![]()
So, Terraform is great, but so far in our project, we have decided to create the first AWS EKS clusters using the AWS CDK, because firstly, it is already on the project, and secondly, it is very interesting to try a new tool.
Today we will see what came out of it, and how a new cluster and necessary resources were created.
I wrote about my first acquaintance with CDK here – AWS: CDK – an overview, and Python examples.
Going ahead – personally, I am absolutely not happy with CDK:
- it’s not about the KISS (Keep It Simple Stupid) principle, it’s not about the “explicit is better than implicit“
- most of the documentation is with TypeScript examples, even in the PyPi repository
- a bunch of separate libraries and modules, sometimes issues with their imports
- overall CDK/Python code overload – Terraform with its HCL or Pulumi with Python seem much easier to understand the overall picture of the infrastructure that this code describes
- the overload of the CloudFormation stack itself created with the CDK – a bunch of IAM roles, unknown Lambda functions, and so on – when it breaks, you will have to search for a very long time where and what exactly “went wrong”
- asking Google about “AWS CDK Python create something ” is almost useless, because there will be no results at all, but they will be in TypeScript
Although the post was planned in the style of “how to do”, but as a result, it’s more about “How to shoot yourself in the foot, implementing the AWS CDK in a project”. And after working with it a few weeks after this post was written, I didn’t change my mind, and my personal impressions even became worse.
As said – “mice cried, pricked, but continued eating a cactus”.
Contents
AWS CDK vs Terraform
Again, although the post itself is not about this, here is a few words after working with CDK and comparing it to Terraform.
Time To Create: AWS CDK vs Terraform
The first thing I want to show at the beginning is the speed of AWS CDK vs Terraform:

The test, of course, is quite synthetic, but it showed the difference in performance very well.
I did not specifically create NAT Gateways, because their creation takes more than a minute just to start the NAT instances themselves while creating VPC/Subnets/etc takes no time, so we can see exactly the speed of CDK/CloudFormation versus Terraform.
Later, I also measured the creation of VPC+EKS with CDK and Terraform:
CDK
- create: 18m54.643s
- destroy: 26m4.509s
Terraform:
- create: 12m56.801s
- destroy: 5m32.329s
AWS CDK workflow
And in general, the CDK work process looks too complicated:
- write a code in Python
- which is routed to the CDK backend on NodeJS
- generates CloudFormation Template and ChangeSets
- the CDK creates a bundle of Lambda functions for its work
- and only then resources are created
Plus, a whole bunch of AIM roles and Lambda functions with unclear and implicit purposes are created in the CloudFormation stack for EKS.
AWS CDK and new AWS features
As expected, CDK doesn’t have all the new features of AWS. I encountered this a few years ago when I needed to create cross-region VPC Peering in CloudFormation, and CloudFormation did not support it, although it was already implemented in Terraform.
It turned out similarly now: the latest version of CDK (2.84.0) does not support EKS 1.27, the release of which took place almost a month ago, on May 24 – Amazon EKS now supports Kubernetes version 1.27. But Terraform already supports it – AWS EKS Terraform module.
Getting Started: Ask ChatGPT
To have some starting point – I’ve asked the ChatGPT. In general, it gave an idea to start from, although with outdated imports and some attributes that had to be rewritten:
Let’s go.
Python virtualevn
Create a Python virtualevn:
[simterm]
$ python -m venv .venv $ ls -l .venv/ total 16 drwxr-xr-x 2 setevoy setevoy 4096 Jun 20 11:18 bin drwxr-xr-x 3 setevoy setevoy 4096 Jun 20 11:18 include drwxr-xr-x 3 setevoy setevoy 4096 Jun 20 11:18 lib lrwxrwxrwx 1 setevoy setevoy 3 Jun 20 11:18 lib64 -> lib -rw-r--r-- 1 setevoy setevoy 176 Jun 20 11:18 pyvenv.cfg
[/simterm]
ACtivate it:
[simterm]
$ . .venv/bin/activate (.venv)
[/simterm]
Now we can create a new application.
AWS CDK Init
Ccreate our Python stack template:
[simterm]
$ cdk init app --language python ... ✅ All done!
[/simterm]
We get the following structure of files and directories:
[simterm]
$ tree .
.
├── README.md
├── app.py
├── atlas_eks
│ ├── __init__.py
│ └── atlas_eks_stack.py
├── cdk.json
├── requirements-dev.txt
├── requirements.txt
├── source.bat
└── tests
├── __init__.py
└── unit
├── __init__.py
└── test_atlas_eks_stack.py
4 directories, 11 files
[/simterm]
Install dependencies:
[simterm]
$ pip install -r requirements.txt Collecting aws-cdk-lib==2.83.1 Using cached aws_cdk_lib-2.83.1-py3-none-any.whl (41.5 MB) ...
[/simterm]
Check that everything works:
[simterm]
$ cdk list AtlasEksStack
[/simterm]
We now have the following content of the app.py:
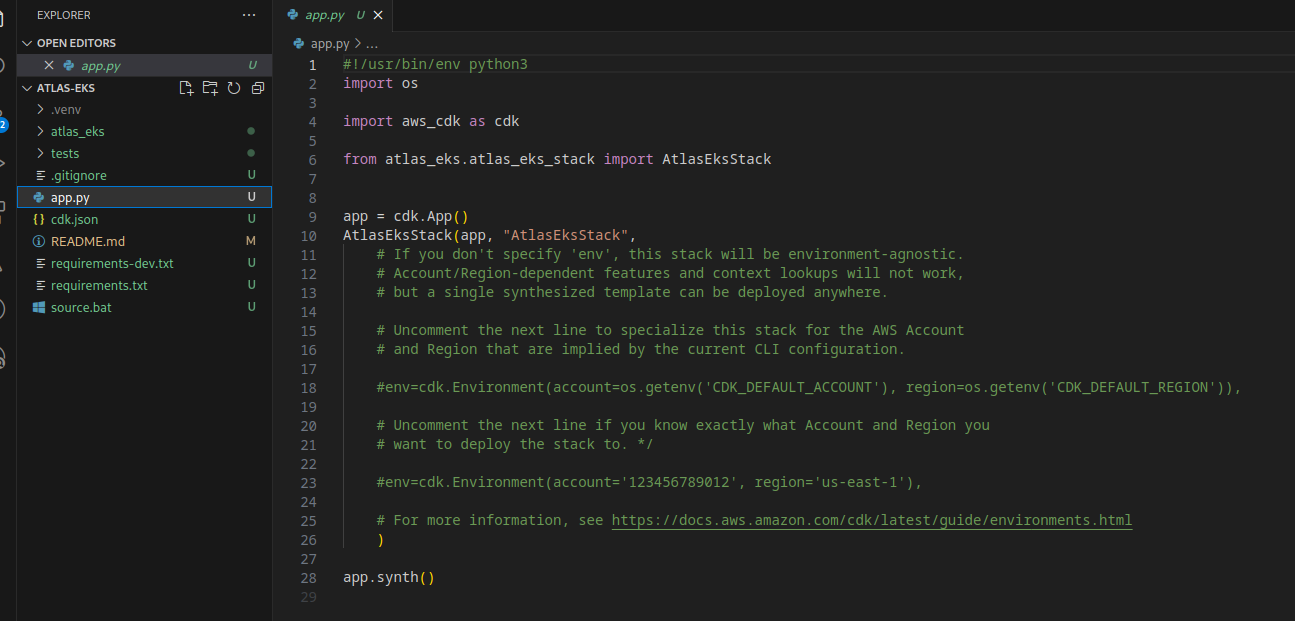
And in the atlas_eks/atlas_eks_stack.py we have a template to create a stack:
from aws_cdk import (
# Duration,
Stack,
# aws_sqs as sqs,
)
from constructs import Construct
class AtlasEksStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# The code that defines your stack goes here
# example resource
# queue = sqs.Queue(
# self, "AtlasEksQueue",
# visibility_timeout=Duration.seconds(300),
# )
Let’s add environment variables to the app.py– AWS account, AWS region, and update the call AtlasEksStack() to use them:
...
AWS_ACCOUNT = os.environ["AWS_ACCOUNT"]
AWS_REGION = os.environ["AWS_REGION"]
app = cdk.App()
AtlasEksStack(app, "AtlasEksStack",
env=cdk.Environment(account=AWS_ACCOUNT, region=AWS_REGION),
)
...
Set the variables in the console:
[simterm]
$ export AWS_ACCOUNT=492***148 $ export AWS_REGION=us-east-1
[/simterm]
Check again with cdk list.
Creating an EKS cluster
Go back to ChatGPT for further instructions:
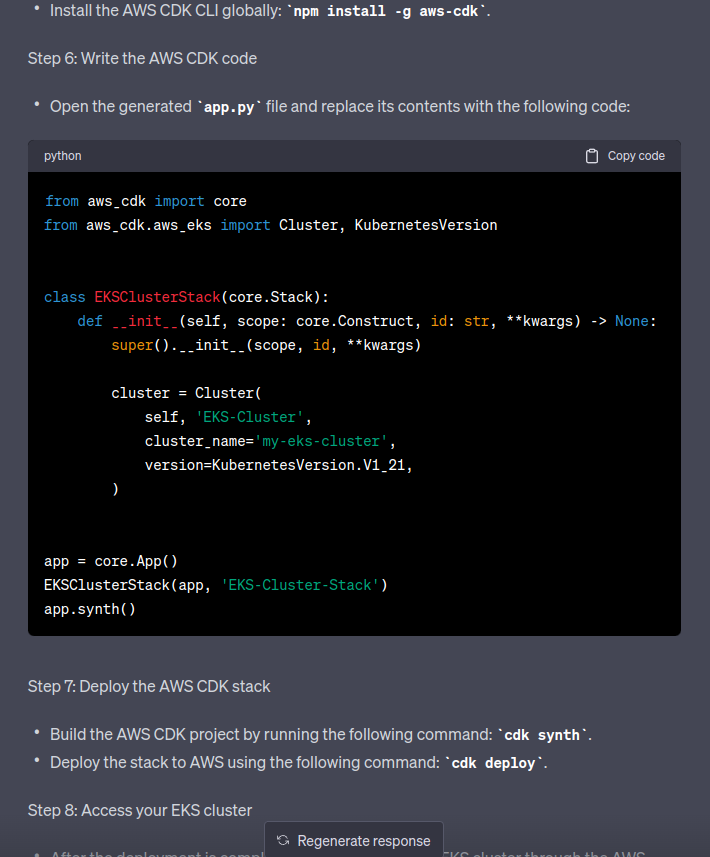
We are interested only in imports here (with which he did not guess), and the cluster = eks.Cluster() resource, to which ChatGPT offers version 1.21, because ChatGPT itself, as we know, has a database until 2021.
CDK: AttributeError: type object ‘KubernetesVersion’ has no attribute ‘V1_27’
Regarding the AWS CDK and the latest AWS features/version, the EKS version error looked like this:
AttributeError: type object ‘KubernetesVersion’ has no attribute ‘V1_27’
Okay – let’s go with the 1.26 for now.
Update the atlas_eks_stack.py file and set version=eks.KubernetesVersion.V1_26:
from aws_cdk import (
aws_eks as eks,
Stack
)
from constructs import Construct
class AtlasEksStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name='my-eks-cluster',
version=eks.KubernetesVersion.V1_26,
)
Check with cdk synth:
[simterm]
$ cdk synth
[Warning at /AtlasEksStack/EKS-Cluster] You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property. This may cause failures as the kubectl version provided with aws-cdk-lib is 1.20, which is only guaranteed to be compatible with Kubernetes versions 1.19-1.21. Please provide a kubectlLayer from @aws-cdk/lambda-layer-kubectl-v26.
Resources:
EKSClusterDefaultVpc01B29049:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
EnableDnsHostnames: true
EnableDnsSupport: true
InstanceTenancy: default
Tags:
- Key: Name
Value: AtlasEksStack/EKS-Cluster/DefaultVpc
Metadata:
aws:cdk:path: AtlasEksStack/EKS-Cluster/DefaultVpc/Resource
...
[/simterm]
CDK itself creates VPCs and subnets and everything else for the network and IAM roles. In general, that’s good, although there are some issues.
Next, we will create our own VPC.
Warning: You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property
At the beginning of its output, cdk synth says something about kubectlLayer:
[Warning at /AtlasEksStack/EKS-Cluster] You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property. This may cause failures as the kubectl version provided with aws-cdk-lib is 1.20, which is only guaranteed to be compatible with Kubernetes versions 1.19-1.21. Please provide a kubectlLayer from @aws-cdk/lambda-layer-kubectl-v26.
From the name, we can assume that CDK will create a Lambda function to run kubectl to perform some tasks in Kubernetes.
The KubectlLayer documentation says that this is “An AWS Lambda layer that includes kubectl and helm”
Thank you very much… But where is it used? For what?
Well, ok… Let’s try to get rid of this warning.
Ask ChatGP again:
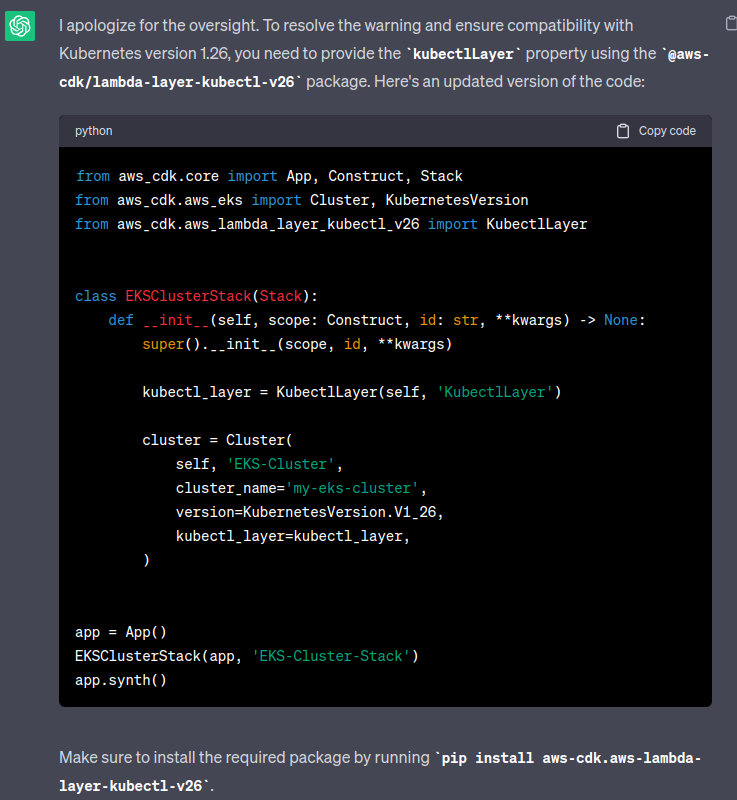
Try to install the aws-lambda-layer-kubectl-v26:
[simterm]
$ pip install aws-cdk.aws-lambda-layer-kubectl-v26 ERROR: Could not find a version that satisfies the requirement aws-cdk.aws-lambda-layer-kubectl-v26 (from versions: none) ERROR: No matching distribution found for aws-cdk.aws-lambda-layer-kubectl-v26
[/simterm]
Da f*****ck!
Well, okay… We remember that ChatGP is “old man” – maybe the lib is called something other?
PyPI no longer supports ‘pip search’
Let’s try the pip search, but first, let’s check that there is the search in PiP at all, because I haven’t used it in a long time:
[simterm]
$ pip search --help Usage: pip search [options] <query> Description: Search for PyPI packages whose name or summary contains <query>. Search Options: -i, --index <url> Base URL of Python Package Index (default https://pypi.org/pypi) ...
[/simterm]
Yeah, it is. So, run the search:
[simterm]
$ pip search aws-lambda-layer-kubectl ERROR: XMLRPC request failed [code: -32500] RuntimeError: PyPI no longer supports 'pip search' (or XML-RPC search). Please use https://pypi.org/search (via a browser) instead. See https://warehouse.pypa.io/api-reference/xml-rpc.html#deprecated-methods for more information.
[/simterm]
What?!?
That is, it is impossible to find the package from the console with PiP?
Okay, for now, we will leave the issue with the aws-lambda-layer-kubectl-v26 as it is, although we will meet with it again later, and will still have to fix it.
Variables in a CDK Stack
Next, I’d like to add a variable for Environment – Dev/Stage/Prod, and then use it in the resource names and tags.
Let’s add a variable $EKS_STAGE to the app.py, and in the AtlasEksStack() pass it as the second argument to be used as the name of the stack. Also, add the stage parameter that will be used then inside the class:
...
EKS_STAGE = os.environ["EKS_ENV"]
app = cdk.App()
AtlasEksStack(app, "f'eks-{EKS_STAGE}-1-26'",
env=cdk.Environment(account=AWS_ACCOUNT, region=AWS_REGION),
stage=EKS_STAGE
)
...
Next, in the atlas_eks_stack.py add the stage: str parameter, and use it when creating eks.Cluster() in the cluster_name:
...
def __init__(self, scope: Construct, construct_id: str, stage: str, **kwargs)
...
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name=f'eks-{stage}-1-26-cluster',
version=eks.KubernetesVersion.V1_26,
)
Set the environment variable in the terminal:
[simterm]
$ export EKS_ENV=dev
[/simterm]
And with cdk list check that the stack name has changed and has $EKS_ENV:
[simterm]
$ cdk list eks-dev-1-26
[/simterm]
Witrh sdk synth check that the name of the cluster has also changed and has the “dev” in it:
[simterm]
$ cdk synth
...
Type: Custom::AWSCDK-EKS-Cluster
Properties:
ServiceToken:
Fn::GetAtt:
- awscdkawseksClusterResourceProviderNestedStackawscdkawseksClusterResourceProviderNestedStackResource9827C454
- Outputs.AtlasEksStackawscdkawseksClusterResourceProviderframeworkonEvent588F9666Arn
Config:
name: eks-dev-1-26-cluster
...
[/simterm]
Good – now we have a cluster, let’s create a VPC for it.
Creating VPC and Subnets
I want a custom VPC because by default CDK will create a Subnet in each AvailabilityZone, i.e. three networks, plus each will have its own NAT Gateway. But firstly, I prefer to control the network breakdown myself, secondly, each NAT Gateway costs money, and we do not need fault-tolerance for up to three AvailabilityZones, so it is better to save some money.
CDK VPC documentation – aws_cdk.aws_ec2.Vpc.
Subnet docs – SubnetType.
Here, in my opinion, is another not the best nuance of CDK: yes, it is nice that it has a lot of high-level resources aka constructs, when all you need is just to specify a subnet_type=ec2.SubnetType.PUBLIC, and CDK will create everything necessary. But personally for me, the declarative approach of Terraform and its HCL looks more attractive, because even if you use the VPC module, and do not describe everything manually, it is much easier to go into the code of that module and see what it has “under the hood” than digging in the CDK library. But this is absolutely personal – “I see it that way“.
In addition, the documentation does not say that PRIVATE_WITH_NAT is already deprecated, I saw it only when I was checking the creation of resources:
[simterm]
$ cdk synth [WARNING] aws-cdk-lib.aws_ec2.VpcProps#cidr is deprecated. Use ipAddresses instead This API will be removed in the next major release. [WARNING] aws-cdk-lib.aws_ec2.SubnetType#PRIVATE_WITH_NAT is deprecated. use `PRIVATE_WITH_EGRESS` This API will be removed in the next major release. [WARNING] aws-cdk-lib.aws_ec2.SubnetType#PRIVATE_WITH_NAT is deprecated. use `PRIVATE_WITH_EGRESS` This API will be removed in the next major release. ...
[/simterm]
Okay.
Let’s add a dictionary availability_zones with zones where we want to create subnets and describe the subnet_configuration.
In the subnet_configuration describe a subnet group, one Public and one Private, and CDK will create a subnet of each type in each Availability Zone.
For the future, create an S3 Endpoint, because Grafana Loki is planned in the cluster, which will go to S3 buckets.
Add the vpc parameter to the eks.Cluster().
The whole file now looks like this:
from aws_cdk import (
aws_eks as eks,
aws_ec2 as ec2,
Stack
)
from constructs import Construct
class AtlasEksStack(Stack):
def __init__(self, scope: Construct, construct_id: str, stage: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
availability_zones = ['us-east-1a', 'us-east-1b']
# Create a new VPC
vpc = ec2.Vpc(self, 'Vpc',
ip_addresses=ec2.IpAddresses.cidr("10.0.0.0/16"),
vpc_name=f'eks-{stage}-1-26-vpc',
enable_dns_hostnames=True,
enable_dns_support=True,
availability_zones=availability_zones,
subnet_configuration=[
ec2.SubnetConfiguration(
name=f'eks-{stage}-1-26-subnet-public',
subnet_type=ec2.SubnetType.PUBLIC,
cidr_mask=24
),
ec2.SubnetConfiguration(
name=f'eks-{stage}-1-26-subnet-private',
subnet_type=ec2.SubnetType.PRIVATE_WITH_EGRESS,
cidr_mask=24
)
]
)
# Add an S3 VPC endpoint
vpc.add_gateway_endpoint('S3Endpoint',
service=ec2.GatewayVpcEndpointAwsService.S3)
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name=f'eks-{stage}-1-26-cluster',
version=eks.KubernetesVersion.V1_26,
vpc=vpc
)
Deploy and check:
[simterm]
$ cdk deploy eks-dev-1-26 ... eks-dev-1-26: deploying... [1/1] eks-dev-1-26: creating CloudFormation changeset... ... ✨ Total time: 1243.08s
[/simterm]
1243.08s seconds – 20 minutes. Okay… Well, that’s not Okay, of course! Gosh – 20 minutes to create a simple stack with EKS and VPC?
Adding Stack Tags
What else I’d like to add is a set of own tags for all the resources that the CDK will create in this stack.
In app.py use the cdk.Tags, and pass the AtlasEksStack() object:
...
app = cdk.App()
eks_stack = AtlasEksStack(app, f'eks-{EKS_STAGE}-1-26',
env=cdk.Environment(account=AWS_ACCOUNT, region=AWS_REGION),
stage=EKS_STAGE
)
cdk.Tags.of(eks_stack).add("environment", EKS_STAGE)
cdk.Tags.of(eks_stack).add("component", "EKS")
app.synth()
Deploy it (Total time: 182.67s just to add tags!), and check the Tags:
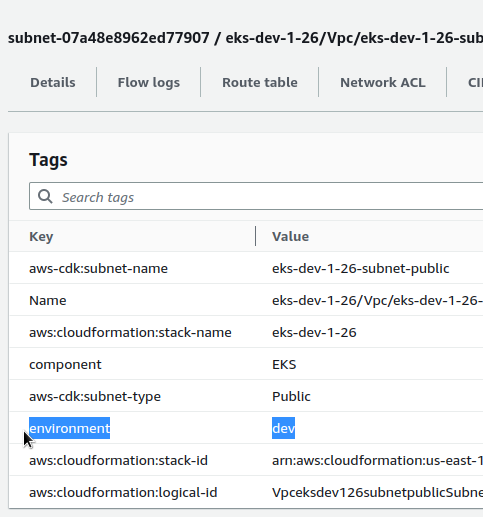
Okay.
Adding a NodeGroup
In general, we will most likely use the Karpenter instead of the “classic” Cluster Autoscaler, because I heard a lot of good reviews about Karpenter and I want to try it in practice, and then the WorkerNodes configuration for our EKS cluster will have to be reworked, but for now, we will create an ordinary Managed NodeGroup using add_nodegroup_capacity().
Add the cluster.add_nodegroup_capacity() with the Amazon Linux AMI to the atlas_eks_stack.py:
...
# Create the EC2 node group
nodegroup = cluster.add_nodegroup_capacity(
'Nodegroup',
instance_types=[ec2.InstanceType('t3.medium')],
desired_size=1,
min_size=1,
max_size=3,
ami_type=eks.NodegroupAmiType.AL2_X86_64
)
The necessary IAM roles must be created by the CDK itself – let’s see.
In the eks.Cluster() resource we set the default_capacity=0 so CDK does not create its own default group:
...
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name=f'eks-{stage}-1-26-cluster',
version=eks.KubernetesVersion.V1_26,
vpc=vpc,
default_capacity=0
)
...
Error: b’configmap/aws-auth configured\nerror: error retrieving RESTMappings to prune: invalid resource batch/v1beta1, Kind=CronJob, Namespaced=true: no matches for kind “CronJob” in version “batch/v1beta1″\n’
Now the stack is already deployed, run cdk deploy to update it, and…
[simterm]
eks-dev-1-26: creating CloudFormation changeset... 1:26:35 PM | UPDATE_FAILED | Custom::AWSCDK-EKS-KubernetesResource | EKSClusterAwsAuthmanifest5D430CCD Received response status [FAILED] from custom resource. Message returned: Error: b'configmap/aws-auth configured\nerror: error retrieving RESTMappings to prune: invalid resource batch/v1beta1, Kind=CronJob, Namespaced=true: no matches for kind "CronJob" in version "bat ch/v1beta1"\n'
[/simterm]
What? What the hell?
aws-auth ConfigMap, Kind=CronJob? Where is it from?
So apparently the CDK is trying to update the aws-auth ConfigMap to add the NodeGroup AIM role, but… But – what?
Judging by Google, the problem is precisely related to the kubectlLayer – the one I wrote about above. See the aws-eks: cdk should validate cluster version and kubectl layer version issue on GitHub.
And it appears only when updating the stack. If you create it anew, everything works. But let’s recall the speed of CDK/CloudFormation because deleting and creating takes 30-40 minutes.
KubectlV26Layer
Well, we still have to fix this problem.
OK… Just search in the browser – aws-cdk.lambda-layer-kubectl-v26. But even in the PyPi repository there are TypeScript examples – thank you very much:
This is generally a problem when working with AWS CDK on Python – a lot of examples are still on TS.
Okay, fine – we found the lib, it is called aws-cdk.lambda-layer-kubectl-v26, install it:
[simterm]
$ pip install aws-cdk.lambda-layer-kubectl-v26
[/simterm]
Add it to the requirements.txt:
[simterm]
$ pip freeze | grep -i lambda-layer-kubectl >> requirements.txt
[/simterm]
Add it to the atlas_eks_stack.py:
...
from aws_cdk.lambda_layer_kubectl_v26 import KubectlV26Layer
...
# to fix warning "You created a cluster with Kubernetes Version 1.26 without specifying the kubectlLayer property"
kubectl_layer = KubectlV26Layer(self, 'KubectlV26Layer')
...
cluster = eks.Cluster(
self, 'EKS-Cluster',
cluster_name=f'eks-{stage}-1-26-cluster',
version=eks.KubernetesVersion.V1_26,
vpc=vpc,
default_capacity=0,
kubectl_layer=kubectl_layer
)
...
Repeat the deployment to update the already existing stack, and…
CloudFormation UPDATE_ROLLBACK_FAILED
And we have another error, because after the “Error: b’configmap/aws-auth configured\nerror” the stack remained in the UPDATE_ROLLBACK_FAILED status:
[simterm]
... eks-dev-1-26: deploying... [1/1] eks-dev-1-26: creating CloudFormation changeset... ❌ eks-dev-1-26 failed: Error [ValidationError]: Stack:arn:aws:cloudformation:us-east-1:492***148:stack/eks-dev-1-26/9c7daa50-10f4-11ee-b64a-0a9b7e76090b is in UPDATE_ROLLBACK_FAILED state and can not be updated. ...
[/simterm]
Here, the option is either to simply delete the stack and create it anew (kill another 30-40 minutes of your time) or Google it and find the How can I get my CloudFormation stack to update if it’s stuck in the UPDATE_ROLLBACK_FAILED state.
Let’s try ContinueUpdateRollback :
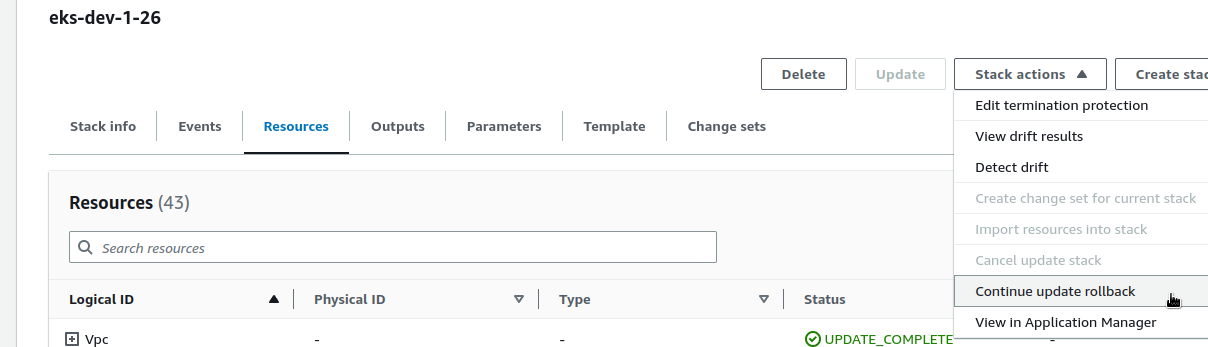
But no – the stack is still broken:
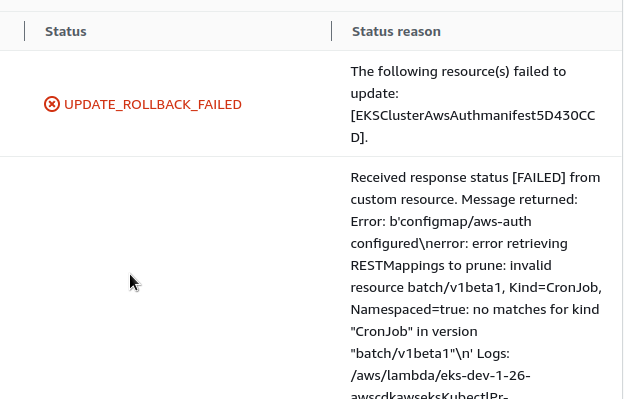
So delete it, and go to Facebook to watch cats while it is recreating.
Cannot replace cluster “since it has an explicit physical name
At this point, I also caught the “Cannot replace cluster “eks-dev-1-26-cluster” since it has an explicit physical name” error, which looked like this:
[simterm]
... 2:30:45 PM | UPDATE_FAILED | Custom::AWSCDK-EKS-Cluster | EKSCluster676AE7D7 Received response status [FAILED] from custom resource. Message returned: Cannot replace cluster "eks-dev-1-26-cluster" since it has an explicit physical name. Either rename the cluster or remove the "name" configuration ...
[/simterm]
But this time it did not reproduced, although it should be kept in mind, because it will definitely come out again someday.
Ok, so now we have a VPC, EKS Cluster and NodeGroup – it’s time to think about IAM.
IAM Role and aws-auth ConfigMap
The next thing to do is to create an IAM role that can be assumed to gain access to the cluster.
So far, without any RBAC and user groups – just a role to be executed later aws eks update-kubeconfig.
Use the aws_cdk.aws_iam.Role() and aws_cdk.aws_eks.AwsAuth():
from aws_cdk import (
...
aws_iam as iam,
...
)
...
# Create an IAM Role to be assumed by admins
masters_role = iam.Role(
self,
'EksMastersRole',
assumed_by=iam.AccountRootPrincipal()
)
# Attach an IAM Policy to that Role so users can access the Cluster
masters_role_policy = iam.PolicyStatement(
actions=['eks:DescribeCluster'],
resources=['*'], # Adjust the resource ARN if needed
)
masters_role.add_to_policy(masters_role_policy)
cluster.aws_auth.add_masters_role(masters_role)
# Add the user to the cluster's admins
admin_user = iam.User.from_user_arn(self, "AdminUser", user_arn="arn:aws:iam::492***148:user/arseny")
cluster.aws_auth.add_user_mapping(admin_user, groups=["system:masters"])
The masters_role is a role that can be assumed by anyone from an AWS account, and admin_user is my personal IAM user for direct access to the cluster.
CfnOutput
Outputs of the CloudFormation stack. As far as I remember, it can be used for cross-stack use of values, but we need it to get the ARN of the masters_role:
from aws_cdk import (
...
Stack, CfnOutput
)
...
# Output the EKS cluster name
CfnOutput(
self,
'ClusterNameOutput',
value=cluster.cluster_name,
)
# Output the EKS master role ARN
CfnOutput(
self,
'ClusterMasterRoleOutput',
value=masters_role.role_arn
)
Deploy:
[simterm]
... Outputs: eks-dev-1-26.ClusterMasterRoleOutput = arn:aws:iam::492***148:role/eks-dev-1-26-EksMastersRoleD1AE213C-1ANPWK8HZM1W5 eks-dev-1-26.ClusterNameOutput = eks-dev-1-26-cluster
[/simterm]
Configuring kubectl with AWS CLI
Well, in the end, after all the suffering, let’s try to get access to the cluster.
First, through master_role – update local ~/.aws/config to add a profile to assume the role:
[profile work] region = us-east-1 output = json [profile work-eks] role_arn = arn:aws:iam::492***148:role/eks-dev-1-26-EksMastersRoleD1AE213C-1ANPWK8HZM1W5 source_profile = work
In the [profile work-eks] we perform the IAM Role Assume of the master_role using the ACCESS/SECRET keys of the [work] profile.
Create kube-config:
[simterm]
$ aws --profile work-eks eks update-kubeconfig --region us-east-1 --name eks-dev-1-26-cluster --alias eks-dev-1-26 Added new context eks-dev-1-26 to /home/setevoy/.kube/config
[/simterm]
And check acces:
[simterm]
$ kubectl get node NAME STATUS ROLES AGE VERSION ip-10-0-2-60.ec2.internal Ready <none> 19h v1.26.4-eks-0a21954
[/simterm]
Similarly, if using a personal AIM account, that is user_arn="arn:aws:iam::492***148:user/arseny":
[simterm]
$ aws --profile work eks update-kubeconfig --region us-east-1 --name eks-dev-1-26-cluster --alias eks-dev-1-26-personal
[/simterm]
“It works” (c)
Based on the result, I can say one thing – I am personally not ready to take responsibility for the operation of such a stack in production.
Perhaps, if work with CDK more, and know its main pitfalls, and recall all the “nuances” of the CloudFormation, then I can live with them. But for now – no, I don’t want to at all.
![]()