lambda"
}
variable "component" {
description = "A team using this project (backend, web, ios, data, devops)"
type = string
}
variable "environment" {
description = "Dev/Prod, will be used in AWS resources Name tag, and resources names"
type = string
}
variable "eks_version" {
description = "Kubernetes version, will be used in AWS resources names and to specify which EKS version to create/update"
type = string
}
Значенням можно передати в defaults, але мені більш подобається задавати значення явно, а не в дефолтах, тому додаємо файл envs/dev/dev.tfvars:
eks_version використовуємо, щоб створювати окремі ресурси під кожну версію EKS-кластеру, бо під час оновлення версій спокійніше буде створити новий кластер і мігрувати workloads, ніж оновлювати живий Production.
Додаємо файл versions.tf з версіями Terraform та провайдерів:
І третє, що треба буде мати – це Security-група, яка дозволить трафік від та до цих Lambd у приватних Subnets нашої VPC. Для її створення візьмемо ще один модуль Антона – terraform-aws-modules/security-group/aws.
В egress_cidr_blocks та ingress_cidr_blocks вносимо адреси приватних мереж, а в egress_rules та ingress_rules – значення з auto_groups, де вже маємо готовий набор правил.
Ще раз виконуємо terraform init, щоб додати модуль SecurityGroup, та деплоїмо:
$ terraform apply -var-file=envs/dev/dev.tfvars
...
module.security_group_lambda.aws_security_group.this_name_prefix[0]: Creating...
module.security_group_lambda.aws_security_group.this_name_prefix[0]: Creation complete after 3s [id=sg-006d09a7a0ff0beb5]
module.security_group_lambda.aws_security_group_rule.ingress_rules[0]: Creating...
module.security_group_lambda.aws_security_group_rule.egress_rules[0]: Creating...
module.security_group_lambda.aws_security_group_rule.ingress_rules[0]: Creation complete after 1s [id=sgrule-1358616028]
module.security_group_lambda.aws_security_group_rule.egress_rules[0]: Creation complete after 2s [id=sgrule-892435573]
Releasing state lock. This may take a few moments...
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.
Тут в циклі for_each перебираємо всі Components, для яких треба створити фукцію, в package_type вказуємо, що функція буде запускатись з Docker-образу, в environment_variables.EXTRA_LABELS задаємо лейблу component, яка буде додана до логів в Loki.
У vpc_subnet_ids знов використовуємо outputs проекту VPC, в vpc_security_group_ids вказуємо SecurityGroup, яку створили вище.
Для створення EKS – йому треба передати VPC ID, щоб потім з data "aws_subnets" отримати список сабнетів, в яких буде створено кластер Kubernetes.
Можна захаркодити значення VPC – просто задати змінну string, в якій зберігати значення, і в данному випадку це більш-менш робоче рішення, бо VPC ID навряд чи буде часто змінюватись. Проте якщо у вас досить багато значень, або вони динамічні – то є сенс використати terraform_remote_state, який зможе “сходити” в AWS S3 бакет іншого проекту, і отримати актуальні значення прямо зі стейт-файлу.
Отже, що маємо: проект з VPC модулем, який має output:
output "vpc_id" {
value = module.vpc.vpc_id
}
Він вже задеплоїний, і ми можемо отримати цей ID зі стейту за допомогою terraform output:
Тепер, як маємо готовий код для розгортання кластеру AWS Elastic Kubernetes Service (див. Terraform: створення EKS, частина 1 – VPC, Subnets та Endpoints і наступні частини), прийшов час подумати про автоматизацію, тобто – про створення пайплайнів в CI/CD, які би виконували створення нових енвів для тестування фіч, або деплоїли апдейти на Dev/Prod оточення Kubernetes.
І тут знову поговоримо про менеджмент Dev/Prod оточень з Terraform.
То чому б не спробувати аналогічний підхід з Terraform?
В будь-якому разі те, що описано в цьому пості не треба сприймати як приклад “це робиться саме так”: тут я більше експерементую і пробую можливості GitHub Actions та Terraform. А в якому вигляді воно піде в продакшен – подивимось.
Проте вийшло доволі цікаво.
Terraform Dev/Prod – Helm-like “flat” approach
Отже, конфігурація для Terraform може бути такою:
аутентифікацію та атворизацію робимо локально зі змінною AWS_PROFILE, в якому виконується AssumeRole, а в GitHub Actions – через OIDC і AssumeRole – таким чином зможемо мати різні параметри для AWS Provider для Dev та Prod оточень
весь код Terraform зберігається в корні
tfvars для Dev/Prod в окремих директоріях envs/dev та envs/prod
загальні параметри backend описуємо у файлі backend.hcl, а ключі і таблицю Дінамо передаємо через -backend-config
А флоу розробки та деплою – таким:
бранчуємось від мастер-бранчу
робимо зміни в коді, тестуємо локально або через GitHub Actions, передаючи потрібні параметри через -var (ім’я енву, якісь версії і т.д.)
як закінчили розробку і тести – пушимо в репозиторій, і робимо Pull Request
при створенні Pull Request можемо задати спеціиальну лейблу, і тоді GitHub Actions виконують деплой на feature-енв, тобто створюється тимчасова інфрастуктура в AWS
Dev-оточення, щоб перевірити, що все працює
після мержу Pull Request можемо додатково задеплоїти на Dev-оточення, щоб перевірити, що зміни між строю версією та новою працюють (такий собі staging env)
якщо треба задеплоїти на Прод – створюємо Git Release
вручну або автоматично тригерим GitHub Actions на деплой з цим релізом
…
profit!
А що там Terragrunt?
Звісно, для управління оточеннями і бекендами можна було б просто взяти Terragrunt, але я поки не впевнений в тому, яка модель управління інфрастуктурою з Terraform складеться на проекті: якщо цим будуть займатись виключно девопси – то, скоріш за все, візьмемо Terragrunt. Якщо діло зайде і девелоперам, і вони захочуть самі щось менеджити – то, можливо, для управління візьмемо якесь рішення на кштал Atlantis або Gaia.
Тому поки це все тільки починається – робимо все максимально просто і “ванільним” Terraform, а далі подивимось, що і як буде краще.
Terraform layout for multiple environments
Зараз структура файлів і каталогів виглядає так – в environments/dev весь код для Dev, в environments/prod – весь код для Prod (поки пусто):
Однак так як ми тут не використвуємо модулі, то код дуже дублюється, і менеджити його буде важко і як то кажусь, “error prone”.
Можна було б створити модулі, але тоді були б модулі в модулях, бо весь EKS-стек створюється через модулі – VPC, EKS, Subnets, IAM, etc, і ускладнювати код, виносячи код в модулі поки що не хочеться, бо знов-таки – подивимось, як підуть процеси. Поки це все на самому початку – то маємо змогу досить швидко переробити так, як потім буде краще в залежності від того, яку модель і систему управління оточеннями оберемо.
Тож що нам треба зробити:
перенести файли .tf в корень директорії terraform
оновити файл providers.tf – видалити з нього assume_role та прибрати --profile в args провайдерів Kubernetes, Helm та kubectl
створити файл backend.hcl для common-конфігурації
у файлі backend.tf лишити тільки backend "s3"
environments перейменуємо в envs
всередені будуть каталоги dev та prod, в яких будуть зберігатись terraform.tfvars для кожного енва
Тестування з terraform init && plan для різних оточень
Маємо AWS Profile в ~/.aws/config:
[profile work]
region = us-east-1
output = json
[profile tf-assume]
role_arn = arn:aws:iam::492***148:role/tf-admin
source_profile = work
Перевіряємо існуючий ключ в S3 – бо вже маємо задеплоїний Dev:
$ aws s3 ls tf-state-backend-atlas-eks/dev/
2023-09-14 15:49:15 450817 atlas-eks.tfstate
Задаємо змінну AWS_PROFILE, і пробуємо terraform init з backend-config:
$ export AWS_PROFILE=tf-admin
$ terraform init -backend-config=backend.hcl -backend-config="key=dev/atlas-eks.tfstate"
Initializing the backend...
Successfully configured the backend "s3"! Terraform will automatically
...
Terraform has been successfully initialized!
Наче ОК – модулі загрузились, існуючий стейт-файл знайшло, все гуд.
Пробуємо terraform plan – в коді нічого не мінялось, тож нічого не має змінитись і в AWS:
$ terraform plan -var-file=envs/dev/dev.tfvars
...
Terraform will perform the following actions:
# helm_release.karpenter will be updated in-place
~ resource "helm_release" "karpenter" {
id = "karpenter"
name = "karpenter"
~ repository_password = (sensitive value)
# (28 unchanged attributes hidden)
# (6 unchanged blocks hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.
...
Найс! Змінить тільки пароль для AWS ECR, це ОК, бо там токен, що міняється.
Спробуємо зробити теж саме, але для Prod – копіюємо файл dev.tfvars як prod.tfvars в каталог envs/prod, міняємо в ньому данні – тільки VPC CIDR та environment:
І пробуємо новий terraform init з -reconfigure, бо робимо це все локально. В backend-config передаємо новий ключ для стейт-файлу в S3:
$ terraform init -reconfigure -backend-config=backend.hcl -backend-config="key=prod/atlas-eks.tfstate"
Initializing the backend...
Successfully configured the backend "s3"! Terraform will automatically
...
Terraform has been successfully initialized!
Перевіряємо з terraform plan:
$ terraform plan -var-file=envs/prod/prod.tfvars
...
Plan: 109 to add, 0 to change, 0 to destroy.
...
Добре! Збирається створити купу нових ресурсів, бо Prod ще не робив, тобто все, як задумано.
Для feature-енвів все теж саме, тільки в -var передаємо ще environment і в backend-config задаємо новий ключ по імені енва:
Для plan та apply використовуємо параметри з файлу dev.tfvars, бо фіча-енви в принципі більш-менш ~= dev-оточенню:
$ terraform plan -var-file=envs/dev/dev.tfvars -var="environment=feat111"
...
Якщо потрібно задати наприклад нову VPC, яка у нас object, в якому є string vpc_cidr:
...
variable "vpc_params" {
description = "AWS VPC for the EKS cluster parameters. Note, that this VPC will be environment-wide used, e.g. all Dev/Prod AWS resources must be placed here"
type = object({
vpc_cidr = string
enable_nat_gateway = bool
one_nat_gateway_per_az = bool
single_nat_gateway = bool
enable_vpn_gateway = bool
enable_flow_log = bool
})
}
...
Тож її передаємо як -var='vpc_params={vpc_cidr="10.3.0.0/16"}'. Але в такому випадку потрібно передавати всі значення об’єкту vpc_params, тобто:
$ terraform plan -var-file=envs/dev/dev.tfvars -var="environment=feat111" \
> -var='vpc_params={vpc_cidr="10.3.0.0/16",enable_nat_gateway=true,one_nat_gateway_per_az=true,single_nat_gateway=false,enable_vpn_gateway=false,enable_flow_log=false}'
Окей – з цим розібрались, можна переходити до GitHub Actions.
Авторизація і аутентифікація – OIDC та IAM
Для доступу з GitHub Actions до AWS ми використовуємо OpenID Connect – тут GitHub виступає в ролі Identity Provider (IDP), а AWS – Service Prodider (SP), тобто на GitHub ми проходимо аутентифікацю, після чого GitHub “передає” нас до AWS, кажучи, що “це дійсно Вася Пупкін”, а вже AWS виконує авторизацію – тобто, AWS перевіряє, чи може цей Вася Пупкін створювати нові ресурси.
Для авторизації в AWS ми в Terraform виконуємо IAM Role Assume, і вже від імені цієї ролі і IAM Policy, які підключені до неї, ми проходимо авторизацію.
Щоб мати можливість виконувати AsuumeRole цієї ролі використовуючи GitHub Identity Provider – треба змінити її Trusted Policy, бо зараз вона дозволяє AssumeRole тільки для юзерів з AWS акаунту:
GitHub дозволяє налаштувати декілька оточень для роботи, і в кожному мати свій набір Variables та Secrets. Крім того, для них можна налаштувати правила, згідно з якими має відбуватись деплой. наприклад – дозволити деплой на Prod тільки з master-гілки.
і створювати feature-енви динамічно під час деплою
GitHub Actions Reusable Workflow та Composite Actions
З Reusable Workflow ми можемо використати вже описаний Workflow в іншому workflow, а з Composite Actions – створити власну Action, яку потім включимо в steps наших workflow-файлів.
при створенні Workflow ви групуєте декілька Jobs в єдиний файл і використовувати тільки в Jobs, тоді як в Actions будуть тільки steps, які групуються в єдиний Action, який потім можна використовувати тільки як step
Workflow не можуть викликати інші Workflow, тоді як в Actions ви можете викликати інші Actions
І в ній створюємо файл воркфлоу – testing-terraform.yaml.
Так як код Terraform лежить в каталозі terraform, то в workflow додамо defaults.run.working-directory та умову on.push.paths, тобто трігерити білд тільки якщо зміни відбулися в каталозі terraform, див. paths.
Пушимо зміни в репозиторій, запускаємо вручну, бо змін в коді Terraform не було:
І маємо наш перший ран:
Note: аби з’явилась кнопка для ручного запуску (workflow_dispatch) – зміни в workflow-файлі мають бути змержені з дефолтним бранчем репозиторія
GitHub Actions TFLint step
Тепер давайте додамо степ з Terraform linter – TFLint.
Спочатку глянемо, як воно працює локально:
$ yay -S tflint
$ tflint
3 issue(s) found:
Warning: module "ebs_csi_irsa_role" should specify a version (terraform_module_version)
on iam.tf line 1:
1: module "ebs_csi_irsa_role" {
Reference: https://github.com/terraform-linters/tflint-ruleset-terraform/blob/v0.1.1/docs/rules/terraform_module_version.md
Warning: module "karpenter" should specify a version (terraform_module_version)
on karpenter.tf line 1:
1: module "karpenter" {
Reference: https://github.com/terraform-linters/tflint-ruleset-terraform/blob/v0.1.1/docs/rules/terraform_module_version.md
Слушні зауваження – забув додати версії модулів, треба пофіксити.
Тепер можна подумати про те, як нам побудувати workflow.
Які ми маємо дії в GitHub-репозиторії, і які дії з Terraform нам можуть знадобитись?
В GitHub:
Push в будь-який бранч
створення Pull Request на merge в master
закриття Pull Request на merge в master
З Terraform:
тестування: fmt, validate, lint
деплой: plan та apply
дестрой: plan та destroy
І як ми можемо це все скомбінувати в різні workflow?
при Push – виконувати тест
при створенні PR в мастер з лейблою “deploy” – деплоїти feature-енв (тест + деплой)
при закритті PR – видаляти feature-енв (дестрой)
вручну мати можливість:
задеплоїти на Dev будь-який бранч або реліз (тест + деплой)
задеплоїти на Prod реліз з мастер-бранчу (тест + деплой)
Тобто виглядає, як п’ять воркфлоу, при чому майже в усіх маємо дії, які повторюються – логін, init та test, тож їх має сенс винести в окремі “функції” – використати Reusable Workflow або Composite Actions.
AWS Login та init можемо об’єднати, і додатково створити “функцію” test. Крім того – додати “функції” “deploy” та “destroy”, і потім “модульно” їх використовувати у наших workflow:
terraform-init:
AWS Login
terraform init
test:
terraform validate
terraform fmt
tflint
deploy:
terraform plan
terraform apply
destroy:
terraform plan
terraform destroy
Тож якщо планувати з п’ятьма окремими воркфлоу з використанням GitHub Environments та “функціями”, то це будуть:
тест-он-пуш:
запускається на push event
запускається з environment Dev, де маємо змінні для Dev-оточення
викликає “функції” terraform-init та test
деплой-дев:
запускається вручну
запускається з environment Dev, де маємо змінні для Dev-оточення
викликає “функції” terraform-init, test та deploy
деплой-прод:
запускається вручну
запускається з environment Prod, де маємо змінні для Prod-оточення та protection rules
викликає “функції” terraform-init, test та deploy
деплой-фіча-енв:
запускається при створенні ПР з лейблою “деплой”
запускається з динамічним оточенням (ім’я генерується з Pull Request ID і створюється під час деплою)
викликає “функції” terraform-init, test та deploy
дестрой-фіча-енв:
запускається при закритті ПР з лейблою “деплой”
запускається з динамічним оточенням (ім’я генерується з Pull Request ID і під час деплою оточення вибирається з існуючих)
викликає “функції” terraform-init, test та destroy
Як саме робити ці “функції” – з Reusable Workflow чи Composite Actions? В прицнипі, в данному випадку мабуть різниці великої нема, бо будемо мати один рівень вкладеності, але тут є нюанс з GitHub Runners: якщо в Workflow робити задачі “terraform-init”, “test” та “deploy” в різних jobs (а Reusable Workflow мають бути тільки в jobs, більш того – ці jobs не можуть мати інших steps) – то вони скоріш за все будуть запускатись на різних Runners, і в такому випадку для виконання terraform plan && apply && destroy нам доведеться кілька раз виконувати step з AWS Login та terraform init.
Тому виглядає більш правильним запускати всі задачі в рамках однієї job, тобто для створення наших “функцій” використати Composite Actions.
Єдине, що в цьому пості я все ж не буду описувати деплой feature-енвів, бо по-перше – пост і так вже досить довгий і містить багато нвоої (принаймні для мене) інформації, по-друге – створення додаткових тестових кластерів AWS EKS буде скоріш виключенням, і буде робитись мною, а я поки що це можу зробити і без додаткової автоматизації. Втім, скоріш за все опишу створення динамічних оточень, коли буду робити GitHub Actions Workflow для деплоїв Helm-чартів.
Окей – давайте пробувати деплоїти Dev та Prod.
Підготовка деплоїв
Створення Actions secrets and variables
У нас буде декілька змінних, які будуть однакові для всіх оточень – AWS_REGION та TF_AWS_PROFILE, тож їх задамо на рівні всього репозиторію.
Переходимо в Settings – Actions secrets and variables > Variables, і додаємо Repository variables:
Створення GitHub Environments
Додаємо два оточення – Dev та Prod:
Аналогічно для Prod.
Створення test-on-push Workflow
Створення Composite Action “terraform-init”
В директорії .github додаємо каталог actions, в якому створюємо каталог terraform-init з файлом action.yaml, в якому описуємо сам Action.
Тут є нюанс з working-directory, який в Composite Action треба задавати окремо для кожного step, бо сам Action в workflow запускається в корні репозиторія, а використати defaults, як це можна зробити в workflow не можна, хоча feature request є давно.
Створення Composite Action “test”
В директорії actions створюємо ще один каталог – terraform-test з файлом action.yaml, в якому описуємо другий Action:
В job: test-terraform задаємо використання environment: 'dev' і його змінних (у нас там вона одна – ENVIRONMENT=dev, а в steps “AWS Login and Terraform init” і “Test and validate” викликаємо наші файли з Actions, які через with передаємо параметри зі значеннями із змінних.
Пушимо зміни в репозиторій, і маємо наш білд:
Можемо переходити до деплою.
Створення deploy-dev Workflow
Отже, що ми хочемо?
деплоїти на Дев з бранчу або тегу
деплоїти на Прод вручну з релізу
Давайте почнемо з Дев-деплою.
Створення Composite Action “deploy”
Створюємо ще один каталог для нового Action – actions/terraform-apply, в ньому у файлі action.yaml описуємо сам Action:
В concurrency задаємо умову “ставити в чергу, а не виконувати паралельно, якщо запущено іншу job, яка використовує такий же concurrency.group“, див. Using concurrency.
Тобто, якщо ми робимо перевірку по group: deploy-${{ vars.ENVIRONMENT }} – то якщо після запуску Dev запустити деплой на Prod – то він буде очікувати, поки не завершиться деплой на Dev:
Пушимо, мержимо в master, щоб з’вилась кнопка “Run workflow“, і перевіряємо:
І після деплою:
Створення deploy-prod Workflow та захист від випадкового запуску
Composite Action ми вже маємо, тож створювати її не треба.
В принципі, тут маємо все аналогчно до деплою на Dev – concurrency, ручний запуск, jobs, едине, що тут має бути інша умова запуску – по тегам замість бранчів і тегів.
Тобто на Дев можемо деплоїти будь-який бранч або тег, а на Прод – тільки тег.
Взагалі я тут намагаюсь уникнути автоматичного деплою, бо це все ж інфрастуктура і все ще в процессі роботи напильником, хоча якщо б у нас був GitHub Enterprise – то можна було б використати Deployment protection rules і Required reviewers в них, а в умові on для запуску воркфлоу деплою на Прод використати створення релізів:
on:
release:
types: [published]
Тобто – деплоїти на Prod тільки коли створено новий GitHub Release, і тільки після того, як, наприклад, деплой апрувнуто кимось з DevOps-тіми.
Ще один варіант забезпечення безпеки Prod-оточення – це дозволяти мерж в master тільки від Code Owners в Branch protection rules:
А Code Owners описати у файлі CODEOWNERS, і дозволити деплой на Prod тільки з мастер-гілки:
Але я хочу тут використати флоу з деплояіми тільки з релізів або тегів, щоб мати щось на кшталт версіонювання.
Ну і можна комбінувати умови, наприклад – додатково через github.actor або github.triggering_actor перевіряти хто саме запускає деплой, і дозволити тільки певним юзерам. Див. всі типи в github context.
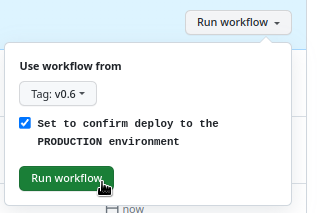
Як додатковий захист від випадкового запуску – можна додати input, до треба явно вказати “yes”:
...
on:
workflow_dispatch:
inputs:
confirm-deploy:
type: boolean
required: true
description: "Set to confirm deploy to the PRODUCTION environment"
...
А потім перевірити в if обидві умови – github.ref_type та github.event.inputs.confirm-deploy.
І при деплої – треба по-перше вибрати тег, а не бранч, по-друге – поставити відмітку “Confirm”:
А вже по ходу діла подивимось, як все буде складатись.
Ну і поки що на цьому все.
В цілому – в GitHub Actions зробили дуже багато всього, і коли починав робити ці деплої – прям не очікував, що буде стільки цікавих можливостей.
Так що – далі буде ще.
Пару моментів на додачу, доробити потім:
Action setup-terraform приймає інпут terraform_version, але не вміє це робити з versions-файлу; поки варіант робити через міні-костиль з додатковим step, див. цей коммент
в jobs має сенс додати параметр timeout-minutes, щоб джоби при проблемах не зависали на довгий час, і не вичерпували Runners time
Отже, вибрав все ж варіант з менеджментом бекендів через окремий проект Terraform, де в змінних маємо список проектів, яким треба мати AWS S3 bucket та таблицю DynamoDB, та їхніх оточень – Dev/Prod.
Потім в циклі for_each проходимось по елементам списку проектів, і створюємо необхідні ресурси.
В такому випадку девелоперам, щоб запустити новий проект, не треба мати справу зі створенням ресурсів для бекенду state-файлів взагалі – вони або самі можуть просто додати нове значення в змінну і виконати terraform apply, чи попросити когось з DevOps-тіми, а потім просто додати значення да власного backend.tf.
Бекенд для самого проекту який менеджить всі бекенди створюється ним же – в перший раз з локальним бекендом, а після створення проекту – його стейт туди імпортується, і надалі вже використовується цей remote state.
Файл backend.tf поки не описуємо – робимо все локально.
Виконуємо terraform init, і переходимо до змінних.
Variables – список проектів і оточень
Тут нам потрібна по факту одна змінна з типом map(list(string)), в якій ми описуємо список проектів, для яких будемо створювати ресурси, в тому числі включаємо в неї сам проект, який буде створювати всі ці ресурси.
І для кожного елементу з іменем проекту в значення включаємо список з іменами оточень цього проекту:
variable "projects" {
description = "Project names with their environments to be used in S3 and DynamoDB resources"
type = map(list(string))
default = {
atlas-tf-backends-test = [
"prod"
]
atlas-eks-test = [
"dev", "prod"
]
}
}
Resources
Створення AWS S3 бакетів
Що нам треба, це для кожного проекту створити AWS S3 Bucket, включити йому Versioning, додати Encryption, і заборонити публічний доступ до об’єктів через S3 Bucket ACL.
Щодо Dev/Prod оточень: можна створювати окремі корзини на кожен Env кожного проекту, чи один бакет на проект, а вже в самому проекті використовувати різні ключі, тобто:
проект atlas-eks-test
корзина atlas-eks-test
при terraform init Dev-оточення використовуємо -backend-config="key=dev/atlas-eks.tfstate"
при terraform init для Prod-оточення використовуємо -backend-config=key=prod/atlas-eks.tfstate
Для таблиць DynamoDB створимо окремі таблиці для Dev/Prod, а всякі feature-енви можна буде деплоїти або без State Lock, бо вони тимчасові, і будуть деплоїтись з якогось одного Pull Request з GitHub Actions, або при потребі – створювати таблицю під час деплою проекту командою AWS CLI create-table.
Отже – в змінних маємо map зі списком проектів.
Для S3 використовуємо for_each, з якого отримуємо each.key, який буде містити ім’я проекту, тобто “atlas-eks-test” або “atlas-tf-backends-test“:
# create state-files S3 buket
resource "aws_s3_bucket" "state_backend" {
for_each = var.projects
bucket = "tf-state-backend-${each.key}"
# to drop a bucket, set to `true`
force_destroy = false
lifecycle {
# to drop a bucket, set to `false`
prevent_destroy = true
}
tags = {
environment = var.environment
}
}
Далі, для ресурсів aws_s3_bucket_versioning, aws_s3_bucket_server_side_encryption_configuration та aws_s3_bucket_public_access_block знов використовуємо for_each, але тепер ітерацію виконуємо по списку ресурсів aws_s3_bucket.state_backend, тобто весь код буде таким:
# create state-files S3 buket
resource "aws_s3_bucket" "state_backend" {
for_each = var.projects
bucket = "tf-state-backend-${each.key}"
# to drop a bucket, set to `true`
force_destroy = false
lifecycle {
# to drop a bucket, set to `false`
prevent_destroy = true
}
tags = {
environment = var.environment
}
}
resource "aws_kms_key" "state_backend_kms_key" {
description = "This key is used to encrypt bucket objects"
deletion_window_in_days = 10
}
# enable S3 bucket versioning
resource "aws_s3_bucket_versioning" "state_backend_versioning" {
for_each = aws_s3_bucket.state_backend
bucket = each.value.id
versioning_configuration {
status = "Enabled"
}
}
# enable S3 bucket encryption
resource "aws_s3_bucket_server_side_encryption_configuration" "state_backend_encryption" {
for_each = aws_s3_bucket.state_backend
bucket = each.value.id
rule {
apply_server_side_encryption_by_default {
kms_master_key_id = aws_kms_key.state_backend_kms_key.arn
sse_algorithm = "aws:kms"
}
bucket_key_enabled = true
}
}
# block S3 bucket public access
resource "aws_s3_bucket_public_access_block" "state_backend_acl" {
for_each = aws_s3_bucket.state_backend
bucket = each.value.id
block_public_acls = true
block_public_policy = true
ignore_public_acls = true
restrict_public_buckets = true
}
В ouputs додаємо відображення створених бакетів, використовуючи цикл for та String Templates:
output "state_backend_bucket_names" {
value = "AWS S3 State Buckets:\n%{for name in aws_s3_bucket.state_backend}- ${name.bucket}\n%{endfor}"
}
І виконуємо terraform init ще раз, щоб перенести власний стейт з локального файлу terraform.tfstate до створеного S3 бакету:
$ terraform init
Initializing the backend...
Do you want to copy existing state to the new backend?
Pre-existing state was found while migrating the previous "local" backend to the
newly configured "s3" backend. No existing state was found in the newly
configured "s3" backend. Do you want to copy this state to the new "s3"
backend? Enter "yes" to copy and "no" to start with an empty state.
Enter a value: yes
...
Terraform has been successfully initialized!
Створення таблиць DynamdoDB
Якщо для S3 ми робили одну корзину на кожен проект, то для DynamoDB буде окрема таблиця на кожен Env кожного проекту (хоча можна мати і одну – тоді Terraform при створенні ключів сам задасть значення Env, див. Backends S3).
Якщо якийсь проект більш не актуальний, і треба видалити його ресурси – то це буде робитись в три етапи apply:
міняємо параметри aws_s3_bucket:
включаємо force_destroy – це потрібно, щоб видалити корзини, в яких включено Versioning і які мають об’єкти
відключаємо prevent_destroy – щоб дозволити видалення
виконуємо apply, щоб застосувати зміни
видаляємо проект з var.projects
виконуємо apply, щоб видалити корзину та пов’язані ресурси
повертаємо значення параметрів aws_s3_bucket – force_destroy та prevent_destroy
виконуємо apply, щоб застосувати зміни
Тобто:
# create state-files S3 buket
resource "aws_s3_bucket" "state_backend" {
for_each = var.projects
bucket = "tf-state-backend-${each.key}"
# to drop a bucket, set to `true`
force_destroy = true
lifecycle {
# to drop a bucket, set to `false`
prevent_destroy = false
}
tags = {
environment = var.environment
}
}
...
Потім видаляємо ім’я проекту зі значень змінної projects:
variable "projects" {
description = "Project names list with its environments to be used in S3 and DynamoDB nresources"
type = map(list(string))
default = {
atlas-tf-backends-test = [
"prod"
]
}
}
Цей аддон можна встановити з Amazon EKS Blueprints Addons, котрий далі будемо використовувати для ExternalDNS, але раз уж ставимо аддони через cluster_addons в модулі EKS, то давайте і цей зробимо таким же чином.
Для aws-ebs-csi-driver ServiceAccount нам знадобиться окрема IAM Role – створимо її за допомогою IRSA Terraform Module.
$ kk get pod
NAME READY STATUS RESTARTS AGE
pvc-pod 1/1 Running 0 106s
$ kk get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-dynamic Bound pvc-a83b3021-03d8-458f-ad84-98805ec4963d 1Gi RWO gp2 119s
$ kk get pv pvc-a83b3021-03d8-458f-ad84-98805ec4963d
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-a83b3021-03d8-458f-ad84-98805ec4963d 1Gi RWO Delete Bound default/pvc-dynamic gp2 116s
З цим все готово.
Terraform та ExternalDNS
Для ExternalDNS спробуємо Amazon EKS Blueprints Addons. На відміну від того, як ми робили EBS CSI, тут нам не потрібно буде окремо створювати IAM Role, бо модуль створить її сам.
Правда, в документації чомусь вказана передача параметрів для чарту external_dns_helm_config (UPD – поки писав цей пост, вже видалили сторінку взагалі), хоча на ділі це призводить до помилки “An argument named “external_dns_helm_config” is not expected here“.
Щоб знайти, як жеж нам передати параметри – йдемо на сторінку модулю в eks-blueprints-addons, і дивимось які інпути є для external_dns:
Далі перевіряємо файл main.tf модулю, де бачимо змінну var.external_dns, в якій можна передати всі параметри.
Дефолтні версії чартів задаються у тому ж файлі, але вони місцями застарілі, теж задамо свої.
Знаходимо останню версію для ЕxternalDNS:
$ helm repo add external-dns https://kubernetes-sigs.github.io/external-dns/
"external-dns" has been added to your repositories
$ helm search repo external-dns/external-dns --versions
NAME CHART VERSION APP VERSION DESCRIPTION
external-dns/external-dns 1.13.1 0.13.6 ExternalDNS synchronizes exposed Kubernetes Ser...
...
Додаємо змінну для версій чартів:
variable "helm_release_versions" {
description = "Helm Chart versions to be deployed into the EKS cluster"
type = map(string)
}
Так як ми використовуємо VPC Endpoint для STS, то в аннотації ServiceAccount передаємо eks.amazonaws.com/sts-regional-endpoints="true" – аналогічно тому, як робили для Karpenter.
У external_dns.values передаємо бажані параметри – policy, в domainFilters наш домен, та задаємо tolerations, щоб под запускався на наших дефолтних нодах:
...
time="2023-09-13T12:01:39Z" level=info msg="Desired change: CREATE cname-test-dns.dev.example.co TXT [Id: /hostedzone/Z09***BL9]"
time="2023-09-13T12:01:39Z" level=info msg="Desired change: CREATE test-dns.dev.example.co A [Id: /hostedzone/Z09***BL9]"
time="2023-09-13T12:01:39Z" level=info msg="Desired change: CREATE test-dns.dev.example.co TXT [Id: /hostedzone/Z09***BL9]"
time="2023-09-13T12:01:39Z" level=info msg="3 record(s) in zone dev.example.co. [Id: /hostedzone/Z09***BL9] were successfully updated
Готово.
Terraform та AWS Load Balancer Controller
Робимо аналогічно з ExternalDNS – будемо встановлювати з модуля Amazon EKS Blueprints Addons.
Спочатку нам треба протегати публічні і приватні сабнети – див. Subnet Auto Discovery.
Також перевірте, щоб на них був тег kubernetes.io/cluster/${cluster-name} = owned (має бути, якщо деплоїли з Terraform модулем EKS, як це робили в першій частині).
Додаємо теги через public_subnet_tags та private_subnet_tags:
Деплоїмо, перевіряємо Ingress – чи додався до нього Load Balancer:
$ kk get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
hello-ingress alb test-dns.dev.example.co k8s-kubesyst-helloing-***.us-east-1.elb.amazonaws.com 80 45s
Ніяк налаштувань тут не треба – тільки додати Tolerations.
Знаходимо версії:
$ helm repo add secrets-store-csi-driver https://kubernetes-sigs.github.io/secrets-store-csi-driver/charts
"secrets-store-csi-driver" has been added to your repositories
$ helm repo add secrets-store-csi-driver-provider-aws https://aws.github.io/secrets-store-csi-driver-provider-aws
"secrets-store-csi-driver-provider-aws" has been added to your repositories
$ helm search repo secrets-store-csi-driver/secrets-store-csi-driver
NAME CHART VERSION APP VERSION DESCRIPTION
secrets-store-csi-driver/secrets-store-csi-driver 1.3.4 1.3.4 A Helm chart to install the SecretsStore CSI Dr...
$ helm search repo secrets-store-csi-driver-provider-aws/secrets-store-csi-driver-provider-aws
NAME CHART VERSION APP VERSION DESCRIPTION
secrets-store-csi-driver-provider-aws/secrets-s... 0.3.4 A Helm chart for the AWS Secrets Manager and Co...
Додаємо нові значення до змінної helm_release_versions у terraform.tfvars:
Для IAM Roles, які ми потім будемо додавати до сервісів, якім потрібен доступ до AWS SecretsManager/ParameterStore треба буде підключати політику, яка дозволяє доступ до відповідних AWS API викликів.
Деплоїмо (у default неймспейс, бо в Trust policy маємо перевірку subject на "system:serviceaccount:default:ascp-test-serviceaccount"), і перевіряємо файл в поді:
$ kk exec -ti pod/ascp-test-pod -- cat /mnt/ascp-secret/eks-test-param
paramLine
Terraform та Metrics Server
Тут теж зробимо з Amazon EKS Blueprints Addons – див. metrics_server.
Теж ніяк додаткових налаштувань не треба – просто включити, і перевірити. Навіть версію можна не задавати, тільки tolerations.
$ kk get pod | grep metr
metrics-server-76c55fc4fc-b9wdb 1/1 Running 0 33s
І перевіряємо з kubectl top:
$ kk top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-10-1-32-148.ec2.internal 53m 2% 656Mi 19%
ip-10-1-49-103.ec2.internal 56m 2% 788Mi 23%
...
Terraform та Vertical Pod Autoscaler
Щось забув, що для Horizontal Pod Autoscaler окремого контроллеру не треба, тож тут нам знадобиться тільки додати Vertical Pod Autoscaler.
Беремо знову з Amazon EKS Blueprints Addons, див. vpa.
Знаходимо версію:
$ helm repo add vpa https://charts.fairwinds.com/stable
"vpa" has been added to your repositories
$ helm search repo vpa/vpa
NAME CHART VERSION APP VERSION DESCRIPTION
vpa/vpa 2.5.1 0.14.0 A Helm chart for Kubernetes Vertical Pod Autosc...
$ kk get vpa
NAME MODE CPU MEM PROVIDED AGE
hamster-vpa 100m 104857600 True 61s
Та статус подів:
$ kk get pod
NAME READY STATUS RESTARTS AGE
hamster-8688cd95f9-hswm6 1/1 Running 0 60s
hamster-8688cd95f9-tl8bd 1/1 Terminating 0 90s
Готово.
Додавання Subscription Filter до Cloudwatch Log Group з Terraform
Майже все зробили. Залишилось дві дрібниці.
Спершу – додати форвадніг логів з EKS Cloudwatch Log Groups до Lambda-функції, в якій працює Promtail, який буде ці логи пересилати до інстансу Grafana Loki.
Наш EKS модуль створює CloudWatch Log Group /aws/eks/atlas-eks-dev-1-27-cluster/cluster зі стрімами:
І виводить ім’я цієї групи через output cloudwatch_log_group_name, який ми можемо використати у aws_cloudwatch_log_subscription_filter, щоб до цієї лог-групи додати фільтр, в якому треба передати destination_arn з ARN нашої Lambda.
Lambda-функція у нас вже є, створюється окремою автоматизацію для моніторинг-стеку. Щоб отримати її ARN – використаємо data "aws_lambda_function", в який передамо ім’я функції, а саме ім’я винесемо у змінні:
variable "promtail_lambda_logger_function_name" {
type = string
description = "Monitoring Stack's Lambda Function with Promtail to collect logs to Grafana Loki"
}
Щоб наш Subscription Filter мав змогу звератись до цієї функції – потрібно додати aws_lambda_permission, де в source_arn передаємо ARN нашої лог-групи. Тут зверніть увагу, що ARN передається як arn::name:*.
У principal треба вказати logs.AWS_REGION.amazonaws.com – AWS_REGION отримаємо з data "aws_region".
Це вже третя частина по розгортанню кластеру AWS Elastic Kubernetes Service з Terraform, в якій будемо додавати в наш кластер Karpenter. Вирішив винести окремо, бо виходить досить довгий пост. І вже в останній (сподіваюсь), четвертій частині, додамо решту – всякі контроллери.
На додачу вже існуючим у нас провайдерам AWS та Kubernetes нам здобляться ще два – Helm та Kubectl.
Helm, очевидно що для встановлення Helm-чартів – а контролери ми будемо встановлювати саме з чартів, а kubectl – для деплою ресурсів з власних Kubernetes-маніфестів.
Отже додаємо їх в наш файл providers.tf. Авторизацію робимо аналогічно тому, як робили для Kubernetes-провайдера – через AWS CLI, і в args передаємо ім’я профілю:
Виконуємо terraform init для установки провайдерів.
Варіанти установки Karpenter в AWS EKS з Terraform
Є декілька варіантів установки Karpenter з Terraform:
написати все самому – IAM-ролі, SQS для interruption-handling, оновлення aws-auth ConfigMap, встановлення Helm-чарту з Karpenter, створення Provisioner та AWSNodeTemplate
Для роботи Karpenter використвує тег karpenter.sh/discovery з SecurityGroup наших WorkerNodes та приватних VPC Subnets щоб знати які SecurityGroups додавати на Nodes, та в яких subnets ці ноди запускати.
В значені тегу задається ім’я кластеру, якому належить SecurityGroup чи Subnet.
Додамо нову локальну змінну eks_cluster_name до main.tf:
locals {
# create a name like 'atlas-eks-dev-1-27'
env_name = "${var.project_name}-${var.environment}-${replace(var.eks_version, ".", "-")}"
eks_cluster_name = "${local.env_name}-cluster"
}
І у файлі eks.tf додаємо параметр node_security_group_tags:
...
output "karpenter_irsa_arn" {
value = module.karpenter.irsa_arn
}
output "karpenter_aws_node_instance_profile_name" {
value = module.karpenter.instance_profile_name
}
output "karpenter_sqs_queue_name" {
value = module.karpenter.queue_name
}
І переходимо до Helm – додаємо чарт з самим Karpenter.
Тут у variables можна винести версію модулю:
...
variable "karpenter_chart_version" {
description = "Karpenter Helm chart version to be installed"
type = string
}
Да terraform.tfvars додаємо значення з останнім релізом чарта:
...
karpenter_chart_version = "v0.30.0"
Для доступу Helm до репозиторія oci://public.ecr.aws нам буде потрібен токен. Отримаємо його з aws_ecrpublic_authorization_token. Тут є нюанс, що він працює тільки для регіону us-east-1, бо токени AWS ECR видаються саме там. Див. aws_ecrpublic_authorization_token breaks if region != us-east-1.
Помилка “cannot unmarshal bool into Go struct field ObjectMeta.metadata.annotations of type string”
Також, так як ми використовуємо VPC Endpoint для AWS STS, то нам до ServiceAccount, який буде створюватись для Karpenter, треба додати аннотацію eks.amazonaws.com/sts-regional-endpoints=true.
Проте якщо додати аннотацію у set як:
set {
name = "serviceAccount.annotations.eks\\.amazonaws\\.com/sts-regional-endpoints"
value = "true"
}
То Terraform видаває помилку “cannot unmarshal bool into Go struct field ObjectMeta.metadata.annotations of type string“.
Рішення нагуглилось ось у цьому коментарі до GitHub Issue – “просто додай води type=string“.
В тексті помилки говориться, що Terraform не може “unmarshal bool” (“розпаковати значення з типом bool”) у поле spec.tolerations.value, яке має тип string.
Рішення – це вказати тип значення явно, через type = "string".
До karpenter.tf додаємо aws_ecrpublic_authorization_token та ресурс helm_release, в якому встановлюємо чарт Karpenter:
...
data "aws_ecrpublic_authorization_token" "token" {}
resource "helm_release" "karpenter" {
namespace = "karpenter"
create_namespace = true
name = "karpenter"
repository = "oci://public.ecr.aws/karpenter"
repository_username = data.aws_ecrpublic_authorization_token.token.user_name
repository_password = data.aws_ecrpublic_authorization_token.token.password
chart = "karpenter"
version = var.karpenter_chart_version
set {
name = "settings.aws.clusterName"
value = local.eks_cluster_name
}
set {
name = "settings.aws.clusterEndpoint"
value = module.eks.cluster_endpoint
}
set {
name = "serviceAccount.annotations.eks\\.amazonaws\\.com/role-arn"
value = module.karpenter.irsa_arn
}
set {
name = "serviceAccount.annotations.eks\\.amazonaws\\.com/sts-regional-endpoints"
value = "true"
type = "string"
}
set {
name = "settings.aws.defaultInstanceProfile"
value = module.karpenter.instance_profile_name
}
set {
name = "settings.aws.interruptionQueueName"
value = module.karpenter.queue_name
}
}
Karpenter Provisioner та Terraform templatefile
Поки що у нас буде тільки один Karpernter Provisioner, проте згодом скоріш за все будемо додавати ще, тому давайте це відразу зробимо через шаблони.
На старому кластері маніфест нашого дефолтного Provisioner виглядає так:
Створюємо сам файл шаблону – спочатку додаємо локальний каталог configs, де будуть всі шаблони, і в ньому додаємо файл karpenter-provisioner.yaml.tmpl.
Для параметрів, в які будуть передаватись елементи з типом list додаємо jsonencode(), щоб перетворити їх на стрінги:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: ${name}
spec:
%{ if taints != null ~}
taints:
- key: ${taints.key}
value: ${taints.value}
effect: ${taints.effect}
%{ endif ~}
%{ if labels != null ~}
labels:
%{ for k, v in labels ~}
${k}: ${v}
%{ endfor ~}
%{ endif ~}
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: ${jsonencode(instance-family)}
- key: karpenter.k8s.aws/instance-size
operator: In
values: ${jsonencode(instance-size)}
- key: topology.kubernetes.io/zone
operator: In
values: ${jsonencode(topology)}
providerRef:
name: default
consolidation:
enabled: true
kubeletConfiguration:
maxPods: 100
ttlSecondsUntilExpired: 2592000
Далі, в karpenter.tf додаємо ресурс kubectl_manifest з циклом for_each, в якому перебираємо всі елементи мапи karpenter_provisioner:
Вказуємо depends_on, бо якщо все це деплоїться перший раз, то Terraform повідомляє про помилку “resource [karpenter.sh/v1alpha5/Provisioner] isn’t valid for cluster, check the APIVersion and Kind fields are valid“, бо в кластері ще немає самого Karpenter.
AWSNodeTemplate у нас навряд чи буде змінюватись, тому його можемо створити просто ще одним kubectl_manifest:
Вже давно і досить часто просять розказати як пишу пости в блог. Ну і раз вже така тема, і я нарешті таки зібрався про це написати – то давайте поглянемо навіщо взагалі вести блог, і як його вести.
Навіщо вести свій IT блог?
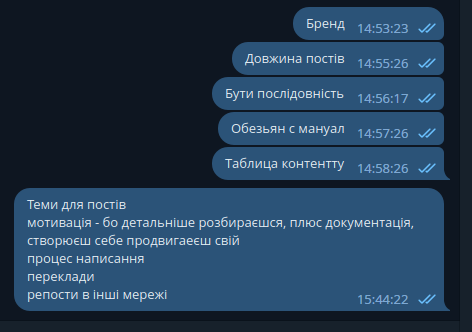
Цей блог я починав головним чином як такий собі блокнот для себе самого – просто записувати як і що я робив, аби потім не шукати в інтернеті якісь мануали, чи записувати те, чого в інтернеті не було взагалі.
Згодом, це трансформувалося в бажання поділитись тим, який я не в біса крутий спеціаліст, бо коли ти вперше збираєш ядро FreeBSD, то здається, що ти бог 🙂 Це, звісно, та ще бугогашенька, бо вперше ядро я зібрав ще у 2007, і робив це як та “мавпа з мануалом” (привіт, Хом’як!) – читав, копіпастив, але дуже мало що розумів.
Насправді коли я вже трохи набрався досвіду, то ведення блогу дало ще один важливий бонус – він допомагає боротись з власним “синдромом самозванця”, бо навіть після (ОМГ!) 18 років в IT цей синдром нікуди не дівався, і я досі іноді думаю “Блін, а нє хєрню лі я написав?”. Проте коли твої пости вже лайкають солюшен архітектори з якогось Oracle – то це дуже допомагає відчувати себе людиною.
Власний бренд
По важливості я б це поставив на друге місце, але почати чомусь хочеться саме з цього.
Ваш блог – це ваш бренд.
Дуже часто, особливо вже за останні років 6-7, приходячи на співбесіду я чув “О! То ви адмін того самого RTFM? Круто – я там дуже багато для себе знайшов!”.
Ось це і є брендом – коли тебе впізнають, як спеціаліста.
Хтось виступає на конференціях – але я надто боюся публіки. А хтось тихенько пише собі бложег, де, звісно, теж публіка, і теж іноді ставлять “мінуси” – але це принаймні “не особисто”.
І от тут ми підходимо до другого пункту:
Власний розвиток
Я вже не представляю як можна виконувати якусь складну задачу, і не вести нотатки в чернетці блогу.
Бо, по-перше, коли ти пишеш – ти структуруєш інформацію, яку отримуєш. Тобі потрібно подати матеріал так, щоб він був зрозумілий і іншим, а для цього потрібно добре зуміти пов’язати всі “компоненти” посту у власній голові.
Це прям дуже, дуже допомагає краще зрозуміти щось нове, запам’ятати це, краще усвідомити всі ті “moving parts” нової системи.
І тут є ще один важливий момент. Колись (я навіть пам’ятаю цей пост – Apache: MPM – worker, prefork или event?, 2012 рік) я показав свій новий пост другу-сисадміну. Дуже прошарений чувак (привіт, Андрій!).
Після того, як він його прочитав, він сказав мені щось на кшталт “Ну, так, прикольно, але ось тут і ось тут відчувається, що ти не дуже шариш в темі”.
І саме відтоді я усвідомив, що, блін – треба копати. Не можна просто “на тяп-ляп” взяти, і написати. Треба писати вдумуючись, усвідомлюючи що і навіщо ти робиш.
А ця потреба призводить до того, що коли ти розбираєшся з новим матеріалом – ти вже не можеш скіпнути якусь не дуже зрозумілу частину – “А, потім розберусь, ілі взагалі фіг з нею”.
Ніт! Ти мусиш сісти, і розібратись. І саме це дуже допомогає у власному розвитку, як спеціаліста, бо потім, коли на якійсь співбесіді тебе питають по якійсь темі – то ти можеш розкрити якісь деталі цієї теми, показати, що ти дійсно розбираєшся в темі, а не просто “навкоси” прочитав документацію, скопіпастив команду, запустив сервіс, і вважаєш, що ти його знаєш.
Взагалі, уважність до деталей, уміння розібратись з тим, “а що там під капотом” дуже допомогає в роботі. Бо тільки знаючи ЯК система працює, що відбувається у неї всередині, ти можеш зрозуміти куди копати, щоб потім цю систему пофіксити.
Повертаючись трохи назад до “усвідомлюючи що і навіщо ти робиш” – така звичка у веденні блогу вже стала звичкою і в роботі: не можна просто “взяти, зробити, і забити”. Ти маєш розуміти що і як ти зробив, бо, по-перше – тобі ж цю систему потім і підтримувати, по-друге – ти несеш відповідальність за те, що ти робиш. А враховуючи те, що наша, девопсів, робота дуже багато пов’язана з інфраструктурою, з цим “фундаментом” будь-якого проекту, з усіма його даними – то відчуття відповідальності тут вкрай необхідно.
Власна документація
Часто, прям дуже часто я повертаюсь до якихось старих постів, щоб подивитись що і як я робив. Це допомагає і під час сетапу якоїсь вже знайомої системи на новому проекті, і під час спроб зрозуміти що зламалось на поточному.
Навіть більше – у твоїх колег є доступ до інформації як саме ти піднімав якусь систему, і коли я був тім-лідом – то хлопці дуже часто використовували РТФМ, щоб розібратись з чимось, що я колись сетапив.
Ведення блогу, звісно, не значить, що можна не вести “локальну документацію” десь в проектному Confluence, але в своєму блозі ти можеш набагато краще описати що і навіщо ти робив, і чому зробив саме так, а не інакше.
Як вести свій блог?
Перше, і головне, над чим я замислювався раніше, коли цей блог тільки починався, це:
А про що, власне, писати?
І зараз тут відповідь та ж сама, що була тоді: про те, що ти робиш, з чим ти стикаєшся, або про те, що не дуже розумієш – а тобі треба розібратись.
Але саме, мабуть, важке, це саме створити структуру поста – зрозуміти про що саме писати, і як саме це висловити – що до чого відноситься, про що написати в першу чергу, про що в другу. Що винести окремою частиною – а про що достатньо буде написати пару речень.
Наприклад ось, як я “морально готувався” до написання цього поста:
Структура матеріалу
Навіть зараз, коли я пишу цей матеріал – я його перечитую, і розділяю на частини (під)заголовками, щоб вони якось логічно розбивали все те, про що тут написано.
Ось ще один приклад зі старих чернеток:
Ти починаєш писати про щось одне, а потім розумієш, що треба розказати і про щось ще, а потім ще про щось… І в результаті сидиш перед мільйоном вкладок, і кашею в голові. Але тобі все одно треба зібратись, і довести це до кінця, і подати так, щоб людина, яка буде читати цей матеріал, зрозуміла що ж насправді ти тут робиш.
Або ось такий приклад:
Тут на початку статті я накидую текст того, про що саме буде йти мова – бо це потім допомагає в голові тримати “нить повествования”.
Шарь в темі!
Так – треба добре розуміти, про що ти пишеш. Але й боятися писати (бо “що ж подумають люди?!?”) – теж не треба.
Ось ще приклад, як іноді виглядає процес написання деяких постів:
Бо знову ж таки – не можна “на тяп-ляп”, а треба розібратись.
Ще, мабуть, варто сказати про довжину постів: краще уникати “полотенець”. Краще розбити пост на декілька частин, і в кожній описати окремо якусь частину теми, ніж намагатись все впихнути в один пост.
Це допоможе і при написанні – бо все ж менша “каша в голові”, і при читанні, бо знов – менше каша в голові у читача.
Мови блогу
Якщо у вас є змога – то краще писати відразу на англійській.
По-перше – це круто.
По-друге – ви не обмежуєте себе читачами тільки з України.
По-третє – це дуже класна практика англійської.
Щодо правопису і помилок – головне, щоб вас зрозуміли. Крім того, можна скористатись плагінами типу Grammarly або LanguageTool, і навіть Google Translate.
Тут вибір вкрай широкий – від готових платформ типу Medium – до власного VPS з WordPress.
Я колись вибрав саме WordPress, і саме на виділеному VPS, щоб мати змогу отримати додатковий досвід з адміністрування Linux та всяких Apache/Nginx/PHP/MySQL – і це було дійсно дуже корисним.
Ще один момент, котрий треба мати на увазі: враховуйте той момент, що ведучи свій блог на платформах типу Medium ви фактично довіряєте всю інформацію йому, це такий собі “вендер-лок”, бо потім мігрувати з одної платформи на іншу може бути дуже боляче, тим більш, якщо у вас буде пару тисяч постів.
В принципі, теж стосується і якихось self-hosted платформ типу Jekyll – якщо розробники Jekyll його закинуть, або змінять цінову політику, то ви можете залишитись у “розбитого корита”.
І в цьому плані WordPress мене більш, ніж влаштовує, бо платформа слава богу існує вже багато років, а зараз навіть пропонує оформити реєстрацію на сто років наперед (The 100-Year Plan on WordPress) – оптимісти 🙂
Висновки
Чи є сенс у ведені свого блогу? Для мене відповідь очевидна, бо це дійсно дуже допомагає і в роботі, і у власному розвитку, і у кар’єрі.
Проте треба усвідомлювати, чи на це потрібен час. Деякі пости на РТФМ пишуться тиждень, а то й більше, а потім ще день-два для перекладу на англійську.
Також треба розуміти, що зовсім не відразу блог будуть читати, і що перші місяці у вас може бути пару випадкових відвідувачів на день.
Втім ті плюси, які дає ведення блогу, однозначно варті того, щоб витрачати на це свій час.
Навіть якщо вас ніхто не буде читати – ви навчитесь висловлювати свої думки, подавати матеріал, або прокачаєте свою англійську. У вас завжди буде ваша власна документація. Ви набагато краще будете розуміти те, що робили, коли писали якийсь новий пост.