
На текущем проекте у нас имеется API-бекенд для мобильных приложений на PHP Yii-фреймворке, который работает на стандартном LEMP — Linux/NGINX/PHP-FPM/MySQL.
Пришла пора и нам разбивать этот монолит на микросервисы, для управления которыми будет использоваться Kubernetes (AWS EKS).
В этом и последующих постах серии — знакомство с основными компонентами и архитектурой Kubernetes, ручное создание кластера и работа с AWS EKS.
Ниже достаточно кратко рассматривается общая архитектура, основные компоненты и понятия Kubernetes, а в следующих — перейдём к более практическим примерам, понемногу углубляюсь в детали и расширяя кругозор экосистемы Kubernetes.
В посте добавлено достаточно много ссылок до материалы, но основная проблема при поиске документации/примеров по Kubernetes — это то, что изменения появляются часто и быстро, а потому любые примеры и документация быстро устаревают — имейте это ввиду.
Продолжение:
- Kubernetes: знакомство, часть 2 — создание кластера с AWS cloud-provider и AWS LoadBalancer
- Kubernetes: знакомство, часть 3 — обзор AWS EKS и ручное создание кластера
Содержание
Архитектура — обзор
Общая схема K8s кластера выглядит так:

Или более простая схема:
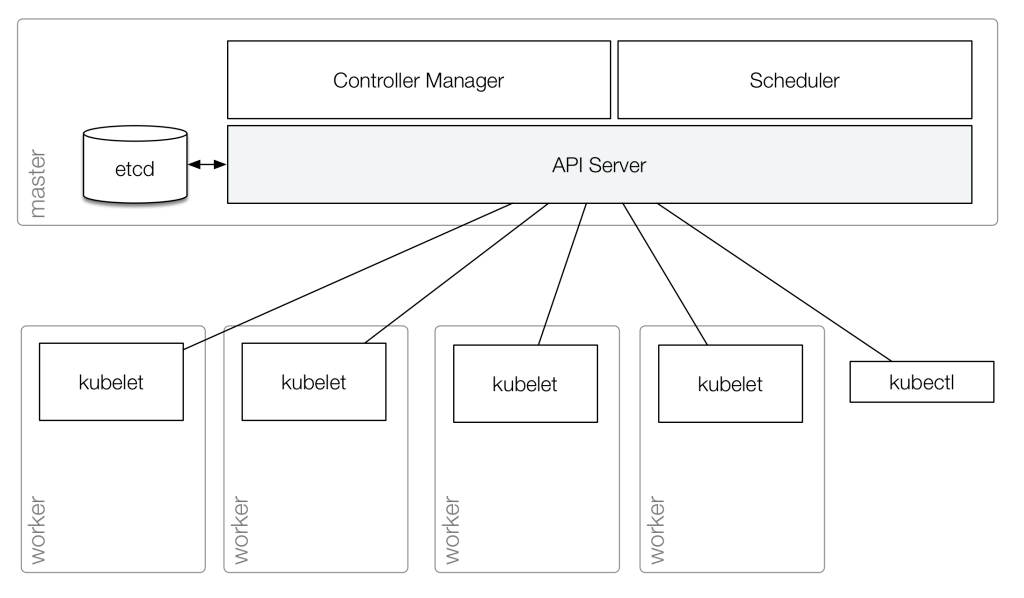
Кластер состоит из одной или более Master Node, и одной или более Worker Node.
Master Node
Сервисы, работающие на Master-ноде называются «Kubernetes Control Plane» (кроме etcd), при этом сам Master используется только для административных задач, тогда как реальные контейнеры с вашими сервисами будут запущены на Worker Node.
Kubernetes core services aka Kubernetes Control Plane
На Master Node работают три основных компонента, которые обеспечивают работу всех компонентов системы:
kube-apiserver- основная точка входа для всех запросов — например, любые команды от
kubectlотправляются в виде API-запросов кkube-apiserverна Master Node - API-сервер обрабатывает все REST-запросы, валидирует их и обновляет информацию в
etcd(API-сервер единственный, кто работает сetcd— все остальные компоненты кластера выполняют запросы к API-серверу, а он уже обновляет информацию вetcd, см. Взаимодействие компонтентов) - выполняет аутентификацию и авторизацию клиентов
- основная точка входа для всех запросов — например, любые команды от
kube-scheduler- определяет, на какой Worker Node создавать новый pod (см. Pod), в зависимости от требуемых ресурсов и занятости нод
kube-controller-manager- демон, включающий в себя Controllers, такие как Replication Controller, Endpoints Controller и Namespace Controller
- проверяет состояние кластера через API-сервер, и выполняет необходимые изменения
- занимается созданием и обслуживаем Linux Namespaces и garbage collection
etcd
Key:value хранилище, используемое Kubernetes для управления конфигурациями и service discovery.
Кроме того, в нём хранится текущее (current) состояние системы, и желаемое (desired), например — после деплоймента.
Если K8s находит отличия в etcd между состояниями current и desired — он выполняет необходимые изменения.
Worker Node
Worker Node (ранее — minion) — виртуальная или физическая машина, на которой имеются компоненты Kubernetes для запуска Pod (см. Pod).
На Worker Node-ах работают два компонента:
kubelet: основной компонент Kubernetes на каждой ноде кластера — проверяет API-сервер на предмет появления описания новых Pods, которые должны быть развёрнуты на данной ноде- обращается с Docker (или другой системой контейнеризации, например
rktилиcontainerd) через их API для управления контейнерами - после внесения изменений в состояние пода на ноде — передаёт информацию о статусе обратно к API-серверу (который, в свою очередь, вносит их в
etcd) - мониторит состояние контейнеров
- обращается с Docker (или другой системой контейнеризации, например
kube-proxy: аналог реверс-прокси сервера, отвечает за пересылку и проксирование запросов к соответствующим сервисам или приложениям в приватной сети Kubernetes-кластера- по умолчанию использует IPTABLES (просмотреть правила можно с помощью
kubectl -n kube-system exec -ti kube-proxy-5ctt2 -- iptables --table nat --list) - см. Understanding Kubernetes Kube-Proxy
- по умолчанию использует IPTABLES (просмотреть правила можно с помощью
Взаимодействие компонтентов
Например, при создании нового pod-а — процесс выглядит так:
kubectlшлёт запрос к API-серверу- API-сервер валидирует его, и передаёт в
etcd etcdсообщает обратно API-серверу, что запрос принят и сохранён- API-сервер обращается к
kube-scheduler kube-schedulerопределяет ноду(ы), на которой будет создан pod, и возвращает информацию обратно API-серверу- API-сервер отправляет эти данные в
etcd etcdсообщает обратно API-серверу, что запрос принят и сохранён- API-сервер обращается к
kubeletна соответствующей ноде(ам) kubeletобращается к Docker демону (или другому container runtime) через его API через сокет Docker-демона на ноде с задачей запустить контейнерkubeletотправляет статус pod-а API-серверу- API-сервер обновляет данные в
etcd
Абстракции Kubernetes
Выше мы говорили о более-менее «осязаемых» вещах, таких как виртуальные машины, сети, IP-адреса и прочее.
Но сам Kubernetes являет собой один большой кусок… абстракции, «накладываемой» на виртуальную или физическую инфрастуктуру.
Соответственно, в K8s имеется множество собственных объектов, являющихся абстрактными, или логическими, компонентами Kubernetes.
Pod
Pod — основная логическая единица Kubernetes.
По сути своей, под является такой себе абстракцией виртуальной машины внутри Kunbernetes-кластера: у него есть свой приватный IP, имя хоста, общие данные на дисках (см. Volumes).
Pod является юнитом деплоймента (см. Deployment), и «внутри» этой «машины» запускаются один или более контейнеров, связанных общим назначением, и представляющих собой логическое приложение (состоящее из одного или более процессов/контейнеров).
Каждый под предзначен для запуска и обслуживания единственного экземпляра приложения: если вы хотите выполнить горизонтальное масштабирование приложения — вы должны использовать различные поды, по одному на каждый инстанс приложения.
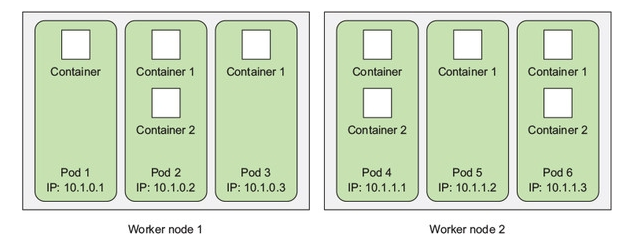
Такая группа нод (Replicated Pods) управляется контроллером (см. Controllers).
При этом сами контейнеры не являются объектами Kubernetes и не управляются им: Kubernetes управляет подами, но контейнеры внутри этого пода используют общее сетевое пространство имён, включая IP адреса и порты, и могут обращаться друг к другу через localhost (потому как под == логическая виртуальная машина).
Пример шаблона для создания пода может выглядеть так:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
app: my-app
type: front-app
spec:
containers:
- name: nginx-container
image: nginx
Services
По теме:
Сервисы — это, в первую очередь, про сеть внутри кластера и обеспечение доступа к подам из мира — они позволяют выполнять коммуникацию между различными компонентами внутри и снаружи приложения.
По сути, сервисы — точно такие же объекты Kubernetes, как Pod, ReplicaSets, DaemonSet, при этом вы можете представлять себе сервис как ещё один виртуальный сервер в ноде.
Например, сервисы можно условно обозначить так:

Тут пользователь приходит к приложению через один сервис, и попадает на фронтенд, затем сам фронтенд через два других сервиса взаимодействует с двумя сервисами бекенда, которые, в свою очередь, через ещё один сервис — общаются с серверов баз данных.
ClusterIP
Открывает доступ к сервису через внутренний IP кластера. Таким образом — сервис будет доступен только внутри самого класетра.
Является типом по-умолчанию.
NodePort
Этот тип открывает доступ к приложению, используя статический IP рабочей ноды кластера. Автоматически создаёт ClusterIP для приложения, на который будет роутиться трафик с NodePort.

Тут:
- 30008 — внешний порт на ноде, на который можно подключаться к сервису (
NodePort), должен быть в диапазоне 30000 — 32767 NodePortсервис — сClusterIPи собственным портом (Port) и IP из блокаserviceSubnet- Pod с приложением в нём — под принимает подключения на порт 80 (TargetPort) и имеет IP из блока
podSubnet
Увидеть подсети можно с помощью kubeadm config view:
[simterm]
root@k8s-master:~# kubeadm config view
apiServer:
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: k8s.gcr.io
kind: ClusterConfiguration
kubernetesVersion: v1.15.0
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}
[/simterm]
Вы можете считать Service ещё одной виртуальной машиной в вашей рабочей ноде, аналогично абстракции Pod.
Шаблон для сервиса типа NodePort может выглядеть так:
apiVersion: v1
kind: Service
metadata:
name: my-svc
spec:
type: NodePort
ports:
- targetPort: 80
port: 80
nodePort: 30008
selector:
app: my-app
type: front-app
Service, Pod, labels, selectors
Что бы Service знал, на какие поды он должен перенаправлять трафик — используются Labels и Selectors.
В описании пода, которое приведено тут в примерах выше, мы указали лейблы нашего приложения:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
labels:
app: my-app
type: front-app
spec:
containers:
- name: nginx-container
image: nginx
Вот наши labels:
...
labels:
app: my-app
А в описании сервиса — используются selectors:
...
selector:
app: my-app
Если в кластере имеется несколько подов с таким лейблом — сервис будет пытаться перенаправлять трафик к ним:

В случае, если приложение размещается на нескольких подах на разных рабочх нодах — то NodePort сервис распределяется по всем связанным нодам, и открывает порт 30008 на каждом из них.
Таким образом — доступ к приложению через NodePort сервис возможен через внешний IP любой из участвующих нод:

LoadBalancer
Создаёт Load Balancer указанного cloud-провайдера, например AWS ALB.
К Load Balancer подключаются Worker Nodes, на которых через внутренний Service типа LoadBalancer трафик маршрутизируется к подам на NodePort.
Сервисы NodePort и ClusterIP создаются автоматически.
ExternalName
Привязывает сервис к значению поля externalName, возвращая CNAME с его значением.
Пример ExternalName:
apiVersion: v1 kind: Service metadata: name: my-google-svc spec: type: ExternalName externalName: google.com
После чего можно обратиться к сервису по имени с любого пода, в данном примере — обращение по имени сервиса my-google-svc:
[simterm]
root@k8s-master:~# kubectl exec -it my-pod -- dig my-google-svc.default.svc.cluster.local +short google.com. 74.125.193.101 ...
[/simterm]
Volumes
Данные в контейнерах являются эфемерными, т.е. в случае, если контейнер упадёт, и kubelet его пересоздаст — то все данные из старого контейнера будут утеряны.
Кроме того — внутри одного пода одни и те же данные могут понадобится нескольким контейнерам.
Volumes в Kubernetes схожи с их идеей в Docker, но имеют намного больше возможностей для управления.
Кроме того, Kubernetes поддерживает большое количество различных драйверов для монтирования разделов к подам — awsElasticBlockStore, hostPath, nfs и т.д.
Namespaces
- Namespaces
- Share a Cluster with Namespaces
- What is: Linux namespaces, примеры PID и Network namespaces
Namespace в Kubernetes представляет собой отдельный виртуальный кластер, со своим пространством имён для сети, дисков, процессов и так делее.
Основная идея пространств имён — разделение окружения между различными рабочими окружениями, пользователями, и среди прочего позволяет задавать ограничения на использование ресурсов кластера (ЦПУ, память и т.д., см. Resource Quotas).
Кроме того, имена пространств имён используются в DNS для сервисов, т.е. каждый сервис обладает именем вида <service-name>.<namespace-name>.svc.cluster.local.
Основная часть ресурсов Kubernetes располагается в пространствах имён, получить их можно с помощью:
[simterm]
$ kubectl api-resources --namespaced=true
[/simterm]
Ресурсы, не использующие namespaces — можно увидеть так:
[simterm]
$ kubectl api-resources --namespaced=false
[/simterm]
Controllers
Controller в Kubernetes представляет собой постоянно работающий процесс, который через API-сервер проверяет текущее состояние кластера и выполняет действия, необходимые для приведения текущего состояния (current) к желаемому (desired).
Кроме стандартных контроллеров, перечисленных ниже, можно создавать свои, см. How to Create a Kubernetes Custom Controller Using client-go.
ReplicaSet
- ReplicaSet
- Key Kubernetes Concepts
- Kubernetes KnowHow — Working With ReplicaSet
- Знакомство с Kubernetes. Часть 4: Реплики (ReplicaSet) (вообще интересный блог)
ReplicaSet создаётся Deployment-ом, и основной задачей ReplicaSet является создание и скейлинг подов.
ReplicaSet является более продвинутой версий ReplicationController с той разницей, что ReplicaSet имеет возможность использования множественных селекторов (см. Service, Pod, labels, selectors).
Рекомендуется использование Deployment вместо прямого создания ReplicaSet.
Пример ReplicaSet:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-nginx-rc
labels:
app: my-nginx-rc-app
spec:
replicas: 3
selector:
matchLabels:
app: my-nginx-rc-app
template: # PODs template
metadata:
labels:
app: my-nginx-rc-app
spec:
containers:
- name: nginx-container
image: nginx
Deployment
- Deployments
- Знакомство с Kubernetes. Часть 5: Развертывания (Deployments)
- Kubernetes Deployments: The Ultimate Guide
- Deployment Strategies
- Kubernetes Deployment Tutorial For Beginners
- Managing Kubernetes Deployments
- K8s: Deployments vs StatefulSets vs DaemonSets
Deployment controller выполняет обновление подов и RelicaSets, и является наиболее используемым ресурсом Kubernetes для деплоя приложения/й, как правило — stateless приложений, но если подключить Persistent Volume — приложение можно использовать как stateful, но все поды деплоймента будут совместно использовать это хранилище и данные из него.
При создании Deployment — он создаёт ReplicaSet, который, в свою очередь, создаёт и оперирует подами для этого деплоймента.
Deployment используются для:
- обновления состояние Pod —
Deploymentсоздаст новуюReplicaSet, и обновит номер ревизииDeployment(deployment.kubernetes.io/revision: "", при этомReplicaSetиспользует опеределённую ревизию деплоймента) - откат деплоймента при неудачном обновлении, используя номера ревизий
- скейлинг и автоскейлнг подов (
kubectl scaleиkubectl autoscale, см. kubectl Cheat Sheet) - canary deployments («канареечный релиз«, или просто «частичный релиз«, см. Intro to deployment strategies: blue-green, canary, and more)
 Кроме
Кроме Deployments можно использовать kubectl rolling-update, хотя Deployments является рекомендуемым способом управления приложениями.
StatefulSet
StatefulSet используются для управления stateful-приложениями.
Создаёт не ReplicaSet, а Pod напрямую с уникальным именем. В связи с этим — при использовании StatefulSet нет возможности выполнить откат версии, но можно его удалить или выполнить скейлинг.
При обновлении StatefulSet — будет выполнено RollingUpdate всех подов.
DaemonSet
DaemonSet в свою очередь является контроллером, основным назначением которого является запуск подов на всех нодах кластера: если нода добавляется/удаляется — DaemonSet автоматически добавит/удалит под на этой ноде.
DaemonSet подходят для запуска приложений, которые должны работать на всех нодах, например — екпортёры мониторинга, сбор логов и так далее.
При этом некоторые ноды, например Мастер нода, будет отвергать запуск подов на этой ноде (см. Taints and Tolerations), т.к. ему задан node-role.kubernetes.io/master:NoSchedule:
[simterm]
# kubectl describe node k8s-master | grep Taint Taints: node-role.kubernetes.io/master:NoSchedule
[/simterm]
Соотвественно, при создании DaemonSet, который должен создавать поды в т.ч. на Мастер-ноде — ему необходимо указать tolerations.
Полностью такой DaemonSet может выглядет так:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: my-nginx-ds
spec:
selector:
matchLabels:
app: my-nginx-pod
template:
metadata:
labels:
app: my-nginx-pod
spec:
tolerations:
- effect: NoSchedule
operator: Exists
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 80
При обновлении DaemonSet — будет выполнено RollingUpdate всех подов.
Job
Job в Kubernetes предназначен для создания пода, в котором будет выполнена только одна задача, после чего под будет остановлен.
Job может создать один или несколько подов, запустить задачу параллельно на нескольких, выполнить заданное количество операций, после чего завершится.
Пример простой задачи:
apiVersion: batch/v1
kind: Job
metadata:
name: job-example
spec:
completions: 2
parallelism: 2
template:
metadata:
name: counter
spec:
containers:
- name: counter
image: ubuntu
command: ["bash"]
args: ["-c", "for i in {1..10}; do echo $i; done"]
restartPolicy: Never
CronJob
Аналогичен Job, но имеет возможность запуска по расписанию, используя schedule.
Пример:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cronjob-example
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
completions: 2
parallelism: 2
template:
metadata:
name: counter
spec:
containers:
- name: counter
image: ubuntu
command: ["bash"]
args: ["-c", "for i in {1..10}; do echo $i; done"]
restartPolicy: Never
Ссылки по теме
Вторая часть — Kubernetes: знакомство, часть 2 — создание кластера с AWS cloud-provider и AWS LoadBalancer.
Common
- Concepts
- Key Kubernetes Concepts
- Kubernetes Master Components: Etcd, API Server, Controller Manager, and Scheduler
- Resource Quotas
- Kubernetes (все посты по тегу, интересный блог у человека)
- kubectl Cheat Sheet
- Taints and Tolerations
Networking
- Service
- Cloud Providers
- Understanding Kubernetes Kube-Proxy
- Kubernetes Services: A Beginner’s Guide
- Kubernetes — Services Explained
- Using Kubernetes LoadBalancer Services on AWS
- Kubernetes: from load balancer to pod
- Kubernetes NodePort vs LoadBalancer vs Ingress? When should I use what?
- How Does The Kubernetes Networking Work? : Part 1
- Kubernetes Services: Exposed!
- Load Balancing and Reverse Proxying for Kubernetes Services
Deployments
- Kubernetes Deployment Strategies
- Kubernetes Deployments: The Ultimate Guide
- Kubernetes Deployment Tutorial For Beginners
- Managing Kubernetes Deployments
- K8s: Deployments vs StatefulSets vs DaemonSets
Jobs
Misc
- How to Create a Kubernetes Custom Controller Using client-go
- Kubernetes KnowHow — Working With ReplicaSet
- Intro to deployment strategies: blue-green, canary, and more
- Kubernetes Volumes Guide
![]()