Фукція в AWS Lambda пише логи в CloudWatch Logs, звідки ми через lambda-promtail забираємо їх в Grafana Loki, звідки потім можемо використати в графіках Grafana.
Що треба зробити: в логах пишеться час “Init duration” та “Max Memory Used”.
В CloudWatch таких метрик нема, а нам цікаво мати графік по цим данним, бо це може бути ознакою cold start, які ми хочемо відслідковувати.
Тож треба:
отримати ці дані і використати як values в графіку
побудувати графік, де зліва будуть відображатись мілісекунди на запуск, а справа – скільки пам’яті при цьому було використано
Grafana Loki і values з labels
Тож що можемо зробити:
зі stram selector вибираємо файл логу потрібної фунції
через log filter вибираємо записи, які містять строку “Init Duration”
з log parcer regex отримуємо значення з Max Memory Used або Init duration, і створюємо нову label з цим значенням
Тобто для створеня лейбли max_mem_use повністю запит буде таким:
Далі, Init Duration в мілісекундах хочемо відображати зліва як Unit > miliseconds, а Memory Used – справа як Unit > megabytes.
З Init Duration все просто – налаштовуємо Standard options > Unit > ms:
А для Memory – йдемо в Overrides і додаємо нові параметри для поля max_mem_use:
В Property вибираємо Axis > Placement:
І встановлюємо значення Right:
Далі, щоб відображати юніт як мегабайти – додаємо другий Override property – Unit:
І встановлюємо значення megabytes:
Тепер на графіку з однієї сторони маємо час запуску функції, а з другої – скільки пам’яті вона при цьому споживала, і явно бачимо кореляцію між цими значеннями:
Єдине, що ці дані все ж не зовсім вірно допоможуть з визначенням саме cold starts, так як в цей проміжок просто було багато запитів до API Gateway > Lambda, і вона запускалась в декількох інстансах – тому і маємо спайк на графіку Init duration та Memory:
Тому треба трохи переробити: запити з Loki винести в Recording Rules та писати у вигляді звичайних метрик в Prometheus/VictoriaMetrics, а потім в Query графіку отримане з Loki значення ділити на кількість отриманиз записів з логу в цей період.
Що ж – зима наближається. Пора починати думати про забезпечення себе електрохарчуванням (с), бо пам’ятаючи минулу зиму – забезпечити себе електрикою треба, та й ціни на всяке електрообладнання почнуть рости дуже скоро.
Загальна задумка – забезпечити себе автономність на тиждень блекауту – будемо брати найбільш песимістичний варіант. На тиждень має вистачити енергії для роботи, тобто по мінімуму – ноутбук та живлення медіаконвертора з роутером.
Окрема подяка @artygan за допомогу у розрахунках 🙂
Що таке Вольт, Ампер та Ват
Згадаймо школу 🙂 Бо я всі ці речі почав розбирати заново минулої зими, коли писав перший такий пост (але він лишився у чернетках).
Вольти: напруга. Це фізична величина, що характеризує величину відносини роботи електричного поля в процесі перенесення заряду з однієї точки A в іншу точку B до величини цього заряду.
Простіше кажучи це різниця потенціалів між двома точками. Вимірюється у Вольтах. Напруга схоже по суті з величиною тиску води в трубі – чим воно вище, тим швидше вода тече з крана.
Позначається як В або V.
Ампер: сила струму. Це фізична величина, рівна відношенню кількості заряду за певний проміжок часу, що протікає через провідник до величини цього самого проміжку часу.
Силу струму можна порівняти з потоком води з крана – чим більше ми його відкриваємо, тим більше води виливається за одиницю часу або навпаки.
Позначається як А.
Ват: потужність. Це швидкість виробництва або передачі енергії, це кількість енергії на одиницю часу. 1 Ват – величина потужності, при якій за одну секунду відбувається робота дорівнює одному джоулів. Отже, Ват – це похідна від інших величин одиниця. Так, наприклад, потужність співвідноситься з напругою в такий спосіб: Вт = В • А, де В – показник величини напруги, Вольти, а А – показник величини сили струму, Ампери.
Потужність можна порівняти з кількістю води в літрах, яке виллється з крана.
Позначається як W (Вт).
Не пам’ятаю звідки взяв, але в старій чернетці був такий опис:
– Напруга (V): ширина річки – Сила струму (A): швидкість течії води в річці Тому одну і ту ж потужність може дати й широка ріка (висока напруга, Вольт) з повільною течією (слабкий струм, Ампер) – і вузька річка (низька напруга, Вольт) зі швидкою течією (сильний струм, Ампер).
Чим швидше ріка і чим вона ширше – тим більше води (Ват) за одиницю часу.
Розрахунок часу роботи батареї/акумулятора
Далі глянемо, як порахувати акумулятори та павербанки – на скільки часу має вистачити кожного приладу, які маю в запасі.
Головна мета покупки павербанок для мене – це живлення ноутбуку, тому давайте рахувати по ньому.
Наприклад візьмемо ноутбук ThinkPad 4750U.
На зарядному маємо показники напруги та сили току – 20 вольт та 3.25 ампери:
Формула вихідної потужності:
Ампер * вольти
Тобто максимальна потужність зарядного – 20 вольт * 3.25 ампери буде 65 ват, як і показано на самому зарядному.
Отже, якщо ноутбук буде працювати на повну потужність – це буде 65 ват-годин.
Далі, беремо банку, наприклад на 30.000 мА/г (30 А/г) з виходом 3.8 вольт, і рахуємо ват-години.
Формула розрахунку Ампер/годин в Ват/години:
мА/г * вольт / 1000
Тобто наша банка на 30.000 мА/г при робочій напрузі у 3.8 вольт має:
[simterm]
30000*3.8/1000
114
[/simterm]
114 ват/годин.
Насправді це теж вказано прямо на самій банці:
Тобто, ноутбук на повній потужності у 65 ват має працювати:
[simterm]
>>> 114/65
1.75
[/simterm]
Але реально він споживає близько 15 ват (можна глянути утілітою типу Powertop або Upower):
Тобто цієї банки має вистачити на 7.5 годин. Хоча насправді за 2 години ноут з цієї банки зжер 50%.
Але якщо рахувати так, як говориться у вищезгаданій статі:
Якщо поруч із ємністю вказаний стандартний для повербанка вольтаж (від 3,6 до 3,8 вольта), спочатку виконайте конвертацію напруги в 5 вольт. Для цього помножте номінальну ємність на вказаний для неї вольтаж і поділіть результат на 5. Далі, щоб врахувати втрати при конвертації та передачі енергії, помножте отриманий на попередньому етапі результат на 85% — це середній ККД при зарядці. У результаті отримаєте теоретичну реальну ємність свого повербанка.
То вийде:
[simterm]
>>> 30000*3.8/5*0.85
19380.0
[/simterm]
А це вже виходить 73 Вт/год, і тоді ноут на 15 ватах пропрацює ~4.5 годин – як і було на тесті.
Автомобільні акумулятори
Для AGM або гелевих акумуляторів формула така ж, але треба враховувати коефіцієнт розряду – 0.65, бо висажувати акум в нуль не можна, і інвертор має відключити живлення при падінні заряду до мінімально допустимого, або подати звуковий сигнал, що його треба виключати.
до нього підключено 1 автомобільний акумулятор Exide AGM на 72 А/г
561 Вт/год
кілька дрібних павербанків для світильників/медіаконвертора/роутера тощо
Загалом запас виходить 3193 Вт/год, тобто якщо будуть включені всі прилади, то запасу лише на 10 з половиною годин.
Але котел, холодильник та монітор (130+90+35 Вт/год == 225 Вт/год) можуть живитись тільки від зарядних на балконі, де інвертори на 600-700 Ват з розетками schuko і в яких сумарно є 1497 Вт/год, тобто їх запасу вистачить лише на 6.5 годин. Але можна докупити інвертор для станцій Kseon ват на 500 і живити з цих станцій – в мене зараз для них китайський інвертор на 200 ват, на який підключати котел стрьомно, бо цей інвертор скоріш за все згорить. Та й взагалі через такі інвертори живити прилади – це зайві витрати, краще зберегти для ноутбука і інших приладів, які можна через заживити через USB.
Якщо відключити холодильник (минулої зими так і робив – зберігав на балконі, де було 10-14 градусів, а заморозку вивішував в пакеті за вікно), то газовому котлу для опалення акумуляторів на балконі вистачить на 11.5 годин.
Ноутбук (15-20 Вт/год), роутер (10-12 Вт/год), медіаконвертор (8 Вт/год) можуть живитись від станцій Kseon та павербанок – разом в них 1696 Вт/год, тобто 42.4 години, або ~3 днів, якщо користуватись 14 годин на день, бо вночі все ж краще спати, або на 5 днів, якщо користуватись виключно для роботи 8 годин на день.
Швидкість розряду
Математика математикою, але частину батарей перевірив “на живу”, щоб більш-менш точно знати чого на скільки вистачить:
інвертор CyberPower + 1х акумулятор Exide AGM на 72 А/г
72.000 мА/г на 12 вольтах * 0.65 це 561 Вт/год
має вистачити на ~4.5 годин роботи
ПК пропрацював з 8.30 – 12.14, тобто 3 години 45 хвилин. Потім інвертор почав пищати, бо напруга впала до 11.4 вольти, хоча на екрані інвертор показував ще половину заряду батареї. В принципі, десь так і виходить – 4.5 години, якщо садити “в нуль”
інвертор Powerware + 2х акумулятори на 60 А/г
120.000 мА/г на 12 вольтах * 0.65 це 936 Вт/год
по розрахунках котлу має вистачити на 6-7 годин, не заміряв (минулої зими пам’ятаю, що було менше – годин на 4-6, але це ще залежить від температури на вулиці – як швидко охолоджуються квартира, і як часто котел буде включатись для підігріву)
2х банки Baseus:
30.000 мА/г на 3.8 вольта 114 Вт/год
обох банок ноутбуку має вистачити на 12 годин – по 6 годин з кожної банки, хоча насправді її вистачило десть на 4.5 години
банка 2Project:
60.000 мА/г на 3.8 вольтах 228 Вт/г
ноутбуку має вистачити на 11 годин (знову ж таки – реально буде годин мабуть 7-8)
Швидкість зарядки
В принципі, це все працює, але головна проблема, яка проявилась тієї зими – це швидкість зарядки, і це треба враховувати наступної зими.
Формула для розрахунку та ж сама: беремо вольтаж зарядного пристрою, його силу струму, перемножуємо – отримаємо Ват/години, котрі він видає, а знаючи ємкість батареї в ват/годинах – можемо легко прикинути швидкість зарядки.
Тобто зарядка на 16.8 вольт з 2 амперами дасть 32 Вт/год, і зарядить Kseni на 620 Вт/год за 19 годин.
Частину батарей заміряв реальною зарядкою, частину прикинув по формулі:
зарядні Kseni по документації на дефолтних зарядках на 2А 16,8 В заряджаються 16 годин
для павербанків Baseus і 2Project минулої зими купував зарядні Baseus GaN3 з виходом на 30 ват (20 Вольт і 1.5 ампера – 20В*1.5А=30Вт)
банка Baseus – включив зарядку з нуля о 13.45 – в 15.50 було 50%, тобто за дві години залило 15.000 мА/г (~57 Вт/г) на 30 ватах – якщо рахувати повну ємкість як 114 Вт/г, то так і виходить – 3.8 години на 30 ватах
банка 2Project – пишуть, що “30 годин через вхід 10 Вт“, тож має бути близько 10 годин на 30 ватах
акумулятори на балконі – тут важко рахувати, бо ніде в документації не знайшов скільки реально йде на акумулятори під час зарядкки, тож просто розрядив і запустив зарядку:
1х72 А/г через CyberPower заряджається:
включив у 12.15, к 16.00 напруга піднялась з 11.4 (коли інвертор почав пищати, що пора виключати, бо низький заряд батареї) до 12.5, а максимальна 13.8, тобто зарядився десь наполовину за 4 години, значить повний заряд 72 А/г буде близько 8 годин
2х60 А/г через PowerWare – не заміряв, але пам’ятаю, що десь також близько 10 годин
Що треба докупити
Саме складне питання.
Можна, звісно, взяти нормальну зарядну станцію типу EcoFlow Delta 2 Max – 2400W, 2048Wh за 83.000 гривень – це на сьогоднішній день, середина серпня. Цього вистачить для котла 130 Вт + холодильника 90 Вт + монітора 30 Вт на 8 годин роботи, а заряджається Delta 2 max за 2 години – те, що треба, якщо світло знов буде кілька годин на добу.
В принципі – дуже достойне рішення, але ж і ціна… Достойна.
Інший варіант – купити два гелевих акумулятори на 100 А/г кожний – зараз це буде в районі 16.000 грн за дві штуки, і докупити другий інвертор CyberPower – ще 18.000 грн. Тоді можна підключити кожен з CyberPower до 1 акуму, і вони будуть їх заряджати за ~10 годин. Разом це вийде 34.000 грн – дешевше, ніш Delta 2 Max, але при тих же 2400 Вт/год запасу енергії і заряджається набагато довше.
Крім того, мабуть, докуплю:
ще пару банок Baseus на 30.000 – показали себе непогано, ноутбук від них працює, вартість зараз 3900 грн (в листопаді чи грудні минулої зими брав по чи то 6000, чи 7000 грн)
докупити зарядні Baseus GaN3 на 30 ват для кожної банки, щоб можна було заряджати одночасно
Type-C шнурки, бо маю тільки два
Ще все ж може таки куплю на балкон датчик диму, бо там акумулятори та інвертори – буду спокійніше спати. Вогнегасник брав ще минулої зими, 2 штуки ВП-3.
Також думаю на цю зиму вже ж взяти газовий обігрівач та газову плитку на балончиках – на випадок, якщо газ все ж будуть відключати.
Працює Loki все в AWS Elastic Kubernetes Service, встановлено з Loki Helm chart, в ролі long-term store використовуємо AWS S3, а для роботи з індексами Loki – BoltDB Shipper.
У Loki в 2.8 для роботи з індексами з’явився механізм TSDB, який мабуть скоро замінить BoltDB Shipper, але я його ще пробував. Див. Loki’s new TSDB Index.
І загалом все працює, все наче добре, але при отримані даних за тиждень або місяць в Grafana дуже часто отримуємо помилки 502/504 або “too many outstanding requests“.
Тож сьогодні трохи поглянемо на те, як можна оптимізувати Loki для кращого перфомансу.
Насправді, витратив дуже багато часу на те, щоб більш-менш розібратись з усім, що буде в цьому пості, бо документація Loki… Вона є. Її багато. Але зрозуміти з цієї документації якісь деталі реалізації, або як різні компоненти один з одним працюють місцями досить складно.
Тим не менш, якщо все ж витратити трохи часу на “причісування”, то загалом система працює дуже добре (принаймні, поки ми не маємо террабайтів логів в день, але зустрічав обговорення, де люди мають такі навантаження).
Отже, що ми можемо зробити, щоб пришвидшити процесс роботи для обробки запросів в Grafana dashboards та/або алертів з логів:
оптимізація запросів
використати Record Rules
включеня кешування запитів, індексів та chunks
оптимізувати роботу Queries
Поїхали.
Loki Pods && Components
Перед тим, як братись за оптимізацію давайте згадаємо що там в Loki взагалі є і як воно все разом працює.
querier: обробляє запити на отримання даних – спочатку намагається взяти дані з пам’яті Ingester, якщо там їх нема – то йде до long-term store
query frontend: опціональний сервіс для покращення швидкості роботи Querier: запити на отримання даних спочатку йдуть на Query Frontend, який розбиває велики запити на менші і виконує формує чергу запитів, а Querier з цієї чегри бере запити на обробку. Крім того, Query Frontend може виконувати кешування відповідей, і части запитів обробляти зі свого кешу замість того, щоб виконувати цей запит на воркері, тобто на Querier
query scheduler: опціональний сервіс для покращеня скейлінгу Querier та Query Frontend, який бере на себе формування черги запитів, та передає їх до декількох Query Frontend
ingester: у Read-path відповідає на запити від Querier даними, які має в пам’яті (ті, що ще не було відправлені до long-term store)
Write:
distributor: приймає вхідні логи від клієнтів (Promtail, Fluent Bit, etc), перевіряє їх та відправляє до Ingester
ingester (again): приймає дані від Distributor, і формує chunks (блоки даних або фрагменти), які відправляє до long-term store
Backend:
ruler: перевіряє дані в логах по expressions, заданим в рулах, та створює алерти або метрики в Prometheus/VictoriaMetrics
compactor: відповідає за компресію індекс-файлів і retention даних у long-term storage
Gateway: звичайний Nginx, який відповідає за роутінг запитів до відповідних сервісів Loki
Table Manager, BoltDB Shipper та індекси
Окремо варто згадати про створення індексів.
По-перше – Table manager, бо особисто мені з його документацій було не дуже зрозуміло використовується він зараз, чи ні. Бо з одного боку в values.yaml він має enabled=false, з іншого – в логах Write-інстансів він подекуди з’являється.
Отже, що маємо про індекси:
Table Manager вже depreacted, і використовується тільки у випадку, якщо індекси зберігається у зовнішніх сховищах – DynamoDB, Cassandra, etc
файли індексів створються Ingester в каталозі active_index_directory (по-дефолту /var/loki/index), коли chunks з пам’яті готові до відправки до long-term storage – див. Ingesters
механізм boltdb-shipper відповідає за відправку індексів з інстансів Ingester до long-term store (S3)
Loki queries optimization
Переглянув Best practices, і спробував рекомендації на практиці, але насправді не помітив різниці.
Проте все ж додам сюди кратко, бо в принципі вони виглядають досить логічно.
Перевіряв за допомогою запросів типу:
[simterm]
$ time logcli query '{app="loki"} |="promtail" | logfmt' --since=168h
[/simterm]
І час виконання все одно був дуже різний навіть при виконанні одного й того ж запросу, незалежно від спроб оптимізації запросу за рахунок використання селекторів чи фільтрів.
Label or log stream selectors
На відміну від ELK, Loki не індексує весь текст в логах, а тільки timestamp та labels:
Тож запит у вигляді {app=~".*"} буде виконуватись довше, ніж при використанні точного stream selector, тобто {app="loki"}.
Чим більш точний stream selector буде використано – тим менше даних Loki буде вигружати даних з long-term store та обробляти для відповіді – запит {app="loki", environment="prod"} буде швидшим, ніж просто вибрати всі стріми з {app="loki"}.
Line Filters та regex
Використовуйте Line filters, та уникайте регулярок в запитах.
Тобто запит {app="loki"} |= "promtail" буде швидшим, ніж просто {app="loki"}, і швидшим, аніж {app="loki"} |~ "prom.+".
LogQL Parsers
Парсери по швидкості роботи:
pattern
logfmt
JSON
regex
І не забувайте про Log Filter: запит {app="loki"} |= "promtail" | logftm буде швидшим, ніж {app="loki"} | logfmt.
А тепер перейдемо до параметрів Loki, які дозволять пришвидшити обробку запитів та зменшать використання CPU/Memory його компонентами.
Взагалі Ruler виявився набагато цікавішим, аніж просто виконувати запити для алертів.
Він чудово підходить для будь яких запитів, бо ми можемо створити Recording Rule, а результати відправляти Prometheus/VicrtoriaMetrics через remote_write, після чого виконувати запити на алерти або в дашбордах Grafana прямо з Prometheus/VicrtoriaMetrics замість того, щоб кожного разу виконувати їх в Loki, і працює це набагато швидше, ніж описувати запит в самій Grafana або алерт-рул у файлі конфігу Ruler.
Отже, щоб зберігати результати в Prometheus/VicrtoriaMetrics – в параметрах Ruler додаємо WAL-директорію, куди Ruler буде записувати результати запитів, та налаштовуємо remote_write, куди він буде зберігати результати запитів:
А якщо робити запит напряму з дашборди – то іноді по кілька секунд:
Кешування
Loki може зберігати дані в кеші, щоб потім віддавати дані з пам’яті або диску, а не виконувати запит “з нуля” і не завантажувати файли індексів та блоків даних з S3.
Теж дало досить відчутний результат по швидкості виконання запросів.
Query Frontend працює як load balancer для Queriers, і розбиває запроси за великий проміжок часу на частини, після чого віддає їх Queriers для виконання паралельно, а після виконання запросу збирає результати обратно в одну відповідь.
Для цього в limits_config задається split_queries_by_interval з дефолтом в 30 хвилин.
Параметри паралелізму задаються через querier max_concurrent – кількість одночасних потоків для виконання запитів. Пишуть, що можна ставити х2 від ядер CPU.
Крім того в limits_config задається ліміт на загальну кількість одночасних виконань через max_query_parallelism, яке має бути кількість Queriers (read-поди) помножена на max_concurrent. Хоча поки не знаю, як це настраювати якщо для read-подів включати автоскейлінг.
У нас моніторинг працює на t3.medium з 4 vCPU, тож поставимо max_concurrent == 8:
Де в топі з великим відривом бачимо дві адреси – 10.0.3.111 та 10.0.2.135, які нагнали аж 28995460061 байт трафіку.
Loki components та трафік
Перевіряємо, що ж це за поди в Kubernetes, і заодно знаходимо відповідні WorkerNodes/EC2.
Спершу 10.0.3.111:
[simterm]
$ kk -n dev-monitoring-ns get pod -o wide | grep 10.0.3.111
loki-backend-0 1/1 Running 0 22h 10.0.3.111 ip-10-0-3-53.ec2.internal <none> <none>
[/simterm]
Та 10.0.2.135:
[simterm]
$ kk -n dev-monitoring-ns get pod -o wide | grep 10.0.2.135
loki-read-748fdb976d-grflm 1/1 Running 0 22h 10.0.2.135 ip-10-0-2-173.ec2.internal <none> <none>
[/simterm]
І вже тут я згадав, що саме 31-го липня включив алерти в Loki, які обробляються як раз в поді backend, де крутиться компонент Ruler (раніше він був у поді read).
Тобто левова частина трфіку відбувається саме між Read та Backend подами.
Окреме питання що саме там в такій кількості передається, але поки треба вирішити проблему с витратами на трафік.
Перевіримо в яких AvailabilityZones знаходяться Kubernetes WorkerNodes.
Інстанс ip-10-0-3-53.ec2.internal, де крутиться под з Backend:
[simterm]
$ kk get node ip-10-0-3-53.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1b
[/simterm]
Та ip-10-0-2-173.ec2.internal, де знаходиться под з Read:
[simterm]
$ kk get node ip-10-0-2-173.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
Перший варіант – це вказати Kubernetes Scheduler, що ми хочемо поді Read розташовувати на тій самій WorkerNode, де є поди з Backend. Для цього можемо використати podAffinity.
Перевірямо лейбли Backend:
[simterm]
$ kk -n dev-monitoring-ns get pod loki-backend-0 --show-labels
NAME READY STATUS RESTARTS AGE LABELS
loki-backend-0 1/1 Running 0 23h app.kubernetes.io/component=backend,app.kubernetes.io/instance=atlas-victoriametrics,app.kubernetes.io/name=loki,app.kubernetes.io/part-of=memberlist,controller-revision-hash=loki-backend-8554f5f9f4,statefulset.kubernetes.io/pod-name=loki-backend-0
[/simterm]
Тож для Reader можемо задати podAntiAffinity з labelSelector=app.kubernetes.io/component=backend – тоді Reader буде “тягнутись” до тії ж AvailabilityZone, де запущено Backend.
Інший варіант – через nodeAffinity, і в Expressions для обох Read та Backend вказати лейблу з бажаною AvailabilityZone.
Спробуємо з preferredDuringSchedulingIgnoredDuringExecution, тобто “soft limit”:
$ kk -n dev-monitoring-ns get pod -l app.kubernetes.io/component=read -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-read-d699d885c-cztj7 1/1 Running 0 50s 10.0.2.181 ip-10-0-2-220.ec2.internal <none> <none>
loki-read-d699d885c-h9hpq 0/1 Running 0 20s 10.0.2.212 ip-10-0-2-173.ec2.internal <none> <none>
[/simterm]
Та зони інстансів:
[simterm]
$ kk get node ip-10-0-2-220.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
$ kk get node ip-10-0-2-173.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
[/simterm]
Окей, тут все є, а що там Backend?
[simterm]
$ kk get nod-n dev-monitoring-ns get pod -l app.kubernetes.io/component=backend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-backend-0 1/1 Running 0 75s 10.0.3.254 ip-10-0-3-53.ec2.internal <none> <none>
Деплоїмо ще раз, і тепер под з Бекендом застряг у статусі Pending:
[simterm]
$ kk -n dev-monitoring-ns get pod -l app.kubernetes.io/component=backend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-backend-0 0/1 Pending 0 3m39s <none> <none> <none> <none>
[/simterm]
Чому? Дивимось Events:
[simterm]
$ kk -n dev-monitoring-ns describe pod loki-backend-0
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 34s default-scheduler 0/3 nodes are available: 1 node(s) didn't match Pod's node affinity/selector, 2 node(s) had volume node affinity conflict. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling..
[/simterm]
Спешу подумав, що на WokrerkNdoes вже маємо максимум подів – 17 штук на t3.medium.
Тоді що – EBS? Часта проблема, коли EBS в одній AvailabilityZone, а Pod запускається в іншій.
Знаходимо Volume Бекенду – там йому підключаються алерт-рули для Ruler:
[simterm]
...
Volumes:
...
data:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: data-loki-backend-0
ReadOnly: false
...
[/simterm]
Знаходимо відповідний Persistent Volume:
[simterm]
$ kubectl k -n dev-monitoring-ns get pvc data-loki-backend-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-loki-backend-0 Bound pvc-b62bee0b-995e-486b-9f97-f2508f07a591 10Gi RWO gp2 15d
[/simterm]
І AvailabilityZone цього EBS:
[simterm]
$ kk -n dev-monitoring-ns get pv pvc-b62bee0b-995e-486b-9f97-f2508f07a591 -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1b
[/simterm]
Так і є – диск у нас в зоні us-east-1b, а под намагаємось запустити под в зоні us-east-1a.
Що можемо зробити – це або Readers запускати в зоні 1b, або видалити PVC для Backend, і тоді при деплої він створить новий PV та EBS в зоні 1a.
Так як в волюмі ніяк даних нема і для Ruler правила створються з ConfigMap, то простіше просто видалити PVC:
$ kk -n dev-monitoring-ns delete pod loki-backend-0
pod "loki-backend-0" deleted
[/simterm]
Перевіряємо, що PVC створений:
[simterm]
$ kk -n dev-monitoring-ns get pvc data-loki-backend-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-loki-backend-0 Bound pvc-5b690c18-ba63-44fd-9626-8221e1750c98 10Gi RWO gp2 14s
[/simterm]
І його локація тепер:
[simterm]
$ kk -n dek -n dev-monitoring-ns get pv pvc-5b690c18-ba63-44fd-9626-8221e1750c98 -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
[/simterm]
І сам под теж запустився:
[simterm]
$ kk -n dev-monitoring-ns get pod loki-backend-0
NAME READY STATUS RESTARTS AGE
loki-backend-0 1/1 Running 0 2m11s
[/simterm]
Результати трафіку
Робив це в п’ятницю, і на понеділок маємо результат:
Все вийшло, як і планувалось – Cross AvailabilityZone трафік тепер майже на нулі.
Оновлював вчора Arch Linux, і за 9 років корисування ціюєю системою вперше зіткнувся с помилкою, коли після ребуту система не змогла підключити диск:
ERROR: device UUID not found.
mount: /new_root: can’t find UUID.
ERROR: Failed to mount UUID on real root.
You are now being dropped into an emergency shell.
В принципі проблема ясна – або змінився UUID диска, або “щось пішло не так” з ядром.
Трапилось це через те, що під час апргейду в /tmp закінчилось місце, і mkinitcpio не зміг зібрати нове ядро.
Завантажуємость с USB, і будемо пробувати фіксити.
Першим перевіряємо, чи правильний UUID вказано в fstab.
Перевіряємо розділи:
[simterm]
[root@archiso ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 693.5M 1 loop /run/archiso/airootfs
sda 8:0 1 14.3G 0 disk
├─sda1 8:1 1 798M 0 part
└─sda2 8:2 1 15M 0 part
nvme0n1 259:0 0 953.9G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part
├─nvme0n1p2 259:2 0 900G 0 part
└─nvme0n1p3 259:3 0 53.4G 0 part
[/simterm]
/dev/nvme0n1p2 – мій рутовий роздил.
Підключаємо його:
[simterm]
[root@archiso ~]# mount /dev/nvme0n1p2 /mnt/
[/simterm]
Перевіряємо UUID в /etc/fstab старої системи:
[simterm]
[root@archiso ~]# cat /mnt/etc/fstab
# Static information about the filesystems.
# See fstab(5) for details.
# <file system> <dir> <type> <options> <dump> <pass>
# /dev/nvme0n1p2
UUID=31268b66-5fca-44f6-8e22-acc281026eaf / ext4 rw,relatime 0 1
Зараз маємо VictoriaMetrics + Grafana на звичайному EC2-інстансі, запущені з Docker Compose – то був Proof of Concept, прийшов час запускати “по-дорослому” – в Kubernetes, і всі конфіги вже винести в GitHub.
Використовувати будемо саме victoria-metrics-k8s-stack, який “під капотом” запустить VictoriaMetrics Operator, Grafana та kube-state-metrics, див. dependencies.
Матеріал вийшов досить великий, але наче описав всі цікаві моменти по розгортанню повноцінного стеку моніторингу з VictoriaMetrics Kubernetes Monitoring Stack.
UPD: робив документацію по нашому моніторингу, вийшла ось така схема того, про що буде в цьому пості:
подивитись і подумати, як запускати існуючі експортери – частина мають чарти, але ми маємо і самописні (див. – Prometheus: GitHub Exporter – пишемо власний експортер для GitHub API), тож їх треба буде пушити в Elastic Container Service і думати, як звідти пулити і запускати в Kubernetes
секрети для моніторингу – паролі Grafana і все таке інше
IRSA для експортерів – створити IAM Policy та ролі для ServiceAccounts
перенесення алертів
конфіг для VMAgent – збір метрик с експортерів
запустити Grafana Loki
Стосовно логів – так, нещодавно вийшла VictoriaLogs, але вона ще в preview, не має підтримки збегірання в AWS S3, не має інтеграції з Grafana, та й взагалі поки не хочеться витрачати зайвий час, а Loki я вже більш-менш знаю. Можливо, запущу VictoriaLogs окремо, “погратись-подивитись”, а коли її вже інтегрують з Grafana – то заміню Loki на VictoriaLogs, бо зараз ми вже маємо дашборди з графіками з логів Loki.
Ще окремо треба буде глянути як там з persistance у VictoriaMetrics в Kubernetes – розмір, типи дисків і так далі. Можливо, подумати про їхні бекапи (VMBackup?).
На існуючому моніторингу маємо досить багато всього:
Яке взагалі деплоїти? Через AWS CDK та його cluster.add_helm_chart() – чи робити окремий степ в GitHub Actions з Helm?
Нам в будь-якому разі буде потрібен CDK – створити сертифікати з ACM, Lambda для логів в Loki, S3-корзини, IAM-ролі для експортерів тощо.
Але чомусь зовсім не хочеться тягнути в CDK деплой чартів, бо краще всеж відокремити деплой інфрастуктурних об’єктів від деплою самого стеку моніторинга.
Добре – зробимо окремо: CDK буде створювати ресурси в AWS, Helm буде деплоїти чарти. Чи чарт? Може – просто зробити власний чарт, а йому вже сабчартами підключити і VictoriaMetrics Stack, и експортери? Виглядає наче непоганою ідею. “Мінуси будуть?” (с)
Також нам треба буде створити Kubernetes Secrets та ConfigMaps з конфігами для VMAgent, Loki (див. Loki: збір логів з CloudWatch Logs з використанням Lambda Promtail), Alertmanager тощо. Робити їх з Kustomize? Чи просто YAML-маніфестами в директорії templates нашого чарту?
Подивимось. Поки думаю, що таки Kustomize.
Тепер по порядку – що треба буде зробити:
запустити експортери
підключити конфіг до VMAgent, щоб почати збирати метрики з експортерів
перевірити, як налаштовуються ServiceMonitors (VMServiceScrape у VictoriaMetrics)
$ helm repo add grafana https://grafana.github.io/helm-charts
"grafana" has been added to your repositories
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
[/simterm]
І саму VictoriaMetrics:
[simterm]
$ helm repo add vm https://victoriametrics.github.io/helm-charts/
"vm" has been added to your repositories
$ helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "vm" chart repository
...Successfully got an update from the "grafana" chart repository
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
[/simterm]
Перевіряємо версії чарту victoria-metrics-k8s-stack:
[simterm]
$ helm search repo vm/victoria-metrics-k8s-stack -l
NAME CHART VERSION APP VERSION DESCRIPTION
vm/victoria-metrics-k8s-stack 0.17.0 v1.91.3 Kubernetes monitoring on VictoriaMetrics stack....
vm/victoria-metrics-k8s-stack 0.16.4 v1.91.3 Kubernetes monitoring on VictoriaMetrics stack....
vm/victoria-metrics-k8s-stack 0.16.3 v1.91.2 Kubernetes monitoring on VictoriaMetrics stack....
...
[/simterm]
Всі values можна взяти так:
[simterm]
$ helm show values vm/victoria-metrics-k8s-stack > default-values.yaml
$ kk -n dev-monitoring-ns get pod
NAME READY STATUS RESTARTS AGE
victoria-metrics-k8s-stack-grafana-76867f56c4-6zth2 0/3 Init:0/1 0 5s
victoria-metrics-k8s-stack-kube-state-metrics-79468c76cb-75kgp 0/1 Running 0 5s
victoria-metrics-k8s-stack-prometheus-node-exporter-89ltc 1/1 Running 0 5s
victoria-metrics-k8s-stack-victoria-metrics-operator-695bdxmcwn 0/1 ContainerCreating 0 5s
vmsingle-victoria-metrics-k8s-stack-f7794d779-79d94 0/1 Pending 0 0s
[/simterm]
Та Ingress:
[simterm]
$ kk -n dev-monitoring-ns get ing
NAME CLASS HOSTS ADDRESS PORTS AGE
victoria-metrics-k8s-stack-grafana <none> monitoring.dev.example.co k8s-devmonit-victoria-***-***.us-east-1.elb.amazonaws.com 80 6m10s
[/simterm]
Чекаємо оновлення DNS, або просто відкриваємо доступ до Grafana Service – знаходимо його:
[simterm]
$ kk -n dev-monitoring-ns get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
victoria-metrics-k8s-stack-grafana ClusterIP 172.20.162.193 <none> 80/TCP 12m
...
[/simterm]
І виконуємо port-forward:
[simterm]
$ kk -n dev-monitoring-ns port-forward svc/victoria-metrics-k8s-stack-grafana 8080:80
Forwarding from 127.0.0.1:8080 -> 3000
Forwarding from [::1]:8080 -> 3000
[/simterm]
В браузері переходимо до http://localhost:8080/
Username по дефолту admin, отримуємо його згенерований пароль:
Отже, зробимо такий собі “umbrella chart“, який буде запускати і сам стек VictoriaMetrics, і експортери, і створювати всі необхідні Secrets/ConfgiMaps тощо.
Як воно буде працювати?
створимо чарт
йому в dependencies вписуємо VictoriaMetrics
через тіж dependencies додамо запуск екпортерів
в каталозі templates опишемо наші кастомні ресурси (ConfigMaps, VMRules, etc)
Потім всі загальні параметри винесемо в якійсь common-values.yaml, а значення, которі будуть різні для Dev/Prod – по окремим файлам.
Оновлюємо наш values – додаємо блок victoria-metrics-k8s-stack, бо він у нас тепер буде сабчартом:
victoria-metrics-k8s-stack:
# no need yet
victoria-metrics-operator:
serviceAccount:
create: true
# to confugire later
alertmanager:
enabled: true
# to confugire later
vmalert:
annotations: {}
enabled: true
# to confugire later
vmagent:
enabled: true
grafana:
enabled: true
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/scheme: internet-facing
hosts:
- monitoring.dev.example.co
Загружаємо чарти з dependencies:
[simterm]
$ helm dependency update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "vm" chart repository
...Successfully got an update from the "grafana" chart repository
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
Saving 1 charts
Downloading victoria-metrics-k8s-stack from repo https://victoriametrics.github.io/helm-charts/
Deleting outdated charts
[/simterm]
Перевіряємо каталог charts:
[simterm]
$ ls -1 charts/
victoria-metrics-k8s-stack-0.17.0.tgz
[/simterm]
І робимо helm template нового Helm-чарту з нашим VictoriaMetrics Stack, щоб перевірити, що сам чарт, його dependencies і values працюють:
Service Invalid value: must be no more than 63 characters
Деплоїмо новий:
[simterm]
$ helm -n dev-monitoring-ns upgrade --install atlas-victoriametrics . -f values/dev/atlas-monitoring-dev-values.yaml
Release "atlas-victoriametrics" does not exist. Installing it now.
Error: 10 errors occurred:
* Service "atlas-victoriametrics-victoria-metrics-k8s-stack-kube-controlle" is invalid: metadata.labels: Invalid value: "atlas-victoriametrics-victoria-metrics-k8s-stack-kube-controller-manager": must be no more than 63 characters
$ helm -n dev-monitoring-ns upgrade --install atlas-victoriametrics . -f values/dev/atlas-monitoring-dev-values.yaml
Release "atlas-victoriametrics" has been upgraded. Happy Helming!
...
[/simterm]
Перевіряємо ресурси:
[simterm]
$ kk -n dev-monitoring-ns get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/atlas-victoriametrics-grafana ClusterIP 172.20.93.0 <none> 80/TCP 0s
service/atlas-victoriametrics-kube-state-metrics ClusterIP 172.20.113.37 <none> 8080/TCP 0s
...
Тепер нам треба налаштувати VMAgent, щоб він почав збирати ці метрики з цього експортеру.
Збір метрик з експортерів: VMAgent && scrape_configs
Звична з Kube Prometheus Stack схема – це просто включити servicemonitor.enabled=true в вальюсах чарту експотера, і Prometheus Operator створить ServiceMonitor та почне збирати метрики.
Натомість у VictoriaMetrics є власний аналог – VMServiceScrape, який можна створити з маніфесту, і йому вказати з якого ендпоінту збирати метрики. До того ж, VictoriaMetrics вміє створювати VMServiceScrape з існуючих ServiceMonitor, але це потребує установки самого ServiceMonitor CRD.
Також ми можемо передати список таргетів через inlineScrapeConfig або additionalScrapeConfigs, див. VMAgentSpec.
Скоріш за все, у нас поки що буде inlineScrapeConfig, бо конфіг не надто великий.
Ще цікаво взагалі глянути VMAgent values.yaml – наприклад, там є дефолтні scrape_configs.
Ще один нюанс, которий треба мати на увазі – VMAgent не перевіряє конфіги таргетів, тобто якщо є помилка в YAML – то VMAgent просто ігнорує зміни, і не перезавантажує файл, при цьому в лог нічого не пише.
VMServiceScrape
Спочатку створимо VMServiceScrape вручну, щоб подивитись як воно взагалі працює.
$ kubectl apply -f vmsvcscrape.yaml
vmservicescrape.operator.victoriametrics.com/prometheus-cloudwatch-exporter-vm-scrape created
[/simterm]
Перевіряємо всі vmservicescrape – тут вже є пачка дефолтних, які створив сам VictoriaMetrics Operator:
[simterm]
$ kk -n dev-monitoring-ns get vmservicescrape
NAME AGE
prometheus-cloudwatch-exporter-vm-scrape 6m45s
vm-k8s-stack-apiserver 4d22h
vm-k8s-stack-coredns 4d22h
vm-k8s-stack-grafana 4d22h
vm-k8s-stack-kube-controller-manager 4d22h
...
[/simterm]
Конфіг VMAgent створюється в поді у файл /etc/vmagent/config_out/vmagent.env.yaml.
І тепер маємо побачити метрики в самій VictoriaMetrics.
Відкриваємо порт:
[simterm]
$ kk -n dev-monitoring-ns port-forward svc/vmsingle-vm-k8s-stack 8429
[/simterm]
В браузері заходимо на http://localhost:8429/vmui/ і для перевірки робимо запит на будь-яку метрику від CloudWatch Exporter:
Добре – побачили, як вручну створити VMServiceScrape. Але що там з автоматизацією цього процесу? Бо якось не дуже хочеться через Kustomize свторювати VMServiceScrape для кожного сервісу.
VMServiceScrape з ServiceMonitor та VictoriaMetrics Prometheus Converter
Тож як вже писалось, для того, щоб в кластері створився об’єкт ServiceMonitor нам потрібен Custom Resource Definition з ServiceMonitor.
Можемо встановити його прямо з маніфесту в репозиторії kube-prometheus-stack:
[simterm]
$ kubectl apply -fhttps://raw.githubusercontent.com/prometheus-community/helm-charts/main/charts/kube-prometheus-stack/charts/crds/crds/crd-servicemonitors.yaml
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
[/simterm]
Оновлюмо наш values – додаємо serviceMonitorenabled=true:
І у вальюсах victoria-metrics-k8s-stack додаємо параметр operator.disable_prometheus_converter=false:
victoria-metrics-k8s-stack:
fullnameOverride: "vm-k8s-stack"
# no need yet
victoria-metrics-operator:
serviceAccount:
create: true
operator:
disable_prometheus_converter: false
...
Деплоїмо та перевіряємо, чи створено servicemonitor:
[simterm]
$ kk -n dev-monitoring-ns get servicemonitors
NAME AGE
atlas-victoriametrics-prometheus-cloudwatch-exporter 2m22s
[/simterm]
І автоматом мав з’явитись vmservicescrape:
[simterm]
$ kk -n dev-monitoring-ns get vmservicescrape
NAME AGE
atlas-victoriametrics-prometheus-cloudwatch-exporter 2m11s
...
[/simterm]
Глянемо targets:
Все є.
Єдиний тут нюанс в тому, что при видалені ServiceMonitor – відповідний vmservicescrape залишиться. Плюс сама необхідність в становленні стороннього CRD, який з часом треба буде якось оновлювати, бажано автоматично.
inlineScrapeConfig
Найбільш мабуть простий варіант – це описати конфіг через inlineScrapeConfig прямо в values нашого чарту:
Більш безпечний варіант, якщо в параметрах є якісь токени/ключі доступу, але потребує створення окремого об’єкту Kubernetes Secret.
В принципі не проблема, бо ConfigMaps/Secrets все одно доведеться створювати, і якщо захочется винести конфіг таргетів окремим файлом – то, скоріш за все, перероблю на additionalScrapeConfigs.
Зараз створимо вручну, просто глянути як воно буде працювати – беремо приклад прямо з документації:
Якщо з дашбордами все більш-менш просто, то з Data Sources є питання: як в них передавати якісь секрети? Наприклад – для датасорсу Sentry треба задати токен, який в вальюсах чарту світити зовсім не хочеться, бо дані в GitHub ми не шифруємо, хоч репозиторії і приватні (див. git-crypt – на минулому проекті був, в приципі робоче рішення).
Давайте спершу поглянемо як воно працює взагалі, потім подумаємо, як нам передати токен.
Будемо додавати Senrty Data Source, див. grafana-sentry-datasource. Токен вже маємо – створено в sentry.io > User settings > User Auth Tokens.
В вальюси Grafana додаємо plugins, де вказуємо ім’я плагіну grafana-sentry-datasource (значення поля type в документації вище) і описуємо блок additionalDataSources з полем secureJsonData, в якому вказуємо сам токен:
при деплої AWS CDK взяти значення у змінну через os.env("SECRET_NAME_VAR") і створити секрет в AWS Secrets Manager
в templates нашого чарту створити SecretProviderClass з полем secretObjects.secretName для створення Kubernetes Secret
При запуску поду з Grafana вона цей секрет підключить до поду:
[simterm]
$ kk -n dev-monitoring-ns get pod atlas-victoriametrics-grafana-64d9db677-dlqfr -o yaml
...
envFrom:
- secretRef:
name: grafana-datasource-sentry-token
...
[/simterm]
І передасть значення до самої Grafana.
Окей, це може працювати, хоча виглядає трохи заплутано.
Але є ще один варіант – з sidecar.datasources.
Kubernetes Secret для всього Data Source і sidecar.datasources
Є другий варіант – створювати дата-сорси через sidecar container: можемо створити Kubernetes Secret з потрібною labels, і в цьому сікреті додати датасорс. Див. Sidecar for datasources
В принципі – цілком робоча схема: створити маніфест секрету в каталозі templates, і при виклику helm install в GitHub Actions передати значення з --set, а значення взяти з GitHub Actions Secrets. І виглядає простішою. Спробуємо.
У файлу templates/grafana-datasources-secret.yaml описуємо Kubernetes Secret:
Для створення дашборд через Helm-чарт маємо аналогічний до grafana-sc-datasources сайдкар-контейнер grafana-sc-dashboard, який буде перевіряти всі ConfigMaps з лейблою, і підключати їх до поду. Див. Sidecar for dashboards.
Майте на увазі рекомендацію:
A recommendation is to use one configmap per dashboard, as a reduction of multiple dashboards inside one configmap is currently not properly mirrored in grafana.
Тобто – один ConfigMap на кожну дашборду.
Тож що нам треба зробити – це описати ConfigMap для кожної дашборди, і Grafana сама додасть їх до /tmp/dashboards.
Експорт існуючої dashboard та Data Source UID not found
Щоб уникнути помилки з UID (“Failed to retrieve datasource Datasource f0f2c234-f0e6-4b6c-8ed1-01813daa84c9 was not found”) – йдемо до дашборди в існуючому інстансі Grafana, і додаємо нову змінну з типом Data Source:
Повторюємо для Loki, Sentry:
Та оновлюємо панелі – задаємо датасорс зі змінної:
Повторюємо теж саме для всіх запитів у Annotations та Variables:
Створюємо каталог для файлів, які потім будемо імпортити в Kubernetes:
[simterm]
$ mkdir -p grafana/dashboards/
[/simterm]
Та робимо Export дашборди в JSON і зберігаємо як grafana/dashboards/overview.json:
Dashboard ConfigMap
В каталозі templates створюємо маніфест для ConfigMap:
І маємо наши графіки – поки не всі, бо запущено тільки один експортер:
Поїхали далі.
Що нам залишилось?
GitHub exporter – зробити чарт, додати до загального чарту (чи просто створити маніфест з Deployment? там один под, нічного більше йому не треба)
Loki
алерти
GitHub exporter мабуть таки просто з Deployment зроблю – маніфест у templates основного чарту, та й все – окремий чарт там не потрібен. Тут описувати не буду, бо це просто.
Запустимо в кластері Promtail, щоб по-перше перевірити роботу Loki, по-друге – всеж мати логи з кластеру.
Знаходимо версії чарта:
[simterm]
$ helm search repo grafana/promtail -l | head
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/promtail 6.11.7 2.8.2 Promtail is an agent which ships the contents o...
grafana/promtail 6.11.6 2.8.2 Promtail is an agent which ships the contents o...
grafana/promtail 6.11.5 2.8.2 Promtail is an agent which ships the contents o...
...
[/simterm]
Додаємо сабчарт в dependencies в нашому Chart.yaml:
Тут знову ж таки треба буде подумати про секрет, бо в slack_api_url маємо токен. Мабуть, зробимо як з Sentry-токеном – просто будемо передавати через --set.
VMAlert використовуює VMRules, які вибирає за ruleSelector:
[simterm]
$ kk -n dev-monitoring-ns get vmrule
NAME AGE
vm-k8s-stack-alertmanager.rules 6d19h
vm-k8s-stack-etcd 6d19h
vm-k8s-stack-general.rules 6d19h
vm-k8s-stack-k8s.rules 6d19h
...
[/simterm]
Тобто – можемо описати в маніфестах потрібні рули, задеплоїти – і VMAlert їх підхопить.
Глянемо сам VMAlert – він у нас зараз один, і в принципі нам цього поки вистачить:
Зберігання даних доступу у Kubernetes Secrets має важливий недолік, бо вони доступні тільки всередені самого Kubernetes кластеру.
Щоб зробити їх доступними зовнішнім сервісам – можемо використати Hashicorp Vault і інтегрувати його з Kubernetes за допомогою таких рішень, як vault-k8s, або скористуватись сервісами від AWS – Secrets Manager або Parameter Store.
Інтеграція AWS Secrets Manager та Parameter Store в Kubernetes дасть нам можливість створювати новий тип ресурсів – SecretProviderClass, який ми зможемо підключати до Kubernetes Pods у вигляді файлів або змінних оточення.
AWS Secrets and Configuration Provider vs Hashicorp Vault
Я давно не користувався Vault, але щодо питання “Що використовувати” – то тут вибір між “сетапити, конфігурити та менеджити Hashicorp Vault самому” (встановлення Helm-чарту та конфігурація доступів) або “використати готове рішення від AWS” (по суті, потрібно тільки налаштувати IAM-ролі).
Також враховуйте, що використання AWS сервісів (suprize!) платне, тож якщо ви плануєте мати тисячі секретів – то мабуть краще таки з Vault.
Крім того, Vault сам по собі дає набагато більше можливостей, наприклад – генерація тимчасових токенів для сервісів, плюс наскільки пам’ятаю – Kubernetes Pods можуть отримувати параметри з Vault без необхідності в створенні Kubernetes Secrets, тоді як при використанні AWS Secrets and Configuration Provider (ASCP) та Kubernetes Secrets Store CSI Driver для підключення змінних будуть створюватиcm звичайні Kubernetes Secrets.
Втім, на нашому проекті вже використовуються Secrets Manager та Parameter Store, сенсу в Vault поки не бачу, тож інтегруємо наші секрети до кластеру в AWS Elastic Kubernetes Service.
обидва використовують AWS KMS для шифрування даних
обидва являють собою Key/Value Store
обидва підтримують versioning
Різниця:
вартість:
Secrets Manager: бере $0.40 за кожен секрет та $0.05 за кожні 10,000 API запросів
Parameter Store: за Standard не бере грошей за зберігання, при higher throughput – коштує $0.05 за кожні 10,000 API запросів, при Advanced parameters – $0.05 за зберігання та $0.05 за кожні 10,000 API запросів
ротація секретів:
Secrets Manager: має вбудований механізм ротації та інтегрує його з сервісами (RDS, DocumentDB, etc)
Parameter Store: маєте імплементувати ротацію самостійно
Cross-account Access:
Secrets Manager: підтримує
Parameter Store: не підтримує
Cross-Regions Replication:
Secrets Manager: підтримує
Parameter Store: не підтримує
розмір даних:
Secrets Manager: до 10KB на кожен секрет
Parameter Store: 4KB на кожен запис (8KB при Advanced Parameters)
ліміти кількості:
Secrets Manager: 500,000 на регіон та акаунт
Parameter Store: 10,000 на регіон та акаунт
Встановлення Secrets Store CSI Driver
Отже, для інтеграції нам потрібні два сервіси – Secrets Store CSI Driver та AWS Secrets and Configuration Provider.
Першим додаємо Secrets Store CSI Driver.
За його допомогою зможемо підключати секрети/параметри з AWS файлами або змінними до Kubernetes Pods.
Додаємо Helm-чарт і встановлюємо з опцією syncSecret.enabled=true для створення RBAC-ролей для роботи з Kubernetes Secrets та їх синхронізації з секретами AWS під час ротації даних (див. Sync as Kubernetes Secret):
Щоб Kubernetes Pod зміг отримати доступ до AWS SecretManager та Parameter Store використаємо IRSA – створимо ServiceAacount, який буде використовувати IAM Role з IAM Policy, яка буде мати дозволи на виклик Secrets Manager та Parameter Store (див. AWS: EKS, OpenID Connect та ServiceAccounts).
Далі описуємо сам SecretProviderClass з двома objects – в parameters.objects.objectName – ім’я об’єкту в Secrets Manager або Parameter Store, а в objectType вказуємо звідки беремо цей об’єкт:
$ kubectl apply -f ascp-test.yaml
serviceaccount/ascp-test-serviceaccount created
secretproviderclass.secrets-store.csi.x-k8s.io/aspc-test-secret-class created
pod/ascp-test-pod created
[/simterm]
Перевіряємо под:
[simterm]
$ kk describe pod ascp-test-pod
...
Mounts:
/mnt/ascp-secret from ascp-test-secret-volume (ro)
...
Volumes:
...
ascp-test-secret-volume:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: secrets-store.csi.k8s.io
FSType:
ReadOnly: true
VolumeAttributes: secretProviderClass=aspc-test-secret-class
...
[/simterm]
Та зміст каталогу /mnt/ascp-secret:
[simterm]
$ kk exec -ti ascp-test-pod -- ls -l /mnt/ascp-secret
total 8
-rw-r--r-- 1 root root 10 Jul 17 09:32 ascp-secret-test-string
-rw-r--r-- 1 root root 9 Jul 17 09:32 ascp-ssm-test-param
[/simterm]
І зміст файлів:
[simterm]
$ kk exec -ti ascp-test-pod -- cat /mnt/ascp-secret/ascp-secret-test-string
secretLine
$ kk exec -ti ascp-test-pod -- cat /mnt/ascp-secret/ascp-ssm-test-param
paramLine
[/simterm]
Підключення SecretProviderClass в Pod змінною оточення
Підключення файлами може бути непоганим рішенням для якихось .env файлів, але як щодо звичайних змінних? Наприклад – передати пароль для DB_PASSWORD.
Для цього до SecretProviderClass додаємо secretObjects – тоді Kubernetes Secrets Store CSI Driver створить звичайний Kubernetes Secret, котрий зможемо підключити в под :
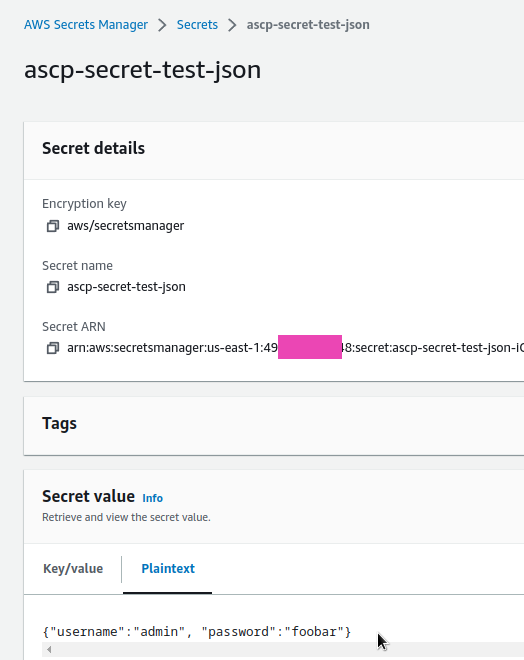
в parameters.objects.objectName: "ascp-secret-test-json" викликаємо jmesPath, який парсить наш секрет і отримує значення довх полів – username та password, для яких створює два objectAlias – ascp-test-username та ascp-test-password
в secretObjects.secretName: aspc-test-kube-secret-json додаємо data з двома objectName, в яких використуємо objectAlias з parameters
Обновлюємо наш Kubernetes Pod – додаємо два secretKeyRef з ключами kube-secret-user та kube-secret-user з секрету aspc-test-kube-secret-json:
Продовжимо про AWS CDK та Python. Пишу не тому, що подобається, а тому, що в інтернеті прикладів ну якось зовсім мало, тож нехай будуть хоча б тут.
Отже, маємо кластер, маємо пару контролерів. Наче все готово – почав встановлювати чарт VictoriaMetrics, і все завелося окрім поду з VMSingle, який завис в статусі Pending.
“VolumeBinding”: binding volumes: timed out waiting for the condition
Перевіряємо Events цього поду:
[simterm]
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 10m default-scheduler running PreBind plugin "VolumeBinding": binding volumes: timed out waiting for the condition
Тож сьогодні глянемо, як з AWS CDK додати аддони до кластеру.
Тут, в принципі, все досить просто, єдине що довелося погуглити як жеж саме використовувати CfnAddon, але цього разу документація знайшлась швидко, і навіть з прикладами на Python, а не TypeScript.
Для драйверу теж використовуємо IRSA – описуємо ServiceAccount, політику беремо вже готову – AWS Managed Policy, підключаємо через виклик iam.ManagedPolicy.from_aws_managed_policy_name():
...
# Create an IAM Role to be assumed by ExternalDNS
ebs_csi_addon_role = iam.Role(
self,
'EbsCsiAddonRole',
# for Role's Trust relationships
assumed_by=iam.FederatedPrincipal(
federated=oidc_provider_arn,
conditions={
'StringEquals': {
f'{oidc_provider_url.replace("https://", "")}:sub': 'system:serviceaccount:kube-system:ebs-csi-controller-sa'
}
},
assume_role_action='sts:AssumeRoleWithWebIdentity'
)
)
ebs_csi_addon_role.add_managed_policy(iam.ManagedPolicy.from_aws_managed_policy_name("service-role/AmazonEBSCSIDriverPolicy"))
...
У from_aws_managed_policy_name вказуємо ім’я як “service-role/ManagedPolicyName“.
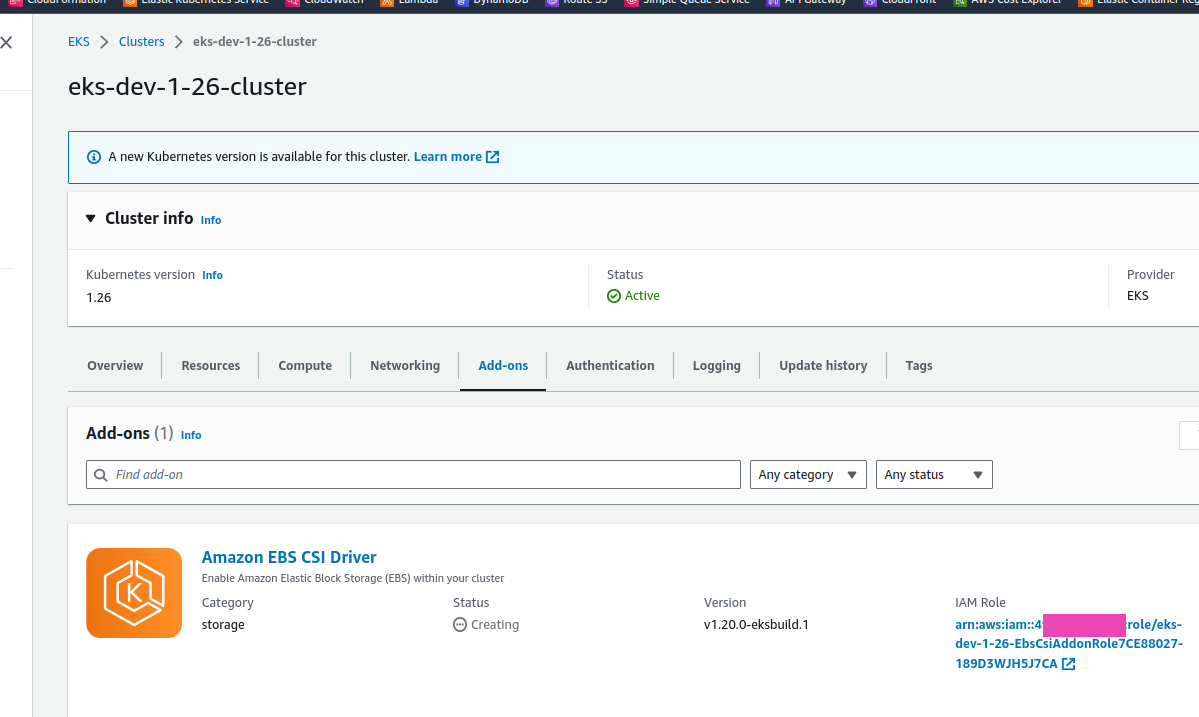
CfnAddon для EBS CSI driver
Знаходимо актувальну версію дайверу, вказавши версію кластеру – у нас 1.26, бо CDK досі не підтримує 1.27:
$ kk -n kube-system get pod | grep csi
ebs-csi-controller-896d87c6b-7rv9z 6/6 Running 0 9m59s
ebs-csi-controller-896d87c6b-v7xg7 6/6 Running 0 9m59s
ebs-csi-node-2zwnr 3/3 Running 0 9m59s
ebs-csi-node-pt5zs 3/3 Running 0 9m59s
[/simterm]
І тепер маємо PVC для VictoriaMetrcis в статусі Bound:
[simterm]
$ kk -n dev-monitoring-ns get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
vmsingle-victoria-metrics-k8s-stack Bound pvc-151a631b-f6de-4567-8baa-97adb4e04a87 20Gi RWO gp2 91m
Наступним кроком після розгортання самого кластеру треба налаштувати OIDC Identity Provider в AWS IAM, та додати два контролери – ExternalDNS для роботи з Route53, то AWS ALB Controller для створення лоад-балансерів при створенні Ingress.
Для аутентифікації в AWS обидва контролери будуть використовувати модель IRSA – IAM Roles for ServiceAccounts, тобто в Kubernetes Pod з контролером підключаємо ServiceAccount, який дозволить використання IAM-ролі, до якої будуть підключені IAM Policy з необіхідними дозволами.
Пізніше окремо розглянемо питання контролеру для скейлінгу WorkerNodes: раніше я використовував Cluster AutoScaler, але цього разу хочу спробувати Karpenter, тож винесу це окремим постом.
Рішення, описані в цьому пості виглядають місцями дуже не гуд, і, може, є варіанти, як це зробити красивіше, але в мене вийшло так. “At least, it works” ¯\_(ツ)_/¯
“Так історично склалося” (с), що продовжуємо їсти кактус використовувати AWS CDK з Python. Ним будемо створювати і IAM-ресурси, і деплоїти Helm-чарти контролерів прямо з CloudFormation-стеку кластеру.
Я намагався винести деплой контролерів окремим стеком, але витратив годину-півтори намагаючись знайти, як у CDK передати значення з одного стеку в інший через CloudFormation Exports та Outputs, тож вреті-решт забив і зробив все в одному класі стеку.
Далі треба додати створення OIDC в IAM, та деплой Helm-чартів з контролерами.
Налаштування OIDC Provider в AWS IAM
Використовуємо boto3 (це одна з речей, яка в AWS CDK не дуже подобається – що багато чого доводиться робити не методами/конструктами самого CDK, а “костилями” у вигляді boto3 чи інших модулів/бібліотек).
...
from botocore.exceptions import ClientError
...
# Create IAM Identity Privder
iam_client = boto3.client('iam')
# to catch the "(EntityAlreadyExists) when calling the CreateOpenIDConnectProvider operation"
try:
response = iam_client.create_open_id_connect_provider(
Url=oidc_provider_url,
ThumbprintList=[oidc_provider_thumbprint],
ClientIDList=["sts.amazonaws.com"]
)
except ClientError as e:
print(f"\n{e}")
...
Тут все загортаємо у костиль у вигляді try/except, бо при подальших апдейтах стеку boto3.client('iam') натикається на те, що Provider вже є, і падає з помилкою EntityAlreadyExists.
Встановлення ExternalDNS
Першим додамо ExternalDNS – в нього досить проста IAM Policy, тож на ньому протестимо як взагалі CDK працює з Helm-чартами.
IRSA для ExternalDNS
Тут першим кроком нам треба створити IAM Role, яку зможе assume наш ServiceAccount для ExternalDNS, і яка дозволить ExternalDNS виконувати дії з доменною зоною у Route53, бо зараз ExternalDNS має ServiceAccount, але видає помилку:
msg=”records retrieval failed: failed to list hosted zones: WebIdentityErr: failed to retrieve credentials\ncaused by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus code: 403
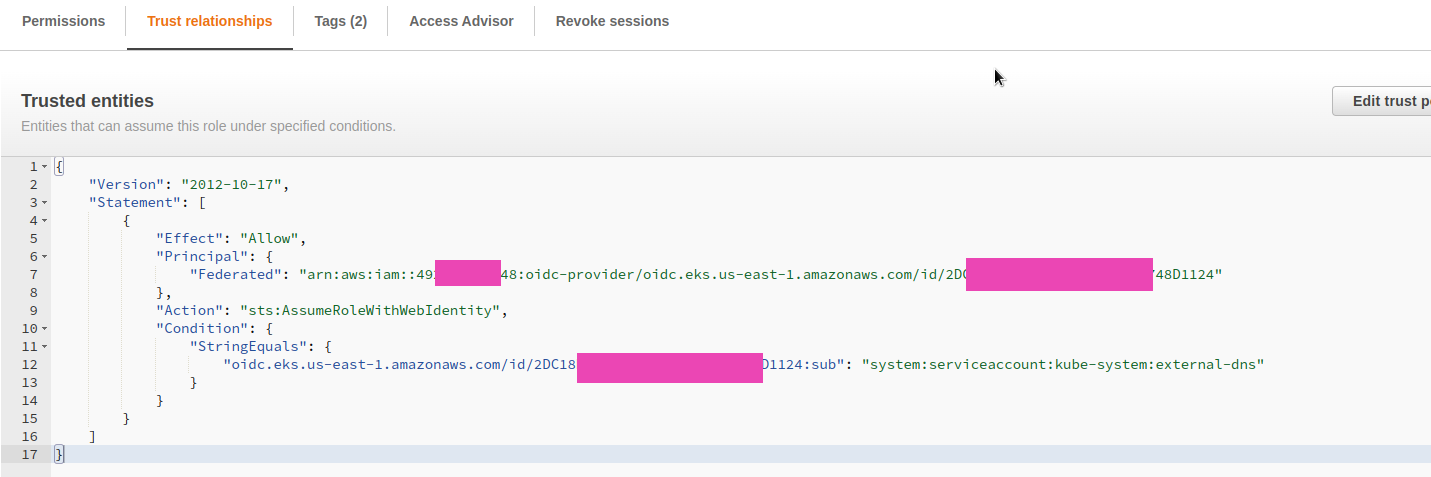
Trust relationships
У Trust relationships цієї ролі маємо вказати Principal у вигляді ARN створенного OIDC Provider, в Action – sts:AssumeRoleWithWebIdentity, а в Condition – якщо запит приходить від ServiceAccount, який буде створений ExternalDNS Helm-чартом.
Створим пару змінних:
...
# arn:aws:iam::492***148:oidc-provider/oidc.eks.us-east-1.amazonaws.com/id/2DC***124
oidc_provider_arn = f'arn:aws:iam::{aws_account}:oidc-provider/{oidc_provider_url.replace("https://", "")}'
# deploy ExternalDNS to a namespace
controllers_namespace = 'kube-system'
...
oidc_provider_arn формуємо зі змінної oidc_provider_url, яку отримали раніше у response = eks_client.describe_cluster(name=cluster_name).
...
# Create an IAM Role to be assumed by ExternalDNS
external_dns_role = iam.Role(
self,
'EksExternalDnsRole',
# for Role's Trust relationships
assumed_by=iam.FederatedPrincipal(
federated=oidc_provider_arn,
conditions={
'StringEquals': {
f'{oidc_provider_url.replace("https://", "")}:sub': f'system:serviceaccount:{controllers_namespace}:external-dns'
}
},
assume_role_action='sts:AssumeRoleWithWebIdentity'
)
)
...
В результаті маємо отримати роль з таким Trust relationships:
Наступний крок – IAM Policy.
IAM Policy для ExternalDSN
Якщо задеплоїти стек зараз, то ExternalDSN почне сваритись на права доступу:
msg=”records retrieval failed: failed to list hosted zones: AccessDenied: User: arn:aws:sts::492***148:assumed-role/eks-dev-1-26-EksExternalDnsRoleB9A571AF-7WM5HPF5CUYM/1689063807720305270 is not authorized to perform: route53:ListHostedZones because no identity-based policy allows the route53:ListHostedZones action\n\tstatus code: 403
Тож описуємо два iam.PolicyStatement() – один для роботи з доменною зоною, другий – для доступу до route53:ListHostedZones.
Робимо їх окремими, бо для route53:ChangeResourceRecordSets у resources хочеться мати обмеження тільки однією конкретною зоною, але для дозволу на route53:ListHostedZones resources має бути у вигляді "*":
...
# A Zone ID to create records in by ExternalDNS
zone_id = "Z04***FJG"
# to be used in domainFilters
zone_name = example.co
# Attach an IAM Policies to that Role so ExternalDNS can perform Route53 actions
external_dns_policy = iam.PolicyStatement(
actions=[
'route53:ChangeResourceRecordSets',
'route53:ListResourceRecordSets'
],
resources=[
f'arn:aws:route53:::hostedzone/{zone_id}',
]
)
list_hosted_zones_policy = iam.PolicyStatement(
actions=[
'route53:ListHostedZones'
],
resources=['*']
)
external_dns_role.add_to_policy(external_dns_policy)
external_dns_role.add_to_policy(list_hosted_zones_policy)
...
...
time="2023-07-11T10:28:28Z" level=info msg="Applying provider record filter for domains: [example.co. .example.co.]"
time="2023-07-11T10:28:28Z" level=info msg="All records are already up to date"
...
[/simterm]
І протестуємо його роботу.
Перевірка роботи ExternalDNS
Для перевірки – створимо простий Service з типом Loadbalancer, в annotations додаємо external-dns.alpha.kubernetes.io/hostname:
...
time="2023-07-11T10:30:29Z" level=info msg="Applying provider record filter for domains: [example.co. .example.co.]"
time="2023-07-11T10:30:29Z" level=info msg="Desired change: CREATE cname-nginx.test.example.co TXT [Id: /hostedzone/Z04***FJG]"
time="2023-07-11T10:30:29Z" level=info msg="Desired change: CREATE nginx.test.example.co A [Id: /hostedzone/Z04***FJG]"
time="2023-07-11T10:30:29Z" level=info msg="Desired change: CREATE nginx.test.example.co TXT [Id: /hostedzone/Z04***FJG]"
time="2023-07-11T10:30:29Z" level=info msg="3 record(s) in zone example.co. [Id: /hostedzone/Z04***FJG] were successfully updated"
...
[/simterm]
Перевіряємо роботу домену:
[simterm]
$ curl -I nginx.test.example.co
HTTP/1.1 200 OK
[/simterm]
“It works!” (c)
Весь код для OIDC та ExternalDNS
Весь код разом зараз виглядає так:
...
############
### OIDC ###
############
eks_client = boto3.client('eks')
# Retrieve the cluster's OIDC provider details
response = eks_client.describe_cluster(name=cluster_name)
# https://oidc.eks.us-east-1.amazonaws.com/id/2DC***124
oidc_provider_url = response['cluster']['identity']['oidc']['issuer']
# AWS EKS OIDC root URL
eks_oidc_url = "oidc.eks.us-east-1.amazonaws.com"
# Retrieve the SSL certificate from the URL
cert = ssl.get_server_certificate((eks_oidc_url, 443))
der_cert = ssl.PEM_cert_to_DER_cert(cert)
# Calculate the thumbprint for the create_open_id_connect_provider()
oidc_provider_thumbprint = hashlib.sha1(der_cert).hexdigest()
# Create IAM Identity Privder
iam_client = boto3.client('iam')
# to catch the "(EntityAlreadyExists) when calling the CreateOpenIDConnectProvider operation"
try:
response = iam_client.create_open_id_connect_provider(
Url=oidc_provider_url,
ThumbprintList=[oidc_provider_thumbprint],
ClientIDList=["sts.amazonaws.com"]
)
except ClientError as e:
print(f"\n{e}")
###################
### Controllers ###
###################
### ExternalDNS ###
# arn:aws:iam::492***148:oidc-provider/oidc.eks.us-east-1.amazonaws.com/id/2DC***124
oidc_provider_arn = f'arn:aws:iam::{aws_account}:oidc-provider/{oidc_provider_url.replace("https://", "")}'
# deploy ExternalDNS to a namespace
controllers_namespace = 'kube-system'
# Create an IAM Role to be assumed by ExternalDNS
external_dns_role = iam.Role(
self,
'EksExternalDnsRole',
# for Role's Trust relationships
assumed_by=iam.FederatedPrincipal(
federated=oidc_provider_arn,
conditions={
'StringEquals': {
f'{oidc_provider_url.replace("https://", "")}:sub': f'system:serviceaccount:{controllers_namespace}:external-dns'
}
},
assume_role_action='sts:AssumeRoleWithWebIdentity'
)
)
# A Zone ID to create records in by ExternalDNS
zone_id = "Z04***FJG"
# to be used in domainFilters
zone_name = "example.co"
# Attach an IAM Policies to that Role so ExternalDNS can perform Route53 actions
external_dns_policy = iam.PolicyStatement(
actions=[
'route53:ChangeResourceRecordSets',
'route53:ListResourceRecordSets'
],
resources=[
f'arn:aws:route53:::hostedzone/{zone_id}',
]
)
list_hosted_zones_policy = iam.PolicyStatement(
actions=[
'route53:ListHostedZones'
],
resources=['*']
)
external_dns_role.add_to_policy(external_dns_policy)
external_dns_role.add_to_policy(list_hosted_zones_policy)
# Install ExternalDNS Helm chart
external_dns_chart = cluster.add_helm_chart('ExternalDNS',
chart='external-dns',
repository='https://charts.bitnami.com/bitnami',
namespace=controllers_namespace,
release='external-dns',
values={
'provider': 'aws',
'aws': {
'region': region
},
'serviceAccount': {
'create': True,
'annotations': {
'eks.amazonaws.com/role-arn': external_dns_role.role_arn
}
},
'domainFilters': [
zone_name
],
'policy': 'upsert-only'
}
)
...
Переходимо до ALB Controller.
Встановлення AWS ALB Controller
Тут, в принципі, все теж саме, єдине, з чим довелось повозитись – це IAM Policy, бо якщо для ExternalDNS маємо тільки два дозволи, і можемо описати їх прямо при створенні цієї Policy, то для ALB Controller політику треба взяти з GitHub, бо вона досить велика.
IAM Policy з GitHub URL
Тут використовуємо requests (знов костилі):
...
import requests
...
alb_controller_version = "v2.5.3"
url = f"https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/{alb_controller_version}/docs/install/iam_policy.json"
response = requests.get(url)
response.raise_for_status() # Check for any download errors
# format as JSON
policy_document = response.json()
document = iam.PolicyDocument.from_json(policy_document)
...
Отримуємо файл політики, формуємо його в JSON, і потм з JSON формуємо вже сам policy document.
IAM Role для ALB Controller
Далі створюємо IAM Role з аналогічними до ExternalDNS Trust relationships, тільки міняємо conditions – вказуємо ServiceAccount, який буде створено для AWS ALB Contoller:
І тепер встановлюємо сам чарт з потрібними values – вказуємо на необхідність створення ServiceAccount, йому в annotations передаємо ARM ролі, яку створили перед цим, та задаємо clusterName:
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
nginx-ingress <none> * internal-k8s-default-nginxing-***-***.us-east-1.elb.amazonaws.com 80 34m
[/simterm]
Єдине тут, що спрацювало не з першого разу – це підключення aws-iam-token: саме тому я в values чарту явно передав 'automountServiceAccountToken': True, хоча в нього і так дефолтне значення true.
Але після декулькох редеплоїв з cdk deploy – токен таки створився і підключився до поду:
Як завжди з CDK – це біль та страждання через відсутність нормальної документації та прикладів, але за допомогою ChatGPT та матюків – воно таки запрацювало.
Ще, мабуть, було б добре створення ресурсів винести хоча б у окремі функції, а не робити все з AtlasEksStack.__init__(), але то може пізніше.
Далі за планом – запуск VictoriaMetrics в Kubernetes, а потім вже потицяємо Karpenter.














 “The Winter is coming!” (c)
“The Winter is coming!” (c)




 Отже, маємо Loki, встановленую з чарту у simple-scale mode, див.
Отже, маємо Loki, встановленую з чарту у simple-scale mode, див.