А використовуючи ці Access/Secret ключі, ми можемо робити все, що дозволено інстансу, і, наприклад, якщо до інстансу підключено ІAМ роль з AdminAccess – ми зможемо отримати ці права.
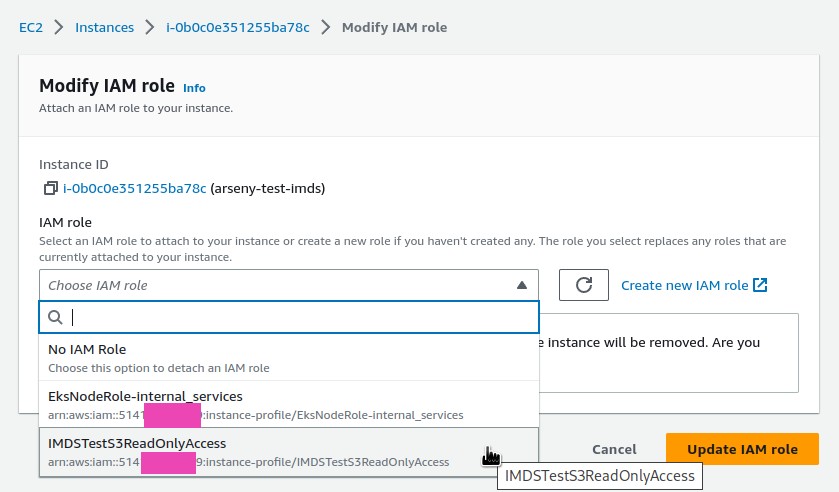
Перевіримо – додамо до інстансу роль з доступом до S3-бакетів:
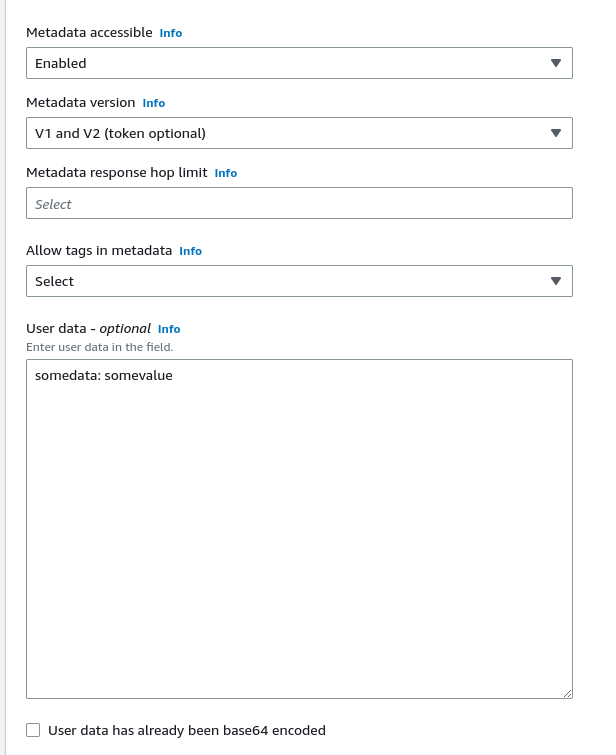
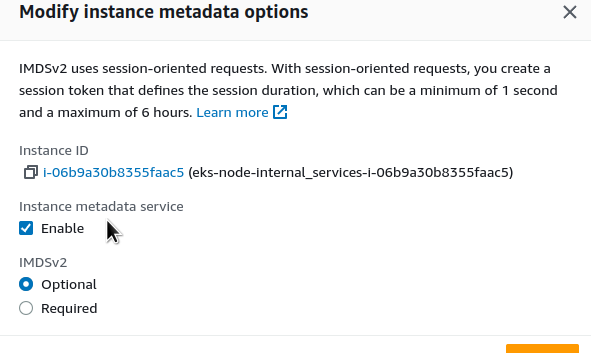
Якщо доступ все ж треба, то можемо відключити IMDS v1 та використовувати тільки IMDS v2 додавши обов’язкове використання токена за допомогою параметру --http-tokens:
Щоб запобігти цьому, додаємо параметр http-put-response-hop-limit зі значенням більше 1, так як виклик з контейнеру додає ще один хоп при проходженні запросу від клієнта до IMDS: перший, це запит з самого хосту, а другий – із контейнера на цьому хості:
Knative – система, яка дозволяє використовувати Serverless модель розробки у Kubernetes. По суті, Knative можна уявляти собі як ще один рівень абстракції, який дозволяє девелоперам не поринати в деталі деплойменту, скелінгу та нетворкінгу у “vanilla” Kubernetes.
Розробка самого Knative була розпочта у Google за співучастю таких компаній, як IBM, Pivotal, Red Hat, та загалом має близько 50 компаній-контрібьюторів.
What is: Serverless computing
Але спочатку, давайте розглянемо що таке Serverless взагалі.
Отже, Server та Less, це модель розробки, коли вам не потрібно перейматись менеджментом серверів – все це бере на себе cloud-провайдер, який надає вам послугу Serverless computing.
Тобто, зазвичай маємо в клауді:
bare-metal сервери десь в дата-центрі
на яких запускаються віртуальні машини
на яких ми запускаємо контейнери
Serverless computing поверх цих шарів додає ще один, де ви можете запускати вашу функцію, тобто мінімальний deployable-юніт, не займаючись ані металом, ані віртуалками, ані контейнерами. Ви просто маєте код, який в пару кліків можна запустити в клауді, а всі задачі по менеджменту інфрастуктури бере на себе клауд-провайдер. Ви не маєте турбуватись ані про хай авайлабіліті, ні про failt-tolerance, ні про бекапи, ні про секьюріті-патчі, ні про бекапи, ні про моніторинг і логування того, що відбувається на рівні інфрастуктури. Ба більше – на рівні мережі вам не треба думати про лоад-балансінг та те, як розподіляти навантаження по вашому сервісу – ви просто приймаєте запити на API Gateway або налаштовуєте триггер на event, який триггерить вашу Функцію. Тобто, cloud provider предоставляє вам послугу Function-as-a-Service, FaaS.
Все це чудово підходить у випадках, коли проект тільки-но стартує, і у девелоперів нема достатнього досвіду та/або часу, щоб піднімати сервери та кластери, тобто – скорочується Time-to-Market, або коли проект тільки тестує свою модель роботи системи взагалі, щоб швидко та безболісно реалізувати свою архітектуру.
“Запусти, та радуйся!”
Крім того, в FaaS інша модель оплати за сервіс – замість того, щоб платити за запущені сервери не зважаючи на те, чи виконують вони якусь роботу, чи просто знаходяться у idle стейті, при використанні FaaS ви платите тільки за той час, коли ваша функція виконується – Pay-for-Use Services.
Отже, ви:
створюєте функцію
налаштовуєте івенти, за якими ця функця буде запускатися (все ще нічого не платите)
при виникненні івента – він тригерить запуск функції (тут вже платите, допоки вона виконується)
після завершення роботи функції – вона “схлопується”, і біллінг за неї зупиняється до наступного запуску
Serverless модель буде ідеальною для рішень, які можуть працювати асінхронно та не потребують збереження стану, тобто являються Stateless системами.
Наприклад, це може бути функція в AWS, котора при створенні нового ЕС2 в аккаунті буде автоматично додавати теги до неї, накшталт AWS: Lambda – копирование тегов EC2 на EBS, часть 2 – создание Lambda-функции, коли ми використовуємо CloudWatch, який при створенні ЕС2 створює event, який триггерить функцю, передаючи їй аргументом ID EC2-інстансу, для дисків якого треба додати теги: функція запускається по цьому триггеру, додає теги, та зупинятється до наступного виклику.
Self-hosted serverless
Для використання Serverless моделі, необов’язково прив’язуватись до FaaS-провайдеру, натомість можна запустити self-hosted сервіс наприклад в своєму Kubernetes-кластері, і таким чином уникнути vendor lock.
Knative: наразі являється найбільш популярним (27%) та найбільше активно розвиваючимся проектом
Knative vs AWS Lambda
Але навіщо взагалі морочитись із запуском власного Serverless?
маєте можливість обійти ліміти, задані провайдером – див. AWS Lambda quotas
уникаєте vendor lock, тобто маєте можливість швидко переїхати до іншого провайдера або використовувати multi-cloud архітектуру для більшої надійності
маєте більше можливостей для моніторингу, трейсінгу та роботи з логами, бо в Kubernetes ми можемо все, на відміну від AWS Lambda та її прив’язки до CloudWatch
Доречі, Knative має змогу запускати функції, розроблені для AWS Labmda завдяки Knative Lambda Runtimes.
Компоненти та архітектура Knative
Knative має два основні компоненти – Knative Serving та Knative Eventing.
Для контролю мережи, роутів та ревізій Knative використовує Istio (хоча може бути і інший, див. Configuring the ingress gateway).
Knative Serving
Knative Serving відповідає за деплоймент контейнеру, оновлення, мережу та автоскейлінг.
Роботу Knative Serving можна відобразити наступним чином:
Трафик від клієнта приходить на Ingress, та в залежності від запиту відправляється на конкретний Knative Service, який являє собою Kubernetes Service та Kubernetes Deployment.
В залежності від конфігурації конкретного Knative Service, трафік може бути розподіленний між різними ревізіями, тобто версіями самого application.
KPA – Knative Pod Autoscaler, перевіряє кількість запитів та при необхідності додає нові поди в Deployment. Якщо трафіка нема – то KPA скейлить поди в нуль, а коли з’являються нові запити від клієнтів – запускає поди та скейлить їх в залежності від кількості запитів, які треба обробити.
Основні типи ресурсів:
Service: service.serving.knative.dev відповідає за весь цикл життя вашого workload (тобто, деплойменту та зв’язанних з ним ресурсів) – контролює створення залежних ресурсів, таких як роути, конфігурації, ревізії
Routes: route.serving.knative.dev відповідає за зв’язок між ендпоінтом та ревізіями
Configurations: configuration.serving.knative.dev відповідає за необхідний стан (desired state) деплойменту та створює revisions, на які буде потрапляти трафік
Revisions: revision.serving.knative.dev являє собою point-in-time snapshot коду та конфігурацї для кожної зміни у workload
Knative Eventing відповідає за асинхронний зв’язок розподіленних частин вашої системи. Замість того, щоб робити їх залежними друг від друга, вони можуть створювати events (event producers), які будуть отримані іншим компонентом системи (event consumers або subcsribers, або в термінології Knative – sinks), тобто реалізувати event-driven architecture.
Knative Eventing використовує стандартні запроси HTTP POST для відправлення та отримання таких івентів, які мають відповідати специфікації CloudEvents.
Knative Eventing дозволяє створити:
Source to Sink: Source (event producers) відправляє івент (чи таки евент?) до Sink, який його обробляє. В ролі Source може бути PingSource, APIServerSource (Kubernetes API івенти), Apache Kafka, GitHub, тощо
Channel and Subscription: створює event pipe, коли івент потрапивши до Channel відразу відправляється до subscriber
Broker and Trigger: являє собою event mesh – івент, потрапляє до Broker, який має одного чи більше Trigger, котрі має фільтри, в залежності від яких отримється від Брокера ці events
Знаходимо останню версію на сторінці релізів, вибираємо потрібну версію, в моєму випадку це буде kn-quickstart-linux-amd64, та завантажуємо у каталог, який є в $PATH:
$ kn plugin list
- kn-quickstart : /usr/local/bin/kn-quickstart
[/simterm]
Перевіряємо:
[simterm]
$ kn quickstart --help
Get up and running with a local Knative environment
Usage:
kn-quickstart [command]
...
[/simterm]
Quickstart плагін замість Istio встановить Kourier, а також створить Minikube кластер та встановить Knative Serving з sslip.io в ролі DNS і Knative Eventing.
Запускаємо:
[simterm]
$ kn quickstart minikube
Running Knative Quickstart using Minikube
Minikube version is: v1.29.0
...
🏄 Done! kubectl is now configured to use "knative" cluster and "default" namespace by default
To finish setting up networking for minikube, run the following command in a separate terminal window:
minikube tunnel --profile knative
The tunnel command must be running in a terminal window any time when using the knative quickstart environment.
Press the Enter key to continue
...
[/simterm]
В іншому терміналі створюємо minikube-тунель для доступу з хост-машини:
[simterm]
$ minikube tunnel --profile knative &
[/simterm]
Повертаємось до попереднього вікна:
[simterm]
...
🍿 Installing Knative Serving v1.8.5 ...
...
🕸 Installing Kourier networking layer v1.8.3 ...
...
🕸 Configuring Kourier for Minikube...
...
🔥 Installing Knative Eventing v1.8.8 ...
...
🚀 Knative install took: 3m23s
🎉 Now have some fun with Serverless and Event Driven Apps!
$ cat hello-world/func.py
from parliament import Context
from flask import Request
import json
# parse request body, json data or URL query parameters
def payload_print(req: Request) -> str:
...
[/simterm]
func run
func run дозволяє перевірити, як функція буде працювати без необхідності її деплою до Knative. Для цього Knative CLI створить образ за допомогою вашого container runtime, та запустить його. Див. Running a function.
Запускаємо, вказуючи шлях до коду:
[simterm]
$ kn func run --path hello-world/
🙌 Function image built: docker.io/setevoy/hello-world:latest
Function already built. Use --build to force a rebuild.
Function started on port 8080
[/simterm]
Перевіряємо Docker-контейнери:
[simterm]
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3869fa00ac51 setevoy/hello-world:latest "/cnb/process/web" 52 seconds ago Up 50 seconds 127.0.0.1:8080->8080/tcp sweet_vaughan
[/simterm]
Та пробуємо curl:
[simterm]
$ curl localhost:8080
{}
[/simterm]
В аутпуті func run:
[simterm]
Received request
GET http://localhost:8080/ localhost:8080
Host: localhost:8080
User-Agent: curl/8.0.1
Accept: */*
URL Query String:
{}
Received request
POST http://localhost:8080/ localhost:8080
Host: localhost:8080
User-Agent: Go-http-client/1.1
Content-Length: 25
Content-Type: application/json
Accept-Encoding: gzip
Request body:
{"message": "Hello World"}
[/simterm]
func deploy
func deploy створить образ, запушить його до registry, та задеплоїть у Kubernetes як Knative Service.
Якшо в коді зробити зміни, або просто виконати func build – то в Knative для функції буде створено нову ревізію, на яку буде переключений відповідний route:
[simterm]
$ kn func deploy --build --path hello-world/ --registry docker.io/setevoy
🙌 Function image built: docker.io/setevoy/hello-world:latest
✅ Function updated in namespace "default" and exposed at URL:
http://hello-world.default.10.106.17.160.sslip.io
[/simterm]
Перевіряємо под в default namespace:
[simterm]
$ kk get pod
NAME READY STATUS RESTARTS AGE
hello-world-00003-deployment-74dc7fcdd-7p6ql 2/2 Running 0 9s
$ kn service list
NAME URL LATEST AGE CONDITIONS READY REASON
hello-world http://hello-world.default.10.106.17.160.sslip.io hello-world-00003 4m41s 3 OK / 3 True
[/simterm]
Або можна за kubectl отримати ресурс kvcs:
[simterm]
$ kubectl get ksvc
NAME URL LATESTCREATED LATESTREADY READY REASON
hello http://hello.default.10.106.17.160.sslip.io hello-00001 hello-00001 True
hello-world http://hello-world.default.10.106.17.160.sslip.io hello-world-00003 hello-world-00003 True
І через хвилину відповідний Pod буде вбито, тобто Deployment заскейлиться в нуль:
[simterm]
$ kk get pod
NAME READY STATUS RESTARTS AGE
hello-world-00003-deployment-74dc7fcdd-7p6ql 2/2 Terminating 0 79s
[/simterm]
Knative Serving
Functions – чудово, але ж ми начебто інженери, і нам цікаво щось більш наближене до Kubernetes, тож давайте глянемо на Knative Service.
Як вже говорилось, Knative Service – це “повний workload”, включаючи Kubernetes Service, Kubernetes Deployment, Knative Pod Autoscaler та відповідні роути і конфіги. Див. Deploying a Knative Service.
Тут використаємо YAML маніфест (хоча можно і kn service create), в якому описано образ, з якого буде створено под:
KPA підтримує scale to zero, але не вміє в CPU-based autoscaling. Крім того, у KPA можемо використовувати concurrency або requests per second метрики для скейлінгу.
HPA ж навпаки – вміє CPU-based autoscaling (і багато іншого), але не знає як скейлити в нуль, а для concurrency або RPS йому потрібні додаткові налаштування (див. Kubernetes: HorizontalPodAutoscaler – обзор и примеры).
Ми вже маємо KPA, які були створені при func deploy та під час створення нашого Knative Service:
[simterm]
$ kk get kpa
NAME DESIREDSCALE ACTUALSCALE READY REASON
hello-00001 0 0 False NoTraffic
hello-world-00001 0 0 False NoTraffic
hello-world-00002 0 0 False NoTraffic
hello-world-00003 0 0 False NoTraffic
А в іншому вікні термінала глянемо на kubectl get pod --watch:
[simterm]
$ kk get pod -w
NAME READY STATUS RESTARTS AGE
hello-00001-deployment-5897f54974-9lxwl 0/2 ContainerCreating 0 1s
hello-00001-deployment-5897f54974-9lxwl 1/2 Running 0 2s
hello-00001-deployment-5897f54974-9lxwl 2/2 Running 0 2s
[/simterm]
“Воу, воно скейлиться!” 🙂
Knative Revisions
Knative завдяки Istio (або Kourier чи Kong) вміє розподіляти трафік між різними версіями (revisions) системи, що дозволяє виконувати blue/green або canary deployments.
В нашому Knative Service ми задавали змінну оточення $TARGET зі значенням World – давайте замінимо його на Knative:
[simterm]
$ kn service update hello --env TARGET=Knative
Updating Service 'hello' in namespace 'default':
0.025s The Configuration is still working to reflect the latest desired specification.
2.397s Traffic is not yet migrated to the latest revision.
2.441s Ingress has not yet been reconciled.
2.456s Waiting for load balancer to be ready
2.631s Ready to serve.
Service 'hello' updated to latest revision 'hello-00002' is available at URL:
http://hello.default.10.106.17.160.sslip.io
[/simterm]
Перевіряємо ревізії:
[simterm]
$ kn revision list
NAME SERVICE TRAFFIC TAGS GENERATION AGE CONDITIONS READY REASON
hello-00002 hello 100% 2 20s 4 OK / 4 True
hello-00001 hello 1 24m 3 OK / 4 True
Knative Eventing – це набор сервісів та ресурсів, які дозволяють нам побудувати event-driven applications, коли Функції викликаються якимось евентом. Для цього можемо підключити sources, які ці події будуть генерувати, та sinks, тобто “споживачі”, які на ці події реагують.
У подальшій документації по Quickstart є приклад роботи з Broker та Trigger за допомогою cloudevents-player, але як на мене, там не дуже-то демонструються можливості Knative Eventing, тож виберемо трошки the hard way.
Як вже писалось, Knative підтримує три типи реалізації event-driven системи – Source to Sink, Channel and Subscription та Broker and Trigger.
Source to Sink
Source to Sink – сама базова модель, створюється за допомогою ресурсів Source та Sink, де Source – це Event Producer, а Sink – ресурс, який можна визвати або адресувати йому повідомлення.
Серед прикладів Sources – APIServerSource (Kubernetes API server), GitHub та GitLab, RabbitMQ та інші, див. Event sources.
В ролі Sink може бути Knative Service, Channel або Broker (тобто, “раковина”, куди ми “зливаємо” наші івенти). Хоча при побудові саме Source to Sink моделі, в ролі sink має бути саме Knative Service – про Channel та Broker поговоримо далі.
Channel and Subscription
Channel та Subscription являє собой even pipe (як pipe в bash, коли ми через | перенаправляємо stdout одніє програми у stdin іншої).
Тут Channel – це інтерфейс між event source та subscriber цього каналу. При цьому channel являє собою тип sink, так як він може зберігати івенти, щоб потім віддати їх своїм subscribers.
Knative підтримує три типи каналів:
In-memory Channel
Apache Kafka Channel
Google Cloud Platform Pub-sub Channel
In-memory Channel – тип за-замовченням, і не має змоги відновити івенти або зберігати їх постійно – для цього використовуйте типи накшталт Apache Kafka Channel.
Далі, Subscription – відповідає за з’єднання Channel з відповідним Knative Service – Сервіси підписуються на Канал через Subscription, та починають отримувати з Каналу повідомлення.
Broker and Trigger
Broker та Trigger являють собою event mesh модель, дозволяючи передавати події необхідним сервісам.
Тут Broker збирає події з різних sources предоставляючи вхідний шлюз дня них, а Trigger по суті є Subscription, але з можливістью фільтрування того, які саме івенти він буде отримувати.
Приклад створення Source to Sink
Створимо Knative Service, який буде нашим sink, тобто отримувачем:
[simterm]
$ kn service create knative-hello --concurrency-target=1 --image=quay.io/redhattraining/kbe-knative-hello:0.0.1
...
Service 'knative-hello' created to latest revision 'knative-hello-00001' is available at URL:
http://knative-hello.default.10.106.17.160.sslip.io
[/simterm]
concurrency-target тут вказує, що наш Service може обробляти тільки один запит одночасно. Якщо їх буде більше – то відповідний KPA створить додаткові поди.
Створюємо Event Source, наприклад – PingSource, який кожну хвилину буде слати повідомлення в вигляді JSON до нашого knative-hello Service:
[simterm]
$ kn source ping create knative-hello-ping-source --schedule "* * * * *" --data '{"message": "Hello from KBE!"}' --sink ksvc:knative-hello
Ping source 'knative-hello-ping-source' created in namespace 'default'.
[/simterm]
Перевіряємо:
[simterm]
$ kn source list
NAME TYPE RESOURCE SINK READY
knative-hello-ping-source PingSource pingsources.sources.knative.dev ksvc:knative-hello True
[/simterm]
І глянемо логи поду з Service knative-hello:
[simterm]
$ kubectl logs -f knative-hello-00001-deployment-864756c67d-sk76m
...
2023-04-06 10:23:00,329 INFO [eventing-hello] (executor-thread-1) ce-id=bd1093a9-9ab7-4b79-8aef-8f238c29c764
2023-04-06 10:23:00,331 INFO [eventing-hello] (executor-thread-1) ce-source=/apis/v1/namespaces/default/pingsources/knative-hello-ping-source
2023-04-06 10:23:00,331 INFO [eventing-hello] (executor-thread-1) ce-specversion=1.0
2023-04-06 10:23:00,331 INFO [eventing-hello] (executor-thread-1) ce-time=2023-04-06T10:23:00.320053265Z
2023-04-06 10:23:00,332 INFO [eventing-hello] (executor-thread-1) ce-type=dev.knative.sources.ping
2023-04-06 10:23:00,332 INFO [eventing-hello] (executor-thread-1) content-type=null
2023-04-06 10:23:00,332 INFO [eventing-hello] (executor-thread-1) content-length=30
2023-04-06 10:23:00,333 INFO [eventing-hello] (executor-thread-1) POST:{"message": "Hello from KBE!"}
[/simterm]
Наразі це все, що хотілося дізнатись про Knative.
Виглядає в цілому досить цікаво, але можуть бути з автоскейлінгом та Istio, бо Istio сам по собі може бути тим ще гемороєм. Хоча на поточному проекті Knative у нас вже в production, та особливих проблем з ним поки не бачили.
Запустились ми в production, і вилізла дуже неприємна бага – при git операціях clone/pull/push запит іноді зависав на 1-2 хвилини.
Виглядало це як якась “плавуюча” бага, тобто 5 раз могло склонити нормально, а потім раз зависає.
Проблеми
gitlab-shell timeouts
Наприклад – раз нормально:
[simterm]
$ time git clone [email protected]:example/platform/tables-api.git
Cloning into 'tables-api'...
...
real 0m1.380s
[/simterm]
А потім clone того ж самого репозиторію – 2 хвилини:
[simterm]
$ time git clone [email protected]:example/platform/tables-api.git
Cloning into 'tables-api'...
...
real 2m10.497s
[/simterm]
І це не виглядає, як якась мережева проблема, а скоріш щось з SSH на етапі встановлення сесії та обміну ключами.
На щастя, не став глибокого копатись, бо спершу вирішив зафіксити проблему з метриками, щоб мати змогу в моніторингу побачити що взагалі коїться з GitLab Shell.
Це виглядало так: відкриваємо порт 9122 (див. values):
[simterm]
$ kk -n gitlab-cluster-prod port-forward gitlab-cluster-prod-gitlab-shell-744675c985-5t8wn 9122
[/simterm]
Пробуємо curl:
[simterm]
$ curl localhost:9122/metrics
curl: (52) Empty reply from server
[/simterm]
І под нам каже, що “Connection refused”:
[simterm]
...
Handling connection for 9122
E0315 12:40:43.712508 826225 portforward.go:407] an error occurred forwarding 9122 -> 9122: error forwarding port 9122 to pod 51856f9224907d4c1380783e46b13069ef5322ae1f286d4301f90a2ed60483c0, uid : exit status 1: 2023/03/15 10:40:43 socat[28712] E connect(5, AF=2 127.0.0.1:9122, 16): Connection refused
E0315 12:40:43.713039 826225 portforward.go:233] lost connection to pod
[/simterm]
Рішення
Як виявилось, GitLab Shell підтримує два SSH-демони – openssh та gitlab-sshd, при чьому саме openssh являється дефолтним значенням, див. values:
...## Allow to select ssh daemon that would be executed inside container
## Possible values: openssh, gitlab-sshd
sshDaemon: openssh
...
$ curl localhost:9122/metrics
# HELP gitlab_build_info Current build info for this GitLab Service
# TYPE gitlab_build_info gauge
gitlab_build_info{built="20230309.174623",version="v14.17.0"} 1
# HELP gitlab_shell_gitaly_connections_total Number of Gitaly connections that have been established
# TYPE gitlab_shell_gitaly_connections_total counter
gitlab_shell_gitaly_connections_total{status="ok"} 2
...
[/simterm]
Проблема з таймаутами теж вирішилась – тепер результат не більше 1 секунди – real 0m0.846s.
У нас в Kubernetes кластері розгорнутий свій Prometehus за допомогою Kube Prometheus Stack (далі – KPS) та його Prometheus Operator.
GitLab вміє запускати власний Prometheus, якому відразу налаштовує збір метрик з усіх подів та сервісів, які мають аннотацію gitlab.com/prometheus_scrape=true.
Крім того, всі поди та сервіси мають аннотацію prometheus.io/scrape=true, але KPS не вміє працювати з аннотаціями, див. документацію:
The prometheus operator does not support annotation-based discovery of services
Тож маємо два варіанти збору метрик:
вимкнути Promethus самого GitLab, та через ServiceMonitor-и збирати метрики з компонентів відразу в KPS Prometheus – але тоді всім компонентам доведеться включати ServiceMonitor (і не всі їх мають, тож деякі доведеться додавати вручну через окремі маніфести)
або ми можемо лишити “вбудований” Prometehus, в якому вже все налаштовано, і через Prometheus federation просто збирати потрібні нам метрики до KPS Prometheus
В другому випадку ми будемо витрачати зайві ресурси на роботу додаткового Prometheus, але знімаємо з себе необхідність в додатковій конфігурації чартів самого GitLab та Prometheus з KPS.
Спочатку, перевіримо налаштування Prometheus самого GitLab – чи є метрики і які є джоби.
Знаходимо Prometheus Service:
[simterm]
$ kk -n gitlab-cluster-prod get svc gitlab-cluster-prod-prometheus-server
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
gitlab-cluster-prod-prometheus-server ClusterIP 172.20.194.14 <none> 80/TCP 27d
[/simterm]
Відкриваємо до нього доступ:
[simterm]
$ kk -n gitlab-cluster-prod port-forward svc/gitlab-cluster-prod-prometheus-server 9090:80
[/simterm]
Заходимо в браузері на http://localhost:9090, переходимо в Status > Configuration, та дивимось які там є джоби:
Далі ще є job_name: kubernetes-service-endpoints та job_name: kubernetes-services, але ніяких метрик по ним зараз нема:
Джоби prometheus та kubernetes-apiservers нам не потрібні, бо це лише ганяти зайві метрики в KPS Prometheus: в job=prometheus метрики по самому GitLab Prometheus, в job=kubernetes-apiservers – дані по Kubernetes API, які Prometheus KPS збирає і так.
Перевіримо, що метрики в GitLab Prometheus взагалі є. Візьмемо, наприклад, метрику sidekiq_concurrency, див. GitLab Prometheus metrics:
Далі налаштовуємо федерацію – в values Kube Prometheus Stack в блоці prometheus додаємо additionalScrapeConfigs, де вказуємо ім’я джоби, шлях для federation, в params – задаємо match, за яким з GitLab Prometheus вибираємо тільки потрібні нам метрики, а в static_configs задаємо таргет – GitLab Prometheus Service URL:
Деплоїмо, та перевіряємо Targets в KPS Prometheus:
І за хвилину-дві перевіряємо чи пішли метрики до Prometheus KPS:
Метрики GitLab
Тепер, як маємо метрики в нашому Prometheus, давайте поглянемо що взагалі можно і треба моніторити в GitLab.
По-перше – це ресурси Kubernetes, але про них поговоримо, коли будемо створювати власний Grafana dashboard.
Але ще у нас є компоненти самого GitLab, які мають власні метрики:
PostgreSQL: моніториться власним експортером
KeyDB/Redis: моніториться власним експортером
Gitaly: віддає метрики сам, включені по дефолту, див. values
Runner: віддає метрики сам, виключені по дефолту, див. values
Shell: віддає метрики сам, виключені по дефолту, див. values
Registry: віддає метрики сам, виключені по дефолту, див. values
Sidekiq: віддає метрики сам, включені по дефолту, див. values
Toolbox && backups: нічого по метрикам, див. values
Webservice: віддає метрики сам, включені по дефолту, див. values
додатково метрики від workhorse, виключені по дефолту, див. values
Також є GitLab Exporter з власними метриками – values.
На сторінці GitLab Prometheus metrics є багато метрик, але не всі, тож має сенс пройтись руками по подах, та переглянути метрики прямо з сервісів.
Наприклад, у Gitaly є метрика gitaly_authentications_total, якої нема в документації.
Відкриваємо доступ до порту з метриками (є у його values):
[simterm]
$ kk -n gitlab-cluster-prod port-forward gitlab-cluster-prod-gitaly-0 9236:9236
[/simterm]
І перевіряємо їх:
[simterm]
$ curl localhost:9236/metrics
# HELP gitaly_authentications_total Counts of of Gitaly request authentication attempts
# TYPE gitaly_authentications_total counter
gitaly_authentications_total{enforced="true",status="ok"} 5511
...
[/simterm]
Далі – список цікавих (на мій власний погляд) метрик з компонентів, які можна буде потім використати для побудови Grafana dashboards per GitLab service та алертів.
Gitaly
Тут метрики:
gitaly_authentications_total: Counts of of Gitaly request authentication attempts
gitaly_command_signals_received_total: Sum of signals received while shelling out
gitaly_connections_total: Total number of connections to Gitaly
gitaly_git_protocol_requests_total: Counter of Git protocol requests
gitaly_gitlab_api_latency_seconds_bucket: Latency between posting to GitLab’s `/internal/` APIs and receiving a response
gitaly_service_client_requests_total: Counter of client requests received by client, call_site, auth version, response code and deadline_type
gitaly_supervisor_health_checks_total: Count of Gitaly supervisor health checks
grpc_server_handled_total: Total number of RPCs completed on the server, regardless of success or failure
grpc_server_handling_seconds_bucket: Histogram of response latency (seconds) of gRPC that had been application-level handled by the server
Runner
Тут метрики:
gitlab_runner_api_request_statuses_total: The total number of api requests, partitioned by runner, endpoint and status
gitlab_runner_concurrent: The current value of concurrent setting
gitlab_runner_errors_total: The number of caught errors
gitlab_runner_jobs: The current number of running builds
gitlab_runner_limit: The current value of concurrent setting
gitlab_runner_request_concurrency: The current number of concurrent requests for a new job
gitlab_runner_request_concurrency_exceeded_total: Count of excess requests above the configured request_concurrency limit
Shell
Тут чомусь не працює ендпоінт метрик, не став копатись:
[simterm]
$ kk -n gitlab-cluster-prod port-forward gitlab-cluster-prod-gitlab-shell-744675c985-5t8wn 9122:9122
Forwarding from 127.0.0.1:9122 -> 9122
Forwarding from [::1]:9122 -> 9122
Handling connection for 9122
E0311 09:36:35.695971 3842548 portforward.go:407] an error occurred forwarding 9122 -> 9122: error forwarding port 9122 to pod 51856f9224907d4c1380783e46b13069ef5322ae1f286d4301f90a2ed60483c0, uid : exit status 1: 2023/03/11 07:36:35 socat[10867] E connect(5, AF=2 127.0.0.1:9122, 16): Connection refused
[/simterm]
Registry
Тут метрики:
registry_http_in_flight_requests: A gauge of requests currently being served by the http server
registry_http_request_duration_seconds_bucket: A histogram of latencies for requests to the http server
registry_http_requests_total: A counter for requests to the http server
registry_storage_action_seconds_bucket: The number of seconds that the storage action takes
registry_storage_rate_limit_total: A counter of requests to the storage driver that hit a rate limit
Sidekiq
Тут метрики:
Jobs:
sidekiq_jobs_cpu_seconds: Seconds of CPU time to run Sidekiq job
sidekiq_jobs_db_seconds: Seconds of DB time to run Sidekiq job
sidekiq_jobs_gitaly_seconds: Seconds of Gitaly time to run Sidekiq job
sidekiq_jobs_queue_duration_seconds: Duration in seconds that a Sidekiq job was queued before being executed
sidekiq_jobs_failed_total: Sidekiq jobs failed
sidekiq_jobs_retried_total: Sidekiq jobs retried
sidekiq_jobs_interrupted_total: Sidekiq jobs interrupted
sidekiq_jobs_dead_total: Sidekiq dead jobs (jobs that have run out of retries)
sidekiq_running_jobs: Number of Sidekiq jobs running
gitlab_cache_operations_total: Cache operations by controller or action
Misc:
user_session_logins_total: Counter of how many users have logged in since GitLab was started or restarted
Workhorse
Про сервіс: GitLab Workhorse is a smart reverse proxy for GitLab, див. GitLab Workhorse.
Тут метрики:
gitlab_workhorse_gitaly_connections_total: Number of Gitaly connections that have been established
gitlab_workhorse_http_in_flight_requests: A gauge of requests currently being served by the http server
gitlab_workhorse_http_request_duration_seconds_bucket: A histogram of latencies for requests to the http server
gitlab_workhorse_http_requests_total: A counter for requests to the http server
gitlab_workhorse_internal_api_failure_response_bytes: How many bytes have been returned by upstream GitLab in API failure/rejection response bodies
gitlab_workhorse_internal_api_requests: How many internal API requests have been completed by gitlab-workhorse, partitioned by status code and HTTP method
gitlab_workhorse_object_storage_upload_requests: How many object storage requests have been processed
gitlab_workhorse_object_storage_upload_time_bucket: How long it took to upload objects
gitlab_workhorse_send_url_requests: How many send URL requests have been processed
Ух… Багацько.
Але було цікаво і корисно, щоб більш-менш поринути в те, що взагалі відбувається всередині GitLab кластеру.
Grafana GitLab Overview dashboard
Ну і останнім – побудуємо власну дашборду для GitLab, хоча є багато готових ось тут>>>, можна з них брати приклади запитів та панелей.
Для самих компонентів GitLab мабуть потім можна буде створити окрему, а поки що хочеться на одному екрані бачити що відбувається з подами, воркер-нодами Kubernetes, та загальную інформацю про сервіси GitLab і їхній статус.
Що нам цікаво?
З ресурсів Kubernetes:
pods: рестарти, pendings
PVC: зайнято/вільно місця на дисках, IOPS
CPU/Memory по подах та CPU throttling (якби у подів були ліміти, по-дефолту нема)
network: in/out bandwich, errors rate
Крім того – хотілося бі мати перед очима статус компонентів GitLab, дані по базі даних, Redis та якусь статистику по HTTP/Git/SSH.
Я вже трохи маю досвід з побудування подібних “обзорних” дашборд, тож в принципі маю уяву як воно буде виглядати, але інколи має сенс набросати схему розміщення блоків олівцем на папері, а потім вже будувати саму борду.
Чисто для мене – бажано, щоб всі дані були на одному екрані/моніторі – потім зручно відразу бачити все, що треба.
Колись давно, коли ще ходив до офісу, це виглядало так – load testing нашого першого Kubernetes-кластеру на колишній роботі:
Поїхали.
Variables
Щоб мати змогу вивести інформацю по конкретному компоненту кластера – додамо змінну component.
Тут трохи цікавіше: треба порахувати всі Kubernetes Worker Nodes, на яких є поди GitLab, але метрики від самого Cluster AutoScaler на мають лейбли типу “namespace”, тож використаємо метрику kube_pod_info, яка має лейбли namespace та node, і по сумі node дізнаємось кількість EC2 інстансів:
count(count(kube_pod_info{namespace="gitlab-cluster-prod", pod!~"logical-backup.+"}) by (node))
Для Max nodes довелося значення задавати вручну, але навряд чи воно буде часто змінюватись.
В Thresholds задаємо значення, коли треба напрягатись, нехай буде 10, і включаємо Show thresholds = As filled regions and lines, щоб бачити його на графіку:
Результат:
І все разом виглядає так:
CPU та Memory by Pod
CPU by Pod
Рахуємо % від доступного CPU по кількості ядер. Тут цю кількість теж задав руками, знаючи тип ЕС2, але можна пошукати метрики типу “cores allocatable”:
sum(rate(container_cpu_usage_seconds_total{namespace="gitlab-cluster-prod", container!="POD",pod!="", image=~"", pod=~"$component.*"}[5m]) / 2 * 100) by (pod)
Не пам’ятаю вже, звідки сам запит – але результат у kubectl top pod підтверджує дані – перевіримо на поді з Sidekiq:
І top:
121 millicpu з 2000 доступних (2 ядра) це:
[simterm]
>>> 121/2000*100
6.05
[/simterm]
На графіку 5,43 – виглядає ок.
В Legend переносимо список вправо, та включаємо Values = Last, щоб сортувати по значеннях:
Результат:
Memory by Pod
Тут рахуємо по container_memory_working_set_bytes, налаштування таблиці аналогічні:
Доречі, можна було вивести % від доступної пам’яті на ноді, але нехай краще буде в “чистих” байтах.
Або можна додати Threshold с максимум 17179869184 байт – але тоді не так добре буде видно графікі з подів.
І разом маємо таке:
Статистка по дисках
Gitaly PVC used space
Що хотілося б по-перше – бачити вільне місце на диску Gitaly, де будуть всі репозиторії, та загальну статистку по записам-читанню на дисках.
Запити брав з якоїсь дефолтної дашборди з комплекту Kube Prometheus Stack.
Для отримання % зайнятого місця на Gitaly використовуємо запит:
Тут рахуємо кількість байт в секунду на кожному поді – container_network_receive_bytes_total та container_network_transmit_bytes_total:
Network Packets/second
Аналогічно, тільки з метриками container_network_receive_packets_total/container_network_transmit_packets_total:
Не впевнений, що воно буде корисно, але поки що нехай буде.
Webservice HTTP statistic
Для загальної картини – додамо трохи даних по HTTP-запитам на Webservice.
HTTP requests/second
Використаємо метрику http_requests_total:
Додамо Override, щоб змінити колір для даних по 4хх та 5хх кодам:
Webservice HTTP request duration
Тут можна було б побудувати Heatmap використовуєчи http_request_duration_seconds_bucket, але як на мене – то звичайний графік по типам запитів буде кращий:
sum(increase(http_request_duration_seconds_sum{kubernetes_namespace="gitlab-cluster-prod"}[5m])) by (method)
/
sum(increase(http_request_duration_seconds_count{kubernetes_namespace="gitlab-cluster-prod"}[5m])) by (method)
Але можна й Heatmap:
sum(increase(http_request_duration_seconds_bucket[10m])) by (le)
Взагалі, по метрикам з типом Histogram можна робити досить багато цікавого, хоча я якось не користувався ними.
Ну й на останнє – трохи даних по компонентам самого GitLab. В процессі роботи вже щось точно буду міняти, бо поки він не сильно використовується – то й не дуже зрозуміло, що саме заслуговує уваги.
Але з того, що поки приходить в голову – це Sidekiq та його джоби, Redis, PostgreSQL, GitLab Runner.
sum(rate(gitlab_database_transaction_seconds_sum[5m])) by (kubernetes_pod_name) / sum(rate(gitlab_database_transaction_seconds_count[5m])) by (kubernetes_pod_name)
User Sessions
Запит:
sum(user_session_logins_total)
Git/SSH failed connections/second – by Grafana Loki
А тут використаємо значення, отримані з Loki – рейт помилок “kex_exchange_identification: Connection closed by remote host“, в Loki це виглядає так:
Ще дуже хотілося написати пост про міграцію даних з GitLab Cloud до self-hosted, але немає часу, та й пройшло це майже повз мене – автоматизували через GitLab API та скрипт силами девелоперів.
Проте, я таки трохи інвестигейтив це питання, і в двох словах – “дефолтна” міграція, тобто direct transfer (recommended) не підтягувала проекти, тож використали depricated, але робочий варіант з file export, тобто коли для групи або проекту у Cloud-версії робиться експорт у файл, а потім імпортується вже у self-hosted.
Ну і поки девелопери працюють над допилюванням міграції – я займуся тествування та налаштування backups/restore на впипадок, якщо (коли?) “щось піде не так” (с).
Отже – подивимось, як зробити бекап вручну, як налаштувати запуск створення бекапів за розкладом, та спробуємо відновити дані. Забігаючи наперед – відновити вдалось, але з PostgreSQL довелося трошки повозитися.
GitLab Toolbox
“Recommended way” – це використовувати Toolbox pod, в якому по cron можна створювати бекапи, та при потребі – відновити дані.
Под Toolbox має декілька корисних утіліт:
gitlab-rails: дозволяє виконувати з консолі всякі адміністративні задачі в GitLab, пов’язані з траблшутінгом або для отримання якихось даних
gitlab-rake: теж для консолі, теж для адміністративних задач, в тому числі по бекапу та відновленню
backup-utility: ну й та сама утіліта, яку ми будемо використовувати для створення повного бекапу GitLab та всіх його залежностей типу бази даних
Так як у нас вже налаштовано ServiceAccount з AWS IAM роллю, яка дозволяє доступ до S3, то замість s3cmd, до якоїх потрібен окремий конфіг, спробуємо AWS CLI.
Поки відкрите питання по розміру диску для самого Toolbox, бо бекап у вигляді TAR-архіву спочатку створюється у поді, а потім вигружається до S3-бакету. Поки зилишимо, як є, але маємо на увазі на майбутнє – якщо що, то можна буде збільшити диск для Toolbox, там це не страшно робити, бо ніяких даних він не сберігає (тобто под з Toolbox є stateless-сервісом).
UPD – схоже, що можна додати окремий диск через values та gitlab.toolbox.backups.persistence.
UPD-2: А ось знайшлось про розмір диску у документації по restore:
GitLab repositories data
Найбільше цікавить, звісно, бекап репозиторіїв.
Самі репозиторії зберігаються у Kubernetes PersistenVolume, який підключено до поду з Gitaly:
[simterm]
$ kk -n gitlab-cluster-prod describe pod gitlab-cluster-prod-gitaly-0
...
Containers:
gitaly:
...
Mounts:
...
/home/git/repositories from repo-data (rw)
...
[/simterm]
В якому і є весь наш код:
[simterm]
$ kk -n gitlab-cluster-prod exec -ti gitlab-cluster-prod-gitaly-0 -- ls -l /home/git/repositories
Defaulted container "gitaly" out of: gitaly, certificates (init), configure (init)
total 28
drwxrwsr-x 3 git git 4096 Feb 28 17:10 +gitaly
drwxrws--- 19 git git 4096 Feb 28 16:04 @hashed
drwxrwsr-x 4 git git 4096 Feb 24 11:39 gitlab.com-import
drwxrws--- 2 root git 16384 Feb 21 13:31 lost+found
Теперь додамо запуск створення бекапу за роскладом, наприклад – о 6 ранку по Києву, що наче як виходить 23.00 у США, бо наша команда є і там, і там, і навряд чи хтось буде пушити в GitLab в ці години.
Я тут навмисно вписав дефолтні resources.requests та persistence, щоб потім легше було їх змінити.
У objectStorage.config.secret спробуємо той самий сікрет, який ми створювали для appConfig.object_store, бо Toolbox його вимагає.
І в extraArgs: "--s3tool awscli" задаємо використання AWS CLI.
Деплоїмо, переверіяємо чи додалась кронджоба:
[simterm]
$ kk -n gitlab-cluster-prod get cj
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
gitlab-cluster-prod-toolbox-backup 0 13 * * * False 0 <none> 6s
logical-backup-devops-gitlab-cluster-psql 0 1 * * * False 0 11h 19d
[/simterm]
І чекаємо на 13.00 – спрацює, чи ні?
І такі да – о 13.00 з’явився под gitlab-cluster-prod-toolbox-backup-27961260-x4n45, в якому почав виконуватись бекап:
Потім створимо бекап, потім видалимо тестові дані, і спробуємо запустити рестор.
Тестовий проект
Створюємо проект:
Побудемо трошки рубістами:
Тестова PostgreSQL
Далі, логінимось до PostgreSQL.
В нас, нагадаю, PostgreSQL Operator (давно в чернетках пост по ньому, якось закінчу).
Знаходимо пароль – беремо із сікрету postgres.devops-gitlab-cluster-psql.credentials.postgresql.acid.zalan.do, виводимо в json, з jq отримаємо значення поля .data.password, та декодимо з base64:
[simterm]
$ kk -n gitlab-cluster-prod get secret postgres.devops-gitlab-cluster-psql.credentials.postgresql.acid.zalan.do -o json | jq -r '.data.password' | base64 -d
IcL***dPP
[/simterm]
Знаходимо master-інстанс:
[simterm]
$ kk -n gitlab-cluster-prod get pod -l application=spilo -L spilo-role
NAME READY STATUS RESTARTS AGE SPILO-ROLE
devops-gitlab-cluster-psql-0 2/2 Running 0 21h replica
devops-gitlab-cluster-psql-1 2/2 Running 0 6d23h replica
devops-gitlab-cluster-psql-2 2/2 Running 0 11d master
[/simterm]
Відкриваємо доступ до поду:
[simterm]
$ kk -n gitlab-cluster-prod port-forward devops-gitlab-cluster-psql-2 5432:5432
Forwarding from 127.0.0.1:5432 -> 5432
Forwarding from [::1]:5432 -> 5432
[/simterm]
Логінимось в кластер з юзером postgres:
[simterm]
$ psql -h localhost -U postgres -d gitlabhq_production
Password for user postgres:
psql (15.1, server 14.4 (Ubuntu 14.4-1.pgdg18.04+1))
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off)
Type "help" for help.
gitlabhq_production=#
[/simterm]
Створюємо табличку в базі gitlabhq_production:
[simterm]
gitlabhq_production=# CREATE TABLE test_restore(key_id serial PRIMARY KEY, key_name VARCHAR (255) UNIQUE NOT NULL);
CREATE TABLE
[/simterm]
Перевіряємо, що вона є:
[simterm]
gitlabhq_production-# \dt test_restore
List of relations
Schema | Name | Type | Owner
--------+--------------+-------+----------
public | test_restore | table | postgres
(1 row)
[/simterm]
Переходимо до поду з Toolbox, та запускаємо бекап:
[simterm]
git@gitlab-cluster-prod-toolbox-6fc9c7fc89-8jws7:/$ backup-utility --s3tool awscli
2023-03-01 14:34:22 UTC -- Dumping main_database ...
Dumping PostgreSQL database gitlabhq_production ... pg_dump: error: query failed: ERROR: permission denied for table test_restore
pg_dump: detail: Query was: LOCK TABLE public.test_restore IN ACCESS SHARE MODE
[FAILED]
2023-03-01 14:34:22 UTC -- Dumping main_database failed: Failed to create compressed file '/srv/gitlab/tmp/backups/db/database.sql.gz' when trying to backup the main database:
- host: 'devops-gitlab-cluster-psql'
- port: '5432'
- database: 'gitlabhq_production'
...
gitlabhq_production=# GRANT USAGE, SELECT ON SEQUENCE test_restore_key_id_seq TO PUBLIC;
GRANT
[/simterm]
Тепер пішло:
[simterm]
git@gitlab-cluster-prod-toolbox-6fc9c7fc89-8jws7:/$ backup-utility --s3tool awscli
2023-03-01 14:40:38 UTC -- Dumping main_database ...
Dumping PostgreSQL database gitlabhq_production ... pg_dump: warning: could not find where to insert IF EXISTS in statement "-- *not* dropping schema, since initdb creates it
"
[DONE]
2023-03-01 14:40:43 UTC -- Dumping main_database ... done
...
Packing up backup tar
[DONE] Backup can be found at s3://or-gitlab-backups-prod/1677681628_2023_03_01_15.8.1-ee_gitlab_backup.tar
[/simterm]
Добре.
Видалення даних
Тепер – видаляємо таблицю з бази:
[simterm]
gitlabhq_production=# DROP TABLE test_restore;
DROP TABLE
gitlabhq_production=# \dt test_restore
Did not find any relation named "test_restore".
[/simterm]
І видаляємо тестовий проект з його репозиторієм:
Відновлення даних з бекапу
Be sure to stop Puma, Sidekiq, and any other process
Ну і пробуємо – визиваємо той самий backup-utility з опцією --restore:
[simterm]
git@gitlab-cluster-prod-toolbox-6fc9c7fc89-8jws7:/$ backup-utility --s3tool awscli --restore -t 1677681628_2023_03_01_15.8.1-ee
Unpacking backup
2023-03-01 14:48:06 UTC -- Restoring main_database ...
2023-03-01 14:48:06 UTC -- Be sure to stop Puma, Sidekiq, and any other process that
connects to the database before proceeding. For Omnibus
installs, see the following link for more information:
https://docs.gitlab.com/ee/raketasks/backup_restore.html#restore-for-omnibus-gitlab-installations
Before restoring the database, we will remove all existing
tables to avoid future upgrade problems. Be aware that if you have
custom tables in the GitLab database these tables and all data will be
removed.
[/simterm]
Ага… А в документації про це не говориться… Хоча в цілому варто переглянути Back up and restore GitLab – там ще багато чого цікавого.
Добре – згадаємо, що у нас використовує Postgres – див. Інфраструктура:
Ну, наче тільки Webservice та Sidekiq.
Стопаємо їх:
[simterm]
$ kk -n gitlab-cluster-prod scale deploy gitlab-cluster-prod-sidekiq-all-in-1-v2 --replicas=0
deployment.apps/gitlab-cluster-prod-sidekiq-all-in-1-v2 scaled
$ kk -n gitlab-cluster-prod scale deploy gitlab-cluster-prod-webservice-default --replicas=0
deployment.apps/gitlab-cluster-prod-webservice-default scaled
[/simterm]
Запускаємо рестор знову:
[simterm]
git@gitlab-cluster-prod-toolbox-6fc9c7fc89-8jws7:/$ backup-utility --s3tool awscli --restore -t 1677681628_2023_03_01_15.8.1-ee
Unpacking backup
2023-03-01 15:01:25 UTC -- Restoring main_database ...
2023-03-01 15:01:25 UTC -- Be sure to stop Puma, Sidekiq, and any other process that
...
[/simterm]
Та ну твою ж дивізію…
Ну, ок… Може це через Postgres Operator? Бо він точно якісь конекти тримає. Чи через моніторинг – експортер?
Глянемо за таким нагугленим запитом:
select pid as process_id,
usename as username,
datname as database_name,
client_addr as client_address,
application_name,
backend_start,
state,
state_change
from pg_stat_activity;
ERROR: must be owner of view pg_stat_statements_info
Добре – думаю, можно з цими конектами запускати – ігноруємо помилку, відповідаємо yes на запит “Do you want to continue?“:
[simterm]
git@gitlab-cluster-prod-toolbox-6fc9c7fc89-8jws7:/$ backup-utility --s3tool awscli --restore -t 1677681628_2023_03_01_15.8.1-ee
Unpacking backup
2023-03-01 15:06:43 UTC -- Restoring main_database ...
2023-03-01 15:06:43 UTC -- Be sure to stop Puma, Sidekiq, and any other process that
...
Do you want to continue (yes/no)? yes
Removing all tables. Press `Ctrl-C` within 5 seconds to abort
2023-03-01 15:07:02 UTC -- Cleaning the database ...
2023-03-01 15:07:02 +0000 -- Deleting backup and restore lock file
rake aborted!
ActiveRecord::StatementInvalid: PG::InsufficientPrivilege: ERROR: must be owner of view pg_stat_statements_info
...
gitlabhq_production=# DROP EXTENSION pg_stat_statements;
ERROR: cannot drop extension pg_stat_statements because other objects depend on it
DETAIL: function metric_helpers.pg_stat_statements(boolean) depends on type pg_stat_statements
view metric_helpers.pg_stat_statements depends on function metric_helpers.pg_stat_statements(boolean)
extension pg_stat_kcache depends on extension pg_stat_statements
HINT: Use DROP ... CASCADE to drop the dependent objects too.
[/simterm]
Ну, ок… залежності не виглядають як якісь супер-критичні, і можливо потім ми таки зможемо повернути цей pg_stat_statements.
Пробуємо з CASCADE:
[simterm]
gitlabhq_production=# DROP EXTENSION pg_stat_statements CASCADE;
NOTICE: drop cascades to 3 other objects
DETAIL: drop cascades to function metric_helpers.pg_stat_statements(boolean)
drop cascades to view metric_helpers.pg_stat_statements
drop cascades to extension pg_stat_kcache
DROP EXTENSION
[/simterm]
Запускаємо…
І – чудо! Воно пішло, хоча з купою помилок на права доступа.
Знов спитало, чи продовжувати – знов відповідаємо yes:
[simterm]
git@gitlab-cluster-prod-toolbox-6fc9c7fc89-8jws7:/$ backup-utility --s3tool awscli --restore -t 1677681628_2023_03_01_15.8.1-ee
Unpacking backup
2023-03-01 15:14:41 UTC -- Restoring main_database ...
2023-03-01 15:14:41 UTC -- Be sure to stop Puma, Sidekiq, and any other process that
connects to the database before proceeding. For Omnibus
installs, see the following link for more information:
https://docs.gitlab.com/ee/raketasks/backup_restore.html#restore-for-omnibus-gitlab-installations
Before restoring the database, we will remove all existing
tables to avoid future upgrade problems. Be aware that if you have
custom tables in the GitLab database these tables and all data will be
removed.
Do you want to continue (yes/no)? yes
Removing all tables. Press `Ctrl-C` within 5 seconds to abort
2023-03-01 15:14:49 UTC -- Cleaning the database ...
2023-03-01 15:14:53 UTC -- done
Restoring PostgreSQL database gitlabhq_production ... ERROR: permission denied for schema metric_helpers
ERROR: permission denied for schema metric_helpers
ERROR: permission denied for schema metric_helpers
ERROR: permission denied for schema user_management
ERROR: permission denied for schema user_management
...
ERROR: permission denied for schema metric_helpers
------ END ERRORS -------
[DONE]
2023-03-01 15:15:39 UTC -- Restoring main_database ... done
2023-03-01 15:15:39 UTC -- There were errors in restoring the schema. This may cause
issues if this results in missing indexes, constraints, or
columns. Please record the errors above and contact GitLab
Support if you have questions:
https://about.gitlab.com/support/
Do you want to continue (yes/no)? yes
...
2023-03-01 15:16:45 UTC -- Restoring repositories ... done
2023-03-01 15:16:45 +0000 -- Deleting backup and restore lock file
Restoring uploads ...
done
Restoring artifacts ...
done
[/simterm]
Перевіряємо нашу тестову таблицю:
[simterm]
gitlabhq_production=# \dt test_restore
List of relations
Schema | Name | Type | Owner
--------+--------------+-------+--------------------------------
public | test_restore | table | gitlabhq_production_owner_user
(1 row)
[/simterm]
Запускаємо стопнуті сервіси:
[simterm]
$ kk -n gitlab-cluster-prod scale deploy gitlab-cluster-prod-webservice-default --replicas=2
deployment.apps/gitlab-cluster-prod-webservice-default scaled
$ kk -n gitlab-cluster-prod scale deploy gitlab-cluster-prod-sidekiq-all-in-1-v2 --replicas=1
deployment.apps/gitlab-cluster-prod-sidekiq-all-in-1-v2 scaled
[/simterm]
Перевіряємо наш репозиторій:
Все є…
Дивно…)
Але ок – виглядає так, наче воно працює.
Плюс, для бази PostgreSQL робиться окремий бекап самим Оператором, тож, думаю, можна йти далі.
Хоча дуже сподіваюсь, що використовувати restore ніколи не доведеться.
Доступно для дисків AWS EBS, GCE PD, Azure Disk, Azure File, Glusterfs, Cinder, Portworx та Ceph RBD.
Спочатку подивимось на приклад, коли у нас PVC створються зі звичайного маніфесту, а потім – як збільшити диск, котрий створювався через StatefulSet та його volumeClaimTemplates.
Збільшення диску через PersistentVolumeClaim
Перевіряємо чи можливо це з нашим “залізом”, тобто StorageClass, який використовується, в нашому випадку це AWS Elastic Block Store з типом gp3 – дивимось ресурс StorageClass, та його колонку ALLOWVOLUMEEXPANSION:
Також памя’таємо, що після зміни розміру EBS потрібно змінити розмір файлової системи. У Kubernetes з версії 1.24 це робиться автоматично завдяки параметру ExpandInUsePersistentVolumes – online file system expansion. Між 1.11 та 1.24 потрібно перезапускати поди, які використовують цей PVC.
Ну і перевіримо.
Створимо Pod з PersistentVolumeClaim на 1 гігабайт:
$ kk -n tests get pvc test-resize-pv-volume-pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-resize-pv-volume-pvc Bound pvc-8e75b850-8ef2-431b-a525-2a3200d17634 2Gi RWO gp3 4m50s
[/simterm]
В самому поді:
[simterm]
$ kk -n tests exec -ti test-resize-pv-pod -- df -h /data
Filesystem Size Used Available Use% Mounted on
/dev/nvme4n1 1.9G 24.0K 1.9G 0% /data
[/simterm]
Гуд.
Збільшення диску з StatefulSet та volumeClaimTemplates
Створюємо маніфест з STS та volumeClaimTemplates – цей volumeClaimTemplates створить PersistentVolumeClaim:
$ kk -n tests get pvc www-web-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pvc-ca9d909f-1d34-40d9-acac-78ab778f500f 1Gi RWO gp3 2m7s
[/simterm]
The StatefulSet is invalid: spec: Forbidden
Пробуємо змінити volumeClaimTemplates.spec.resources.requests.storage на 2GB, аплаїмо:
[simterm]
$ kubectl -n tests apply -f test-sts-w-pvc.yaml
The StatefulSet "web" is invalid: spec: Forbidden: updates to statefulset spec for fields other than 'replicas', 'template', 'updateStrategy' and 'minReadySeconds' are forbidden
[/simterm]
Ага…
Тож лишаємо значення в volumeClaimTemplates, та редагуємо PVC вручну:
$ kk -n tests get pvc www-web-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
www-web-0 Bound pvc-ca9d909f-1d34-40d9-acac-78ab778f500f 2Gi RWO gp3 3m43s
[/simterm]
Та сам Persistent Volume:
[simterm]
$ kk -n tests get pv pvc-ca9d909f-1d34-40d9-acac-78ab778f500f
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-ca9d909f-1d34-40d9-acac-78ab778f500f 2Gi RWO Delete Bound tests/www-web-0 gp3 4m14s
Для цього Прометеус надає клієнтські бібліотеки, які можемо використати для генерації метрик з потрібними лейблами.
Експортер можна включити прямо в код вашого додатку, або можна запускати окремим сервісом, який буде звертатися до якогось вашого сервісу і отримувати від нього дані, які потім буде конвертувати в Prometheus-формат та віддавати серверу Prometheus.
Prometheus Metrics
Загальна схема роботи Prometheus-серверу та його експортерів у Kubernetes виглядає так:
Тут маємо:
Prometheus Server, який в нашому випадку розгортається за допомогою Kube Promeheus Stack та Prometheus Operator
за допомогою ServiceMonitor через Operator ми створюємо Scrape Job, яка має один чи декілька Targets, тобто сервісів, які буде опитувати Prometheus для отримання метрик, які він зберігає у своїй Time Series Database
за URL, які вказані в Target, Prometheus звертається до ендпоінту Prometheus Exporter
а Prometheus Exporter збирає метрики з вашого додатку, які потім віддає до Prometheus
Типи метрик Prometheus
Коли плануємо писати свій експортер, необхідно знати які типи метрик ми можемо в ньому використовувати. Основні типи:
Counter: може тільки збільшувати своє значення, наприклад для підрахунку кількості HTTP-запитів
Enum: має попередньо задані значення, використовується наприклад для моніторингу кількості подів у статус Running або Failed
Histograms: зберігає значення за проміжок часу, можна використовавти для, наприклад, отримання часу відповіді веб-северу за період часу – rate(metric_name{}[5m])
Gauges: може приймати будь-яке значення, можемо використовувати для, наприклад, зберігання значень нагрузки на CPU
Info: key-value storage, наприклад для Build information, Version information, або metadata
У кожного типу є свої методи, тож варто подивитись документацію, там ще й приклади є. Див. Prometheus Python Client, або в документації самої бібліотеки:
Для початку, давайте подивимось як воно взагалі працює – напишимо скрипт на Python, в якому на порту 8080 буде звичайний HTTP-сервер, а на порту 9000 – експортер, який буде збирати статистику по запитах з кодами відповідей і створювати метрику http_requests з двома лейблами – в одній будемо зберігати код відповіді, а в іншій – ім’я хоста, з якого метрика була отримана.
Встановлюємо бібліотеку:
[simterm]
$ pip install prometheus_client
[/simterm]
Пишемо скрипт:
#!/usr/bin/env python
import os
import re
import platform
from time import sleep
from http.server import BaseHTTPRequestHandler, HTTPServer
from prometheus_client import start_http_server, Counter, REGISTRY
class HTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
if self.path == '/':
self.send_response(200)
self.send_header('Content-type','text/html')
self.end_headers()
self.wfile.write(bytes("<b> Hello World !</b>", "utf-8"))
request_counter.labels(status_code='200', instance=platform.node()).inc()
else:
self.send_error(404)
request_counter.labels(status_code='404', instance=platform.node()).inc()
if __name__ == '__main__':
start_http_server(9000)
request_counter = Counter('http_requests', 'HTTP request', ["status_code", "instance"])
webServer = HTTPServer(("localhost", 8080), HTTPRequestHandler).serve_forever()
print("Server started")
Тут ми:
start_http_server() – запускаємо HTTP-сервер самого експортеру на порту 9000
request_counter – створюємо метрику з ім’ям http_requests, типом Counter, і додаємо їй дві labels – status_code та instance
webServer – запускаємо звичайний HTTP-сервер на Python на порту 8080
Далі, коли ми робитимо HTTP-запит на localhost:8080, він буде попадати до do_GET(), в якому буде перевірятися URI. Якщо йдемо на / – то отримаємо код 200, якщо будь-який інший – то 404.
І там же оновлюємо значення метрики http_requests – додаємо код відповіді та ім’я хоста, і викликаємо метод Counter.inc(), який інкрементить значення метрики на одиницю. Таким чином кожен запит, який буде оброблено веб-сервером webServer буде додавати +1 в нашу метрику, а в залежності від коду відповіді – ми отримаємо цю метрику з двома різними лейблами – 200 та 404.
Перевіряємо – запускаємо сам скрипт:
[simterm]
$ ./py_http_exporter.py
[/simterm]
Робимо декілька запитів з різними URI:
[simterm]
$ curl -I -X GET localhost:8080/
HTTP/1.0 200 OK
$ curl -I -X GET localhost:8080/
HTTP/1.0 200 OK
$ curl -I -X GET localhost:8080/
HTTP/1.0 200 OK
$ curl -I -X GET localhost:8080/blablabla
HTTP/1.0 404 Not Found
$ curl -I -X GET localhost:8080/blablabla
HTTP/1.0 404 Not Found
$ curl -I -X GET localhost:8080/blablabla
HTTP/1.0 404 Not Found
[/simterm]
А тепер перевіримо, що маємо на ендпоінті експортеру:
[simterm]
$ curl -X GET localhost:9000
...
# HELP http_requests_total HTTP request
# TYPE http_requests_total counter
http_requests_total{instance="setevoy-wrk-laptop",status_code="200"} 3.0
http_requests_total{instance="setevoy-wrk-laptop",status_code="404"} 3.0
[/simterm]
Чудово – маємо три запроси з кодом 200, та три – з кодом 404.
Jenkins Jobs Exporter з Gauage
Або інший варіант – коли експортер буде звертатися до якось зовнішнього ресурсу, отримувати значення, і вносити їх до метрики.
Наприклад, ми можемо звертатись до якогось API, і від нього отримати дані, в цьому прикладі це буде Jenkins:
#!/usr/bin/env python
import time
import random
from prometheus_client import start_http_server, Gauge
from api4jenkins import Jenkins
jenkins_client = Jenkins('http://localhost:8080/', auth=('admin', 'admin'))
jenkins_jobs_counter = Gauge('jenkins_jobs_count', "Number of Jenkins jobs")
def get_metrics():
jenkins_jobs_counter.set(len(list(jenkins_client.iter_jobs())))
if __name__ == '__main__':
start_http_server(9000)
while True:
get_metrics()
time.sleep(15)
Тут ми за допомогою бібліотеки api4jenkins створюємо об’єкт jenkins_client, який підключається до інстансу Jenkins та отримує кількість його jobs. Потім в функції get_metrics() ми рахуємо кількість об’єктів із jenkins_client.iter_jobs(), та вносимо їх до метрики jenkins_jobs_counter.
Запускаємо в Docker:
[simterm]
$ docker run -p 8080:8080 jenkins:2.60.3
[/simterm]
Створюємо тестову задачу:
В результаті отримуємо такий результат:
[simterm]
$ curl localhost:9000
...
# HELP jenkins_jobs_count Number of Jenkins jobs
# TYPE jenkins_jobs_count gauge
jenkins_jobs_count 1.0
[/simterm]
Prometheus Exporter та Kubernetes
І давайте протестимо якийсь більш реальний приклад.
У нас є API-сервіс, який використовує базу даних PostgreSQL. Для перевірки підключення девелопери створили ендпоінт, на який ми можемо звертатися для отримання поточного статусу – є чи нема підключення до серверу баз даних.
Зараз для його моніторингу ми використовуємо Blackbox Exporter, але згодом хочется трохи розширити можливості, тож спробуємо створити експортер, котрий поки що буде просто перевіряти код відповіді він цього ендпоінту.
Exporter з Enum та Histogram
#!/usr/bin/env python
import os
import requests
import time
from prometheus_client import start_http_server, Enum, Histogram
hitl_psql_health_status = Enum("hitl_psql_health_status", "PSQL connection health", states=["healthy", "unhealthy"])
hitl_psql_health_request_time = Histogram('hitl_psql_health_request_time', 'PSQL connection response time (seconds)')
def get_metrics():
with hitl_psql_health_request_time.time():
resp = requests.get(url=os.environ['HITL_URL'])
print(resp.status_code)
if not (resp.status_code == 200):
hitl_psql_health_status.state("unhealthy")
if __name__ == '__main__':
start_http_server(9000)
while True:
get_metrics()
time.sleep(1)
$ kubectl -n monitoring apply -f hitl_exporter.yaml
pod/hitl-exporter-pod created
service/hitl-exporter-service created
servicemonitor.monitoring.coreos.com/hitl-exporter-monitor created
Redis – поки використовуємо дефолтний, потім переїдемо на KeyDB, який теж розгортається оператором
Gitaly – спробуємо в кластері, можливо, на окремій ноді – у нас всього 150-200 користувачів, навантаження не повинно бути великим, скейлінг і тим більше Praefik не потрібні
GitLab Operator виглядає в цілому цікаво, але в документації через слово “Experimental” і “Beta”, тому поки не чіпаємо – використовуємо чарт.
Helm chart prerequisites
По чарту: для початку треба пройтися по доступним параметрам чарту, і подивитися, що нам взагалі треба буде із зовнішніх ресурсів (лоад-балансери, корзини S3, PostgreSQL), і що ще можна налаштувати через чарт.
PostgreSQL: ми будемо використовувати оператор, та розгорнемо свій кластер з блекджеком і базами
Redis: у нас є KeyDB-оператор, потім будемо використовувати його, поки дефолтний із чарту
Networking and DNS: використовуємо AWS ALB Contoller, створимо ACM сертифікат, DNS у Route53, записи створюються через External DNS
Persistence: цікавий нюанс, можливо, треба буде налаштувати reclaimPolicy to Retain, див. Configuring Cluster Storage
Prometheus: теж поінт на подумати – у нас є Kube Prometheus Stack зі своїм Prometheus та Alertmanager, треба буде подумати чи відключати вбудований у GitLab, чи залишати
Outgoing email: поки не налаштовуватимемо, але потім треба буде подумати. У принципі є підтримка AWS SES, десь у документації зустрічав, так що нормально
RBAC: у нас є, підтримується, тож залишаємо за замовчуванням, тобто включаємо
Враховуємо, що чарт включає цілу пачку залежностей, і корисно пройтися і подивитися що там ще деплоїться і з якими параметрами.
Структура Helm-чарту та його values.yaml
У GitLab Helm-чарту досить складна структура його values, так як чарт включає набір сабчартів і залежностей, див. GitLab Helm subcharts .
Щоб краще зрозуміти структуру його values – можна подивитися структуру каталогу charts з дочірніми чартами:
Відповідно у values основного чарту параметри розбиті на global (див. Subcharts and Global Values), які використовуються дочірніми чартами, та параметри для конкретних чартів, див. Configure charts using globals, тобто наш values.yaml виглядатиме так:
global:
hosts:
domain:
hostSuffix: # використовується у ./charts/gitlab/charts/webservice, ./charts/gitlab/charts/toolbox/, ./charts/registry/, etc
...
gitlab:
kas:
enabled: # використовується у ./charts/gitlab/charts/kas/
...
nginx-ingress:
enabled: # використовується для ./gitlab/charts/nginx-ingress
...
postgresql:
install: # використовується при встановленні зовнішнього чарту postgresql
Тепер подивимося на самі values, і які нам можуть бути корисні.
key: ключ/поле у Секреті, за яким отримуємо пароль
global.redis: взагалі буде зовнішній, KeyDB, і тут треба буде вказати параметри доступу до нього, але спочатку залишимо дефолтний, див. Configure Redis settings
global.grafana.enabled: включаємо – подивимося, які там є дашборди (таки треба буде налаштовувати окремо, див. Grafana JSON Dashboards )
bucket: треба буде створити S3 бакет, цей параметр використовується /charts/gitlab/charts/toolbox/ для бекапів, сам GitLab Registry налаштовується через окремі параметри, розглянемо нижче
global.gitaly: поки використовуємо з чарту, незважаючи на рекомендації – будемо деплоїти у вигляді Kubernetes Pod в кластер, залишаємо за замовчуванням, але маємо на увазі
global.minio: відключимо – використовуємо відразу AWS S3
cdnHost: взагалі-то корисна начебто річ, але подивимося, як його використовувати, поки не чіпаємо
contentSecurityPolicy: теж корисна штука, але налаштуємо потім, див. Content Security Policy
enableUsagePing: “телеметрія” для самого GitLab Inc, не бачу сенсу, відключимо
enableSeatLink: не зрозумів, що це, посилання seat link support веде в “нікуди” – на сторінці інформації про seat не знайшов, але мабуть це щось пов’язане з кількістю користувачів в ліцензії, а оскільки ми її не купуємо – то можна вимкнути
object_store: загальні параметри для роботи з S3 типу ключів доступу та proxy, див. Consolidated object storage
connection: тут потрібно буде створити секрет, в якому описуються налаштування підключення до корзин, у тому числі ACCESS/SECRET ключі, але ми замість ключів використовуємо ServiceAccount та IAM role
Specify buckets : які корзини потрібні, є набір дефолтних імен типу gitlab-artifacts , але для dev- та test- має сенс перевизначити
storage_options: шифрування для бакетів, має сенс змінювати якщо використовується AWS KMS, але ми швидше за все залишимо дефолтне шифрування
$ kk apply -f postgresql.yaml
postgresql.acid.zalan.do/gitlab-cluster-test-psql created
[/simterm]
Перевіряємо поди:
[simterm]
$ kk -n gitlab-cluster-test get pod
NAME READY STATUS RESTARTS AGE
devops-gitlab-cluster-test-psql-0 2/2 Running 0 24s
devops-gitlab-cluster-test-psql-1 0/2 ContainerCreating 0 4s
[/simterm]
Окей, створюються.
Перевіряємо Секрети – потім використуємо секрет юзера postgres у конфігах GitLab:
[simterm]
$ kk -n gitlab-cluster-test get secret
NAME TYPE DATA AGE
default-token-2z2ct kubernetes.io/service-account-token 3 4m12s
gitlabhq-test-owner-user.devops-gitlab-cluster-test-psql.credentials.postgresql.acid.zalan.do Opaque 2 65s
gitlabhq-test-reader-user.devops-gitlab-cluster-test-psql.credentials.postgresql.acid.zalan.do Opaque 2 65s
gitlabhq-test-writer-user.devops-gitlab-cluster-test-psql.credentials.postgresql.acid.zalan.do Opaque 2 66s
postgres-pod-token-p7b4g kubernetes.io/service-account-token 3 66s
postgres.devops-gitlab-cluster-test-psql.credentials.postgresql.acid.zalan.do Opaque 2 66s
standby.devops-gitlab-cluster-test-psql.credentials.postgresql.acid.zalan.do Opaque 2 66s
Щоб уникнути помилки BucketAlreadyExists, до імен корзин додаємо or як власний “ідентифікатор”, бо імена загальні, і ім’я оточення – test , тобто список виходить такий:
or-gitlab-registry-test
or-gitlab-artifacts-test
or-git-lfs-test
or-gitlab-packages-test
or-gitlab-uploads-test
or-gitlab-mr-diffs-test
or-gitlab-terraform-state-test
or-gitlab-ci-secure-files-test
or-gitlab-dependency-proxy-test
or-gitlab-pages-test
or-gitlab-backups-test
or-gitlab-tmp-test
Не факт, що знадобляться всі, подивимося по ходу налаштування GitLab та його фіч, але поки що створимо.
Для Ingress нам потрібен TLS-сертифікат, див. Requesting a public certificate, а для отримання сертифіката – вочевидь, що домен.
У нашому випадку використовуємо internal.example.com, для якого створимо wildcard-сертифікат в ACM:
У FQDN вказуємо *.internal.example.com, щоб включити всі субдомени. Потім для GitLab використуємо параметри global.hosts.domain=internal.example.com та hostSuffix=test, що в результаті створить кілька Ingress та Services, які через ExternalDNS створять необхідні записи у Route53.
У Validation Method вибираємо DNS – найпростіший, тим більш що доменна зона хоститься в Route53 – все створюється в пару кліків:
Переходимо до сертифікату – він зараз у Pending validation, клікаємо Create records in Route53 :
Тепер статус Issued, запам’ятовуємо його ARN – він нам знадобиться у values:
Всі дефолтні values тут>>>, можна використати як приклад, але не варто повністю копіювати – у свій values пишемо тільки те, що у нас відрізняється від дефолтного.
Вказуємо домен, використовуючи який чарт пропише значення для Ingress та Services які буде створювати – отримаємо набір доменів виду gitlab.internal.example.com, registry.internal.example.com і т.д.
Для SSH у прикладі для Ingress вказаний окремий субдомен, оскільки під SSH буде створюватися окремий Service з Network Load Balancer для доступу до 22 TCP.
hostSuffix додасть суфікс до створюваних записів, тобто в результаті будуть субдомени виду gitlab-test.internal.example.com та registry-test.internal.example.com .
Але для SSH hostSuffix не застосовується, тому вказуємо відразу з суфіксом.
Виходить так:
global:
hosts:
domain: internal.example.com
hostSuffix: test
ssh: gitlab-shell-test.internal.example.com
Знаходимо ім’я Service, який був створений під час деплою PostgreSQL кластеру:
[simterm]
$ kk -n gitlab-cluster-test get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
devops-gitlab-cluster-test-psql ClusterIP 172.20.67.135 <none> 5432/TCP 63m
devops-gitlab-cluster-test-psql-config ClusterIP None <none> <none> 63m
devops-gitlab-cluster-test-psql-repl ClusterIP 172.20.165.249 <none> 5432/TCP 63m
[/simterm]
Користувача поки що візьмемо дефолтного postgress, з готового секрету:
[simterm]
$ kk -n gitlab-cluster-test get secret postgres.devops-gitlab-cluster-test-psql.credentials.postgresql.acid.zalan.do
NAME TYPE DATA AGE
postgres.devops-gitlab-cluster-test-psql.credentials.postgresql.acid.zalan.do Opaque 2 67m
[/simterm]
Для production таки треба буде робити окремого, бо postgress == root .
Треба буде моніторити як він ресурси використовує, але у випадку з нашими 150-200 користувачів навряд чи там буде необхідність сильно допилювати його або тим більше розгортати кластер Praefect .
Тут треба налаштувати storage, який зберігається в Secret, і в якому теж необхідно вказати ім’я корзини: параметр globals.registry буде використовуватися для бекапів, а параметр тут – самим сервісом Registry, див Docker Registry images .
Для прикладу візьмемо файл registry.s3.yaml, але без ключів, тому що для Registry буде створено свій ServiceAccoumt з IAM Role:
Окремо описуємо Services для kas, webservice та gitlab-shell, з того ж прикладу alb-full.yaml.
Для gitlab-shell Service в аннотації external-dns.alpha.kubernetes.io/hostname вказуємо ім’я хоста:
gitlab:
kas:
enabled: true
ingress:
# Specific annotations needed for kas service to support websockets
annotations:
alb.ingress.kubernetes.io/healthcheck-path: /liveness
alb.ingress.kubernetes.io/healthcheck-port: "8151"
alb.ingress.kubernetes.io/healthcheck-protocol: HTTP
alb.ingress.kubernetes.io/load-balancer-attributes: idle_timeout.timeout_seconds=4000,routing.http2.enabled=false
alb.ingress.kubernetes.io/target-group-attributes: stickiness.enabled=true,stickiness.lb_cookie.duration_seconds=86400
alb.ingress.kubernetes.io/target-type: ip
kubernetes.io/tls-acme: "true"
nginx.ingress.kubernetes.io/connection-proxy-header: "keep-alive"
nginx.ingress.kubernetes.io/x-forwarded-prefix: "/path"
# k8s services exposed via an ingress rule to an ELB need to be of type NodePort
service:
type: NodePort
webservice:
enabled: true
service:
type: NodePort
# gitlab-shell (ssh) needs an NLB
gitlab-shell:
enabled: true
service:
annotations:
external-dns.alpha.kubernetes.io/hostname: "gitlab-shell-test.internal.example.com"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "ip"
service.beta.kubernetes.io/aws-load-balancer-scheme: "internet-facing"
service.beta.kubernetes.io/aws-load-balancer-type: "external"
type: LoadBalancer
Перевіряємо роботу з репозиторієм, тобто роботу сервісів Gitaly та GitLab Shell.
Створюємо тестовий репозиторій:
Копіюємо адресу – з субдоменом gitlab-shell-test.internal.example.com, який вказували в конфігах:
Клонуємо:
[simterm]
$ git clone [email protected]:gitlab-instance-da4355a9/test-repo.git
Cloning into 'test-repo'...
The authenticity of host 'gitlab-shell-test.internal.example.com (3.***.***.79)' can't be established.
ED25519 key fingerprint is SHA256:xhC1Q/lduNbg49kGljYUb21YlBBsxrG89xE+iCHD+xc.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'gitlab-shell-test.internal.example.com' (ED25519) to the list of known hosts.
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Receiving objects: 100% (3/3), done.
[/simterm]
І зміст:
[simterm]
$ ll test-repo/
total 8
-rw-r--r-- 1 setevoy setevoy 6274 Feb 4 13:24 README.md
[/simterm]
Спробуємо пушнути якісь зміни назад:
[simterm]
$ cd test-repo/
$ echo test > test.txt
$ git add test.txt
$ git commit -m "test"
$ git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 16 threads
Compressing objects: 100% (2/2), done.
Writing objects: 100% (3/3), 285 bytes | 285.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To gitlab-shell-test.internal.example.com:gitlab-instance-da4355a9/test-repo.git
7217947..4eb84db main -> main
[/simterm]
І в WebUI:
Окей, працює.
Container Registry
Далі перевіримо Registry – приклади команд є у веб-інтерфейсі > Container Registry :
Логінимося з тим же логіном:паролем, які використовували для логіна в веб-інтерфейс GitLab (користувач root, пароль з секрету gitlab-gitlab-initial-root-password):
$ docker push registry-test.internal.example.com/gitlab-instance-da4355a9/test-repo:1
The push refers to repository [registry-test.internal.example.com/gitlab-instance-da4355a9/test-repo]
b64792c17e4a: Mounted from gitlab-instance-da4355a9/test
1: digest: sha256:eb45a54c2c0e3edbd6732b454c8f8691ad412b56dd10d777142ca4624e223c69 size: 528
[/simterm]
Перевіряємо корзину or-gitlab-registry-test:
[simterm]
$ aws --profile internal s3 ls or-gitlab-registry-test/docker/registry/v2/repositories/gitlab-instance-da4355a9/test-repo/_manifests/tags/1/
PRE current/
PRE index/
[/simterm]
Окей – Registry працює, доступ до S3 є, з ServiceAccounts проблем начебто немає.
ServiceAccounts та S3 access
Але про всяк випадок перевіримо ServiceAccounts та доступ до S3 в інших сервісах, наприклад з поду Toolbox:
[simterm]
$ kk -n gitlab-cluster-test exec -ti gitlab-toolbox-565889b874-vgqcb -- bash
git@gitlab-toolbox-565889b874-vgqcb:/$ aws s3 ls or-gitlab-registry-test
PRE docker/
Оскільки GitLab нещодавно змінив політику надання Free-доступу, і тепер по Free підписці буде доступно лише 5 користувачів, то вирішили ми переїжджати на self-hosted версію.
Взагалі з ліцензією у них цікаво: ціна залежить від кількості користувачів, купити можна щонайменше на рік, і після покупки зменшити кількість користувачів у ліцензії не можна (але можна збільшити).
GitLab буде жити в Kubernetes, і питань перед запуском багато, тим більше особисто я раніше GitLab взагалі не дуже користувався.
Деплоїти GitLab будемо через ArgoCD, запускати будемо в AWS Elastic Kubernetes Service, для object store використовуємо AWS S3. Але про це все потім, а для початку подивимося що GitLab є “зсередини” і як його взагалі деплоїти.
GitLab Workhorse: реверс-проксі для завантаження та вивантаження файлів, Git push/pull і т.д.
Puma: веб-сервер на Ruby, використовується GitLab для API та своїх веб-сторінок
Sidekiq: для створення та управління чергами завдань
використовує Redis для зберігання інформації про джоби
PostgreSQL: зберігання інформації про користувачів, права доступу, метаданих і т.д.
GitLab Shell: працює з репозиторіями по SSH та керує ключами доступів
звертається до Gitaly для обробки Git-об’єктів
надсилає інформацію в Redis для створення завдань у Sidekiq
Gitaly: Git RPC server, займається завданнями в репозиторіях, які отримує від GitLab Shell і GitLab веб-додатки
Інфраструктура
Для роботи GitLab потрібні PostgreSQL, Redis, бакети AWS S3 та поштовий сервіс для отримання та надсилання листів.
Helm-чарт за замовчуванням встановлює PostgreSQL та Redis, але для production PostgreSQL рекомендується встановлювати окремо, див. Configure the GitLab chart with an external database та Configure PostgreSQL, хоча ми будемо використовувати PostgreSQL Operator і крутити кластер PostgreSQL у Kubernetes.
Аналогічні вимоги Redis та Gitaly – їх теж бажано запускати не з чарту та не в Kubernetes-кластері. Див. Installing GitLab by using Helm. У нас замість Redis швидше за все буде KeyDB, теж через оператор, також у Kubernetes.
Документація з розгортання Gitaly говорить, що до 500 користувачів достатньо однієї окремої віртуальної машини з самим Gitaly. Якщо планується 1000 і більше користувачів, то рекомендується запускати Gitaly Cluster з Praefect. Див. Gitaly > High Availability. Враховуючи кількість користувачів у нас – не бачу сенсу виносити на окремий EC2, тому будемо деплоїти разом із чартом, потім подивимося на його роботу та ресурси, можливо винесемо на окрему ноду Kubernetes.
Є гарний приклад інфраструктури в GitLab on AWS Partner Solution Deployment Guide, але це для прям серйозних масштабів, ми будемо робити простіше. Проте, сама схема цікава і корисна для розуміння загальної концепції при плануванні інфраструктури:
Крім того, є Reference architectures, в яких описані варіанти запуску GitLab під різні навантаження. З них нам можуть бути особливо цікаві Cloud native hybrid, які описують запуск у Kubernetes (hybrid – тому що частину сервісів таки рекомендується запускати не в кластері):
Для LoadBalancer рекомендується least outstanding requests замість стандартного round-robin – треба не забути.
Корисно пройтися по всіх доступних опціях, подивитися що і як можна налаштувати, див. GitLab Helm chart deployment options, займемося цим в наступному пості.
Моніторинг GitLab – окрема тема, дійдемо до неї пізніше, поки див. Monitoring GitLab.
Запуск GitLab в Minikube
Взагалі використовується для розробників, які пиляють фічі під Kubernetes, але ми використовуємо для знайомства з чартом GitLab. Див. Developing for Kubernetes with minikube.
Запускаємо Minikube:
[simterm]
$ minikube start --cpus 4 --memory 10240
[/simterm]
Включаємо Ingress плагін:
[simterm]
$ minikube addons enable ingress
[/simterm]
Клонуємо репозиторій та встановлюємо залежності – корисно на них подивитися, хоча вони описані в документації до чарту:
[simterm]
$ git clone https://gitlab.com/gitlab-org/charts/gitlab.git
$ cd gitlab
$ helm dependency update
...
Dependency gitlab did not declare a repository. Assuming it exists in the charts directory
Dependency certmanager-issuer did not declare a repository. Assuming it exists in the charts directory
Dependency minio did not declare a repository. Assuming it exists in the charts directory
Dependency registry did not declare a repository. Assuming it exists in the charts directory
Downloading cert-manager from repo https://charts.jetstack.io/
Downloading prometheus from repo https://prometheus-community.github.io/helm-charts
Downloading postgresql from repo https://raw.githubusercontent.com/bitnami/charts/eb5f9a9513d987b519f0ecd732e7031241c50328/bitnami
Downloading gitlab-runner from repo https://charts.gitlab.io/
Downloading grafana from repo https://grafana.github.io/helm-charts
Downloading redis from repo https://raw.githubusercontent.com/bitnami/charts/eb5f9a9513d987b519f0ecd732e7031241c50328/bitnami
Dependency nginx-ingress did not declare a repository. Assuming it exists in the charts directory
...
kas – Kubernetes agent server для Gitlab Agent, “GitLab Agent for Kubernetes is an active in-cluster component for solving any GitLab<->Kubernetes integration tasks” – подивимось на нього уважніше іншим разом
migrations – джоби для роботи з міграціями бази даних
minio – High Performance Object Storage, API compatible with Amazon S3 – використовується, коли немає S3
postgresql – база даних, читали
prometheus-server – моніторинг GitLab
redis-master – Редіс)
registry – Container Registry для зберігання образів
Дуже правильне діло – моніторити, наскільки ефективно використовується кластер, особливо, якщо ресурси деплояться розробниками, які не сильно вникають у requests, і встановлюють завищені значення “про запас”. Запас, звичайно, потрібен, але й просто так реквестити ресурси ідеї погана.
Наприклад, у вас є WorkerNode з 4 vCPU (4000 milicpu) та 16 ГБ оперативної пам’яті, і ви створюєте Kubernetes Deployment, у якому для подів задаєте CPU requests 2500m і 4 Гб пам’яті. Після запуску одного пода – він зареквестить більше половини доступного процесорного часу, і під час запуску другого поду Kubernetes повідомить про нестачу ресурсів на доступних нодах, що призведе до запуску ще одного WorkerNode, який, зрозуміло, відразиться на загальній вартості кластера.
Kubernetes Resource Report – найпростіший у запуску та можливостях: просто виводить ресурси групуючи їх за типом, і відображає статистику – скільки CPU/MEM requested і скільки реально використовується.
Мені вона подобається саме простотою – просто запускаємо, раз в пару тижнів дивимося що відбувається в кластері, і за необхідності пінгуємо розробників із питанням “А вам насправді потрібно 100500 гіг пам’яті для цієї апки? »
Є Helm-чарт, але він оновлюється рідко, тому простіше встановити з маніфестів.
Створюємо Namespace:
[simterm]
$ kk create ns kube-resource-report
namespace/kube-resource-report created
$ kubectl apply -k deploy/
serviceaccount/kube-resource-report created
clusterrole.rbac.authorization.k8s.io/kube-resource-report created
clusterrolebinding.rbac.authorization.k8s.io/kube-resource-report created
configmap/kube-resource-report created
service/kube-resource-report created
deployment.apps/kube-resource-report created
Далі переходимо, наприклад, до Namespaces, сортуємо колонки за CR (CPU Requested):
При наведенні курсора на повзунок Kube Resource Report підкаже оптимальне з його точки зору значення.
Далі думаємо самі – чи дійсно потрібно стільки requests, чи його можна зменшити.
У цьому випадку у нас Apache Druid з 16 подами, в кожній працює JVM, яка і процесор і пам’ять любить, і для Druid процесор бажано виділяти по одному ядру на кожен thread виконання Java, тому ОК – нехай буде 14,65 процесора.
Kubecost
Kubecost – це Kube Resource Report на стероїдах. Вміє рахувати трафік, відправляти алерти, генерує метрики для Prometheus, має свої дашборди Grafana, може підключатися до кількох кластерів Kubernetes та багато іншого.
Місцями не без багів, але в цілому штука приємна.
Правда, вартість бізнес-ліцензії в 499 доларів трохи завищена, як на мене. Втім для базових речей цілком доступна Free версія.
“Під капотом” використовує свій Prometheus для зберігання даних. Можна відключити і використовувати зовнішній, але не рекомендується .
Installation
Основні доступні параметри описані в документації на Github , також можна переглянути дефолтні values його Helm-чарту.
Потребує реєстрації для отримання ключа – заходимо на https://www.kubecost.com/install.html , вказуємо пошту – і відразу переадресує на інструкцію з вашим ключем:
Helm chart values
Поспішати з установкою не будемо – спочатку створимо свої values.
Якщо ви вже маєте Kube Prometheus Stack, є Grafana і NodeExporter – то в Kubecost їх має сенс відключити. Крім того, відключимо kube-state-metrics, що б не дублювали дані в моніторингу.
Що б Prometheus із нашого власного стека почав збирати метрики Kubecost – налаштуємо створення ServiceMonitor і додамо йому labels – тоді можна буде генерувати свої алерти та використовувати Grafana dashboard.
А ось якщо відключити запуск вбудованої Grafana – под с kubecost-cost-analyzer не стартує. Не знаю – бага чи фіча. Але в ній є свої дашборды які можуть бути корисними, тож можна залишити.
Ще можна включити networkCosts, але мені так і не вдалося побачити адекватних витрат на трафік – можливо, неправильно налаштував.
networkCosts може бути достатньо прожорливим по ресурсам – треба моніторити використання ЦПУ.
Тут скрин з Kubecost, який вже майже тиждень запущено на одному з наших кластерів:
Коротко оглянемо основні пункти меню.
Assets
Для розуміння витрат краще почати з пункту Assets , де виводиться вартість “заліза”:
Бачимо, що в день наш кластер коштує 43 долари.
Можна “провалитися” глибше в деталі кластера, і побачити розбивку по ресурсам – WorkerNodes, лоад-балансерам, дискам та вартість самого AWS Elastic Kubernetes Service:
Переходимо ще далі, в Nodes:
І дивимось деталі вартості по конкретній ноді:
Перевіряємо:
0.167 за годину, як Kubecost і репортить в Hourly Rate.
Тут наш Apache Druid має реквестів CPU на цілих 48 долларів за тиждень або 4.08 в день.
Переходимо далі, і маємо картину по конкретним контролерам – StatefulSet, Deployment:
Колонки тут:
CPU, RAM: вартість використовуваних ресурсів в залежності від вартості ресурсів WorkerNode
PV: вартість PersistentVolume у вибраному контролері, тобто для StaefulSet MiddleManager маємо PV, котрий являє собою AWS EBS, за який ми платимо гроші
Network: треба перевіряти, бо якось дивно рахує – дуже мало
LB: LoadBalancers по вартості в AWS
Shared: загальні ресурси, які не будут рахуватися окремо, наприклад неймспейс kube-system, налаштовується в http://localhost:9090/settings > Shared Cost
Efficiency: утилізація vs реквесты за формулою: ((CPU Usage / CPU Requested) * CPU Cost) + (RAM Usage / RAM Requested) * RAM Cost) / (RAM Cost + CPU Cost)) основний показник ефективності ресурсу, див. Efficiency and Idle
Якщо перейти ще глибше – буде посилання на Grafana, де можна переглянути використання ресурсів конкретним подом:
Правда, “з коробки” не відображаються метрики в RAM Requested.
Для перевірки метрик можна зайти на локальний Pometheus:
І так – kube_pod_container_resource_requests_memory_bytes пуста:
Тому що метрика теперь називаєтся kube_pod_container_resource_requests з resource="memory", треба оновити запрос в цій Графані:
avg(kube_pod_container_resource_requests{namespace=~"$namespace", pod="$pod", container!="POD", resource="memory"}) by (container)
__idle__
Витрати __idle__ – різниця між вартістю ресурсів виділених під існуючі об’єкти (поди, деплойменти) – їх реквести і реальний usage, та “заліза, що простоює”, на якому вони працюють, тобто не зайняті ЦПУ/пам’ять, які можна використовувати під запуск нових ресурсів.
Savings
Тут зібрані поради щодо оптимізації витрат:
Наприклад, у “Right-size your container requests” зібрані рекомендації щодо налаштувань реквестів для ресурсів – аналог репортів у Kubernetes Resource Report:
Глянемо той же Apache Druid:
Тут явний овер-реквест по CPU, і Kubecost рекомендує зменшити ці реквести:
Але про Druid вже писалося вище – JVM, на кожен под MiddleManager ми запускаємо один Supervisor із двома Tasks, а під кожну Task бажано виділяти по повному ядру. Тож залишаємо, як є.
Корисна штука “Delete unassigned resources” – у нас, наприклад, знайшлася пачка EBS, що не використовуються:
Health
Теж корисна штука, що відображає основні проблеми із кластером:
kubecost-network-costs активно використовує CPU, вище своїх реквестів, і Kubernetes його тротлить.
Alerts
Тут можемо налаштувати алерти, але мені вдалося налаштувати відправку тільки через Slack Webhook:
Prometehus Alertmanager можна налаштувати через values , але використовується свій локальний, який запускається разом з Prometheus, а як йому налаштувати роути – не знайшов.
Приклад алерту, який можна налаштувати в Kubecost:
Тут тестові алерти, які можна буде в принципі тягнути у продакшен.
ServiceMonitor для отримання метрик у зовнішньому Prometheus відключив, бо сенсу поки що не бачу – алертити буде через Slack Webhook своїми алертами, а дашборда для Grafana у вбудованій Графані краща, і їх там кілька.
Додав direct-classification для networkCosts – подивимося, можливо покаже більш правильні дані щодо трафіку.
#TODO
З чим поки що не вдалося розібратися:
алерти через Alertmanager (можливо, має сенс таки спробувати відключити внутрішній Prometheus)
Kubecost не бачить Node Exporter (перевіряти на сторінці http://localhost:9090/diagnostics ), але це наче ні на що не впливає – основні метрики отримує від cAdvisor
витрати на нетворкінг занадто маленькі (але це не точно)