Вже давно просили написати пост про те, як я готувався до зими – ось, таки вмовили.
Хоча вже трошки запізно, бо половина зими пройдено, але – нехай буде.
Голове, що дуже спасає цією зимою це те, що ЖК, в якому живу, по-перше має газові плити, по-друге – опалення газовими котлами.
Однак, все ж були проблеми, которі довелося вирішувати.
В перші дні, коли почали вимикати світло, я мав пару павербанків на 10.000 mAh, і досі пам’ятаю це відчуття, коли в ноутбуку сіла батарея, провайдер інтернету вирубився, мобільний інтернет теж не працював, ще й телефон почав сідати і не було можливості навіть почитати книгу (хоча є ще паперова бібліотека – але чим світити ввечері?)
Повне відчуття ізоляції, як в печері.
Тож перше, що я зробив – це докупив пару павербанок на 20.000 для телефона. Але це було тільки початком.
Інтернет
Друге питання, яке потрібно було вирішити – це інтернет. Живу за містом, і як вимикається світло – то вежі мобільного вирубаються теж, лишається тільки одна. З телефону інтернет через неї не тягнуло зовсім, тож докупив собі комплект зовнішньої антени з 3/4G роутером. Див детальнішне тут – Networking: коли немає світла – модем 4G ZTE + зовнішня антена:
Антена стоїть за вікном, в квартирі мав два модеми з двома операторами – Водафон та Лайф: то один, то другий працювали більш-менш, і свої 1-2 мб/с я мав.
Обидва модеми були підключені до павербанок, тож працювали постійно: як тільки виключалось світло, і провайдер “падав” – ноутбук переключався на один з модемів.
Ще пізніше в ЖК нарешті дотягнули оптику, і тепер маю GPON з гігабітним підключенням:
Так як це GPON (Gigabit Passive Optical Network) – то ми не дуже залежимо від електрохарчування (с), і інтернет працює стабільно навіть декілька діб без світла поспіль.
Електрохарчування (с)
Заряд ноубтука
Ще до того, як я затарився купою всяких акумуляторів (зараз до них дойдемо) я максимально оптимізував роботу свого ноутбука – визначив, які саме процеси/сервіси найбільше витрачають заряд батареї, та почав іх відключати, див. Linux: збереження заряду батареї ноутбуку.
Щоб спростити процесс – накидав скрипта:
#!/usr/bin/bash
#sudo ifconfig enp2s0f0 down
sudo nmcli radio wifi off
sudo bash -c 'echo -n 60 > /sys/class/backlight/amdgpu_bl0/brightness'
#xrandr --output eDP-1 --auto --mode 1280x720 --output HDMI-1 --auto --left-of eDP-1 --output DP-1 --off
##xrandr --output eDP-1 --auto --mode 1280x720 --primary --output HDMI-1 --off --output DP-1 --off
#systemctl --user stop pulseaudio.socket
#systemctl --user stop pulseaudio.service
sudo systemctl stop bluetooth
sudo ip link set docker0 down
sudo systemctl stop docker.service
sudo systemctl stop docker.socket
killall polybar
killall ktorrent
killall slack
killall thunderbird
Далі в rc.xml (в мене Arch Linux та Openbox) додав дві комбінації для клавіатури – одна запускає скрипт setPowerDown.sh, наведений вище, друга – setPowerUp.sh, в якому робиться все теж саме, тільки навпаки – включає сервіси:
По-перше – замовив зарядну станцію. Мене душила жаба віддавати купу грошей, та ще й чекати на доставку, тож я замовив не EcoFlow, а Kseon-168 – 168.000 mAh (14.000 грн, для військових дешевше), плюс інвертор на 500 ват. 4 виходи USB (без QuickCharge, нажаль), та з двома автомобільними виходами. І вже для автомобільного конектора – докупив Baseus Particular Digital Display QC+PPS Dual Quick Charger 65W Dark, тож спокійно можу заряджати і мобільні, і ноутбук:
Єдиний, як на мене, недолік Kseon – довга зарядка, до 18 годин для повного заряду. Але пізніше купив ще один, тож маю запас.
Ще треба було вирішити питання з опаленням: газовий котел теж потребує електроенергії для свого насоса, яким він жене воду по системі.
Спеціально для нього замовив звичайні автомобільні акумулятори та інвертор:
Інвертор до 600 ват, тож котел тягне без проблем, можна підключити ще й холодильник. Обійшлося все це приблизно в 15.000 грн – не скажу, де бралося, бо цим займався знайомий прораб.
Два кумулятори по 60 ампер-годин вистачає на 5-6 годин роботи котла, але квартира та будинок нові, і тепло тримають добре.
Ще пізніше купив аналогічний набор, але вже з гелевими AGM на 72 а/г (близько 10.000 грн) та інвертором CyberPower CPS1000E (обійшовся тоді у 23.000 грн – зато привезли все на наступний день – ніяких тобі “місяць чекати”, та ще й мати справу з поштою):
Цей акум та інвертор переважно живлять настільну лампу, колонки, ноутбук, зовнішній монітор та роутер.
Тож зараз в мене запаси по енергії:
3х павербанка на 10.000 mAh
1х павербанк на 20.000 mAh
2х павербанка Baseus на 30.000 mAh, 65 ват
1х павербанк на 60.000 mAh, 65 ват
2х автоакуми на 60.000 mAh + інвертор 600 ват
1х автоакум на 72.000 mAh + інвертор 700 ват
2х зарядні станції Kseon по 168.000 mAh + інвертор 500 ват
Зараз, думаю, можу спокійно (якщо економно) прожити без світла до тижня.
Безпека
Акумлятори стоять на балконі, де температура мінімум +7. До того ж докупив декілька Вологовбирач Pouce, бо трохи переймався високою вологістю повітря та кондесатом.
Один в коридорі, біля вхідних дверей, другий в шкафчику біля балкона.
Брав два, бо ніколи ними не користувався, і якщо з першого разу щось не вийде – то буде друга спроба.
Продукти харчування
Ну, тут все просто: затарився консервами від Вербена, брав на Prom.ua (хоча взагалі цю площадку дуже не люблю) – коробок 20 різноманітних каш з м’ясом, плюс “мівіни”, паштети, галети і все таке інше із супермаркету.
Знайомі купляли Консерви Tushe, прям ящиками – теж рекомендують.
Крім того, купив 1.5 кг сала – лежить в морозильнику.
Ще гарна їдея мати запас шоколаду.
Вода
В ЖК свої насоси і ми не залежимо від міського водопостачання, але тут проблема, бо насоси – сюрпрайз! – працють від електрики.
Тому маю запас 2х20 літрів технічної води, плюс 2х20 питної бутильованної:
Пізніше ЖК купив генератор, мешканці щомісяця скидаються по 200 грн на паливо, і тепер маємо воду шонайменш двічі на добу.
Також, так як вода є не завжди, купив собі ось такий рукомийник:
Ще купив звичайний чайник для плити Ofenbach Happy Kettle 2л, бо гріти воду в кастрюльці швидко набридло.
Так наче і все.
В цілому – зараз проблеми не відчуваються зовсім, хоча спочатку було трохи… Неспокійно, скажімо так, да. Але все вийшло чудово 🙂
Тепер час розібратися з тим, що взагалі ми можемо робити в Loki використовуючи її LogQL.
Підготовка
Далі для прикладів будемо використовувати два поди – один з nginxdemo/hello для звичайних логів nginx, а інший thorstenhans/fake-logger, який буде писати логи в JSON.
Для Nginx додамо Service, что б мати можливість слати запити з curl:
$ watch -n 1 curl -X POST localhost:8080 2&>1 /dev/null
[/simterm]
Поїхали.
Grafana Explore: Loki – інтерфейс
Декілька слів про сам інтерфейс Grafana Explore > Loki.
Ви можете використовувати декілька запитів одночасно:
Також, є можливість розділити інтефейс на дві частини, і в кожній виконувати окремі запити:
Як і в звичайних дашбордах Grafana, є можливість вибрати період, за який ви хочете отримати дані, та задати інтервал для автооновлювання:
Або можете включити Live-режим – тоді дані будуть з’являтися як тільки вони потраплять до Loki:
Для створення запитів є два режими – Builder та Code.
В режимі Builder Loki видає список доступних тегів та фільтрів:
В режимі Code вони будуть підставлятися автоматично по мірі набору:
Функція Explain буде роз’яснювати що саме ваш запит робить:
А Inspector відобразить деталі про ваш запит – скільки часу і ресурсів було використано для формування відповіді – корисно для оптимізації запитів:
Крім того, завжди можна відкрити Loki Cheat Sheet, натиснувши (?) з правої сторони від поля для запиту:
LogQL: overview
В цілому, робота з Loki та її LogQL майже аналогічна роботі з Prometheus та його PromQL – майже всі тіж самі функції та загальний підхід, це навіть відображено в опису Loki: “Like Prometheus, but for logs”.
Отже, основна вибірка базується на проіндексованих лейблах (або тегах, кому як більше до вподоби), за допомогою яких ми робимо основний пошук в логах – вибираємо стрім.
Типи запитів в Loki залежать від фінального результату:
Log queries: формують строки з лог-файлів
Metric queries: включають в себе Log queries, але в результаті формують числові значення, які можна використовувати для формування графіків в Grafana або для алертів в Ruler
В цілому, будь-який запит складається із трьох основних частин:
{app="nginxdemo"} – це Log Stream Selector, в якому ми вибираємо конкретний стрім из Loki, |= – початок Log Pipeline, який включає в себе Log Filter Expression – "172.17.0.1".
Окрім Log filter, пайплайн може включати в себе Log або Tag formatting expression, який міняє отримані в пайплайн дані.
Обов’язковим є Log Stream Selector, тоді як Log Pipeline з його expressions являється опціональним, і використовуюється для уточненя або форматування результатів.
Log queries
Log Stream Selectors
Для селекторів викристовуються лейбли, які задаються агентом, який збирає логи – promtail, fluentd або іншими.
Log Stream Selector визначає скільки індексів та блоків данних будуть завантажені для повернення результату, тобто напряму впливає на швидкість роботи і ресурси CPU/RAM, задіяні для формування відповіді.
В прикладі вище в селекторі {app="nginxdemo"} ми використовуємо оператор “=“, який може бути:
= : дорівнює
!= : не дорівнює
=~ : regex
!~ : негативний regex
Отже, за запитом {app="nginxdemo"} ми отримаємо логи всіх подів, у яких є тег app зі значенням nginxdemo:
Можемо комбінувати декілька селекторів, наприклад отримати всі логи з logging=test, але без app=nginxdemo:
{logging="test", app!="nginxdemo"}
Або використати regex:
{app=~"nginx.+"}
Або просто вибрати взагалі всі логи (стріми), в яких є тег app:
Log Pipeline
Данні, отримані зі стриму можна передати в пайплайн для подальшого фільтрування або форматування. При цьому результат роботи одного пайплайну можна передати в наступний, і так далі.
Pipeline може включати в себе:
Log line filtering expressions – для фільтрування попередніх результатів
Parser expressions – для отримання тегів з логів, які можна передати в Tag filtering
Tag filtering expressions – для фільтрування даних по тегам
Log line formatting expressions – використовується для редагування отриманних результатів
Tag formatting expressions – редагування тегів/лейбл
Log Line filtering
Фільтри використовуються для… фільтрування)
Тобто, коли ми отримали дані із стриму, і хочемо з нього вибрати окремі строки – то використовуємо log filter.
Фільтр складається з оператора та строкового запиту, за яким робиться вибірка данних.
Операторами можуть буди:
|=: строка містить строковий запит
! =: строка НЕ містить строковий запит
|~: строка дорівнює регулярному виразу
! ~: строка НЕ дорівнює регулярному виразу
При використанні regex майте на увазі, что використовується синтаксис Golang RE2, і за замочуванням він є case-sensitive. Щоб переключити його на незалежний від регистру режим – додаємо (i?).
Окрім того, Log Line filtering краще використовувати на початку запиту, бо вони працють швидко, і позбавлять наступні пайплайни він зайвої роботи.
Прикладом log filter може бути вибірка за строкою:
{job=~".+"} |= "promtail"
Або декілька виразів, використовуючи регулярку:
Parser expressions
Парсери… парсять) (гвинтокрили гвинтять) вхідні дані, та отримують з них лейбли, які потім можна використати в подальших фільтрах або для формування Metric queries.
Наразі, LogQL підтримує json, logfmt, pattern, regexp та unpack для роботи з тегами.
json
Наприклад, json формує всі json-ключі в лейбли, тобто запит {app="fake-logger"} | json замість:
Сформує новий набір тегів:
Отримані через json теги можна далі використати для додаткових фільтрів, наприклад – вибрати тільки строки з level=debug:
logfmt
Для формування тегів з логів не в форматі JSON можно використати logfmt, який всі знайдені поля перетворить на лейбли.
Наприклад, job="monitoring/loki-read" має поля ключ=значення:
Як видно з назви, дозволяє створювати нові фільтри з тегів які вже є в запису, або які були створені за допомогою попереднього парсеру, наприклад logfmt.
За допомогою label_format можемо перейменувати, змінити чи додати нові лейбли.
Для цього, аргументом передаємо ім’я лейбли з оператором =, за яким йде потрібне значення.
Наприклад, маємо лейблу app:
Яку хочемо перейменувати в application – використовуємо label_format application=app:
Або можемо використати значення існуючого тегу для створення нового, для цього використовуємо шаблонізатор у вигляді {{.field_name}}, де можемо комбінувати декілька полів.
Тобто, якщо хочемо створити тег error_message в якому будуть значення полів level та msg – формуємо такий запит:
Задаємо в nodeSelector ім’я ноди, щоб було простіше шукати в Локі.
При старті цього поду Kubernetes його вбиватиме через перевищення лімітів, а journald на WorkerNode записуватиме подію в системний журнал, який збирається promtail:
[simterm]
$ kk -n monitoring get cm logs-promtail -o yaml
...
- job_name: journal
journal:
labels:
job: systemd-journal
max_age: 12h
path: /var/log/journal
relabel_configs:
- source_labels:
- __journal__systemd_unit
target_label: unit
- source_labels:
- __journal__hostname
target_label: hostname
[/simterm]
Запускаємо наш под:
[simterm]
$ kk apply -f test-oom.yaml
pod/oom-test created
[/simterm]
Перевіряємо:
[simterm]
$ kk describe pod oom-test
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 91s default-scheduler Successfully assigned default/oom-test to ip-10-0-0-27.us-west-2.compute.internal
Normal SandboxChanged 79s (x12 over 90s) kubelet Pod sandbox changed, it will be killed and re-created.
Warning FailedCreatePodSandBox 78s (x13 over 90s) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed to start sandbox container for pod "oom-test": Error response from daemon: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: container init was OOM-killed (memory limit too low?): unknown
[/simterm]
І перевіряємо логі Loki:
Окей, тепер у нас є oom-killed под для тестів – давайте формувати запит для майбутнього алерту.
Формування запиту в Loki
В логах ми дивилися по запиту {hostname="eks-node-dev_data_services-i-081719890438d467f"} |~ ".*OOM-killed.*" – використовуємо його ж для тестового алерту.
Спочатку перевіримо що нам намалює сама Локі – використовуємо rate()та sum(), див.Log range aggregations:
sum(rate({hostname="eks-node-dev_data_services-i-081719890438d467f"} |~ ".*OOM-killed.*" [5m])) by (hostname)
Гуд!
З цим вже можна працювати – створювати тестовий алерт.
В subPath вказуємо key з ConfigMap, щоб підключити саме як файл.
Налаштування Ruler alerting
Знаходимо Alertmanager URL:
[simterm]
$ kk -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
prometheus-kube-prometheus-alertmanager ClusterIP 172.20.240.159 <none> 9093/TCP 110d
...
Перевіряємо Алерти в Алертменеджері – http://localhost:9093:
Loki та додаткові labels
В алертах хочеться виводити трохи більше інформації, ніж просто повідомлення “Test Loki OOM Killer Alert”, наприклад – відобразити ім’я пода, який був вбитий.
Тут я для тестів створював нові лейбли, які підключалися до логів – sourceі level.
Інший варіант із Promtail – використовуючи static_labels.
Але тут є проблема: оскільки Loki на кожний набір лейбл створює окремий лог-стрім, для якого створюються окремі індекси та блоки даних, то в результаті отримаємо по-перше проблеми з продуктивністю, по-друге – з вартістю, т.к. на кожен індекс і блок даних будуть виконуватися запити читання-запису в shared store, у нашому випадку це AWS S3, де за кожен запит доводиться платити гроші.
Натомість, ми можемо створювати нові лейбли прямо із запиту за допомогою самої Loki.
Візьмемо запис із лога, в якому йдеться про спрацювання OOM Killer:
E1213 16:52:25.879626 3382 pod_workers.go:951] “Error syncing pod, skipping” err=”failed to \”CreatePodSandbox\” for \”oom-test_default(f02523a9-43a7-4370-85dd-1da7554496e6)\” with CreatePodSandboxError: \”Failed to create sandbox for pod \\\”oom-test_default(f02523a9-43a7-4370-85dd-1da7554496e6)\\\”: rpc error: code = Unknown desc = failed to start sandbox container for pod \\\”oom-test\\\”: Error response from daemon: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: container init was OOM-killed (memory limit too low?): unknown\”” pod=”default/oom-test” podUID=f02523a9-43a7-4370-85dd-1da7554496e6
Тут ми маємо поле pod з ім’ям пода, який був вбитий – pod="default/oom-test".
Останній раз працював з Loki коли вона була ще в Beta, і виглядала вона тоді набагато простіше, ніж зараз.
У новому проекті системи логування немає взагалі, а так як у нас усі люблять Grafana-стек – то вирішили і для логів підняти Loki.
Правда мені думалося, що все буде набагато простіше. Виявилося – ні. Багато змінилося, і довелося знайомитися з нею по суті з нуля.
Що залишилося, як і раніше, – це така собі документація. Якщо опис архітектури та компонентів ще більш-менш нормально описаний, то коли справа доходить до налаштування – то натикаєшся на купу проблем, особливо те, що стосується сторейджа та зберігання в AWS S3 (хоча поки писав цей пост викотили реліз 2.7, і документацію теж оновили – можливо, тепер вона краща). Довелося збирати по шматочках, але в результаті все-таки завелося.
Розглянемо загальну архітектуру та компоненти, потім встановимо в AWS Kubernetes із Helm-чарта.
Архітектура Grafana Loki
Loki створена за мікросервісною архітектурою, при цьому всі мікросервіси зібрані в один бінарник.
Для запуску компонентів використовується опція --target, в якій можна визначити яку частину Loki запустити.
Вхідні дані діляться на стріми – це потік даних, логів, що мають загальний tenant_id (“відправник”), і загальний набір тегів/labels. Докладніше про стріми поговоримо в Storage.
Компоненти Loki
Робота системи ділиться на два основні потоки: Read path– читання (обробка запитів на вибірку даних) та Write path – запис цих даних в сторейдж.
Загальна схема всіх компонентів:
Тут:
distributor (write path): займається обробкою вхідних даних від клієнтів – одержує від них дані, валідує їх, ділить дані на блоки, і відправляє в ingester. Бажано мати LoadBalancer перед дистриб’юторами, щоб вхідні стріми розподілялися по інстансах дистриб’юторів. Є stateless компонентом – не зберігає в собі жодних даних. Також відповідає за рейт-ліміти та препроцесинг тегів.
ingester (write, read path): відповідає за запис даних у довгострокове сховище та за передачу даних для обробки запитів на їх читання клієнтами. Для запобігання втратам даних у разі рестарту інжестера, їх зазвичай запускають у вигляді декількох інстансів (див. replication_factor)
querier (read path): обробляє LogQL запити, завантажуючи для відповіді дані з інжестерів та/або довгострокового сховища – спочатку запитує інжестер, якщо в пам’яті інжестера даних немає – то querier йде в сховище даних
query frontend (read path): опціональний сервіс, що надає доступ до querier API для прискорення операцій читання. При його використанні він зберігає запити, що надходять, а querier звертається до нього, щоб взяти з черги запит на обробку
compactor: зменшення розміру індексів та управління часом зберіганням логів у сховищі даних (retention)
Data flow
Коротко про сам процес обробки даних – запити читання (read), і запис (write).
Loki отримує дані з promtail (або інших агентів, наприклад fluentd)
створює блоки даних (chunks), індекс, завантажує їх у довгострокове сховище
користувач використовує LogQL для вибірки логів у Grafana
ruler перевіряє данні, і при необхідності відправляє алерт у Prometheus Alertmanager
Read Path
При отриманні запиту на вибірку даних:
querier отримує HTTP запит
передає запит до ingesters для пошуку даних в пам’яті
якщо ingesters знаходитт дані у себе – то повертає їх querier
якщо в ingesters даних нема – querier йде в сховище даних, і отримує їх звідти
querier повертає відповідь через теж HTTP-з’єднання
Write Path
При отриманні нових даних:
distributor отримує HTTP/1 запрос на додавання даних в конкретний стрім
distributor передає кожний стрім в ingester
ingester створює новий chunk (“блок даних”, див. Loki Storage) або доповнює існуючий
distributor відповідає ОК на HTTP/1 запит
Режими запуску
Запускати Loki можна в трьох режимах, кожен з яких визначає, як будуть запущені компоненти – у вигляді одного або декількох подів Kubernetes.
Monolithic mode
Дефолтний тип при використанні локальної filesystem для зберігання даних.
Підходить для швидкого запуску та невеликих об’ємів даних, до 100GB на день
Балансування запитів виконується по round robin.
Паралелізація запитів обмежена кількістю інстансів та налаштуванням кожної інстансу.
Основне обмеження – не можна використовувати object store, такі як AWS S3.
Simple scalable deployment mode
Дефолтний тип під час використання object store.
Якщо у вас логів більше кількох сотень гігабайт, але менше кількох терабайт на день, або ви хочете ізолювати читання та запис, то можна задеплоїти Loki в режимі simple scalable deployment:
У такому режимі Loki запускається з двома таргетами – read & write.
Потребує наявності лоад-балансера, який буде роутити запити до інстансів з компонентами Loki.
Microservices mode
І для найскладніших випадків, коли у вас логи йдуть терабайтами на день, має сенс деплоїти кожен сервіс окремо:
ingester
distributor
query-frontend
query-scheduler
querier
index-gateway
ruler
compactor
Дозволяє моніторити та скейлити кожен компонент незалежно.
Loki для зберігання логів використовує два типи даних – chunks та індекси. Не придумав корректного перекладу для chunk, тому нехай буде “блок даних”.
Loki отримує дані від кількох стримів, де кожен стрім – це tenant_id та набір тегів. При отриманні нових записів від стриму вони упаковуються в блоки і відправляються в довгострокове сховище, в ролі якого можуть бути AWS S3, локальна файлова система, або бази даних типу AWS DynamoDB чи Apache Cassandra.
В індексах зберігається інформація про набір тегів кожного стриму і є посилання на пов’язані з цим стримом блоки даних.
Раніше Loki використовувала два окремі сховища – одне під індекси (наприклад, таблиці DynamoDB), і друге – безпосередньо під самі дані (AWS S3).
Десь з версії 2.0 у Loki з’явилася можливість зберігати індекси у вигляді BotlDB файлів та використовувати Single Store – єдине сховище і для блоків даних, і для індексів. Див. Single Store Loki (boltdb-shipper index type).
Ми будемо використовувати boltdb-shipper – він буде формувати індекси локально, а потім пушити їх у shared object store. Там же будуть зберігатися і самі chunks.
Важливий момент, який необхідно враховувати під час роботи з тегами в Loki це те, як формуються індекси та блоки даних: кожен окремий набір тегів формує окремий стрім, а для кожного окремого стріму формуються свої індекси та блоки даних.
Тобто, якщо ви динамічно створюєте теги/лейбли, наприклад client_ip – то у вас буде формуватися окремий набір файлів на кожен клієнтський IP, що призведе до того, що на кожен такий файл будуть виконуватися окремі запити GET/POST/DELETE, що може привести по-перше до зростання вартості сховища (як у випадку з AWS S3, де оплачується кожен виклик), так і до проблем з швидкістю обробки запитів.
Окрім документації у Loki ще й із чартами трохи складнощів, оскільки переносили між репозиторіями, об’єднували, і тепер деякі стали deprecated (хоча посилання на них у документації зустрічаються).
Нижче – не про установку, а просто деякі особливості чартів Loki, з якими довелося повозитися.
Ще один момент, який трохи поламав мозок: окей, ми бачили, що Loki можна запустити з різними Deployment modes – але як це визначити у чарті? Якогось values типу -targetтам немає.
Нижче – трохи копання в чарті, можна пропустити, якщо вам підходить дефолтна установка.
Отже, якщо встановити з дефолтними values, то отримуємо наступні компоненти:
$ kk get pod
NAME READY STATUS RESTARTS AGE
loki-canary-7vrj2 0/1 ContainerCreating 0 12s
loki-gateway-5868b68c68-lwtfj 0/1 ContainerCreating 0 12s
loki-grafana-agent-operator-684b478b77-zmw5t 1/1 Running 0 12s
loki-logs-kwxcx 0/2 ContainerCreating 0 3s
loki-read-0 0/1 ContainerCreating 0 12s
loki-read-1 0/1 Pending 0 12s
loki-read-2 0/1 Pending 0 12s
loki-write-0 0/1 ContainerCreating 0 12s
loki-write-1 0/1 Pending 0 12s
loki-write-2 0/1 Pending 0 12s
[/simterm]
Тобто, по дефолту воно встановлюється в simple-scalable, при цьому в документації самих чартів про це нічого не сказано, як ні слова про те, як задати деплоймент-режим взагалі.
А якщо я хочу Single Binary?
Зносимо:
[simterm]
$ helm uninstall loki
release "loki" uninstalled
[/simterm]
Спробуємо повірити документації, і створюємо свої values:
Тобто, тупо перевизначивши сторейдж – ми змінюємо режим деплойменту?!?
Ах#*$ть – дайте два!
Як воно працює?
Відкриваємо файл templates/_helpers.tpl, в якому є два шаблони – loki.deployment.isScalable і loki.deployment.isSingleBinary, в яких одна і та ж умова, тільки з різними значеннями:
Якщо true – то це isScalable, а якщо false – то isSingleBinary.
Окей, а що за isUsingObjectStorage?
Знаходимо його в тому же хелпері:
...
{{/* Determine if deployment is using object storage */}}
{{- define "loki.isUsingObjectStorage" -}}
{{- or (eq .Values.loki.storage.type "gcs") (eq .Values.loki.storage.type "s3") (eq .Values.loki.storage.type "azure") -}}
{{- end -}}
...
Тобто, якщо ми використовуємо .Values.loki.storage.type із значенням gcs, s3 або azure – то loki.isUsingObjectStorage прийме значення true, і Loki буде встановлено в режимі Simple Scale.
Зовсім не очевидно і не описано в документації до чарту.
Запуск Grafana Loki
А тепер, нарешті, перейдемо до запуску і налаштування Loki.
Для зберігання даних будемо використовувати AWS S3, для роботи з індексами – bottledb-shipper, для налаштування терміну зберігання логів – compactor.
Аутентифікацію Loki реалізуємо через підключення ServiceAccount із AWS IAM Role, але покажу приклад і зі звичайними ACCESS/SECRET keys.
Створення AWS S3 корзини
Почнемо зі створення корзини. Можна через AWS CLI та create-bucket, або через Terraform:
Для корзини буде потрібна політика, яка дозволяє до неї доступ, і роль, яку потім підключимо до Kubernetes Pod.
Повертаючись до проблем документації Loki – на сторінці Grafana Loki Storage є приклад політики для AWS S3, яка… не проходить валідацію в AWS IAM :faceplam:
Взагалі часто виникали асоціації з Miscrosoft Azure – там документації теж вірити не можна від слова зовсім, і все треба перевіряти і збирати по шматочках.
Переходимо до конфігу Loki – тут теж вистачило болю та страждань із документацією та чартом.
Запуск Grafana Loki в Kubernetes
Ну і тепер, коли мені стало ясно і з чартами, і з тим, як же через Helm-чарт Loki задати Deployment Mode, і взагалі який чарт використовувати – спробуємо її запустити.
Готуємо мінімальний конфіг, в якому для початку відключимо весь її внутрішній моніторинг щоб зменшити кількість подів – буде простіше розбиратися з тим, як воно працює, і для початку використовуємо сховище filesystem, щоб зберігати дані та індекси локально в подах:
$ kk -n test-loki-0 get pod
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 118s
[/simterm]
Окей – є один под, нічого зайвого.
Чарт створює StatefulSet, в якому описується створення цього поду і через який підключаються різні volumes:
[simterm]
$ kk -n test-loki-0 get sts
NAME READY AGE
loki 1/1 3m
[/simterm]
І ConfigMap, в якій зберігається конфіг, доповнений нашим loki-minimal-values.yaml:
[simterm]
$ kk -n test-loki-0 get cm loki -o yaml
apiVersion: v1
data:
config.yaml: |
auth_enabled: false
common:
path_prefix: /var/loki
replication_factor: 1
storage:
filesystem:
chunks_directory: /var/loki/chunks
rules_directory: /var/loki/rules
...
[/simterm]
Grafana Loki S3 config
Дуже багато віддав би, щоб десь знайти повний конфіг для Grafana Loki з AWS S3 як у прикладі нижче, та ще й з авторизацією через ServiceAccount і AWS IAM – витратив багато часу, щоб змусити все це працювати.
Власне, сам конфіг, потім трохи про опції та підводні камені, з якими зіткнувся:
auth_enabled: false – відключаємо авторизацію в самій Loki (в результаті отримаємо tenant_idfake в корзині – це ок, нормально, хоча могли б придумати щось красивіше ніж “фейк”)
storage.bucketNames.chunks – потрібно вказати ім’я корзини для блоків, інакше намагатиметься використовувати локальне сховище; у документації не вказано;
schema_config.configs.store:
boltdb-shipper – вказуємо на використання boltdb-shipper для роботи з індексами, оскільки він вміє в Single Store, тобто і блоки даних і їх індекси будуть в одній корзині
object_store: s3 – вказуємо тип сховища, яке налаштовується в storage_config.aws.s3 (але тут вказуємо саме як schema_config.configs.store.s3, а не schema_config.configs.store.aws.s3)
storage_config – найбільший біль:
aws.s3: вказуємо саме у вигляді s3://<S3_BUCKET_REGION>/<S3_BUCKET_NAME>, інакше при підключенні ServiceAccount Loki починає намагатися ходити для авторизації на https://sts.dummy.amazonaws.com – я так і не знайшов чому, але при використанні ServiceAccount потрібен саме такий формат
boltdb_shipper – вказуємо йому локальний шлях, де він створює індекси – active_index_directory, та shared_store – куди потім їх відправляти; візьме конфіг із тієї ж storage_config.aws.s3
rulerConfig.storage.type: local – для ruler поки вкажемо локальний каталог, з алертами розберемося в інший раз; якщо не вказати – буде постійно писати в лог помилку, що не може отримати доступ до своєї корзини, яка десь прописана у дефолтах, не пам’ятаю вже де саме
write.replicas: 2 – мінімальна кількість подів write, щоб Promatil міг писати дані
$ aws --profile development s3 ls test-loki-0
2022-12-25 11:53:13 251 loki_cluster_seed.json
[/simterm]
І ще за кілька хвилин повинні повитися каталоги fake та index:
[simterm]
$ aws --profile development s3 ls test-loki-0
PRE fake/
PRE index/
2022-12-25 11:53:13 251 loki_cluster_seed.json
[/simterm]
У fake – chunks, в index – індекси.
Окей – начебто завелося.
Дивно, насправді, що цього разу все з першої спроби завелося… Поки сетапив Loki на проекті, де працюю – реально вже подумував взяти ELK та не гаяти час.
Тепер після додавання promatil, який писатиме дані – Loki Write через ingester писатиме блоки даних, а bottledb-shipper почне створювати індекси, і пушити їх у корзину.
Запуск Promtail
Знаходимо Service для Loki Gateway:
[simterm]
$ kk -n test-loki-0 get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki-gateway ClusterIP 10.109.225.168 <none> 80/TCP 22m
...
Цього разу трохи детальніше про його сетап і можливості.
Отже, blackbox-exporter – це експортер, який вміє моніторити різноманітні ендпоінти – це можуть бути або якісь URL-и в інтернеті, ваші LoadBalancer-и в Амазоні, або Services в Кубернетесі, такі як MySQL або PostgreSQL бази данних.
Вміє виводити статистику по швидкості відповіді HTTP, коди відповідей, інформацію по SSL-сертіфікатах тощо.
$ kk -n monitoring get pod
NAME READY STATUS RESTARTS AGE
prometheus-blackbox-prometheus-blackbox-exporter-6865d9b44h546j 1/1 Running 0 27s
...
[/simterm]
Blackbox тримає свій конфіг в ConfigMap-і, яка підключається до поду і передає дефолтні параметри. Див. тут>>>.
[simterm]
$ kk -n monitoring get cm prometheus-blackbox-prometheus-blackbox-exporter -o yaml
apiVersion: v1
data:
blackbox.yaml: |
modules:
http_2xx:
http:
follow_redirects: true
preferred_ip_protocol: ip4
valid_http_versions:
- HTTP/1.1
- HTTP/2.0
prober: http
timeout: 5s
[/simterm]
Власне, тут ми і бачимо модулі, точніше поки що один, який використвує prober http, який виконує HTTP-запроси до targets, які ще треба додати.
Blackbox та ServiceMonitor
Для того, щоб додати ендпоінти, котрі ми хочемо моніторити, можна використовувати ServiceMonitor, див. конфіг тут>>>.
Чомусь ніде в нагуглених гайдах цей момент толком не описаний, хоча він дуже зручний: в конфіг Блекбоксу додаємо список таргетів, а Блекбокс створює ServiceMonitor для кожного з них, і Prometheus починає їх моніторити.
Створюємо файл blackbox-exporter-values.yaml, в якому додаємо поки що один ендпоінт – просто перевірити, чи воно взагалі працює:
Якщо не вказано інше, то Блекбокс використвує дефолтні значення із values.yaml чарту, в данному випадку це буде модуль http_2xx, який виконує GET запрос, та перевіряє код відповіді: якщо отримано 200 – то перевірка пройдена, якщо інший – то фейл.
$ kk apply -f testpod-with-svc.yaml
pod/nginx created
service/nginx-service created
[/simterm]
Перевіряємо:
[simterm]
$ kk -n test-ns get all
NAME READY STATUS RESTARTS AGE
pod/nginx 1/1 Running 0 23s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/nginx-service ClusterIP 10.106.58.247 <none> 80/TCP 23s
$ kk -n monitoring get servicemonitor
NAME AGE
prometheus-blackbox-prometheus-blackbox-exporter-google.com 12m
prometheus-blackbox-prometheus-blackbox-exporter-nginx-test 5s
[/simterm]
І за хвилину – можемо перевіряти probe_success:
Взагалі, не обов’язково вказувати повний URL у вигляді nginx-service.test-ns.svc.cluster.local – достатньо буде servicename.namespace, тобто nginx-service.test-ns, але повний URL як на мене виглядає більш наочно в лейблах та алертах.
Модулі Blackbox Exporter
Все виглядає чудово, поки ми опитуємо звичайний HTTP-ендпоінт, який завжди віддає код 200.
Що як треба перевірити інші коди?
Створимо власний модуль, використвуючи probes Блекбоксу:
Тут в modules задаємо ім’я нового модуля – http_4xx, який пробер він має викорисовувати – http, і параметри для цього пробера – яким саме запитом перевіряємо, і які коди відповіді будемо вважати правильними.
Далі, в Таргетах для nginx-test-404 явно вказуємо використання модулю http_4xx.
Тестування модулів
Окремо подивимось як саме можемо перевірити – чи буде модуль працювати так, як ми розраховуємо.
Все просто – запускаємо тестовий под, і curl-ом з опцією -I дивимось на відповідь ендпоінта.
Якшо перевіряємо TCP-коннект – то telnet.
Отже, створюємо под з Убунтою, підключаємось до нього – запускаємо всередені bash:
[simterm]
$ kk -n monitoring run pod --rm -i --tty --image ubuntu -- bash
probe_success{target="nginx-test-404"} == 1 – все робить.
TCP Connect і моніторинг баз данних
Ще один модуль, котрий дуже часто використовуємо – TCP, який просто намагається відкрити TCP-сессію на вказанний URL та порт. Підходить для перевірок баз данних та будь-яких інших не-HTTP-ресурсів.
$ kk get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 20h
mysql ClusterIP 10.99.71.124 <none> 3306/TCP 40s
mysql-headless ClusterIP None <none> 3306/TCP 40s
Запускаємо init, что б підтягнути необхідні модулі самого Тераформу:
[simterm]
$ terraform init
Initializing the backend...
Initializing provider plugins...
- Finding latest version of hashicorp/local...
- Installing hashicorp/local v2.2.3...
- Installed hashicorp/local v2.2.3 (signed by HashiCorp)
...
Terraform has been successfully initialized!
[/simterm]
Потім plan – перевіряємо чи буде воно робити взагалі, та що саме:
[simterm]
$ terraform plan
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# local_file.file will be created
+ resource "local_file" "file" {
+ content = "file content"
+ directory_permission = "0777"
+ file_permission = "0777"
+ filename = "file.txt"
+ id = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
$ terraform apply
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# local_file.file will be created
+ resource "local_file" "file" {
+ content = "file content"
+ directory_permission = "0777"
+ file_permission = "0777"
+ filename = "file.txt"
+ id = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
local_file.file: Creating...
local_file.file: Creation complete after 0s [id=87758871f598e1a3b4679953589ae2f57a0bb43c]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
[/simterm]
І перевіряємо зміст каталогу, в якому запускали:
[simterm]
$ ls -l
total 12
-rwxr-xr-x 1 setevoy setevoy 12 Nov 28 13:14 file.txt
-rw-r--r-- 1 setevoy setevoy 90 Nov 28 13:09 main.tf
-rw-r--r-- 1 setevoy setevoy 854 Nov 28 13:14 terraform.tfstate
Оновлюємо корневий модуль, тобто modules_example/main.tf – видаляємо resource "local_file", і замість нього описуємо два модулі, в яких вказуємо шляхи до каталогів обох модулів:
Запускаеємо init знову, щоб Тераформ створив свою структуру модулей:
[simterm]
$ terraform init
Initializing modules...
- file_1 in modules/file_1
- file_2 in modules/file_2
Initializing the backend...
Initializing provider plugins...
- Reusing previous version of hashicorp/local from the dependency lock file
- Using previously-installed hashicorp/local v2.2.3
Terraform has been successfully initialized!
$ terraform apply -auto-approve
module.file_2.local_file.file_2: Refreshing state... [id=5771aa8b1046de4f4342d492faee20e3c289365d]
module.file_1.local_file.file_1: Refreshing state... [id=8a3552bfa2e46f311e7b718f8eed71b69bb8115f]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# local_file.concat_file will be created
+ resource "local_file" "concat_file" {
+ content = <<-EOT
file_1 content from user1
file_2 content from user2
EOT
+ directory_permission = "0777"
+ file_permission = "0777"
+ filename = "concat_file.txt"
+ id = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
local_file.concat_file: Creating...
local_file.concat_file: Creation complete after 0s [id=a4e1240fb9cdc96fffc1b0984392f6218422d194]
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
[/simterm]
Перевіряємо:
[simterm]
$ cat concat_file.txt
file_1 content from user1
file_2 content from user2
[/simterm]
Передача значень змінних між модулями
І, нарешті, те, з чого почали – як передати значення з одного модулю в інший?
В файлі main.tf першого модулю додаємо змінну з іменем module_1_value, якій задаємо дефолтне значення “module 1 value“:
Теперь в файлі file_1.txt маємо отримати значення із module "file_2", і навпаки.
Запускаємо:
[simterm]
$ terraform apply -auto-approve
module.file_1.local_file.file_1: Refreshing state... [id=d74b0e0b3296ab02e7b4791942d983b175d071b4]
local_file.concat_file: Refreshing state... [id=e0e88293b53693a484db146b15bd2ab3d8f4d250]
module.file_2.local_file.file_2: Refreshing state... [id=12faf027dc96d886c6022b54c878324a21d3d112]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
-/+ destroy and then create replacement
Terraform will perform the following actions:
# local_file.concat_file must be replaced
-/+ resource "local_file" "concat_file" {
~ content = <<-EOT # forces replacement
- file_1 content from user1 with value from file_2: variable 2 value
- file_2 content from user2 with value from file_1: variable 1 value
+ file_1 content from user1 with value from file_2: module 2 value
+ file_2 content from user2 with value from file_1: module 1 value
EOT
~ id = "e0e88293b53693a484db146b15bd2ab3d8f4d250" -> (known after apply)
# (3 unchanged attributes hidden)
}
Plan: 1 to add, 0 to change, 1 to destroy.
local_file.concat_file: Destroying... [id=e0e88293b53693a484db146b15bd2ab3d8f4d250]
local_file.concat_file: Destruction complete after 0s
local_file.concat_file: Creating...
local_file.concat_file: Creation complete after 0s [id=648854841581b273d26646fff776b33fdf060a19]
Apply complete! Resources: 1 added, 0 changed, 1 destroyed.
[/simterm]
Перевіряємо результат:
[simterm]
$ cat concat_file.txt
file_1 content from user1 with value from file_2: module 2 value
file_2 content from user2 with value from file_1: module 1 value
Маємо Grafana Loki для логів, до подів якої треба підключити AWS IAM Role з AWS IAM Policy, котра дає доступ до AWS S3 бакету, в якому будуть зберігатися чанки та індекси (про сетап самої Loki з AWS S3 трохи пізніше окремим постом).
IAM ролі для Kubernetes подів працють тим самим чином, як ми це робимо, коли підключаємо IAM-ролі до ЕС2-інстансів – процес всередині пода виконує запит до AWS API, а AWS SDK чи AWS CLI, за допомогою якого робиться запит, виконує запит AssumeRole, якому передається сама IAM Role (див. AWS: ротация ключей IAM пользователей, EC2 IAM Roles и Jenkins).
Щоб перевірити, як воно взагалі буде працювати в Кубері – створимо тестову IAM Role, ServiceAccount з аннотацією цієї ролі, та запустимо под з цим ServiceAccount.
Забігаючи наперед – в самій Локі це все одно працює через якусь альтернативну реальність, тобто навіть коли їй підключаєш вже протестований ServiceAccount – вона валиться з помилками. Треба буде копати.
EKS кластер розгорнутий за допомогою Terraform модуля aws_eks_cluster, і OpenID Connect (OIDC) provider вже має бути налаштований.
Заходимо на сторінку кластера, знаходимо OpenID Connect provider URL:
Або з консолі:
[simterm]
$ aws --profile development --region us-west-2 eks describe-cluster --name dev_data_services --query "cluster.identity.oidc.issuer" --output text
https://oidc.eks.us-west-2.amazonaws.com/id/537***A10
[/simterm]
Копіюємо URL без https://, та перевіряємо в IAM > Identity providers:
Окей, тут все є.
Створення Kubernetes ServiceAccount з AWS IAM role
Для початку, створимо IAM policy, яка дає права на AWS S3 bucket, потім IAM Role з TrustedPolicy, яка дозволяє виконувати AssumeRole, використовуючи OIDC identity provider (IDP) кластеру.
$ aws --profile development iam create-policy --policy-name test-iam-sa-pod-policy --policy-document file://test-iam-sa-pod-policy.json
[/simterm]
Переходимо до ролі.
AWS IAM role та TrustedPolicy
Знаходимо ARN нашого Identity Provier:
URL OIDC identity provider вже знаходили раніше:
[simterm]
$ aws --profile development --region us-west-2 eks describe-cluster --name dev_data_services --query "cluster.identity.oidc.issuer" --output text
https://oidc.eks.us-west-2.amazonaws.com/id/537***A10
[/simterm]
Створення IAM Role з AWS CLI
Створюємо файл з TustedPolicy, в Principal якої вказуємо ARN IDP, а в Condition – URL OIDC кластеру, якому дозволяємо виконувати запит до sts.amazonaws.com:
На цей раз стало мені цікаво – а чи можна якось поекономити заряд батерії ноутбука? Не сказати, що швидко разряжається – на 5-6 годин роботи вистачає, але зайвим не буде.
Знайшов декілька утіліт, про них сьогодні й запишу.
Upower
Перша утілітка – upower:
[simterm]
$ sudo pacman -S upower
[/simterm]
Спочатку можна визвати з опцією --monitor-detail – буде в ріалтаймі виводити інформацію про стан батареї:
[simterm]
$ $ sudo upower --monitor-detail
Monitoring activity from the power daemon. Press Ctrl+C to cancel.
[20:42:20.071] device changed: /org/freedesktop/UPower/devices/battery_BAT0
native-path: BAT0
vendor: SMP
model: LNV-5B10W13895
serial: 2056
power supply: yes
updated: Fri Nov 18 20:42:20 2022 (0 seconds ago)
has history: yes
has statistics: yes
battery
present: yes
rechargeable: yes
state: charging
warning-level: none
energy: 36.7 Wh
energy-empty: 0 Wh
energy-full: 0 Wh
energy-full-design: 0 Wh
energy-rate: 15.538 W
voltage: 12.391 V
charge-cycles: N/A
time to full: 22.7 minutes
percentage: 86%
technology: lithium-polymer
icon-name: 'battery-full-charging-symbolic'
History (charge):
1668796940 86.000 charging
1668796850 85.000 charging
History (rate):
1668796940 15.538 charging
1668796910 15.784 charging
1668796880 16.006 charging
1668796850 16.253 charging
[/simterm]
Відразу бачимо модель батареї ноута – LNV-5B10W13895, та її стан – кількість ватт-годин (36.7 Wh), та скількі споживає зараз (15.538 W), і на якій потужності – 12.391 V.
Можна порахувати в ампер-годинах:
[simterm]
>>> 37.31/12.3
3.03
[/simterm]
Тобто зараз 3033 mAh заряду в батареї.
Заодно побачили сам девайс батареї – /org/freedesktop/UPower/devices/battery_BAT0.
Отримати інфо про неї без моніторингу, а один раз – опція -i з пристроєм – sudo upower -i /org/freedesktop/UPower/devices/battery_BAT0.
ACPI
Друга, аналогічна утіліта – acpi, але ще вміє відображати температуру (і не тільки – див. About ACPI):
[simterm]
$ sudo pacman -S acpi
[/simterm]
Виводимо інформацію щодо батареї:
[simterm]
$ acpi -i
Battery 0: Charging, 91%, 00:21:40 until charged
Battery 0: design capacity 3649 mAh, last full capacity 3431 mAh = 94%
[/simterm]
“design capacity 3649 mAh” – все майже як рахували вище, тільки там брали поточний заряд, який зараз десь 94% від design capacity.
Batstat
Третя корисна річ – batstat. Простенька, але може стати в нагоді.
Качаємо репозіторій, збираємо:
[simterm]
$ git clone https://github.com/Juve45/batstat.git
$ cd batstat
$ make
$ chmod +x batstat
$ sudo mv batstat /usr/local/bin/
[/simterm]
І запускаємо:
Powertop
Powertop вміє не просто виводити інформацю про батарею, але й по-перше – виводити інформацю про процеси, які споживать енергію, по-друге – може виконати налаштування для економії заряду.
[simterm]
$ sudo pacman -S powertop
[/simterm]
Запускаємо під рутом:
[simterm]
$ sudo powertop
[/simterm]
В табі Tunables виводиться інформація по налаштуванням, які можуть оптимізувати споживання енергії.
Вибираємо потрібний пункт, Enter – і опція переключається:
Вміє генерувати html:
[simterm]
$ sudo powertop --html=powerreport.html
[/simterm]
І результат:
Можна додати systemd-сервіс, який буде виконувати автоматичний тюнінг при старті системи.
Bluetooth мені постійно не потрібен, рідко його включаю, теж саме з Притунлом.
tick_sched_timer та Polybar
Ще виявив цікаву річ – tick_sched_timer, шедулєр ядра, з’їдав аж 1.7W:
Погуглив, знайшов цей тред, прибив процес Polybar, який зверху виводить всяку інформацю по системі, використовуючи власні модулі – і tick_sched_timer почав споживати лише 150-300 mW.
Що робити, коли немає світла, вежі мобильного зв’язку відключаються, а подивитися відосиків з нашими котиками хочеться? Правильно – купити собі 3/4G модем з антеною!
До того ж самій антені живлення не треба, а модем можна вставити в звичайний павербанк, якого вистачає надовго, бо модему багато не треба.
Купував комплект 4G Zte Mf79U + Квадрат Mimo – цікавий магазин (не реклама), і продають відразу комплектами, що дуже зручно для таких як я, які не шарять в тому, як його вибирати, особливо коли діло стосується самої антени.
Окрема подяка @Artem за ідею та поміч при налаштуванні)
Сам комплект виглядає так:
Підключення модему
Вставляємо карту micro-SIM в порт карти, я взяв карточку Водафона – він тут наче краще всіх робить, коли вирубає вишки.
Другий – під карту памя’ті:
Пароль та SSID є на девайсі:
Вставляємо в комп/ноут:
Сигнали описані в інструкції, кратко:
зверху – WiFi, знизу – мобільний
мобільний блимає зеленим – підключено до 3G, трафік йде
мобільний блимає блакитним – підключено до 4G, трафік йде
Заходимо на http://192.168.0.1:
Переходимо до налаштувань WiFi:
За бажанням – міняємо SSID та пароль на свої:
Сигнал модему навіть кращий за домашній роутер, який стоїть поруч – setevoy-linksys:
Переходимо до антени.
Підключення антени
Готуємо кабелі.
В комплекті йде один довгий, розрізаємо на дві однакові частини.
На кінцівках надрізаємо пластик, обережно, бо під ним обмотка. Знімаємо верхній шар ізоляції:
Мідну обмотку під ним разом з алюмінюєвий екраном загортаємо донизу, надрізаємо внутрішню ізоляцю, та оголяємо внутрішній мідний стержень:
Накручуємо конектор (всередені різьба) – готово:
З витою парою гемору більше 🙂
Повторюмо для всіх чотирьох, и врешті-решт підключаємо всю систему:
Розміщення антени
Встановлюємо на телефон утілітку Network Cell Info Lite & Wifi – показує найближчі вежі, до яких конектиться телефон.
В мене вишка Водафону як раз навпроти вікон, тож і антену розміщуємо “обличчям” до вежі:
Сила сигналу та тест швидкості
Краще антену взагалі виносити за вікно, бо, сюрпрайз – навіть склопакет впливає на силу сигналу.
Отже, за допомогою Network Cell Info знаходимо напрямок вежі, виставляємо антену в її напрямку, і перевіряємо сигнал, прямо на стартовій сторінці адміністрування самого модему:
-91 decibel-milliwatts (децибел-мілівати) – не вражає, але враховуючи, що я живу за містом, і вишка від мене приблизно в трьох кілометрах – то не так вже й погано.
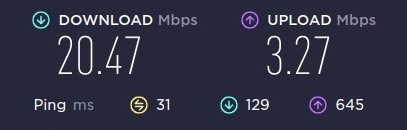
Швидкість до відключення живлення “на районі”:
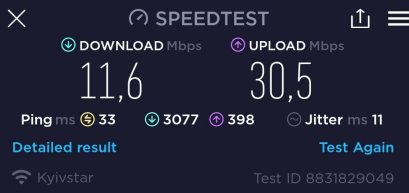
І під час вимкнення свіла:
Швидкість не найкраща, але для роботи/месенджерів та навіть Ютубу вистачає.
При цьому мобільний інтернет на телефоні не працює взагалі – Speedtest навіть не стартує, видає помилку.
В самому Києві результати набагато краще – кажуть, що 2Мбс на загрузку видає стабильно.
Або навіть так – Оболонь, з таким же комплектом обладнання:
Хочеться прибрати россійські сайти із результатів пошуку в Гуголі, тож нагуглив декілька варіантів.
Перші два – “ручні”, через додавання параметру ?lr=-lang_ru або ?cr=-countryRU в URL Гугла, тобто виглядатиме він як https://google.com.ua/?lr=-lang_ru:
Але ж це мануальщина…
Нажаль, в Хромі автоматизувати не вийшло – вирізає цю частину при виконанні запиту:
 Вже давно просили написати пост про те, як я готувався до зими – ось, таки вмовили.
Вже давно просили написати пост про те, як я готувався до зими – ось, таки вмовили.








 Добре – Loki запускати навчились –
Добре – Loki запускати навчились – 






































 Загальну інформацію по Grafana Loki див. у
Загальну інформацію по Grafana Loki див. у 





































 Маємо Grafana Loki для логів, до подів якої треба підключити AWS IAM Role з AWS IAM Policy, котра дає доступ до AWS S3 бакету, в якому будуть зберігатися чанки та індекси (про сетап самої Loki з AWS S3 трохи пізніше окремим постом).
Маємо Grafana Loki для логів, до подів якої треба підключити AWS IAM Role з AWS IAM Policy, котра дає доступ до AWS S3 бакету, в якому будуть зберігатися чанки та індекси (про сетап самої Loki з AWS S3 трохи пізніше окремим постом).

























 -91 decibel-milliwatts (децибел-мілівати) – не вражає, але враховуючи, що я живу за містом, і вишка від мене приблизно в трьох кілометрах – то не так вже й погано.
-91 decibel-milliwatts (децибел-мілівати) – не вражає, але враховуючи, що я живу за містом, і вишка від мене приблизно в трьох кілометрах – то не так вже й погано.