![]() Зараз сетаплю новий ЕКС кластер, і серед інших компонентів запускаю в ньому ExternalDNS, який використовує Kubernetes ServiceAccount для аутентифікації в AWS, щоб мати змогу вносити зміни до доменної зони в Route53.
Зараз сетаплю новий ЕКС кластер, і серед інших компонентів запускаю в ньому ExternalDNS, який використовує Kubernetes ServiceAccount для аутентифікації в AWS, щоб мати змогу вносити зміни до доменної зони в Route53.
Однак забув налаштувати Identity Provider в AWS IAM, і ExternalDNS видав помилку:
level=error msg=”records retrieval failed: failed to list hosted zones: WebIdentityErr: failed to retrieve credentials\ncaused by: InvalidIdentityToken: No OpenIDConnect provider found in your account for https://oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F\n\tstatus code: 400
Тож почав згадувати за OIDC, потім взагалі про аутентифікацію в Kubernetes, и вирішив ще раз копнути в те, як воно все працює, бо в останніх версіях EKS/Kubernetes були досить цікаві зміни.
Що таке OpenID Connect та Identity Provider
OpenID Connect (OIDC) це протокол, який дозволяє сервісам виконувати аутентифікацію іншого сервісу або користувача на основі Identity Tokens, які являють собою JSON Web Tokens (JWT).
Сам JWT підписується Identity Provider (IDP), і містить в собі інформацю про юзера або сервіс.
В нашому випадку, AWS Elastic Kubernetes Service – це Identity Provider, а AWS – це Service Provider. Тобто, EKS аутентифікує юзерів, і каже Амазону, що цьому юзеру можна довіряти виконувати якісь дії в AWS.
Тож головне, що треба усвідомлювати, коли ви налаштовуєте Identity Providers в AWS IAM, це те, що ви не налаштовуєте якийсь окремий AWS Service під назвою “Identity Providers“, а налаштовуєте AWS IAM, якому кажете – “Хей, довіряй чуваку з оцим URL”, тобто налаштовуєте Trust relations між вашим Identity Provider (EKS, GitHub, GitLab, Google тощо) та Service Provider (AWS).
Якщо провести аналогію, то це якби ви в аеропорту на паспортному контролі десь в Амстердамі прийшли зі своїм українським паспортом, і вам там повірили, що ви – то саме ви, бо прикордонна служба Нідерландів (Service Provider) довіряє уряду України (Identity Provider), який вам видав цей паспорт (JWT).
AWS EKS та IAM Role
Окей, тож як Kubernetes Pod у EKS отримує доступ до AIM-ролі?
Ми повернемось детальніше до цієї теми в кінці, у AWS IAM Roles for Kubernetes ServiceAccounts, але зараз глянемо загальну картину процесу:
- ми створюємо ServiceAccount для Kubernetes Pod, в
annotationsцього ServiceAccount вказуємо ARN IAM-ролі, яку цей Pod має використовувати для аутентифікації в AWS (авторизація, тобто перевірка які саме дії ви можете в AWS виконувати, буде виконуватись на рівні самого AWS в IAM за допомогою IAM Policy, яка підключена до вашої IAM Role) - EKS генерує JWT-токен, в якому вказано, що “подавач” цього токену дійсно є валідним EKS-юзером, і EKS це підтвержує своїм сертифікатом
- процес із поду за допомогою цього токену проходить аутентифікацію в AWS IAM і виконує AssumeRole
- і вже від імені цїєї ролі виконує необхідні дії з AWS API
Тобто, в процесі приймаються участь Kubernetes ServiceAccount, AWS AIM, та JWT-токени.
Розберемося з цим усім по черзі, і почнемо з ServiceAccounts та JWT в EKS, бо з часів написання Kubernetes: ServiceAccounts, JWT-токены, аутентификация и RBAC-авторизация процес трохи змінився.
EKS ServiceAccounts та Projected Volumes
Якщо раніше при створенні ServiceAccount створювався статичний Kubernetes Secret, який в собі мав три поля – namespace, ca.crt та власне token, то тепер це все генерується динамічно для кожного поду та ServiceAccount.
Давайте переглянемо, що ми зараз маємо в поді з ExternalDNS:
[simterm]
$ kk -n kube-system get pod external-dns-85587d4b76-2flhg -o yaml
...
env:
- name: AWS_DEFAULT_REGION
value: us-east-1
- name: AWS_STS_REGIONAL_ENDPOINTS
value: regional
- name: AWS_ROLE_ARN
value: arn:aws:iam::492***148:role/eks-dev-1-26-EksExternalDnsRoleB9A571AF-1CFSB6BBQDGSZ
- name: AWS_WEB_IDENTITY_TOKEN_FILE
value: /var/run/secrets/eks.amazonaws.com/serviceaccount/token
...
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-qdgjr
readOnly: true
- mountPath: /var/run/secrets/eks.amazonaws.com/serviceaccount
name: aws-iam-token
readOnly: true
...
serviceAccount: external-dns
serviceAccountName: external-dns
...
volumes:
- name: aws-iam-token
projected:
defaultMode: 420
sources:
- serviceAccountToken:
audience: sts.amazonaws.com
expirationSeconds: 86400
path: token
- name: kube-api-access-qdgjr
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
...
[/simterm]
Отже, в volumeMounts ми бачимо два volumes – kube-api-access-qdgjr та aws-iam-token. До aws-iam-token повернемось пізніше, а поки давайте розглянемо volumes.projected для kube-api-access-qdgjr.
ServiceAccount Tokens
Починаючи з версії 1.22, Kubernetes має два типи токені – Long Live та Time Bound.
Long Live вже вважається deprecated, і не має використовуватись, хоча його можливо зробити зо допомогою Secret – це той самий тип токенів, які використовувались для ServiceAccounts раніше:
apiVersion: v1
kind: ServiceAccount
metadata:
name: test-sa
---
apiVersion: v1
kind: Secret
metadata:
name: test-secret
annotations:
kubernetes.io/service-account.name: test-sa
type: kubernetes.io/service-account-token
Time Bound токени генеруються Kubernetes TokenRequest API, мають обмежений час життя, валідні тільки для конкретного Pod та ServiceAccount, і підключаються до поду за допомогою Projected Volumes та serviceAccountToken.
Kubernetes API JWT authentification
Глянемо в самому поді зміст каталогу /var/run/secrets/kubernetes.io/serviceaccount:
[simterm]
$ kk exec -ti pod/test-pod -- ls -l /var/run/secrets/kubernetes.io/serviceaccount total 0 lrwxrwxrwx 1 root root 13 Jul 5 09:37 ca.crt -> ..data/ca.crt lrwxrwxrwx 1 root root 16 Jul 5 09:37 namespace -> ..data/namespace lrwxrwxrwx 1 root root 12 Jul 5 09:37 token -> ..data/token
[/simterm]
Тут маємо три файли, які створені з Projected Volumes, в яких ми бачили три source, кожний з власним path:
serviceAccountToken: містить токен, отриманий від kube-apiserver за допомогою TokenRequest API, і використовується подом для аутентифікації на Kubernetes API. Має обмежений час життя, і валідний тільки для цього конкретного поду та його ServiceAccount- підключається у
path: token
- підключається у
configMap: бере змістkube-root-ca.crtConfigMap, використовується подом, щоб впевнитись, що він підключається саме до потрібного Kubernetes API- підключається у
path: ca.crt
- підключається у
downwardAPI: отримує від API інформацію проmetadata.namespace- підключається у
path: namespace
- підключається у
Давайте глянемо, що в самому токені – він теж змінився.
Отримуємо сам токен:
[simterm]
$ token=`kubectl -n kube-system exec external-dns-85587d4b76-2flhg -- cat /var/run/secrets/kubernetes.io/serviceaccount/token`
[/simterm]
І дивимось зміст за допомогою jwt-cli або на сайті https://jwt.io:
[simterm]
$ jwt decode $token
Token header
------------
{
"alg": "RS256",
"kid": "64aacc8aa986bf6161312dfdfeba00e63ed64f9d"
}
Token claims
------------
{
"aud": [
"https://kubernetes.default.svc"
],
"exp": 1720254790,
"iat": 1688718790,
"iss": "https://oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F",
"kubernetes.io": {
"namespace": "kube-system",
"pod": {
"name": "external-dns-85587d4b76-2flhg",
"uid": "d59b56f1-fa01-4a0f-8897-1933926e4d42"
},
"serviceaccount": {
"name": "external-dns",
"uid": "38c8f023-60bf-416e-b6c2-d37939ac3c06"
},
"warnafter": 1688722397
},
"nbf": 1688718790,
"sub": "system:serviceaccount:kube-system:external-dns"
}
[/simterm]
Тут:
aud(audience): для кого цей токен призначений – отримувач має ідентифікувати себе з цим ім’ям, інакше токен має бути відхиленийexp(expiration time): “термін придатності” цього токену – після його закінчення, токен має бути відхиленийiat(issued at): час створення токену, від якого буде рахуватисьexpiss(issuer): OIDC Issuer URL нашого кластеру – той самий Identity Provider URL, який потім будемо використовувати при налаштувані AWS IAMkubernetes.io: тут бачимо UID самого пода та ServiceAccount – саме тому якщо под або його ServiceAccount буде перестворено, то цей токен стане невалідним, бо зміняться UIDsub(subject): “ім’я користувача” цього токену – буде перевірятись у AWS IAM для авторизації дій з AWS API
Використовуючи це токен – ми з поду можемо аутентифікуватись на API нашого Kubernetes-кластеру.
Описуємо под з cURL:
---
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: curl
image: curlimages/curl
command: ['sleep', '36000']
restartPolicy: Never
Створюємо його:
[simterm]
$ kubectl apply -f test-pod.yaml pod/test-pod created
[/simterm]
Підключаємось, та створюємо змінні:
[simterm]
$ kubectl exec -ti test-pod -- sh
~ $ SERVICEACCOUNT=/var/run/secrets/kubernetes.io/serviceaccount
~ $ TOKEN=$(cat ${SERVICEACCOUNT}/token)
~ $ CACERT=${SERVICEACCOUNT}/ca.crt
~ $ curl --cacert ${CACERT} --header "Authorization: Bearer ${TOKEN}" -X GET https://kubernetes.default.svc/api
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "ip-172-16-110-147.ec2.internal:443"
}
]
}
[/simterm]
Тоді як без токену – підемо за російським кораблем отримаємо відповідь 403:
[simterm]
~ $ curl --cacert ${CACERT} -X GET https://kubernetes.default.svc/api
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/api\"",
"reason": "Forbidden",
"details": {},
"code": 403
}
[/simterm]
Добре – з аутентифікацією в Kubernetes API наче розібралися, давайте глянемо на AWS.
AWS IAM Roles для Kubernetes ServiceAccounts
Для роботи з AWS API, Kubernetes Pod використовує модель IRSA – IAM Role for Service Accounts.
Хоча ви все ще можете використовувати підхід з ACCESS/SECRET через змінні оточення, або підключати необхідну роль до EC2 WorkerNode як EC2 IAM Instance Role, робота через IRSA дозволяє вам видавати права на роботу з AWS для конкретного поду, а не всіх подів на цьому ЕС2-інстансі.
У випадку ж з ACCESS/SECRET для поду – ключі у вас статичні, і по-перше – можуть бути скомпрометовані (вкрадені), по-друге – вам необхідно їх десь тримати та передавати у Deployment/StatefulSet, etc під час створення вашого workload, тоді як IRSA використовує динамічні дані доступу (credentials), яки створються під час запиту поду до IAM-ролі, і вам не потрібно їх ані зберігати, ані хвилюватись через їх витік.
Assume Role з AWS CLI
Отже, Kubernetes Pod буде виконувати AssumeRole для отримання ролі, тож давайте згадаємо, як AssumeRole працює з AWS CLI – тоді будемо краще уявляти собі, як це працює в EKS з його подами.
Описуємо IAM Policy, яка дозволяє доступ до S3-бакетів:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets",
"s3:GetBucketLocation"
],
"Resource": "*"
}
]
}
Створюємо її:
[simterm]
$ aws iam create-policy --policy-name irsa-test --policy-document file://irsa-policy.json
{
"Policy": {
"PolicyName": "irsa-test",
...
"Arn": "arn:aws:iam::492***148:policy/irsa-test",
...
}
}
[/simterm]
Описуємо Trusted Policy для майбутньої IAM Role – хто зможе виконувати запит sts:AssumeRole цієї ролі до AWS API:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::492***148:root"
},
"Action": "sts:AssumeRole"
}
]
}
Тут в Principal "arn:aws:iam::492***148:root" вказуємо, що будь-який валідний юзер цього AWS-аккаунту може виконати "Action": "sts:AssumeRole".
Cтворюємо саму роль, якій підключаємо цю полісі:
[simterm]
$ aws iam create-role --role-name irsa-test-role --assume-role-policy-document file://irsa-trust.json
{
"Role": {
"Path": "/",
"RoleName": "irsa-test-role",
"RoleId": "AROAXFIUAIGSBE2Q2WORF",
"Arn": "arn:aws:iam::492***148:role/irsa-test-role",
"CreateDate": "2023-07-05T11:05:37Z",
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::492***148:root"
},
"Action": "sts:AssumeRole"
}
]
}
}
}
[/simterm]
І додаємо до ролі політику, яка дозволяє виконувати запити до S3:
[simterm]
$ aws iam attach-role-policy --role-name irsa-test-role --policy-arn arn:aws:iam::492****148:policy/irsa-test
[/simterm]
Тепер з AWS CLI перевіряємо чи зможемо ми виконати assume цієї ролі:
[simterm]
$ aws sts assume-role --role-arn arn:aws:iam::492***148:role/irsa-test-role --role-session-name TestIrsa
{
"Credentials": {
"AccessKeyId": "ASI***GU3",
"SecretAccessKey": "g5N***xhR",
"SessionToken": "Fwo***g==",
"Expiration": "2023-07-05T12:25:54Z"
},
"AssumedRoleUser": {
"AssumedRoleId": "AROAXFIUAIGSBE2Q2WORF:TestIrsa",
"Arn": "arn:aws:sts::492***148:assumed-role/irsa-test-role/TestIrsa"
}
}
[/simterm]
Працює.
Що тут відбувається?
- AWS CLI виконує запит до AWS STS
- STS перевіряє, чи може користувач (який у
~/.aws/credentialsмає ACCESS/SECRET ключі юзеру в AWS) виконувати API-запитsts:AssumeRole(а так як ми в Trust Policy цієї ролі вказалиPrincipal "arn:aws:iam::492***148:root"– то може) - якщо перевірку пройдено, то STS створює тимчасові дані доступу для цієї ролі –
AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEYтаAWS_SESSION_TOKENі повертає їх до AWS CLI
Далі, використовуючи ці дані, ми можемо виконувати дії від імені ціьєї IAM-ролі:
[simterm]
$ export AWS_ACCESS_KEY_ID=ASI***YHO $ export AWS_SECRET_ACCESS_KEY=WPN***ZiN $ export AWS_SESSION_TOKEN=Fwo***Vo=
[/simterm]
Перевіримо юзера тепер:
[simterm]
$ aws sts get-caller-identity
{
"UserId": "AROAXFIUAIGSBE2Q2WORF:TestIrsa",
"Account": "492***148",
"Arn": "arn:aws:sts::492***148:assumed-role/irsa-test-role/TestIrsa"
}
[/simterm]
І глянемо чи маємо ми доступ до бакетів:
[simterm]
$ aws s3 ls 2023-02-01 13:29:34 amplify-staging-112927-deployment 2023-02-02 17:40:56 amplify-dev-174045-deployment ...
[/simterm]
Окей, з цим розібралися.
Тепер глянемо, як це відбувається в EKS.
AssumeRole as a ServiceAccount
Спочатку налаштуємо Identity Provider в IAM, створимо ServiceAccount та IAM Role, яку будемо використовувати, перевіримо, і потім глянемо як саме воно працює.
Отримуємо OpenID Connect provider URL:
[simterm]
$ aws eks describe-cluster --name eks-dev-1-26-cluster --query "cluster.identity.oidc.issuer" --output text https://oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F
[/simterm]
Переходимо до AWS Console > IAM > Identity Providers, додаємо нового провайдера з типом OpenID Connect.
Вказуємо Provider URL, клікаємо Get thumbprint:

За цим відбитком IAM в майбутньому буде перевіряти, чи дійсно до нього прийшов той самий Issuer, якого ми вказуємо в Provider URL.
В полі Audience задаємо sts.amazonaws.com – “до кого” цей IDP зможе звертатись.
Клікаємо Add provider, переходимо до нього, та копіюємо його ARN:

Створюємо файл “політики довіри” – описуємо, хто зможе виконувати Assume ролі, яку будемо створювати для нашого тестового поду:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::492***148:oidc-provider/oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F:aud": "sts.amazonaws.com",
"oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F:sub": "system:serviceaccount:default:irsa-test-service-account"
}
}
}
]
}
Тут:
Federated: ARN Identity Provider-у, якого ми створилиAction: яку саме дію він зможе виконуватиCondition: і при яких умовах – якщоsub, тобто “юзер” буде irsa-test-service-account ServiceAccount, і він буде звертатись до sts.amazonaws.com
Створюємо IAM Role, нотуємо її ARN:
[simterm]
$ aws iam create-role --role-name irsa-test --assume-role-policy-document file://irsa-trust.json
...
"Arn": "arn:aws:iam::492***148:role/irsa-test",
...
[/simterm]
Підключимо ту саму S3 Policy, яку робили ще на початку:
[simterm]
$ aws iam attach-role-policy --role-name irsa-test --policy-arn arn:aws:iam::492***148:policy/irsa-test
[/simterm]
Описуємо ServiceAccount, в annotations якого вказуємо IAM Role ARN – тієї ролі, яку тільки що створили:
apiVersion: v1
kind: ServiceAccount
metadata:
name: irsa-test-service-account
namespace: default
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::492***148:role/irsa-test
І додаємо тестовий под з AWS CLI, якому вказуємо цей serviceAccountName:
---
apiVersion: v1
kind: Pod
metadata:
name: irsa-test-pod
spec:
containers:
- name: aws-cli
image: amazon/aws-cli:latest
command: ['sleep', '36000']
restartPolicy: Never
serviceAccountName: irsa-test-service-account
Деплоїмо:
[simterm]
$ kubectl apply -f irsa-sa.yaml serviceaccount/irsa-test-service-account created pod/irsa-test-pod created
[/simterm]
Підключаємось в под, і пробуємо переглянути S3 корзини в аккаунті:
[simterm]
sh-4.2# aws s3 ls 2023-02-01 11:29:34 amplify-staging-112927-deployment 2023-02-02 15:40:56 amplify-dev-174045-deployment ...
[/simterm]
І переконаємось, що ми це зробили дійсно використовуючи роль irsa-test:
[simterm]
sh-4.2# aws sts get-caller-identity
{
"UserId": "AROAXFIUAIGSM3R35H4WY:botocore-session-1688726924",
"Account": "492***148",
"Arn": "arn:aws:sts::492***148:assumed-role/irsa-test/botocore-session-1688726924"
}
[/simterm]
А тепер розберемося, як воно працює.
IRSA та Amazon EKS Pod Identity webhook
Глянемо на наш под, як ми це робили на самому початку з подом ExternalDNS:
[simterm]
$ kubectl get pod/irsa-test-pod -o yaml
...
- name: AWS_ROLE_ARN
value: arn:aws:iam::492***148:role/irsa-test
- name: AWS_WEB_IDENTITY_TOKEN_FILE
value: /var/run/secrets/eks.amazonaws.com/serviceaccount/token
...
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-frc4n
readOnly: true
- mountPath: /var/run/secrets/eks.amazonaws.com/serviceaccount
name: aws-iam-token
readOnly: true
...
volumes:
- name: aws-iam-token
projected:
defaultMode: 420
sources:
- serviceAccountToken:
audience: sts.amazonaws.com
expirationSeconds: 86400
path: token
- name: kube-api-access-frc4n
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
[/simterm]
Ми вже розбирали що знаходиться в /var/run/secrets/kubernetes.io/serviceaccount/token, який створюється з Projected Volume kube-api-access-frc4n – теперь глянемо на /var/run/secrets/eks.amazonaws.com/serviceaccount/token.
Для нього використовується той самий тип serviceAccountToken, якому передається audience: sts.amazonaws.com. В результаті маємо JWT-токен для аутентифікації в AWS:
[simterm]
$ token=`kubectl exec -ti pod/irsa-test-pod -- cat /var/run/secrets/eks.amazonaws.com/serviceaccount/token`
$ jwt decode $token
...
Token claims
------------
{
"aud": [
"sts.amazonaws.com"
],
"exp": 1688813222,
"iat": 1688726822,
"iss": "https://oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F",
"kubernetes.io": {
"namespace": "default",
"pod": {
"name": "irsa-test-pod",
"uid": "cc040630-1e85-4339-9699-7106c2b37a9b"
},
"serviceaccount": {
"name": "irsa-test-service-account",
"uid": "65b197d7-1609-433c-825e-b423f622978b"
}
},
"nbf": 1688726822,
"sub": "system:serviceaccount:default:irsa-test-service-account"
}
[/simterm]
Бачимо всі тіж поля:
aud: має співпадати з audience нашого Identity Provider в AWS AIM (інакше отримаємо помилку “An error occurred (InvalidIdentityToken) when calling the AssumeRoleWithWebIdentity operation: Incorrect token audience” – я с першого разу помилився, коли додавав IDP – в Audience вказав sts.amazon.com замість sts.amazonaws.com)iss: IAM буде перевіряти, від кого прийшов токен, і чи може він довіряти цьому джерелуsub: буде використовуватись у IAM Role Trusted Policy – згадайтеCondition.StringEqualsу файліirsa-trust.json
Тобто, з цим токеном ми можемо звернутись до AWS STS, і отримати temporary crdentials, за якими зможемо виконати запит на sts:AssumeRoleWithWebIdentity.
Перевіримо?
Використаємо AWS CLI та assume-role-with-web-identity:
[simterm]
sh-4.2# token=`cat /var/run/secrets/eks.amazonaws.com/serviceaccount/token`
sh-4.2# aws sts assume-role-with-web-identity --role-session-name "test-irsa" --role-arn arn:aws:iam::492***148:role/irsa-test --web-identity-token $token
{
"Credentials": {
"AccessKeyId": "ASI***PUU",
"SecretAccessKey": "Y/Z***KQW",
"SessionToken": "IQo***A==",
"Expiration": "2023-07-07T12:54:30+00:00"
},
"SubjectFromWebIdentityToken": "system:serviceaccount:default:irsa-test-service-account",
"AssumedRoleUser": {
"AssumedRoleId": "AROAXFIUAIGSM3R35H4WY:test-irsa",
"Arn": "arn:aws:sts::492***148:assumed-role/irsa-test/test-irsa"
},
"Provider": "arn:aws:iam::492***148:oidc-provider/oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F",
"Audience": "sts.amazonaws.com"
}
[/simterm]
Wow! It’s a magic!
То щож відбувається, коли ми створюємо ServiceAccount с IAM Role ARN в аннотаціях?
Чудово описано ось тут – Introducing fine-grained IAM roles for service accounts:
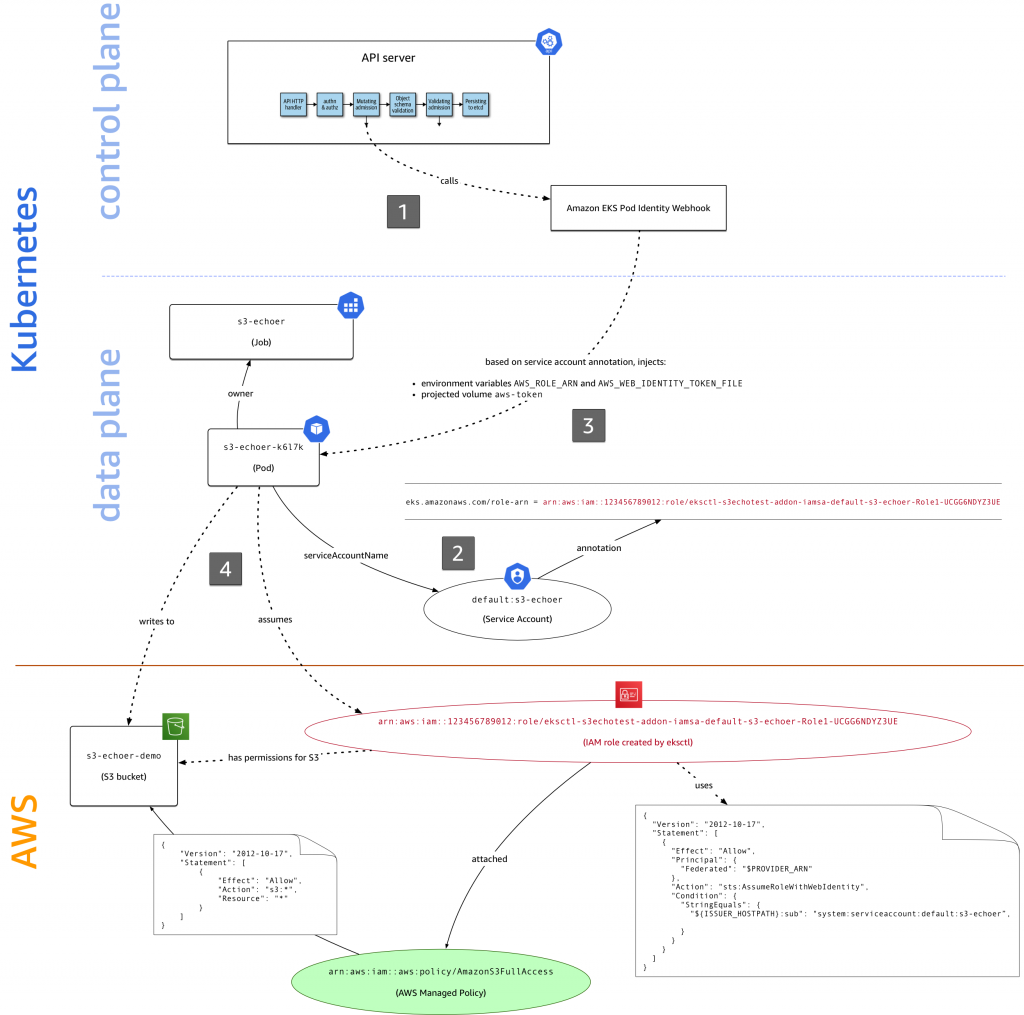 Отже:
Отже:
- при створенні пода з ServiceAccount, якому вказано IAM Role, Amazon EKS Pod Identity webhook створює змінні оточення
AWS_ROLE_ARNтаAWS_WEB_IDENTITY_TOKEN_FILE, і додаєaws-iam-tokenprojected volume, в якому генерує JWT - при роботі процесу всередині поду – цей процес (AWS CLI, CDK, SDK, whatever) використовує змінні оточення:
AWS_ROLE_ARN– щоб знати, Assume якої ролі робити- та
AWS_WEB_IDENTITY_TOKEN_FILE– що знати, звідки йому взяти токен для аутентифікації в AWS
Тобто, коли ми викликали aws s3 ls і не передавали йому ніяких параметрів – він просто взяв їх з оточення:
[simterm]
sh-4.2# env | grep AWS_ AWS_ROLE_ARN=arn:aws:iam::492***148:role/irsa-test AWS_WEB_IDENTITY_TOKEN_FILE=/var/run/secrets/eks.amazonaws.com/serviceaccount/token AWS_DEFAULT_REGION=us-east-1 AWS_REGION=us-east-1 AWS_STS_REGIONAL_ENDPOINTS=regional
[/simterm]
That’s all, folks!
Корисні посилання
- What is OpenID Connect
- RFC 6749: The OAuth 2.0 Authorization Framework
- SAML vs. OpenID (OIDC)
- What’s the magic of OIDC identity providers?
- AssumeRoleWithWebIdentity WHAT?! Solving the Github to AWS OIDC InvalidIdentityToken Failure Loop
- IAM roles for service accounts
- Projected Service Account Token
- Introducing fine-grained IAM roles for service accounts
- How to use trust policies with IAM roles
- Creating a role for web identity or OpenID Connect Federation (console)
- BIG change in K8s 1.24 about ServiceAccounts and their Secrets
- Service Account Tokens in Kubernetes v1.24
- Understanding service accounts and tokens in Kubernetes
- Configure Service Accounts for Pods
- Managing Service Accounts
![]()

















 Збирати логи у Grafana Loki з Kubernetes дуже просто – запускаємо Promtail у DaemonSet, йому вказуємо читати всі дані з
Збирати логи у Grafana Loki з Kubernetes дуже просто – запускаємо Promtail у DaemonSet, йому вказуємо читати всі дані з 









































 Окрім
Окрім 



