![]() Маємо AWS EKS з Karpenter, який займається автоскелінгом EC2 – див. AWS: знайомство з Karpenter для автоскейлінгу в EKS, та встановлення з Helm-чарту.
Маємо AWS EKS з Karpenter, який займається автоскелінгом EC2 – див. AWS: знайомство з Karpenter для автоскейлінгу в EKS, та встановлення з Helm-чарту.
В цілому проблем з ним поки не маємо, але в будь-якому разі потрібен його моніторинг, для чого Karpeneter “з коробки” надає метрики, які можемо використати в Grafana та Prometheus/VictoriaMetrics алертах.
Тож що будемо робити сьогодні:
- додамо збір метрик до VictoriaMetrics
- подивимось які метрики нам можуть бути корисні
- додамо Grafana Dashboard для WorkerNodes + Karpenter
Взагалі пост вийшов більше про Grafana, ніж про Karpenter, але в графіках в основному використовуються метрики саме від Karpenter.
Окремо треба буде створити алерти – але це вже іншим разом. Маючи уяву про доступні метрики Karpenter та Prometheus-запити для графіків в Grafana проблем з алертами не має бути.
Поїхали.
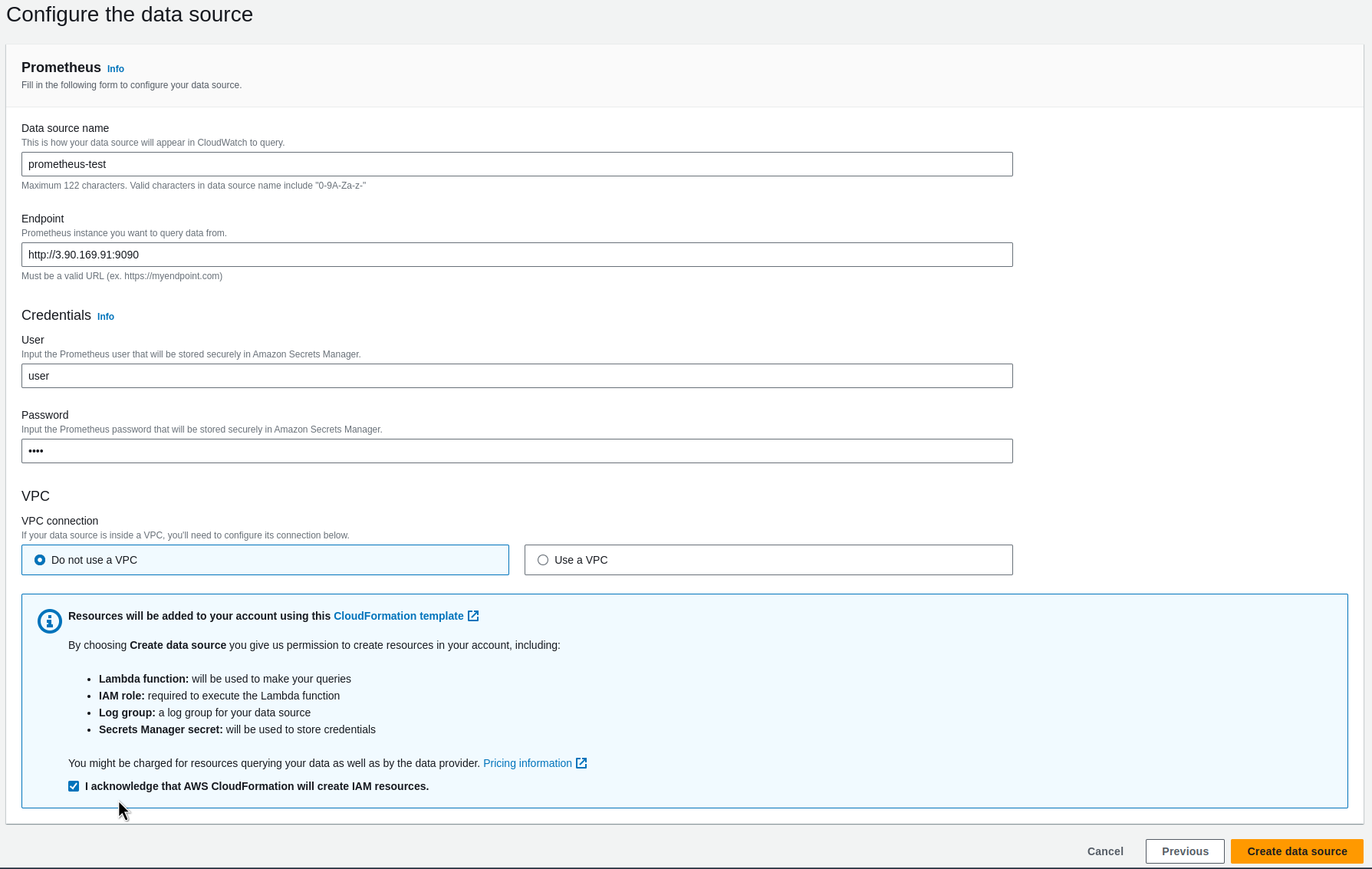
Збір метрик Karpenter з VictoriaMetrics VMAgent
Наша VictoriaMetrics деплоїться власним чартом, див. VictoriaMetrics: створення Kubernetes monitoring stack з власним Helm-чартом.
Для додавання нового target оновлюємо values цього чарту – додаємо ендпоінт karpenter.karpenter.svc.cluster.local:8000:
...
vmagent:
enabled: true
spec:
replicaCount: 1
inlineScrapeConfig: |
- job_name: yace-exporter
metrics_path: /metrics
static_configs:
- targets: ["yace-service:5000"]
- job_name: github-exporter
metrics_path: /
static_configs:
- targets: ["github-exporter-service:8000"]
- job_name: karpenter
metrics_path: /metrics
static_configs:
- targets: ["karpenter.karpenter.svc.cluster.local:8000"]
...
Деплоїмо, і для перевірки таргету відкриваємо порт до VMAgent:
$ kk port-forward svc/vmagent-vm-k8s-stack 8429
Перевіряємо таргети:

Для перевірки метрик відкриваємо порт до VMSingle:
$ kk port-forward svc/vmsingle-vm-k8s-stack 8429
І шукаємо дані по запиту {job="karpenter"}:

Корисні метрики Karpenter
Тепер глянемо, які саме метрики нам можуть бути корисні.
Але перед тим, як розбиратись з метриками – давайте проговоримо основні поняття в Karpenter (окрім очевидних типу Node, NodeClaim або Pod):
- controller: компонент Karpenter, який віподвідає за певний аспект його роботи, наприклад, Pricing controller відповідає за перевірку вартості інстансів, а Disruption Controller відповідає за керування процесом зміни стану WorkerNodes
- reconciliation (“узгодження”): процес, коли Karpenter виконує узгодження бажаного стану (desired state) и реального (current state), наприклад – при появі Pod, для якого нема вільних ресурсів на існуючих WorkerNodes, Karpenter створить нову Node, на якій зможе запустись Pod, і його статус стане Running – тоді reconciliation процес статусу цього поду завершиться
- consistency (“когерентність” або “узгодженість”): процес внутрішнього контролю і забезпечення відповідності необхідним параметрам (наприклад, перевірка того, що створена WorkerNode має диск розміром саме 30 GB)
- disruption: процес зміни WorkerNodes в кластері, наприклад перестворення WorkerNode (для заміни на інстанс з більшою кількістю CPU або Memory), або видалення існуючої ноди, на якій нема запущених Pods
- interruption: випадки, коли EC2 буде зупинено у зв’язку з помилками на hardware, виключення інстансу (коли робиться Stop або Terminate instance), або у випадку зі Spot – коли AWS “відкликає” інстанс; ці евенти йдуть на віподвідну SQS, звідки їх отримує Karpenter, щоб запустити новий інстанс на заміну
- provisioner: компонент, який аналізує поточні потреби кластера, такі як запити на створення нових Pod, визначає, які ресурси потрібно створити (WorkerNodes), і ініціює створення нових (взагалі, Provisioner був замінений на NodePool, але окремі метрики по ньому залишились)
Тут я зібрав тільки ті метрики, які мені вважаються найбільш корисними в даний момент, але варто самому передивитись документацію Inspect Karpenter Metrics і є трохи більше деталей у документації Datadog:
Controller:
controller_runtime_reconcile_errors_total: кількість помилок при оновленні WorkerNodes (тобто в роботі Disruption Controller при виконанні операцій по Expiration, Drift, Interruption та Consolidation) – корисно мати графік або алертcontroller_runtime_reconcile_total: загальна кількість таких операції – корисно мати уяву про активність Karpenter і, можливо, мати алерт, якщо це відбувається надто часто
Сonsistency:
karpenter_consistency_errors: виглядає як корисна метрика, але в мене вона пуста (принаймні поки що)
Disruption:
karpenter_disruption_actions_performed_total: загальна кількість дій по disruption (видалення/перестворення WorkerNodes), в лейблах метрик вказується disruption method – корисно мати уяву про активність Karpenter і, можливо, мати алерт, якщо це відбувається надто частоkarpenter_disruption_eligible_nodes: загальна кількість WorkerNodes для виконання disruption (видалення/перестворення WorkerNodes), в лейблах метрик вказується disruption methodkarpenter_disruption_replacement_nodeclaim_failures_total: загальна кількість помилок при створенні нових WorkerNodes на заміну старим, в лейблах метрик вказується disruption method
Interruption:
karpenter_interruption_actions_performed: кількість дій за повідомленнями про EC2 Interruption (з SQS) – можливо має сенс, але в мене за тиждень збору метрик такого не траплялось
Nodeclaims:
karpenter_nodeclaims_created: загальна кількість створенних NodeClaims з лейблами по причині створення та відповідним NodePoolkarpenter_nodeclaims_terminated: аналогічно, але по видаленним NodeClaims
Provisioner:
karpenter_provisioner_scheduling_duration_seconds: можливо, має сенс моніторити, бо якщо цей показник буде рости але буде надто великим – то це може бути ознакою проблем; проте, в мене за тиждень хістограмаkarpenter_provisioner_scheduling_duration_seconds_bucketнезмінна
Nodepool:
karpenter_nodepool_limit: ліміт CPU/Memory NodePool, заданий в його Provisioner (spec.limits)karpenter_nodepool_usage: використання ресурсів NodePool – CPU, Memory, Volumes, Pods
Nodes:
karpenter_nodes_allocatable: інформація по існуючим WorkerNodes – тип, кількість CPU/Memory, Spot/On-Demand, Availability Zone, etc- можна мати графік по кількості Spot/On-Demand інстансів
- можна використовувати для отримання даних по доступних ресурсах ЦПУ/пам’яті –
sum(karpenter_nodes_allocatable) by (resource_type)
karpenter_nodes_created: загальна кількість створенних нодkarpenter_nodes_terminated: загальна кількість видалених нодkarpenter_nodes_total_pod_limits: загальна кількість всіх Pod Limits (окрім DaemonSet) на кожній WorkerNodekarpenter_nodes_total_pod_requests: загальна кількість всіх Pod Requests (окрім DaemonSet) на кожній WorkerNode
Pods:
karpenter_pods_startup_time_seconds: час від сторення поду до його переходу в статус Running (сума по всім подам)karpenter_pods_state: досить корисна метрика, бо в лейблах має статус поду, на якій він ноді запущений, неймспейс тощо
Cloudprovider:
karpenter_cloudprovider_errors_total: кількість помилок від AWSkarpenter_cloudprovider_instance_type_price_estimate: вартість інстансів по типам – можна на дашборді виводити вартість compute-потужностей кластеру
Створення Grafana dashboard
Для Grafana є готовий дашборд – Display all useful Karpenter metrics, але він якось зовсім не інформативний. Втім, з нього можна взяти деякі графіки та/або запити.
Зараз в мене є власна борда для перевірки статусу та ресурів по кожній окремій WorkerNode:

В графіках цієї борди є Data Links на дашборду з деталями по на дашборду з інформацією по конкретному Pod:

Графіки ALB внизу будуються з логів в Loki.
Тож що зробимо: нову борду, на якій будуть всі WorkerNodes, а в Data Links графіків цієї борди зробимо лінки на перший дашборд.
Тоді буде непогана навігація:
- загальна борда по всім WorkerNodes з можливістю перейти на дашборду з більш детальною інформацією по конкретній ноді
- на борді по конкретній ноді вже буде інформація по подах на цій ноді, і data links на борду по конкретному поду
Планування дашборди
Давайте поміркуємо, що саме ми б хотіли бачити на новій борді.
Фільтри/змінні:
- мати змогу бачити всі WorkerNodes разом, або обрати одну чи кілька окремо
- мати змогу бачити ресурси по конкретним Namespaces або Applications (в моєму випадку кожен сервіс має власний неймспейс, тому використаємо їх)
Далі, інформація по нодам:
- загальна інформаця по нодам:
- кількість нод
- кількість подів
- кількість ЦПУ
- кількість Мем
- spot vs on-deman ratio
- вартість всіх нод за добу
- відсотки від allocatable використано:
- cpu – від pods requested
- mem – від pods requested
- pods allocation
- реальне використання ресурсів – графіки по нодам:
- CPU та Memory подами
- кількість подів – процент від максимума на ноді
- створено-видалено нод (by Karpenter)
- вартість нод
- процент EBS used
- network – in/our byes/sec
По Karpenter:
controller_runtime_reconcile_errors_total– загальна кількість помилокkarpenter_provisioner_scheduling_duration_seconds– час створення подівkarpenter_cloudprovider_errors_total– загальна кількість помилок
Looks like a plan?
Поїхали творити.
Створення дашборди
Робимо нову борду, задаємо основні параметри:

Grafana variables
Нам потрібні дві змінні – по нодам і неймпспейсам.
Ноди можемо вибрати з karpenter_nodes_allocatable, неймспейси отримати з karpenter_pods_state.
Створюємо першу змінну – node_name, включаємо можливість вибору All або Multi-value:


Створюємо другу змінну – $namespace.
Щоб вибирати неймспейси тільки з обраних в фільтрі нод – додаємо можливість фільтру по $node_name яку створили вище і використовуємо регулярку “=~” – якщо нод буде обрано кілька:

Переходимо до графіків.
Кількість нод в кластері
Запит – використовуємо фільтр под обраним нодам:
count(sum(karpenter_nodes_allocatable{node_name=~"$node_name"}) by (node_name))

Кількість подів в кластері
Запит – тут фільтр і по нодам, і по неймспейсу:
sum(karpenter_pods_state{node=~"$node_name", namespace=~"$namespace"})

Кількість ядер CPU на всіх нодах
Частина ресурсів зайнята системою то ДемонСетами – вони у karpenter_nodes_allocatable не враховються. Можна перевірити запитом sum(karpenter_nodes_system_overhead{resource_type="cpu"}).
Тому можемо вивести або загальну кількість – karpenter_nodes_allocatable{resource_type="cpu"} + karpenter_nodes_system_overhead{resource_type="cpu"}, або тільки дійсно доступну для наших workloads – karpenter_nodes_allocatable{resource_type="cpu"}.
Так як тут ми хочемо бачити саме загальну кількість – то давайте використаємо суму:
sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="cpu"}) + sum(karpenter_nodes_system_overhead{node_name=~"$node_name", resource_type="cpu"})

Загальний доступний об’єм пам’яті
JFYI:
- SI standard: 1000 bytes in a kilobyte.
- IEC standart: 1024 bytes in a kibibyte
Але давайте просто самі зробимо / 1024, і використаємо Кілобайти:
sum(sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="memory"}) + sum(karpenter_nodes_system_overhead{node_name=~"$node_name", resource_type="memory"})) / 1024

Spot instances – % від загальної кількості Nodes
Окрім нод створенних самим Karpenter у нас є окрема “дефолтна” нода, яка створються при створенні кластеру – для всяких controllers. Вона теж Spot (поки що), тож рахуймо і її.
Формула буде такою:
загальна сума нод = всі спот від karpenter + 1 дефолтна / на загальну кількість нод
Сам запит:
sum(count(sum(karpenter_nodes_allocatable{node_name=~"$node_name", nodepool!="", capacity_type="spot"}) by (node_name)) + 1) / count(sum(karpenter_nodes_allocatable{node_name=~"$node_name"}) by (node_name)) * 100

CPU requested – % від загального allocatable
Запит беремо з дефолтної борди Karpenter, трохи підпилюємо під свої фільтри:
sum(karpenter_nodes_total_pod_requests{node_name=~"$node_name", resource_type="cpu"}) / sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="cpu"})

Memory requested – % від загального allocatable
Аналогічно:
sum(karpenter_nodes_total_pod_requests{node_name=~"$node_name", resource_type="memory"}) / sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="memory"})

Pods allocation – % від загального allocatable
Скільки подів маємо від загальної ємності:
sum(karpenter_pods_state{node=~"$node_name", namespace=~"$namespace"} / sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="pods"})) * 100

Controller errors
Метрика controller_runtime_reconcile_errors_total включає в себе і контролери від VictoriaMetrcis, тож виключаємо їх через {container!~".*victoria.*"}:
sum(controller_runtime_reconcile_errors_total{container!~".*victoria.*"})

Cloudprovider errors
Рахуємо як рейт в секунду (з контролерами мабуть теж краще рейт, подивимось, як будуть помилки):
sum(rate(karpenter_cloudprovider_errors_total[15m]))

Nodes cost 24h – вартість всіх Nodes за добу
А от тут прям дуже цікаво вийшло.
По-перше – у AWS є дефолтні метрики білінгу від CloudWatch, але наш проект користується кредитами від AWS і ці метрики пусті.
Тому скористаємось метриками від Karpenter – karpenter_cloudprovider_instance_type_price_estimate.
Щоб відобразити вартість серверверів нам треба вибрати кожен тип інстансу які використовуються і потім порахувати загальну вартість по кожному типу і іх кількості.
Що ми маємо:
- дефолта нода: з типом Spot, але створюється не Karpenter – можемо її ігнорувати
- ноди, створені Karpenter: можуть бути або spot або on-demand, і можуть бути різних типів (
t3.medium.c5.large, etc)
Спочатку нам треба отримати кількість нод по кожному типу:
count(sum(karpenter_nodes_allocatable) by (node_name, instance_type,capacity_type)) by (instance_type, capacity_type)
Отримуємо 4 spot, і один інстанс без лейбли capacity_type – бо це з дефолтної нод-групи:

Можемо його виключити з {capacity_type!=""} – він у нас один, без скейлінгу, можемо не враховувати, бо це тільки для CriticalAddons.
Для кращої картини візьмемо більший проміжок часу, бо там був ще t3.small:

Далі, у нас є метрика karpenter_cloudprovider_instance_type_price_estimate, використовуючи яку нам треба порахувати вартість всіх інстансів по кожному instance_type і capacity_type.
Запит буде виглядати так (дякую ChatGPT):
sum by (instance_type, capacity_type) (
count(sum(karpenter_nodes_allocatable) by (node_name, instance_type, capacity_type)) by (instance_type, capacity_type)
* on(instance_type, capacity_type) group_left
avg(karpenter_cloudprovider_instance_type_price_estimate) by (instance_type, capacity_type)
)
Тут:
- “внутрішній” запит
sum(karpenter_nodes_allocatable) by (node_name, instance_type, capacity_type): рахується сума всіх CPU, memory тощо для кожної комбінаціїnode_name,instance_type,capacity_type - “зовнішній”
count(...) by (instance_type, capacity_type): результат попереднього запиту рахуємо зcount, щоб отримати кількість кожної комбінації – отримуємо кількіть WorkerNodes кожногоinstance_typeтаcapacity_type - другий запит –
avg(karpenter_cloudprovider_instance_type_price_estimate) by (instance_type, capacity_type): повертає нам середню ціну по кожномуinstance_typeтаcapacity_type - використовуючи
* on(instance_type, capacity_type): множимо кількість нод с запита номер 2 (count(...)) на результат с запита номер 3 (avg(...)) по співпадаючим комбінаціям метрикinstance_typeтаcapacity_type - і самий перший “зовнішній” запит
sum by (instance_type, capacity_type) (...): повертає нам суму по кожій комбінації
В результаті маємо такий графік:

Отже, що ми тут маємо:
- 4 інстанси
t3.mediumта 2t3.small - загальна вартість всіх
t3.mediumна годину виходить 0.074, всіхt3.small– 0.017
Для перевірки порахуємо вручну.
Спочатку по t3.small:
{instance_type="t3.small", capacity_type="spot"}
Виходить 0.008:

І по t3.medium:
{instance_type="t3.medium", capacity_type="spot"}
Виходить 0.018:

Тож:
- 4 інстанси
t3.mediumпо 0.018 == 0.072 usd/година - 2 інстанси
t3.smallпо 0.008 == 0.016 usd/година

Все сходиться.
Залишилось все це зібрати разом, і вивести загальную вартість всіх серверів за 24 години – використаємо avg() і результат помножимо на 24 години:
avg(
sum by (instance_type, capacity_type) (
count(sum(karpenter_nodes_allocatable{capacity_type!=""}) by (node_name, instance_type, capacity_type)) by (instance_type, capacity_type)
* on(instance_type, capacity_type) group_left
avg(karpenter_cloudprovider_instance_type_price_estimate) by (instance_type, capacity_type)
)
) * 24

І в результаті все у нас зараз виглядає так:

Йдемо далі – до графіків.
CPU % use by Node
Тут вже використаємо дефолтні метрики від Node Exporter – node_cpu_seconds_total, але вони мають лейбли instance у вигляді instance="10.0.32.185:9100", а не node_name або node як у метриках від Karpenter (karpenter_pods_state{node="ip-10-0-46-221.ec2.internal"}).
Тож щоб їх застосувати node_cpu_seconds_total з нашою змінною $node_name – додамо нову змінну node_ip, яку будемо формувати з метрики kube_pod_info з фільтром по лейблі node, де використовуємо нашу стару змінну node_name – щоб вибирати поди тільки з обраних в фільтрах нод.
Додаємо нову змінну, поки для перевірки не вимикаємо “Show on dashboard“:

І тепер можемо створити графік с запитом:
100 * avg(1 - rate(node_cpu_seconds_total{instance=~"$node_ip:9100", mode="idle"}[5m])) by (instance)

Але в такому випадку instance нам поверне результати як “10.0.38.127:9100” – а ми всюди використовуємо “ip-10-0-38-127.ec2.internal“. До того ж ми не зможемо додати data links, бо друга панель використовує формат ip-10-0-38-127.ec2.internal.
Тож ми можемо використати label_replace(), і переписати запит так:
100 * avg by (instance) (
label_replace(
rate(node_cpu_seconds_total{instance=~"$node_ip:9100", mode="idle"}[5m]),
"instance",
"ip-${1}-${2}-${3}-${4}.ec2.internal",
"instance",
"(.*)\\.(.*)\\.(.*)\\.(.*):9100"
)
)
Тут label_replace отримує 4 агрументи:
- перший – метрика, над якою будемо виконувати трансформацію (результат
rate(node_cpu_seconds_total)) - другий – лейбла, над якою ми будемо виконувати трансформацію –
instance - третій – новий формат value для лейбли – “
ip-${1}-${2}-${3}-${4}.ec2.internal“ - четвертий – ім’я лейбли, з якої ми будемо тримувати дані за допомогою regex
І останнім описуємо сам regex “(.*)\\.(.*)\\.(.*)\\.(.*):9100“, за яким треба отрмати кожен октет з IP 10.0.38.127, а потім кожен результат відповідно записати у ${1}-${2}-${3}-${4}.
Тепер маємо графік в такому вигляді:

Memory used by Node
Тут все аналогічно:
sum by (instance) (
label_replace(
(
1 - (
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes
)
) * 100,
"instance", "ip-${1}-${2}-${3}-${4}.ec2.internal", "instance", "(.*)\\.(.*)\\.(.*)\\.(.*):9100"
)
)

Pods use % by Node
Тут нам треба виконати запит між двома метриками – karpenter_pods_state та karpenter_nodes_allocatable:
(
sum by (node) (kube_pod_info{node=~"$node_name", created_by_kind!="Job"})
/
sum by (node) (kube_node_status_allocatable{node=~"$node_name", resource="pods"})
) * 100
Або ми можемо виключити нашу дефолтну ноду “ip-10-0-41-2.ec2.internal” і відобразити тільки ноди самого Карпентеру додавши вибірку по karpenter_nodes_allocatable{capacity_type!=""} – бо нам тут більше цікаво наскільки зайняті ноди, які створено самим Karpenter під наші аплікейшени.
Але для цього нам знабиться метрика karpenter_nodes_allocatable, в якій ми можемо перевірити наявність лейбли capacity_type – capacity_type!="".
Проте karpenter_nodes_allocatable має лейблу node_name а не node як в попередніх двух, тому ми знову можемо додати label_replace, і зробити такий запит:
(
sum by (node) (kube_pod_info{node=~"$node_name", created_by_kind!="Job"})
/
on(node) group_left
sum by (node) (kube_node_status_allocatable{node=~"$node_name", resource="pods"})
) * 100
and on(node)
label_replace(karpenter_nodes_allocatable{capacity_type!=""}, "node", "$1", "node_name", "(.*)")
Тут в and on(node) ми використовуємо лейблу node в результатах запиту зліва (sum by()) і в результаті справа, щоб зі списку нод в karpenter_nodes_allocatable{capacity_type!=""} (тобто всі ноди, окрім нашої “дефолтної”) вибрати тільки ті, які є в результатх першого запиту:

EBS use % by Node
Тут вже простіше:
sum(kubelet_volume_stats_used_bytes{instance=~"$node_name", namespace=~"$namespace"}) by (instance)
/
sum(kubelet_volume_stats_capacity_bytes{instance=~"$node_name", namespace=~"$namespace"}) by (instance)
* 100
Nodes created/terminated by Karpenter
Для відображення активності автоскейлінгу додамо графік з двома запитами:
increase(karpenter_nodes_created[1h])
Та:
- increase(karpenter_nodes_terminated[1h])
Тут в функції increase() перевіряємо наскільки змінилося значення за годину:

А щоб позбутися цих “сходинок” – можемо додатково загорнути результат у функцію avg_over_time():

Grafana dashboard: фінальний результат
І все разом у нас тепер виглядає так:

Додавання Data links
Останім кроком буде додавання Data Links на графіки: потрібно додати лінку на іншу дашборду, по конкретній ноді.
Ця борда має такий URL: https://monitoring.ops.example.co/d/kube-node-overview/kubernetes-node-overview?var-node_name=ip-10-0-41-2.ec2.internal
Де в var-node_name=ip-10-0-41-2.ec2.internal задається ім’я ноди, по якій треба вивести дані:

Тож відкриваємо графік, знаходимо Data links:

Задаємо ім’я та URL – список всіх полів можна отримати по Ctrl+Space:

__field візьме дані з labels.node з результату запиту в панелі:

І сформує посилання у вигляді “https://monitoring.ops.example.co/d/kube-node-overview/kubernetes-node-overview?var-node_name=ip-10-0-38-110.ec2.internal“.
Ну і на цьому начебто все.
![]()









































 Що маємо: є у нас Kubernetes cluster, на якому скейлінгом WorkerNodes займається
Що маємо: є у нас Kubernetes cluster, на якому скейлінгом WorkerNodes займається  Зараз ми вміємо збирати логи API Gateway та CloudWatch Logs, див.
Зараз ми вміємо збирати логи API Gateway та CloudWatch Logs, див.