 On our AWS Elastic Kubernetes Service Dev cluster, we got a couple of namespaees hanging i nthe Termination state.
On our AWS Elastic Kubernetes Service Dev cluster, we got a couple of namespaees hanging i nthe Termination state.
Contents
“401 Unauthorized”, response: “Unauthorized”
Remembering a similar issue where the root cause was the metrics-server (see the Kubernetes: namespace hangs in Terminating and metrics-server non-obviousness post for details), the first thing I did was to check its logs:
[simterm]
$ kk -n kube-system logs -f metrics-server-5f956b6d5f-r7v8f ... E0416 11:54:47.022378 1 manager.go:111] unable to fully collect metrics: unable to fully scrape metrics from source kubelet_summary:ip-10-21-39-158.us-east-2.compute.internal: unable to fetch metrics from Kubelet ip-10-21-39-158.us-east-2.compute.internal (ip-10-21-39-158.us-east-2.compute.internal): request failed - "401 Unauthorized", response: "Unauthorized" ...
[/simterm]
request failed – “401 Unauthorized”, response: “Unauthorized” – aha…
And kubectl top node for this node also not working:
[simterm]
$ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ... ip-10-21-39-158.us-east-2.compute.internal <unknown> <unknown> <unknown> <unknown>
[/simterm]
“Kubelet stopped posting node status”
Next, I’ve check logs on the kube-controller-manager in the AWS CloudWatch:
node_lifecycle_controller.go:1127] node ip-10-21-39-158.us-east-2.compute.internal hasn’t been updated for 666h59m43.490707998s. Last Ready is: &NodeCondition{Type:Ready,Status:Unknown,LastHeartbeatTime:2021-03-11 06:02:06 +0000 UTC,LastTransitionTime:2021-03-11 05:51:24 +0000 UTC,Reason:NodeStatusUnknown,Message:Kubelet stopped posting node status.,}
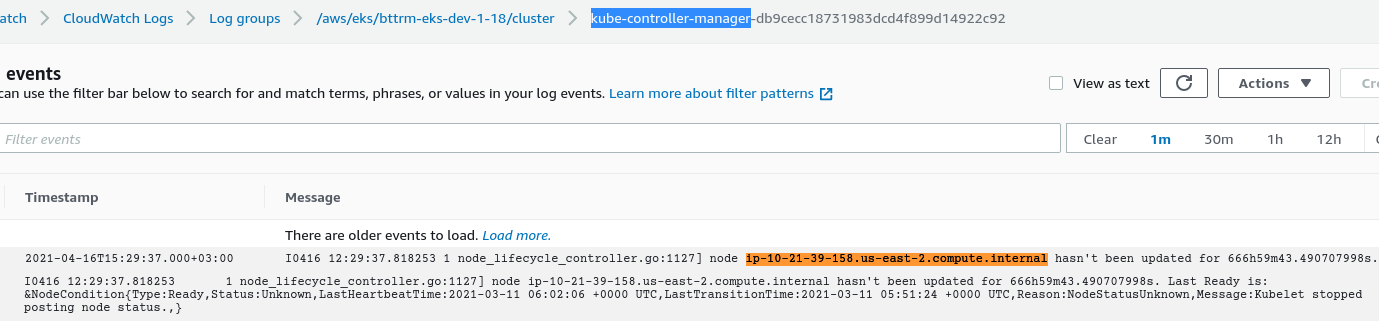
The error found here was the “Reason:NodeStatusUnknown,Message:Kubelet stopped posting node status“.
Let’s check our Prometheus Kubernetes metrics – kube_node_status_condition{condition="Ready",status="true",env=~".*dev.*"} == 0:

Also, we have an alert for such situations:
- alert: KubernetesNodeNotReady
expr: kube_node_status_condition{condition="Ready", status="true", env=~".*prod.*"} == 0
for: 15m
labels:
severity: warning
annotations:
summary: "Kubernetes node is not in the Ready state"
description: "*Kubernetes cluster*: `{{ $labels.ekscluster }}`\nNode `{{ $labels.node }}`\nEC2 instance: `{{ $labels.instance }}` has been unready for a long time"
tags: kubernetes, aws
But it works for the Production cluster only.
kubelet: use of closed network connection
Let’s go further, and log in to a WorkerNode with SSH to check kubelet‘s logs there:
[simterm]
[root@ip-10-21-39-158 ec2-user]# journalctl -u kubelet ... Mar 18 11:27:25 ip-10-21-39-158.us-east-2.compute.internal kubelet[584]: E0318 11:27:25.616937 584 webhook.go:111] Failed to make webhook authenticator request: Post https://676***892.gr7.us-east-2.eks.amazonaws.com/apis/authentication.k8s.io/v1/tokenreviews: write tcp 10.21.39.158:33930->10.21.40.129:443: use of closed network connection Mar 18 11:27:25 ip-10-21-39-158.us-east-2.compute.internal kubelet[584]: E0318 11:27:25.617339 584 server.go:263] Unable to authenticate the request due to an error: Post https://676***892.gr7.us-east-2.eks.amazonaws.com/apis/authentication.k8s.io/v1/tokenreviews: write tcp 10.21.39.158:33930->10.21.40.129:443: use of closed network connection ...
[/simterm]
You can google a lot discussions with the “kubelet use of closed network connection” query, for example here>>>, but I have no time to dive into it, so let’s just try to:

AWS was not able to validate the provided access credentials
But even after retsarting kubelet, it won’t work saying “AWS was not able to validate the provided access credentials“:
[simterm]
... Apr 19 10:06:23 ip-10-21-39-158.us-east-2.compute.internal kubelet[19492]: I0419 10:06:23.691844 19492 aws.go:1289] Building AWS cloudprovider Apr 19 10:06:23 ip-10-21-39-158.us-east-2.compute.internal kubelet[19492]: F0419 10:06:23.740946 19492 server.go:274] failed to run Kubelet: could not init cloud provider "aws": error finding instance i-04e759611b9075cd2: "error listing AWS instances: \"AuthFailure: AWS was not able to validate the provided access credentials\\n\\tstatus code: 401, request id: 81dc17d9-ceae-47b9-ba74-6903a9a1be87\"" ...
[/simterm]
Well…
Time to reboot the whole EC2:
[simterm]
[root@ip-10-21-39-158 ec2-user]# reboot
[/simterm]
And now everything is working:
[simterm]
... Apr 19 09:05:32 ip-10-21-39-158.us-east-2.compute.internal kubelet[3901]: I0419 09:05:32.667289 3901 aws.go:1289] Building AWS cloudprovider Apr 19 09:05:32 ip-10-21-39-158.us-east-2.compute.internal kubelet[3901]: I0419 09:05:32.827269 3901 tags.go:79] AWS cloud filtering on ClusterID: bttrm-eks-dev-1-18 Apr 19 09:05:32 ip-10-21-39-158.us-east-2.compute.internal kubelet[3901]: I0419 09:05:32.836393 3901 dynamic_cafile_content.go:167] Starting client-ca-bundle::/etc/eksctl/ca.crt Apr 19 09:05:32 ip-10-21-39-158.us-east-2.compute.internal kubelet[3901]: I0419 09:05:32.921831 3901 server.go:647] --cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to / ...
[/simterm]
Check kubectl top node once again:
[simterm]
$ kubectl top node ip-10-21-39-158.us-east-2.compute.internal NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-21-39-158.us-east-2.compute.internal 102m 5% 502Mi 15%
[/simterm]
Done.
![]()