![]() Наче звична задача – оновити версію модулю Terraform, але в
Наче звична задача – оновити версію модулю Terraform, але в terraform-aws-modules/eks версії 20.0 були досить великі зміни з breaking changes.
Зміни стосуються аутентифікації та авторизації в AWS IAM та AWS EKS, які розбирав в пості AWS: Kubernetes та Access Management API – нова схема авторизації в EKS.
Але там ми все робили руками, аби взагалі подивись на новий механізм – а тепер давайте це зробимо з Terraform.
Крім того, зміни відбулися в Karpenter відносно IRSA (IAM Roles for ServiceAccounts). Нову схему роботи з ServiceAccount описував в AWS: EKS Pod Identities – заміна IRSA? Спрощуємо менеджмент IAM доступів, а апдейт конкретно в модулі Karpenter глянемо в цьому пості.
Хоча я буду робити апгрейд версії самого AWS EKS і модуля Terraform через створення нового кластеру, а тому в принципі можу не морочити голову з “live-update” кластера, але хочеться спробувати зробити так, аби це можна було застосувати на живому кластері та не втратити до нього доступу і не поламати умовний Production.
Втім, майте на увазі, що те, що описано в цьому пості робиться на тестовому кластері (бо в мене взагалі один кластер для Dev/Staging/Prod). Тож не варто відразу робити апгрейд на продакшені, а краще спочатку протестувати на якомусь Dev-оточенні.
Про сетап самого кластеру детальніше писав у Terraform: створення EKS, частина 2 – EKS кластер, WorkerNodes та IAM, і в цьому пості приклади коду будуть саме звідти, хоча він вже трохи відрізняється від того, що було описано там, бо створення EKS зробив окремим власним модулем, щоб простіше було менеджити різні кластери-оточення.
В цілому, змін наче і дуже небагато – але пост вийшов довгий, бо намагався показати все детально і з реальними прикладами.
Що змінилося?
Повний опис є в GitHub – див. v20.0.0 та Upgrade from v19.x to v20.x.
Що саме нас цікавить (знов-таки – конкретно в моєму випадку):
- EKS:
aws-auth: винесено в окремий модуль, в параметрах самого модуляterraform-aws-modules/eksйого вже нема- з
terraform-aws-modules/eksвидалено параметриmanage_aws_auth_configmap,create_aws_auth_configmap,aws_auth_roles,aws_auth_users,aws_auth_accounts
- з
authentication_mode: додано значенняAPI_AND_CONFIG_MAPbootstrap_cluster_creator_admin_permissions: hardcoded уfalse- але можна передати
enable_cluster_creator_admin_permissionsзі значеннямtrue, хоча тут наче треба додавати Access Entry
- але можна передати
create_instance_profile: дефолтне значення змінилось зtrueнаfalse, аби відповідати змінам в Karpenter v0.32 (але в мене Karpenter і так вже 0.32 і все працює, тому тут змін не має бути)
- Karpenter:
irsa: видалено імена змінних з “irsa” – пачка перейменувань і декілька імен видалено взагаліcreate_instance_profile: дефолтне значення зtrueсталоfalseenable_karpenter_instance_profile_creation: видаленаiam_role_arn: сталоnode_iam_role_arnirsa_use_name_prefix: сталоiam_role_name_prefix
В документації по апдейту описано ще досить багато змін по Karpenter – але в мене зараз сам Karpenter версії 0.32 (див. Karpenter: Beta version – обзор змін та upgrade v0.30.0 на v0.32.1), модуль Terraform terraform-aws-modules/eks/aws//modules/karpenter зараз 19.21.0, і процес апгрейду самого EKS з 19 на 20 ніяк не вплинув на роботу Karpenter, тож їх можна оновлювати окремо – спочатку EKS, потім вже Karpenter.
План апгрейду
Що будемо робити:
- EKS: оновлення версії модулю з 19.21 => 20.0 з
API_AND_CONFIG_MAP- додавання
aws-authокремим модулем
- додавання
- Karpenter: оновлення версії модулю з 19.21 => 20.0
EKS: upgrade 19.21 на 20.0
Нам потрібно:
- видалити все, пов’язане з
aws_auth, в моєму випадку це:-
manage_aws_auth_configmap aws_auth_usersaws_auth_roles
-
- додати
authentication_modeзі значеннямAPI_AND_CONFIG_MAP(пізніше, для 21, треба буде замінити наAPI) - додати новий модуль для
aws_auth_rolesі перенестиaws_auth_usersтаaws_auth_rolesтуди
Щодо bootstrap_cluster_creator_admin_permissions та enable_cluster_creator_admin_permissions – так як цей кластер створювався з 19.21, то root-юзер там вже є, і він буде доданий в Access Entries разом з WorkerNodes IAM Role, тому тут нічого робити не треба.
А як перенести в access_entries наших юзерів і ролі – подивимось мабуть вже в наступному пості, бо зараз будемо робити тільки оновлення версії модуля зі збереженням aws-auth ConfigMap.
Для тесту Karpenter – створив тестовий деплой з одним подом, який затригерить створення WorkerNode, і до нього Ingress/ALB, на який йде постійний ping, аби впевнитись, що все буде працювати без даунтаймів.
NodeClaims зараз:
$ kk get nodeclaim NAME TYPE ZONE NODE READY AGE default-7hjz7 t3.small us-east-1a ip-10-0-45-183.ec2.internal True 53s
Окей, поїхали оновлювати EKS.
Поточний код Terraform та структура модулів
Аби далі краще розуміти момент з видаленням ресурс aws_auth з Terraform state – моя поточна структура файлів/модулів:
$ tree . . |-- Makefile |-- backend.hcl |-- backend.tf |-- envs | `-- test-1-28 | |-- VERSIONS.md | |-- backend.tf | |-- main.tf | |-- outputs.tf | |-- providers.tf | |-- test-1-28.tfvars | `-- variables.tf |-- modules | `-- atlas-eks | |-- configs | | `-- karpenter-nodepool.yaml.tmpl | |-- controllers.tf | |-- data.tf | |-- eks.tf | |-- iam.tf | |-- karpenter.tf | |-- outputs.tf | |-- providers.tf | `-- variables.tf |-- outputs.tf |-- providers.tf |-- variables.tf `-- versions.tf
Тут:
- в
envs/test-1-28/main.tfвикликається модуль зmodules/atlas-eksз необхідними параметрами – і виконуватиterraform state rmми будемо саме вenvs/test-1-28 - в
modules/atlas-eks/eks.tfвикликається модульterraform-aws-modules/eks/awsпотрібної версії – тут ми будемо робити зміни в коді
Виклик рутового модуля в файлі envs/test-1-28/main.tf виглядає так:
module "atlas_eks" {
source = "../../modules/atlas-eks"
# 'devops'
component = var.component
# 'ops'
aws_environment = var.aws_environment
# 'test'
eks_environment = var.eks_environment
env_name = local.env_name
# '1.28'
eks_version = var.eks_version
# 'endpoint_public_access', 'enabled_log_types'
eks_params = var.eks_params
# 'coredns = v1.10.1-eksbuild.6', 'kube_proxy = v1.28.4-eksbuild.1', etc
eks_addon_versions = var.eks_addon_versions
# AWS IAM Roles to be added to EKS aws-auth as 'masters'
eks_aws_auth_users = var.eks_aws_auth_users
# GitHub IAM Roles used in Workflows
eks_github_auth_roles = var.eks_github_auth_roles
# 'vpc-0fbaffe234c0d81ea'
vpc_id = var.vpc_id
helm_release_versions = var.helm_release_versions
# override default 'false' in the module's variables
# will trigger a dedicated module like 'eks_blueprints_addons_external_dns_test'
# with a domainFilters == variable.external_dns_zones.test == 'test.example.co'
external_dns_zone_test_enabled = true
# 'instance-family', 'instance-size', 'topology'
karpenter_nodepool = var.karpenter_nodepool
}
А код основного модуля – так:
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 19.21.0"
# is set in `locals` per env
# '${var.project_name}-${var.eks_environment}-${local.eks_version}-cluster'
# 'atlas-eks-test-1-28-cluster'
# passed from the root module
cluster_name = "${var.env_name}-cluster"
# passed from the root module
cluster_version = var.eks_version
# 'eks_params' passed from the root module
cluster_endpoint_public_access = var.eks_params.cluster_endpoint_public_access
# 'eks_params' passed from the root module
cluster_enabled_log_types = var.eks_params.cluster_enabled_log_types
# 'eks_addons_version' passed from the root module
cluster_addons = {
coredns = {
addon_version = var.eks_addon_versions.coredns
configuration_values = jsonencode({
replicaCount = 1
resources = {
requests = {
cpu = "50m"
memory = "50Mi"
}
}
})
}
kube-proxy = {
addon_version = var.eks_addon_versions.kube_proxy
configuration_values = jsonencode({
resources = {
requests = {
cpu = "20m"
memory = "50Mi"
}
}
})
}
vpc-cni = {
# old: eks_addons_version
# new: eks_addon_versions
addon_version = var.eks_addon_versions.vpc_cni
configuration_values = jsonencode({
env = {
ENABLE_PREFIX_DELEGATION = "true"
WARM_PREFIX_TARGET = "1"
AWS_VPC_K8S_CNI_EXTERNALSNAT = "true"
}
})
}
aws-ebs-csi-driver = {
addon_version = var.eks_addon_versions.aws_ebs_csi_driver
# iam.tf
service_account_role_arn = module.ebs_csi_irsa_role.iam_role_arn
}
}
# make as one complex var?
# passed from the root module
vpc_id = var.vpc_id
# for WorkerNodes
# passed from the root module
subnet_ids = data.aws_subnets.private.ids
# for the Control Plane
# passed from the root module
control_plane_subnet_ids = data.aws_subnets.intra.ids
manage_aws_auth_configmap = true
# `env_name` make too long name causing issues with IAM Role (?) names
# thus, use a dedicated `env_name_short` var
eks_managed_node_groups = {
# eks-default-dev-1-28
"${local.env_name_short}-default" = {
# `eks_managed_node_group_params` from defaults here
# number, e.g. 2
min_size = var.eks_managed_node_group_params.default_group.min_size
# number, e.g. 6
max_size = var.eks_managed_node_group_params.default_group.max_size
# number, e.g. 2
desired_size = var.eks_managed_node_group_params.default_group.desired_size
# list, e.g. ["t3.medium"]
instance_types = var.eks_managed_node_group_params.default_group.instance_types
# string, e.g. "ON_DEMAND"
capacity_type = var.eks_managed_node_group_params.default_group.capacity_type
# allow SSM
iam_role_additional_policies = {
AmazonSSMManagedInstanceCore = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}
taints = var.eks_managed_node_group_params.default_group.taints
update_config = {
max_unavailable_percentage = var.eks_managed_node_group_params.default_group.max_unavailable_percentage
}
}
}
# 'atlas-eks-test-1-28-node-sg'
node_security_group_name = "${var.env_name}-node-sg"
# 'atlas-eks-test-1-28-cluster-sg'
cluster_security_group_name = "${var.env_name}-cluster-sg"
# to use with EC2 Instance Connect
node_security_group_additional_rules = {
ingress_ssh_vpc = {
description = "SSH from VPC"
protocol = "tcp"
from_port = 22
to_port = 22
cidr_blocks = [data.aws_vpc.eks_vpc.cidr_block]
type = "ingress"
}
}
# 'atlas-eks-test-1-28'
node_security_group_tags = {
"karpenter.sh/discovery" = var.env_name
}
cluster_identity_providers = {
sts = {
client_id = "sts.amazonaws.com"
}
}
# passed from the root module
aws_auth_users = var.eks_aws_auth_users
# locals flatten() 'eks_masters_access_role' + 'eks_github_auth_roles'
aws_auth_roles = local.aws_auth_roles
}
Трохи більше про модулі Terraform див. у Terraform: модулі, Outputs та Variables та Terraform: створення модулю для збору логів AWS ALB в Grafana Loki.
Ролі/юзери для aws-auth формуються в locals зі змінних у variables.tf та envs/test-1-28/test-1-28.tfvars, всі з system:masters – до RBAC ми ще не дійшли:
locals {
# create a short name for node names in the 'eks_managed_node_groups'
# 'test-1-28'
env_name_short = "${var.eks_environment}-${replace(var.eks_version, ".", "-")}"
# 'eks_github_auth_roles' passed from the root module
github_roles = [for role in var.eks_github_auth_roles : {
rolearn = role
username = role
groups = ["system:masters"]
}]
# 'eks_masters_access_role' + 'eks_github_auth_roles'
# 'eks_github_auth_roles' from the root module
# 'aws_iam_role.eks_masters_access' from the iam.tf here
aws_auth_roles = flatten([
{
rolearn = aws_iam_role.eks_masters_access_role.arn
username = aws_iam_role.eks_masters_access_role.arn
groups = ["system:masters"]
},
local.github_roles
])
}
Антон в документації зробив класний Diff of Before (v19.21) vs After (v20.0) по змінам, то давайте спробуємо.
Зміни в authentication_mode та aws_auth
В модулі EKS найбільша зміна це переключення authentication_mode на API_AND_CONFIG_MAP.
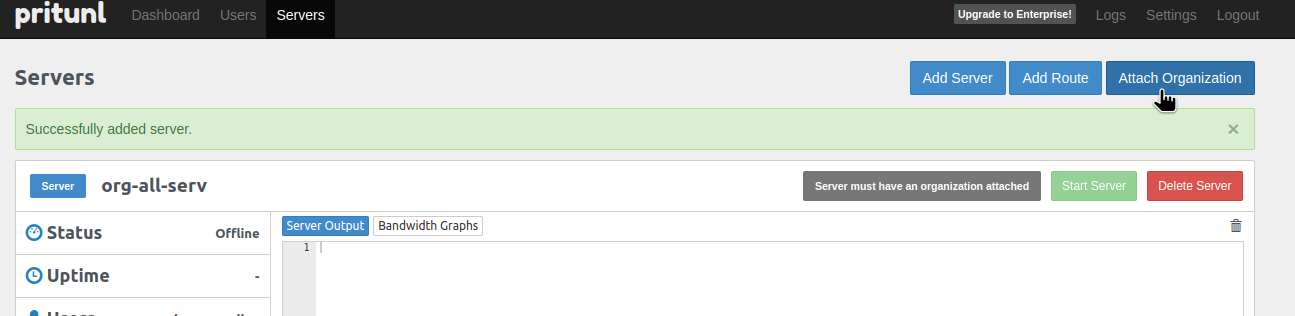
Кластер вже є, створений з версією 19.21.0.
Вкладка Access зараз виглядає так:

Access configuration == ConfgiMap, і в IAM access entries пусто.
Тепер робимо зміни в коді файла modules/atlas-eks/eks.tf:
- міняємо версію на
v20.0 - видаляємо все, що пов’язано з
aws_auth - додаємо
authentication_modeзі значеннямAPI_AND_CONFIG_MAP
Зміни поки виглядають так:
module "eks" {
source = "terraform-aws-modules/eks/aws"
#version = "~> 19.21.0"
version = "~> v20.0"
...
# removing for API_AND_CONFIG_MAP
#manage_aws_auth_configmap = true
# adding for API_AND_CONFIG_MAP
authentication_mode = "API_AND_CONFIG_MAP"
...
# removing for API_AND_CONFIG_MAP
# passed from the root module
#aws_auth_users = var.eks_aws_auth_users
# removing for API_AND_CONFIG_MAP
# locals flatten() 'eks_masters_access_role' + 'eks_github_auth_roles'
#aws_auth_roles = local.aws_auth_roles
}
Виконуємо terraform init, аби оновити модуль EKS:
... Initializing modules... Downloading registry.terraform.io/terraform-aws-modules/eks/aws 20.0.1 for atlas_eks.eks... - atlas_eks.eks in .terraform/modules/atlas_eks.eks - atlas_eks.eks.eks_managed_node_group in .terraform/modules/atlas_eks.eks/modules/eks-managed-node-group - atlas_eks.eks.eks_managed_node_group.user_data in .terraform/modules/atlas_eks.eks/modules/_user_data - atlas_eks.eks.fargate_profile in .terraform/modules/atlas_eks.eks/modules/fargate-profile ...
Глянемо aws-auth зараз – заодно будемо мати його “бекап” в YAML:
$ kk -n kube-system get cm aws-auth -o yaml
apiVersion: v1
data:
mapAccounts: |
[]
mapRoles: |
- "groups":
- "system:bootstrappers"
- "system:nodes"
"rolearn": "arn:aws:iam::492***148:role/test-1-28-default-eks-node-group-20240705095955197900000003"
"username": "system:node:{{EC2PrivateDNSName}}"
- "groups":
- "system:masters"
"rolearn": "arn:aws:iam::492***148:role/atlas-eks-test-1-28-masters-access-role"
"username": "arn:aws:iam::492***148:role/atlas-eks-test-1-28-masters-access-role"
- "groups":
- "system:masters"
"rolearn": "arn:aws:iam::492***148:role/atlas-test-ops-1-28-github-access-role"
"username": "arn:aws:iam::492***148:role/atlas-test-ops-1-28-github-access-role"
...
mapUsers: |
- "groups":
- "system:masters"
"userarn": "arn:aws:iam::492***148:user/arseny"
"username": "arseny"
...
Виконуємо terraform plan, і бачимо, що дійсно – aws-auth буде видалено:

Отже, якщо ми хочемо його залишити – то треба додати новий модуль з terraform-aws-modules/eks/aws//modules/aws-auth.
Приклад в документації виглядає так:
module "eks" {
source = "terraform-aws-modules/eks/aws//modules/aws-auth"
version = "~> 20.0"
manage_aws_auth_configmap = true
aws_auth_roles = [
{
rolearn = "arn:aws:iam::66666666666:role/role1"
username = "role1"
groups = ["custom-role-group"]
},
]
aws_auth_users = [
{
userarn = "arn:aws:iam::66666666666:user/user1"
username = "user1"
groups = ["custom-users-group"]
},
]
}
В моєму випадку – для aws_auth_roles та aws_auth_users використовуємо значення з locals:
module "aws_auth" {
source = "terraform-aws-modules/eks/aws//modules/aws-auth"
version = "~> 20.0"
manage_aws_auth_configmap = true
aws_auth_roles = local.aws_auth_roles
aws_auth_users = var.eks_aws_auth_users
}
Виконуємо ще раз terraform init, ще раз робимо terraform plan, і тепер маємо новий ресурс для aws-auth:

А старий все ще буде видалятись – тобто, спочатку Terraform його видалить, а потім створить заново, просто з новим іменем та ID в стейті:

Аби Terraform не видалив ресурс aws-auth з кластеру – нам потрібно видалити його зі state-файла: тоді Terraform не буде нічого знати про цей ConfgiMap, а при створенні з нашого module "aws_auth" – просто створить записи у своєму state file, але не буде нічого виконувати в Kubernetes.
Important: про всяк випадок – зробіть бекап відповідного state-file, бо будемо робити state rm.
Видалення aws_auth з Terraform State
В моєму випадку треба перейти в каталог з оточенням, envs/test-1-28, і вже звідти виконувати операції зі state.
Note: уточнюю, бо випадково все ж таки видалив aws-auth ConfigMap з production-кластеру. Але просто заново виконав terraform apply на ньому – і все без проблем відновилось.
Знаходимо ім’я модуля, як він записаний в стейті:
$ cd envs/test-1-28/ $ terraform state list | grep aws_auth module.atlas_eks.module.eks.kubernetes_config_map_v1_data.aws_auth[0]
Можна перевірити з terraform plan output, який робили вище, аби впевнитись, що видаляємо саме його:
... module.atlas_eks.module.eks.kubernetes_config_map_v1_data.aws_auth[0]: Refreshing state... [id=kube-system/aws-auth] ...
Тут ім’я module.atlas_eks – саме так, як задано в моєму модулі EKS у файлі envs/test-1-28/main.tf:
module "atlas_eks" {
source = "../../modules/atlas-eks"
...
З terraform state rm видаляємо запис про ресурс:
$ terraform state rm 'module.atlas_eks.module.eks.kubernetes_config_map_v1_data.aws_auth[0]' Acquiring state lock. This may take a few moments... Removed module.atlas_eks.module.eks.kubernetes_config_map_v1_data.aws_auth[0] Successfully removed 1 resource instance(s). Releasing state lock. This may take a few moments...
Виконуємо terraform plan ще раз, і тепер нема ніяких “destroy” – тільки створення module.atlas_eks.module.aws_auth.kubernetes_config_map_v1_data.aws_auth[0]:
# module.atlas_eks.module.aws_auth.kubernetes_config_map_v1_data.aws_auth[0] will be created
+ resource "kubernetes_config_map_v1_data" "aws_auth" {
...
Plan: 1 to add, 10 to change, 0 to destroy.
Виконуємо terraform apply:
... module.atlas_eks.module.eks.aws_eks_cluster.this[0]: Still modifying... [id=atlas-eks-test-1-28-cluster, 50s elapsed] module.atlas_eks.module.eks.aws_eks_cluster.this[0]: Modifications complete after 52s [id=atlas-eks-test-1-28-cluster] ... module.atlas_eks.module.aws_auth.kubernetes_config_map_v1_data.aws_auth[0]: Creation complete after 6s [id=kube-system/aws-auth] ...
Перевіряємо сам ConfigMap – ніяк змін:
$ kk -n kube-system get cm aws-auth -o yaml
apiVersion: v1
data:
mapAccounts: |
[]
mapRoles: |
- "groups":
- "system:masters"
"rolearn": "arn:aws:iam::492***148:role/atlas-eks-test-1-28-masters-access-role"
"username": "arn:aws:iam::492***148:role/atlas-eks-test-1-28-masters-access-role"
...
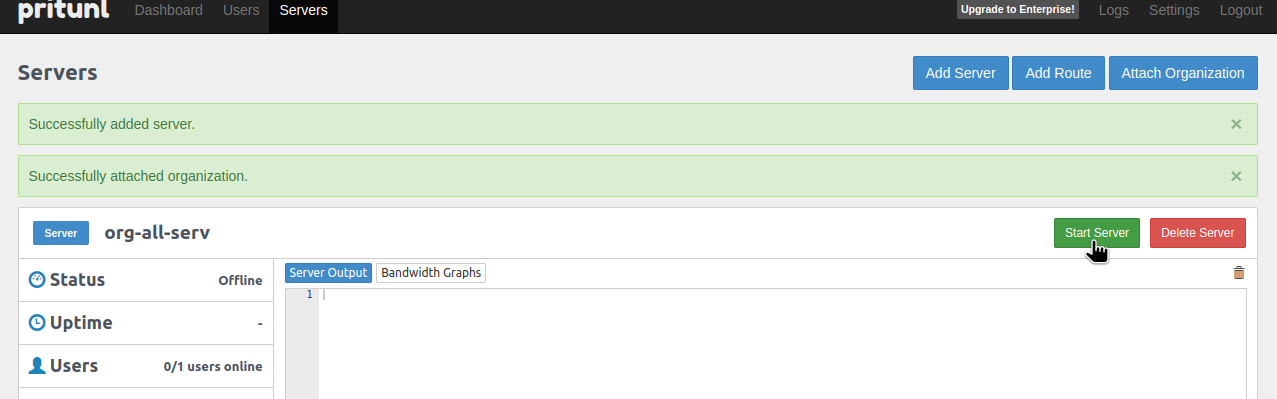
І глянемо, що змінилось в AWS Console > EKS > ClusterName > Access:

Тепер у нас тут значення EKS API and ConfigMap та дві Access Entries – для WorkerNodes, та для рутового юзера.
Перевіряємо NodeClaims – Karpenter працює?
Можна поскейлити ворклоади, аби впевнитись:
$ kk -n test-fastapi-app-ns scale deploy fastapi-app --replicas=20 deployment.apps/fastapi-app scaled
Логи Karpenter – все добре:
...
karpenter-8444499996-9njx6:controller {"level":"INFO","time":"2024-07-05T12:27:41.527Z","logger":"controller.provisioner","message":"created nodeclaim","commit":"a70b39e","nodepool":"default","nodeclaim":"default-59ms4","requests":{"cpu":"1170m","memory":"942Mi","pods":"8"},"instance-types":"c5.large, r5.large, t3.large, t3.medium, t3.small"}
...
І нові NodeClaims створились:
$ kk get nodeclaim NAME TYPE ZONE NODE READY AGE default-59ms4 t3.small us-east-1a ip-10-0-46-72.ec2.internal True 59s default-5fc2p t3.small us-east-1a ip-10-0-39-114.ec2.internal True 7m6s
Тут в принципі все – можемо переходити до апгрейду модуля з Karpenter.
Karpenter: upgrade 19.21 на 20.0
Також є Karpenter Diff of Before (v19.21) vs After (v20.0), але дещо довелося міняти вручну.
Тут я пішов “методом тика” – робимо terraform plan, дивимось, що не так в результатах – фіксимо – ше раз plan. Пройшло без проблем, хоча з деякими помилками – подивимось на них.
Поточний код Terraform для Karpenter
Поточний код в modules/atlas-eks/karpenter.tf:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
version = "19.21.0"
cluster_name = module.eks.cluster_name
irsa_oidc_provider_arn = module.eks.oidc_provider_arn
irsa_namespace_service_accounts = ["karpenter:karpenter"]
create_iam_role = false
iam_role_arn = module.eks.eks_managed_node_groups["${local.env_name_short}-default"].iam_role_arn
irsa_use_name_prefix = false
# In v0.32.0/v1beta1, Karpenter now creates the IAM instance profile
# so we disable the Terraform creation and add the necessary permissions for Karpenter IRSA
enable_karpenter_instance_profile_creation = true
}
Деякі outputs з модулю Karpenter використовуються в helm_release – module.karpenter.irsa_arn:
resource "helm_release" "karpenter" {
namespace = "karpenter"
create_namespace = true
name = "karpenter"
repository = "oci://public.ecr.aws/karpenter"
repository_username = data.aws_ecrpublic_authorization_token.token.user_name
repository_password = data.aws_ecrpublic_authorization_token.token.password
chart = "karpenter"
version = var.helm_release_versions.karpenter
values = [
<<-EOT
replicas: 1
settings:
clusterName: ${module.eks.cluster_name}
clusterEndpoint: ${module.eks.cluster_endpoint}
interruptionQueueName: ${module.karpenter.queue_name}
featureGates:
drift: true
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: ${module.karpenter.irsa_arn}
EOT
]
depends_on = [
helm_release.karpenter_crd
]
}
Апгрейд модулю Karpenter
Для початку міняємо версію на 20.0:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
#version = "19.21.0"
version = "20.0"
...
Робимо terraform init та terraform plan, і дивимось на помилки:
... An argument named "iam_role_arn" is not expected here. ... │ An argument named "irsa_use_name_prefix" is not expected here. ... │ An argument named "enable_karpenter_instance_profile_creation" is not expected here.
Міняємо імена параметрів, і з Karpenter Diff of Before (v19.21) vs After (v20.0) додаємо створення ресурсів для IRSA (IAM Role for ServiceAccounts – роль для Karpenter), бо вона у нас є в поточному сетапі:
iam_role_arn=>node_iam_role_arnirsa_use_name_prefix– тут трохи не зрозумів, бо по документації вона сталаiam_role_name_prefix, алеiam_role_name_prefixв inputs нема взагалі, тому просто закоментивiam_role_name_prefix– теж не поняв – по документації вона сталаnode_iam_role_name_prefix, але знов-таки – такої нема, тому теж просто закоментивenable_karpenter_instance_profile_creation: видалена
Тепер код виглядає так:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
#version = "19.21.0"
version = "20.0"
cluster_name = module.eks.cluster_name
irsa_oidc_provider_arn = module.eks.oidc_provider_arn
irsa_namespace_service_accounts = ["karpenter:karpenter"]
create_iam_role = false
# 19 > 20
#iam_role_arn = module.eks.eks_managed_node_groups["${local.env_name_short}-default"].iam_role_arn
node_iam_role_arn = module.eks.eks_managed_node_groups["${local.env_name_short}-default"].iam_role_arn
# 19 > 20
#irsa_use_name_prefix = false
#iam_role_name_prefix = false
#node_iam_role_name_prefix = false
# 19 > 20
#enable_karpenter_instance_profile_creation = true
# 19 > 20
enable_irsa = true
create_instance_profile = true
# 19 > 20
# To avoid any resource re-creation
iam_role_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_role_description = "Karpenter IAM role for service account"
iam_policy_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_policy_description = "Karpenter IAM role for service account"
}
Ще раз робимо terraform plan, і тепер маємо іншу помилку, тепер вже в helm_release:
... This object does not have an attribute named "irsa_arn". ...
Бо irsa_arn тепер стала iam_role_arn, міняємо теж:
...
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: ${module.karpenter.iam_role_arn}
EOT
...
Ще раз робимо terraform plan – тепер маємо іншу проблему, з довжиною імені ролі:
...
Plan: 1 to add, 3 to change, 0 to destroy.
╷
│ Error: expected length of name_prefix to be in the range (1 - 38), got KarpenterIRSA-atlas-eks-test-1-28-cluster-
│
│ with module.atlas_eks.module.karpenter.aws_iam_role.controller[0],
│ on .terraform/modules/atlas_eks.karpenter/modules/karpenter/main.tf line 69, in resource "aws_iam_role" "controller":
│ 69: name_prefix = var.iam_role_use_name_prefix ? "${var.iam_role_name}-" : null
...
Тому задав iam_role_use_name_prefix = false, і тепер весь оновлений код виглядає так:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
#version = "19.21.0"
version = "20.0"
cluster_name = module.eks.cluster_name
irsa_oidc_provider_arn = module.eks.oidc_provider_arn
irsa_namespace_service_accounts = ["karpenter:karpenter"]
# 19 > 20
#create_iam_role = false
create_node_iam_role = false
# 19 > 20
#iam_role_arn = module.eks.eks_managed_node_groups["${local.env_name_short}-default"].iam_role_arn
node_iam_role_arn = module.eks.eks_managed_node_groups["${local.env_name_short}-default"].iam_role_arn
# 19 > 20
#irsa_use_name_prefix = false
#iam_role_name_prefix = false
#node_iam_role_name_prefix = false
# 19 > 20
#enable_karpenter_instance_profile_creation = true
# 19 > 20
enable_irsa = true
create_instance_profile = true
# To avoid any resource re-creation
iam_role_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_role_description = "Karpenter IAM role for service account"
iam_policy_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_policy_description = "Karpenter IAM role for service account"
# expected length of name_prefix to be in the range (1 - 38), got KarpenterIRSA-atlas-eks-test-1-28-cluster-
iam_role_use_name_prefix = false
}
...
resource "helm_release" "karpenter" {
...
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: ${module.karpenter.iam_role_arn}
EOT
]
...
}
Виконуємо terraform plan – нічого не має видалитись:
... Plan: 1 to add, 5 to change, 0 to destroy.
В плані у нас є:
- буде додано
module.atlas_eks.module.karpenter.aws_eks_access_entry.node: – трохи забігаючи наперед – це треба буде відключити, зараз побачимо, чому - в
module.atlas_eks.module.karpenter.aws_iam_policy.controller: будуть оновлені політики – тут наче все ОК. - в
module.atlas_eks.module.karpenter.aws_iam_role.controller: буде додано правилоAllowзpods.eks.amazonaws.com– для роботи з EKS Pod Identities
Наче виглядає ОК – давайте деплоїти і тестити.
Логи Karpenter запущені, NodeClaim зараз вже є, пінги на тестовий Ingress/ALB йдуть.
EKS: CreateAccessEntry – access entry resource is already in use on this cluster
Робимо terraform apply, і – як неочікувано! – маємо помилку:
... │ Error: creating EKS Access Entry (atlas-eks-test-1-28-cluster:arn:aws:iam::492***148:role/test-1-28-default-eks-node-group-20240710092944387500000003): operation error EKS: CreateAccessEntry, https response error StatusCode: 409, RequestID: 004e014d-ebbb-4c60-919b-fb79629bf1ff, ResourceInUseException: The specified access entry resource is already in use on this cluster.
Тому що “EKS automatically adds access entries for the roles used by EKS managed node groups and Fargate profiles“, див. authentication_mode = “API_AND_CONFIG_MAP”.
І ми вже бачили Access Entry для WorkerNodes, коли виконували апгрейд версії модулю EKS:

Якщо використовуються self-managed NodeGroups – то для них в terraform-aws-eks/modules/self-managed-node-group/variables.tf була додана змінна create_access_entry з дефолтним значенням true.
Для Kaprneter теж є нова змінна create_access_entry, і вона теж з дефолтним значенням true.
Задаємо її в false, бо в моєму випадку ноди створенні з Karpenter використовують ту саму IAM Role, що ноди з module.eks.eks_managed_node_groups:
...
# To avoid any resource re-creation
iam_role_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_role_description = "Karpenter IAM role for service account"
iam_policy_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_policy_description = "Karpenter IAM role for service account"
# expected length of name_prefix to be in the range (1 - 38), got KarpenterIRSA-atlas-eks-test-1-28-cluster-
iam_role_use_name_prefix = false
# Error: creating EKS Access Entry ResourceInUseException: The specified access entry resource is already in use on this cluster.
create_access_entry = false
}
...
Ще раз виконуємо terraform apply – і тепер все пройшло без помилок.
В логах Karpenter взагалі нічого, тобто Kubernetes Pod не перестворювався, пінги на тестову апку продовжують йти.
Можна її поскейлити, аби тригернути створення нових Karpenter NodeClaims:
$ kk -n test-fastapi-app-ns scale deploy fastapi-app --replicas=10 deployment.apps/fastapi-app scaled
І вони створились без проблем:
...
karpenter-649945c6c5-lj2xh:controller {"level":"INFO","time":"2024-07-10T11:33:34.507Z","logger":"controller.nodeclaim.lifecycle","message":"launched nodeclaim","commit":"a70b39e","nodeclaim":"default-pn64t","provider-id":"aws:///us-east-1a/i-0316a99cd2d6e172c","instance-type":"t3.small","zone":"us-east-1a","capacity-type":"spot","allocatable":{"cpu":"1930m","ephemeral-storage":"17Gi","memory":"1418Mi","pods":"110"}}
Наче виглядає як все працює.
Фінальний Terraform код для EKS та Karpenter
В результаті всіх змін код буде виглядати так.
Для EKS:
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> v20.0"
# is set in `locals` per env
# '${var.project_name}-${var.eks_environment}-${local.eks_version}-cluster'
# 'atlas-eks-test-1-28-cluster'
# passed from a root module
cluster_name = "${var.env_name}-cluster"
# passed from a root module
cluster_version = var.eks_version
# 'eks_params' passed from a root module
cluster_endpoint_public_access = var.eks_params.cluster_endpoint_public_access
# 'eks_params' passed from a root module
cluster_enabled_log_types = var.eks_params.cluster_enabled_log_types
# 'eks_addons_version' passed from a root module
cluster_addons = {
coredns = {
addon_version = var.eks_addon_versions.coredns
configuration_values = jsonencode({
replicaCount = 1
resources = {
requests = {
cpu = "50m"
memory = "50Mi"
}
}
})
}
kube-proxy = {
addon_version = var.eks_addon_versions.kube_proxy
configuration_values = jsonencode({
resources = {
requests = {
cpu = "20m"
memory = "50Mi"
}
}
})
}
vpc-cni = {
# old: eks_addons_version
# new: eks_addon_versions
addon_version = var.eks_addon_versions.vpc_cni
configuration_values = jsonencode({
env = {
ENABLE_PREFIX_DELEGATION = "true"
WARM_PREFIX_TARGET = "1"
AWS_VPC_K8S_CNI_EXTERNALSNAT = "true"
}
})
}
aws-ebs-csi-driver = {
addon_version = var.eks_addon_versions.aws_ebs_csi_driver
# iam.tf
service_account_role_arn = module.ebs_csi_irsa_role.iam_role_arn
}
}
# make as one complex var?
# passed from a root module
vpc_id = var.vpc_id
# for WorkerNodes
# passed from a root module
subnet_ids = data.aws_subnets.private.ids
# for the ControlPlane
# passed from a root module
control_plane_subnet_ids = data.aws_subnets.intra.ids
# adding for API_AND_CONFIG_MAP
# TODO: change to the "API" only after adding aws_eks_access_entry && aws_eks_access_policy_association
authentication_mode = "API_AND_CONFIG_MAP"
# `env_name` make too long name causing issues with IAM Role (?) names
# thus, use a dedicated `env_name_short` var
eks_managed_node_groups = {
# eks-default-dev-1-28
"${local.env_name_short}-default" = {
# `eks_managed_node_group_params` from defaults here
# number, e.g. 2
min_size = var.eks_managed_node_group_params.default_group.min_size
# number, e.g. 6
max_size = var.eks_managed_node_group_params.default_group.max_size
# number, e.g. 2
desired_size = var.eks_managed_node_group_params.default_group.desired_size
# list, e.g. ["t3.medium"]
instance_types = var.eks_managed_node_group_params.default_group.instance_types
# string, e.g. "ON_DEMAND"
capacity_type = var.eks_managed_node_group_params.default_group.capacity_type
# allow SSM
iam_role_additional_policies = {
AmazonSSMManagedInstanceCore = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}
taints = var.eks_managed_node_group_params.default_group.taints
update_config = {
max_unavailable_percentage = var.eks_managed_node_group_params.default_group.max_unavailable_percentage
}
}
}
# 'atlas-eks-test-1-28-node-sg'
node_security_group_name = "${var.env_name}-node-sg"
# 'atlas-eks-test-1-28-cluster-sg'
cluster_security_group_name = "${var.env_name}-cluster-sg"
# to use with EC2 Instance Connect
node_security_group_additional_rules = {
ingress_ssh_vpc = {
description = "SSH from VPC"
protocol = "tcp"
from_port = 22
to_port = 22
cidr_blocks = [data.aws_vpc.eks_vpc.cidr_block]
type = "ingress"
}
}
# 'atlas-eks-test-1-28'
node_security_group_tags = {
"karpenter.sh/discovery" = var.env_name
}
cluster_identity_providers = {
sts = {
client_id = "sts.amazonaws.com"
}
}
}
Для Karpenter:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
version = "20.0"
cluster_name = module.eks.cluster_name
irsa_oidc_provider_arn = module.eks.oidc_provider_arn
irsa_namespace_service_accounts = ["karpenter:karpenter"]
create_node_iam_role = false
node_iam_role_arn = module.eks.eks_managed_node_groups["${local.env_name_short}-default"].iam_role_arn
enable_irsa = true
create_instance_profile = true
# backward compatibility with 19.21.0
# see https://github.com/terraform-aws-modules/terraform-aws-eks/blob/master/docs/UPGRADE-20.0.md#karpenter-diff-of-before-v1921-vs-after-v200
iam_role_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_role_description = "Karpenter IAM role for service account"
iam_policy_name = "KarpenterIRSA-${module.eks.cluster_name}"
iam_policy_description = "Karpenter IAM role for service account"
iam_role_use_name_prefix = false
# already created during EKS 19 > 20 upgrade with 'authentication_mode = "API_AND_CONFIG_MAP"'
create_access_entry = false
}
...
resource "helm_release" "karpenter" {
namespace = "karpenter"
create_namespace = true
name = "karpenter"
repository = "oci://public.ecr.aws/karpenter"
repository_username = data.aws_ecrpublic_authorization_token.token.user_name
repository_password = data.aws_ecrpublic_authorization_token.token.password
chart = "karpenter"
version = var.helm_release_versions.karpenter
values = [
<<-EOT
replicas: 1
settings:
clusterName: ${module.eks.cluster_name}
clusterEndpoint: ${module.eks.cluster_endpoint}
interruptionQueueName: ${module.karpenter.queue_name}
featureGates:
drift: true
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: ${module.karpenter.iam_role_arn}
EOT
]
depends_on = [
helm_release.karpenter_crd
]
}
Ще треба буде оновити сам Karpenter з 0.32 на 0.37.
Підготовка до апгрейду з v20.0 на v21.0
Див. Upcoming Changes Planned in v21.0.
Що зміниться?
Основне – це зміни з aws-auth: модуль буде видалено, тому варто відразу вже переходити на authentication_mode = API, а для цього нам треба перенести всіх наших юзерів та ролі з aws-auth ConfigMap в EKS Access Entries.
Крім того, варто вже переходити на нову систему роботи з ServiceAccounts – EKS Pod Identities.
І виходить, що зміни буде дві:
- в
aws-authє записи для IAM Roles та IAM Users: їх треба створити як EKS Access Entries- в Terraform для цього маємо нові ресурси
aws_eks_access_entryтаaws_eks_access_policy_association
- в Terraform для цього маємо нові ресурси
- окремо маємо кілька IAM Roles, які використовуються в ServiceAccounts – їх треба перенести в Pod Identity associations
- в Terraform для цього маємо новий ресурс
aws_eks_pod_identity_association - а OIDC схоже не потрібен буде зовсім
- в Terraform для цього маємо новий ресурс
Але все це я вже буду робити новим проектом в окремому репозиторії, який буде займатись IAM та доступом до EKS і RDS. Можливо, опишу в наступному пості.
![]()








































 Перший пост цієї “серії” (яка взагалі не планувалась як серія) – я написав ще у 2022, коли вперше довелося почати розбиратись з електрикою і тим, як забезпечити електрохарчування вдома під час відключень:
Перший пост цієї “серії” (яка взагалі не планувалась як серія) – я написав ще у 2022, коли вперше довелося почати розбиратись з електрикою і тим, як забезпечити електрохарчування вдома під час відключень:




























 Маємо API-сервіс в Kubernetes, який періодично видає 502, 503, 504 помилки.
Маємо API-сервіс в Kubernetes, який періодично видає 502, 503, 504 помилки.