Де в топі з великим відривом бачимо дві адреси – 10.0.3.111 та 10.0.2.135, які нагнали аж 28995460061 байт трафіку.
Loki components та трафік
Перевіряємо, що ж це за поди в Kubernetes, і заодно знаходимо відповідні WorkerNodes/EC2.
Спершу 10.0.3.111:
[simterm]
$ kk -n dev-monitoring-ns get pod -o wide | grep 10.0.3.111
loki-backend-0 1/1 Running 0 22h 10.0.3.111 ip-10-0-3-53.ec2.internal <none> <none>
[/simterm]
Та 10.0.2.135:
[simterm]
$ kk -n dev-monitoring-ns get pod -o wide | grep 10.0.2.135
loki-read-748fdb976d-grflm 1/1 Running 0 22h 10.0.2.135 ip-10-0-2-173.ec2.internal <none> <none>
[/simterm]
І вже тут я згадав, що саме 31-го липня включив алерти в Loki, які обробляються як раз в поді backend, де крутиться компонент Ruler (раніше він був у поді read).
Тобто левова частина трфіку відбувається саме між Read та Backend подами.
Окреме питання що саме там в такій кількості передається, але поки треба вирішити проблему с витратами на трафік.
Перевіримо в яких AvailabilityZones знаходяться Kubernetes WorkerNodes.
Інстанс ip-10-0-3-53.ec2.internal, де крутиться под з Backend:
[simterm]
$ kk get node ip-10-0-3-53.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1b
[/simterm]
Та ip-10-0-2-173.ec2.internal, де знаходиться под з Read:
[simterm]
$ kk get node ip-10-0-2-173.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
Перший варіант – це вказати Kubernetes Scheduler, що ми хочемо поді Read розташовувати на тій самій WorkerNode, де є поди з Backend. Для цього можемо використати podAffinity.
Перевірямо лейбли Backend:
[simterm]
$ kk -n dev-monitoring-ns get pod loki-backend-0 --show-labels
NAME READY STATUS RESTARTS AGE LABELS
loki-backend-0 1/1 Running 0 23h app.kubernetes.io/component=backend,app.kubernetes.io/instance=atlas-victoriametrics,app.kubernetes.io/name=loki,app.kubernetes.io/part-of=memberlist,controller-revision-hash=loki-backend-8554f5f9f4,statefulset.kubernetes.io/pod-name=loki-backend-0
[/simterm]
Тож для Reader можемо задати podAntiAffinity з labelSelector=app.kubernetes.io/component=backend – тоді Reader буде “тягнутись” до тії ж AvailabilityZone, де запущено Backend.
Інший варіант – через nodeAffinity, і в Expressions для обох Read та Backend вказати лейблу з бажаною AvailabilityZone.
Спробуємо з preferredDuringSchedulingIgnoredDuringExecution, тобто “soft limit”:
$ kk -n dev-monitoring-ns get pod -l app.kubernetes.io/component=read -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-read-d699d885c-cztj7 1/1 Running 0 50s 10.0.2.181 ip-10-0-2-220.ec2.internal <none> <none>
loki-read-d699d885c-h9hpq 0/1 Running 0 20s 10.0.2.212 ip-10-0-2-173.ec2.internal <none> <none>
[/simterm]
Та зони інстансів:
[simterm]
$ kk get node ip-10-0-2-220.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
$ kk get node ip-10-0-2-173.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
[/simterm]
Окей, тут все є, а що там Backend?
[simterm]
$ kk get nod-n dev-monitoring-ns get pod -l app.kubernetes.io/component=backend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-backend-0 1/1 Running 0 75s 10.0.3.254 ip-10-0-3-53.ec2.internal <none> <none>
Деплоїмо ще раз, і тепер под з Бекендом застряг у статусі Pending:
[simterm]
$ kk -n dev-monitoring-ns get pod -l app.kubernetes.io/component=backend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-backend-0 0/1 Pending 0 3m39s <none> <none> <none> <none>
[/simterm]
Чому? Дивимось Events:
[simterm]
$ kk -n dev-monitoring-ns describe pod loki-backend-0
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 34s default-scheduler 0/3 nodes are available: 1 node(s) didn't match Pod's node affinity/selector, 2 node(s) had volume node affinity conflict. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling..
[/simterm]
Спешу подумав, що на WokrerkNdoes вже маємо максимум подів – 17 штук на t3.medium.
Тоді що – EBS? Часта проблема, коли EBS в одній AvailabilityZone, а Pod запускається в іншій.
Знаходимо Volume Бекенду – там йому підключаються алерт-рули для Ruler:
[simterm]
...
Volumes:
...
data:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: data-loki-backend-0
ReadOnly: false
...
[/simterm]
Знаходимо відповідний Persistent Volume:
[simterm]
$ kubectl k -n dev-monitoring-ns get pvc data-loki-backend-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-loki-backend-0 Bound pvc-b62bee0b-995e-486b-9f97-f2508f07a591 10Gi RWO gp2 15d
[/simterm]
І AvailabilityZone цього EBS:
[simterm]
$ kk -n dev-monitoring-ns get pv pvc-b62bee0b-995e-486b-9f97-f2508f07a591 -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1b
[/simterm]
Так і є – диск у нас в зоні us-east-1b, а под намагаємось запустити под в зоні us-east-1a.
Що можемо зробити – це або Readers запускати в зоні 1b, або видалити PVC для Backend, і тоді при деплої він створить новий PV та EBS в зоні 1a.
Так як в волюмі ніяк даних нема і для Ruler правила створються з ConfigMap, то простіше просто видалити PVC:
$ kk -n dev-monitoring-ns delete pod loki-backend-0
pod "loki-backend-0" deleted
[/simterm]
Перевіряємо, що PVC створений:
[simterm]
$ kk -n dev-monitoring-ns get pvc data-loki-backend-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-loki-backend-0 Bound pvc-5b690c18-ba63-44fd-9626-8221e1750c98 10Gi RWO gp2 14s
[/simterm]
І його локація тепер:
[simterm]
$ kk -n dek -n dev-monitoring-ns get pv pvc-5b690c18-ba63-44fd-9626-8221e1750c98 -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
[/simterm]
І сам под теж запустився:
[simterm]
$ kk -n dev-monitoring-ns get pod loki-backend-0
NAME READY STATUS RESTARTS AGE
loki-backend-0 1/1 Running 0 2m11s
[/simterm]
Результати трафіку
Робив це в п’ятницю, і на понеділок маємо результат:
Все вийшло, як і планувалось – Cross AvailabilityZone трафік тепер майже на нулі.
Оновлював вчора Arch Linux, і за 9 років корисування ціюєю системою вперше зіткнувся с помилкою, коли після ребуту система не змогла підключити диск:
ERROR: device UUID not found.
mount: /new_root: can’t find UUID.
ERROR: Failed to mount UUID on real root.
You are now being dropped into an emergency shell.
В принципі проблема ясна – або змінився UUID диска, або “щось пішло не так” з ядром.
Трапилось це через те, що під час апргейду в /tmp закінчилось місце, і mkinitcpio не зміг зібрати нове ядро.
Завантажуємость с USB, і будемо пробувати фіксити.
Першим перевіряємо, чи правильний UUID вказано в fstab.
Перевіряємо розділи:
[simterm]
[root@archiso ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 693.5M 1 loop /run/archiso/airootfs
sda 8:0 1 14.3G 0 disk
├─sda1 8:1 1 798M 0 part
└─sda2 8:2 1 15M 0 part
nvme0n1 259:0 0 953.9G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part
├─nvme0n1p2 259:2 0 900G 0 part
└─nvme0n1p3 259:3 0 53.4G 0 part
[/simterm]
/dev/nvme0n1p2 – мій рутовий роздил.
Підключаємо його:
[simterm]
[root@archiso ~]# mount /dev/nvme0n1p2 /mnt/
[/simterm]
Перевіряємо UUID в /etc/fstab старої системи:
[simterm]
[root@archiso ~]# cat /mnt/etc/fstab
# Static information about the filesystems.
# See fstab(5) for details.
# <file system> <dir> <type> <options> <dump> <pass>
# /dev/nvme0n1p2
UUID=31268b66-5fca-44f6-8e22-acc281026eaf / ext4 rw,relatime 0 1
Зараз маємо VictoriaMetrics + Grafana на звичайному EC2-інстансі, запущені з Docker Compose – то був Proof of Concept, прийшов час запускати “по-дорослому” – в Kubernetes, і всі конфіги вже винести в GitHub.
Використовувати будемо саме victoria-metrics-k8s-stack, який “під капотом” запустить VictoriaMetrics Operator, Grafana та kube-state-metrics, див. dependencies.
Матеріал вийшов досить великий, але наче описав всі цікаві моменти по розгортанню повноцінного стеку моніторингу з VictoriaMetrics Kubernetes Monitoring Stack.
UPD: робив документацію по нашому моніторингу, вийшла ось така схема того, про що буде в цьому пості:
подивитись і подумати, як запускати існуючі експортери – частина мають чарти, але ми маємо і самописні (див. – Prometheus: GitHub Exporter – пишемо власний експортер для GitHub API), тож їх треба буде пушити в Elastic Container Service і думати, як звідти пулити і запускати в Kubernetes
секрети для моніторингу – паролі Grafana і все таке інше
IRSA для експортерів – створити IAM Policy та ролі для ServiceAccounts
перенесення алертів
конфіг для VMAgent – збір метрик с експортерів
запустити Grafana Loki
Стосовно логів – так, нещодавно вийшла VictoriaLogs, але вона ще в preview, не має підтримки збегірання в AWS S3, не має інтеграції з Grafana, та й взагалі поки не хочеться витрачати зайвий час, а Loki я вже більш-менш знаю. Можливо, запущу VictoriaLogs окремо, “погратись-подивитись”, а коли її вже інтегрують з Grafana – то заміню Loki на VictoriaLogs, бо зараз ми вже маємо дашборди з графіками з логів Loki.
Ще окремо треба буде глянути як там з persistance у VictoriaMetrics в Kubernetes – розмір, типи дисків і так далі. Можливо, подумати про їхні бекапи (VMBackup?).
На існуючому моніторингу маємо досить багато всього:
Яке взагалі деплоїти? Через AWS CDK та його cluster.add_helm_chart() – чи робити окремий степ в GitHub Actions з Helm?
Нам в будь-якому разі буде потрібен CDK – створити сертифікати з ACM, Lambda для логів в Loki, S3-корзини, IAM-ролі для експортерів тощо.
Але чомусь зовсім не хочеться тягнути в CDK деплой чартів, бо краще всеж відокремити деплой інфрастуктурних об’єктів від деплою самого стеку моніторинга.
Добре – зробимо окремо: CDK буде створювати ресурси в AWS, Helm буде деплоїти чарти. Чи чарт? Може – просто зробити власний чарт, а йому вже сабчартами підключити і VictoriaMetrics Stack, и експортери? Виглядає наче непоганою ідею. “Мінуси будуть?” (с)
Також нам треба буде створити Kubernetes Secrets та ConfigMaps з конфігами для VMAgent, Loki (див. Loki: збір логів з CloudWatch Logs з використанням Lambda Promtail), Alertmanager тощо. Робити їх з Kustomize? Чи просто YAML-маніфестами в директорії templates нашого чарту?
Подивимось. Поки думаю, що таки Kustomize.
Тепер по порядку – що треба буде зробити:
запустити експортери
підключити конфіг до VMAgent, щоб почати збирати метрики з експортерів
перевірити, як налаштовуються ServiceMonitors (VMServiceScrape у VictoriaMetrics)
$ helm repo add grafana https://grafana.github.io/helm-charts
"grafana" has been added to your repositories
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
[/simterm]
І саму VictoriaMetrics:
[simterm]
$ helm repo add vm https://victoriametrics.github.io/helm-charts/
"vm" has been added to your repositories
$ helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "vm" chart repository
...Successfully got an update from the "grafana" chart repository
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
[/simterm]
Перевіряємо версії чарту victoria-metrics-k8s-stack:
[simterm]
$ helm search repo vm/victoria-metrics-k8s-stack -l
NAME CHART VERSION APP VERSION DESCRIPTION
vm/victoria-metrics-k8s-stack 0.17.0 v1.91.3 Kubernetes monitoring on VictoriaMetrics stack....
vm/victoria-metrics-k8s-stack 0.16.4 v1.91.3 Kubernetes monitoring on VictoriaMetrics stack....
vm/victoria-metrics-k8s-stack 0.16.3 v1.91.2 Kubernetes monitoring on VictoriaMetrics stack....
...
[/simterm]
Всі values можна взяти так:
[simterm]
$ helm show values vm/victoria-metrics-k8s-stack > default-values.yaml
$ kk -n dev-monitoring-ns get pod
NAME READY STATUS RESTARTS AGE
victoria-metrics-k8s-stack-grafana-76867f56c4-6zth2 0/3 Init:0/1 0 5s
victoria-metrics-k8s-stack-kube-state-metrics-79468c76cb-75kgp 0/1 Running 0 5s
victoria-metrics-k8s-stack-prometheus-node-exporter-89ltc 1/1 Running 0 5s
victoria-metrics-k8s-stack-victoria-metrics-operator-695bdxmcwn 0/1 ContainerCreating 0 5s
vmsingle-victoria-metrics-k8s-stack-f7794d779-79d94 0/1 Pending 0 0s
[/simterm]
Та Ingress:
[simterm]
$ kk -n dev-monitoring-ns get ing
NAME CLASS HOSTS ADDRESS PORTS AGE
victoria-metrics-k8s-stack-grafana <none> monitoring.dev.example.co k8s-devmonit-victoria-***-***.us-east-1.elb.amazonaws.com 80 6m10s
[/simterm]
Чекаємо оновлення DNS, або просто відкриваємо доступ до Grafana Service – знаходимо його:
[simterm]
$ kk -n dev-monitoring-ns get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
victoria-metrics-k8s-stack-grafana ClusterIP 172.20.162.193 <none> 80/TCP 12m
...
[/simterm]
І виконуємо port-forward:
[simterm]
$ kk -n dev-monitoring-ns port-forward svc/victoria-metrics-k8s-stack-grafana 8080:80
Forwarding from 127.0.0.1:8080 -> 3000
Forwarding from [::1]:8080 -> 3000
[/simterm]
В браузері переходимо до http://localhost:8080/
Username по дефолту admin, отримуємо його згенерований пароль:
Отже, зробимо такий собі “umbrella chart“, який буде запускати і сам стек VictoriaMetrics, і експортери, і створювати всі необхідні Secrets/ConfgiMaps тощо.
Як воно буде працювати?
створимо чарт
йому в dependencies вписуємо VictoriaMetrics
через тіж dependencies додамо запуск екпортерів
в каталозі templates опишемо наші кастомні ресурси (ConfigMaps, VMRules, etc)
Потім всі загальні параметри винесемо в якійсь common-values.yaml, а значення, которі будуть різні для Dev/Prod – по окремим файлам.
Оновлюємо наш values – додаємо блок victoria-metrics-k8s-stack, бо він у нас тепер буде сабчартом:
victoria-metrics-k8s-stack:
# no need yet
victoria-metrics-operator:
serviceAccount:
create: true
# to confugire later
alertmanager:
enabled: true
# to confugire later
vmalert:
annotations: {}
enabled: true
# to confugire later
vmagent:
enabled: true
grafana:
enabled: true
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/scheme: internet-facing
hosts:
- monitoring.dev.example.co
Загружаємо чарти з dependencies:
[simterm]
$ helm dependency update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "vm" chart repository
...Successfully got an update from the "grafana" chart repository
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
Saving 1 charts
Downloading victoria-metrics-k8s-stack from repo https://victoriametrics.github.io/helm-charts/
Deleting outdated charts
[/simterm]
Перевіряємо каталог charts:
[simterm]
$ ls -1 charts/
victoria-metrics-k8s-stack-0.17.0.tgz
[/simterm]
І робимо helm template нового Helm-чарту з нашим VictoriaMetrics Stack, щоб перевірити, що сам чарт, його dependencies і values працюють:
Service Invalid value: must be no more than 63 characters
Деплоїмо новий:
[simterm]
$ helm -n dev-monitoring-ns upgrade --install atlas-victoriametrics . -f values/dev/atlas-monitoring-dev-values.yaml
Release "atlas-victoriametrics" does not exist. Installing it now.
Error: 10 errors occurred:
* Service "atlas-victoriametrics-victoria-metrics-k8s-stack-kube-controlle" is invalid: metadata.labels: Invalid value: "atlas-victoriametrics-victoria-metrics-k8s-stack-kube-controller-manager": must be no more than 63 characters
$ helm -n dev-monitoring-ns upgrade --install atlas-victoriametrics . -f values/dev/atlas-monitoring-dev-values.yaml
Release "atlas-victoriametrics" has been upgraded. Happy Helming!
...
[/simterm]
Перевіряємо ресурси:
[simterm]
$ kk -n dev-monitoring-ns get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/atlas-victoriametrics-grafana ClusterIP 172.20.93.0 <none> 80/TCP 0s
service/atlas-victoriametrics-kube-state-metrics ClusterIP 172.20.113.37 <none> 8080/TCP 0s
...
Тепер нам треба налаштувати VMAgent, щоб він почав збирати ці метрики з цього експортеру.
Збір метрик з експортерів: VMAgent && scrape_configs
Звична з Kube Prometheus Stack схема – це просто включити servicemonitor.enabled=true в вальюсах чарту експотера, і Prometheus Operator створить ServiceMonitor та почне збирати метрики.
Натомість у VictoriaMetrics є власний аналог – VMServiceScrape, який можна створити з маніфесту, і йому вказати з якого ендпоінту збирати метрики. До того ж, VictoriaMetrics вміє створювати VMServiceScrape з існуючих ServiceMonitor, але це потребує установки самого ServiceMonitor CRD.
Також ми можемо передати список таргетів через inlineScrapeConfig або additionalScrapeConfigs, див. VMAgentSpec.
Скоріш за все, у нас поки що буде inlineScrapeConfig, бо конфіг не надто великий.
Ще цікаво взагалі глянути VMAgent values.yaml – наприклад, там є дефолтні scrape_configs.
Ще один нюанс, которий треба мати на увазі – VMAgent не перевіряє конфіги таргетів, тобто якщо є помилка в YAML – то VMAgent просто ігнорує зміни, і не перезавантажує файл, при цьому в лог нічого не пише.
VMServiceScrape
Спочатку створимо VMServiceScrape вручну, щоб подивитись як воно взагалі працює.
$ kubectl apply -f vmsvcscrape.yaml
vmservicescrape.operator.victoriametrics.com/prometheus-cloudwatch-exporter-vm-scrape created
[/simterm]
Перевіряємо всі vmservicescrape – тут вже є пачка дефолтних, які створив сам VictoriaMetrics Operator:
[simterm]
$ kk -n dev-monitoring-ns get vmservicescrape
NAME AGE
prometheus-cloudwatch-exporter-vm-scrape 6m45s
vm-k8s-stack-apiserver 4d22h
vm-k8s-stack-coredns 4d22h
vm-k8s-stack-grafana 4d22h
vm-k8s-stack-kube-controller-manager 4d22h
...
[/simterm]
Конфіг VMAgent створюється в поді у файл /etc/vmagent/config_out/vmagent.env.yaml.
І тепер маємо побачити метрики в самій VictoriaMetrics.
Відкриваємо порт:
[simterm]
$ kk -n dev-monitoring-ns port-forward svc/vmsingle-vm-k8s-stack 8429
[/simterm]
В браузері заходимо на http://localhost:8429/vmui/ і для перевірки робимо запит на будь-яку метрику від CloudWatch Exporter:
Добре – побачили, як вручну створити VMServiceScrape. Але що там з автоматизацією цього процесу? Бо якось не дуже хочеться через Kustomize свторювати VMServiceScrape для кожного сервісу.
VMServiceScrape з ServiceMonitor та VictoriaMetrics Prometheus Converter
Тож як вже писалось, для того, щоб в кластері створився об’єкт ServiceMonitor нам потрібен Custom Resource Definition з ServiceMonitor.
Можемо встановити його прямо з маніфесту в репозиторії kube-prometheus-stack:
[simterm]
$ kubectl apply -fhttps://raw.githubusercontent.com/prometheus-community/helm-charts/main/charts/kube-prometheus-stack/charts/crds/crds/crd-servicemonitors.yaml
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
[/simterm]
Оновлюмо наш values – додаємо serviceMonitorenabled=true:
І у вальюсах victoria-metrics-k8s-stack додаємо параметр operator.disable_prometheus_converter=false:
victoria-metrics-k8s-stack:
fullnameOverride: "vm-k8s-stack"
# no need yet
victoria-metrics-operator:
serviceAccount:
create: true
operator:
disable_prometheus_converter: false
...
Деплоїмо та перевіряємо, чи створено servicemonitor:
[simterm]
$ kk -n dev-monitoring-ns get servicemonitors
NAME AGE
atlas-victoriametrics-prometheus-cloudwatch-exporter 2m22s
[/simterm]
І автоматом мав з’явитись vmservicescrape:
[simterm]
$ kk -n dev-monitoring-ns get vmservicescrape
NAME AGE
atlas-victoriametrics-prometheus-cloudwatch-exporter 2m11s
...
[/simterm]
Глянемо targets:
Все є.
Єдиний тут нюанс в тому, что при видалені ServiceMonitor – відповідний vmservicescrape залишиться. Плюс сама необхідність в становленні стороннього CRD, який з часом треба буде якось оновлювати, бажано автоматично.
inlineScrapeConfig
Найбільш мабуть простий варіант – це описати конфіг через inlineScrapeConfig прямо в values нашого чарту:
Більш безпечний варіант, якщо в параметрах є якісь токени/ключі доступу, але потребує створення окремого об’єкту Kubernetes Secret.
В принципі не проблема, бо ConfigMaps/Secrets все одно доведеться створювати, і якщо захочется винести конфіг таргетів окремим файлом – то, скоріш за все, перероблю на additionalScrapeConfigs.
Зараз створимо вручну, просто глянути як воно буде працювати – беремо приклад прямо з документації:
Якщо з дашбордами все більш-менш просто, то з Data Sources є питання: як в них передавати якісь секрети? Наприклад – для датасорсу Sentry треба задати токен, який в вальюсах чарту світити зовсім не хочеться, бо дані в GitHub ми не шифруємо, хоч репозиторії і приватні (див. git-crypt – на минулому проекті був, в приципі робоче рішення).
Давайте спершу поглянемо як воно працює взагалі, потім подумаємо, як нам передати токен.
Будемо додавати Senrty Data Source, див. grafana-sentry-datasource. Токен вже маємо – створено в sentry.io > User settings > User Auth Tokens.
В вальюси Grafana додаємо plugins, де вказуємо ім’я плагіну grafana-sentry-datasource (значення поля type в документації вище) і описуємо блок additionalDataSources з полем secureJsonData, в якому вказуємо сам токен:
при деплої AWS CDK взяти значення у змінну через os.env("SECRET_NAME_VAR") і створити секрет в AWS Secrets Manager
в templates нашого чарту створити SecretProviderClass з полем secretObjects.secretName для створення Kubernetes Secret
При запуску поду з Grafana вона цей секрет підключить до поду:
[simterm]
$ kk -n dev-monitoring-ns get pod atlas-victoriametrics-grafana-64d9db677-dlqfr -o yaml
...
envFrom:
- secretRef:
name: grafana-datasource-sentry-token
...
[/simterm]
І передасть значення до самої Grafana.
Окей, це може працювати, хоча виглядає трохи заплутано.
Але є ще один варіант – з sidecar.datasources.
Kubernetes Secret для всього Data Source і sidecar.datasources
Є другий варіант – створювати дата-сорси через sidecar container: можемо створити Kubernetes Secret з потрібною labels, і в цьому сікреті додати датасорс. Див. Sidecar for datasources
В принципі – цілком робоча схема: створити маніфест секрету в каталозі templates, і при виклику helm install в GitHub Actions передати значення з --set, а значення взяти з GitHub Actions Secrets. І виглядає простішою. Спробуємо.
У файлу templates/grafana-datasources-secret.yaml описуємо Kubernetes Secret:
Для створення дашборд через Helm-чарт маємо аналогічний до grafana-sc-datasources сайдкар-контейнер grafana-sc-dashboard, який буде перевіряти всі ConfigMaps з лейблою, і підключати їх до поду. Див. Sidecar for dashboards.
Майте на увазі рекомендацію:
A recommendation is to use one configmap per dashboard, as a reduction of multiple dashboards inside one configmap is currently not properly mirrored in grafana.
Тобто – один ConfigMap на кожну дашборду.
Тож що нам треба зробити – це описати ConfigMap для кожної дашборди, і Grafana сама додасть їх до /tmp/dashboards.
Експорт існуючої dashboard та Data Source UID not found
Щоб уникнути помилки з UID (“Failed to retrieve datasource Datasource f0f2c234-f0e6-4b6c-8ed1-01813daa84c9 was not found”) – йдемо до дашборди в існуючому інстансі Grafana, і додаємо нову змінну з типом Data Source:
Повторюємо для Loki, Sentry:
Та оновлюємо панелі – задаємо датасорс зі змінної:
Повторюємо теж саме для всіх запитів у Annotations та Variables:
Створюємо каталог для файлів, які потім будемо імпортити в Kubernetes:
[simterm]
$ mkdir -p grafana/dashboards/
[/simterm]
Та робимо Export дашборди в JSON і зберігаємо як grafana/dashboards/overview.json:
Dashboard ConfigMap
В каталозі templates створюємо маніфест для ConfigMap:
І маємо наши графіки – поки не всі, бо запущено тільки один експортер:
Поїхали далі.
Що нам залишилось?
GitHub exporter – зробити чарт, додати до загального чарту (чи просто створити маніфест з Deployment? там один под, нічного більше йому не треба)
Loki
алерти
GitHub exporter мабуть таки просто з Deployment зроблю – маніфест у templates основного чарту, та й все – окремий чарт там не потрібен. Тут описувати не буду, бо це просто.
Запустимо в кластері Promtail, щоб по-перше перевірити роботу Loki, по-друге – всеж мати логи з кластеру.
Знаходимо версії чарта:
[simterm]
$ helm search repo grafana/promtail -l | head
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/promtail 6.11.7 2.8.2 Promtail is an agent which ships the contents o...
grafana/promtail 6.11.6 2.8.2 Promtail is an agent which ships the contents o...
grafana/promtail 6.11.5 2.8.2 Promtail is an agent which ships the contents o...
...
[/simterm]
Додаємо сабчарт в dependencies в нашому Chart.yaml:
Тут знову ж таки треба буде подумати про секрет, бо в slack_api_url маємо токен. Мабуть, зробимо як з Sentry-токеном – просто будемо передавати через --set.
VMAlert використовуює VMRules, які вибирає за ruleSelector:
[simterm]
$ kk -n dev-monitoring-ns get vmrule
NAME AGE
vm-k8s-stack-alertmanager.rules 6d19h
vm-k8s-stack-etcd 6d19h
vm-k8s-stack-general.rules 6d19h
vm-k8s-stack-k8s.rules 6d19h
...
[/simterm]
Тобто – можемо описати в маніфестах потрібні рули, задеплоїти – і VMAlert їх підхопить.
Глянемо сам VMAlert – він у нас зараз один, і в принципі нам цього поки вистачить:
Зберігання даних доступу у Kubernetes Secrets має важливий недолік, бо вони доступні тільки всередені самого Kubernetes кластеру.
Щоб зробити їх доступними зовнішнім сервісам – можемо використати Hashicorp Vault і інтегрувати його з Kubernetes за допомогою таких рішень, як vault-k8s, або скористуватись сервісами від AWS – Secrets Manager або Parameter Store.
Інтеграція AWS Secrets Manager та Parameter Store в Kubernetes дасть нам можливість створювати новий тип ресурсів – SecretProviderClass, який ми зможемо підключати до Kubernetes Pods у вигляді файлів або змінних оточення.
AWS Secrets and Configuration Provider vs Hashicorp Vault
Я давно не користувався Vault, але щодо питання “Що використовувати” – то тут вибір між “сетапити, конфігурити та менеджити Hashicorp Vault самому” (встановлення Helm-чарту та конфігурація доступів) або “використати готове рішення від AWS” (по суті, потрібно тільки налаштувати IAM-ролі).
Також враховуйте, що використання AWS сервісів (suprize!) платне, тож якщо ви плануєте мати тисячі секретів – то мабуть краще таки з Vault.
Крім того, Vault сам по собі дає набагато більше можливостей, наприклад – генерація тимчасових токенів для сервісів, плюс наскільки пам’ятаю – Kubernetes Pods можуть отримувати параметри з Vault без необхідності в створенні Kubernetes Secrets, тоді як при використанні AWS Secrets and Configuration Provider (ASCP) та Kubernetes Secrets Store CSI Driver для підключення змінних будуть створюватиcm звичайні Kubernetes Secrets.
Втім, на нашому проекті вже використовуються Secrets Manager та Parameter Store, сенсу в Vault поки не бачу, тож інтегруємо наші секрети до кластеру в AWS Elastic Kubernetes Service.
обидва використовують AWS KMS для шифрування даних
обидва являють собою Key/Value Store
обидва підтримують versioning
Різниця:
вартість:
Secrets Manager: бере $0.40 за кожен секрет та $0.05 за кожні 10,000 API запросів
Parameter Store: за Standard не бере грошей за зберігання, при higher throughput – коштує $0.05 за кожні 10,000 API запросів, при Advanced parameters – $0.05 за зберігання та $0.05 за кожні 10,000 API запросів
ротація секретів:
Secrets Manager: має вбудований механізм ротації та інтегрує його з сервісами (RDS, DocumentDB, etc)
Parameter Store: маєте імплементувати ротацію самостійно
Cross-account Access:
Secrets Manager: підтримує
Parameter Store: не підтримує
Cross-Regions Replication:
Secrets Manager: підтримує
Parameter Store: не підтримує
розмір даних:
Secrets Manager: до 10KB на кожен секрет
Parameter Store: 4KB на кожен запис (8KB при Advanced Parameters)
ліміти кількості:
Secrets Manager: 500,000 на регіон та акаунт
Parameter Store: 10,000 на регіон та акаунт
Встановлення Secrets Store CSI Driver
Отже, для інтеграції нам потрібні два сервіси – Secrets Store CSI Driver та AWS Secrets and Configuration Provider.
Першим додаємо Secrets Store CSI Driver.
За його допомогою зможемо підключати секрети/параметри з AWS файлами або змінними до Kubernetes Pods.
Додаємо Helm-чарт і встановлюємо з опцією syncSecret.enabled=true для створення RBAC-ролей для роботи з Kubernetes Secrets та їх синхронізації з секретами AWS під час ротації даних (див. Sync as Kubernetes Secret):
Щоб Kubernetes Pod зміг отримати доступ до AWS SecretManager та Parameter Store використаємо IRSA – створимо ServiceAacount, який буде використовувати IAM Role з IAM Policy, яка буде мати дозволи на виклик Secrets Manager та Parameter Store (див. AWS: EKS, OpenID Connect та ServiceAccounts).
Далі описуємо сам SecretProviderClass з двома objects – в parameters.objects.objectName – ім’я об’єкту в Secrets Manager або Parameter Store, а в objectType вказуємо звідки беремо цей об’єкт:
$ kubectl apply -f ascp-test.yaml
serviceaccount/ascp-test-serviceaccount created
secretproviderclass.secrets-store.csi.x-k8s.io/aspc-test-secret-class created
pod/ascp-test-pod created
[/simterm]
Перевіряємо под:
[simterm]
$ kk describe pod ascp-test-pod
...
Mounts:
/mnt/ascp-secret from ascp-test-secret-volume (ro)
...
Volumes:
...
ascp-test-secret-volume:
Type: CSI (a Container Storage Interface (CSI) volume source)
Driver: secrets-store.csi.k8s.io
FSType:
ReadOnly: true
VolumeAttributes: secretProviderClass=aspc-test-secret-class
...
[/simterm]
Та зміст каталогу /mnt/ascp-secret:
[simterm]
$ kk exec -ti ascp-test-pod -- ls -l /mnt/ascp-secret
total 8
-rw-r--r-- 1 root root 10 Jul 17 09:32 ascp-secret-test-string
-rw-r--r-- 1 root root 9 Jul 17 09:32 ascp-ssm-test-param
[/simterm]
І зміст файлів:
[simterm]
$ kk exec -ti ascp-test-pod -- cat /mnt/ascp-secret/ascp-secret-test-string
secretLine
$ kk exec -ti ascp-test-pod -- cat /mnt/ascp-secret/ascp-ssm-test-param
paramLine
[/simterm]
Підключення SecretProviderClass в Pod змінною оточення
Підключення файлами може бути непоганим рішенням для якихось .env файлів, але як щодо звичайних змінних? Наприклад – передати пароль для DB_PASSWORD.
Для цього до SecretProviderClass додаємо secretObjects – тоді Kubernetes Secrets Store CSI Driver створить звичайний Kubernetes Secret, котрий зможемо підключити в под :
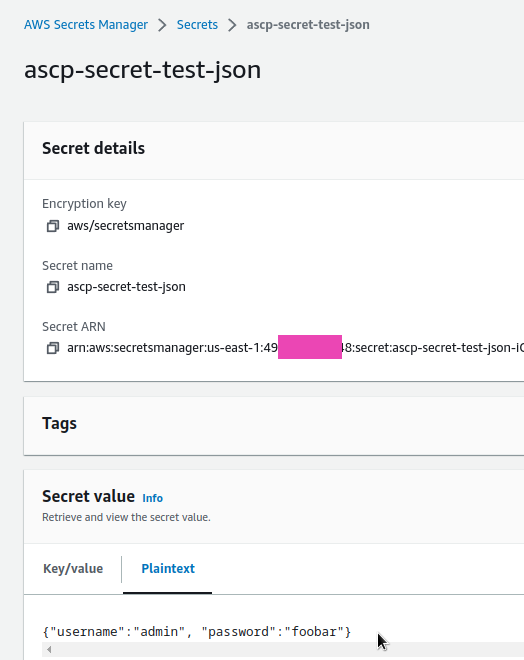
в parameters.objects.objectName: "ascp-secret-test-json" викликаємо jmesPath, який парсить наш секрет і отримує значення довх полів – username та password, для яких створює два objectAlias – ascp-test-username та ascp-test-password
в secretObjects.secretName: aspc-test-kube-secret-json додаємо data з двома objectName, в яких використуємо objectAlias з parameters
Обновлюємо наш Kubernetes Pod – додаємо два secretKeyRef з ключами kube-secret-user та kube-secret-user з секрету aspc-test-kube-secret-json:
Продовжимо про AWS CDK та Python. Пишу не тому, що подобається, а тому, що в інтернеті прикладів ну якось зовсім мало, тож нехай будуть хоча б тут.
Отже, маємо кластер, маємо пару контролерів. Наче все готово – почав встановлювати чарт VictoriaMetrics, і все завелося окрім поду з VMSingle, який завис в статусі Pending.
“VolumeBinding”: binding volumes: timed out waiting for the condition
Перевіряємо Events цього поду:
[simterm]
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 10m default-scheduler running PreBind plugin "VolumeBinding": binding volumes: timed out waiting for the condition
Тож сьогодні глянемо, як з AWS CDK додати аддони до кластеру.
Тут, в принципі, все досить просто, єдине що довелося погуглити як жеж саме використовувати CfnAddon, але цього разу документація знайшлась швидко, і навіть з прикладами на Python, а не TypeScript.
Для драйверу теж використовуємо IRSA – описуємо ServiceAccount, політику беремо вже готову – AWS Managed Policy, підключаємо через виклик iam.ManagedPolicy.from_aws_managed_policy_name():
...
# Create an IAM Role to be assumed by ExternalDNS
ebs_csi_addon_role = iam.Role(
self,
'EbsCsiAddonRole',
# for Role's Trust relationships
assumed_by=iam.FederatedPrincipal(
federated=oidc_provider_arn,
conditions={
'StringEquals': {
f'{oidc_provider_url.replace("https://", "")}:sub': 'system:serviceaccount:kube-system:ebs-csi-controller-sa'
}
},
assume_role_action='sts:AssumeRoleWithWebIdentity'
)
)
ebs_csi_addon_role.add_managed_policy(iam.ManagedPolicy.from_aws_managed_policy_name("service-role/AmazonEBSCSIDriverPolicy"))
...
У from_aws_managed_policy_name вказуємо ім’я як “service-role/ManagedPolicyName“.
CfnAddon для EBS CSI driver
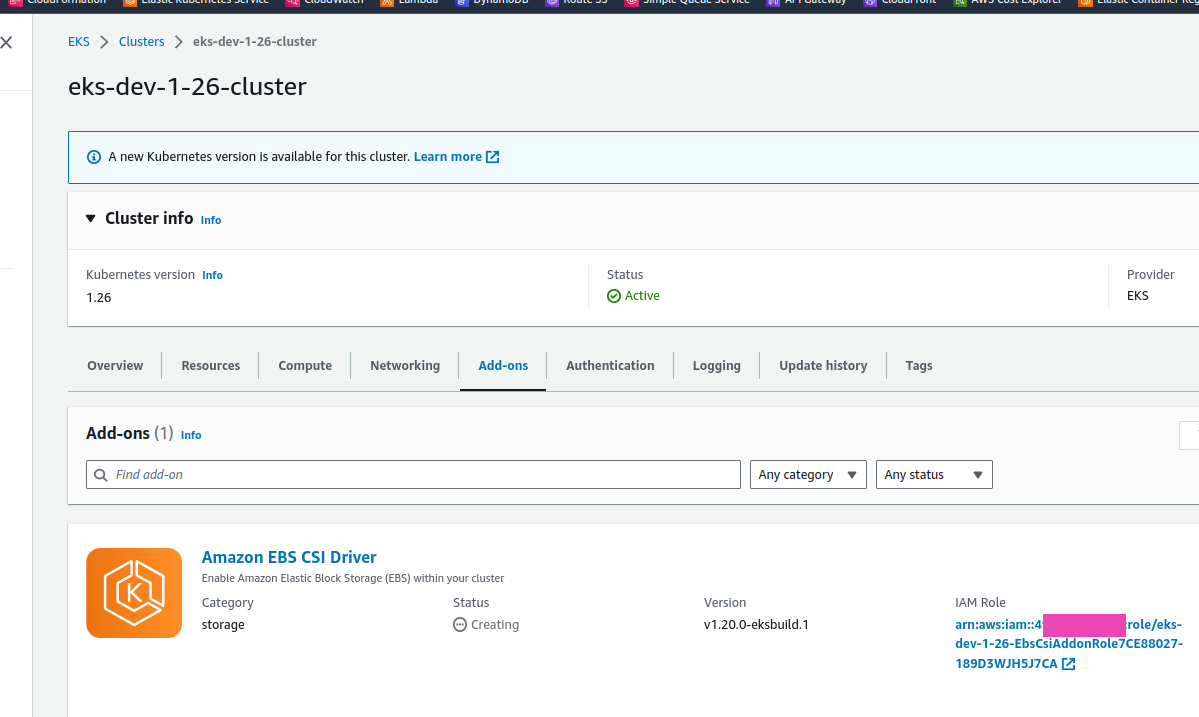
Знаходимо актувальну версію дайверу, вказавши версію кластеру – у нас 1.26, бо CDK досі не підтримує 1.27:
$ kk -n kube-system get pod | grep csi
ebs-csi-controller-896d87c6b-7rv9z 6/6 Running 0 9m59s
ebs-csi-controller-896d87c6b-v7xg7 6/6 Running 0 9m59s
ebs-csi-node-2zwnr 3/3 Running 0 9m59s
ebs-csi-node-pt5zs 3/3 Running 0 9m59s
[/simterm]
І тепер маємо PVC для VictoriaMetrcis в статусі Bound:
[simterm]
$ kk -n dev-monitoring-ns get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
vmsingle-victoria-metrics-k8s-stack Bound pvc-151a631b-f6de-4567-8baa-97adb4e04a87 20Gi RWO gp2 91m
Наступним кроком після розгортання самого кластеру треба налаштувати OIDC Identity Provider в AWS IAM, та додати два контролери – ExternalDNS для роботи з Route53, то AWS ALB Controller для створення лоад-балансерів при створенні Ingress.
Для аутентифікації в AWS обидва контролери будуть використовувати модель IRSA – IAM Roles for ServiceAccounts, тобто в Kubernetes Pod з контролером підключаємо ServiceAccount, який дозволить використання IAM-ролі, до якої будуть підключені IAM Policy з необіхідними дозволами.
Пізніше окремо розглянемо питання контролеру для скейлінгу WorkerNodes: раніше я використовував Cluster AutoScaler, але цього разу хочу спробувати Karpenter, тож винесу це окремим постом.
Рішення, описані в цьому пості виглядають місцями дуже не гуд, і, може, є варіанти, як це зробити красивіше, але в мене вийшло так. “At least, it works” ¯\_(ツ)_/¯
“Так історично склалося” (с), що продовжуємо їсти кактус використовувати AWS CDK з Python. Ним будемо створювати і IAM-ресурси, і деплоїти Helm-чарти контролерів прямо з CloudFormation-стеку кластеру.
Я намагався винести деплой контролерів окремим стеком, але витратив годину-півтори намагаючись знайти, як у CDK передати значення з одного стеку в інший через CloudFormation Exports та Outputs, тож вреті-решт забив і зробив все в одному класі стеку.
Далі треба додати створення OIDC в IAM, та деплой Helm-чартів з контролерами.
Налаштування OIDC Provider в AWS IAM
Використовуємо boto3 (це одна з речей, яка в AWS CDK не дуже подобається – що багато чого доводиться робити не методами/конструктами самого CDK, а “костилями” у вигляді boto3 чи інших модулів/бібліотек).
...
from botocore.exceptions import ClientError
...
# Create IAM Identity Privder
iam_client = boto3.client('iam')
# to catch the "(EntityAlreadyExists) when calling the CreateOpenIDConnectProvider operation"
try:
response = iam_client.create_open_id_connect_provider(
Url=oidc_provider_url,
ThumbprintList=[oidc_provider_thumbprint],
ClientIDList=["sts.amazonaws.com"]
)
except ClientError as e:
print(f"\n{e}")
...
Тут все загортаємо у костиль у вигляді try/except, бо при подальших апдейтах стеку boto3.client('iam') натикається на те, що Provider вже є, і падає з помилкою EntityAlreadyExists.
Встановлення ExternalDNS
Першим додамо ExternalDNS – в нього досить проста IAM Policy, тож на ньому протестимо як взагалі CDK працює з Helm-чартами.
IRSA для ExternalDNS
Тут першим кроком нам треба створити IAM Role, яку зможе assume наш ServiceAccount для ExternalDNS, і яка дозволить ExternalDNS виконувати дії з доменною зоною у Route53, бо зараз ExternalDNS має ServiceAccount, але видає помилку:
msg=”records retrieval failed: failed to list hosted zones: WebIdentityErr: failed to retrieve credentials\ncaused by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus code: 403
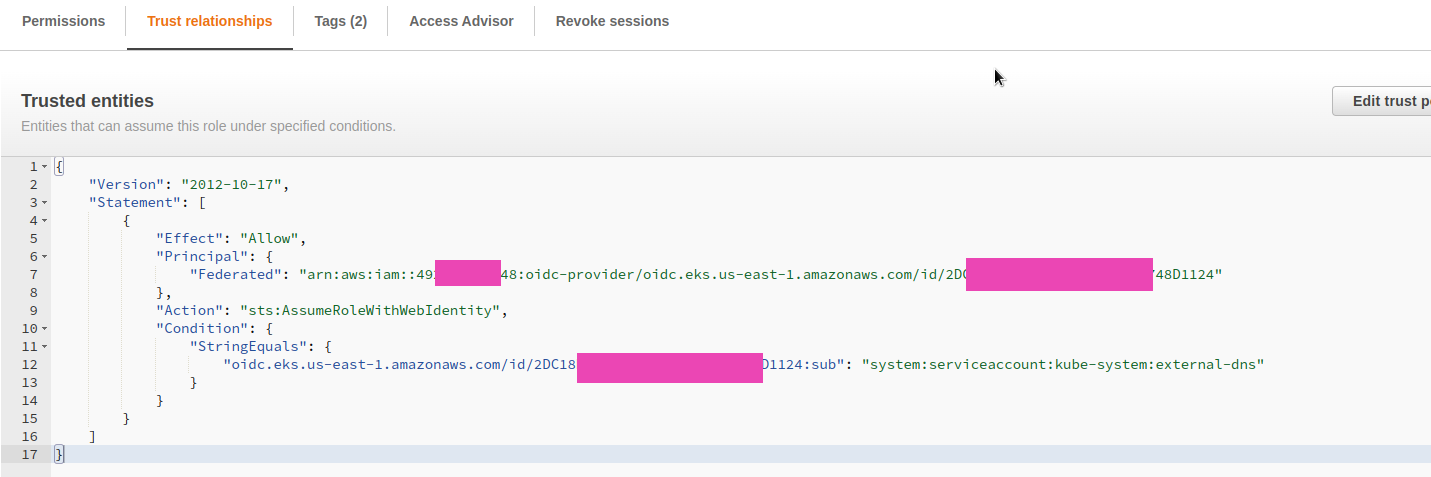
Trust relationships
У Trust relationships цієї ролі маємо вказати Principal у вигляді ARN створенного OIDC Provider, в Action – sts:AssumeRoleWithWebIdentity, а в Condition – якщо запит приходить від ServiceAccount, який буде створений ExternalDNS Helm-чартом.
Створим пару змінних:
...
# arn:aws:iam::492***148:oidc-provider/oidc.eks.us-east-1.amazonaws.com/id/2DC***124
oidc_provider_arn = f'arn:aws:iam::{aws_account}:oidc-provider/{oidc_provider_url.replace("https://", "")}'
# deploy ExternalDNS to a namespace
controllers_namespace = 'kube-system'
...
oidc_provider_arn формуємо зі змінної oidc_provider_url, яку отримали раніше у response = eks_client.describe_cluster(name=cluster_name).
...
# Create an IAM Role to be assumed by ExternalDNS
external_dns_role = iam.Role(
self,
'EksExternalDnsRole',
# for Role's Trust relationships
assumed_by=iam.FederatedPrincipal(
federated=oidc_provider_arn,
conditions={
'StringEquals': {
f'{oidc_provider_url.replace("https://", "")}:sub': f'system:serviceaccount:{controllers_namespace}:external-dns'
}
},
assume_role_action='sts:AssumeRoleWithWebIdentity'
)
)
...
В результаті маємо отримати роль з таким Trust relationships:
Наступний крок – IAM Policy.
IAM Policy для ExternalDSN
Якщо задеплоїти стек зараз, то ExternalDSN почне сваритись на права доступу:
msg=”records retrieval failed: failed to list hosted zones: AccessDenied: User: arn:aws:sts::492***148:assumed-role/eks-dev-1-26-EksExternalDnsRoleB9A571AF-7WM5HPF5CUYM/1689063807720305270 is not authorized to perform: route53:ListHostedZones because no identity-based policy allows the route53:ListHostedZones action\n\tstatus code: 403
Тож описуємо два iam.PolicyStatement() – один для роботи з доменною зоною, другий – для доступу до route53:ListHostedZones.
Робимо їх окремими, бо для route53:ChangeResourceRecordSets у resources хочеться мати обмеження тільки однією конкретною зоною, але для дозволу на route53:ListHostedZones resources має бути у вигляді "*":
...
# A Zone ID to create records in by ExternalDNS
zone_id = "Z04***FJG"
# to be used in domainFilters
zone_name = example.co
# Attach an IAM Policies to that Role so ExternalDNS can perform Route53 actions
external_dns_policy = iam.PolicyStatement(
actions=[
'route53:ChangeResourceRecordSets',
'route53:ListResourceRecordSets'
],
resources=[
f'arn:aws:route53:::hostedzone/{zone_id}',
]
)
list_hosted_zones_policy = iam.PolicyStatement(
actions=[
'route53:ListHostedZones'
],
resources=['*']
)
external_dns_role.add_to_policy(external_dns_policy)
external_dns_role.add_to_policy(list_hosted_zones_policy)
...
...
time="2023-07-11T10:28:28Z" level=info msg="Applying provider record filter for domains: [example.co. .example.co.]"
time="2023-07-11T10:28:28Z" level=info msg="All records are already up to date"
...
[/simterm]
І протестуємо його роботу.
Перевірка роботи ExternalDNS
Для перевірки – створимо простий Service з типом Loadbalancer, в annotations додаємо external-dns.alpha.kubernetes.io/hostname:
...
time="2023-07-11T10:30:29Z" level=info msg="Applying provider record filter for domains: [example.co. .example.co.]"
time="2023-07-11T10:30:29Z" level=info msg="Desired change: CREATE cname-nginx.test.example.co TXT [Id: /hostedzone/Z04***FJG]"
time="2023-07-11T10:30:29Z" level=info msg="Desired change: CREATE nginx.test.example.co A [Id: /hostedzone/Z04***FJG]"
time="2023-07-11T10:30:29Z" level=info msg="Desired change: CREATE nginx.test.example.co TXT [Id: /hostedzone/Z04***FJG]"
time="2023-07-11T10:30:29Z" level=info msg="3 record(s) in zone example.co. [Id: /hostedzone/Z04***FJG] were successfully updated"
...
[/simterm]
Перевіряємо роботу домену:
[simterm]
$ curl -I nginx.test.example.co
HTTP/1.1 200 OK
[/simterm]
“It works!” (c)
Весь код для OIDC та ExternalDNS
Весь код разом зараз виглядає так:
...
############
### OIDC ###
############
eks_client = boto3.client('eks')
# Retrieve the cluster's OIDC provider details
response = eks_client.describe_cluster(name=cluster_name)
# https://oidc.eks.us-east-1.amazonaws.com/id/2DC***124
oidc_provider_url = response['cluster']['identity']['oidc']['issuer']
# AWS EKS OIDC root URL
eks_oidc_url = "oidc.eks.us-east-1.amazonaws.com"
# Retrieve the SSL certificate from the URL
cert = ssl.get_server_certificate((eks_oidc_url, 443))
der_cert = ssl.PEM_cert_to_DER_cert(cert)
# Calculate the thumbprint for the create_open_id_connect_provider()
oidc_provider_thumbprint = hashlib.sha1(der_cert).hexdigest()
# Create IAM Identity Privder
iam_client = boto3.client('iam')
# to catch the "(EntityAlreadyExists) when calling the CreateOpenIDConnectProvider operation"
try:
response = iam_client.create_open_id_connect_provider(
Url=oidc_provider_url,
ThumbprintList=[oidc_provider_thumbprint],
ClientIDList=["sts.amazonaws.com"]
)
except ClientError as e:
print(f"\n{e}")
###################
### Controllers ###
###################
### ExternalDNS ###
# arn:aws:iam::492***148:oidc-provider/oidc.eks.us-east-1.amazonaws.com/id/2DC***124
oidc_provider_arn = f'arn:aws:iam::{aws_account}:oidc-provider/{oidc_provider_url.replace("https://", "")}'
# deploy ExternalDNS to a namespace
controllers_namespace = 'kube-system'
# Create an IAM Role to be assumed by ExternalDNS
external_dns_role = iam.Role(
self,
'EksExternalDnsRole',
# for Role's Trust relationships
assumed_by=iam.FederatedPrincipal(
federated=oidc_provider_arn,
conditions={
'StringEquals': {
f'{oidc_provider_url.replace("https://", "")}:sub': f'system:serviceaccount:{controllers_namespace}:external-dns'
}
},
assume_role_action='sts:AssumeRoleWithWebIdentity'
)
)
# A Zone ID to create records in by ExternalDNS
zone_id = "Z04***FJG"
# to be used in domainFilters
zone_name = "example.co"
# Attach an IAM Policies to that Role so ExternalDNS can perform Route53 actions
external_dns_policy = iam.PolicyStatement(
actions=[
'route53:ChangeResourceRecordSets',
'route53:ListResourceRecordSets'
],
resources=[
f'arn:aws:route53:::hostedzone/{zone_id}',
]
)
list_hosted_zones_policy = iam.PolicyStatement(
actions=[
'route53:ListHostedZones'
],
resources=['*']
)
external_dns_role.add_to_policy(external_dns_policy)
external_dns_role.add_to_policy(list_hosted_zones_policy)
# Install ExternalDNS Helm chart
external_dns_chart = cluster.add_helm_chart('ExternalDNS',
chart='external-dns',
repository='https://charts.bitnami.com/bitnami',
namespace=controllers_namespace,
release='external-dns',
values={
'provider': 'aws',
'aws': {
'region': region
},
'serviceAccount': {
'create': True,
'annotations': {
'eks.amazonaws.com/role-arn': external_dns_role.role_arn
}
},
'domainFilters': [
zone_name
],
'policy': 'upsert-only'
}
)
...
Переходимо до ALB Controller.
Встановлення AWS ALB Controller
Тут, в принципі, все теж саме, єдине, з чим довелось повозитись – це IAM Policy, бо якщо для ExternalDNS маємо тільки два дозволи, і можемо описати їх прямо при створенні цієї Policy, то для ALB Controller політику треба взяти з GitHub, бо вона досить велика.
IAM Policy з GitHub URL
Тут використовуємо requests (знов костилі):
...
import requests
...
alb_controller_version = "v2.5.3"
url = f"https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/{alb_controller_version}/docs/install/iam_policy.json"
response = requests.get(url)
response.raise_for_status() # Check for any download errors
# format as JSON
policy_document = response.json()
document = iam.PolicyDocument.from_json(policy_document)
...
Отримуємо файл політики, формуємо його в JSON, і потм з JSON формуємо вже сам policy document.
IAM Role для ALB Controller
Далі створюємо IAM Role з аналогічними до ExternalDNS Trust relationships, тільки міняємо conditions – вказуємо ServiceAccount, який буде створено для AWS ALB Contoller:
І тепер встановлюємо сам чарт з потрібними values – вказуємо на необхідність створення ServiceAccount, йому в annotations передаємо ARM ролі, яку створили перед цим, та задаємо clusterName:
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
nginx-ingress <none> * internal-k8s-default-nginxing-***-***.us-east-1.elb.amazonaws.com 80 34m
[/simterm]
Єдине тут, що спрацювало не з першого разу – це підключення aws-iam-token: саме тому я в values чарту явно передав 'automountServiceAccountToken': True, хоча в нього і так дефолтне значення true.
Але після декулькох редеплоїв з cdk deploy – токен таки створився і підключився до поду:
Як завжди з CDK – це біль та страждання через відсутність нормальної документації та прикладів, але за допомогою ChatGPT та матюків – воно таки запрацювало.
Ще, мабуть, було б добре створення ресурсів винести хоча б у окремі функції, а не робити все з AtlasEksStack.__init__(), але то може пізніше.
Далі за планом – запуск VictoriaMetrics в Kubernetes, а потім вже потицяємо Karpenter.
Зараз сетаплю новий ЕКС кластер, і серед інших компонентів запускаю в ньому ExternalDNS, який використовує Kubernetes ServiceAccount для аутентифікації в AWS, щоб мати змогу вносити зміни до доменної зони в Route53.
Однак забув налаштувати Identity Provider в AWS IAM, і ExternalDNS видав помилку:
level=error msg=”records retrieval failed: failed to list hosted zones: WebIdentityErr: failed to retrieve credentials\ncaused by: InvalidIdentityToken: No OpenIDConnect provider found in your account for https://oidc.eks.us-east-1.amazonaws.com/id/FDF***F2F\n\tstatus code: 400
Тож почав згадувати за OIDC, потім взагалі про аутентифікацію в Kubernetes, и вирішив ще раз копнути в те, як воно все працює, бо в останніх версіях EKS/Kubernetes були досить цікаві зміни.
Що таке OpenID Connect та Identity Provider
OpenID Connect (OIDC) це протокол, який дозволяє сервісам виконувати аутентифікацію іншого сервісу або користувача на основі Identity Tokens, які являють собою JSON Web Tokens (JWT).
Сам JWT підписується Identity Provider (IDP), і містить в собі інформацю про юзера або сервіс.
В нашому випадку, AWS Elastic Kubernetes Service – це Identity Provider, а AWS – це Service Provider. Тобто, EKS аутентифікує юзерів, і каже Амазону, що цьому юзеру можна довіряти виконувати якісь дії в AWS.
Тож головне, що треба усвідомлювати, коли ви налаштовуєте Identity Providers в AWS IAM, це те, що ви не налаштовуєте якийсь окремий AWS Service під назвою “Identity Providers“, а налаштовуєте AWS IAM, якому кажете – “Хей, довіряй чуваку з оцим URL”, тобто налаштовуєте Trust relations між вашим Identity Provider (EKS, GitHub, GitLab, Google тощо) та Service Provider (AWS).
Якщо провести аналогію, то це якби ви в аеропорту на паспортному контролі десь в Амстердамі прийшли зі своїм українським паспортом, і вам там повірили, що ви – то саме ви, бо прикордонна служба Нідерландів (Service Provider) довіряє уряду України (Identity Provider), який вам видав цей паспорт (JWT).
AWS EKS та IAM Role
Окей, тож як Kubernetes Pod у EKS отримує доступ до AIM-ролі?
ми створюємо ServiceAccount для Kubernetes Pod, в annotations цього ServiceAccount вказуємо ARN IAM-ролі, яку цей Pod має використовувати для аутентифікації в AWS (авторизація, тобто перевірка які саме дії ви можете в AWS виконувати, буде виконуватись на рівні самого AWS в IAM за допомогою IAM Policy, яка підключена до вашої IAM Role)
EKS генерує JWT-токен, в якому вказано, що “подавач” цього токену дійсно є валідним EKS-юзером, і EKS це підтвержує своїм сертифікатом
процес із поду за допомогою цього токену проходить аутентифікацію в AWS IAM і виконує AssumeRole
і вже від імені цїєї ролі виконує необхідні дії з AWS API
Тобто, в процесі приймаються участь Kubernetes ServiceAccount, AWS AIM, та JWT-токени.
Якщо раніше при створенні ServiceAccount створювався статичний Kubernetes Secret, який в собі мав три поля – namespace, ca.crt та власне token, то тепер це все генерується динамічно для кожного поду та ServiceAccount.
Давайте переглянемо, що ми зараз маємо в поді з ExternalDNS:
Отже, в volumeMounts ми бачимо два volumes – kube-api-access-qdgjr та aws-iam-token. До aws-iam-token повернемось пізніше, а поки давайте розглянемо volumes.projected для kube-api-access-qdgjr.
ServiceAccount Tokens
Починаючи з версії 1.22, Kubernetes має два типи токені – Long Live та Time Bound.
Long Live вже вважається deprecated, і не має використовуватись, хоча його можливо зробити зо допомогою Secret – це той самий тип токенів, які використовувались для ServiceAccounts раніше:
Time Bound токени генеруються Kubernetes TokenRequest API, мають обмежений час життя, валідні тільки для конкретного Pod та ServiceAccount, і підключаються до поду за допомогою Projected Volumes та serviceAccountToken.
Kubernetes API JWT authentification
Глянемо в самому поді зміст каталогу /var/run/secrets/kubernetes.io/serviceaccount:
Тут маємо три файли, які створені з Projected Volumes, в яких ми бачили три source, кожний з власним path:
serviceAccountToken: містить токен, отриманий від kube-apiserver за допомогою TokenRequest API, і використовується подом для аутентифікації на Kubernetes API. Має обмежений час життя, і валідний тільки для цього конкретного поду та його ServiceAccount
підключається у path: token
configMap: бере зміст kube-root-ca.crt ConfigMap, використовується подом, щоб впевнитись, що він підключається саме до потрібного Kubernetes API
підключається у path: ca.crt
downwardAPI: отримує від API інформацію про metadata.namespace
підключається у path: namespace
Давайте глянемо, що в самому токені – він теж змінився.
aud (audience): для кого цей токен призначений – отримувач має ідентифікувати себе з цим ім’ям, інакше токен має бути відхилений
exp (expiration time): “термін придатності” цього токену – після його закінчення, токен має бути відхилений
iat (issued at): час створення токену, від якого буде рахуватись exp
iss (issuer): OIDC Issuer URL нашого кластеру – той самий Identity Provider URL, який потім будемо використовувати при налаштувані AWS IAM
kubernetes.io: тут бачимо UID самого пода та ServiceAccount – саме тому якщо под або його ServiceAccount буде перестворено, то цей токен стане невалідним, бо зміняться UID
sub (subject): “ім’я користувача” цього токену – буде перевірятись у AWS IAM для авторизації дій з AWS API
Використовуючи це токен – ми з поду можемо аутентифікуватись на API нашого Kubernetes-кластеру.
Описуємо под з cURL:
---
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: curl
image: curlimages/curl
command: ['sleep', '36000']
restartPolicy: Never
Створюємо його:
[simterm]
$ kubectl apply -f test-pod.yaml
pod/test-pod created
Хоча ви все ще можете використовувати підхід з ACCESS/SECRET через змінні оточення, або підключати необхідну роль до EC2 WorkerNode як EC2 IAM Instance Role, робота через IRSA дозволяє вам видавати права на роботу з AWS для конкретного поду, а не всіх подів на цьому ЕС2-інстансі.
У випадку ж з ACCESS/SECRET для поду – ключі у вас статичні, і по-перше – можуть бути скомпрометовані (вкрадені), по-друге – вам необхідно їх десь тримати та передавати у Deployment/StatefulSet, etc під час створення вашого workload, тоді як IRSA використовує динамічні дані доступу (credentials), яки створються під час запиту поду до IAM-ролі, і вам не потрібно їх ані зберігати, ані хвилюватись через їх витік.
Assume Role з AWS CLI
Отже, Kubernetes Pod буде виконувати AssumeRole для отримання ролі, тож давайте згадаємо, як AssumeRole працює з AWS CLI – тоді будемо краще уявляти собі, як це працює в EKS з його подами.
Описуємо IAM Policy, яка дозволяє доступ до S3-бакетів:
STS перевіряє, чи може користувач (який у ~/.aws/credentials має ACCESS/SECRET ключі юзеру в AWS) виконувати API-запит sts:AssumeRole (а так як ми в Trust Policy цієї ролі вказали Principal "arn:aws:iam::492***148:root" – то може)
якщо перевірку пройдено, то STS створює тимчасові дані доступу для цієї ролі – AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY та AWS_SESSION_TOKEN і повертає їх до AWS CLI
Далі, використовуючи ці дані, ми можемо виконувати дії від імені ціьєї IAM-ролі:
Спочатку налаштуємо Identity Provider в IAM, створимо ServiceAccount та IAM Role, яку будемо використовувати, перевіримо, і потім глянемо як саме воно працює.
Ми вже розбирали що знаходиться в /var/run/secrets/kubernetes.io/serviceaccount/token, який створюється з Projected Volume kube-api-access-frc4n – теперь глянемо на /var/run/secrets/eks.amazonaws.com/serviceaccount/token.
Для нього використовується той самий тип serviceAccountToken, якому передається audience: sts.amazonaws.com. В результаті маємо JWT-токен для аутентифікації в AWS:
aud: має співпадати з audience нашого Identity Provider в AWS AIM (інакше отримаємо помилку “An error occurred (InvalidIdentityToken) when calling the AssumeRoleWithWebIdentity operation: Incorrect token audience” – я с першого разу помилився, коли додавав IDP – в Audience вказав sts.amazon.com замість sts.amazonaws.com)
iss: IAM буде перевіряти, від кого прийшов токен, і чи може він довіряти цьому джерелу
sub: буде використовуватись у IAM Role Trusted Policy – згадайте Condition.StringEquals у файлі irsa-trust.json
Тобто, з цим токеном ми можемо звернутись до AWS STS, і отримати temporary crdentials, за якими зможемо виконати запит на sts:AssumeRoleWithWebIdentity.
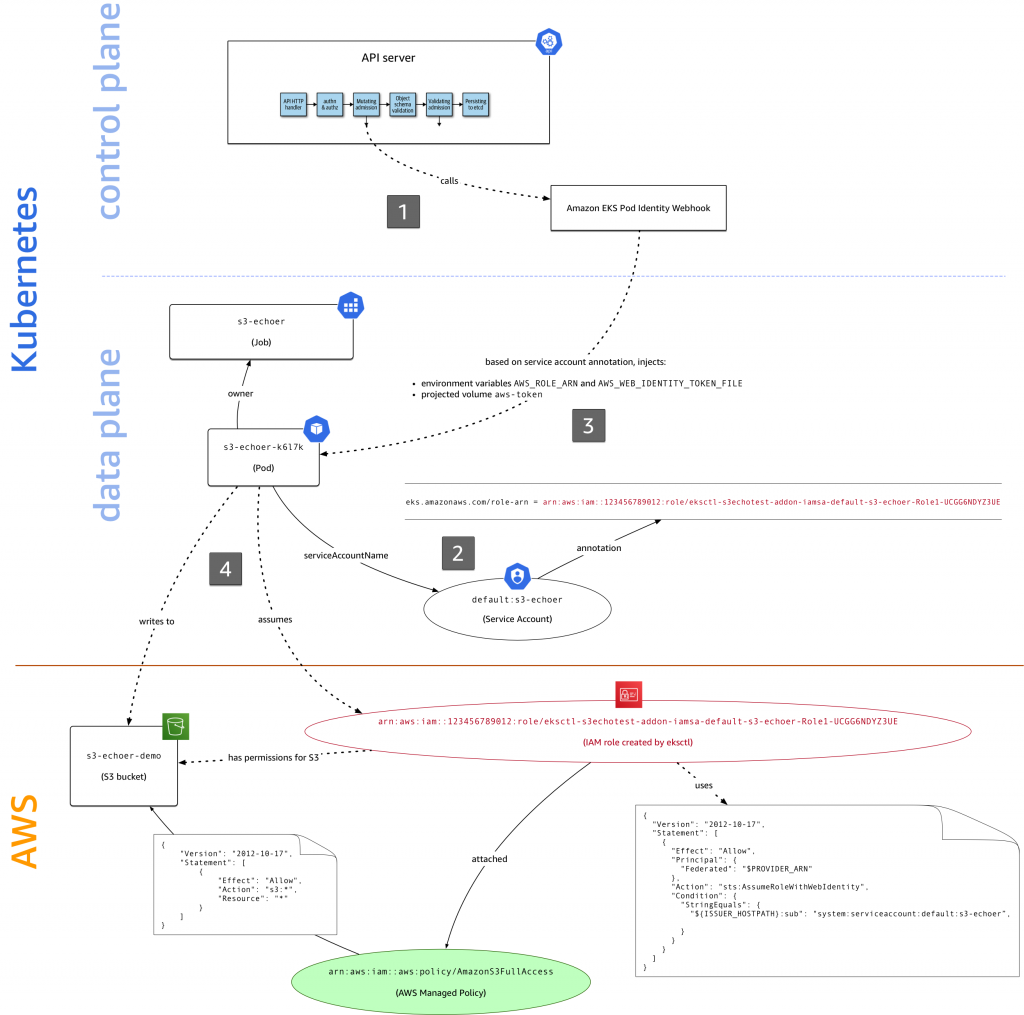
при створенні пода з ServiceAccount, якому вказано IAM Role, Amazon EKS Pod Identity webhook створює змінні оточення AWS_ROLE_ARN та AWS_WEB_IDENTITY_TOKEN_FILE, і додає aws-iam-token projected volume, в якому генерує JWT
при роботі процесу всередині поду – цей процес (AWS CLI, CDK, SDK, whatever) використовує змінні оточення:
AWS_ROLE_ARN – щоб знати, Assume якої ролі робити
та AWS_WEB_IDENTITY_TOKEN_FILE – що знати, звідки йому взяти токен для аутентифікації в AWS
Тобто, коли ми викликали aws s3 ls і не передавали йому ніяких параметрів – він просто взяв їх з оточення:
Terraform то чудово, але поки що вирішили перші кластера AWS EKS створювати за допомогою AWS CDK, бо по-преше – він вже є на проекті, по-друге – самому цікаво спробувати новий інструмент.
Тож сьогодні розглянемо що з цього вийшло, та як створювався кластер і необхідні ресурси.
Забігаючи наперед – особисто я, дуже м’яко кажучи, не в захваті від CDK:
ніякого тобі KISS – Keep It Simple Stupid, ніякого тобі “явне краще неявного”
місцями незрозуміла документація з приклами на TypeScript навіть в репозиторії PyPi
купа окремих бібліотек та модулів, іноді геморой з їхніми імпортами
загальна перенавантаженість коду CDK/Python – Terraform з його HCL або Pulumi з Python виглядає набагато простішим для розуміння загальної картини інфрастуктури, котора цим кодом описана
перенавантаженість самого CloudFormation стеку, створенного за допомогою CDK – купа IAM-ролей, якісь Lambda-функції і таке інше – коли воно зламається, то доведеться дуже довго шукати де і що саме “пішло не так”
питати Google на тему “AWS CDK Python create something” – майже марна справа, бо результатів або не буде взагалі, але будуть на TypeScript
Хоча пост планувався в стилі “як зробити”, але в результаті вийшло “Як вистрілити собі в ногу, запроваджуючи на проекті AWS CDK”.
AWS CDK vs Terraform
Знову-таки, хоча сам пост не про це, але кілька слів після роботи з CDK та його порівняння з Terraform.
Time To Create: AWS CDK vs Terraform
Перше, що хочеться прям на початку показати – це швидкість роботи AWS CDK vs Terraform:
Тест, звісно, достаточно штучний, але дуже гарно показав різницю в роботі.
Я спецільно не створював NAT Gateways, бо їхнє створення займає більше хвилини просто на запуск самих NAT-інстансів, тоді як на створення VPC/Subnets/etc час не витрачається, тож бачимо саме швидкість роботи CDK/CloudFormation versus Terraform.
Пізніше ще заміряв створення VPC+EKS з CDK та Terraform:
CDK
create: 18m54.643s
destroy: 26m4.509s
Terraform:
create: 12m56.801s
destroy: 5m32.329s
AWS CDK workflow
Та й в цілому процес роботи CDK виглядає занадто ускладненим:
пишемо код на Python
який траснлюється до бекенду CDK на NodeJS
генерує CloudFormation Template та ChangeSets
CDK для своєї роботи створює пачку Lambda-функцій
і тільки потім створюються ресурси
Плюс в самому CloudFormation стеку для EKS створюється ціла купа AIM ролей та Lambda-функцій з неясним та неявним призначенням.
AWS CDK та нові “фічі” AWS
Ще з насправді досить очікуваного – CDK не має всіх нових “плюшок” AWS. Я с цим зіткнувся ще кілька років тому, коли потрібно було у CloudFormation створити cross-region VPC Peering, а CloudFormation це не підтримував, хоча у Terraform це вже було реалізовано.
Щоб мати якусь точку для старту – спитав ChatGPT. В цілому, ідею від подав, хоча з застарілими імпортами та деякими атрибутами, які довелось переписувати:
Поїхали.
Python virtualevn
Створюємо Python virtualevn:
[simterm]
$ python -m venv .venv
$ ls -l .venv/
total 16
drwxr-xr-x 2 setevoy setevoy 4096 Jun 20 11:18 bin
drwxr-xr-x 3 setevoy setevoy 4096 Jun 20 11:18 include
drwxr-xr-x 3 setevoy setevoy 4096 Jun 20 11:18 lib
lrwxrwxrwx 1 setevoy setevoy 3 Jun 20 11:18 lib64 -> lib
-rw-r--r-- 1 setevoy setevoy 176 Jun 20 11:18 pyvenv.cfg
Повертаємось до ChatGPT, що він там далі рекомендує:
Нам тут цікаві тільки імпорти (з якими він не вгадав), та сам ресурс cluster = eks.Cluster(), якому він пропонує версію 1.21, бо сам ChatGPT, як ми знаємо, має базу до 2021 року.
CDK: AttributeError: type object ‘KubernetesVersion’ has no attribute ‘V1_27’
Щодо AWS CDK та версії EKS, писав про це на початку – виглядала помилка так:
AttributeError: type object ‘KubernetesVersion’ has no attribute ‘V1_27’
Окей – давайте поки 1.26, там подивимось, як з цим жити.
from aws_cdk import (
aws_eks as eks,
Stack
)
from constructs import Construct
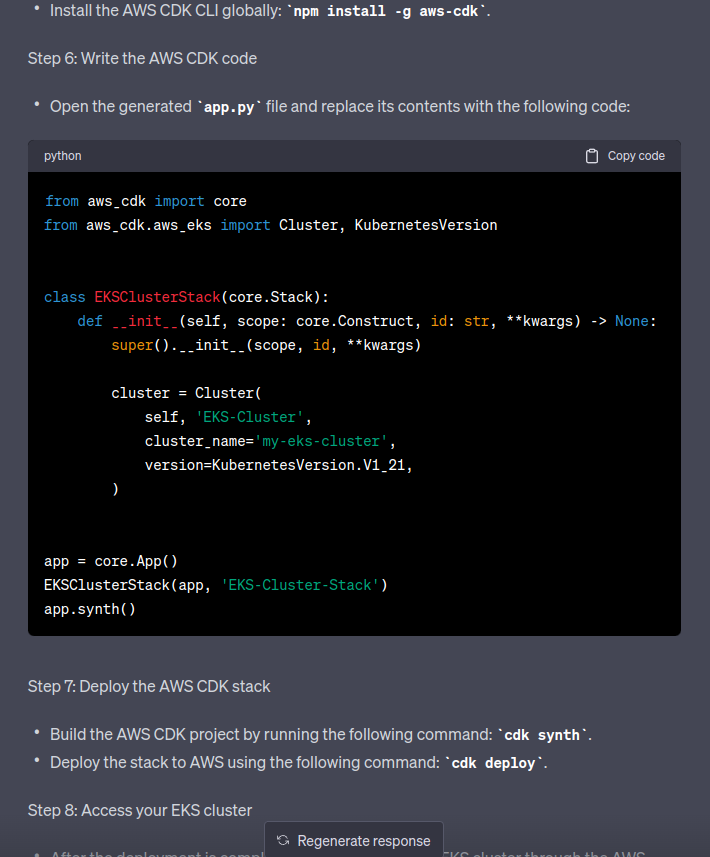
class AtlasEksStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name='my-eks-cluster',
version=eks.KubernetesVersion.V1_26,
)
Перевіряємо з cdk synth:
[simterm]
$ cdk synth
[Warning at /AtlasEksStack/EKS-Cluster] You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property. This may cause failures as the kubectl version provided with aws-cdk-lib is 1.20, which is only guaranteed to be compatible with Kubernetes versions 1.19-1.21. Please provide a kubectlLayer from @aws-cdk/lambda-layer-kubectl-v26.
Resources:
EKSClusterDefaultVpc01B29049:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
EnableDnsHostnames: true
EnableDnsSupport: true
InstanceTenancy: default
Tags:
- Key: Name
Value: AtlasEksStack/EKS-Cluster/DefaultVpc
Metadata:
aws:cdk:path: AtlasEksStack/EKS-Cluster/DefaultVpc/Resource
...
[/simterm]
CDK сам тсворить VPC та subnets і все інше для мережі, та IAM ролі. Це, в принципі, зручно, хоча там є свої питання.
Ми далі будемо створювати власну VPC.
Warning: You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property
На початку cdk synth каже щось про kubectlLayer:
[Warning at /AtlasEksStack/EKS-Cluster] You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property. This may cause failures as the kubectl version provided with aws-cdk-lib is 1.20, which is only guaranteed to be compatible with Kubernetes versions 1.19-1.21. Please provide a kubectlLayer from @aws-cdk/lambda-layer-kubectl-v26.
З імені можно припустити, що CDK створить Lambda-функцію, в якій буде викликати kubectl для виконання якихось задач в самоу Kubernetes.
В документації KubectlLayer сказано, що “An AWS Lambda layer that includes kubectl and helm.”
Дуже дякую – все відразу стало зрозуміло. Де воно використовується, для чого?
Ну, ок… Давайте спробуємо позбутися цього варнінгу.
Знову спитаємо ChatGP:
Пробуємо встановити aws-lambda-layer-kubectl-v26:
[simterm]
$ pip install aws-cdk.aws-lambda-layer-kubectl-v26
ERROR: Could not find a version that satisfies the requirement aws-cdk.aws-lambda-layer-kubectl-v26 (from versions: none)
ERROR: No matching distribution found for aws-cdk.aws-lambda-layer-kubectl-v26
Пробуємо pip search – спочатку перевіримо, що search в PiP взагалі є, бо давно ним не користувався:
[simterm]
$ pip search --help
Usage:
pip search [options] <query>
Description:
Search for PyPI packages whose name or summary contains <query>.
Search Options:
-i, --index <url> Base URL of Python Package Index (default https://pypi.org/pypi)
...
[/simterm]
Окей – шукаємо:
[simterm]
$ pip search aws-lambda-layer-kubectl
ERROR: XMLRPC request failed [code: -32500]
RuntimeError: PyPI no longer supports 'pip search' (or XML-RPC search). Please use https://pypi.org/search (via a browser) instead. See https://warehouse.pypa.io/api-reference/xml-rpc.html#deprecated-methods for more information.
[/simterm]
WHAAAAT?!?
Тобто, просто з консолі з PiP знайти пакет неможливо? Це як так? Трохи “розрив шаблону”.
Окей – поки лишимо, як є, хоча далі з цим знову зустрінемось, і таки доведеться фіксити.
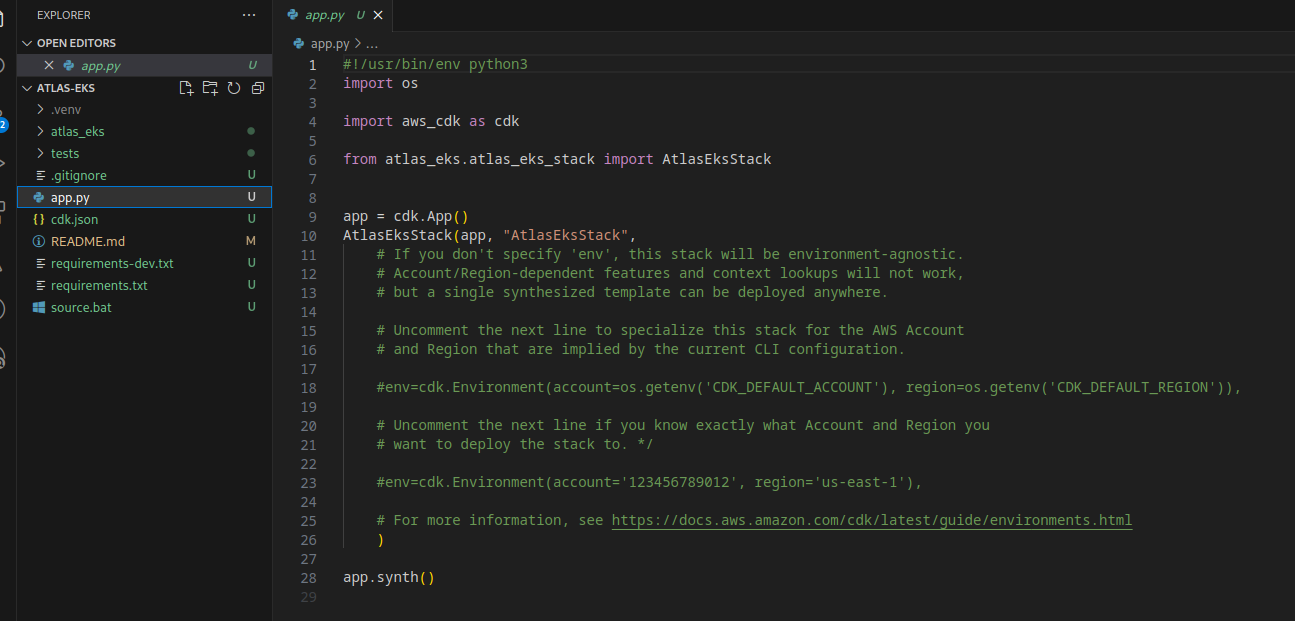
Змінні в CDK Stack
Що тепер хочеться, це додати змінну для Environment – Dev/Stage/Prod, і потім використовати її в іменах ресурсів та тегах.
Додамо до app.py змінну $EKS_STAGE, а до створення AtlasEksStack() – передаємо її другим агрументом, щоб використати як ім’я стеку, і додаємо параметр stage, що потім використовувати всередені класу:
Кастомну VPC хочеться, бо по-дефолту CDK створить по Subnet-у у кожній AvailabilityZone, тобто три мережі, плюс до кожної буде свій NAT Gateway. Але по-перше – мені більше подобається самому контролювати розбивку мережі, по-друге – кожен NAT Gateway коштує грошей, а нам поки що fault-tolerance аж на три AvailabilityZone не потрібен, краще зекономити трохи грошей.
Тут як на мене ще один не найкращий нюанс CDK: так, це зручно, що він має багато викорорівневих ресурсів, коли тобі достатньо просто вказати subnet_type=ec2.SubnetType.PUBLIC, а CDK сам створить все необхідне, але особисто мені декларативний підхід Terraform та його HCL виглядає привабливішим, бо навіть якщо використовувати модуль VPC, а не описувати все вручну – набагато простіше зайти в код того модулю і подивитись, що він має “під капотом”, ніж копатись у бібліотеці CDK. Але це чисто особисте “Я так бачу“.
Крім того, в документації не сказано, що PRIVATE_WITH_NAT вже deprecated, побачив це тільки коли перевіряв створення ресурсів:
[simterm]
$ cdk synth
[WARNING] aws-cdk-lib.aws_ec2.VpcProps#cidr is deprecated.
Use ipAddresses instead
This API will be removed in the next major release.
[WARNING] aws-cdk-lib.aws_ec2.SubnetType#PRIVATE_WITH_NAT is deprecated.
use `PRIVATE_WITH_EGRESS`
This API will be removed in the next major release.
[WARNING] aws-cdk-lib.aws_ec2.SubnetType#PRIVATE_WITH_NAT is deprecated.
use `PRIVATE_WITH_EGRESS`
This API will be removed in the next major release.
...
[/simterm]
Окей.
Додаємо availability_zones, в яких хочемо створювати subnets, і описуємо subnet_configuration.
В subnet_configuration описуємо subnet group – одну Public, та одну Private – CDK створить subnet кожного типу в кожній Availability Zone.
На майбутнє – відразу створимо S3 Endpoint, бо в кластері планується Grafana Loki, яка буде ходити в S3 бакети.
До ресурсу eks.Cluster() додаємо параметр vpc.
Весь файл тепер виглядає так:
from aws_cdk import (
aws_eks as eks,
aws_ec2 as ec2,
Stack
)
from constructs import Construct
class AtlasEksStack(Stack):
def __init__(self, scope: Construct, construct_id: str, stage: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
availability_zones = ['us-east-1a', 'us-east-1b']
# Create a new VPC
vpc = ec2.Vpc(self, 'Vpc',
ip_addresses=ec2.IpAddresses.cidr("10.0.0.0/16"),
vpc_name=f'eks-{stage}-1-26-vpc',
enable_dns_hostnames=True,
enable_dns_support=True,
availability_zones=availability_zones,
subnet_configuration=[
ec2.SubnetConfiguration(
name=f'eks-{stage}-1-26-subnet-public',
subnet_type=ec2.SubnetType.PUBLIC,
cidr_mask=24
),
ec2.SubnetConfiguration(
name=f'eks-{stage}-1-26-subnet-private',
subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS,
cidr_mask=24
)
]
)
# Add an S3 VPC endpoint
vpc.add_gateway_endpoint('S3Endpoint',
service=ec2.GatewayVpcEndpointAwsService.S3)
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name=f'eks-{stage}-1-26-cluster',
version=eks.KubernetesVersion.V1_26,
vpc=vpc
)
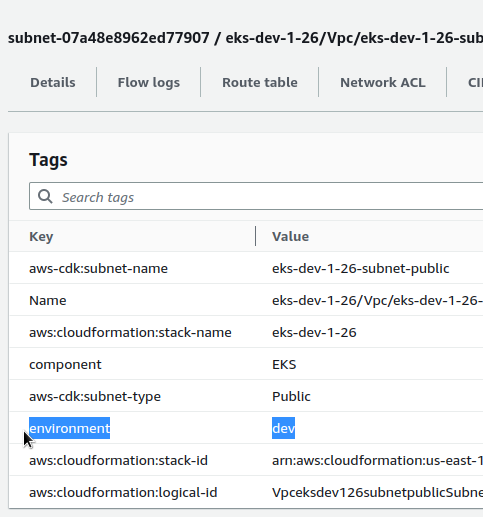
Деплоїмо (Total time: 182.67s просто на додавання тегів на ресурси), та перевіряємо теги:
Все є.
Створення NodeGroup
Взагалі скоріш за все будемо використовувати Karpenter замість “класичного” Cluster Autoscaler, бо про Karpenter чув багато гарних відгуків і хочеться його спробувати у ділі, і тоді ноди треба буде переробити, але поки що створимо звичайну Managed NodeGroup за допомогою add_nodegroup_capacity().
До файлу atlas_eks_stack.py додаємо cluster.add_nodegroup_capacity() з Amazon Linux AMI :
...
# Create the EC2 node group
nodegroup = cluster.add_nodegroup_capacity(
'Nodegroup',
instance_types=[ec2.InstanceType('t3.medium')],
desired_size=1,
min_size=1,
max_size=3,
ami_type=eks.NodegroupAmiType.AL2_X86_64
)
Необхідні IAM-ролі CDK має створити сам – подивимось.
У ресурсі eks.Cluster() вказуємо default_capacity=0, щоб СDK не створював власну дефолтну групу:
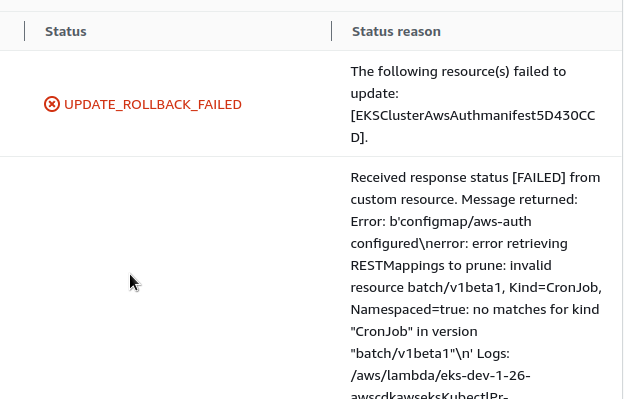
Error: b’configmap/aws-auth configured\nerror: error retrieving RESTMappings to prune: invalid resource batch/v1beta1, Kind=CronJob, Namespaced=true: no matches for kind “CronJob” in version “batch/v1beta1″\n’
Зараз стек вже задеплоєно, запускаємо cdk deploy, щоб оновити – і…
[simterm]
eks-dev-1-26: creating CloudFormation changeset...
1:26:35 PM | UPDATE_FAILED | Custom::AWSCDK-EKS-KubernetesResource | EKSClusterAwsAuthmanifest5D430CCD
Received response status [FAILED] from custom resource. Message returned: Error: b'configmap/aws-auth configured\nerror: error retrieving RESTMappings to prune: invalid resource batch/v1beta1, Kind=CronJob, Namespaced=true: no matches for kind "CronJob" in version "bat
ch/v1beta1"\n'
[/simterm]
Шта? Якого біса?
aws-auth ConfigMap, Kind=CronJob? Звідки це?
Тобто, мабуть, CDK намагається оновити aws-auth ConfigMap, щоб додати NodeGroup AIM роль, але… Але – що?
При чьому проявляється це тільки під час оновлення стеку. Якщо створювати його заново – то все працює. Але тут варто згадати про швидкість роботи CDK/CloudFormation, бо видалення і створення займає хвилин 30-40.
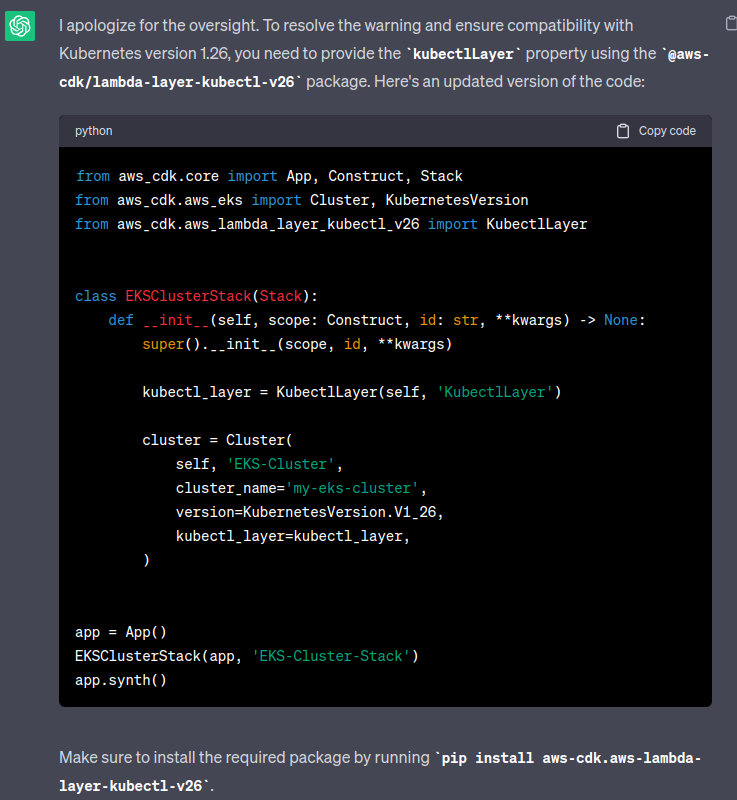
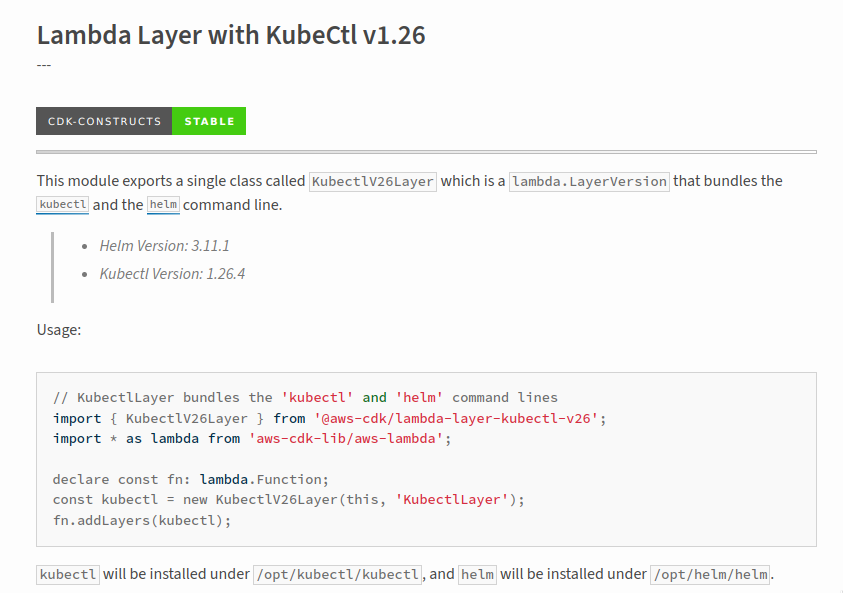
KubectlV26Layer
Ну, все ж довелося фіксити цю проблему.
Добре… Шукаємо просто в браузері – aws-cdk.lambda-layer-kubectl-v26. Є така ліба. Але навіть у PyPi репозиторії приклади на TypeScript – щиро дякую:
Це взагалі проблема при роботі з AWS CDK на Python – дуже багато прикладів все одно на TS.
Окей, ладно – лібу знайшли, вона називається aws-cdk.lambda-layer-kubectl-v26, встановлюємо:
...
from aws_cdk.lambda_layer_kubectl_v26 import KubectlV26Layer
...
# to fix warning "You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property"
kubectl_layer = KubectlV26Layer(self, 'KubectlV26Layer')
...
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name=f'eks-{stage}-1-26-cluster',
version=eks.KubernetesVersion.V1_26,
vpc=vpc,
default_capacity=0,
kubectl_layer=kubectl_layer
)
...
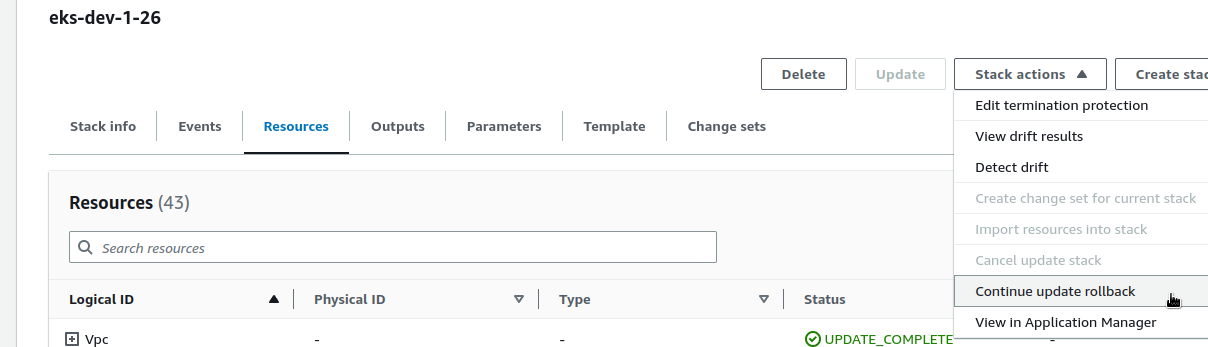
Повторюємо деплой для апдейту вже існуючого стеку, і…
CloudFormation UPDATE_ROLLBACK_FAILED
І маємо іншу помилку, бо після “Error: b’configmap/aws-auth configured\nerror” стек лишився у статусі UPDATE_ROLLBACK_FAILED:
[simterm]
...
eks-dev-1-26: deploying... [1/1]
eks-dev-1-26: creating CloudFormation changeset...
❌ eks-dev-1-26 failed: Error [ValidationError]: Stack:arn:aws:cloudformation:us-east-1:492***148:stack/eks-dev-1-26/9c7daa50-10f4-11ee-b64a-0a9b7e76090b is in UPDATE_ROLLBACK_FAILED state and can not be updated.
...
Тож видаляємо, і йдемо на Фейсбук дивитись котиків, поки воно буде перестворюватись.
Cannot replace cluster “since it has an explicit physical name
На цьому місці ще ловив “Cannot replace cluster “eks-dev-1-26-cluster” since it has an explicit physical name.“, виглядало це так:
[simterm]
...
2:30:45 PM | UPDATE_FAILED | Custom::AWSCDK-EKS-Cluster | EKSCluster676AE7D7
Received response status [FAILED] from custom resource. Message returned: Cannot replace cluster "eks-dev-1-26-cluster" since it has an explicit physical name. Either rename the cluster or remove the "name" configuration
...
[/simterm]
Але на цей раз не зарепродьюсилось, хоча треба мати на увазі, бо точно вилізе ще колись.
Добре, отже тепер вже маємо VPC, EKS Cluster та NodeGroup – час подумати про IAM.
IAM Role та aws-auth ConfigMap
Що треба зробити наступним – це створити IAM-роль, яку можна буде assume для отримання доступу до кластеру.
Поки що без всяких RBAC та юзер-груп – просто роль, щоб потім виконати aws eks update-kubeconfig.
from aws_cdk import (
...
aws_iam as iam,
...
)
...
# Create an IAM Role to be assumed by admins
masters_role = iam.Role(
self,
'EksMastersRole',
assumed_by=iam.AccountRootPrincipal()
)
# Attach an IAM Policy to that Role so users can access the Cluster
masters_role_policy = iam.PolicyStatement(
actions=['eks:DescribeCluster'],
resources=['*'], # Adjust the resource ARN if needed
)
masters_role.add_to_policy(masters_role_policy)
cluster.aws_auth.add_masters_role(masters_role)
# Add the user to the cluster's admins
admin_user = iam.User.from_user_arn(self, "AdminUser", user_arn="arn:aws:iam::492***148:user/arseny")
cluster.aws_auth.add_user_mapping(admin_user, groups=["system:masters"])
masters_role – роль, яку можна буде assume будь-ким з AWS-аккаунту, а admin_user – мій IAM юзер для “прямого” доступу до кластеру.
CfnOutput
Outputs CloudFormation-стеку. Наскільки пам’ятаю, може використовуватись для cross-stack передачі values, але нам більше треба для отримання ARN-у masters_role:
from aws_cdk import (
...
Stack, CfnOutput
)
...
# Output the EKS cluster name
CfnOutput(
self,
'ClusterNameOutput',
value=cluster.cluster_name,
)
# Output the EKS master role ARN
CfnOutput(
self,
'ClusterMasterRoleOutput',
value=masters_role.role_arn
)
По результату можу сказати одне – особисто я не готовий брати відповідальність за роботу такого стеку у production.
Можливо, якщо з CDK попрацювати ще, і знати основні його підводні камені, та згадати всі “особливості” CloudFormation – то з ними можна жити. Але поки що – ні, взагалі не хочеться.
Давно і багато чув про VictoriaMetrics, і нарешті настав час, коли її можна спробувати.
Отже, в двох словах – VictoriaMetrics це “Prometheus на стероідах”, і повністю з ним сумісна – може використовувати його файли конфігурації, експортери, PromQL тощо.
Тож як для людини, яка завжди користувалась Prometheus, перше питання – в чьому різниця? Єдине, що пам’ятаю, це те, що VictoriaMetrics начебто вміє в anomaly detection, чого не вистачало в Prometheus – давно хотілось додати.
В Google порівнянь не так багато, але знайшлись такі:
Отже, сьогодні глянемо на архітектуру і компоненти, запустимо VictoriaMetrics з Docker Compose, налаштуємо збір метрик с Prometheus exporters, глянемо як там з алертами, і підключимо Grafana.
Prometheus з Alertmanager, пачка експортерів та Grafana вже є, наразі запущені просто через Docker Compose на AWS EC2, туди ж додамо інстанс VictoriaMetrics. Тобто основна ідея – замінити Prometheus на VictoriaMetrics.
З того, що побачив поки запускав VictoriaMetrics – виглядає прям дуже цікаво. Більше можливостей по функціям, по шаблонам алертів, сам UI дає більше можливостей для роботи з метриками. Спробуємо його використати замість Prometehus в нашому проекті, подивимось, як воно буде. Правда, якихось прикладів в тому ж Гуглі небагато, проте ChatGPT може допомогти.
Архітектура VictoriaMetrics
VictoriaMetrics має cluster version та single-node version. Для невеликих проектів до мільйона метрик в секунду рекомендується використовувати single node, але у кластер-версії гарно описана загальна архітектура.
Основні сервіси та компоненти VictoriaMetrics:
vmstorage: відповідає за зберігання даних та відповіді на запит даних клієнтами (vmselect)
vmselect: відповідає за обробку вхідних запитів на вибірку даних та збор даних з нод vmstorage
vminsert: відповідає за прийом метрик та розподіл даних по нодам vmstorage у відповідності до імен та лейбл цих метрик
vmui: Web UI для доступу к даним і параметрам конфігурацї
vmalert: обробляє алерти з файлу конфігурації та відправляє їх до Alertmanager
vmagent: займається збором метрик з різних джерел, таких як експортери Prometheus, їхнє фільтрування та релейбл, і зберігання у сховищі даних (самій VictoriaMetrics або через remote_write протокол Prometheus)
vmanomaly: VictoriaMetrics Anomaly Detection – сервіс, який постійно сканує дані у VictoriaMetrics і за допомогою механізмів machine learning виявляє несподівані зміни, які можна використовувати у алертах
vmauth: простий auth proxy, роутер та лоад-балансер для VictoriaMetrics.
Запуск VictoriaMetrics з Docker Compose
Отже, як ми можемо використати VictoriaMetrics у випадку, якщо вже є Prometheus та його експортери?
можемо налаштувати Prometheus слати метрики у VictoriaMetrics, див. Prometheus setup (майте на увазі, що remote_write на Prometheus-інстансі збільшить споживання ресурсів ЦПУ та диску на 25%) – не бачу сенсу в нашому випадку, але можливо буде корисним у разі використання якогось KubePrometehusStack
можемо налаштувати VictoriaMetrics на збір даних з експортерів Prometheus, див. How to scrape Prometheus exporters such as node-exporter, тобто як раз зробити те, що хочеться зараз – замінити Prometheus на VictoriaMetrics з мінімальними змінами у конфігурації Prometheus
Для victoriametrics поки що закоментуємо --vmalert.proxyURL, додамо його згодом.
До vmagent підключаємо каталог ./prometheus – в ньому маємо файл prometheus.yaml з конфігурацією srape_jobs, та файли параметрів експортерів (наприклад – ./prometheus/blackbox.yml та /prometheus/blackbox-targets/targets.yaml для Blackbox Exporter).
У --remoteWrite.url вказуємо, куди будемо писати отримані метрики – до інстансу VictoriaMetrics.
Запускаємо:
[simterm]
# docker compose up
[/simterm]
Якщо перейти без URI, тобто просто на domain.com/ – то видасть всі доступні шляхи, дуже прям зручно:
field evaluation_interval not found in type promscrape.GlobalConfig
Але vmagent не запустився:
[simterm]
2023-06-05T09:38:31.376Z fatal VictoriaMetrics/lib/promscrape/scraper.go:117 cannot read "/etc/prometheus/prometheus.yml": cannot parse Prometheus config from "/etc/prometheus/prometheus.yml": cannot unmarshal data: yaml: unmarshal errors:
line 4: field evaluation_interval not found in type promscrape.GlobalConfig
line 13: field rule_files not found in type promscrape.Config
line 19: field alerting not found in type promscrape.Config; pass -promscrape.config.strictParse=false command-line flag for ignoring unknown fields in yaml config
Перезапускаємо сервіси, та заглянемо на порт 8429, vmagent – теж є лінки :
Перевіряємо таргети – вони є, тобто vmagent зчитав файл prometheus.yaml, але не всі працюють, наприклад – Sentry експортер є, YACE є, а от blackbox, node_exporter та cAdvisor не бачить:
А чому?
Ага… Не бачить тих, у кого sd_configs, тобто динамічний сервіс-діскавері:
... - job_name: 'cadvisor'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
dns_sd_configs:
- names:
- 'tasks.cadvisor'
type: 'A'
port: 8080
...
error in A lookup for “tasks.cadvisor”: lookup tasks.cadvisor on 127.0.0.11:53: no such host
А логи кажуть, що контейнер з vmagent не може отримати A-запис з DNS:
[simterm]
...
vmagent | 2023-06-05T10:04:10.818Z error VictoriaMetrics/lib/promscrape/discovery/dns/dns.go:163 error in A lookup for "tasks.cadvisor": lookup tasks.cadvisor on 127.0.0.11:53: no such host
vmagent | 2023-06-05T10:04:10.821Z error VictoriaMetrics/lib/promscrape/discovery/dns/dns.go:163 error in A lookup for "tasks.node-exporter": lookup tasks.node-exporter on 127.0.0.11:53: no such host
...
[/simterm]
Читаємо документацію по dns_sd_configs, де говориться про “# names must contain a list of DNS names to query“, але в мене зараз job описана з names = tasks.container_name, див. Container discovery.
Спробуємо вказати просто ім’я, тобто cadvisor замість tasks.cadvisor:
Отже, зара маємо запущений Alertmanager та Prometheus.
У prometheus.yaml маємо вказаний файл з алертами:
...
rule_files:
- 'alert.rules'
...
Що нам треба – це запустити vmalert, якому вкажемо “бекенд” у вигляді Alertmanager, якому він буде слати алерти, та сам файл з алертами у форматі Prometheus.
Як і сама VictoriaMetrics, vmalert має дещо ширші можливості, ніж Prometheus, наприклад – зберігає статус алертів, тож рестарт контейнеру не сбиває silenced алерти. Ще є зручна змінна $for для шаблонів, в якій передається значення for з алерту, і можемо мати щось таке:
...
for: 5m
annotations:
description: |-
{{ if $value }} *Current latency*: `{{ $value | humanize }}` milliseconds {{ end }} during `{{ $for }}` minutes
...
Також є підримка httpAuth, є можливість виконати запит алерту з query та багато іншого, див. Template functions.
Тут у datasource.url вказуємо, звідки брати метрики для перевірки у алертах, remoteRead.url та remoteWrite.url – де зберігати стан алертів.
У notifier.url – куди будемо слати алерти (а вже Alertmanager через свій конфіг відправить їх у Slack/Opsgenie/etc). І у rule вказуємо сам файл з алертами, який підключаємо у volumes.
Перезапускаємо контейнери з docker compose restart, и заходимо на порт 8880:
Окей, є алерт-рули.
Спробуємо тригернути тестовий алерт – і маємо новий алерт у vmalert Alerts:
Та повідомлення в Slack від Alertmanager:
Все працює.
Тепер можна відключати контейнер з Prometheus, тільки оновити depends_on у Grafana – замість prometheus вказати victoriametrics, і замінити data sources у дашбордах.
Bonus: Alertmanager Slack template
І приклад шаблону для нотіфікацій в Slack. Він ще буде перероблюватись, поки що вся система більше в стані proof of concept, але в цілому буде якось так.
Файл alertmanager/notifications.tmpl з шаблоном:
{{/* Title of the Slack alert */}}
{{ define "slack.title" -}}
{{ if eq .Status "firing" }} :scream: {{- else -}} :relaxed: {{- end -}}
[{{ .Status | toUpper -}} {{- if eq .Status "firing" -}}:{{ .Alerts.Firing | len }} {{- end }}] {{ (index .Alerts 0).Annotations.summary }}
{{ end }}
{{ define "slack.text" -}}
{{ range .Alerts }}
{{- if .Annotations.description -}}
*Description*: {{ .Annotations.description }}
{{- end }}
{{- end }}
{{- end }}
Темплейт для алерту – підключається в контейнер vmalerts, див. Reusable templates:
{{ define "grafana.filter" -}}
{{- $labels := .arg0 -}}
{{- range $name, $label := . -}}
{{- if (ne $name "arg0") -}}
{{- ( or (index $labels $label) "All" ) | printf "&var-%s=%s" $label -}}
{{- end -}}
{{- end -}}
{{- end -}}
І сам алерт:
- record: aws:apigateway_integration_latency_average_sum
expr: sum(aws_apigateway_integration_latency_average) by (dimension_ApiName, tag_environment)
- alert: APIGatewayLatencyBackendProdTEST2
expr: aws:apigateway_integration_latency_average_sum{tag_environment="prod"} > 100
for: 1s
labels:
severity: info
component: backend
environment: test
annotations:
summary: "API Gateway latency too high"
description: |-
The time between when API Gateway relays a request to the backend and when it receives a response from the backend
*Environment*: `{{ $labels.tag_environment }}`
*API Gateway name*: `{{ $labels.dimension_ApiName }}`
{{ if $value }} *Current latency*: `{{ $value | humanize }}` milliseconds {{ end }}
grafana_url: '{{ $externalURL }}/d/overview/overview?orgId=1{{ template "grafana.filter" (args .Labels "environment" "component") }}'
А $externalURL отримується vmalerts з параметру --external.url=http://100.***.***.197:3000".
Прийшла досить цікава задачка – побудувати в Grafana дашборду, в якій би відображався статус процессу розробки, а саме – перформанс, тобто ефективність наших DevOps-процесів.
Потрібно це тому, что ми намагаємось побудувати “true continuous deployment”, щоб код автоматично потрапляв у Production, і нам важливо бачити як саме проходить процес розробки.
Загалом для оцінки ефективності процессу розробки ми придумали 5 метрик:
Deployment Frequency: як часто виконуються деплої
Lead Time for Changes: скільки часу займає доставка фічі до Production, тобто час між її першим коммітом в репозиторій до моменту, коли вона потрапляє в Production
PR Lead Time: час, котрий фіча “вісить” у статусі Pull Request
Change Failure Rate: процент деплоїв, які викликали проблеми у Production
Time to Restore Service: час на відновлення системи у випадку її краху
Почати вирішили з метрики для PR Lead Time – будемо міряти час від створення Pull Request до його мержу в master-гілку, і виводити його на Grafana-дашборді.
Далі, спробуємо отримати інформацю про пул-реквест, а саме – час його створення та закриття.
Тут, щоб спростити та пришвидшити розробку експортеру і його тестування, будемо використовувати тільки один репозиторій і будемо вибирати закриті пул-реквести тільки за останній тиждень, а потім вже повернемо цикл, в якому будемо перебирати всі репозиторії та пул-реквести в них:
...
# get infro about a repository
repository = github_instance.get_repo("OrgName/repo-name")
# get all PRs in a given repository
pull_requests = repository.get_pulls(state='closed')
# to get PRs closed during last N days
days_ago = datetime.now() - timedelta(days=7)
for pull_request in pull_requests:
merged_at = pull_request.closed_at
created_at = pull_request.merged_at
if created_at >= days_ago and created_at and merged_at:
print(f"Pull Request: {pull_request.number} Created at: {pull_request.created_at} Merged at: {pull_request.merged_at}")
Тут у циклі для кожного PR отримуємо його атрибути merged_at та created_at, див. List pull requests – у Response schema є список всіх атрибутів, які ми можемо побачити для кожного PR.
У days_ago = datetime.now() - timedelta(days=7) отримуємо день 7 днів тому, щоб вибрати пул-реквести, створені після цієї дати, а потім для перевірки виводимо на екран інформацію про дату створення PR та дату, коли його змержили в master.
Тепер можемо починати думати про метрику для Prometheus.
Prometheus Client та метрики
Встановлюємо бібліотеку:
[simterm]
$ pip install prometheus_client
[/simterm]
Щоб мати більше уяви про те, що саме ми хочимо побудувати – можна почитати How to Read Lead Time Distribution, де є приклад такого графіку:
Тобто в нашому випадку будуть:
x-axis (горизонталь): час (години на закриття PR)
y-axis (вертикаль): кількість PR закриті за Х-годин
Тут я досить багато часу витратив, намагюсь зробити це з використанням різних типів метрик для Prometheus, і спочатку пробував Histogram, бо наче ж виглядає логічно – в бакети гістрограми вносити значення, по типу такого:
buckets = [1, 2, 5, 10, 20, 100, 1000]
gh_repo_lead_time = Histogram('gh_repo_lead_time', 'Time in hours between PR open and merge', buckets=buckets, labelnames=['gh_repo_name'])
Проте, з Histogram не вийшло, бо в бакет 1000 потрапляють всі значення меньше 1000, в бакет 100 – всі менше ста, і так далі, а нам потрібно в бакет 100 включати тільки дані про пул-реквести, які були закриті між 50 годин та 100 годин.
Але врешті-решт все вийшло з використанням типу Counter та лейбл repo_name та time_interval.
Спочатку створимо Python dictionary з “бакетами” – це години, на протязі яких були закриті пул-реквести:
time_intervals = [1, 2, 5, 10, 20, 50, 100, 1000]
Далі будемо отримувати кількість годин на закриття у кожному PR, перевіряти в який саме “бакет” цей PR попадає, і потім заносити дані у метрику – додавати лейблу time_interval зі значенням з бакету, в який це PR попав, та інкрементити значення каунтеру.
Створємо саму метрику pull_request_duration_count та функцію calculate_pull_request_duration(), в яку будемо передавати пул-реквест для перевірки:
...
# buckets for PRs closed during {interval}
time_intervals = [1, 2, 5, 10, 20, 50, 100, 1000] # 1 hour, 2 hours, 5 hours
# prometheus metric to count PRs in each {interval}
pull_request_duration_count = Counter('pull_request_duration_count',
'Count of Pull Requests within a time interval',
labelnames=['repo_name', 'time_interval'])
def calculate_pull_request_duration(repository, pr):
created_at = pr.created_at
merged_at = pr.merged_at
if created_at >= days_ago and created_at and merged_at:
duration = (merged_at - created_at).total_seconds() / 3600
# Increment the histogram for each time interval
for interval in time_intervals:
if duration <= interval:
print(f"PR ID: {pr.number} Duration: {duration} Interval: {interval}")
pull_request_duration_count.labels(time_interval=interval, repo_name=repository).inc()
break
...
Тут у calculate_pull_request_duration():
отримуємо час створення та мержу пул-реквеста
перевіряємо, що PR молодший за $days_ago і має атрібути created_at та merged_at, тобто він вже змержений
рахуємо, скільки часу він провів до моменту його мержу в мастер-гілку, та переводимо в години – duration = (merged_at - created_at).total_seconds() / 3600
у циклі проходимось по “бакетах” з нашого time_intervals dictionary – шукаємо, в який з них попадає цей PR
і в кінці створюємо метрику pull_request_duration_count, в labels якої вносимо ім’я репозиторію та “бакет”, в який попав цей пул-реквест, і інкриментимо значення каунтера на +1: pull_request_duration_count.labels(time_interval=interval, repo_name=repository).inc()
Далі, описуємо функцію main() та ї виклик:
...
def main():
# connect to Gihub
github_instance = Github(github_token)
organization_name = 'OrgName'
# read org
organization = github_instance.get_organization(organization_name)
# get repos list
repositories = organization.get_repos()
for repository in repositories:
# to set in labels
repository_name = repository.full_name.split('/')[1]
pull_requests = repository.get_pulls(state='closed')
if pull_requests.totalCount > 0:
print(f"Checking repository: {repository_name}")
for pr in pull_requests:
calculate_pull_request_duration(repository_name, pr)
else:
print(f"Sckipping repository: {repository_name}")
# Start Prometheus HTTP server
start_http_server(8000)
print("HTTP server started")
while True:
time.sleep(15)
pass
if __name__ == '__main__':
main()
Тут ми:
створємо об’єкт Github
отримуємо список репозиторіїв організацї
для кожного репозиторія викликаємо get_pulls(state='closed')
перевіряємо, що в репозиторії були пул-реквести, і по черзі відправляємо їх до функції calculate_pull_request_duration()
запускаємо HTTP-сервер на порту 8000, де будемо отримувати метрики
Повний код Prometheus-експортеру
Все разом тепер виходить так:
#!/usr/bin/env python
from datetime import datetime, timedelta
import time
from prometheus_client import start_http_server, Counter
from github import Github
# TODO: move to env vars
github_token = "ghp_ys9***ilr"
# to get PRs closed during last N days
days_ago = datetime.now() - timedelta(days=7)
# buckets for PRs closed during {interval}
time_intervals = [1, 2, 5, 10, 20, 50, 100, 1000] # 1 hour, 2 hours, 5 hours
# prometheus metric to count PRs in each {interval}
pull_request_duration_count = Counter('pull_request_duration_count',
'Count of Pull Requests within a time interval',
labelnames=['repo_name', 'time_interval'])
def calculate_pull_request_duration(repository, pr):
created_at = pr.created_at
merged_at = pr.merged_at
if created_at >= days_ago and created_at and merged_at:
duration = (merged_at - created_at).total_seconds() / 3600
# Increment the Counter for each time interval
for interval in time_intervals:
if duration <= interval:
print(f"PR ID: {pr.number} Duration: {duration} Interval: {interval}")
pull_request_duration_count.labels(time_interval=interval, repo_name=repository).inc()
break
def main():
# connect to Gihub
github_instance = Github(github_token)
organization_name = 'OrgNameg'
# read org
organization = github_instance.get_organization(organization_name)
# get repos list
repositories = organization.get_repos()
for repository in repositories:
# to set in labels
repository_name = repository.full_name.split('/')[1]
pull_requests = repository.get_pulls(state='closed')
if pull_requests.totalCount > 0:
print(f"Checking repository: {repository_name}")
for pr in pull_requests:
calculate_pull_request_duration(repository_name, pr)
else:
print(f"Skipping repository: {repository_name}")
# Start Prometheus HTTP server
start_http_server(8000)
print("HTTP server started")
while True:
time.sleep(15)
pass
if __name__ == '__main__':
main()
Чекаємо, поки будуть перевірені всі репозиторії і запуститься http_server(), та перевіряємо метрики з curl:
[simterm]
$ curl localhost:8000
...
# HELP pull_request_duration_count_total Count of Pull Requests within a time interval
# TYPE pull_request_duration_count_total counter
pull_request_duration_count_total{repo_name="***-ios",time_interval="10"} 1.0
pull_request_duration_count_total{repo_name="***-ios",time_interval="1"} 1.0
pull_request_duration_count_total{repo_name="***-ios",time_interval="50"} 2.0
pull_request_duration_count_total{repo_name="***-ios",time_interval="100"} 1.0
pull_request_duration_count_total{repo_name="***-ios",time_interval="20"} 1.0
pull_request_duration_count_total{repo_name="***-ios",time_interval="1000"} 1.0
...
[/simterm]
Гуд! Працює.
GitHub API rate limits
Майте на увазі, що GitHub обмежує кількість запитів до API – 5,000 на годину зі звичайним юзерським токеном, та 15.000, якщо у вас Enterprise ліцензія. Див. Rate limits for requests from personal accounts.
Якщо його перевищити – отримаєте 403:
[simterm]
...
File "/usr/local/lib/python3.11/site-packages/github/Requester.py", line 423, in __check
raise self.__createException(status, responseHeaders, output)
github.GithubException.RateLimitExceededException: 403 {"message": "API rate limit exceeded for user ID 132904972.", "documentation_url": "https://docs.github.com/rest/overview/resources-in-the-rest-api#rate-limiting"}
[/simterm]
Prometheus Server та отримання метрик
Залишилось почати збирати метрики у Prometheus, та створити Grafana dashboard.
Запуск Prometheus Exporter
Створюємо Dockerfile:
FROM python:latest
COPY github-exporter.py ./
RUN pip install prometheus_client PyGithub
CMD [ "python", "./github-exporter.py"]
Збираємо образ:
[simterm]
$ docker build -t gh-exporter .
[/simterm]
У нас Prometheus/Grafana поки що в простому Docker Compose – додаємо запуск нашого нового експортеру:
Запускаємо, і за хвилину перевіряємо метрики в Prometheus:
Найс!
Grafana dashboard
Останнім робимо саму борду.
Додамо змінну, щоб мати змогу відобразити дані по конкретному репозіторію/ях:
Для візуалізації я використав тип Bar gauge і такий query:
sum(pull_request_duration_count_total{repo_name=~"$repository"}) by (time_interval)
У Overrides задаємо колір для кожної колонки.
Єдине, що тут не дуже – це сортування колонок: сам Prometheus це не вміє і не хоче (див. Added sort_by_label function for sorting by label values), а Grafana сортує по першим цифрам у отриманих з label значеннях, тобто 1, 2, 5, не враховуючи кількість 0 після цифри.
Але то вже деталі – може, таки візьмемо Victoria Metrics з її sort_by_label, або в Grafana просто створимо кілька графіків, і в кожному будемо виводити дані по конкретному “бакету” та кількості пул-реквестів в ньому.