 Перший пост цієї “серії” (яка взагалі не планувалась як серія) – я написав ще у 2022, коли вперше довелося почати розбиратись з електрикою і тим, як забезпечити електрохарчування вдома під час відключень:
Перший пост цієї “серії” (яка взагалі не планувалась як серія) – я написав ще у 2022, коли вперше довелося почати розбиратись з електрикою і тим, як забезпечити електрохарчування вдома під час відключень:
- Підготовка до зими 2022-2023: інтернет, електрика, опалення, їжа та вода (опублікований 1 січня 2023)
- Підготовка до зими 2023-2024: електрохарчування (опублікований 13 серпня 2023)
Окремо варто згадати пост Linux: збереження заряду батареї ноутбуку – як визначити споживану потужність ноутбука, і як її можна зменшити.
Цей пост я почав писати в кінці жовтня – на початку листопада 2023 року, коли готувався до зими, але недописав, та й зима пройшла без відключень.
Втім, раптом питання стало дуже актуальним влітку 2024 року – тож давайте повернемось до цієї теми.
Отже, про що будемо говорити:
- згадаємо що таке вольти/ампери/вати
- як порахувати потужність електроприладів вдома і прикинути необхідний запас енергії
- як ми цей запас можемо тримати – які типи зарядних станцій та інших подібних рішень є
- розглянемо питання, пов’язані з ДБЖ та інверторами – на що звертати увагу при виборі, як правильно користуватись
- і поговоримо про акумулятори – які типи є, їхні характеристики, плюси-мінуси, і розглянемо питання зарядки
Відразу хочу нагадати, що я не електрик, а звичайний айтішник.
І цей пост – не “повний гайд” з точними рекомендаціями що вибрати і як налаштувати, а більше має на меті дати загальну інформацію по основним питанням.
Note: чому “електрохарчування”а не електроживлення? Див. Визначення «електрохарчування».
Вольти, вати, ампери
Трохи детальніше намагався розібрати в Підготовка до зими 2023-2024: електрохарчування, але давайте згадаємо:
- Вольти: напруга – по суті схожа з величиною тиску води в трубі – чим він вище, тим с більшою силою йде вода з крана, тобто з якою “силою” електрони штовхаються через провідник. Позначається як В або V.
- Ампер: сила струму – можна порівняти з кількістю води, що протікає через трубу за одиницю часу, або з кількістю даних, що передається через мережевий канал за одиницю часу (наприклад, кількість пакетів або бітів). В цьому випадку ампери визначають, скільки електричних зарядів проходить через провідник за одиницю часу.
- Ват: потужність – можна порівняти з кількістю води в літрах, яке виллється з крана. Позначається як W (Вт).
Наприклад, якщо знаємо, що батареї EcoFlow працюють на 50 вольтах, а споживана потужність під час зарядки 2000 ват – то отримуємо силу струму зарядки у 2000/50 == 40 ампер. Але про це все будемо детальніше говорити далі.
Або навпаки: якщо зарядний пристрій працює на 12 вольтах і видає 10 ампер сили струму – то він передає 120 ват, а якщо 24 вольти на тих жеж 10 амперах – то вже 240 ват.
Ще досить гарне пояснення – побачив колись давно десь в коментарях на Ютубі, і мені воно прям дуже подобається:
– Напруга (V): ширина річки
– Сила струму (A): швидкість течії води в річці
Тому одну і ту ж потужність може дати й широка ріка (висока напруга, Вольт) з повільною течією (слабкий струм, Ампер) – і вузька річка (низька напруга, Вольт) зі швидкою течією (сильний струм, Ампер).
Чим швидше ріка і чим вона ширше – тим більше води (Ват) за одиницю часу.
Тобто:
- Напруга (V) – ширина річки: широка річка може передати більше води при тій же швидкості течії (силі струму)
- хоча ширина річки тут не дуже вдала аналогія, бо напруга (в вольтах) описує різницю електричних потенціалів, що штовхає електрони через провідник, подібно до того, як різниця висот штовхає воду вниз по річці
- Сила струму (A) – швидкість течії води в річці:
- умовна річка шириною в 10 метрів при швидкості течії води в 10 метрів на секунду передає 100 кубометрів води в секунду
- умовна річка шириною в 100 метрів при швидкості течії води в 1 метр на секунду також передає 100 кубометрів води в секунду
- Потужність (W) – кількість води за одиницю часу: потужність визначається як кількість енергії, переданої (або спожитої) за одиницю часу, і в цій аналогії це кількість води, що проходить через річку за певний проміжок часу (наші 100 кубометрів в секунду)
Потужність можна отримати за допомогою формули P=V×I, де P – потужність в ватах, V – напруга в вольтах, а I – сила струму в амперах.
Рахуємо потужність приладів вдома
Ми не будемо брати до уваги прилади по типу стиральної машини або кавоварки, бо під час відключення електроенергії ви навряд чи будете їх живити від батарей.
Але є така ось табличка, аби мати уявлення про потужність різних приладів:

Отже, що нам знадобиться? Рахуємо те, що має працювати постійно, тобто телевізор, ігрову приставку або ігровий ПК пропускаємо.
В моєму випадку це:
- холодильник: 80 ват (маємо на увазі пусковий струм до х10 від номінального – але про це поговоримо, коли будемо розглядати інвертори та ДБЖ)
- газовий котел для опалення і гарячої води для душа/кухні (у нас в ЖК свої скважини, насоси та генератори для них): 130 ват (і теж має пусковий струм, хоча тут, мабуть, поменше, бо нема компресора, як у холодильнику – тільки двигун насоса)
- і “куточок користувача”:
- настільна лампа: 8 ват
- колонки: 10 ват
- роутер: 18 ват
- медіаконвертер (оптика => ethernet): 12 ват
- монітор: 40 ват
- ноутбук: 60 ват
Заміряти можна ватметром, наприклад мій холодильник:

Але холодильник і котел працюють не постійно, а вмикаються та вимикаються при потребі, коли змінюється температура. Давайте вважати, що вони працюють 50/50 від загального часу.
Тоді холодильник і котел працюючи одночасно споживають ~210 ват, умовно кажучи, годину через годину. Значить в розрахунок беремо 100 ват/годину.
Тепер додаємо решту – “куточок користувача”, і тут маємо ще ~150 ват/годин.
Отже, разом це 250 ват/годину – і тепер ми можемо рахувати необхідний запас.
Самий довгий блекаут 2022/2023 був три доби, а на добу нам потрібно:
- холодильник і котел: працюють цілодобово, по 100 Вт/г – на добу потрібен запас у 2400 ват/годин
- “куточок користувача”: працюють умовних 14 годин на добу, по 150 Вт/г – на добу потрібен запас у 2100 ват/годин
Тобто разом необхідний добовий запас енергії – 4500 ват/годин. Хоча взимку 2022/2023 я обходився без холодильника – м’ясо з морозильника вивішував в пакеті за вікном.
Тепер можна поговорити про те, як цей запас отримувати та зберігати.
Варіанти енергозабезпечення: зарядні станції, акумулятори, ДБЖ
Ну і тут вибір на всі смаки:
- зарядні станції типу EcoFlow/Bluetti: найкращій варіант з точки зору безпеки та обслуговування, бо “it just works”, але і найдорожчий
- саморобні станції від майстрів: дешевші від EcoFlow, прості в обслуговуванні, але є ризики що китайська начинка накриється, і станція перестане працювати, або можливі проблем з батареями (і навіть пожежа)
- ДБЖ та акумулятори: більш складний варіант з точки зору зборки самої системи, більш небезпечний ніж EcoFlow (але безпечніший за саморобні станції), проте дешевше, ніш EcoFlow
- окремо зарядне, інвертор та акумулятори: найскладніший з точку зору зборки системи та її обслуговування, і найбільш небезпечний при порушенні правил використання
Трохи окремо стоять сонячні батареї та генератори – але я про них писати не буду, бо живу у квартирі, і генератор ставити на балконі не можна, а сонячні батареї вішати хіба що за балкон – але тут є питання в їх ефективності, особливо взимку, бо балкон на захід, і питання їхнього монтажу – треба або шукати майстрів, а це не дуже просто, або робити самому – а в мене не настільки прямі руки.
Найбільші ризики використання всіх подібних приладів – це пожежа, і ці ризики треба мати на увазі, бо ми багато в новинах чуємо про черговий випадок вибухів на балконах.
Наприклад я собі “від гріха подалі” ще у 2022 купив два вогнегасники:

Ще – якщо дійдуть руки, буде час та натхнення – то хочу зробити з Adruino датчики тепла (міряти температуру на балконі, це стоять зарядні станції та акумулятори, і температуру самих акумуляторів), та датчик диму. Хоча можна просто купити готові рішення від того ж Ajax Systems.
Окей. Тепер давайте розберемо ці системи детальніше.
Зарядні станції EcoFlow/Bluetti/etc
Я їх не розглядав в минулих записах, бо в мене їх не було 🙂
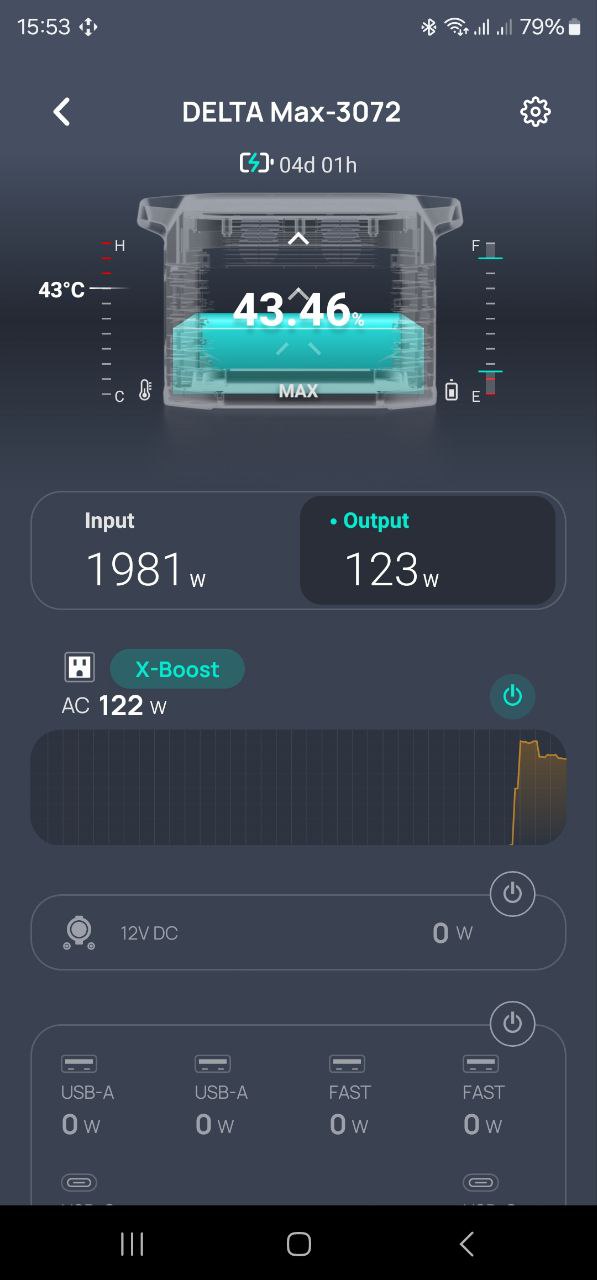
Але в цьому році я все ж купив собі EcoFlow DELTA Max 2000 (2016 Вт·год). Обійшлася вона мені в ~59.000 грн (брав на Rozetka), і я вважаю, що воно того варте.
В мене Li-ion батареї, а аналогічна станція з LiFePo4 буде коштувати близько 100.000 (це зараз, при курсі долара ~40 грн). Про батареї будемо говорити окремо і детальніше далі, але в принципі LiFePo4 варті свої грошей.
Коли я себе вговорював купити її, то останнім було – “Блін, ти собі на день народження подарував Samsung S23 Ultra за 50.000 грн! І це просто телефон – а тут питання нормального функціювання!“.
Тобто – да, воно коштує грошей, і не мало, проте ви просто його вмикаєте – і спокійно собі живете.
Переваги:
- простота: воно просто працює, і нічого в принципі від вас не вимагає
- безпека: це, мабуть, максимальний рівень безпеки в плані як вибуху/пожежі, так і випадкового замикання дротів або удару током вас, як юзера
- надійність: це, мабуть, максимальний рівень безпеки надійності з точки зору поломки – якщо правильно використовувати та не перенавантажувати
- швидкість зарядки: це дуже важливий момент, і про нього будемо говорити далі, але щодо EcoFlow – то він свої 2000 Вт/год “заливає” за півтори години – і це дуже круто
- мобільний додаток: керування параметрами та відображення даних по споживанню/запасу енергії – дуже зручно, дуже корисно
- компактність: для розміщення такого девайсу знадобиться набагато менше місця, ніж для звичайних акумуляторів на той самий об’єм енергії
Недоліки:
- фактично, він тут один – це ціна, інших поки не побачив
- ще до недоліків можна додати, що ані станція, ані мобільний застосунок не попереджають про низький заряд батареї – станція просто мовчки виключається
Але EcoFlow має купу метрик, з якими ми можемо зробити крутий моніторинг з алертами – див. EcoFlow: моніторинг з Prometheus та Grafana.
Щодо шумності: EcoFlow DELTA Max доволі шумна, і включає кулери як під час зарядки, так і під час використання. Спати з такою станцією в одній кімнаті буде не дуже зручно (навряд чи можливо взагалі), тож у випадку однокімнатної квартири-студії треба або вимикати станцію на ніч, або ставити десь в кладовку чи на балкон, а враховуючи відносну пожежобезпечність такого приладу – цілком собі варіант тримати десь там.
Але слідкуйте за температурою, особливо якщо балкон на сонячній стороні, бо в мене станція іноді нагрівається до +45, і починає видавати попередження – доводиться ставити вентилятор. Або закривайте вікна балкона, наприклад Сонцезахисною плівкою.
Мобільний додаток для EcoFlow виглядає ось так – тут підключений ігровий ПК, монітор, роутер, колонки:

Налаштування девайсу:

І під час зарядки – 2000 ват (це на початку, потім зменшується сила струма на батареї, і, відповідно, споживана потужність):
EcoFlow: рекомендації з використання
Кілька рекомендацій по використанню EcoFlow, хоча це відноситься і до інших аналогічних девайсів.
Треба мати на увазі, що деградація батарей – це зменшення їх ємності. 800 циклів в документації EcoFlow – це зменшення ємності до 80% від початкової, а не повністю вихід з ладу. До того ж зараз наче можна легко замінити батареї на нові.
Мінімальний та максимальний рівень заряду
Має сенс виставити обмеження на мінімальний та максимальний рівень заряду – 20% мінімум, і 90% максимум. В такому випадку станція не буде повністю висаджувати батареї, що для них не є ОК, і не буде повністю їх заряджати. Хоча я впевнений, що контролер самої станції і так має потрібні обмеження – але зайвим не буде.
Не тримати постійно на зарядці
Друге, що я роблю – це не тримаю її на зарядці постійно, бо по документації вона розрахована на 800 циклів заряду/розряду (це при Li-ion батареях, для LiFePo4 це здається 3000 циклів). Так – доводиться робити додаткові рухи руками, і перемикати розетки/подовжувачі, коли вимикають/вмикають світло – зато проживе станція довше, бо світло вимикається кілька раз на добу, і кілька раз на добу вмикається зарядка батарей.
Хоча просто тримати її ввімкненою зручно, бо станція вміє працювати як UPS, тобто коли в мережі є енергія – станція живить прилади від мережі, а як в мережі пропадає – то переключається на батареї.
Не перенавантажувати станцію
Ну і, звісно, не можна перенавантажувати станцію. В неї заявлена видача у 2000 ват, є режим X Boost до 4600 ват. Тож не варто підключати стиральну машинку, кавоварку і чайник одночасно.
Вимикати інвертор
Також майте на увазі, що вбудований інвертор станції (взагалі будь-який інвертор) також споживає енергію, навіть якщо не підключено ніяких приладів, і споживає близько 20-30 ват на годину – тобто він з’їсть ~500 ват запасу за добу, навіть працюючи вхолосту. Тому можете або вимикати AC вручну, або налаштувати автовимкнення (дефолт – 12 годин).
Наприклад, з включеним AC при заряді в 34% станція видає 1 день роботи (без приладів):

А з відключеним – 99 годин:

Зменшувати швидкість зарядки
Можна зменшити максимальне навантаження станції під час зарядки батарей (2000 ват/годину в моїй).
Аби включити опцію власного налаштування – на задній панелі треба переключити Fast – Slow/Custom:

Після чого в мобільному застосунку стане доступним налаштування AC charge speed:

Це зменшить струм заряду, і батареї будуть почуватись краще.
Саморобні зарядні станції від “умільців”
Я не скажу, що рекомендував би такий варіант, бо тут занадто багато “як пощастить”: як пощастить з руками майстра, як пощастить з компонентами (Китай/не Китай і т.д.).
Але в цілому – варіант робочий, і в мене одне таке чудо є:

Заявлені такі ж самі 2000 Вт/годин, але реально вдається накопичити близько 1300 – тестував як раз на ігровому ПК, який споживає ~300 ват, і працює близько 4 годин.
В середині це чудо виглядає так:

Синя плата справа – це BMS, Battery Management System, яка контролює заряд акумуляторних батарей – рівень їх заряду/розряду, і додатково може вміти в захист від замикань, перенавантаження тощо.
Переваги:
- швидкість зарядки: зазвичай такі станції роблять з потужними зарядками, наприклад в мене вона заряджається за пару годин
- компактність: конкретно ця більша за EcoFlow, але це все ще менше місця, ніж 2 акумулятори і ДБЖ, плюс тут все в одному корпусі
- ціна: на Olx такі системи продаються за ціною в районі 20.000 грн за 2000 Вт/г, що набагато дешевше, ніж EcoFlow, який, нагадаю, коштує майже 60.000 за 2.000 Вт/г
Недоліки:
- надійність: Китай
 іноді інвертор починає пищати під час роботи, і я поки не зрозумів чому (5 коротких звукових сигналів – хтось, може, в курсі?)
іноді інвертор починає пищати під час роботи, і я поки не зрозумів чому (5 коротких звукових сигналів – хтось, може, в курсі?) - безпека: тут знов-таки покладаємось на руки майстра – наскільки він все правильно зробив (якість пайки, сама схема роботи), наскільки якісні компоненти використовував (а враховуючи факт, що такі станції намагаються зробити не надто дорогими – то можливі нюанси)
- шум: під час зарядки гудить, як літак на форсажі – набагато гучніша за EcoFlow
ДБЖ та зовнішні акумулятори
Ще один варіант – це купити окремо акумулятор, і окремо до нього – ДБЖ.
Наприклад, в мене є ось такий комплект:

Тут ДБЖ CyberPower CPS1000E та AGM-акумулятор на 72 Ампер/години.
Про типи і ємність акумуляторів теж будемо говорити далі.
Але цей сетап більш резервний, і купувався ще у 2022, коли вибору особливо не було, бо тоді скупали просто все, що з’являлось.
Переваги:
- ну, воно працює… в принципі це, мабуть, все
- ціна: насправді, не впевнений, чи заносити це в плюси, чи в мінуси, але в порівнянні з EcoFlow цей варіант буде дешевшим (хоча в порівнянні з EcoFlow, мабуть, будь-що буде дешевшим 🙂 )
- мені сам ДБЖ обійшовся у 2022 році в 23.000 грн, зараз такий коштує від 16.000 (на Розетці) до тих жеж 23.500 гривень
- акумулятор – якщо брати ті ж умовні 2.000 ват/годин (200 ампер/годин на 12 вольт, тобто 1 шт), то за Li-ion це буде близько 20.000 грн, а за LiFePo4 – 35-50 тисяч гривень
- надійність: через те, що тут два компоненти, то і говорити про них треба окремо, але щодо самого ДБЖ – то CyberPower наче доволі відома компанія, тож тут можна поставити плюс
- безпека: при умовах правильного використання більш безпечне рішення в порівнянні в саморобними станціями, але залежить від самого ДБЖ та акумуляторів, але точно менш безпечне за EcoFlow
Недоліки:
- шум: ДБЖ (принаймні цей) доволі шумний під час зарядки, в кімнаті не поставиш (приблизно на рівні EcoFlow)
- надійність: а тут вже про акумулятор, і тут багато чого “It depends” – і виробник акумулятору, і те, наскільки ДБЖ правильно заряджає акумулятор(и), і температура в місці, де акумулятор стоїть – бо вони не люблять ані холод, ані жару
- безпека: і тут знов-таки дуже багато залежить від акумулятора і умов експлуатації, тому запишу в мінуси, бо ризики вибуху/пожежі акумулятора є
- швидкість зарядки: багато залежить від ДБЖ та акумуляторів, але скоріш за все це буде в кілька разів довше (якщо не в 10 раз), ніж той же EcoFlow
- компактність: це система, яку треба один раз поставити, і забути, бо з місця на місце просто так не перенесеш – треба розбирати компоненти, і переносити окремо
Окремо зарядне, інвертор та акумулятори
В мене такої системи нема, але в Телеграм-чаті RTFM після публікації першого посту хтось скидав фотки системи вдома, де стоїть акумулятор, окремо до нього підключається зарядне, і окремо – інвертор.
Переваги:
- ціна: єдина, мабуть, перевага такого рішення – це ціна, і то не впевнений
Недоліки:
- простота: ніякої, бо маєте, по-перше, дуже ретельно вибрати всі компоненти – і акумулятор, і відповідний зарядний пристрій, по-друге – це все з’єднується окремо, і маєте або перемикати постійно вручну – або знов-таки мати мороку з якимись додатковими компонентами контролю/перемикання
- безпека: трохи є, але гірше за інші рішення, бо дуже багато “It depends” – як правильно виберете компоненти, надійність компонентів, їхній моніторинг і так далі
- компактність: і знов мінус, бо в рішення з ДБЖ+акумулятор у вас принаймні зарядне+інвертор в одному корпусі, а тут – купа проводів
Знайшов фотки з чату в Телеграмі:
 І ще окремо сам зарядний пристрій:
І ще окремо сам зарядний пристрій:
 Імхо – дуже так собі рішення, бо надто багато геморою.
Імхо – дуже так собі рішення, бо надто багато геморою.
Втім, на Youtube-каналі @izmailinvertor є багато відео, де людина з прямими руками розказує про такі системи.
Висновки
Тож якщо обирати рішення для дому – то, звісно, якщо є гроші – найкращим варіантом будуть станції по типу EcoFlow.
Другий варіант – це ДБЖ+зовнішні акумулятори. З недоліків – швидкість зарядки і компактність, але має бути дешевшим.
Варіант з саморобними зарядними станціями з Olx особисто я не рекомендував би, бо віри в надійність і безпеку мало. Хоча так – сам вдома таку станцію тримаю, але купував, бо на той час не було грошей, економив, а викинути тепер жалко – “запас карман нє тянєт”.
Ну і варіант “мати все окремо” – це треба бути або дуже шарящою людиною аби все зібрати самому, або мати надійних людей/компанії, які таку систему можуть зібрати для вас. Втім, це все одно доволі геморно з точки зору обслуговування, а я людина лінива.
ДБЖ та інвертори
Мабуть, окремо варто трохи поговорити про різницю між ними, і як їх вибирати.
Отже, ДБЖ – це “all inclusive” система, де в одному корпусі ви маєте і зарядний пристрій для акумуляторів, і інвертор. Зарядний пристрій, власне, заряджає батареї, а інвертор – “розряджає”, тобто передає струм з них на побутові прилади, при потребі збільшуючи струм з 12/24/etc вольт до звичних 220, і перетворюючи його з постійного на змінний.
Інвертор жеж – це тільки перетворення постійного струму 12 вольт з акумулятору на 220 вольт змінного струму, і нічого більше. Хіба що якийсь додатковий захист від замикань/перенавантаження тощо.
І не забуваємо, що будь-який інвертор, навіть в EcoFlow частину енергії витрачає на перетворення струму, приблизно 15%. Тобто, якщо батарея на 1000 ват/годин – то реальної ємності буде 850.
Вибір ДБЖ/інвертора
При виборі ДБЖ є три основних параметри, на які треба звертати увагу – це вихідна та зарядна потужність, і синусоїда.
Вихідна потужність ДБЖ та інверторів
На початку ми порахували, що разом в мене вдома споживається 250 ват/на годину, тож мінімально ДБЖ має бути з запасом хоча б х2, тобто 500 ват – мій CyberPower CPS1000E видає до 700 ват, а EcoFlow – до 2000.
Але тут треба враховувати нюанс з системами типу холодильника, у яких дуже високе споживання при старті двигуна/компресора – від 800 до 1500 ват, тому від CyberPower його захарчувати не вийде, бо або спрацює захист і ДБЖ виключиться – або захист не спрацює, і ДБЖ згорить.
Вольт-ампери та вати
Також потужність ДБЖ часто вказується у вольт-амперах (ВА, також позначається як “повна потужність”), а споживана потужність приладів зазвичай в ватах (“активна потужність”). В такому випадку, аби перевести потужність в вольт-амперах в вати – вольт-ампери множимо на коефіцієнт потужності приладу, зазвичай це 0.6 – 0.9, але має бути вказаний в документації приладу. Можна просто брати середнє значення – 0.85.
Зарядна потужність ДБЖ
І оце дуже важливий момент, про який будемо говорити далі, бо згадуючи зиму 2022/2023, коли світло іноді бувало по кілька годин на добу – то за ці кілька годин вам потрібно повністю зарядити ваші акумулятори.
При цьому є нюанс і з самими акумуляторами, які не дуже люблять високі токи, і якщо якийсь AGM кожен день по кілька раз заряджати на 10 амперах – то спасибі він вам не скаже. Втім, це знов-таки окрема тема, про яку говоритимо далі.
Типи ДБЖ
ДБЖ поділяються на різні типи – в залежності від задачі, для якої проектувались:
- резервні ДБЖ (Off-Line, Standby): самі прості, призначені виключно для підстрахування на кілька хвилин – поки світло є, то живлення передається напряму з мережі і паралельно заряджаються акумулятори, а коли вмикається напруга в мережі – то вмикається живлення від акумуляторів
- лінійно-інтерактивні (Line-Interactive): поки в мережі є напруга – то передають її на прилади і паралельно згладжують коливання напруги в електромережі, тобто працюють як стабілізатори напруги, при вимиканні світла або перепадах напруги – перемикаються на роботу від батарей
- інверторні або ДБЖ безперервної дії (Online): найбільш просунуті системи, які постійно перетворюють струм з мережі в постійний струм, вирівнюють будь-які коливання, перетворюють назад в змінний, а потім передають на прилади
Форма вихідної напруги
ДБЖ можуть видавати чисту або модифіковану синусоїду змінного струму, і деякі прилади вимагають саме чисту – наприклад, двигун холодильника, газовий котел або медична апаратура.
Дуже важлива характеристика ДБЖ, яку треба мати на увазі.
Непоганий матеріал на цю і інші теми по ДБЖ – Що потрібно знати про джерела безперебійного живлення (ДБЖ).
Рекомендації по використанню інверторів
Коротко про те, як правильно використовувати інвертори:
- при включенні:
- у виключеному стані інвертор підключаємо до батареї
- включаємо інвертор, чекаємо, поки він “заведеться”
- підключаємо прилади
- при виключенні:
- відключаємо прилади
- виключаємо інвертор
- відключаємо від батареї
Див. трохи більше деталей у відео Как правильно включать – выключать инвертор 12-220В.
Акумулятори
Тему про акумулятори, мабуть, варто було б винести взагалі окремим постом, бо тема досить велика і місцями складна.
Але давайте спробуємо відносно стисло про неї поговорити.
Отже, що ми маємо мати на увазі при виборі акумулятора:
- тип: кислотні, AGM, гелеві, LiFePo4 – вибір великий, і важливий
- ємність: як правильно розрахувати наскільки вам вистачить акумулятору
- швидкість заряду: як вибрати знов-таки тип акумулятору і ДБЖ для нього
Типи акумуляторів
Окрім описаних нижче також є звичайні свинцево-кислотні акумулятори (тягові або стартові – для старту двигуна авто), які також називають автомобільними. Можуть виділяти водень і кисень, а тому пожежонебезпечні, і для дому їх точно використовувати не варто.
Основні характеристики акумуляторів:
- кількість циклів заряду-розряду: чим більше виконується циклів перезарядки – тим більше деградує (втрачає ємність батарея)
- рівень саморозряду: як швидко акумулятор розряджається без підключених приладів
- стійкість до глибокого розряду: наскільки деградує батарея при розряді до мінімальних значень
- стійкість до перезаряду:
- здатність акумулятора не перегріватися при надмірній зарядці, що впливає на його перегрів і може призвести до займання або вибуху
- рівень деградації батареї під час зарядки високим струмом, особливо під час завершення зарядки
- температурний режим: допустима/комфортна температура навколишнього середовища
- чутливість до зарядного пристрою: різні типи акумуляторів мають різні характеристики процесу заряджання, і ДБЖ має це враховувати
- вартість
- “ефект пам’яті“: втрата ємності акумулятора при неповному розряді перед наступною зарядкою
- швидкість зарядки: власне, як швидко можна зарядити акумулятор – залежить від максимальної сили струму і типу акумулятора
Absorbent Glass Mat (AGM) акумулятори
Також є свинцево-кислотними, але електроліт всередині знаходиться в абсорбованому стані, тому вони герметичні і їх можна встановлювати в будь-яке положення окрім “догори ногами”.
Характеристики:
- кількість циклів заряду-розряду: 300-500
- рівень саморозряду: низький (1-3% на місяць)
- стійкість до глибокого розряду: середня
- стійкість до перезаряду: середня
- температурний режим: від -20°C до +50°C (оптимально 20-25°C)
- чутливість до зарядного пристрою: середня
- вартість: середня
- “ефект пам’яті“: відсутній
- швидкість зарядки: середня (можна заряджати до 20% від ємності на годину)
Переваги:
- велика кількість циклів перезаряджання і тривалий термін служби
- низький рівень саморозряду
- немає “ефекту пам’яті” (можна заряджати у будь-який час, не чекаючи повної розрядки)
- швидко заряджаються
Недоліки:
- погано переносять перезаряджання (високий струм наприкінці зарядки), тому треба мати відповідний ДБЖ
- обмежена кількість циклів заряду-розряду
- відносно важкі (бо свинець)
Гелеві та мультигелеві акумулятори
За характеристиками подібні до AGM, але в якості електроліту використовується гель.
Характеристики:
- кількість циклів заряду-розряду: 500-800
- рівень саморозряду: низький (1-2% на місяць)
- стійкість до глибокого розряду: висока
- стійкість до перезаряду: висока
- температурний режим: від -20°C до +55°C (оптимально 20-25°C)
- чутливість до зарядного пристрою: висока
- вартість: вище середньої
- “ефект пам’яті“: відсутній
- швидкість зарядки: низька (можна заряджати 10-15% від ємності на годину)
Переваги:
- довго можуть бути розрядженими
- пристосовані під циклічний характер роботи з глибоким розрядом
- допустимість короткострокових глибоких розрядів
Недоліки:
- висока вартість
- чутливість до коротких замикань
- повільна зарядка
- більша чутливість до температур, хоча працюють при температурі від -30 до +50
- чутливі до зарядного пристрою
LiFePO4
Нове покоління акумуляторів – літій-залізо-фосфатні. Також герметичні, зокрема використовується в електромобілях.
Характеристики:
- кількість циклів заряду-розряду: 2000-5000
- рівень саморозряду: дуже низький (менше 1% на місяць)
- стійкість до глибокого розряду: дуже висока
- стійкість до перезаряду: висока
- температурний режим: від -20°C до +60°C (оптимально 15-35°C)
- чутливість до зарядного пристрою: висока (потребує спеціального зарядного пристрою або просунутий ДБЖ)
- вартість: висока
- “ефект пам’яті“: відсутній
- швидкість зарядки: дуже висока (можна заряджати до 1C, тобто струм заряду може дорівнювати ємності акумулятора, деякі моделі підтримують ще швидшу зарядку)
Переваги:
- велика кількість циклів перезаряджання і тривалий термін служби – набагато більший, ніж у AGM та гелевих акумуляторів
- низький рівень саморозряду
- широкий діапазон робочих температур (від -15 до +60°C)
- не бояться великих струмів (можна швидше заряджати)
- висока швидкість заряджання – і за рахунок можливості подачі більш високого струму, ніж у AGM та гелевих акумуляторів, і за рахунок самої технології
Недоліки:
- висока вартість в порівнянні з AGM та гелевими акумуляторами
- потребують спеціальної системи управління зарядкою
Інші типи літій-іонних акумуляторів
Окрім LiFePO4 є і інші типи літій-іонних акумуляторів:
- Li-ion (літій-кобальт оксид, LiCoO2): найпоширеніший тип, використовується в смартфонах, ноутбуках
- LiMn2O4 (літій-марганець оксид): використовується в електроінструментах, медичному обладнанні
- NMC (літій-нікель-марганець-кобальт): поширений в електромобілях та портативній електроніці
- NCA (літій-нікель-кобальт-алюміній): використовується в електромобілях Tesla та деяких портативних пристроях.
Висновки
- Свинцево-кислотні AGM: надійні, доступна ціна, хороший вибір для більшості домашніх систем
- Гелеві акумулятори: підходять там, де необхідна глибока розрядка і довготривала робота без підзарядки, підходять для систем з частими і довгими відключеннями електроенергії
- LiFePO4: все “най-” – найдовший термін служби, найшвидша зарядка, найкраща безпечність
Рекомендації по експлуатації акумуляторів
- правильна зарядка:
- використовуйте зарядні пристрої, призначені для конкретного типу акумулятора
- уникайте перезаряду, особливо для свинцево-кислотних акумуляторів
- для літій-іонних акумуляторів підтримуйте рівень заряду між 20% і 80%
- температурний режим: зберігайте і експлуатуйте акумулятори в рекомендованому температурному діапазоні, особливо, якщо акумулятори десь на балконі, який влітку нагрівається від сонця
- глибина розряду:
- для свинцево-кислотних акумуляторів уникайте глибокого розряду (нижче 50%)
- LiFePO4 акумулятори краще переносять глибокий розряд, але краще не розряджати нижче 20%
- регулярне використання: періодично використовуйте акумулятори, не залишайте їх повністю зарядженими або розрядженими на тривалий час
- зберігання: при тривалому зберіганні підтримуйте частковий заряд (40-60%)
Рівень розряду акумулятора та його ємність
Важливий момент, котрий треба враховувати при розрахунках: розряджати акумулятор бажано максимум до 30-40% його ємності, хоча це дуже залежить від типу – гелеві цього не люблять, AGM трохи краще переживає глибокий розряд, а LiFePO4 краще інших.

Давайте порахуємо скільки реальної (або корисної) ємності буде в акумуляторі.
Наприклад, маємо AGM 12 вольт на 100 ампер/годин – отримуємо 1200 ват/годин повної ємності.
Від цих 1200 віднімаємо хоча б 30% заряду, який потрібно залишати, аби батареї в акумуляторі почувались краще – і вже маємо 800 ват/годин.
І додатково від цих 800 Вт/г віднімаємо ще втрати на роботу інвертора – це відсотків 15, і в залишку корисної або реальної ємності вже маємо 680 ват/годин.
За цим треба або слідкувати самому (якщо використовуємо схему з окремим інвертором+зарядне+акумулятор), або сам ДБЖ має відключатись автоматично при низькому заряді батареї (і буде добре, якщо ДБЖ досить інтелектуальний, аби враховувати тип акумулятору).
Зарядка акумуляторів та важливість вибору правильного ДБЖ
Отже, від того, який саме у вас тип акумулятора дуже сильно залежить те, як він має заряджатись.
Дуже корисне відео на цю тему – Чи можна заряджати LiFePo4 акуми автомобільними зарядками?
Ще один важливий нюанс при виборі акумулятору та ДБЖ – це скільки часу буде займати зарядка.
Час заряду залежить від:
- типу акумулятора: різні типи мають різний рівень швидкості зарядки, і у LiFePo4 найшвидша зарядка
- максимальний/рекомендований струм заряду:
- свинцево-кислотні AGM, мультигель та гель мають рекомендований рівень в 0.1С (1/10 ємності), тобто акумулятор в 100 ампер-годин можна заряджати максимум на 10 амперах, в такому випадку повний цикл зарядки займе 10 годин
- LiFePo4 можна заряджати на струмі 0.5С – 1С, тобто акумулятор на 100 ампер-годин можна заряджати струмом від 50 ампер, і повний цикл зарядки займе 2 години
При перевищені струму заряду батарея може перегрітись і вибухнути (проте вас покажуть по телевізору).
На струм заряду може впливати вбудована плата BMS, про яку згадував вище, бо вона може мати власні обмеження. Втім, не варто покладатись тільки на неї (тим більш, її може і не бути), а читати документацію до ДБЖ та акумулятора.
Схеми підключення акумуляторів
Див. Паралельне та послідовне з’єднання АКБ.
Паралельне підключення
Позначається на акумуляторах як P (paralel).
При такому підключенні всі плюси та всі мінуси батарей підключаються до плюса на ДБЖ. В такому випадку загальна ємність сумується, але напруга лишається такою ж самою:

Тобто, отримаємо 200 ампер/годин і 12 вольт.
Дозволяє використовувати акумулятори з різною ємністю, але може призвести до нерівномірного розряду акумуляторів.
Послідовне підключення
Позначається на акумуляторах як S (serial).
При такому підключенні мінус одного акумулятора підключається до плюса наступного. В результаті ємність залишається такою ж самою, але їхня напруга сумується:

Тобто, отримаємо 100 ампер/годин і 24 вольт.
Вимагає точного підбору акумуляторів за ємністю та станом.
12 вольт vs 24 вольти: а для чого?
Схема підключення залежить від того, який ДБЖ у вас використовується, бо ДБЖ на 12 вольт не видасть високої потужності. 1000-2000 ват потужності для таких ДБЖ, мабуть, максимум.
Наприклад, у нас є кавоварка, яка працює з напругою 220 вольт і споживає 1000 ват/годин. Маємо інвертор, до якого підключено акумулятор на 12 вольт.
В такому випадку аби забезпечити необхідну потужність у 1000 ват від інвертора до кавоварки нам потрібна сила струму у 1000W/220V=4.54 ампери. Але сила струму від акумулятора до інвертора вже буде 1000W/12V, тобто 83 ампери. Відповідно, великі втрати на передачу енергії, і потрібні більш товсті кабелі. А при використанні інвертора на 24 вольти – це було б 41.6 ампери.
Це дуже грубий приклад, але основна ідея така.
То що в результаті? І трохи про розетки.
Отже, якщо повернутись до початку цього посту:
- у нас є 4500 ват-годин на добу споживання
- ми хочемо зарядити акумулятори за умовні 2 години
Чому 2 години? Бо, по-перше, говорять, що цією зимою в найгіршому варіанті світло буде 4 години на добу, але давайте ми будемо песимістами х2, і припускати, що світло буде лише 2 години на добу.
По-друге – EcoFlow свої 2 кіловат/години заряджає менш ніж за 2 години, і хочеться побудувати щось хоча б приблизно таке ж саме.
Що ми можемо зробити, аби забезпечити себе хоча б на добу?
Варіант 1 – купити пару EcoFlow. Дорого, але надійно.
Варіант 2 – купувати ДБЖ та акумулятори. З урахування специфіки різних типів АКБ, якщо ми хочемо заряджати швидко – то нам потрібні LiFePo4.
4500 ват-годин запасу – це 375 ампер/годин при 12 вольтах – тобто, 2 акуми по 200 ампер-годин. І це якщо рахувати тільки повну ємність – без втрат на перетворення і “залишковий запас” акумулятора, аби не розряджати його повністю.
А аби їх зарядити за 2 години – нам потрібен ДБЖ/зарядне, яке буде видавати 100 ампер! І таке зарядне потрібне на кожен акумулятор окремо!
Таке, звісно, реалізувати можна, але я не зустрічав таких зарядних пристроїв. До того ж, аби витримати таку силу струму будуть потрібні ну прям дуже товсті кабелі.
Тому єдине, що можна зробити – це підключити акумулятори послідовно, аби мати напругу у 24 вольти (в EcoFlow, наприклад, батареї працюють на 48 вольтах – як раз для того, аби знизити необхідну силу струму).
А маючи 24 вольти – ми можемо заряджати їх при струмі в 50 ампер, що вже більш реально, і такі зарядні пристрої знайти можна.
Тоді будемо мати 50 ампер * 24 вольти == 1200 ват потужності, а повна зарядка акумуляторів займе ~4 години. А насправді навіть більше, бо насправді “профіль зарядки” виглядає не рівномірно. Див. ось цей момент у відео – там людина малює графіки заряду.
В такому випадку, якщо ми беремо собі ліміт в 50 ампер – то варіанти будуть такі:
- зарядне на 50 ампер + 2 акумулятори по 200 А/г послідовно: отримуємо ~2000 ват/годин, зарядка 4 години
- зарядне на 50 ампер + 2 акумулятори по 100 А/г послідовно: отримуємо ~1000 ват/годин, зарядка 2 години

І аби забезпечити свої 4500 ват/годин запасу на добу, нам потрібно або два комплекти з двома акумуляторами по 200 А/г – які будуть заряджатись 4 години, або 4 комплекти з двома акумуляторами по 100 А/г – які будуть заряджатись за 2 дві години.

Але навіть якщо ми підемо на зборку 4-х комплектів – нам їх потрібно заряджати одночасно!
А маючи 1200 ват потужності через розетку на зарядку одного такого блоку батарей в розетці будемо мати 1200/220 = 5.4 ампер, що в принципі нормально, бо стандартно розетки розраховані на 16 ампер максимум – і це треба мати на увазі.
Тобто в одну розетку ми можемо максимум одночасно включити 2 комплекти – сила струму через розетку буде близько 10 ампер.
А включати одночасно 2 EcoFlow в один блок розеток або навіть в одній кімнаті все ж не варто: один EcoFlow при зарядці споживає до 2000 ват, тобто 9 ампер з розетки, до якої від підключений.
Це грубі розрахунки, але плюс-мінус виходить так.
Підсумки і варіанти
А тепер давайте порахуємо вартість варіантів на ~2000 Вт/годину (але пам’ятаємо, що ми нарахували необхідний добовий запас в 4500 Вт/г).
Строк служби далі – доволі умовна одиниця, бо батарея не вмре повністю, а просто втратить частину своєї ємності.
EcoFlow на 2000 Вт/годин з Li-ion батареями
Найкращій варіант з усіх точок зору, окрім ціни:
-
- ціна: ~60.000 гривень
- строк служби: враховуючи заявлені 800 циклів заряду, при щоденних відключеннях електрики пропрацює ~2-3 роки
- плюси:
- просто працює
- компактні, можна перенести
- швидко заряджається
- мінуси: ціна
Якщо ж брати відразу з LiFePo4 батареями (нагадаю – близько 100.000 гривень на сьогодні) – то це гарантовано років 5 і більше роботи.
Або за 105.000 взагалі відразу взяти EcoFlow DELTA Pro на 3600 Вт/годин з тими ж LiFePo4.
Ну і не EcoFlow єдиним – подібних рішень багато. Просто в мене вона є, тому пишу про неї.
ДБЖ з зовнішнім LiFePo4 акумулятором на 200 ампер/годин (~2000 Вт/годин)
Непоганий варіант, але не транспортабельний і за ціною може вийти не набагато дешевше за EcoFlow. Втім, прослужить скоріш за все довше за EcoFlow з Li-ion:
-
- ціна:
- ДБЖ: 10-15 тисяч гривень
- акумулятор: від 35 до 50 тисяч
- строк служби: враховуючи ~3000 циклів заряду, при щоденних відключеннях електрики – пропрацює ~4-5 років
- плюси:
- трохи дешевший за EcoFlow
- при правильно підібраному зарядному пристрої – швидко заряджається
- достатньо надійно і безпечно
- мінуси:
- швидкість заряду: залежить від зарядного, але навряд чи вам вдасться “залити” його повністю за 2-3 години, навіть використовуючи LiFePo4 (або брати менші за ємністю акумулятори в більшій кількості – а це вплине на загальну вартість системи)
- не можна просто так перенести в інше приміщення
- потребує додаткових знань, додаткового обслуговування, моніторингу, обережності
- ціна:
Можна замість LiFePo4 взяти AGM-акумулятори – вийде в пару раз дешевше, але вони і заряджатись будуть в кілька раз довше, і строк служби буде в кілька раз меншим.
Приклад ДБЖ – LPE-B-PSW-1500VA+, і акумулятора – Kepworth LiFePO4 12V/200AH.
Зарядні станції від “майстрів” на 2000 Вт/годин
Найбільш небезпечний, проте самий бюджетний варіант:
-
- ціна: від 20-25 тисяч гривень
- строк служби: на 1-2 роки можна розраховувати, але навряд чи більше (скоріш менше, і тут вже саме про те, скілька така станція пропрацює взагалі, а не втрата ємності батареї)
- плюси:
- компактні, можна перенести
- швидко заряджається
- мінуси:
- надійність – може зламатись в будь-який момент
- безпека і пожежонебезпечність: відносно до EcoFlow або ДБЖ з LiFePo4 акумулятором доволі (дуже?) небезпечне рішення
- шумні
В цілому, це, мабуть, все.
І капелька про павербанки
Ну і павербанки ніхто не відміняв.
Це мій запас, який зробив ще в кінці минулого року:

Тут:
- дві зарядні станції Kseni по 160.000 mAh (до них інвертор на 500 ват)
- два павербанка FutureSolar по 160.000 mAh (до них два інвертори на 150 ват кожен – телевізор від них працює без проблем)
- один павербанк ChinaNoName на 60.000 mAh
- два павербанка ChinaNoName по 50.000 mAh
- два павербанка Baseus по 30.000 mAh
- два павербанка Xiomi по 20.000 mAh
Живити через інвертор від павербанок всякі ноутбуки/монітори/світильники можна спокійно, а от холодильник і котел – вже тільки від ДБЖ/EcoFlow. Втім тут ще пам’ятаємо, що сам інвертор буде з’їдати частину енергії (хоча ноутбук можна напряму, якщо потужність павербанка дозволяє).
Як рахувати ємність павербанка?
Тут вже зовсім коротенько.
Ємність на всіх банках вказується з розрахунком на 3.7 вольти, але по факту на виході більшість видає 5 вольт. Якщо через автомобільний “прикурювач” – то там 12 вольт:

Формула:
мА/г * Вольти / 1000
Тепер рахуємо:
- павербанк з 60.000 номінальної ємності при 3.7 вольти – це 60.000 (міліампер/годин) * 3.7 вольти == 222 ват-години
- той же павербанк при 5 вольтах на виході – це вже 222 (ват-години) / 5 (вольт) == 44.400 mAh
- а він жеж, живлячи інвертор на 12 вольтах – 18.500 mAh
Див. How many times can I recharge a cell phone with a power bank?
Такі діла.
P.S. Як завжди – дякую Артему aka @artygan за допомогу в деяких питаннях)
![]()








 Маємо API-сервіс в Kubernetes, який періодично видає 502, 503, 504 помилки.
Маємо API-сервіс в Kubernetes, який періодично видає 502, 503, 504 помилки.







































 З часом, коли проект росте, то рано чи пізно постане питання про апгрейд версій пакетів, модулів, чартів.
З часом, коли проект росте, то рано чи пізно постане питання про апгрейд версій пакетів, модулів, чартів.













 is in progress")
 is in progress")
























