Коли я готувався до цієї зими, то довго не міг вирішити – що ж брати? Зекономити, і взяти просто акумулятори + ДБЖ, чи купити зарядну станцію від “народних умільців”, або психанути – та купити EcoFlow?
При роботі котла опалення + холодильника споживається близько 280 Вт/годину, і цієї станції має вистачити на 12-15 годин роботи. А враховуючи швидкість зарядки EcoFlow в пару годин – цілком нормальний варіант:
В “офісі” ж в мене стоїть EcoFlow Delta Max 2000 2016Wh, і на резерв – саморобна станція, куплена на OLX (не рекомендую, але працює з 2023):
АВР – Автомат Введення Резерву
Якщо “офіс” в мене однокімнатна квартира, і там я обійшовся кабелями з балкону, які йдуть на кухню і в робочу кімнату, то в 3к квартирі це було б, по-перше, дуже не зручно – десятиметрові кабеля через всю квартиру, по-друге – там хотілося мати нормальне освітлення і роботу розеток, тим більш вдома є дитина.
Тому ще влітку я встановив там АВР, який автоматично переключає живлення квартири на EcoFlow, коли в загальній мережі пропадає напруга.
Виглядає це ось так:
Тут зверху – звичайний ЗУБР з автоматами, на нього заходить лінія живлення з будинку.
А під ним – вже сам АВР: з розетки в ньому йде кабель живлення до EcoFlow, а з EcoFlow ще один назад до АВР, і вже від нього живиться квартира.
Це просто чудова штука, рекомендую, хоча обійшлася вона мені в 16.000 гривень. Якщо комусь треба – то пишіть в Telegram, дам контакт майстра (до речі, служить в ППО Київської області).
Холодильник – режим Eco Friendly (LG)
Але при таких відключеннях, як сьогодні, коли світла не буде майже добу – доводиться вже економити, і тут я вперше спробував функцію Eco Friendly в холодильнику LG:
Вона обмежує споживання електроенергії, і дуже відчутно – замість ~120 Вт/г холодильник забирає близько 60-80.
При цьому він підвищує температуру в морозильнику з -20 до -15, і в самому холодильнику з +3 до +7.
Ще одна дуже корисна штука, яка прям маст хев всім, у кого опалення газовим котлом – це термостат, я собі брав Computherm Q7 RF:
Тут на стіні приймач, і з нього йдуть команди на сам котел:
По-перше, такий термостат програмується на різні режими в різні години доби: на ніч можна поставити 18-20 градусів, на ранок – 21-22, вдень, поки нікого немає вдома – знов 18, а ввечері, перед поверненням всіх додому – знов до 21-22.
Це відчутно економить витрати електроенергії на роботу котла опалення, який теж їсть немало – 100-120 Вт/г. Ну і рахунок за газ буде трохи меншим.
Ноутбуки та павербанки
Знов-таки, коли вже доводиться прям сильно економити – то ноутбуки я переключаю на живлення від павербанок або менших зарядний станцій.
Або використати звичайний павербанк, який зможе видати 30+ ват потужності, наприклад в мене є парочка 30000 mah 65W 6A Baseus PowerBank, або ось такі китайські:
До них ще докупав пару маленьких інверторів на 150 ват – телевізор від них працює без проблем.
Загалом моя “колекція” павербанок виглядає так:
Інтернет
Благо, в Україні вже давно багато де є GPON, і в моєму селі, на щастя, теж, тому ще в кінці 2022 я собі підключив таку оптику.
Єдине, що для неї треба – це живити сам ONU (медіаконвертор) та роутер.
Для дому я купив ДБЖ для роутеру UPS DC1018P (на AliExpress можна взяти рази в два дешевше, ніж на Rozetka, але і чекати довго, і якщо прийде Укрпоштою – то ну його до біса), тримає 8-10 годин:
А в офісі ONU живиться або від павербанки:
Або від Step4Net UPS-18W, і такий жеж стоїть в кімнаті для роутера – але його вистачає години на 4 роботи:
Освітлення
Для квартири ще в минулі роки купив лампи на акумуляторах Yeelight Xiaomi з магнітами:
Ще купив датчики диму CoVi Security, які вміють слати альорти на мобільний телефон:
На телефоні виглядає якось так:
Тестив, підпалюючи тряпку – працює.
Вода та водопостачання
Тут мені дуже повезло з ЖК, бо у нас власні скважини з насосами. Для них є окремий генератор, але він працює 2 рази на добу по 3-4 години, і буває, що не вмикають зовсім.
Тому в будь-якому випадку тримаю вдома запас води технічної, 2 бутилі по 20 літрів, і питної, теж 2х20 літрів.
Ну і останнє, що теж купував ще в 2022 – це звичайний чайник на плиту, аби не садити EcoFlow з електрочайником (тим більш тоді ще EcoFlow в мене не було):
Подивились ми на наші витрати на AWS Load Balancers, і подумали, що треба трохи це діло привести в порядок.
Чого хочеться: мати один LoadBalancer, і через нього роутити запити на різні Kubernetes Ingresses та Services в різних Namespaces.
Перше, що спало на думку – це або додавати в Kubernetes кластер якийсь Service Mesh типу Istio або Linkerd, або додавати Nginx Ingress Controller, а перед ним – AWS ALB.
Тож давайте подивимось як це працює, і як таку схему можна додати на існуючі Ingress ресурси.
Тест Load Balancer Controller IngressGroup
Отже, ідея доволі проста: в маніфесті Kubernetes Ingress ми задаємо ще один атрибут – group.name, і по ньому Load Balancer Controller визначає до якого AWS LoadBalancer цей Ingress належить.
Потім він використовуючи spec.hosts в Ingress визначає hostnames і на LoadBalancer будує роутинг до необхідних Target Groups.
Давайте спробуємо на простому прикладі.
Спочатку створюємо звичайну схему з окремими Ingress/ALB – описуємо маніфест з Namespace, Deployment, Service та Ingress:
$ kk apply -f .
namespace/test-app-1-ns created
deployment.apps/app-1-deploy created
service/app-1-service created
ingress.networking.k8s.io/app-1-ingress created
namespace/test-app-2-ns created
deployment.apps/app-2-deploy created
service/app-2-service created
ingress.networking.k8s.io/app-2-ingress created
Перевіряємо Ingress та його LoadBalancer для app-1:
$ kk -n test-app-1-ns get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
app-1-ingress alb app-1.ops.example.com k8s-testapp1-app1ingr-9375bc68bc-376038977.us-east-1.elb.amazonaws.com 80 33s
Тут ADDRESS – “k8s-testapp1-app1ingr-9375bc68bc-376038977“.
Перевіряємо для app-2:
$ kk -n test-app-2-ns get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
app-2-ingress alb app-2.ops.example.com k8s-testapp2-app2ingr-0277bbb198-1743964934.us-east-1.elb.amazonaws.com 80 64s
Тут ADDRESS – “k8s-testapp2-app2ingr-0277bbb198-1743964934“.
Відповідно, в AWS маємо два Load Balancers:
Тепер до обох Ingress додаємо анотацію alb.ingress.kubernetes.io/group.name: test-app-alb:
У app-1 – це “k8s-testappalb-95eaaef0c8-2109819642“:
$ kk -n test-app-1-ns get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
app-1-ingress alb app-1.ops.example.com k8s-testappalb-95eaaef0c8-2109819642.us-east-1.elb.amazonaws.com 80 6m19s
У app-2 – теж “k8s-testappalb-95eaaef0c8-2109819642“:
$ kk -n test-app-2-ns get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
app-2-ingress alb app-2.ops.example.com k8s-testappalb-95eaaef0c8-2109819642.us-east-1.elb.amazonaws.com 80 6m48s
І в AWS у нас тепер один Load Balancer:
Який має два Listerner Rules, які в залежності від hostname в Ingress будуть редіректити запити до потрібних Target Groups:
IngressGroups – ліміти та реалізація в Production
При використанні такої схеми треба мати на увазі, що деякі параметри LoadBalancer не можуть задаватись в різних Ingress.
Наприклад, якщо один Ingress має анотацію alb.ingress.kubernetes.io/tags: "component=devops", а другий Ingress намагається задати тег component=backend, то Load Balancer Controller не задеплоїть такі зміни, і повідомить про конфлікт, наприклад:
aws-load-balancer-controller-7647c5cbc7-2stvx:aws-load-balancer-controller {"level":"error","ts":"2024-09-25T10:50:23Z","msg":"Reconciler error","controller":"ingress","object":{"name":"ops-1-30-external-alb"},"namespace":"","name":"ops-1-30-external-alb","reconcileID":"1091979f-f349-4b96-850f-9e7203bfb8be","error":"conflicting tag component: devops | backend"}
aws-load-balancer-controller-7647c5cbc7-2stvx:aws-load-balancer-controller {"level":"error","ts":"2024-09-25T10:50:44Z","msg":"Reconciler error","controller":"ingress","object":{"name":"ops-1-30-external-alb"},"namespace":"","name":"ops-1-30-external-alb","reconcileID":"19851b0c-ea82-424c-8534-d3324f4c5e60","error":"conflicting tag environment: ops | prod"}
Аналогічно до параметрів на кшталт alb.ingress.kubernetes.io/load-balancer-attributes: access_logs.s3.enabled=true,access_logs.s3.bucket=some-bucket-name, або параметри SecurityGroups.
А от з TLS все простіше: для кожного Ingress в його annotations з alb.ingress.kubernetes.io/certificate-arn можна передати ARN сертифікату з AWS Certificates Manager, і вони будуть налаштовані у Listener certificates for SNI:
Тому я принаймні поки що зробив так:
створив окремий GitHub репозиторій
в ньому Helm- чарт
в цьому чарті два маніфести для двох Ingress – один з типом internal, другий – internet-facing, і задав там всякі дефолтні параметри
Натомість ми всі Access логи лоад-балансерів збираємо до Loki, а далі вже з її Recording Rules генеруємо метрики, де в лейблах маємо ім’я домену при запиті на який помилка виникла:
Там ми розбирали роботу з VPC Flow Logs в цілому, і дізнались, як ми можемо отримувати інформацію про трафік з/до Kubernetes Pods.
Але при використанні Flow Logs з CloudWatch Logs є одна проблема – це вартість.
Наприклад, коли ми включаємо Flow Logs і вони пишуться до CloudWatch Logs, то навіть у невеликому проекті з невеликим трафіком кости на CloudWatch Logs виглядають так – 23-го жовтня включив, 8 листопада відключив:
Тому замість використання CloudWatch Logs ми можемо зробити інакше: Flow Logs писати до AWS S3 бакета, а звідти забирати з Promtail і писати в Grafana Loki, див. Grafana Loki: збираємо логи AWS LoadBalancer з S3 за допомогою Promtail Lambda. А вже маючи логи в Loki – мати і алерти з VMAlert/Alertmanager, і дашборди в Grafana.
Головна проблема, яку ми зараз хочемо вирішити за допомогою VPC Flow Logs – це визначити, хто шле багато трафіку через NAT Gateway, бо це теж з’їдає наші гроші.
Друга задача – це надалі мати загальну картину і якісь алерти по трафіку.
Отже, що будемо робити:
створимо AWS S3 для логів
створимо Lambda-функцію з інстансом Promtail, який буде писати логи з бакета до Grafana Loki
подивимось що ми маємо в логах цікавого, і що корисного там може бути для нас по трафіку
Взагалі модуль створювався для збору логів AWS Load Balancers, тому в іменах буде зустрічатись “alb” – потім треба буде його переписати аби імена бакетів та функцій передавати параметром.
Єдиний момент, який треба мати на увазі: VPC Flow Logs пише багато даних, тому варто додати більший таймаут для Lambda, бо частина записів втрачалась через помилку Lambda “Task timed out after 3.05 seconds“.
...
module "promtail_lambda" {
source = "terraform-aws-modules/lambda/aws"
version = "~> 7.8.0"
# key: dev
# value: ops-1-28-backend-api-dev-alb-logs
for_each = aws_s3_bucket.alb_s3_logs
# <aws_env>-<eks_version>-<component>-<application>-<app_env>-alb-logs-logger
# bucket name: ops-1-28-backend-api-dev-alb-logs
# lambda name: ops-1-28-backend-api-dev-alb-logs-loki-logger
function_name = "${each.value.id}-loki-logger"
description = "Promtail instance to collect logs from ALB Logs in S3"
create_package = false
# https://github.com/terraform-aws-modules/terraform-aws-lambda/issues/36
publish = true
# an error when sending logs from Flow Logs S3:
# 'Task timed out after 3.05 seconds'
timeout = 60
...
Отже, ми маємо AWS S3 бакет, маємо Lambda, яка з цього бакету бути отримувати повідомлення про появу нових об’єктів, а потім Promtail з цієї Lambda-функції відправляє логи до інстансу Loki через Internal LoadBalancer:
При передачі логів до Loki Promtail додає кілька нових лейбл – component=vpc-flow-logs, logtype=alb, environment=ops. Далі ми зможемо їх використовувати в метриках та Grafana dashboards.
logtype=alb то знов-таки модуль писався під логи ALB, і це треба буде змінити
Тепер нам треба налаштувати Flow Logs для нашої VPC.
...
enable_flow_log = var.vpc_params.enable_flow_log
# Default: "cloud-watch-logs"
flow_log_destination_type = "s3"
# disalbe to use S3
create_flow_log_cloudwatch_log_group = false
create_flow_log_cloudwatch_iam_role = false
# ARN of the a CloudWatch log group or an S3 bucket
# disable if use 'create_flow_log_cloudwatch_log_group' and the default 'flow_log_destination_type' value (cloud-watch-logs)
flow_log_destination_arn = "arn:aws:s3:::ops-1-30-vpc-flow-logs-devops-ops-alb-logs"
# set 60 to use more detailed recoring
flow_log_max_aggregation_interval = 600
# when use CloudWatch Logs, set this prefix
flow_log_cloudwatch_log_group_name_prefix = "/aws/${local.env_name}-flow-logs/"
# set custom log format for more detailed information
flow_log_log_format = "$${region} $${vpc-id} $${az-id} $${subnet-id} $${instance-id} $${interface-id} $${flow-direction} $${srcaddr} $${dstaddr} $${srcport} $${dstport} $${pkt-srcaddr} $${pkt-dstaddr} $${pkt-src-aws-service} $${pkt-dst-aws-service} $${traffic-path} $${packets} $${bytes} $${action}"
...
Нас тут зараз цікавлять такі параметри:
flow_log_destination_type: замість дефолтного cloud-watch-logs задаємо s3
create_flow_log_cloudwatch_log_group та create_flow_log_cloudwatch_iam_role: відключаємо створення ресурсів для CloudWatch Logs
flow_log_destination_arn: задаємо ARN корзини, в яку будуть писатись логи
flow_log_log_format: створюємо власний формат, аби мати більше інформації, в тому числі з IP подів в Kubernetes, див. VPC Flow Log – Custom format
Виконуємо terraform apply, перевіряємо нашу VPC:
І через 10 хвилин перевіряємо логи в Grafana Loki:
Чудово – логи пішли.
Далі до запиту в Loki додаємо парсер pattern, аби сформувати поля в записах:
10.0.5.175: це dst_addr – приватний IP нашого NAT Gateway
443: це src_port – звідки прийшов пакет
18779: це dst_port – куди прийшов пакет
52.46.154.111 та 10.0.5.175: це pkt_src_addr та pkt_dst_addr відповідно, значення такі ж, як і в5432src_addr та dst_addr – тобто трафік явно “чисто NAT”, як розбирали в Від Remote Server до NAT Gateway
AMAZON: сервіс, від якого пакет отримано (але про це трохи далі)
pkt_dst_aws_service та traffic_path: пусті
105: кількість пакетів
113390: кількість байт
ACCEPT: пакет пройшов через Security Group/WAF
А в наступному запису бачимо dst_port5432 – тут трафік явно до PostgreSQL RDS.
NAT Gateway та traffic_path
З цікавих моментів, які можна побачити в логах.
По-перше – це traffic_path. Іноді в логах, які пов’язані в NAT Gateway можна побачити “8”, тобто “Through an internet gateway” – див. Available fields.
Чому Internet Gateway? Бо трафік приходить з приватної мережі на NAT Gateway, але далі в інтернет він йде вже через Internet Gateway – див. One to Many: Evolving VPC Design.
pkt_src_aws_service, pkt_dst_aws_service та визначення сервісу
Щодо адрес не з нашої мережі, тобто якихось зовнішніх сервісів. В полях pkt_src_aws_service та pkt_dst_aws_service часто можна побачити запис типу “EC2” або “AMAZON” – але нам це нічого не каже.
Навіть більше – технічна підтримка самого AWS не змогла сказати що ж то за сервіси, на які йдуть пакети.
Але тут є хак: якщо в src_port/dst_port ми бачимо порт 443 – то можна просто відкрити IP в браузері, де ми отримаємо помилку SSL, і в помилці буде ім’я сервісу, на який це сертифікат видано.
Наприклад, вище ми бачили, що pkt_src_aws_service == AMAZON. Якщо відкрити https://52.46.154.111 – то побачимо що саме на цьому IP:
Аналогічно будуть записи типу monitoring.us-east-1.amazonaws.com для AWS CloudWatch або athena.us-east-1.amazonaws.com для AWS Athena.
Створення Grafana dashboard
Тепер давайте пробувати створити Grafana dashboard.
Планування
Отже, головна мета – це мати уяву про трафік, який проходить через AWS NAT Gateway.
Що ми знаємо та маємо?
знаємо CIDR приватних сабнетів для Kubernetes Pods
знаємо Elastic Network Interface ID, Public IP та Private IP для NAT Gateway – він у нас один, тому тут все просто
в логах маємо IP подів Kubernetes та якихось зовнішніх ресурсів
в логах маємо напрямок трафіку через інтерфейс NAT Gateway – IN/OUT (ingress/egress, або RX/TX – Recieved та Transmitted)
Що ми б хотіли бачити на дашборді?
загальний об’єм трафіку, який пройшов через NAT Gateway і за який ми заплатити
загальний об’єм трафіку NAT Gateway за напрямком – ingress/egress
сервіси в Kubernetes, які генерують найбільший трафік
AWS сервіси та зовнішні ресурси, які генерують трафік – для цього маємо поля pkt-src-aws-service та pkt-dst-aws-service
дія з пакетами ACCEPT та REJECT – може бути корисним, якщо є AWS Web Application Firewall, або вам цікаві спрацювання VPC Network Access List
Availability Zones для визначення cross-AZ трафіку – але це наразі не в нашому випадку, бо у нас все в одній зоні
traffic-path – може бути корисним для визначення якого типу трафік йде – всередині VPC, через VPC Endpoint тощо (хоча особисто я не став це використовувати в дашборді)
NAT Gateway total traffic processed
Отримати суму всього трафіку за період часу ми можемо таким запитом:
Використовуємо [$__range], аби взяти проміжок часу, який задано в Grafana dashboard. В sum_over_time рахуємо всі bytes за цей час, і “загортаємо” все в sum(), аби мати просто цифру.
Для панелі “Total traffic processed” можна взяти тип візуалізації Stat, використати Unit з Bytes(IEC), і виглядати це буде так:
Маємо тут 5.8 GB за 15 хвилин.
Зараз маю для перевірки Flow Logs в CloudWatch, де можемо зробити такий запит для порівняння:
Так як панель у нас з типом Stat, де просто відображається цифра – то задля зменшення навантаження на Grafana та Loki в Options є сенс поставити Type == Instant.
Змінні дашборди – $kubernetes_pod_ip та $remote_svc_ip
По-перше – нам цікавий трафік саме з/до Kubernetes Pods, бо майже всі наші сервіси живуть там.
По-друге – хочеться мати можливість вибрати дані тільки по обраним pkt_src_addr та pkt_dst_addr – це може бути або Kubernetes Pod, або якийсь зовнішній сервіс – в залежності від ingress/egress трафіку.
Так як ми оперуємо з “сирими” записами в логах, а не метриками з лейблами – то ми не можемо просто взяти значення з полів, тому я додав дві змінні з типом Textbox, в які можна внести IP вручну:
А далі ми можемо ці змінні додати в усі наші запити з регуляркою pkt_src_addr=~"${kubernetes_pod_ip}", аби запит спрацьовував, якщо в змінній не задано жодного значення:
Але якщо з даними типу “total processed bytes” це нормальний варіант, то далі, коли ми будемо створювати панелі з інформацією по IP, у нас буде проблема в тому, як ці IP зберігати в метриках.
Якщо ми будемо значення з pkt_src_addr та pkt_dst_addr заносити в лейбли метрики – то це призведе до того, що Loki буде створювати окремий набір блоків даних (chunks) на кожний унікальний набір лейбл.
А так як IP в VPC у нас багато, а зовнішніх IP може бути ще більше – то можемо отримати мільйони блоків даних, що вплине і на вартість зберігання даних в AWS S3, і на перформанс самої Loki та VictoriaMetrics або Prometheus, бо їм доведеться всі ці дані завантажувати про виконанні запитів в Grafana. Див. Loki Recording Rules, Prometheus/VictoriaMetrics та High Cardinality.
Крім того, лейбли в метриках взагалі мають використовуватись для “опису” цієї метрики і можливості вибирати дані, а не для зберігання якихось даних для подальшого використання. Тобто лейбла – це тег, який “описує” метрику, а не поле для передачі параметрів.
Тому тут варіант або змиритись з high cardinality issue і не дотримуватись best practices – або використовувати “сирі логи” в дашбордах.
При роботі з сирими логами в Loki та Grafana ми, звісно, обмежуємо себе, бо на запитах за відносно великий проміжок часу – наприклад, кілька годин – Loki починає жрати ресурси, як дурна, див. колонку CPU – майже 4 ядра зайняті повністю:
Можливо, я все ж спробую створити Recording Rules з IP в лейблах, подивитись як це вплине на систему. Поки у нас невеликий стартап і мало трафіку – це ще може бути варіантом. Але на великих обсягах такого краще не робити.
Крім того, до VictoriaLogs вже завели і підтримку Recording Rules, і алерти – див. vmalert.
NAT Gateway та traffic processed – графіки
На додачу до простих Stat панелей може бути корисним створити графіки – аби мати уявлення про те, як якісь зміни впливали на трафік.
Тут запит може бути аналогічним, тільки замість sum_over_time() використаємо rate(), в Options використовуємо Type == Range, а в Standart Options > Unit задаємо “bytes/sec”:
Для rate() беремо період 15 хвилин, бо логи у нас пишуться раз на 10 хвилин – дефолтне значення для flow_log_max_aggregation_interval в модулі terraform-aws-modules/vpc/aws.
Сервіси в Kubernetes, які генерують найбільший трафік
Наступним хочеться бачити IP з Kubernetes Pods, які генерують трафік.
Тут можемо створити візуалізацію з типом Pie chart і таким запитом:
Використовуємо ip() з CIDR нашої приватної мережі, аби вибрати записи тільки з IP наших Pods (див. Matching IP addresses), і topk(5), аби відобразити тільки ті Pods, які генерують найбільше трафіку.
В результаті маємо таку картину:
В топі у нас IP 10.0.44.66 – глянемо, що за сервіс:
$ kk get pod -A -o wide | grep -w 10.0.44.66
dev-backend-api-ns backend-celery-workers-deployment-b68f88f74-rzq4j ... 10.0.44.66 ...
Є такий Kubernetes Pod, окей. Тепер маємо уяву хто шле багато трафіку.
Grafana Data links
Аби швидко отримати інформацію що за IP, та до якого Kubernetes Pod він належить – можемо додати Grafana Data Links.
Наприклад, в мене є окрема дашборда, де по Pod IP можна отримати всю інформацію про нього.
Тоді можемо створити Data link з полем ${__field.labels.pkt_src_addr}:
І дашборда по IP “10.0.44.66”:
Всі доступні поля для Data links можна отримати з Ctrl+Space.
Або замість (чи на додачу) Pie chart можемо створити звичайний графік, аби мати “історичну картину”, як ми це робили для NAT Gateway Total traffic:
По Kubernetes Pods інформацію отримали – давайте глянемо, звідки до нас приходить найбільше трафіку.
Тут все аналогічно, тільки фільтр робимо по pkt_dst_addr=ip("10.0.32.0/20") – тобто вибираємо всі записи, де пакет йде ззовні на NAT Gateway і потім до наших Pods:
А в Data Links можемо використати сервіс https://ipinfo.io і поле pkt_src_addr:
Сервіси в Kubernetes, які генерують найбільший трафік – таблиця з портами
Окремо можна додати табличку, де буде трохи більше інформації по кожному запису з логів.
Чому окремо – бо тут ми робимо запит з великою вибіркою по декільком полям, і через це Loki доведеться тягнути додаткові дані. Тому на запитах за великий проміжок часу нехай краще не прогрузиться одна табличка – але будуть графіки.
В табличку можемо додати відображення портів – буде корисно при визначенні сервісу.
Створюємо візуалізацію з типом Table і таким запитом:
Organize fields by name: міняємо заголовки колонок
Значення для Standard options > Unit та Data Links задаємо через Fields override, бо для кожної колонки у нас будуть власні параметри:
Grafana dashboard: фінальний результат
І все разом в мене поки що вийшло ось так:
Якщо не зважати не проблеми з перформансом Loki при використанні raw logs – то наче непогано. Вже дуже допомогло визначити зайвий трафік, наприклад – багато трафіку йшло від Athena, тому додамо VPC Endpoint для неї, аби не ганяти цей трафік через NAT Gateway.
Далі, мабуть, таки спробую варіант з Recording Rules для Loki, і точно буду пробувати писати логи до VictoriaLogs, і робити графіки та алерти через неї.
Тут є два варіанти – більш кошерний для production через GitHub App, або через персональний токен.
З GitHub App виглядає як більш правильне рішення, але ми невеликий стартап, і через персональний токен буде простіше – тому поки зробимо так, а “потім” (с) при потребі зробимо вже “як треба”.
Переходимо до свого профайлу, клікаємо Settings > Developer settings > Personal access tokens, клікаємо Generate new token (classic):
Self-hosted runners поки будемо використовувати тільки для одного репозиторію, тому задаємо права тільки на repo:
Expiration було б добре задати, але це PoC (який потім, як завжди, піде в production), тому поки ОК – нехай буде вічний.
Створюємо Kubernetes Namespace для раннерів:
$ kk create ns ops-github-runners-ns
namespace/ops-github-runners-ns created
Створюємо в ньому Kubernetes Secret з токеном:
$ kk -n ops-github-runners-ns create secret generic gh-runners-token --from-literal=github_token='ghp_FMT***5av'
secret/gh-runners-token created
Перевіряємо його:
$ kk -n ops-github-runners-ns get secret -o yaml
apiVersion: v1
items:
- apiVersion: v1
data:
github_token: Z2h***hdg==
kind: Secret
...
Запуск Actions Runner Controller з Helm
Actions Runner Controller складається з двох частин:
gha-runner-scale-set-controller: власне сам контролер – його Helm-чарт створить необхідні Kubernetes CRD та запустить поди контролера
gha-runner-scale-set: відповідає за запуск Kubernetes Pods з GitHub Action Runners
Хоча в документації Scale Sets Controller теж називається Actions Runner Controller, і при цьому є ще й легасі Actions Runner Controller… Трохи плутає, майте на увазі, що частина нагуглених прикладів/документації може бути саме про легасі-версію.
$ kk -n ops-github-controller-ns get pod
NAME READY STATUS RESTARTS AGE
github-runners-controller-gha-rs-controller-5d6c6b587d-fv8bz 1/1 Running 0 2m26s
Перевіряємо нові CRD:
$ kk get crd | grep github
autoscalinglisteners.actions.github.com 2024-09-17T10:41:28Z
autoscalingrunnersets.actions.github.com 2024-09-17T10:41:29Z
ephemeralrunners.actions.github.com 2024-09-17T10:41:29Z
ephemeralrunnersets.actions.github.com 2024-09-17T10:41:30Z
Встановлення Scale Set для Runners
Кожен Scale Set (ресурс AutoscalingRunnerSet) відповідає за конкретні Runners, які ми будемо використовувати через runs-on в workflow-файлах.
Задаємо дві змінні оточення – потім це передамо через власний файл values:
INSTALLATION_NAME: ім’я runners (в values задається через runnerScaleSetName)
GITHUB_CONFIG_URL: URL GitHub Organization або репозиторію в форматі https://github.com/<ORG_NAME>/<REPO_NAME>
Ще раз перевіряємо поди в неймспейсі контролера – має додатись новий, з ім’ям test-runners-*-listener – він буде відповідати за запуск подів з ранерами для групи “test-runners“:
$ kk -n ops-github-controller-ns get pod
NAME READY STATUS RESTARTS AGE
github-runners-controller-gha-rs-controller-5d6c6b587d-fv8bz 1/1 Running 0 8m38s
test-runners-694c8c97-listener 1/1 Running 0 40s
А створюється він з AutoscalingListeners:
$ kk -n ops-github-controller-ns get autoscalinglisteners
NAME GITHUB CONFIGURE URL AUTOSCALINGRUNNERSET NAMESPACE AUTOSCALINGRUNNERSET NAME
test-runners-694c8c97-listener https://github.com/***/atlas-test ops-github-runners-ns test-runners
Перевіряємо поди в неймспейсі з самими ранерами – тут поки що пусто:
$ kk -n ops-github-runners-ns get pod
No resources found in ops-github-runners-ns namespace.
Власне, для початку на цьому і все – можна починати запускати джоби. А там по ходу діла будемо дивитись “де впало”, і додавати конфігурації.
Тест з GitHub Actions Workflow
Спробуємо запустити якийсь мінімальний білд, просто аби впевнитись, що в цілому схема працює.
В тестовому репозиторії створюємо файл .github/workflows/test-gh-runners.yml.
В runs-on задаємо ім’я нашого пулу раннерів – test-runners:
name: "Test GitHub Runners"
concurrency:
group: github-test
cancel-in-progress: false
on:
workflow_dispatch:
permissions:
# allow read repository's content by steps
contents: read
jobs:
aws-test:
name: Test EKS Runners
runs-on: test-runners
steps:
- name: Test Runner
run: echo $HOSTNAME
Пушимо в репозиторій, запускаємо білд, чекаємо хвилину, і бачимо ім’я раннера:
Перевіряємо поди в Kubernetes:
$ kk -n ops-github-runners-ns get pod
NAME READY STATUS RESTARTS AGE
test-runners-p7j9h-runner-xhb94 1/1 Running 0 6s
Цей жеж раннер і відповідний Runner Scale Set буде в Settings > Actions > Runners:
І джоба завершилась:
Окей – воно працює. Що далі?
треба створити Karpenter NodePool з серверів виключно під GitHub Runners
треба задати requests на поди
треба подивитись як раннери зможуть білдити Docker-образи
Типи інстансів тут не тюнив, скопіював з NodePool нашого Backend API – потім подивимось, скільки ресурсів раннери будуть використовувати для роботи.
Ще є сенс потюнити disruption – consolidationPolicy, consolidateAfter та budgets. Наприклад, якщо всі девелопери працюють за одною таймзоною – то WhenEmptyOrUnderutilized робити вночі, а вдень видаляти тільки по WhenEmpty, і задати вищий consolidateAfter, аби нові джоби не чекали зайвого часу на створення EC2. Див. Karpenter: використання Disruption budgets.
можемо створити власний чарт, і в ньому встановлювати чарти GitHub Runners через Helm Dependency
Або зробити ще простіше – створити репозиторій з конфігами-вальюсами, додати Makefile – і поки що деплоїти вручну.
Я скоріш за все заміксую схему:
сам контролер буде встановлюватись з Terraform коду, який розгортає весь Kubernetes кластер – там встановлюються інші контролери типу ExternalDNS, ALB Ingress Controller, etc
для створення Scale Sets з пулами раннерів під кожен репозиторій зроблю окремий Helm chart в окремому репозиторії, і в ньому у templates/ додам конфіг-файли для кожного пула раннерів
але поки це ще в PoC – то Scale Sets буде встановлюватись з Makefile який виконує helm install -f values.yaml
Створюємо власний values.yaml, задаємо runnerScaleSetName, requests та tolerations до tains з нашого NodePool:
$ docker run -ti ghcr.io/actions/actions-runner:latest bash
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
runner@c8aa7e25c76c:~$ make
bash: make: command not found
runner@c8aa7e25c76c:~$ git
bash: git: command not found
Ну, те, що нема make – ще якось можна зрозуміти. Але на GitHub Runners не додати “в коробку” git?
Але ок… Маємо, що маємо. Що ми можемо зробити – це створити власний образ, де за базу будемо брати ghcr.io/actions/actions-runner, і встановлювати все, що нам необхідно для щастя.
Отже, наш базовий образ GitHub Runners використовує Ubuntu 22.04, тому можемо з apt встановити всі потрібні пакети.
Описуємо Dockerfile – я тут вже додав і AWS CLI, і кілька пакетів для Python:
FROM ghcr.io/actions/actions-runner:latest
RUN sudo curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | sudo bash
RUN sudo apt update && \
sudo apt -y install git make python3-pip awscli python3-venv
Але ще можливі warnings типу такого:
WARNING: The script gunicorn is installed in ‘/home/runner/.local/bin’ which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use –no-warn-script-location.
Тому в Dockerfile додав PATH:
FROM ghcr.io/actions/actions-runner:latest
ENV PATH="$PATH:/home/runner/.local/bin"
RUN sudo curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | sudo bash
RUN sudo apt update && \
sudo apt -y install git make python3-pip awscli python3-venv
Деплоїмо Helm, і тепер маємо два контейнери в поді з раннером – один сам runner, інший – dind:
==> New container [kraken-eks-runners-trb9h-runner-klfxk:dind]
==> New container [kraken-eks-runners-trb9h-runner-klfxk:runner]
Запускаємо білд, і… Маємо нову помилку 🙂
Привіт DinD та Docker volumes.
Помилка виглядає так:
Error: ENOENT: no such file or directory, open ‘/app/openapi.yml’
Docker in Docker та Docker volumes
Виникає вона через те, що в коді API створюється директорія в /tmp, в якій генерується файл openapi.yml, з якого потім генерується HTML з документацією:
Тут Path(tempfile.mkdtemp()) створює нову директорію в /tmp – але це виконується всередині контейнера kraken-eks-runners-trb9h-runner-klfxk:runner, а docker run -v f"{app_volume_path}:/app" запускається всередині контейнера kraken-eks-runners-trb9h-runner-klfxk:dind.
Давайте просто глянемо на маніфест поду:
$ kk -n ops-github-runners-ns describe autoscalingrunnerset kraken-eks-runners
...
Template:
Spec:
Containers:
...
Image: 492***148.dkr.ecr.us-east-1.amazonaws.com/github-runners/kraken:0.8
Name: runner
...
Volume Mounts:
Mount Path: /home/runner/_work
Name: work
...
Image: docker:dind
Name: dind
...
Volume Mounts:
Mount Path: /home/runner/_work
Name: work
...
Тобто, у обох контейнерів є спільний каталог /home/runner/_work, який створюється на хості/EC2, і маунтиться в Kubernetes Pod до обох Docker-контейнерів.
А каталог /tmp в контейнері runner – “локальний” для нього, і недоступний для контейнера з dind.
Тому як варіант – просто створювати новий каталог для файлу openapi.yml всередині /home/runner/_work:
...
# get $HONE, fallback to the '/home/runner'
home = os.environ.get('HOME', '/home/runner')
# set app_volume_path == '/home/runner/_work/tmp/'
app_volume_path = Path(home) / "_work/tmp/"
# mkdir recursive, exist_ok=True in case the dir already created by openapi/asyncapi
app_volume_path.mkdir(parents=True, exist_ok=True)
(app_volume_path / "openapi.yml").write_text(yml_path.read_text())
...
Або зробити ще краще – на випадок, якщо білд буде запускатись на GitHub hosted Runners, то додати перевірку того, на якому саме раннері запущена джоба, і відповідно вибирати де створювати каталог.
В values нашого Scale Set додаємо змінну RUNNER_EKS:
А в коді – перевірку цієї змінної, і в залежності від неї задаємо каталог app_volume_path:
...
# our runners will have the 'RUNNER_EKS=true'
if os.environ.get('RUNNER_EKS', '').lower() == 'true':
# Get $HOME, fallback to the '/home/runner'
home = os.environ.get('HOME', '/home/runner')
# Set app_volume_path to the '/home/runner/_work/tmp/'
app_volume_path = Path(home) / "_work/tmp/"
# mkdir recursive, exist_ok=True in case the dir already created by openapi/asyncapi
app_volume_path.mkdir(parents=True, exist_ok=True)
# otherwize if it's a GitHub hosted Runner without the 'RUNNER_EKS', use the old code
else:
app_volume_path = Path(tempfile.mkdtemp())
(app_volume_path / "openapi.yml").write_text(yml_path.read_text())
...
Запускаємо білд ще раз – і тепер все працює:
Помилка “Access to the path ‘/home/runner/_work/_temp/_github_home/.kube/cache’ is denied”
Ще іноді виникає проблема, коли в кінці білда-деплоя джоба завершується з повідомленням “Error: The opeation was canceled“:
В логах раннера при цьому є і причина – він не може видалити директорію _github_home/.kube/cache:
...
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z INFO TempDirectoryManager] Cleaning runner temp folder: /home/runner/_work/_temp
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z ERR TempDirectoryManager] System.AggregateException: One or more errors occurred. (Access to the path '/home/runner/_work/_temp/_github_home/.kube/cache' is denied.)
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z ERR TempDirectoryManager] ---> System.UnauthorizedAccessException: Access to the path '/home/runner/_work/_temp/_github_home/.kube/cache' is denied.
kraken-eks-runners-wwn6k-runner-zlw7s:runner [WORKER 2024-09-20 10:55:23Z ERR TempDirectoryManager] ---> System.IO.IOException: Permission denied
...
І дійсно, якщо перевірити каталог /home/runner/_work/_temp/_github_home/ з контейнера runner – то він туди доступу не має:
runner@kraken-eks-runners-7pd5d-runner-frbbb:~$ ls -l /home/runner/_work/_temp/_github_home/.kube/cache
ls: cannot open directory '/home/runner/_work/_temp/_github_home/.kube/cache': Permission denied
Але доступ є з контейнера з dind, який цей каталог і створює:
runner@kraken-eks-runners-7pd5d-runner-frbbb:~$ id runner
uid=1001(runner) gid=1001(runner) groups=1001(runner),27(sudo),123(docker)
Цікаво, що помилка виникає не постійно, а час від часу, хоча в самому workflow нічного не міняється.
Каталог .kube/config створюється з action bitovi/github-actions-deploy-eks-helm, який виконує aws eks update-kubeconfig з власного Docker-контейнера, і запускається від рута, бо запускається в Docker in Docker.
З варіантів приходить в голову два рішення:
або просто додати костиль у вигляді додаткової команди chown -r 1001:1001 /home/runner/_work/_temp/_github_home/.kube/cache в кінці деплою (хоча можна таким жеж костилем просто видаляти директорію)
або змінити GITHUB_HOME в іншу директорію – тоді aws eks update-kubeconfig буде створювати .kube/cache в іншому місці, і контейнер з runner зможе виконати Cleaning runner temp folder
Хоча я все одно не розумію, чому Cleaning runner temp folder виконується не кожного разу, і, відповідно, це “плаваючий баг”. Подивимось далі, як воно буде в роботі.
Підключення High IOPS Volume
Одна з причин, чому ми хочемо перейти на власні раннери – це пришвидшити білди-деплої.
Але велику частку часу займаються команди типу docker load && docker save.
Тому хочеться спробувати підключити AWS EBS з високим IOPS, бо дефолтний gp2 має 100 IOPS на кожен GB розміру – див. Amazon EBS volume types.
У values нашого пула раннерів додаємо блок volumes, де перевизначаємо параметри для диска work, який по дефолту створюється з emptyDir: {} – задаємо новий storageClassName:
Деплоїмо ці зміни AutoscalingRunnerSet, запускаємо наш деплой, і – поди з раннерами створюються, але тут жеж вбиваються, а сама джоба фейлиться.
Помилка “Access to the path ‘/home/runner/_work/_tool’ is denied”
Дивимось логи раннерів, і бачимо, що:
kraken-eks-runners-gz866-runner-nx89n:runner [RUNNER 2024-09-24 10:15:40Z ERR JobDispatcher] System.UnauthorizedAccessException: Access to the path ‘/home/runner/_work/_tool’ is denied.
Про саму VictoriaMetrics Cloud напишу окремо, а зараз хочу перевірити як можна писати CloudWatch Metrcis через AWS Firehose до VictoriaMetrics Cloud.
Власне, сам сервіс AWS Data Firehose дозволяє передачу потокових даних з різних джерел до сервісів Amazon на кшталт AWS S3, Redshift, OpenSearch, або до зовнішніх – Datadog, New Relic, і т.д.
Нещодавно VictoriaMetrics запустила (поки що в Beta) власну підтримку AWS Data Firehose, і тепер ми можемо стрімити дані до VictoriaMetrics Cloud.
Приємна особливість цього сетапу, що нам фактично не треба самим запускати якісь сервери або експортери для збору метрик – все повністю agentless та serverless, бо Data Firehose – це AWS Managed сервіс, який просто працює, а VictoriaMetrics Cloud працює повністю на інфраструктурі VictoriaMetrics, і не потребує від нас якихось особливих налаштувань.
Ще з цікавих моментів, це те, що CloudWatch віддає метрики а VictoriaMetrics приймає їх в форматі OpenTelemetry, хоча при бажанні у VictoriaMetrics можна їх конвертувати в формат Prometheus.
Власне, що будемо робити:
налаштуємо AWS Data Firehose Stream для передачі даних до VictoriaMetrics Cloud
налаштуємо CloudWatch Metrics Stream для передачі метрик в цей Firehose Stream
VictoriaMetrics Cloud Authentification
Перше, що потрібно зробити – це отримати URL ендпоінту, на який будуть відправлятись дані.
У VictoriaMetrics Cloud маємо створений Deployment (див. Creating deployments), в Overview якого маємо параметр Access Endpoint:
З CloudWatch до VictoriaMetrics будемо писати в форматі OpenTelemetry, тому повний ендпоінт буде з URI /opentelemetry/api/v1/push – https://gw-c7-2b.cloud.victoriametrics.com/opentelemetry/api/v1/push.
Створення AWS Data Firehose Stream
Тут все доволі просто: нам потрібно задати Source, тобто – звідки і які дані будуть йти, і вказати Destination – куди ці дані відправляти.
При необхідності можна з AWS Lambda робити трансформації, але у випадку з метриками CloudWatch це не обов’язково.
Отже, переходимо до Amazon Data Firehose, клікаємо Create Firehose stream:
В Source вибираємо Direct PUT:
В Destination – HTTP Endpoint:
Задаємо Firehose stream name:
В Destination settings – вказуємо HTTP endpoint URL, який отримали в VictoriaMetrics Cloud + /opentelemetry/api/v1/push:
Токен аутентифікації задаємо в Access key у форматі “Bearer TOKEN_VALUE“:
Опціонально – включаємо GZIP.
Firehose потребує налаштування Backup storage для даних, які не зміг відправити до Destination – див. Handle data delivery failures.
Задаємо ім’я AWS S3 бакету:
Зберігаємо новий стрім – він готовий приймати дані.
Вибираємо Custom setup with Firehose, вибираємо створений вище стрім:
При необхідності – можна вибрати формат, але дефолтний OpenTelemetry 1.0 підтримується:
Вибираємо які саме метрики хочемо відправляти – всі, або тільки обрані:
Останнім задаємо ім’я стріма:
Перевіряємо, що Status == Running:
Перевірка Firehose Stream
Тепер маємо CloudWatch Metrcis Stream, який пише метрики до Firehose Stream, який потім відправляє їх до HTTP Endpoint у VictoriaMetrcis Cloud.
Чекаємо хвилин 5, і спершу перевіряємо метрики в CloudWatch Metrcis Stream:
Якщо тут метрики є, то переходимо до Firehose Stream > Monitoring, де маємо побачити, що дані йдуть до VictoriaMetrics Cloud:
При проблемах з відправкою даних – дивимось вкладку Destination error logs:
Також можна перевірити вкладку Monitoring в VictoriaMetrics – на графіку Ingestion rate мають бути запити з {type="opentelemetry"}:
VictoriaMetrics Explore та метрики CloudWatch
Включаємо Autocomplete – і маємо отримати список метрик, які приходять з AWS CloudWatch:
І далі можемо вже робити запити, наприклад використовуючи лейблу __name__:
sum({__name__="amazonaws.com/AWS/EC2/CPUUtilization"}) by (Namespace, cloud.region)
А аби переключити формат метрик з OpenTelemetry на Prometheus – переходимо до Settings > Advanced Settings, і додаємо параметр -opentelemetry.usePrometheusNaming:
Disruption budgets з’явились в версії 0.36, і виглядає як дуже цікавий інструмент для того, аби обмежити Karpenter в перестворенні WorkerNodes.
Наприклад в моєму випадку ми не хочемо, аби EC2 вбивались в робочі часи по США, бо там у нас клієнти, а тому зараз маємо consolidationPolicy=whenEmpty, аби запобігти “зайвому” видаленню серверів та Pods на них.
Натомість з Disruption budgets ми можемо налаштувати політики таким чином, що в один період часу будуть дозволені операції з WhenEmpty, а в інший – WhenEmptyOrUnderutilized.
Спочатку глянемо, в яких випадках Disruption взагалі відбувається:
Drift: виникає, коли є різниця між створеними конфігураціями NodePools або EC2NodeClass та існуючими WorkerNodes – тоді Karpenter почне перестворювати EC2 аби привести їх у відповідність до заданих параметрів
Interruption: якщо Karpenter отримує AWS Event, що інстанс буде виключено, наприклад – якщо це Spot
Consolidation: якщо маємо налаштування Consolidation на WhenEmptyOrUnderutilized або WhenEmpty, і Karpenter переносить наші Pods на інші WorkerNodes
у нас Karpenter 1.0, тому полісі WhenEmptyOrUnderutilized, для 0.37 це WhenUnderutilized
Karpenter Disruption Budgets
За допомогою Disruption budgets ми можемо дуже гнучко налаштувати в який час і які операції Karpenter може проводити, і задати ліміт на те, скільки WorkerNodes одночасно будуть видалятись.
duration: і скільки часу правило діє, наприклад – 1h15m
При цьому не обов’язково задавати всі параметри.
Наприклад, ми можемо описати два таких бюджети:
- nodes: "25%"
- nodes: "10"
Тоді у нас постійно будуть працювати обидва правила, і перше обмежує кількість нод в 25% від загальної кількості, а друге – не більше як 10 інстансів – якщо у нас більш ніж 40 серверів.
Також, Budgets можна комбінувати, і якщо їх задано кілька – то ліміти будуть братись по найбільш суворому.
В першому прикладі ми застосовуємо правило на 20% нод і умові WhenEmpty, а решту часу будуть працювати дефолтні правила disruption – тобто, 10% від загальної кількості серверів із заданою consolidationPolicy.
Тут останнє правило працює постійно, і буде таким собі запобіжником: ми забороняємо все, але дозоляємо виконувати disruption за політикою WhenEmpty на протязі 10 хвилин раз на добу починаючи з 00:00 UTC.
Приклад Disruption Budgets
Повертаючись до моєї задачі:
маємо Backend API в Kubernetes на окремому NodePool, а наші клієнти в основному з США, тому ми хочемо мінімізувати down-скейлінг WorkerNodes в робочий час по США
для цього ми хочемо заблокувати всі операції по WhenUnderutilized в період робочого часу по Central Time USA
в schedule Karpenter використовує зону UTC, тому початок робочого дня по Central Time USA 9:00 – це 15:00 UTC
операції з WhenEmpty дозволимо в будь-який час, але тільки по 1 WorkerNode одночасно
Drift – аналогічно, бо коли я деплою зміни – то хочу побачити результат відразу
Фактично, нам потрібно задати два бюджети:
по Underutilized – забороняємо все з понеділка по п’ятницю на протязі 9 годин починаючи з 15:00 по UTC
по Empty та Drifted – дозволяємо в будь-який час, але тільки по 1 ноді, а не дефолтні 10%
Тоді наш NodePool буде виглядати так:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: backend1a
spec:
template:
metadata:
labels:
created-by: karpenter
component: devops
spec:
taints:
- key: BackendOnly
operator: Exists
effect: NoSchedule
nodeClassRef:
group: karpenter.k8s.aws
kind: EC2NodeClass
name: defaultv1a
requirements:
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["c5"]
- key: karpenter.k8s.aws/instance-size
operator: In
values: ["large", "xlarge"]
- key: topology.kubernetes.io/zone
operator: In
values: ["us-east-1a"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot", "on-demand"]
# total cluster limits
limits:
cpu: 1000
memory: 1000Gi
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 600s
budgets:
- nodes: "0" # block all
reasons:
- "Underutilized" # if reason == underutilized
schedule: "0 15 * * mon-fri" # starting at 15:00 UTC during weekdays
duration: 9h # during 9 hours
- nodes: "1" # allow by 1 WorkerNode at a time
reasons:
- "Empty"
- "Drifted"
VictoriaLogs – відносно нова система для збору та аналізу логів, схожа на Grafana Loki, але – як і VictoriaMetrics в порівнянні з “ванільним” Prometheus – менш вибаглива до ресурсів CPU/Memory.
Особисто я користуюсь Grafana Loki років 5, але до неї іноді буває дуже багато питань – і по документації, і по загальній складності системи, бо багато компонентів, і по перформансу – бо як я її не тюнив (див. Grafana Loki: оптимізація роботи – Recording Rules, кешування та паралельні запити), але іноді на відносно невеликих запитах Grafana повертає 504 від Loki Gateway, і я, якщо чесно, вже втомився з цим розбиратись.
Ну а оскільки у нас сам моніторинг побудований на VictoriaMetrics, і до VictoriaLogs вже “завезли” підтримку Grafana data source – то прийшов час спробувати її в роботі, і порівняти з Grafana Loki.
Чого у VictoriaLogs поки що нема:
підтримки AWS S3 бекенду – але обіцяють зробити в листопаді 2024 (до того, ж якоюсь “магічною” автоматизацією – коли старі дані з локального диску автоматично будуть перенесені до відповідного S3)
поки що нема аналога Loki RecordingRules – коли з логів створюємо звичайні метрики, їх записуємо в VictoriaMetrics/Prometheus, а потім робимо алерти в VMAlert та дашборди в Grafana, але знов-таки скоро має бути – жовтень-листопад 2024
Grafana data source теж ще в Beta, тому є складності з побудовою графіків в Grafana
І прям біда з всякими ChatGPT для генерації запитів – але про це поговоримо далі.
Документація – як завжди у VictoriaMetrcis чудова – VictoriaLogs.
Для початку зробимо все руками, спочатку з якимись дефолтними values, потім подивимось, що воно нам встановить в Kubernetes і як воно працює – а потім будемо додавати в автоматизацію.
В чарті VictoriaLogs є можливість відразу запустити Fluetbit DaemonSet, але в нас вже є Promtail, тому будемо використовувати його.
Всі values є в документації до чарту, а з того, що може бути цікаве зараз:
extraVolumeMounts та extraVolumes: можемо створити власний окремий persistentVolume з AWS EBS, та підключати його до VictoriaLogs
persistentVolume.enabled та persistentVolume.storageClassName: або можемо просто вказати, що його треба створювати, і при потребі задати власний storageClass з ReclaimPolicy retain
$ kk get pod
NAME READY STATUS RESTARTS AGE
vlsingle-victoria-logs-single-server-0 1/1 Running 0 36s
І глянемо на ресурси:
$ kk top pod
NAME CPU(cores) MEMORY(bytes)
vlsingle-victoria-logs-single-server-0 1m 3Mi
3 мегабайти пам’яті 🙂
Забігаючи наперед – після підключення запису логів з Promtail до VictoriaLogs ресурсів буде використовуватись не набагато більше.
Відкриваємо доступ до UI:
$ kk -n ops-test-vmlogs-ns port-forward svc/vlsingle-victoria-logs-single-server 9428
В браузері заходимо на http://localhost:9428.
Як і інші сервіси від VictoriaMetrics – попадаємо на сторінку з усіма необхідними посиланнями:
Переходимо на http://localhost:9428/select/vmui/ – поки що тут пусто:
Додамо відправку логів з Promtail.
Налаштування Promtail
До VictoriaLogs можна писати логи в форматі Elasticsearch, ndjson або Loki – див. Data ingestion.
Власне нас цікавить саме Loki, і логи ми пишемо з Promtail. Приклад конфігурації Promtail для VictoriaLogs див. у Promtail setup.
У нас Promtail встановлюється з його власного чарту, який створює Kubernetes Secret з promtail.yml.
Оновлюємо values чарту, в config.clients додаємо ще один URL – в моєму випадку він буде неймспейсом з ops-test-vmlogs-ns.svc, бо VictoriaLogs запущена в іншому неймспейсі, ніж Loki:
Деплоїмо зміни, чекаємо рестарту подів з Promtail, і ще раз перевіряємо логи в VictoriaLogs:
VictoriaLogs Log Streams
Під час запису логів до VictoriaLogs ми можемо задати додаткові параметри – див. HTTP parameters.
З того, що може бути цікавим зараз – це спробувати створити власні Log Stream, аби по ним потім робити фільтрацію логів для більш швидкої їх обробки. див. Stream fields.
Якщо лог-стрім не заданий – то VictoriaLogs пише все в один дефолтний стрім {}, як ми бачили на скріні вище.
Наприклад, у нас в кластері всі аплікейшени розбиті по власним Kubernetes Namespaces – dev-backend-api-ns, prod-backend-api-ns, ops-monitoring-ns і т.д.
Давайте створимо окремий стрім на кожен неймспейс – до url додаємо ?_stream_fields=namespace:
$ kk top pod
NAME CPU(cores) MEMORY(bytes)
vlsingle-victoria-logs-single-server-0 2m 14Mi
При тому, що пишеться однакова кількість логів.
Так – в Loki зараз є пачка RecordingRules, так – є пара дашборд в Grafana, які виконують запити напряму до Loki для графіків, але ж ну камон! Це небо і земля!
Можливо, це ще й мої криві руки, які не змогли нормально затюнити Loki – проте VictoriaLogs зараз запущена взагалі без всякого тюнингу.
LogsQL
Окей – маємо інстанс VictoriaLogs, маємо логи, які в неї пишуться.
Давайте спробуємо “покверяти” і розібратися з LogsQL взагалі, та трохи порівняти з LogQL від Loki.
Тут все просто – пишемо запит в полі Log queiry, отримуємо результат.
Результат можемо сформувати в форматі Group by, Table та JSON – його ми вже бачили в HTTP API.
В форматі Group by результат виводиться по кожному стріму:
А в форматі Table – колонками по іменам полей з логів:
Синтаксис LogsQL
Взагалі, можливостей прям дуже багато – див. всі в документації LogsQL.
Але давайте глянемо хоча б основні, аби мати уяву що ми можемо робити.
Самий простий приклад запитів з LogsQL ми вже бачили – просто по слову “error“.
Аби виконати пошук по фразі – “загортаємо” її в лапки:
Сортування
Важливий нюанс – результати повертаються у довільному порядку з метою покращення перформансу, тому рекомендується використовувати sort pipe по полю _time:
_time:5m error | sort by (_time)
Comments
Дуже прикольно, що ми в запити можемо додавати коментарі, наприклад:
_time:5m | app:="backend-api" AND namespace:="prod-backend-api-ns" # this is a comment
| unpack_json | keep path, duration, _msg, _time # and an another one comment
| stats by(path) avg(duration) avg_duration | path:!"" | limit 10
Оператори
В LogsQL вони називаються Logical filter – AND, OR, NOT.
Наприклад, використати AND можемо так – шукаємо запис, в якому є строка “Received request” та ID “dada85f9246d4e788205ee1670cfbc6f“:
"Received request" AND "dada85f9246d4e788205ee1670cfbc6f"
Або зробити пошук по “Received request” тільки зі стриму namespace="prod-backend-api-ns":
"Received request" AND _stream:{namespace="prod-backend-api-ns"}
Або по полю pod:
"Received request" AND pod:="backend-api-deployment-98fcb6bcb-w9j26"
При чому оператор AND можна не задавати явно, тобто запит:
Але в прикладах далі я все ж буду додавати AND для ясності.
Фільтри
Будь-який запит LogsQL має містити хоча б один фільтр.
Коли ми робимо запит на кшталт “Received request” – то фактично ми використовуємо фільтр Phrase filter, який за замовченням застосовується до поля _msg.
А в запиті _stream:{namespace="prod-backend-api-ns"} ми використовуємо Stream filter.
Інші цікаві фільтри:
Time filter – можна задати проміжок часу в хвилинах/годинах або датах
Я вже не буду тут описувати приклади, бо в цілому вони – і багато іншого – є в документації, але давайте глянемо приклад запиту для Loki, і спробуємо переписати його для VictoriaLogs – і там як раз спробуємо pipes в ділі.
З логів Kubernetes Pods нашого бекенду створює метрику eks:pod:backend:api:path_duration:avg, в якій відображає середній час відповіді по ендпоінтам.
В ньому маємо:
вибираємо логи з лог-стріма app="backend-api"
логи пишуться в JSON, тому використовуємо json парсер
потім з regex parser створюємо поле domain зі значенням після “https://“
з line_format отримуємо поля path та duration
з unwrap “витягуємо” значення з duration
рахуємо середнє значення з duration за допомогою оператора avg_over_time() за останні 5 хвилин, групуючи по полям domain, path, node_name – вони потім використовуються в алертах і графіках Grafana
збираємо інформацію по топ-10 записів
Як ми можемо щось схоже зробити з VictoriaLogs та LogsQL?
Почнемо з фільтра по полю:
app:="backend-api"
Отримуємо всі записи з подів цієї апки.
Пам’ятаємо, що можемо використати тут регулярку, і задати фільтр як app:~"backend" – тоді будуть результати з app="backend-celery-workers", app="backend-api" і т.д.
Можна додати фільтр по стріму – тільки з продакшена:
_stream:{namespace="prod-backend-api-ns"} AND app:="backend-api"
Або просто:
namespace:="prod-backend-api-ns" AND app:="backend-api"
В наших метриках Loki неймспейс не використовується, бо фільтри в алертах і Grafana використовують ім’я домену з поля domain, але тут для приклада най буде.
Далі нам треба створити поля domain, path та duration.
unpack_json розпарсить JSON, і створить поля для запису з кожного ключа в JSON:
в документації до unpack_json говориться, що краще використовувати extract pipe
якщо використовувати його, то запит був би | extract '"duration": <duration>,'
Але нам всі поля не потрібні – тому можемо дропнути всі, і з фільтром keep залишити тільки duration, _msg та _time:
Далі, нам потрібно створити поле domain. Але просто взяти key url який створив unpack_json із {"url": "http://api.app.example.co/coach/notifications?limit=0" ...} нам не підходить, бо потрібен тільки домен – без строки “/coach/notifications?limit=0“.
Замість limit можна використати top pipe – бо limit просто обмежує кількість запитів, а top обмежує саме по значенню поля:
_time:5m | app:="backend-api" AND namespace:="prod-backend-api-ns" | unpack_json | keep path, duration, _msg, _time | stats by(path) avg(duration) avg_duration | path:!"" | top 10 by (path, duration)
І можемо додати sort(), а умову path:!"" винести перед викликом stats(), аби швидше оброблювався запит:
_time:5m | app:="backend-api" AND namespace:="prod-backend-api-ns" | unpack_json | keep path, duration, _msg, _time | path:!"" | stats by(path) avg(duration) avg_duration | sort by (_time, avg_duration) | top 10 by (path, avg_duration)
Порівняємо його з результатом з Loki, наприклад – API-ендпоінт /sprint-planning/backlog/challenges в результатах VictoriaLogs у нас тут має значення 160.464981 мілісекунд.
Давайте відразу сюди ж додамо VictoriaLogs. Нагадаю, що у нас весь стек моніторинг встановлюється з нашого власного чарту, в якому через Helm dependency додаються victoria-metrics-k8s-stack, k8s-event-logger, aws-xray і т.д.
Зверніть увагу, що тут _time переміщено у виклик stats() – робити статистку по останній хвилині для кожного path.
І результат такий:
Крім того, Data source поки не дає можливості переписати Options > Legend.
Висновки
Складно робити якісь висновки отак одразу, але в цілому – система подобається, і однозначно варта того, аби її спробувати.
До LogsQL треба звикнути та навчитись з ним працювати, але можливостей дає більше.
По ресурсам CPU/Memory – тут взагалі жодних питань.
Grafana data source працює, чекаємо на його реліз.
Ну і чекаємо, коли завезуть підтримку AWS S3 та аналог Loki RecordingRules, бо на сьогодні VictoriaLogs можна використовувати виключно як систему для роботи з логами – але не для графіків чи алертів.
Біда, що всякі ChatGPT толком не можуть допомогти з запитами LogsQL, бо для Loki я ними користувався доволі часто, але згодом і вони цьому навчаться. Проте Perplexity відповідає майже без помилок.
Отже, з плюсів:
працює дійсно швидше, і дійсно НАБАГАТО менше споживає ресурсів
LogsQL приємний, багато можливостей
документація у VictoriaMetrics завжди досить детальна, з прикладами, добре структурована
підтримка у VictoriaMetrics теж чудова – і в GitHub Issues, і в Slack, і в Telegram – завжди можна поставити питання, і досить швидко отримати відповідь
на відміну від Grafana Loki – VictoriaLogs має власний Web UI, і як на мене – то це жирний плюс
З відносних мінусів:
і VictoriaLogs і Grafana data source все ще в Beta – тому можливі і якісь неочікувані проблеми, і не всі можливості поки що реалізовані
але знаючи команду VictoriaMetrics – вони досить швидко все роблять
відсутність RecordingRules та підтримки AWS S3 – це наразі те, що блокує особисто мене від того, аби повністю видалити Grafana Loki
але всі основні плюшки мають завезти до кінця 2024
ChatGPT/Gemini/Claude прям зовсім погано знають LogsQL, тому на їх допомогу очікувати не треба
але є допомога в Slack, і в Telegram самої VictoriaMetrics – і від комьюніті, і від команди розробників, ну і Perplexity непогано справляється
Перевіряємо статус поду – і бачимо чудове повідомлення “An IAM role must be associated with service account“:
Warning FailedMount 43s (x2 over 2m45s) kubelet MountVolume.SetUp failed for volume "backend-api-secret-class-volume" : rpc error: code = Unknown desc = failed to mount secrets store objects for pod dev-backend-api-ns/backend-api-deployment-65c559d47-bb4dz, err: rpc error: code = Unknown desc = us-east-1: An IAM role must be associated with service account backend-api-sa (namespace: dev-backend-api-ns)
В ній жеж є і пул-реквест Add support for Pod Identity Association, який наче має пофіксити цю проблему – але і він досі в Open, хоча декілька днів тому додали комент, що “We are conducting initial investigation on this feature request and will share updates soon“.
І драйвер зараз останньої версії – 0.3.9:
$ helm list -n kube-system | grep secret
secrets-store-csi-driver kube-system 1 2024-07-18 12:46:20.945937022 +0300 EEST deployed secrets-store-csi-driver-1.4.4 1.4.4
secrets-store-csi-driver-provider-aws kube-system 1 2024-07-18 12:46:23.287242734 +0300 EEST deployed secrets-store-csi-driver-provider-aws-0.3.9
То що робити?
Варіант перший – це знов додавати OIDC і стару схему. Але цього прям зовсім не хочеться, бо на новому Kubernetes-кластері хотілося б вже і повністю нову аутентифікацію, а не ліпити костилі, які потім треба буде випилювати.
Варіант другий – спробувати перейти з Kubernetes Secrets Store CSI Driver на External Secrets Operator, який вміє працювати з купою різних провайдерів – AWS Secrets Manager, Hashicorp Vault, Google Secrets Manager тощо.
Крім того, мені не дуже подобається те, що для створення Kubernetes Secret за допомогою Kubernetes Secrets Store CSI Driver, в його SecretProviderClass треба окремо описувати objects, а потім їх фактично дублювати в secretObjects.
External Secrets Operator: знайомство
Отже, External Secrets Operator (ESO) вміє отримувати сікрети із зовнішніх ресурсів і створювати звичайні Kubernetes Secrets.
Для доступу в AWS він використовує стандартну схему з ServiceAccount, а значить ми можемо створити EKS Pod Identity Association на AWS IAM Role, яка буде давати доступ до AWS Secrets Manager.
External Secrets Operator використовує два основні ресурси:
SecretStore: описує як саме отримати доступ до секретів – який провайдер (AWS, Google, Vault, etc) та аутентифікація, і створюється на рівні окремого Kubernetes Namespace для розподілення доступів
також є ClusterSecretStore, який можна створити глобально і доступний з будь-якого Namespace
ExternalSecret: описує які дані отримати від провайдера, і при потребі – які зміни зробити
External Secrets Operator має цілу купу зовнішніх провайдерів – див. Provider.
Крім того, External Secrets Operator може навіть вносити зміни в AWS Secrets Manager – але ми будемо його використовувати тільки для створення Kubernetes Secrets, бо самі секрети в AWS Secrets Manager створюються з Terraform кожного проекту.
Отже, наша задача:
встановити External Secrets Operator
налаштувати йому доступ до AWS з AWS IAM Role та Kubernetes ServiceAccount використовуючи EKS Pod Identities
і створити Kubernetes Secret, який ми зможемо підключити в Kubernetes Pod, аби задати потрібні environment variables для роботи нашого сервісу
Запуск External Secrets Operator з Helm
Додаємо репозиторій:
$ helm repo add external-secrets https://charts.external-secrets.io
"external-secrets" has been added to your repositories
$ kk -n ops-external-secrets-ns get pod
NAME READY STATUS RESTARTS AGE
external-secrets-5859d8dc69-vxhjb 1/1 Running 0 33s
external-secrets-cert-controller-5bbb8c4bb8-nmjn9 1/1 Running 0 33s
external-secrets-webhook-564cd5b69-r5mmb 1/1 Running 0 33s
Та ServiceAccounts:
$ kk -n ops-external-secrets-ns get sa
NAME SECRETS AGE
default 0 10m
external-secrets 0 9m59s
external-secrets-cert-controller 0 9m59s
external-secrets-webhook 0 9m59s
Нас тут цікавить ServiceAccount external-secrets – оператор буде використовувати його для доступу до Secrets Manager та Parameter Store, і його ми будемо підключати до EKS з Pod Indentity.
Аутентифікація з AWS IAM
Що нам потрібно:
IAM Policy, яка надає доступ до Secrets Manager та Parameter Store
IAM Role з Trust Policy для EKS Pod Indentity
і до цієї ролі підключимо IAM Policy
Тоді под з External Secrets Operator через Kubernetes ServiceAccount буде виконувати Assume цієї ролі, і отримувати доступ до секретів.
Поки зробимо найпростішою схемою, а далі подивимось, як додатково можна розділяти доступи через окремі IAM Roles для кожного SecretStore в різних неймспейсах.
Створення IAM Policy
Переходимо в IAM, створюємо нову IAM Policy, дозволяємо тільки read-операції:
Зберігаємо з ім’ям external-secrets-operator-test-policy:
Створення IAM Role для EKS Pod Identity
Переходимо в IAM Role, створюємо нову роль, в Use case вибираємо EKS – Pod Identity:
Підключаємо створену вище IAM Policy external-secrets-operator-test-policy:
Зберігаємо нову роль з ім’ям external-secrets-operator-test-role, в Trust policy маємо "Service": "pods.eks.amazonaws.com":
Створення EKS Pod Identity Association
Тепер підключаємо цю роль до нашого EKS-кластеру atlas-eks-ops-1-30-cluster в неймспейс ops-external-secrets-ns до Kubernetes ServiceAccount з ім’ям external-secrets:
Окей – тут все готово. Тепер ESO має отримати доступ до секретів та параметрів.
Далі нам потрібен SecretStore, який буде описувати як отримати доступ до AWS Secrets Manager або Parameter Store, та ExternalSecret, який власне буде відповідати за Kubernetes Secrets.
Створення Kubernetes Secrets з AWS Secrets Manager
Документація по всім значенням для ресурсів Operator – в API specification.
Але в такому вигляді воно нам не дуже корисно, тому можемо зробити інакше – додати в data параметр property, в якому вказати конкретний ключ з секрету:
$ kk get secret test-kubernetes-secret -o yaml
apiVersion: v1
data:
SECRET_KEY_1: c2VjcmV0X3ZhbHVlXzE=
SECRET_KEY_2: c2VjcmV0X3ZhbHVlXzI=
...
Advanced IAM Permissions per SecretStore
Тепер давайте глянемо, як ми можемо використовувати IAM Role з окремою IAM Policy на рівні SecretStore.
Тобто замість того, аби мати одну IAM Role з IAM Policy, яка надає доступ до всіх секретів в AWS Secrets Manager, і яку використовує наш External Secrets Operator – ми можемо створити окрему IAM Role, її підключити до конкретного SecretStore в конкретному Kubernetes Namespace, і тоді цей SecretStore буде мати доступ тільки до тих секретів, які описані у відповідній IAM Policy.
Схематично це можна відобразити так:
Отже, що зробимо:
в ролі external-secrets-operator-test-role, яка через EKS Pod Identity підключена до ServiceAccount external-secrets відключимо IAM Policy, яка дає доступ до всіх AWS Secrets
створимо нову IAM Policy external-secrets-operator-test-application-policy, яка буде надавати дозвіл тільки до конкретного секрету
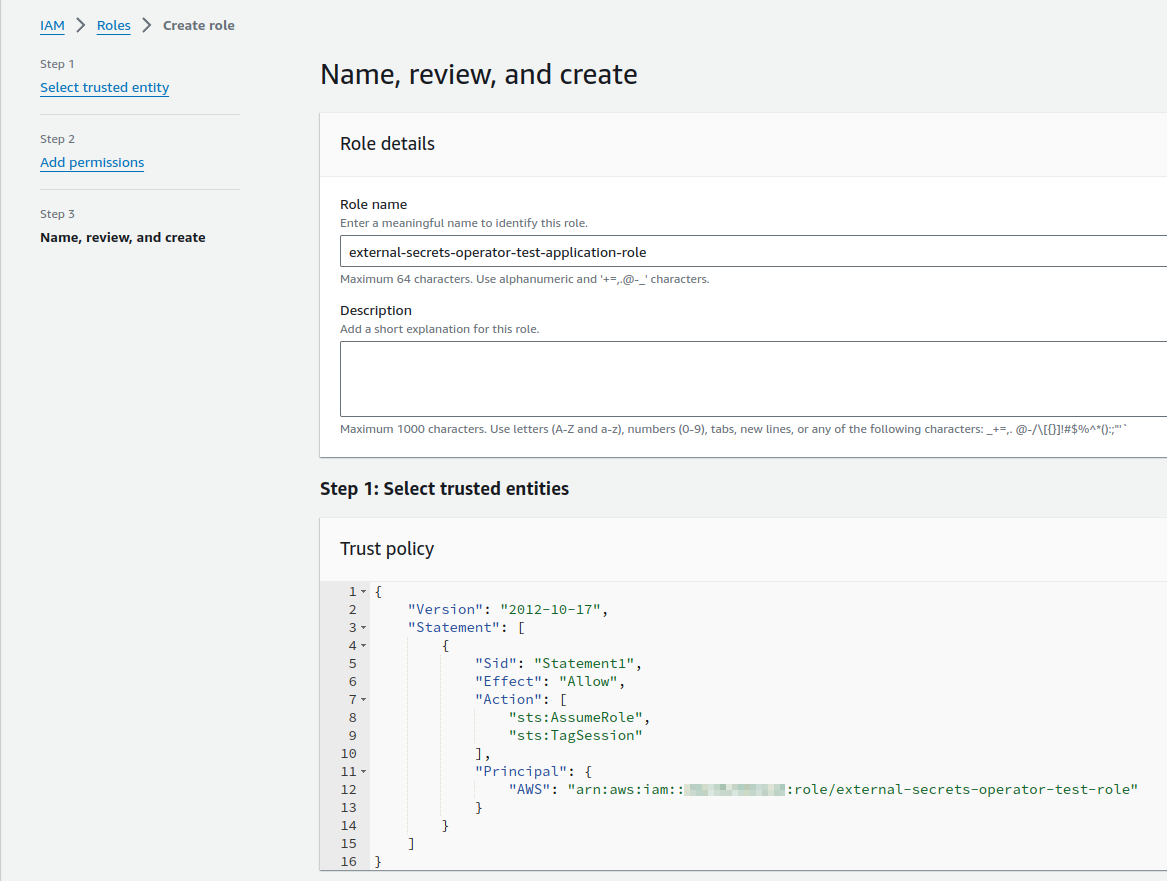
створимо нову IAM Role external-secrets-operator-test-application-role:
їй в Trust Policy дозволимо виконувати Assume від імені ролі external-secrets-operator-test-role
і до цієї ролі підключимо IAM Policy external-secrets-operator-test-application-policy
а до SecretStore додамо параметр з role: external-secrets-operator-test-application-role
Тоді External Secrets буде працювати так:
Kubernets Pod з External Secrets через EKS Pod Identity виконує AssumeRole external-secrets-operator-test-role
при створенні ExternalSecret він використає SecretStore, в якому задана external-secrets-operator-test-application-role
External Secrets з external-secrets-operator-test-role виконає другий AssumeRole – “візьме” роль external-secrets-operator-test-application-role з її IAM Policy external-secrets-operator-test-application-policy
і вже з цієї роллю отримає доступ до секрету в AWS Secrets Manager
Поїхали.
В IAM Role external-secrets-operator-test-role видаляємо підключену IAM Policy, яка давала повний доступ до AWS Secrets Manager:
Створимо нову IAM Policy external-secrets-operator-test-application-policy з доступом до одного конкретного секрету test-aws-secret:
$ kk apply -f test-secretstore.yml
secretstore.external-secrets.io/test-secret-store configured
Для перевірки видалимо старий ExternalSecret:
$ kk delete externalsecret test-external-secret
externalsecret.external-secrets.io "test-external-secret" deleted
Створимо ще раз:
$ kk apply -f test-externalsecret.yml
externalsecret.external-secrets.io/test-external-secret created
І дивимось статус:
$ kk get externalsecret
NAME STORE REFRESH INTERVAL STATUS READY
test-external-secret test-secret-store 1h SecretSynced True
А тепер давайте спробуємо використати інший секрет з AWS Secrets Manager – “test/rds/kraken“, до якого ми не давали дозволу в IAM Policy external-secrets-operator-test-application-policy:
$ kk get externalsecret
NAME STORE REFRESH INTERVAL STATUS READY
test-external-secret test-secret-store 1h SecretSyncedError False
І тепер STATUS == SecretSyncedError.
В логах це добре видно – “external-secrets-operator-test-application-role is not authorized to perform: secretsmanager:GetSecretValue on resource: test/rds/kraken“:
external-secrets-5859d8dc69-2fgc8:external-secrets {... "msg":"could not get secret data from provider","ExternalSecret":{"name":"test-external-secret","namespace":"ops-test-ns"},"error":"AccessDeniedException: User: arn:aws:sts::492***148:assumed-role/external-secrets-operator-test-application-role/1724248118674412261 is not authorized to perform: secretsmanager:GetSecretValue on resource: test/rds/kraken because no identity-based policy allows the secretsmanager:GetSecretValue action\n\tstatus code: 400 ...}
Висновки
Поки що мені External Secrets Operator прям дуже сподобався.
По-перше – дійсно набагато менше коду маніфестів для створення ресурсів.
По-друге – він нормально працює з EKS Pod Identity.
Третє – це дуже гнучка система розподілення доступів до секретів.
Четверте – що за допомогою одного оператора можна створювати Kubernetes Secrets з різних провайдерів.
Та і взагалі простіша система, бо не потрібно мати DaemonSet з подами на кожній WorkerNode, як це реалізовано в secrets-store-csi-driver-provider-aws.
Виглядає дуже прикольно, тому будемо мігрувати на нього.
Доволі частий кейс, коли на новому проекті, який тільки створює свою інфраструктуру і CI/CD, робиться це як MVP/PoC, і на початку на тюнінг AWS IAM Roles та IAM Policies час не витрачається, а просто підключається AdministratorAccess.
Власне, саме так відбувалось і в моєму проекті, але ми ростемо, і прийшов час навести лад в IAM.
Проблема і задача
Отже, маємо GitHub Actions джоби, які деплоять інфрастуктуру з Terraform.
Для доступу до AWS з GitHub використовується Identity Provider з IAM Role: GitHub Actions Worker при старті джоби виконує аутентифікацію та авторизацію в AWS з заданою IAM Role, і потім запускає власне деплой з Terraform.
Для IAM Role зараз підключена політика AdministratorAccess, і наша задача – написати нову fine grained політику, де б не було зайвих доступів.
Варіант перший – це створити пусту політику, підключити її до ролі замість AdministratorAccess, і раз за разом запускати джобу дивлячись на помилки в логах:
А потім по черзі додавати дозволи, наприклад lambda:ListVersionsByFunction.
Він використає CloudTrail events для конкретної ролі та створить IAM Policy в якій будуть тільки ті API-виклики, які дійсно робились цією роллю.
Окрім IAM Access Analyzer є цікава тулза iann0036/iamlive, але в нашому випадку вона не дуже підходить, бо IAM Role використовується в GitHub Actions з AWS Indetity Provider.
Давайте глянемо, як налаштувати IAM Access Analyzer policy generation – створимо CloudTrail, IAM Role, напишемо Terraform-код який буде створювати ресурси, а потім перевіримо які політики нам запропонує Access Analyzer.
Створення CloudTrail Trail
Перше, що нам буде потрібно – це створити CloudTrail Trail, який буде логувати дії. Детальніше про CloudTrail писав в AWS: CloudTrail – обзор и интеграция с CloudWatch и Opsgenie, але зараз нам цікаві тільки типи івентів, які він вміє записувати:
Management events: все, що стосується змін в ресурсах – створення EC2, VPC, зміни в SecurtyGroups тощо
Data events: все, що стосується даних – створення об’єктів в S3-бакетах, зміни в таблицях DynamoDB, виклики Lambda-функцій
Отже, якщо наш Terraform-код займається тільки створенням ресурсів в AWS – то має вистачити Management events, якщо ж він додатково виконує якісь дії з даними/об’єктами – то потрібні обидва. Можна включити всі, але майте на увазі, що CloudTrail trails не безкоштовний – див. AWS CloudTrail pricing.
Переходимо в CloudTrail > Trails, створюємо новий Trail:
Включаємо логування обох типів – просто для перевірки, в цьому випадку точно вистачило б тільки Management events:
Для Data events вибираємо які саме сервіси будемо логувати:
Переходимо до IAM.
Створення IAM Role
Додаємо нову роль з Trusted entity type == AWS Account, бо зараз тестувати будемо локально з AWS CLI від свого IAM-юзера, а не через GitHub OIDC Identity Provider:
Підключаємо AdministratorAccess:
Зберігаємо цю роль:
Налаштування AWS CLI
Тестити будемо локально, але імітуємо роботу GitHub Actions.
Що нам треба – це створити AWS CLI Profile, який буде виконувати AssumeRole, яку ми створили, а потім з цим профайлом Terraform буде створювати ресурси в AWS.
В файлі ~/.aws/config додаємо новий профайл:
[profile iam-test]
region = us-east-1
role_arn = arn:aws:iam::492***148:role/iam-generator-test-TO-DEL
source_profile = work
source_profile = work тут – це мій робочий профайл, в якому задані Access та Secrets keys.
Напишемо простий код, який буде створювати S3 бакет використовуючи створений вище IAM CLI Profile iam-test (пам’ятаємо, що ім’я бакету має бути унікальним для заданого AWS Region, інакше AWS спробує створити корзину в іншому регіоні):
Використання IAM Access Analyzer policy generation
Краще зачекати хвилин 5 після запуску Terraform, аби CloudTrail встиг записати всі події, а потім можемо згенерувати IAM Policy для цієї ролі:
Вибираємо період, регіон та створений раніше Trail:
Чекаємо 5-10 хвилин, поки проаналізуються логи CloudTrail (можна перезавантажувати сторінку з F5, бо іноді Status сам не оновлюється):
І дивимось які політики нам пропонуються:
Ціла купа, і основна для нашого тесту – s3:CreateBucket.
Клікаємо Next, і маємо саму політику в JSON:
Зверніть увагу, що Access Analyzer створив окремі правила на API-виклики, які стосуються всіх бакетів – s3:ListAllMyBuckets, і окремі правила для викликів, які стосуються конкретного бакету/бакетів – s3:CreateBucket.
При цьому в Resource використовується ${BucketName}, який ми можемо замінити на своє значення:
Зберігаємо та підключаємо цю політику:
І тепер можемо відключити AdministratorAccess.
Але маємо на увазі, що ми виконували тільки створення ресурсів і, відповідно, виконувались API-виклики пов’язані тільки зі створенням корзини.
Тобто, якщо ми зараз приберемо AdministratorAccess і залишимо тільки цю нову політику – то виконати terraform destroy не зможемо, бо, по-перше – у нас нема права на s3:DeleteBucket, по-друге – при видаленні корзини AWS має перевірити чи нема в ній об’єктів, а для цього виконується операція s3:ListBucket – тому отримаємо помилку operation error S3: HeadBucket:
Тож треба виконати всі дії з Terraform, а вже після цього генерувати політику:
І потім відключати AdministratorAccess. Але навіть в такому випадку s3:ListBucket (для S3: HeadBucket) треба додавати вручну.
Хоча це вже проблема більш специфічна саме до S3, але може бути подібна і з іншими ресурсами.
Перед тим, як переключати EKS Authentication mode повністю на API – нам потрібно з aws-auth ConfgiMap перенести всіх юзерів і ролі в Access Entries EKS-кластера.
І ідея зараз така, щоб створити окремий проект Terraform, назвемо його “atlas-iam“, в якому ми будемо менеджити всі IAM-доступи – і для EKS з Access Entries та Pod Identities, і для RDS з IAM database authentication, і, можливо, потім сюди ж перенесемо і юзер-менеджмент взагалі.
Не знаю, наскільки описана нижче схема зайде нам в майбутньому Production, але в цілому мені ідея поки що подобається – окрім проблеми з динамічними іменами для EKS Pod Identities.
Отже, поглянемо як ми з Terraform можемо реалізувати автоматизацію управління доступом для IAM Users та IAM Roles до EKS Cluster з EKS Access Entries, та як у Terraform можна створювати EKS Pod Identities для ServiceAccounts. Про додавання RDS сьогодні говорити не будемо – але його будемо мати на увазі при плануванні.
Все описане нижче – скоріш чернетка того, як воно буде, і скоріш за все якісь апдейти по ходу реалізації будуть робитись. Але загальна ідея може бути приблизно такою.
EKS Authentification та IAM: the current state
Зараз в aws-auth ConfgiMap зараз маємо:
IAM Users: звичайні юзери, які ходять в Kubernetes
IAM Roles: ролі для доступу в кластер з GitHub Actions
І всі з правами system:master – заодно наведемо трохи порядок в цьому.
Окремо зараз в проектах (окремі репозиторії для Backend API, моніторинг і т.д.) для відповідних Kubernetes Pods створюються IAM Roles та Kubernetes ServiceAccounts, які теж хочеться звідти винести в цей новий проект, і управляти з одного місця з EKS Pod Identity associations.
Тож наразі у нас по EKS дві задачі:
створити EKS Authentification API Access Entries для юзерів та GitHub ролей
створити Pod Identity associations для ServiceAccounts
Планування проекту
Головне питання тут – на якому рівні будемо менеджити? На рівні AWS-акаунтів – чи на рівні EKS-кластерів/RDS? А від цього будуть залежати і структура коду, і змінні.
Multiple AWS accounts з одним EKS та RDS оточеннями
Варіант 1 – якщо маємо декілька AWS-акаунтів, то можемо управляти на рівні акаунтів: тоді для кожного акаунта можемо створити змінну зі списком EKS-кластерів, змінну зі списком юзерів/ролей, і потім в циклах створювати відповідні ресурси.
Тоді структура файлів Terraform може бути такою:
providers.tf: описуємо AWS provider з assume_role для AWS-акаунту Dev/Staging/Prod (або використовуємо якийсь Terragrunt)
variables.tf: наші змінні з дефолтними значеннями
envs/: каталог з іменами AWS-акаунтів
aws-env-dev: каталог конкретного акаунту
dev.tfvars: значення для змінних з іменами EKS-кластерів і списком юзерів в цьому AWS-акаунті
eks_access_entires.tf: ресурси для EKS
…
І потім в коді в циклі проходимось по всім кластерам та всім юзерам, які задані в envs/aws-env-dev/dev.tfvars.
Але тут буде питання в тому, як створювати юзерів на кластерах:
або мати однакових юзерів і пермішени на всіх кластерах в акаунті, що, в принципі, ОК, якщо маємо AWS-мультіакаунт, і в кожному умовному AWS-Dev у нас тільки EKS-Dev
або створювати декілька ресурсів access_entries – під кожен кластер окремо, і вже в access_entries в циклі проходитись по групам юзерів для конкретного кластеру – якщо в AWS-Dev у нас окрім EKS-Dev якісь додаткові кластери EKS, де треба мати окремий набір юзерів
В моєму випадку у нас поки що один AWS-акаунт з одним Kubernetes-кластером, але пізніше скоріш за все ми будемо їх розділяти та створювати окремі акаунти під Ops/Dev/Staging/Prod. Тоді просто додамо нове оточення в каталог envs/, і там опишемо новий EKS-кластер(и).
Multiple EKS та RDS clusters в одному AWS-акаунті
Варіант 2 – якщо AWS account один на всі EKS-оточення, то можна всім управляти на рівні кластерів, і тоді структура може бути такою:
providers.tf: описуємо AWS provider з assume_role для AWS-акаунту Main
variables.tf: наші змінні з дефолтними значеннями
envs/: каталог з іменами EKS-кластерів
dev/: каталог для EKS Dev
dev-eks-cluster.tfvars – зі списком юзерів EKS Dev
dev-rds-backend.tfvars – зі списком юзерів RDS Dev
prod/
prod-eks-cluster.tfvars – зі списком юзерів EKS Prod
prod-rds-backend.tfvars – зі списком юзерів RDS Prod
eks_access_entires.tf: ресурси для EKS
…
Можна взагалі все “огорнути” в модулі, і потім в циклах викликати саме модулі.
User permissions
Крім того, ще подумаємо про те, які права яким юзерам можуть знадобитись? Це треба, аби далі продумати структуру змінних і цикли for_each в ресурсах:
група devops: будуть кластер-адмінами
група backend:
права edit в усіх Namespaces з іменами “backend“
права read-only на якісь обрані неймспейси
група qa:
права edit в усіх Namespaces з іменами “qa“
права read-only на якісь обрані неймспейси
Тепер, маючи уявлення про те, що нам треба – можна починати створювати файли Terraform і формувати змінні.
Структура файлів Terraform
У нас вже склалась однакова схема на всіх проектах, і новий буде виглядати так – аби не ускладнювати поки що вирішив без модулів, далі побачимо:
в Makefile: команди terraform init/plan/apply – і для виклику локально, і для CI/CD
backend.tf: S3 для стейт-файлів, DynamoDB для state-lock
envs/ops: файли tfvars зі списками кластерів та юзерів в цьому AWS-акаунті
providers.tf: тут provider "aws" з дефолтними тегами і необхідними параметрами
в моєму випадку provider "aws" бере значення змінної оточення AWS_PROFILE для визначення того, на який акаунт він має підключатись, а в AWS_PFOFILE задається регіон та необхідна IAM Role
variables.tf: змінні з дефолтними значеннями
versions.tf: версії самого Terraform та AWS Provider
І сюди ж потім можна буде додати файл типу iam_rds_auth.tf.
Terraform та EKS Access Management API
Почнемо з основного – доступ юзерів.
Для цього нам потрібно:
є юзер, який може належати до однії з груп – devops, backend, qa
йому потрібно задати тип прав доступу – admin, edit, read-only
і ці права видати або на весь кластер – для девопсів, або на конкретний неймспейс(и) – для backend та qa
в aws_eks_access_entry: описуємо EKS Access Entity – IAM User, для якого налаштовуємо доступ, та ім’я кластера, до якого доступ буде додаватись; параметри тут будуть:
cluster name
principal-arn
в eks_access_policy_association – описуємо тип доступу – admin/edit/etc та scope – cluster-wide, або конкретний неймспейс; параметри тут будуть:
списки з юзерами, різні списки для різних груп – можна зробити однієї змінною типу map():
devops:
arn:aws:iam::111222333:user/user-1
arn:aws:iam::111222333:user/user-2
backend:
arn:aws:iam::111222333:user/user-3
arn:aws:iam::111222333:user/user-4
список з EKS Cluster Access Policies – хоча вони дефолтні, і змінюватись навряд чи будуть, але задля загального шаблону давайте теж зробимо окремою змінною
access-scope для aws_eks_access_policy_association – перепробував різні варіанти, але в результаті зробив без овер-інжинірінгу – можемо зробити змінну типу map(object):
група devops:
aws_eks_access_policy_association буде задаватись з access_scope = cluster
група backend:
список неймпспейсів, де всі члени групи будуть мати права edit
список неймпспейсів, де всі члени групи будуть мати права read-only
група qa:
список неймпспейсів, де всі члени групи будуть мати права edit
список неймпспейсів, де всі члени групи будуть мати права read-only
І потім створимо aws_eks_access_policy_association декількома ресурсами для кожної групи окремо. Далі побачимо як саме.
Поїхали – у файлі variables.tf описуємо змінні. Поки що всі значення запишемо в defaults, потім винесемо в tfvars оточень.
Змінна eks_clusters
Спочатку змінну з кластерами – поки тут буде один, тестовий:
variable "eks_clusters" {
description = "List of EKS clusters to create records"
type = set(string)
default = [
"atlas-eks-test-1-28-cluster"
]
}
Змінна eks_users
Додаємо список юзерів в трьох групах:
variable "eks_users" {
description = "IAM Users to be added to EKS with aws_eks_access_entry, one item in the set() per each IAM User"
type = map(list(string))
default = {
devops = [
"arn:aws:iam::492***148:user/arseny"
],
backend = [
"arn:aws:iam::492***148:user/oleksii",
"arn:aws:iam::492***148:user/test-eks-acess-TO-DEL"
],
qa = [
"arn:aws:iam::492***148:user/yehor"
],
}
}
Змінна eks_access_scope
Список для aws_eks_access_policy_association і access-scope, як це може виглядати:
ім’я команди
список неймспейсів на які будуть права admin
список неймспейсів на які будуть права edit
список неймспейсів на які будуть права read-only
Тож можна зробити щось накшталт такого:
variable "eks_access_scope" {
description = "EKS Namespaces for teams to grant access with aws_eks_access_policy_association"
type = map(object({
namespaces_admin = optional(set(string)),
namespaces_edit = optional(set(string)),
namespaces_read_only = optional(set(string))
}))
default = {
backend = {
namespaces_edit = ["*backend*", "*session-notes*"],
namespaces_read_only = ["*ops*"]
},
qa = {
namespaces_edit = ["*qa*"],
namespaces_read_only = ["*backend*"]
}
}
}
Тут:
backend мають права edit доступ на всі Namespaces і іменами “*backend*” та “*session-notes*“, і права read-only на неймспейси з “*ops*” – наприклад, доступ в Namespace “ops-monitoring-ns“, куди бекенд-тіма інколи заходить.
qa мають права edit на всі Namespaces і іменами “*qa*“, і права read-only на неймспейси Backend API
І тоді ми в принципі досить гнучко зможемо додавати першмішени для кожної групи юзерів.
Зверніть увагу, що в type ми задаємо optional(set()) – бо група юзерів може не мати якоїсь групи неймспейсів.
Аби в одному циклі створювати aws_eks_access_entry і для кожного кластера зі списку eks_clusters, і для кожного юзерів з кожної групи – створимо три змінних в locals:
locals {
eks_access_entries_devops = flatten([
for cluster in var.eks_clusters : [
for user_arn in var.eks_users.devops : {
cluster_name = cluster
principal_arn = user_arn
}
]
])
eks_access_entries_backend = flatten([
for cluster in var.eks_clusters : [
for user_arn in var.eks_users.backend : {
cluster_name = cluster
principal_arn = user_arn
}
]
])
eks_access_entries_qa = flatten([
for cluster in var.eks_clusters : [
for user_arn in var.eks_users.qa : {
cluster_name = cluster
principal_arn = user_arn
}
]
])
}
А потім їх використаємо в resource "aws_eks_access_entry" з for_each, яким сформуємо map() з key=idx та value=entry:
І аналогічно створюємо ресурси aws_eks_access_entry для груп backend з local.eks_access_entries_backend і для qa з local.eks_access_entries_qa:
...
resource "aws_eks_access_entry" "backend" {
for_each = { for cluser, user in local.eks_access_entries_backend : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
}
resource "aws_eks_access_entry" "qa" {
for_each = { for cluser, user in local.eks_access_entries_qa : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
}
Створення eks_access_policy_association
Наступний крок – надати цим юзерам пермішени.
Для групи devops це буде cluster-admin, а для бекенду – edit в одних неймспейсах і read-only в інших – по спискам неймспейсів в namespaces_edit та namespaces_read_only у змінній eks_access_scope.
Як і з aws_eks_access_entry – ресурси eks_access_policy_association для кожної групи юзерів зробимо трьома окремими сутностями.
Я вирішив не ускладнювати код, і зробити його більш читабельним, хоча можна було додати ще якийсь locals з flatten() і потім все робити в одному-двох ресурсах aws_eks_access_policy_association з циклами.
Тут знов використовуємо вже існуючі locals – eks_access_entries_devops, eks_access_entries_backend та eks_access_entries_qa з яких беремо кластери і юзерів, а потом для кожного задаємо права – аналогічно тому, як робили для aws_eks_access_entry.
Додаємо перший eks_access_policy_association – для девопсів, з Policy var.eks_access_policies.cluster_admin та access_scope = cluster:
# DEVOPS CLUSTER ADMIN
resource "aws_eks_access_policy_association" "devops" {
for_each = { for cluser, user in local.eks_access_entries_devops : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.cluster_admin
access_scope {
type = "cluster"
}
}
Група backend і права edit на неймспейси задані в списку namespaces_edit змінної eks_access_scope для групи “backend“:
# BACKEND EDIT
resource "aws_eks_access_policy_association" "backend_edit" {
for_each = { for cluser, user in local.eks_access_entries_backend : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_edit
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["backend"].namespaces_edit
}
}
Аналогічно – бекенди, але вже права read-only на групу неймспейсів зі списку namespaces_read_only:
# BACKEND READ ONLY
resource "aws_eks_access_policy_association" "backend_read_only" {
for_each = { for cluser, user in local.eks_access_entries_backend : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_read_only
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["backend"].namespaces_read_only
}
}
І аналогічно для QA:
# QA EDIT
resource "aws_eks_access_policy_association" "qa_edit" {
for_each = { for cluser, user in local.eks_access_entries_qa : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_edit
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["qa"].namespaces_edit
}
}
# QA READ ONLY
resource "aws_eks_access_policy_association" "qa_read_only" {
for_each = { for cluser, user in local.eks_access_entries_qa : cluser => user }
cluster_name = each.value.cluster_name
principal_arn = each.value.principal_arn
policy_arn = var.eks_access_policies.namespace_read_only
access_scope {
type = "namespace"
namespaces = var.eks_access_scope["qa"].namespaces_read_only
}
}
Робимо terraform plan – і маємо юзерів:
Виконуємо terraform apply, і перевіряємо EKS Access Entries:
І пермішени тестового юзера з групи backend:
Перевіряємо як все працює.
Створюємо kubectl context для тестового юзера (--profile test-eks):
$ kk -n ops-monitoring-ns get sa yace-serviceaccount -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::492***148:role/atlas-monitoring-ops-1-28-yace-exporter-access-role
...
Що нам потрібно – це створити Pod Identity associations з такими параметрами:
cluster_name
namespace
service_account
role_arn
Зараз IAM Role для YACE створюється в коді Terraform в репозиторії з моніторингом, і тут є два варіанти:
перенести створення всіх IAM Roles для всіх проектів в цей новий, і потім тут жеж створювати aws_eks_pod_identity_association
але для цього доведеться міняти досить багато коду – випилювати створення ролей в інших проектах, і додавати їх в цей новий, плюс девелопери (якщо говорити про Backend API) вже якось звикли робити це в своїх проектах – потрібно буде писати документацію, як це робити в іншому проекті
або залишити створення ролей в кожному проекті окремо – а в новому просто мати змінну зі списками інших проектів та їхніх ролей (чи використати terraform_remote_state і terraform outputs з кожного проекту)
але тут будемо мати трохи геморою із запуском нових проектів, особливо, якщо там ролі будуть створюватись з якимись динамічними іменами – бо доведеться спочатку виконати terraform apply в новому проекті, отримати там ARN ролей, потім додавати їх в змінні нашого проекту “atlas-iam“, робити terraform apply тут аби ці ролі підключити до EKS, і тільки тоді робити умовний helm install зі створенням ServiceAccount та подів нового проекту
Але в обох варіантах нам для Pod Identity associations потрібно буде задавати такі параметри:
cluster_name: змінна вже є
імена ServiceAccount: вони будуть однакові на всіх кластерах
role_arn: залежить від того, як будемо створювати IAM Roles
namespace: а от тут питаннячко:
ім’я неймспейсу для моніторингу на всіх кластерах у нас однакове – “ops-monitoring-ns“, де Ops – це AWS або EKS оточення
а от для бекенду у нас на одному кластері є і Dev, і Staging, і Production – кожен у власному неймспейсі
А в неймспейсах для Pod Identity association ми вже не можемо використати “*“, як робили з Access Entries для юзерів, тобто маємо створювати окрему Pod Identity association на кожен конкретний неймспейс.
Давайте спочатку подивимось як ми взагалі можемо створювати необхідні ресурси – а потім подумаємо над змінними, і вирішимо яким чином це все реалізувати.
З використанням resource "aws_eks_pod_identity_association"
Варіант перший – використати “ванільний” aws_eks_pod_identity_association з Terraform AWS Provider.
Аби створити Pod Identity association для нашого умовного YACE-екпортеру, нам потрібно:
assume_role_policy: хто зможе виконувати IAM Role Assume
aws_iam_role: IAM Role з необхідними доступами до AWS API
aws_eks_pod_identity_association: підключити цю роль до EKS-кластеру і ServiceAccount в ньому
Давайте зробимо окремий файл для ролей – eks_pod_iam_roles.tf.
Описуємо aws_iam_policy_document – тепер ніяких OIDC, просто pods.eks.amazonaws.com:
# Trust Policy to be used by all IAM Roles
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["pods.eks.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
"sts:TagSession"
]
}
}
Далі – сама роль.
Ролі треба буде створювати для кожного кластеру – тому знов візьмемо нашу змінну variable "eks_clusters", і потім в циклі створимо ролі з іменами під кожен кластер:
# Create an IAM Role to be assumed by Yet Another CloudWatch Exporter
resource "aws_iam_role" "yace_exporter_access" {
for_each = var.eks_clusters
name = "${each.key}-yace-exporter-role"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
inline_policy {
name = "${each.key}-yace-exporter-policy"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"cloudwatch:ListMetrics",
"cloudwatch:GetMetricStatistics",
"cloudwatch:GetMetricData",
"tag:GetResources",
"apigateway:GET"
]
Effect = "Allow"
Resource = ["*"]
},
]
})
}
tags = {
Name = "${each.key}-yace-exporter-role"
}
}
І тепер в eks_pod_identities.tf можемо додати асоціацію:
Де в "aws_iam_role.yace_exporter_access["${each.key}"].arn" посилаємось на IAM Role з конкретним іменем кожного кластеру:
...
# aws_eks_pod_identity_association.yace["atlas-eks-test-1-28-cluster"] will be created
+ resource "aws_eks_pod_identity_association" "yace" {
+ association_arn = (known after apply)
+ association_id = (known after apply)
+ cluster_name = "atlas-eks-test-1-28-cluster"
+ id = (known after apply)
+ namespace = "example"
+ role_arn = (known after apply)
+ service_account = "example-sa"
+ tags_all = {
+ "component" = "devops"
+ "created-by" = "terraform"
+ "environment" = "ops"
}
}
...
З використанням модуля terraform-aws-eks-pod-identity
Інший варіант – робити через terraform-aws-eks-pod-identity. Тоді нам не потрібно окремо описувати роль – ми можемо задати IAM Policy прямо в модулі, і він все створить за нас. Крім того, він дозволяє в одному модулі створити кілька associations для різних кластерів.
І для кожного кластера буде створено і роль, і асоціація:
Крім того, terraform-aws-eks-pod-identity вміє створювати всякі дефолтні IAM Roles – для ALB Ingress Controller, External DNS тощо.
Але в моєму випадку ці сервіси в EKS створюються з aws-ia/eks-blueprints-addons/aws, який сам створює ролі, і якихось змін відносно Pod Identity association я там не бачу (хоча GitHub Issue з обговоренням відкрита ще в листопаді 2023 – див. Switch to IRSAv2/pod identity).
Окей.
То як ми можемо зробити всю цю схему?
у нас будуть IAM Roles – створюються в інших проектах, або в нашому “atlas-iam“
ми будемо знати в які неймспейси які ServiceAccounts нам треба підключати
Яку ми можемо придумати змінну для всього цього діла?
Можемо задати ім’я проекту – “backend-api“, “monitoring“, etc, і в кожному проекті мати списки з неймспейсами, ServiceAccount та IAM Roles.
А потім для кожного проекту мати окремий ресурс aws_eks_pod_identity_association, який в циклі буде проходитись по всім EKS-кластерам в AWS-акаунті.
Проблема: Pod Identity association та динамічні Namespaces
Але! Для Backend API в GitHub Actions у нас створюються динамічні оточення, і для них – Kubernetes Namespaces з іменами типу “pr-1212-backend-api-ns“. Тобто, є статичні неймспейси – “dev-backend-api-ns“, “staging-backend-api-ns” та “prod-backend-api-ns“, які ми знаємо – але будуть імена, які ми ніяк заздалегідь дізнатись не можемо.
Тому як рішення поки що бачу тільки залишити старий IRSA для бекенду, а Pod Identity використовувати тільки для тих проектів, які мають статичні неймспейси.
Pod Identity association для Monitoring project
Ну й давайте зробимо одну асоціацію, і потім вже в процесі роботи будемо дивитись як можна покращити процес.
В проекті з моніторингом в мене є 5 кастомних IAM Roles – для Grafana Loki з доступами до S3, для звичайного CloudWatch Exporter, для Yet Another CloudWatch Exporter, для нашого власного Redshift Exporter, і для X-Ray Daemon.
Створення ролей все ж, мабуть, краще винести в цей проект, “atlas-iam“. Тоді при створенні нового проекту ми спочатку в цьому проекті описуємо його роль і асоціацію в потрібних неймспейсах з потрібним ServiceAccount, а потім в самому проекті в Helm-чарті вказуємо ім’я ServiceAccount.
Щодо terraform-aws-modules/eks-pod-identity/aws – як на мене, то він більш заточений під всякі дефолтні ролі, хоча можливість створення власних там є.
Але зараз простішим буде зробити так:
створювати IAM Roles для кожного сервісу зі звичайним resource "aws_iam_role"
і з resource "aws_eks_pod_identity_association" підключати ці ролі до кластерів
Отже, створимо нову змінну, де будуть проекти та їхні неймспейси і ServiceAccounts:
Далі, у файлі eks_pod_iam_roles.tf зробимо роль – як робили вище, але без циклів, бо у нас одна роль на весь AWS-акаунт, яка буде підключатись до різних Kubernetes-кластерів:
# Trust Policy to be used by all IAM Roles
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["pods.eks.amazonaws.com"]
}
actions = [
"sts:AssumeRole",
"sts:TagSession"
]
}
}
# Create an IAM Role to be assumed by Yet Another CloudWatch Exporter
resource "aws_iam_role" "yace_exporter_access" {
name = "monitoring-yace-exporter-role"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
inline_policy {
name = "monitoring-yace-exporter-policy"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"cloudwatch:ListMetrics",
"cloudwatch:GetMetricStatistics",
"cloudwatch:GetMetricData",
"tag:GetResources",
"apigateway:GET"
]
Effect = "Allow"
Resource = ["*"]
},
]
})
}
tags = {
Name = "monitoring-yace-exporter-role"
}
}
Об’єкт data "aws_iam_policy_document" "assume_role" у нас тут буде один – і потім його використаємо в усіх IAM Roles.
Далі в файлі eks_pod_identities.tf описуємо власне aws_eks_pod_identity_association з використанням namespace та service_account зі змінної, яку описали вище, role_arn отримуємо з resource "aws_iam_role" "yace_exporter_access", а імена кластерів беремо в циклі зі змінної var.eks_clusters:
bash-4.2# aws s3 ls
An error occurred (AccessDenied) when calling the ListBuckets operation: Access Denied
Висновки
Отже, що ми маємо в результаті.
З EKS Access Entries все доволі ясно, і рішення має право на життя: можемо з одного Terraform-коду управляти юзерами для різних EKS кластерів і навіть в різних AWS-акаунтах.
Код, описаний в eks_access_entires.tf дозволяє нам досить гнучко створювати нові EKS Authentification API Access Entries для різних юзерів з різними правами, хоча я не торкався питання Kubernetes RBAC – створення окремих груп з власними RoleBindings. Але в моєму випадку це поки трохи overhead.
А от з EKS Pod Identities автоматизація “дала збій” – бо на цей час нема можливості використовувати “*” в іменах неймспейсів та/або ServiceAccounts – а тому ми маємо досить жорстко прив’язуватись до якихось постійних імен. Тому описане рішення може застосувати, коли у вас заздалегідь відомі імена об’єктів в Kubernetes – але для якихось динамічних рішень все ще доведеться використовувати стару схему з IRSA та OIDC.
Втім, сподіваюсь, цей момент пофіксять, і тоді можна буде всі наші проекти менеджити вже з одного коду.
 Хотілося б написати про щось айтішне, тим більш є зараз цікава тема, і не одна – але доведеться написати про трохи більш актуальні речі.
Хотілося б написати про щось айтішне, тим більш є зараз цікава тема, і не одна – але доведеться написати про трохи більш актуальні речі.












 А в офісі ONU живиться або від павербанки:
А в офісі ONU живиться або від павербанки:
 Освітлення
Освітлення Вони з датчиком руху, класна штука.
Вони з датчиком руху, класна штука.








 Подивились ми на наші витрати на AWS Load Balancers, і подумали, що треба трохи це діло привести в порядок.
Подивились ми на наші витрати на AWS Load Balancers, і подумали, що треба трохи це діло привести в порядок.