Давно подумував спробувати MikroTik, але все якось було ліньки розбиратись з RouterOS.
Нарешті, на хвилі зборки Home NAS проекту (див. початок в FreeBSD: Home NAS, part 1 – налаштування ZFS mirror) таки вирішив, що пора оновити і мережевий стек і замінити простенький TP-Link Archer на щось більш серйозне.
До цього в мене були Linksys E4200 (2012-2020), потім з’явився Linksys EA6350 (2020-2024), і останнім був TP-Link Archer AX12 (2024-2025), і коли я перший раз відкрив MikroTik Web UI і подивився можливості… Це як пересісти з Запорожця на Мерседес.
Ну і нарешті – повноцінна консоль і SSH з коробки, а не через кастомні прошивки.
Можливостей в RouterOS дуже багато, тому одним постом по цій темі не обійтись, і в чернетках вже є кілька матеріалів, а почнемо з першого знайомства і початку роботи.
Архітектура моєї мережі
Перш ніж говорити про сам роутер – трохи про мій networking і ролі роутерів MikroTik.
Є дві мережі – “офіс” та дом, в обох “на вході” були TP-Link Archer AX12.
В “офісі” (в лапках, бо це просто сусідня квартира) стоїть ThnikCenter з FreeBSD/NAS, плюс робочий ноутбук і ігровий ПК. В основному всі девайси підключені до роутера кабелями, WiFi тільки для телефону і всяких EcoFlow, робота-пилососа тощо.
Вдома – пара ноутбуків, там вся мережа виключно WiFi.
Обидві мережі об’єднані з VPN, і по старій схемі TP-Link Archer в офісі мав port forwading до WireGuard на FreeBSD, а на FreeBSD були власне WireGuard як хаб та Unbound для локального DNS, плюс всякі Samba/NFS/etc.
Тепер жеж в офісі схема буде іншою:
MikroTik RB4011iGS:
на нього заходить кабель провайдера (оптика через ONU і далі по квартирі з Ethernet на роутер RB4011)
до RB4011iGS кабелями підключені ThinkCentre/NAS, робочий ноутбук та ігровий ПК
MikroTik hAP ax3: підключений кабелем до RB4011, пізніше переключу його в режим Access Point, поки стандартний WiFi роутер з власним NAT
TP-Link Archer AX12: підключений кабелем до RB4011, на ньому нічого не міняю, бо ліньки перепідключати різні домашні девайси типу дверного дзвоника, пожежної сигналізації, EcoFlow, etc
В домашній мережі не міняється нічого окрім налаштувань WireGuard на домашньому ноуті: раніше він через port-forwarding на офісному роутері підключався до FreeBSD, тепер буде ходити до RB4011.
І окремо – сервер самого rtfm.co.ua в DigitalOcean, який (буде) теж підключений з WireGuard до цієї мережі.
Загальна схема буде виглядати приблизно так:
Перше підключення до MikroTik
Боже, який це кайф – мати повноцінний SSH! Але про SSH трохи далі тут і потім ще окремим постом.
Взагалі MikroTik предоставляє кілька варіантів підключення:
Дуже цікава можливість Safe Mode: відкотить зміни, якщо зламали доступ і підключення розірвалось без коректного збереження налаштувань.
В RouteOS є повноцінна консоль, яка складається з ієрархічного дерева команд.
Наприклад, якщо в Web пункт меню IP => Firewall:
То в консолі це буде /ip firewall.
Є повноцінне автодоповнення по Tab:
Після переходу в меню можна з F1 подивитись доступні команди:
В документації говориться, що “?” має виводити підказку теж – але на 7+ версії це вже не працює (Reddit).
Замість “?” просто вибираємо команду, а потім F1 або Tab:
Getting started: перші налаштування
У MikroTik дуже класна документація (привіт, Confluence), і є власний розділ Getting started.
Пройдусь по основним речам, які робив на початку роботи.
Деякі скріни старі, тому ім’я хоста там буде “MikroTik” – дефолтне, далі глянемо, як це міняється.
IP теж може бути старий, дефолтний – 192.168.88.1. зараз він 192.168.0.1. Про налаштування DHCP – в наступному пості.
Backup та restore
У MirkoTik є два варіанти створення бекапу – з /export та /system backup.
/export створить текстовий файл з історією команд який можна прочитати – а /system backup створює бінарний файл, який включає в себе все, в тому числі ключі і сертифікати.
Але якщо конфіг переноситься на інший роутер – то system backup може сфейлитись, бо містить в собі прив’язку до конкретного девайсу, а результат з export – просто виконає команди.
Columns: NAME, VERSION, BUILD-TIME, SIZE
# NAME VERSION BUILD-TIME SIZE
0 routeros 7.18.2 2025-03-11 11:59:04 11.5MiB
Перевіряємо наявність апдейтів:
/system package update check-for-updates
Результат:
[setevoy@MikroTik] > /system package update check-for-updates
channel: stable
installed-version: 7.18.2
latest-version: 7.21
status: New version is available
Завантажуємо – це тільки загрузка:
/system package update download
Результат:
[setevoy@MikroTik] > /system package update download
channel: stable
installed-version: 7.18.2
latest-version: 7.21
status: Downloaded, please reboot router to upgrade it
І запускаємо вже сам процес апгрейду:
/system package update install
Система піде в ребут:
[setevoy@MikroTik] > /system package update install
channel: stable
installed-version: 7.18.2
latest-version: 7.21
status: calculating download size...
Received disconnect from 192.168.88.1 port 22:11: shutdown/reboot
Disconnected from 192.168.88.1 port 22
[setevoy@MikroTik] > /system routerboard upgrade
Do you really want to upgrade firmware? [y/n]
y
[setevoy@MikroTik] >
14:13:58 echo: system,info,critical Firmware upgraded successfully, please reboot for changes to take effect!
Ребутаємо роутер:
[setevoy@MikroTik] > /system reboot
Reboot, yes? [y/N]:
y
system will reboot shortly
Connection to 192.168.88.1 closed.
Distance тут – пріорітет: можна мати друге інтернет-підключення (як я планую – на ethernet port 2 підключити LTE-роутер з SIM-картою), задати йому Distance == 2, і тоді трафік буде йти через перший порт – якщо він доступний, а якщо ні – то через другий.
Інформація по DNS:
/ip dns print
Виконати ping на якийсь хост:
/ping 8.8.8.8 src-address=192.168.0.1
Або traceroute (динамічний, як mtr на Linux/FreeBSD):
/tool traceroute 8.8.8.8
Коректно перезавантажити або виключити:
/system reboot
/system shutdown
Задати ім’я хоста:
/system identity set name=mikrotik-rb4011-gw
Власне, на цьому для початку все.
Що далі? Next steps
Про що ще думаю писати – частина вже є в чернетках, частину буду (якщо буде час) писати з нуля:
налаштування DHCP
налаштування DNS
SSH і firewall – юзери, аутентифікація по ключам, правила фаєрволу
налаштування WireGuard для підключення Peers
scripts, alerting, monitoring – дуже класна можливість писати скрипти, які можуть слати алерти, див. Scripting
Але окрім архівних даних в S3 хочеться мати “offsite hot copy” в Google Drive та AWS S3, аби мати доступ до даних постійно, і які не треба відновлювати із бекапу, а можна просто скопіювати з CLI або навіть з браузера.
При цьому не хочеться розводити зоопарк різних систем, а працювати з одною, яка буде вміти підключатись і до AWS, і до Google Drive.
Власне, під час пошуку того, як з restic копіювати дані в Google Drive знайшов такий собі “швейцарський ніж” – Rclone.
Всі частини серії по налаштуванню домашнього NAS на FreeBSD:
Rclone (“rsync for cloud storage“) – CLI-утиліта, вміє працювати просто з безліччю різних бекендів – і локальними даними або NFS, Samba, і FTP, і WebDAV, і, звісно, AWS S3 та Google Drive, див. всі в Overview of cloud storage systems.
Основні плюшки системи:
написаний на Go
можливість одною CLI отримати доступ до даних в Google Drive та S3
client-side шифрування даних і імен файлів
режими copy та sync, аналогічні rsync
є можливість змонтувати ремоут в локальну директорію, і працювати як зі звичайною папкою з даними (див. rclone mount)
вміє працювати як “проксі” між двома remotes (наприклад, копіювати дані між Google Drive та S3)
Для роботи з Google Drive створимо API keys, і цей процес опишу окремо, бо створення ключів в Google трохи заплутане, і я кожного разу шукаю гайд як це робити.
Переходимо в Google API Console, вибираємо існуючий або створюємо новий проект:
Переходимо в “Branding”, заповнюємо “App information” – задаємо ім’я, це чисто для нас, вказуємо email:
І внизу в “Developer contact information” ще раз пошту:
Зберігаємо, переходимо в “Audience”, перевіряємо, що тут “User type” заданий як External:
Переходимо в “Clients”, потім “Create client”:
Вказуємо “Application type” як Desktop app:
Отримуємо Client ID та Client Secret, зберігаємо собі:
Переходимо до налаштувань підключень вже в самому rclone.
Налаштування Google Drive remote
Виконуємо rclone config, вибираємо “n) New remote“, задаємо ім’я:
...
e/n/d/r/c/s/q> n
Enter name for new remote.
name> nas-google-drive
...
Далі вибираємо з яким бекендом rclone буде працювати.
Для Google Drive це 22 (можна вказати номер, можна ім’я “drive“):
...
22 / Google Drive
\ (drive)
...
Наступний крок аутентифікація – задаємо ключі:
...
Option client_id.
Google Application Client Id
...
Enter a value. Press Enter to leave empty.
client_id> 377***7i7.apps.googleusercontent.com
Option client_secret.
OAuth Client Secret.
Leave blank normally.
Enter a value. Press Enter to leave empty.
client_secret> GOC***gjX
...
Задаємо рівень доступу – тут можна дати або повний доступ до всього драйву, або, якщо rclone буде тільки для бекапів, то вибрати “Access to files created by rclone only”.
На ноутбуках можна задати повний доступ, а на FreeBSD зробимо “тільки для свої файлів”:
В Advanced можна редагувати параметри типу “use_trash” та “Upload chunk size”, але це можна зробити пізніше – зараз просто тиснемо Enter.
Наступний крок – аутентифікація для отримання токену від Google:
...
Use web browser to automatically authenticate rclone with remote?
* Say Y if the machine running rclone has a web browser you can use
* Say N if running rclone on a (remote) machine without web browser access
If not sure try Y. If Y failed, try N.
y) Yes (default)
n) No
Так як це робиться на FreeBSD без браузеру, то вибираємо No –rclone згенерує токен, який треба вказати на машині з браузером, де є інший інстанс rclone:
...
y/n> n
Option config_token.
For this to work, you will need rclone available on a machine that has
a web browser available.
For more help and alternate methods see: https://rclone.org/remote_setup/
Execute the following on the machine with the web browser (same rclone
version recommended):
rclone authorize "drive" "eyJ***ifQ"
Then paste the result.
Enter a value.
Виконуємо на ноуті:
$ rclone authorize "drive" "eyJ***ifQ"
2026/01/07 16:35:38 NOTICE: Make sure your Redirect URL is set to "http://127.0.0.1:53682/" in your custom config.
2026/01/07 16:35:38 NOTICE: If your browser doesn't open automatically go to the following link: http://127.0.0.1:53682/auth?state=Lf9q_HUVFlBUc2UqlSUqpw
2026/01/07 16:35:38 NOTICE: Log in and authorize rclone for access
2026/01/07 16:35:38 NOTICE: Waiting for code...
Відкривається браузер, вибираємо акаунт:
Дозволяємо доступ:
Отримуємо Success:
А на ноут в консолі, з якої викликали rclone authorize прийде токен:
...
2026/01/07 16:35:38 NOTICE: Waiting for code...
2026/01/07 16:37:33 NOTICE: Got code
Paste the following into your remote machine --->
eyJ...ifQ
<---End paste
Копіюємо його до rclone config на FreeBSD хості:
...
Enter a value.
config_token> eyJ***ifQ
...
І нове підключення готове:
...
Configuration complete.
Options:
- type: drive
- client_id: 377***7i7.apps.googleusercontent.com
- client_secret: GOC***gjX
- scope: drive.file
- token: {"access_token":"ya2***","expires_in":3599}
- team_drive:
Keep this "nas-google-drive" remote?
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
root@setevoy-nas:~ # rclone config
Current remotes:
Name Type
==== ====
nas-google-drive drive
e) Edit existing remote
n) New remote
d) Delete remote
r) Rename remote
c) Copy remote
s) Set configuration password
q) Quit config
e/n/d/r/c/s/q> n
Enter name for new remote.
name> nas-s3-setevoy-backups
...
Далі тип – вибираємо 4 (s3), потім 1 – AWS:
...
Option Storage.
Type of storage to configure.
Choose a number from below, or type in your own value.
1 / 1Fichier
\ (fichier)
2 / Akamai NetStorage
\ (netstorage)
3 / Alias for an existing remote
\ (alias)
4 / Amazon S3 Compliant Storage Providers including AWS, Alibaba, ArvanCloud, Ceph, ChinaMobile, Cloudflare, DigitalOcean, Dreamhost, Exaba, FlashBlade, GCS, HuaweiOBS, IBMCOS, IDrive, IONOS, LyveCloud, Leviia, Liara, Linode, Magalu, Mega, Minio, Netease, Outscale, OVHcloud, Petabox, RackCorp, Rclone, Scaleway, SeaweedFS, Selectel, StackPath, Storj, Synology, TencentCOS, Wasabi, Qiniu, Zata and others
\ (s3)
...
Storage> s3
Option provider.
Choose your S3 provider.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / Amazon Web Services (AWS) S3
\ (AWS)
...
Далі вибираємо “Enter AWS credentials in the next step” і задаємо ключі:
...
Option env_auth.
Get AWS credentials from runtime (environment variables or EC2/ECS meta data if no env vars).
Only applies if access_key_id and secret_access_key is blank.
Choose a number from below, or type in your own boolean value (true or false).
Press Enter for the default (false).
1 / Enter AWS credentials in the next step.
\ (false)
2 / Get AWS credentials from the environment (env vars or IAM).
\ (true)
env_auth> 1
Option access_key_id.
AWS Access Key ID.
Leave blank for anonymous access or runtime credentials.
Enter a value. Press Enter to leave empty.
access_key_id> AKI***VXZ
Option secret_access_key.
AWS Secret Access Key (password).
Leave blank for anonymous access or runtime credentials.
Enter a value. Press Enter to leave empty.
secret_access_key> MkP***xJ/
...
Далі регіон бакету – він є в Properties:
Задаємо його:
...
Option region.
Region to connect to.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
/ The default endpoint - a good choice if you are unsure.
1 | US Region, Northern Virginia, or Pacific Northwest.
| Leave location constraint empty.
\ (us-east-1)
...
region> eu-west-1
...
Option endpoint залишаємо без мін, в Option location_constraint ще раз задаємо “eu-west-1“:
Option location_constraint.
Location constraint - must be set to match the Region.
Used when creating buckets only.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / Empty for US Region, Northern Virginia, or Pacific Northwest
\ ()
...
6 / EU (Ireland) Region
\ (eu-west-1)
...
location_constraint> eu-west-1
Option acl можна пропустити – у нас окрема корзина, в якій вже є всі налаштування ACL.
В server_side_encryption вибираємо “AES256“, далі “None“:
...
Option server_side_encryption.
The server-side encryption algorithm used when storing this object in S3.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / None
\ ()
2 / AES256
\ (AES256)
3 / aws:kms
\ (aws:kms)
server_side_encryption> 2
Option sse_kms_key_id.
If using KMS ID you must provide the ARN of Key.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / None
\ ()
2 / arn:aws:kms:*
\ (arn:aws:kms:us-east-1:*)
sse_kms_key_id> 1
...
Option storage_class.
The storage class to use when storing new objects in S3.
Choose a number from below, or type in your own value.
Press Enter to leave empty.
1 / Default
\ ()
...
8 / Intelligent-Tiering storage class
\ (INTELLIGENT_TIERING)
...
storage_class> 8
Зберігаємо – маємо новий бекенд:
...
Edit advanced config?
y) Yes
n) No (default)
y/n>
Configuration complete.
Options:
- type: s3
- provider: AWS
- access_key_id: AKI***VXZ
- secret_access_key: MkP***zxJ/
- region: eu-west-1
- location_constraint: eu-west-1
- server_side_encryption: AES256
- storage_class: INTELLIGENT_TIERING
Keep this "nas-s3-setevoy-backups" remote?
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
y/e/d>
Current remotes:
Name Type
==== ====
nas-google-drive drive
nas-s3-setevoy-backups s3
...
Для роботи з S3 бакетом використовуємо формат remote_name:backet_name.
Створюємо в бакеті файл healthcheck.txt і каталог test – використовуємо rclone rcat:
root@setevoy-nas:~ # echo test | rclone rcat nas-s3-setevoy-backups:setevoy-backups-nas/test/healthcheck.txt
root@setevoy-nas:~ # rclone ls nas-s3-setevoy-backups:setevoy-backups-nas/test
5 healthcheck.txt
Rclone та шифрування
Задля більшої безпеки rclone може шифрувати свій локальний конфігураційний файл, а для безпечного зберігання даних в remote backends – може шифрувати дані там.
crypt створюється як окремий бекенд, але використовує вже існуючий.
Наприклад, маючи nas-google-drive можна створити новий storage backend nas-google-drive-crypted і використовувати його: він буде таким собі “проксі” – ми пишемо дані “в нього”, він виконує шифрування, а потім “під капотом”, аби записати файли в Google Drive, використовує “оригінальний” бекенд nas-google-drive.
Створюємо новий remote:
root@setevoy-nas:~ # rclone config
Current remotes:
Name Type
==== ====
nas-google-drive drive
nas-s3-setevoy-backups s3
e) Edit existing remote
n) New remote
d) Delete remote
r) Rename remote
c) Copy remote
s) Set configuration password
q) Quit config
e/n/d/r/c/s/q> n
Enter name for new remote.
name> nas-google-drive-crypted
В типі вибираємо “15 – Encrypt/Decrypt a remote”:
...
Option Storage.
Type of storage to configure.
Choose a number from below, or type in your own value.
...
15 / Encrypt/Decrypt a remote
\ (crypt)
...
Storage> crypt
Далі вказуємо “source backend”, в якому будуть зашифровані дані.
Тут важливий момент: можна вказати або весь storage як nas-google-drive:Backups/Rclone (корінь для rclone в моєму випадку) – або створити в ньому окремий каталог, в якому будуть зберігатись зашифровані дані:
...
Option remote.
Remote to encrypt/decrypt.
Normally should contain a ':' and a path, e.g. "myremote:path/to/dir",
"myremote:bucket" or maybe "myremote:" (not recommended).
Enter a value.
remote> nas-google-drive:Backups/Rclone/Vault
Далі є варіанти – шифрувати імена файлів і каталогів чи ні, дефолт – шифрувати:
...
Option filename_encryption.
How to encrypt the filenames.
Choose a number from below, or type in your own value of type string.
Press Enter for the default (standard).
/ Encrypt the filenames.
1 | See the docs for the details.
\ (standard)
2 / Very simple filename obfuscation.
\ (obfuscate)
/ Don't encrypt the file names.
3 | Adds a ".bin", or "suffix" extension only.
\ (off)
filename_encryption>
Option directory_name_encryption.
Option to either encrypt directory names or leave them intact.
NB If filename_encryption is "off" then this option will do nothing.
Choose a number from below, or type in your own boolean value (true or false).
Press Enter for the default (true).
1 / Encrypt directory names.
\ (true)
2 / Don't encrypt directory names, leave them intact.
\ (false)
directory_name_encryption>
І останнє – вказати пароль і опціонально salt:
...
Option password.
Password or pass phrase for encryption.
Choose an alternative below.
y) Yes, type in my own password
g) Generate random password
y/g> y
Enter the password:
password:
Confirm the password:
password:
Option password2.
Password or pass phrase for salt.
Optional but recommended.
Should be different to the previous password.
Choose an alternative below. Press Enter for the default (n).
y) Yes, type in my own password
g) Generate random password
n) No, leave this optional password blank (default)
y/g/n>
Готово:
...
Configuration complete.
Options:
- type: crypt
- remote: nas-google-drive:Backups/Rclone/Vault
- password: *** ENCRYPTED ***
Keep this "nas-google-drive-crypted" remote?
y) Yes this is OK (default)
e) Edit this remote
d) Delete this remote
y/e/d>
Current remotes:
Name Type
==== ====
nas-google-drive drive
nas-google-drive-crypted crypt
nas-s3-setevoy-backups s3
Тепер, якщо скопіюємо туди текстовий файл, то прочитати його зможемо тільки з rclone:
--check-first: виконати перевірку даних між src та dst до початку копіювання
--checksum: порівнювати файл між src та dst не за size+mtime, а по MD5SUM checksum – повільніше, але точніше, корисно для критичних даних
--immutable: не змінювати файл в dst, якщо він відрізняється від src, а впасти з помилкою
--interactive: підтвердження змін вручну
--dry-run: тестове виконання без копіювання
--progress: відобразити процес
--transfers N: кількість файлів, які копіюються одночасно (дефолт 4)
--create-empty-src-dirs: якщо src каталог порожній – то створити порожній каталог в dst (не працює з S3)
--exclude та --exclude-from, --include та --include-from: список або файл зі списком даних, які треба включити або виключити з копіювання, див. Filter
--log-file: куди писати лог (корисно для автоматизації)
--fast-list: створює один великий список директорій і файлів, який тримає в пам’яті, а не для кожної директорії окремо (більше пам’яті – але швидше і менше API-запитів до dst)
--update: пропустити файли, modification time яких на dst новіший, ніж в src
--human-readable: використовувати формат Ki/Mi/Gi
Використання rclone copy та rclone copyto
rclone copy просто копіює файл або директорію до заданого remote.
Якщо src – каталог з підкаталогами, то будуть скопійовані всі дані і збережено структуру каталогів.
Наприклад, маємо локально каталоги з файлами:
root@setevoy-nas:~ # tree /tmp/new/
/tmp/new/
└── another
└── dir
├── a.txt
└── sub
└── b.txt
Вже пару місяців, як на робочому ноуті Lenovo ThinkPad T14 Gen 5 з Arch Linux виникла проблема з відкриттям нових сайтів – перші 10-15 секунд сайт завантажується “шматочками”, наприклад:
Але потім “розчехляється”, і все починає працювати чудово:
І проблема виявилась дуже цікавою. Причину шукав довго, і перепровірив купу різних налаштувань – від IPv6 і DNS до драйверу мережової карти.
Головне, що проблема не те щоб була критичною – в цілому інет працював, а тому я іноді починав шукати причину, потім закидував, потім знов повертався.
The issue: “communications error to 192.168.0.1#53: timed out”
Що цікаво, що проблема спостерігалась тільки на Ethernet-підключені – на WiFi все працювало чудово.
А на Ethernet репродьюсилось на різних кабелях і через різні роутери.
Значить – що? Значить – або Сєня щось наковиряв руками у своєму Linux, або десь колись прилетів “кривий” апдейт чи до ядра, чи до драйвера, чи до якось бібліотеки.
Вже не пам’ятаю чому, але спершу грішив на DNS, бо ми ж знаємо, що:
І такі да – під час спроб зарепродьюсити це вдалось саме з DNS, під час тестів з dig – тому довго копав в цю сторону.
Виглядала проблема так: робимо dig, 10-15 запитів проходять нормально, а потім прилітає “communications error to 192.168.0.1#53: timed out“:
$ time dig google.com +short @192.168.0.1
;; communications error to 192.168.0.1#53: timed out
...
real 0m5.018s
user 0m0.004s
sys 0m0.008s
Ну і це виглядало, як дійсно причина того, що сайти тупили з загрузкою контенту: якщо DNS періодично відвалюється, а сайти мають купу додаткових скриптів і картинок, які підвантажуються з інших ресурсів – то поки всі хости разрезолвляться, поки отримаємо всі адреси, поки почнеться завантаження – як раз маємо цю затримку в кількадесят секунд.
Логічно? Так.
Тому і всі подальше тести я робив вже в циклі з dig:
$ for i in {1..50}; do { time dig +nocookie +noedns +tries=1 +time=2 google.com >/dev/null; } 2>&1; done
...
real 0m0.016s
...
real 0m2.015s
...
real 0m0.013s
...
real 0m1.392s
І такий результат був постійно – пачка запитів проходить нормально – “real 0m0.016s“, а потім на якомусь одному – таймаут і “real 0m2.015s” (бо +time=2 – чекати 2 секунди, а не дефолтні 5).
Ця ж проблема була видна з tcpdump: в 09:57:47 запит відправлений, але відповіді не отримано, через 2 секунди, в 09:57:49 – новий запит, і на нього вже відповідь прийшла:
...
09:57:47.717951 IP setevoy-work.40923 > _gateway.domain: 13058+ [1au] A? google.com. (51)
09:57:49.729589 IP setevoy-work.45441 > _gateway.domain: 63641+ [1au] A? google.com. (51)
09:57:49.730249 IP _gateway.domain > setevoy-work.45441: 63641 6/4/4 A 142.250.109.101, A 142.250.109.100, A 142.250.109.139, A 142.250.109.138, A 142.250.109.102, A 142.250.109.113 (260)
...
Тут в 0.002788 відкритий сокет для відправки запиту, а через 5 секунд (5.005754) – бо зараз dig запускався без +time=2 – відкривається новий сокет для нового запиту, бо на попередній відповіді не було.
В пошуках Немо проблеми
Тут опишу що взагалі перевіряв – квест вийшов той ще.
Хоча записав не все, робив більше, але основне зберіг – вже давно є звичка закидувати в чорнетку поста на RTFM під час дебагу проблем.
Перевірка DNS в Linux
Перше – що з DNS в системі?
В /etc/resolv.conf заданий роутер:
# Generated by NetworkManager
nameserver 192.168.0.1
Міняємо на 1.1.1.1 чи на 8.8.8.8 – проблема залишається.
Окей… Може, в системі ще якийсь активний резолвер, і починається “DNS-гонка в ядрі” – запит “блукає” між ними?
Перевіряємо systemd-resolved – ні, не запущений:
$ systemctl status systemd-resolved
○ systemd-resolved.service - Network Name Resolution
Loaded: loaded (/usr/lib/systemd/system/systemd-resolved.service; disabled; preset: enabled)
Active: inactive (dead)
...
Може, dnsmasq?
Теж виключений:
$ systemctl status dnsmasq
○ dnsmasq.service - dnsmasq - A lightweight DHCP and caching DNS server
Loaded: loaded (/usr/lib/systemd/system/dnsmasq.service; disabled; preset: disabled)
Active: inactive (dead)
...
Значить, DNS-запити йдуть напряму до роутера, і… Що? Тупить роутер з відповідями? До нього не доходять запити – іноді губляться?
Що це може бути?
локальний firewall на Linux чи роутері?
ні – вимикав, проблема залишалась
race між кількома локальними DNS-сервісами?
виключили вище
power management мережевої карти – вона уходить в sleep?
маловірогідно, але далі перевіряв і це
баг драйвера мережевої карти?
можливо, бо проблема з’явилась не так давно, до цього на цьому ноуті і цій системі все працювало без проблем
якісь проблеми конкретно з UDP?
теж ніж – робив dig +tcp google.com, проблема залишалась
відповідь на DNS-запит повертається з іншого IP?
екзотична ідея, але як варіант – на роутері кілька мережевих інтерфейсів, об’єднаних в bridge, і – теоретично – роутер може відправити відповідь з іншої
але це прям щось дуже неординарне, та і проблема виникала однаково на різних роутерах, і раніше її не було
IPv6 та DNS
Не пам’ятаю чому, але десь на початку грішив на IPv6 під час виконання DNS.
/etc/gai.conf керує алгоритмом вибору адрес у glibc (GAI = getaddrinfo()), і визначає яку адресу (IPv4 чи IPv6) програма, яка робила DNS-запит вибере першою у випадку, якщо DNS повернув і A, і AAAA записи.
Можна включити IPv4 first – розкоментувати строку:
...
precedence ::ffff:0:0/96 100
...
Перевіряємо, що повернеться першим – адреса IPv4, чи IPv6:
Тут здавалось, що проблема знайдена – бо перший раз все пройшло без проблем, але ні – потім знов таймаути.
NIC Offloading
NIC Offloading – це коли частина операцій виконується на самому мережевому інтерфейсі, тобто offload деяких задач з CPU ноутбука на контролер карти.
Перевіряємо активні з ethtool -k:
$ sudo ethtool -k enp0s31f6 | grep on
rx-checksumming: on
tx-checksumming: on
tx-checksum-ip-generic: on
scatter-gather: on
tx-scatter-gather: on
tcp-segmentation-offload: on
...
generic-segmentation-offload: on
generic-receive-offload: on
rx-vlan-offload: on
tx-vlan-offload: on
receive-hashing: on
...
Самі цікаві тут:
TSO (TCP Segmentation Offloading): процесор віддає карті один великий шматок даних (наприклад, 64 КБ), а карта сама “нарізає” його на маленькі TCP-пакети по 1500 байт
GSO (Generic Segmentation Offloading): те саме, що й TSO, але більш універсальне (працює не лише для TCP)
GRO (Generic Receive Offloading): зворотний процес – карта отримує багато дрібних пакетів, “склеює” їх в один великий і лише тоді віддає процесору, що економить ресурси CPU
RX та TX Checksum Offloading: карта сама перевіряє контрольні суми (CRC) вхідних пакетів – якщо пакет “битий”, карта його просто викидає, навіть не повідомляючи операційну систему
По черзі вимикаємо їх, і перевіряємо:
sudo ethtool -K enp0s31f6 gro off: не допомогло
sudo ethtool -K enp0s31f6 gso off: не допомогло
sudo ethtool -K enp0s31f6 tso off: не допомогло
sudo ethtool -K enp0s31f6 rx off: не допомогло, і стало навіть гірше
Насправді те, що після відключення RX Checksum Offloading стало гірше – вже було підказкою: якщо до цього мережева карта сама фільтрувала помилки, то тепер вони всі повалили до ядра, що створило додаткове навантаження і хаос у черзі пакетів, тому корисні DNS-відповіді стали губитися ще частіше.
IR-PCI-MSI-0000:00:1f.6 – драйвер використовує MSI (Message Signaled Interrupts), яка начебто на Linux може давати drops для UDP на деяких картах Intel.
rx_crc_errors каже, що проблема з цілісністю пакетів, і – якщо з роутерам і кабелем все в порядку (а проблема спостерігалась на різних роутерах і з різними кабелями) – то скоріш за все проблема в самому RJ-45 на ноутбуці, хоча контакти виглядають нормально.
Спробував примусово зменшити швидкість на інтерфейсі з гігабіта до 100 Mbps:
$ sudo ethtool -s enp0s31f6 speed 100 duplex full autoneg on
І чудо! Все працює!
Повертаємо знов 1000:
$ sudo ethtool -s enp0s31f6 speed 1000 duplex full autoneg on
І проблема знову з’являється.
Можна було б просто залишити 100 Mbps – але ж я не для того підключений по кабелю і плачу за гігабітний GPON?
Благо, вдома є кілька USB-адаптерів з Ethernet, перемкнув кабель на нього:
$ ip a s enp0s13f0u2u3
2: enp0s13f0u2u3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether c8:4d:44:29:27:6b brd ff:ff:ff:ff:ff:ff
altname enxc84d4429276b
inet 192.168.0.198/24 brd 192.168.0.255 scope global dynamic noprefixroute enp0s13f0u2u3
...
Є гігабіт і Full Duplex:
$ sudo ethtool enp0s13f0u2u3
Settings for enp0s13f0u2u3:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
...
Speed: 1000Mb/s
Duplex: Full
...
drv probe link timer ifdown ifup rx_err tx_err tx_queued intr tx_done rx_status pktdata hw wol
Link detected: yes
Власне, по налаштуванню NAS вже зроблено майже все – з VPN є доступи з різних мереж, є різні шари, трохи затюнили безпеку.
Залишилось дві основні речі: моніторинг і бекапи, бо мати ZFS mirror на двох дисках з регулярними ZFS snapshots це, звісно, класно, але все одно недостатньо, а тому хочеться додатково робити бекапи десь в клауд.
Особливо я відчув необхідність мати доступ до бекапів в клаудах на початку війни, коли не ясно було де я опинюсь через годину, і чи буде в мене можливість забрати із собою бодай якесь залізо.
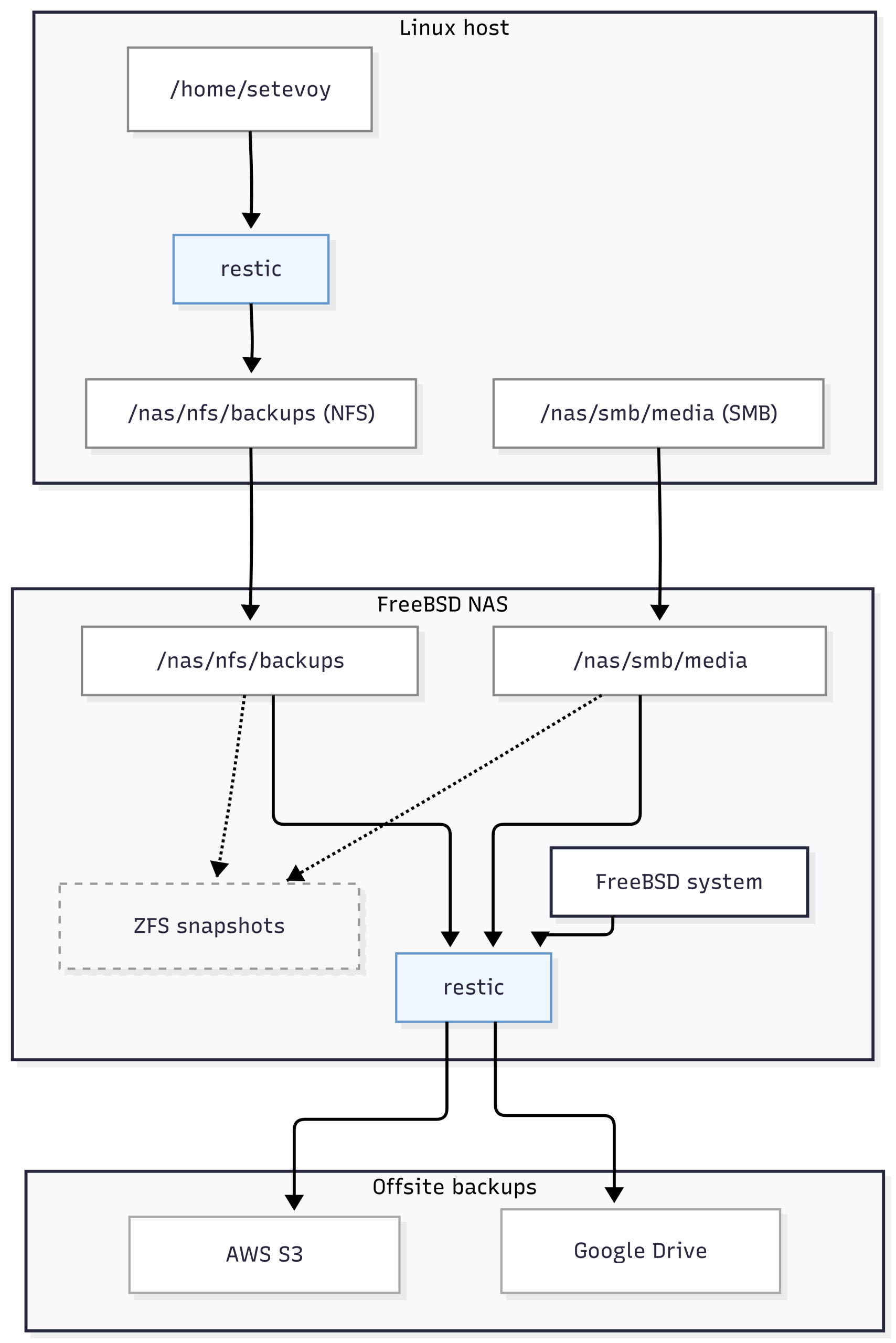
Сьогодні подумаємо і заплануємо як робити бекапи з Linux-хостів на NFS share та як робити бекапи даних NFS і Samba на FreeBSD. При чому бекапи хочеться зробити у два незалежних сховища – AWS S3 та Google Disk: S3 буде основним, а Гугл – резервною копією (резервної копії).
Всі частини серії по налаштуванню домашнього NAS на FreeBSD:
Дані в restic організовані у репозиторіях: кожен репозиторій – це окремий каталог, який містить конфігурацію репозиторію, індекси та зашифровані дані.
Під час створення бекапу restic формує власні логічні snapshots. Дані розбиваються на незалежні блоки (blobs), які і є базовими одиницями зберігання в репозиторії.
При наступних бекапах restic перевіряє, які саме блоки були змінені, і копіює тільки їх, а на блоки даних, які не змінились – створює посилання з нового снапшоту, таким чином оптимізуючи зайнятий дисковий простір.
Тобто тут процес схожий із ZFS snapshots – тільки у ZFS посилання створюється на блоки самої файлової системи і оригінальні дані, а в restic – на власні блоки даних в каталозі репозиторію.
При цьому restic зберігає дані у власному форматі, а тому ми не залежимо від файлової системи – створюємо бекап з ext4, копіюємо на ZFS, зберігаємо в S3, і відновлюємо на упасі боже Windows з NTFS. Єдине, що нам буде треба – це клієнт restic.
Створюємо тестовий репозиторій:
$ restic init --repo test-repo
enter password for new repository:
enter password again:
created restic repository 50ef450308 at test-repo
Перевіряємо зміст:
$ ll test-repo/
total 24
-r-------- 1 setevoy setevoy 155 Jan 1 16:47 config
drwx------ 258 setevoy setevoy 4096 Jan 1 16:47 data
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 index
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 keys
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 locks
drwx------ 2 setevoy setevoy 4096 Jan 1 16:47 snapshots
Кожен репозиторій має ключ, який використовується для доступу до зашифрованих даних:
$ restic key list --repo test-repo
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
ID User Host Created
-----------------------------------------------------
*0ca1c659 setevoy setevoy-work 2026-01-01 16:49:49
-----------------------------------------------------
Шифрування даних виконується з master key, який зберігається в репозиторії:
$ restic -r test-repo cat masterkey
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
{
"mac": {
"k": "v1PIB3bB1VW46oWWBtKQYA==",
"r": "Tia4a7HGs7PmN1EzWoWh4g=="
},
"encrypt": "0c3l/00P3dTgdbAqPZApAYn7E/MiloqOXyQsYr6AGOA="
}
Для отримання доступу до якого використовуються дані user keys:
scrypt: KDF (Key Derivation Function), яка використовується для отримання криптографічного ключа з пароля (див. Scrypt Key Derivation Function)
salt: сіль з рандомним значенням
data: зашифрований master key – саме він використовується для шифрування даних
Коли restic потрібно отримати доступ до даних у репозиторії – він бере введений пароль і salt, передає їх у KDF і формує ключ, який використовується для розшифрування master key репозиторію.
Master key, у свою чергу, застосовується для шифрування та розшифрування ключів, якими вже безпосередньо шифруються дані та метадані в репозиторії.
При цьому можна мати кілька різних user keys (або access keys), які будуть використовуватись для отримання master key.
При потребі пароль можна змінити:
$ restic key passwd --repo test-repo/
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
created new cache in /home/setevoy/.cache/restic
enter new password:
enter password again:
saved new key as <Key of setevoy@setevoy-work, created on 2026-01-01 16:49:49.010471345 +0200 EET m=+13.105722833>
При налаштуванні автоматизації бекапів – пароль можна передати зі змінної оточення RESTIC_PASSWORD (див. Environment Variables) або з файлу через --password-file.
Наприклад, для використання паролю з файлу – створимо директорію:
$ restic key add --repo test-repo
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
enter new password:
enter password again:
saved new key with ID c08c993b87363c17526e98fd46aeaf14767fa051e3b0d87a32c0cecc50e361d4
Перевіряємо ключі тепер:
[setevoy@setevoy-work ~/Projects/Restic] $ restic key list --repo test-repo
enter password for repository:
repository 50ef4503 opened (version 2, compression level auto)
ID User Host Created
-----------------------------------------------------
*0ca1c659 setevoy setevoy-work 2026-01-01 16:49:49
c08c993b setevoy setevoy-work 2026-01-01 17:02:10
-----------------------------------------------------
В *0ca1c659 зірочка показує, що зараз репозиторій відкритий з цим ключем.
Пробуємо відкрити з новим ключем – паролем з файла:
$ restic stats --repo test-repo --password-file ~/.config/restic-test/test-repo-password
repository 50ef4503 opened (version 2, compression level auto)
[0:00] 0 index files loaded
scanning...
Stats in restore-size mode:
Snapshots processed: 0
Total Size: 0 B
Для створення бекапів використовуємо команду restic backup, а для відновлення, власне, restic restore.
Бекапимо файл /tmp/restic-test.txt в наш репозиторій:
$ restic backup /tmp/restic-test.txt --repo test-repo
repository 50ef4503 opened (version 2, compression level auto)
no parent snapshot found, will read all files
[0:00] 0 index files loaded
Files: 1 new, 0 changed, 0 unmodified
Dirs: 1 new, 0 changed, 0 unmodified
Added to the repository: 755 B (687 B stored)
processed 1 files, 13 B in 0:01
snapshot bf8def5f saved
Під час кожного виклику restic backup в репозиторії створюється новий snapshot, навіть якщо дані в source не змінювались.
Але, як писав вище – якщо не змінюються дані, то і розмір репозиторію не росте, бо restic просто створить посилання з нового снапшоту на старі блоки даних.
При зміні частини даних – відповідно будуть створені нові блоки тільки для нових даних, на які буде замаплений цей снапшот, а на незмінні дані – в новому снапшоті залишаться старі посилання.
Перевіряємо наявні снапшоти:
$ restic snapshots --repo test-repo
repository 50ef4503 opened (version 2, compression level auto)
ID Time Host Tags Paths Size
-----------------------------------------------------------------------------------
bf8def5f 2026-01-01 17:07:53 setevoy-work /tmp/restic-test.txt 13 B
-----------------------------------------------------------------------------------
1 snapshots
Основні корисні команди при роботі з репозиторіями та снапшотами:
restic stats: статистика по репозиторію або снапшоту
restic check: перевірка цілісності репозиторію
restic ls: подивитись зміст снапшоту
restic diff: порівняти дані у двох снапшотах
restic copy: скопіювати зміст одного репозиторію в інший
І окремо варто згадати --dry-run – перевірити що саме буде виконуватись, і яких даних торкнеться операція.
Для відновлення даних з бекапу використовуємо restic restore і вказуємо ID снапшоту та куди його відновити.
Якщо в destination каталогу нема – restic його створить, а в ньому відновить ієрархію каталогів та файлів зі снапшоту:
$ restic restore --repo test-repo bf8def5f --target /tmp/test-restic-restore
...
restoring snapshot bf8def5f of [/tmp/restic-test.txt] at 2026-01-01 17:07:53.016664301 +0200 EET by setevoy@setevoy-work to /tmp/test-restic-restore
Summary: Restored 2 files/dirs (13 B) in 0:00
Перевіряємо:
$ tree /tmp/test-restic-restore
/tmp/test-restic-restore
└── tmp
└── restic-test.txt
Include та exclude для backup та restore
При створенні бекапу з restic backup ми вказуємо шлях, який бекапиться, а тому окремої опції --include нема.
Але є --exclude, з яким можна вказати які дані не треба включати в снапшот.
Наприклад, маємо каталог:
$ tree /tmp/restic-dir-test
/tmp/restic-dir-test
├── a.txt
└── sub
└── b.txt
Бекапимо весь цей каталог, але пропускаємо файл a.txt:
--keep-daily 7: залишаємо снапшоти за останні 7 днів
--keep-weekly 4: залишаємо снапшоти за останні 4 тижні (по одному snapshot на тиждень)
--keep-monthly 6: залишаємо снапшоти за останні 6 місяців (по одному snapshot на місяць)
застосовуємо тільки для снапшотів з тегом daily, і відразу видаляємо дані з диску
Restic mount – репозиторій як директорія
Можна змонтувати репозиторій як звичайну папку, монтується тільки в режимі read-only:
$ mkdir /tmp/restic-mounted-test-repo
$ restic mount -r test-repo /tmp/restic-mounted-test-repo
...
Now serving the repository at /tmp/restic-mounted-test-repo
...
$ restic snapshots -r new-test-repo
repository fc8a407c opened (version 2, compression level auto)
ID Time Host Tags Paths Size
-----------------------------------------------------------------------------------------------
7335e7bf 2026-01-04 15:08:41 setevoy-work daily,2026-01-04-15-08 /tmp/restic-dir-test 18 B
-----------------------------------------------------------------------------------------------
Restic та репозиторій в AWS S3
З S3 все більш-менш аналогічно до роботи з локальними репозиторіями, але є деякі нюанси.
Для аутентифікації restic використовує звичайний механізм – пошук змінних оточення AWS_ACCESS_KEY_ID та AWS_SECRET_ACCESS_KEY, або пошук у файлах ~/.aws/config та ~/.aws/credentials.
Важливі нюанси, які треба мати на увазі при роботі з S3:
видаляти дані з репозиторію restic в AWS S3 можна тільки через restic forget та restic prune
використання S3 Lifecycle rules для restic не рекомендується – навіть для зміни storage class
Каталоги (index/, snapshots/, keys/) активно використовуються restic; якщо перенести, наприклад, keys/ у Glacier або Deep Archive – restic може зависати або падати по таймауту, очікуючи доступ до ключів.
Теоретично lifecycle transitions можна застосувати лише до каталогу data/, де зберігаються pack-файли з даними, але якщо потім запустити restic prune – то restic буде потрібен доступ до старих pack-файлів в data/, і, якщо вони знаходяться в Glacier або Deep Archive, операція стане або дуже повільною, або взагалі неможливою
Тому краще просто робити періодичний restic forget і restic prune, та залишити S3 Standart class даних в бакеті.
Restic та Google Drive через rclone
В мене rclone для Google Drive вже налаштований, допишу про нього окремо, вже є в чернетках, бо теж дуже цікава система.
Що ми можемо зробити – це використати rclone як storage backend для роботи з типами storage, яких нема в самому restic.
Але працює ця схема ну дуже повільно (принаймні з Google Drive) – тому її краще використовувати як one time copy, а не для регулярних бекапів.
Запускаємо restic copy, але тепер для copy вказуємо тільки --from-repo – бо destination у нас вже заданий через $RESTIC_REPOSITORY:
$ restic copy --from-repo s3:s3.amazonaws.com/test-restic-repo-bucket/test-restic-repository
enter password for source repository:
repository 58303a9c opened (version 2, compression level auto)
created new cache in /home/setevoy/.cache/restic
enter password for repository:
repository e1a8edae opened (version 2, compression level auto)
created new cache in /home/setevoy/.cache/restic
[0:00] 0 index files loaded
[0:00] 0 index files loaded
Перевіряємо в Google Drive:
$ restic snapshots
enter password for repository:
repository e1a8edae opened (version 2, compression level auto)
ID Time Host Tags Paths Size
-----------------------------------------------------------------------------------------------
...
bb02e44b 2026-01-04 15:08:41 setevoy-work daily,2026-01-04-15-08 /tmp/restic-dir-test 18 B
-----------------------------------------------------------------------------------------------
Що треба мати на увазі при роботі restic через clone:
не використовувати rclone mount
не виконувати запис одночасно з двох restic клієнтів
не використовувати одночасно два rclone serve restic для одного репозиторію
Власне, на цьому все.
Залишилось додати автоматизацію запуску бекапів на Linux та FreeBSD, але це вже опишу окремим постом.
Там часто всякі боти запускаються, нічого незвичного.
Далі, вирішив з nmap глянути що за сервіси є на тому атакуючому хості:
# nmap -sS 46.101.201.123
...
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
443/tcp open https
...
Хм, думаю – дивно, що за бот такий, що має 80 і 443 порти?
Відкриваю https://46.101.201.123 в браузері, і… попадаю на власний блог 🙂
Шта?…
Перевіряю, які IP в мене в DigitalOcean, і:
Тобто – да, 46.101.201.123 – це Droplet IP сервера, на якому хоститься RTFM.
Хоча взагалі на DNS в IN A для rtfm.co.ua використовується DigitalOcean Reserved IP, який можна переключати між дроплетами:
Тобто:
NS для rtfm.co.ua – Cloudflare
на них IN A 67.207.75.157
Droplet IP 46.101.201.123 не вказаний ніде
але запити йдуть на нього
Окей…
Тут ще буде окреме питання – чому в CloudFlare показувались запити від 46.101.201.123 – але про це в кінці.
SYN flood та підключення в SYN_RECV
Пішов глянути що взагалі на сервері в нетворкінгу, які активні конекти?
А там…
Купа підключень в статусі SYN_RECV – класичний SYN flood: клієнт нам відправляє TCP-пакет з флагом SYN, ми йому відповіли з SYN-ACK, і чекаємо на ACK від нього – але він не приходить, а ресурси CPU/RAM сервера на очікування зайняті (див. TCP handshake, нещодавно писав).
Mitigating the issue
Так як підключення йдуть не через CloudFalre – то і його Security Rules нам не допоможуть.
А Network Firewall в Digital Ocean, як і Security Groups в AWS вміють тільки в Allow правила – але не в Deny (в AWS можна зробити Deny через правила у VPC NACL – Network Access Control List).
А друге – сама причина 46.101.201.123 в логах Clodflare: “GET /wp-json/pvc/v1/increase/” – це запит до WordPress-плагіна Page View Count, який не так давно включив. А “https://rtfm.co.ua/en/freebsd-home-nas-part-1-configuring-zfs-mirror-raid1″ – звідки запит був зроблений.
Тобто, плагін на сторінці поста робить запит, аби збільшити лічильник переглядів – при цьому підставляючи Referrer у вигляді тої сторінки, звідки він запит робить.
Cloudflare жеж бачить, що запит йде від Origin – і використовує в логах Droplet IP.
Це при тому, що зазвичай переглядів кілька десятків, ну максимум 100-200.
І перевірка в гуглі вже показала причину такого напливу:
А трапилось те, що я сьогодні вранці перший раз запостив лінк на https://lobste.rs, звідки його перепостили на Hacker News, і я отримав “Hacker News hug of death” – див. Surviving the Hug of Death, де у людини була схожа ситуація.
Після відключення плагіну Page View Count – Droplet IP 46.101.201.123 в Cloudflare зник.
Наступний крок в процесі налаштування домашнього NAS на FreeBSD – додати NFS share.
Samba зробили в попередній частині – тепер до неї додамо шари з NFS: моя ідея в тому, щоб Samba share використовувалась для всяких медіа-ресурсів, до яких потрібен доступ з телефонів та TV, а NFS буде виключно для Linux-хостів – двох ноутбуків в різних мережах (дім і офіс), які на цей розділ будуть робити свої бекапи з rsync, rclone або restic.
Всі частини серії по налаштуванню домашнього NAS на FreeBSD:
В 192.168.0.2:/backups каталог /backups вказуємо від корня, який задали в /etc/exports: тобто корінь у нас “/nas/nfs” – значить на клієнтах він буде “/“, і, відповідно, внутрішні датасети монтуємо від цього корня як /backups.
А по-дефолту NFS виконує root_squash, і всі операції від клієнтів на сервері виконує від локального юзера nobody.
Є кілька варіантів вирішення:
на сервері створити групу типу nfsusers, дати їй права на запис в каталог (775), і додати локального юзера setevoy в цю групу
самий кошерний і безпечний варіант
або можна задати опцію -maproot=root – тоді root на клієнті буде == root на сервері (UID в обох 0)
але це тільки про доступ до файлів, і тільки в межах NFS root – /nas/nfs
ОК варіант для домашнього NAS
трохи безпечніший варіант – вказати -maproot=setevoy і на сервері змінити власника /nas/nfs/backups/ – тоді операції від root на клієнті на сервері будуть виконуватись від UID/GID юзера setevoy на сервері
або взагалі зробити -mapall=root – і тоді всі юзери на клієнті будуть виконувати операції як локальний root
аналогічно до -maproot=root, але і самий небезпечний варіант
Так як ця шара для бекапів, які на клієнтах будуть виконуватись від root – то можна використати maproot=root:
root@setevoy-nas:/home/setevoy # zfs set sharenfs="-network 192.168.0.0/24 -maproot=root" nas/nfs/backups
root@setevoy-nas:/home/setevoy # service nfsd restart
Тепер на клієнті від звичайного юзера у нас доступу все ще нема:
Допомогли на форумі FreeBSD, див. NFSv4 and share for multiply networks (взагалі, FreeBSD community дуже відкрите, і набагато менш токсичне, аніж ті ж форуми Arch Linux).
І, звісно, хочеться доступ до NFS мати захищеним на рівні мереж (хоча в моєму випадку цілком можна було обійтись без цього, але краще відразу робити правильно).
А проблема полягає в том, що у ZFS ver 2.2.7, яка використовується у FreeBSD 14.3 зараз, нема можливості вказати кілька мереж в sharenfs property.
Тобто, не можна використати щось типу:
# zfs set sharenfs="-network 192.168.0.0/24 -network 192.168.100.0/24 -network 10.8.0.0/24" nas/nfs/backups
Але у FreeBSD 15.0 і ZFS 2.4.0 начебто розширили синтаксис, і там вже можна передати список, розділений “;“:
[setevoy@setevoy-home ~]$ sudo wg show
interface: wg0
...
peer: xLWA/FgF3LBswHD5Z1uZZMOiCbtSvDaUOOFjH4IF6W8=
endpoint: 178.***.***.184:51830
allowed ips: 10.8.0.1/32, 192.168.0.0/24
З адресою 10.8.0.3:
[setevoy@setevoy-home ~]$ ip a s wg0
44: wg0: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1420 qdisc noqueue state UNKNOWN group default qlen 1000
link/none
inet 10.8.0.3/24
...
Встановлюємо nfs-utils, інакше буде помилка “NFS: mount program didn’t pass remote address“:
Дуже рідко бувають проблеми з апгрейдами на Arch Linux, а така ситуація, як сьогодні, в мене за майже 10 років користування системою вперше.
Отже, що трапилось:
встановив апгрейди з pacman -Syu
після установки sudo reboot зависав
ребутнутись вдалось тільки з sudo reboot -f (force)
після ребуту – X.Org запустився, SDDM теж, Plasma теж – але на робочому столі все зависало і не реагувало на клаву і мишку
Дичина якась 🙂
Пофіксити вдалось, хоча так і не зрозумів що саме і чому впало.
Проблема #1: sudo reboot та “Failed to connect to system scope bus via local transport”
Це насправді було першим дзвіночком.
В логах при виконанні sudo reboot з’являлось повідомлення про:
...
Call to Reboot failed: Connection timed out
Failed to connect to system scope bus via local transport: Connection refused
...
Явно проблема з D-Bus/systemd, і саме тому допомогло sudo reboot -f (чи з sudo shutdown -r now, щось з них двох спрацювало), бо в такому випадку systemd не намагається координувати shutdown через system bus і напряму викликає примусовий перезапуск.
Окей – ребутнулись, і тут виникла друга – сама цікава – проблема.
KDE Plasma “висить” після апгрейду і ребуту
Беру в лапки “Plasma висить”, бо проблема все ж була не в ній – але проявлялось саме там.
Отже, ребунувся, залогінився, робочий стіл і сервіси запустились:
Але на цьому – все.
Ніякої реакції на клаву і мишку.
Перша підозра – проблема з KDE Wallet або GNOME Keyring – бо все виглядало так, що зависання виникає після їх старту.
При цьому SSH працював, і я зміг підключатись з іншого ноутбука аби подебажити і пофіксити.
Хоча xorg-server і xorg-xinit вже були, бо я на X11, а не глючному Wayland.
Далі по SSH прибив поточну сесію:
$ sudo systemctl stop sddm
На ноутбуці через Alt + F2 зайшов в консоль (до речі… дивно, що це спрацювало, але ок), і запустив startx.
X11 та xterm завантажились – і тут жеж все знов перестало реагувати на клаву-мишку.
…
Краса…)
А отже, проблема виникає не на рівні Plasma чи конкретного desktop environment, а нижче – на рівні ядра, systemd, input stack та їх ініціалізації.
Fix attempt #3: pacman.log та “Failed to connect to system scope bus via local transport: Connection refused”
Окей – пішов дивитись логи pacman, і ось тут було дещо цікаве:
[2025-12-29T09:33:25+0200] [PACMAN] Running 'pacman -Syu --noconfirm'
[2025-12-29T09:33:25+0200] [PACMAN] synchronizing package lists
[2025-12-29T09:33:28+0200] [PACMAN] starting full system upgrade
...
[2025-12-29T09:33:49+0200] [ALPM] upgraded systemd (258.3-1 -> 259-1)
[2025-12-29T09:33:49+0200] [ALPM-SCRIPTLET] Creating group 'empower' with GID 946.
[2025-12-29T09:35:20+0200] [ALPM-SCRIPTLET] Failed to connect to system scope bus via local transport: Connection refused
[2025-12-29T09:35:20+0200] [ALPM-SCRIPTLET] Failed to connect to system scope bus via local transport: Connection refused
[2025-12-29T09:35:20+0200] [ALPM-SCRIPTLET] :: This is a systemd feature update. You may want to have a look at
[2025-12-29T09:35:20+0200] [ALPM-SCRIPTLET] NEWS for what changed, or if you observe unexpected behavior:
[2025-12-29T09:35:20+0200] [ALPM-SCRIPTLET] /usr/share/doc/systemd/NEWS
[2025-12-29T09:35:20+0200] [ALPM] upgraded polkit (126-2 -> 127-2)
[2025-12-29T09:35:20+0200] [ALPM-SCRIPTLET] Failed to connect to system scope bus via local transport: Connection refused
...
[2025-12-29T09:35:26+0200] [ALPM] running '30-systemd-catalog.hook'...
[2025-12-29T09:35:26+0200] [ALPM] running '30-systemd-daemon-reload-system.hook'...
[2025-12-29T09:35:26+0200] [ALPM-SCRIPTLET] Failed to connect to system scope bus via local transport: Connection refused
[2025-12-29T09:35:26+0200] [ALPM] running '30-systemd-daemon-reload-user.hook'...
[2025-12-29T09:35:27+0200] [ALPM-SCRIPTLET] Failed to connect to system scope bus via local transport: Connection refused
[2025-12-29T09:35:27+0200] [ALPM] running '30-systemd-hwdb.hook'...
[2025-12-29T09:35:27+0200] [ALPM] running '30-systemd-restart-marked.hook'...
[2025-12-29T09:35:27+0200] [ALPM-SCRIPTLET] Failed to connect to system scope bus via local transport: Connection refused
....
[2025-12-29T09:35:30+0200] [ALPM-SCRIPTLET] ==> Building image from preset: /etc/mkinitcpio.d/linux.preset: 'default'
[2025-12-29T09:35:30+0200] [ALPM-SCRIPTLET] ==> Using default configuration file: '/etc/mkinitcpio.conf'
[2025-12-29T09:35:30+0200] [ALPM-SCRIPTLET] -> -k /boot/vmlinuz-linux -g /boot/initramfs-linux.img
...
[2025-12-29T09:35:33+0200] [ALPM-SCRIPTLET] ==> Creating zstd-compressed initcpio image: '/boot/initramfs-linux.img'
[2025-12-29T09:35:33+0200] [ALPM-SCRIPTLET] -> Early uncompressed CPIO image generation successful
[2025-12-29T09:35:33+0200] [ALPM-SCRIPTLET] ==> Initcpio image generation successful
[2025-12-29T09:35:33+0200] [ALPM] running 'dbus-reload.hook'...
[2025-12-29T09:35:33+0200] [ALPM-SCRIPTLET] Failed to connect to system scope bus via local transport: Connection refused
...
І згадуємо першу проблему – що нормальний reboot не працював з тою самою помилкою підключення до системної шини (через /run/dbus/system_bus_socket).
І система не змогла виконати всі hooks, і в результаті після рестарту частина системних сервісів зависала.
Найімовірніше, це торкнулось компонентів, які залежать від udev, logind та input stack. В результаті X.Org і display manager стартували, але пристрої вводу (keyboard/mouse) опинились у неконсистентному стані, без коректної обробки подій.
Final fix: установка ядра linux-lts (але діло не в LTS)
Тут в мене з’явилась підозра, що проблема в ядрі і Intel-дайверах, і вирішив спробувати встановити LTS-ядро:
$ pacman -S linux-lts linux-lts-header
Правда, після встановлення забув зробити grub-mkconfig, а тому в меню GRUB “Advanced options for Arch Linux” нове ядро не з’явилось, і я просто загрузився зі старим.
Але… Саме після цього все запрацювало.
Чому – бо під час встановлення LTS заново запустились всі хуки, бо перший апдейт відбувався в момент оновлення systemd і D-Bus, а другий – у вже стабільному systemd-оточенні:
Коротше – класичний приклад неочевидної “магії” systemd, D-Bus та системних hooks під час апгрейду.
Lessons learned
якщо під час pacman -Syu з’являються помилки systemd/dbus, їх не варто ігнорувати – а я звик, що апгрейди проходять без проблем, і не подивився на pacman output в консолі, а відразу почав ребутати машину
зависання GUI не завжди означає проблему в Destop Environment або Wayland/X11
повторний запуск системних hooks у стабільному середовищі може повністю виправити систему
Прийшов час трохи привести в порядок SSH на самому FreeBSD та на клієнтах – ноутбуках з Arch Linux, бо на домашніх машинках досі використовую парольну аутентифікацію.
Власне, описані нижче налаштування не специфічні ні для FreeBSD, ні для Linux, бо SSH server один і той самий на всіх системах (OpenSSH_9.9p2 на FreeBSD 14.3 і OpenSSH_10.2p1 на Arch Linux).
хост з FreeBSD/NAS: доступний тільки в локальній мережі і VPN, тому SSH brute force не очікується (але при параної або на публічно доступних серверах можна додати Fail2Ban чи SSHGuard)
sshd: друга лінія захисту, базові налаштування доступу
SSH та аутентифікація по ключам
Перше і основне – це налаштувати доступ по ключам замість парольної аутентифікації.
Зробимо це, потім доступ по паролям відключимо взагалі.
На клієнті, ноутбуці з Linux, створюємо ключі:
[setevoy@setevoy-work ~] $ ssh-keygen -t ed25519 -C "setevoy@setevoy"
Generating public/private ed25519 key pair.
Enter file in which to save the key (/home/setevoy/.ssh/id_ed25519): /home/setevoy/.ssh/freebsd-nas
Enter passphrase for "/home/setevoy/.ssh/freebsd-nas" (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/setevoy/.ssh/freebsd-nas
Your public key has been saved in /home/setevoy/.ssh/freebsd-nas.pub
Копіюємо на хост з FreeBSD:
[setevoy@setevoy-work ~] $ ssh-copy-id -i /home/setevoy/.ssh/freebsd-nas [email protected]
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/setevoy/.ssh/freebsd-nas.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
([email protected]) Password for setevoy@setevoy-nas:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh -i /home/setevoy/.ssh/freebsd-nas '[email protected]'"
and check to make sure that only the key(s) you wanted were added.
Перевіряємо файл ~/.ssh/authorized_keys на FreeBSD у юзера setevoy:
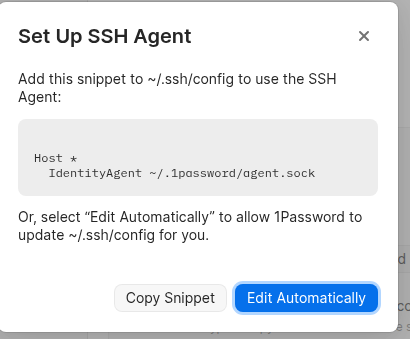
root@setevoy-nas:/home/setevoy # op account add
Enter your sign-in address (example.1password.com): my.1password.com
Enter the email address for your account on my.1password.com: <ACCOUNT_EMAIL>
Enter the Secret Key for [email protected] on my.1password.com: <SECRET_KEY>
Enter the password for [email protected] at my.1password.com:
Enter your six-digit authentication code: <OTP_CODE>
Now run 'eval $(op signin)' to sign in.
Перевіряємо акаунти:
root@setevoy-nas:/home/setevoy # op account list
SHORTHAND URL EMAIL USER ID
my https://my.1password.com [email protected] 7BS***KMM
Логінимось:
root@setevoy-nas:/home/setevoy # eval $(op signin)
Enter the password for [email protected] at my.1password.com:
І маємо доступ до сікретів.
Наприклад, отримати ключ, який додамо далі:
root@setevoy-nas:/home/setevoy # op item get "FreeBSD NAS SSH"
ID: ulz***4ce
Title: FreeBSD NAS SSH
Vault: Personal (wb7***guq)
Created: 1 week ago
Updated: 1 week ago by Arseny
Favorite: false
Tags: FreeBSD,SSH
Version: 1
Category: LOGIN
Fields:
password: [use 'op item get ulz***4ce --reveal' to reveal]
username: setevoy
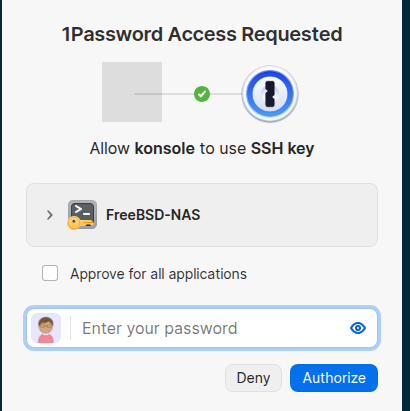
Виконуємо ssh nas.setevoy, 1Password запросить підтвердження – пароль самого 1Password:
І тепер все працює через його SSH Agent:
[setevoy@setevoy-work ~] $ ssh nas.setevoy
...
Last login: Sat Dec 27 09:03:15 2025 from 192.168.0.4
FreeBSD 14.3-RELEASE (GENERIC) releng/14.3-n271432-8c9ce319fef7
Welcome to FreeBSD!
...
[setevoy@setevoy-nas ~]$
Як працює SSH Agent
При підключені SSH-клієнт:
читає конфігурацію (~/.ssh/config, опції CLI)
підключається до SSH-агента (у нашому випадку 1Password) і отримує список доступних публічних ключів
по черзі пропонує серверу публічні ключі, які в нього є (з агента і, за відсутності обмежень, з ~/.ssh/)
sshd на сервері дивиться в ~/.ssh/authorized_keys конкретного юзера і перевіряє, чи є там запропонований публічний ключ
коли сервер знаходить збіг, він приймає цей публічний ключ і надсилає клієнту дані для підпису (випадковий набір чисел)
клієнт передає ці дані SSH-агенту, який володіє відповідним приватним ключем
агент створює криптографічний підпис приватним ключем і повертає його клієнту
сервер перевіряє підпис публічним ключем і завершує аутентифікацію
Глянути це можемо з ssh -v user@host:
[setevoy@setevoy-work ~] $ ssh -v [email protected]
debug1: OpenSSH_10.2p1, OpenSSL 3.6.0 1 Oct 2025
debug1: Reading configuration data /home/setevoy/.ssh/config
...
debug1: Connecting to nas.setevoy [192.168.0.2] port 22.
debug1: Connection established.
...
debug1: Authenticating to nas.setevoy:22 as 'setevoy'
...
debug1: Will attempt key: RTFM RSA SHA256:nedb3Qgpkxgu57MRP7/eXShHgw6N6b7SjZ3S1rNyFb4 agent
debug1: Will attempt key: FreeBSD-NAS ED25519 SHA256:ZuJ77z6BNMwra41BiTKDrJSSQrDJ0/u+4wZRCvGJMpA agent
debug1: Will attempt key: /home/setevoy/.ssh/id_rsa
debug1: Will attempt key: /home/setevoy/.ssh/id_ecdsa
debug1: Will attempt key: /home/setevoy/.ssh/id_ecdsa_sk
debug1: Will attempt key: /home/setevoy/.ssh/id_ed25519 ED25519 SHA256:X8L1lCBQz8Bk7K5rMGqiE+tlSthCbgaqK7ryLZ6gVWU
debug1: Will attempt key: /home/setevoy/.ssh/id_ed25519_sk
debug1: Offering public key: RTFM RSA SHA256:nedb3Qgpkxgu57MRP7/eXShHgw6N6b7SjZ3S1rNyFb4 agent
debug1: Authentications that can continue: publickey
debug1: Offering public key: FreeBSD-NAS ED25519 SHA256:ZuJ77z6BNMwra41BiTKDrJSSQrDJ0/u+4wZRCvGJMpA agent
debug1: Server accepts key: FreeBSD-NAS ED25519 SHA256:ZuJ77z6BNMwra41BiTKDrJSSQrDJ0/u+4wZRCvGJMpA agent
Authenticated to nas.setevoy ([192.168.0.2]:22) using "publickey".
...
Last login: Sun Dec 28 13:44:51 2025 from 192.168.0.4
FreeBSD 14.3-RELEASE (GENERIC) releng/14.3-n271432-8c9ce319fef7
Welcome to FreeBSD!
...
[setevoy@setevoy-nas ~]$
І для ключів “Will attempt key: RTFM RSA [...] та FreeBSD-NAS [...] як раз бачимо, що вони були отримані від agent.
SSH Agent та помилка “Too many authentication failures”
Вище бачили, що передається ціла пачка ключів, і якщо їх багато – то сервер може відкинути подальшу аутентифікацію.
Кількість спроб задається на сервері параметром MaxAuthTries (дефолт “6”) в /etc/ssh/sshd_config. Тобто, якщо маємо 7 ключів, і перші 6 не підійшли – то підключитись не зможемо.
Аби вказати SSH клієнту який конкретно приватний ключ з агента використовувати – вказуємо публічний ключ та задаємо IdentitiesOnly:
root@setevoy-nas:/home/setevoy # sshd -T
port 22
addressfamily any
listenaddress 0.0.0.0:22
...
Наприклад, чи дозволений логін root:
root@setevoy-nas:/home/setevoy # sshd -T | grep root
permitrootlogin no
Редагуємо конфіг /etc/ssh/sshd_config, задаємо мінімальні параметри, і нехай буде PermitRootLogin no вказаний тут явно.
Плюс явно вказуємо дозвіл на PubkeyAuthentication та PasswordAuthentication – парольну аутентифікацію відключимо пізніше, коли впевнимось, що все працює:
PermitRootLogin no
PubkeyAuthentication yes
PasswordAuthentication yes
Перевіряємо синтаксис з sshd -t, якщо все добре – то команда просто нічого не виведе:
...
# allow SSH from Office LAN (192.168.0.0/24) to FreeBSD host
pass in log on em0 proto tcp from 192.168.0.0/24 to (em0) port 22 keep state
# allow SSH from Home network (192.168.100.0/24) to FreeBSD host
pass in log on em0 proto tcp from 192.168.100.0/24 to (em0) port 22 keep state
# allow SSH from VPN clients to FreeBSD host
pass in on wg0 proto tcp from 10.8.0.0/24 to (wg0) port 22 keep state
...
Можна мережі вказати як { 192.168.0.0/24, 192.168.100.0/24, 10.8.0.0/24 }, але для SSH вирішив залишити в такому вигляді, аби було явно видно.
Далі можна додати ще трохи параметрів:
PermitRootLogin no: заборона підключення root, це вже є
PubkeyAuthentication yes: аутентифікація по ключам, теж вже є
PasswordAuthentication yes: пароль аутентифікація, поки залишаємо включеною
ChallengeResponseAuthentication no: вимикаємо keyboard-interactive аутентифікацію через PAM, яка не потрібна без 2FA
тут ще нюанс в тому, що навіть якщо відключити PasswordAuthentication, але ChallengeResponseAuthentication буде “yes” і при UsePAM = “yes” – то система все одно може запросити парольну аутентифікацію
AuthorizedKeysFile .ssh/authorized_keys: це дефолтне значення, але задамо явно
Перевіряємо ще раз з sshd -t, виконуємо reload, перевіряємо підключення з ключем з клієнта.
Якщо все ОК – то додаємо ще трохи тюнингу:
PasswordAuthentication no: тепер відключаємо парольну аутентифікацію
AuthenticationMethods publickey: явно заборонити всі механізми окрім ключів
MaxSessions 2: максимальна кількість активних сесій на одне TCP-підключення
LoginGraceTime 30: кількість секунд, за яку клієнт має пройти аутентифікацію
Для ще більшої безпеки – можна налаштувати інший порт замість 22 (наприклад, задати Port 2222), обмежити IP, на яких слухає sshd (параметр ListenAddress 192.168.0.2), і навіть налаштувати Two-factor Authentication For SSH – але для домашнього сервера з доступом тільки з локальних мереж це вже overkill.
Продовжуємо налаштовувати домашній NAS на FreeBSD.
Власне, NAS – Network System, і хочеться мати до нього доступ з інших девайсів – з Linux та Windows хостів, з телефонів, телевізорів.
Тут у нас на вибір дві основні опції – Samba та NFS. Можна, звісно, згадати і sshfs – але це рішення точно не для домашньої мережі (хоча простіше).
Я для себе вирішив для Windows (на ігровому ПК), Android телефонів та Android TV зробити доступ з Samba share – а NFS буде чисто для Linux систем для бекапів.
В цьому пості налаштуємо Samba на FreeBSD, а в наступному – додамо NFS.
Всі частини серії по налаштуванню домашнього NAS на FreeBSD:
без можливості логіна в систему – /usr/sbin/nologin
але якщо планується виконувати локальні операції від юзера – то створюємо з -s /bin/sh, а SSH все одно буде заблокований в sshd config (про SSH буде окремим постом)
і з -g smbshare вказуємо primary group
Перевіряємо юзера:
root@setevoy-nas:/home/setevoy # id smbshare
uid=1004(smbshare) gid=1004(smbshare) groups=1004(smbshare)
І права доступу до каталога тепер – можна глянути розширену інформацію з getfacl, аби отримати POSIX/NFSv4 ACL, які ZFS використовує замість класичних Unix-бітів:
Samba буде встановлювати власні права доступу, тому в параметрах ZFS ACL треба переключити режими.
Samba керує правами доступу самостійно, тому для ZFS ACL потрібно увімкнути режими passthrough, щоб ZFS не змінював ACL.
Перевіряємо параметри датасету зараз:
root@setevoy-nas:/home/setevoy # zfs get acltype,aclmode,aclinherit nas/share
NAME PROPERTY VALUE SOURCE
nas/share acltype nfsv4 default
nas/share aclmode discard default
nas/share aclinherit restricted default
Задаємо aclmode та aclinherit в значення passthrough – тоді ZFS буде використовувати ті права, які задає Samba:
root@setevoy-nas:/home/setevoy # zfs set aclmode=passthrough nas/share
root@setevoy-nas:/home/setevoy # zfs set aclinherit=passthrough nas/share
Перевіряємо тепер:
root@setevoy-nas:/home/setevoy # zfs get acltype,aclmode,aclinherit nas/share
NAME PROPERTY VALUE SOURCE
nas/share acltype nfsv4 default
nas/share aclmode passthrough local
nas/share aclinherit passthrough local
На відміну від acltype=off, який повністю вимикає ACL і залишає лише POSIX-права, режим passthrough дозволяє Samba керувати ACL без втручання ZFS.
Надалі зміни в директорії /nas/share краще виконувати від імені smbshare або root, а не звичайного користувача, щоб не порушувати модель прав доступу Samba.
Або більше детально, просто явно вказуємо деякі дефолтні опції:
[global]
workgroup = WORKGROUP
security = user
[shared]
path = /nas/share
read only = no
browseable = yes
valid users = @smbshare
create mask = 0660
directory mask = 2770
Перевіряємо синтаксис:
root@setevoy-nas:/home/setevoy # testparm
Load smb config files from /usr/local/etc/smb4.conf
Loaded services file OK.
Weak crypto is allowed
Server role: ROLE_STANDALONE
Press enter to see a dump of your service definitions
# Global parameters
[global]
security = USER
idmap config * : backend = tdb
[shared]
create mask = 0660
directory mask = 02770
path = /nas/share
read only = No
valid users = @smbshare
Додаємо Samba-юзера:
root@setevoy-nas:/home/setevoy # smbpasswd -a smbshare
New SMB password:
Retype new SMB password:
Added user smbshare.
smbpasswd збереже його пароль в /var/db/samba4/private/passdb.tdb.
Запускаємо сервіс:
root@setevoy-nas:~ # service samba_server start
Performing sanity check on Samba configuration: OK
Starting nmbd.
Starting smbd.
root@setevoy-nas:/home/setevoy # smbclient //localhost/shared -U smbshare
Password for [WORKGROUP\smbshare]:
Try "help" to get a list of possible commands.
smb: \>
Робимо list files – поки тут пусто:
smb: \> ls
. D 0 Fri Dec 26 15:46:55 2025
.. D 0 Fri Dec 26 15:46:55 2025
3771191492 blocks of size 1024. 3771191396 blocks available
Копіюємо щось із системи:
smb: \> put /etc/hosts hosts.test
putting file /etc/hosts as \hosts.test (252.7 kb/s) (average 252.7 kb/s)
smb: \> ls hosts.test
hosts.test A 1035 Fri Dec 26 16:14:29 2025
3771191480 blocks of size 1024. 3771191380 blocks available
І тепер маємо файл в /nas/share:
root@setevoy-nas:/home/setevoy # ls -l /nas/share
total 5
-rw-rw---- 1 smbshare smbshare 1035 Dec 26 16:14 hosts.test
cifs-utils: утиліти для роботи з Samba share через CIFS:
mount -t cifs
запису в /etc/fstab
systemd automount
Перевіряємо підключення з Linux до Samba на FreeBSD:
[setevoy@setevoy-work ~] $ smbclient //192.168.0.2/shared -U smbshare
Can't load /etc/samba/smb.conf - run testparm to debug it
Password for [WORKGROUP\smbshare]:
Try "help" to get a list of possible commands.
smb: \>
Ще раз list – все на місці:
smb: \> ls hosts.test
hosts.test A 1035 Fri Dec 26 16:14:29 2025
3771191480 blocks of size 1024. 3771191380 blocks available
Налаштування /etc/fstab та systemd-automount
Якщо хочемо, аби шара підключалась автоматично – налаштуємо /etc/fstab та systemd-automount.
На клієнті створюємо каталог, в який буде підключатись /nas/share з серверу:
Через файл mnt-nas\x2dshared.automount systemd відстежує доступ до /mnt/nas-shared, і як тільки ми виконаємо якусь дію (наприклад, cd /mnt/nas-shared) – systemd виконає mnt-nas\x2dshared.mount, який власне підключить розділ.
57.2 MB/s, тобто 457.6 Mbit/s. При тому, що ноут зараз на WiFi – цілком нормальна швидкість.
Підключення Samba клієнтів
І приклади того, як до Samba підключитись з різних девайсів.
Samba та KDE Dolphin
Взагалі, ми вже зробили automount через systemd, але можна відкрити напряму з KDE Dolphin file manager – вказуємо адресу smb://192.168.0.2, вводимо логін-пароль:
root@setevoy-nas:~ # camcontrol devlist
<Samsung SSD 870 EVO 4TB SVT03B6Q> at scbus0 target 0 lun 0 (pass0,ada0)
<Samsung SSD 870 EVO 4TB SVT03B6Q> at scbus1 target 0 lun 0 (pass1,ada1)
<CT500P310SSD8 VACR001> at scbus7 target 0 lun 1 (pass3,nda0)
Тут в мене ada1 та ada2 – це SATA-диски для самого NAS storage, а nda0 – NVMe, на якому встановлена система (там зараз UFS, але потім, скоріш за все, перевстановлю із ZFS теж).
Імена пристроїв на кшталт /dev/ada0, /dev/ada1 або /dev/nda0 можуть змінюватися залежно від порядку підключення дисків, а тому напряму використовувати їх у ZFS не рекомендується – далі створимо власні GPT labels.
Створення GPT tables
Про всяк випадок – видаляємо існуючі таблиці розділів.
ВАЖЛИВО: таблиця розділів буде знищена. Дані залишаються на носії, але стануть недоступними.
В моєму випадку – диски нові, тому бачимо помилку “Invalid argument“:
Для подальшої роботи з дисками створимо постійні GPT lables – іменовані ідентифікатори розділів, які зберігаються в GPT-таблиці розділів і читаються при старті системи.
Вони не змінюються після reboot, не залежать від порядку SATA портів, не залежать від того, як ядро виявило диск.
root@setevoy-nas:~ # glabel status
Name Status Components
gpt/zfs_disk1 N/A ada0p1
gptid/67ebfac9-dcce-11f0-98bf-00d861f3bff0 N/A ada0p1
diskid/DISK-S758NX0Y701757D N/A ada0
gpt/zfs_disk2 N/A ada1p1
gptid/6a9c3ee5-dcce-11f0-98bf-00d861f3bff0 N/A ada1p1
diskid/DISK-S758NX0Y701756A N/A ada1
Диски готові – переходимо до ZFS, нам треба:
налаштувати ZFS pool з mirror
створити datasets
подивитись на шифрування даних
перевірити, як працювати зі snapshots
І в кінці окремо поговоримо про моніторинг дисків та ZFS pool.
Створення ZFS mirror pool
Використовуємо такі параметри:
ashift=12: розмір фізичного сектора, який ZFS використовує для I/O
розмір сектора визначається як 2^ashift байт, тобто 2¹² = 4096 байт
замінити значення ashift після створення Pool не можна
atime=off: вимикаємо оновлення часу доступу до файлів, зменшує кількість зайвих записів на диск
compression=lz4: швидка компресія даних на диску з мінімальним CPU-оверхедом
xattr: налаштування зберігання атрибутів файлі:
xattr=on: старий і default варіант, extended attributes зберігаються як окремі приховані файли
xattr=sa: xattr зберігаються безпосередньо в dnode файлу (аналог inode в UFS/ext4), без створення окремих прихованих файлів – менше звернень до диска і краща продуктивність
mirror: використовуємо ZFS mirror (аналог RAID1) – дані синхронно записуються на обидва диски (див. також vdev)
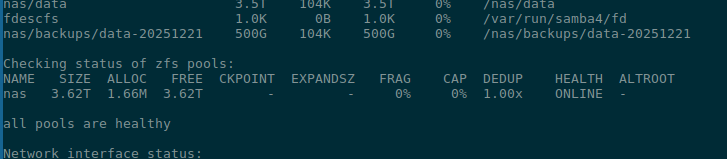
root@setevoy-nas:~ # zpool status
pool: nas
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
nas ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/zfs_disk1 ONLINE 0 0 0
gpt/zfs_disk2 ONLINE 0 0 0
errors: No known data errors
Додаємо підключення при ребутах:
root@setevoy-nas:/home/setevoy # sysrc zfs_enable=YES
zfs_enable: NO -> YES
Створення ZFS datasets
ZFS dataset – це окрема файлова система всередині ZFS pool, яка має власні властивості (compression, quota, mountpoint тощо) і керується незалежно від інших datasets.
Зараз у нас один, корневий dataset:
root@setevoy-nas:~ # zfs list
NAME USED AVAIL REFER MOUNTPOINT
nas 420K 3.51T 96K /nas
Корінь pool – це технічний корінь, а не місце для даних, тому створимо кілька окремих.
Не факт, що в мене датасети залишаться такими і надалі, але просто як ідея того, як можна розділити простір на дисках:
nas/data: основний dataset для збереження всяких даних типу музики-фільмів
nas/backups: сюди можна буде копіювати якісь periodic бекапи з робочого і домашнього ноутбуків
nas/private: зашифрований розділ для приватних даних та/або баз даних типу KeePass або бекапів 1Password
nas/shared: загальнодоступний dataset для доступу з телефонів і ноутбуків через Samba share (про налаштування Samba – окремим постом, вже є в чернетках)
Створюємо новий датасет з іменем nas/data:
root@setevoy-nas:~ # zfs create nas/data
Перевіряємо список ще раз:
root@setevoy-nas:~ # zfs list
NAME USED AVAIL REFER MOUNTPOINT
nas 540K 3.51T 96K /nas
nas/data 96K 3.51T 96K /nas/data
І каталог цього датасету:
root@setevoy-nas:~ # ls -la /nas/data/
total 1
drwxr-xr-x 2 root wheel 2 Dec 19 13:41 .
drwxr-xr-x 3 root wheel 3 Dec 19 13:41 ..
Він жеж має власну точку підключення:
root@setevoy-nas:/home/setevoy # mount | grep data
nas/data on /nas/data (zfs, local, noatime, nfsv4acls)
Яка задана у властивостях датасету:
root@setevoy-nas:/home/setevoy # zfs get mountpoint nas/data
NAME PROPERTY VALUE SOURCE
nas/data mountpoint /nas/data default
Додамо ще один:
root@setevoy-nas:~ # zfs create nas/backups
Ще раз список:
root@setevoy-nas:~ # zfs list
NAME USED AVAIL REFER MOUNTPOINT
nas 696K 3.51T 96K /nas
nas/backups 96K 3.51T 96K /nas/backups
nas/data 96K 3.51T 96K /nas/data
Шифрування dataset
Хочеться мати окремий dataset для чутливих даних, тому глянемо, як це зроблено у ZFS.
включити шифрування можна тільки створенні dataset – але можна відключити після
якщо батьківський dataset не зашифрований – дочірній можна зашифрувати
якщо батьківський зашифрований – дочірні успадковують його шифрування
Створимо новий dataset, вказуємо, що шифрується з паролем:
root@setevoy-nas:~ # zfs create -o encryption=on -o keyformat=passphrase -o keylocation=prompt nas/private
Enter new passphrase:
Re-enter new passphrase:
Перевіряємо цей датасет:
root@setevoy-nas:~ # zfs get encryption,keyformat,keylocation nas/private
NAME PROPERTY VALUE SOURCE
nas/private encryption aes-256-gcm -
nas/private keyformat passphrase -
nas/private keylocation prompt local
Як це буде виглядати після reboot:
pool nas імпортується
nas/private буде заблокований, і mountpoint не зʼявиться, доки вручну не ввести пароль і не розблокувати його
Для розблокування потім використовуємо:
root@setevoy-nas:~ # zfs load-key nas/private
root@setevoy-nas:~ # zfs mount nas/private
На відміну від, наприклад, шифрування розділів з LUKS – ZFS дозволяє змінювати пароль для зашифрованого dataset без перешифрування даних. Фактично змінюється лише ключ, який захищає основний ключ шифрування.
Якщо хочемо змінити пароль – виконуємо zfs change-key:
root@setevoy-nas:~ # zfs change-key nas/private
Enter new passphrase for 'nas/private':
Замість використання паролю можемо створити файл-ключ, який буде використаний про ребутах для підключення датасету.
root@setevoy-nas:/home/setevoy # zfs get encryption,keyformat,keylocation nas/private
NAME PROPERTY VALUE SOURCE
nas/private encryption aes-256-gcm -
nas/private keyformat raw -
nas/private keylocation file:///root/nas-private-pass.key local
Ребутаємо машину:
root@setevoy-nas:/home/setevoy # shutdown -r now
Shutdown NOW!
shutdown: [pid 13519]
І потім перевіряємо розділи:
root@setevoy-nas:/home/setevoy # mount | grep nas
nas on /nas (zfs, local, noatime, nfsv4acls)
nas/backups on /nas/backups (zfs, local, noatime, nfsv4acls)
nas/data on /nas/data (zfs, local, noatime, nfsv4acls)
Та з zfs list:
root@setevoy-nas:/home/setevoy # zfs list
NAME USED AVAIL REFER MOUNTPOINT
nas 200G 3.32T 112K /nas
nas/backups 200K 500G 104K /nas/backups
nas/data 96K 3.51T 96K /nas/data
nas/private 200K 3.32T 200K /nas/private
Налаштування dataset quotas
ZFS datasets підтримують задання квот на розмір датасетів – тобто, максимальний розмір, який він може займати.
Зручно, наприклад, аби якийсь backups/ випадково не забив весь диск.
Є ще dataset reservation, але про це трохи далі.
Задамо ліміт в 500 гігабайт на nas/backups:
root@setevoy-nas:~ # zfs set quota=500G nas/backups
Перевіряємо:
root@setevoy-nas:~ # zfs get quota,used,available nas/backups
NAME PROPERTY VALUE SOURCE
nas/backups quota 500G local
nas/backups used 96K -
nas/backups available 500G -
Налаштування dataset reservation
ZFS дозволяє зарезервувати місце для датасету, гарантуючи доступний простір незалежно від заповненості пулу.
Важливо, що ZFS Reservation резервує місце незалежно від того, використовується воно чи ні.
Задамо мінімально доступний розмір основного датасету nas/data:
root@setevoy-nas:~ # zfs set reservation=200G nas/data
Перевіряємо:
root@setevoy-nas:~ # zfs get reservation,used,available nas/data
NAME PROPERTY VALUE SOURCE
nas/data reservation 200G local
nas/data used 96K -
nas/data available 3.51T -
Аби змінити reservation чи видалити – просто раз виконуємо zfs set з новим значенням:
root@setevoy-nas:~ # zfs set reservation=100G nas/data
root@setevoy-nas:~ # zfs set reservation=none nas/data
Використання ZFS snapshots
ZFS Snapshots – це миттєві read-only знімки стану dataset, які дозволяють швидко відкотитись до попереднього стану.
ZFS працює за принципом COW (Copy On Write), тобто при зміні в блоках даних – зміни робляться в новому блоку, а старі блоки не перезаписуються, поки на них є активні посилання
при створенні снапшоту ZFS не копіює дані, а створює таке посилання на цей блок
далі, коли ми робимо зміни в даних датасета, для якого є снапшот – то зміни на диску робляться в нових блоках даних, а доступ до старих зберігається через снапшот
root@setevoy-nas:/home/setevoy # zfs list -t snapshot nas/data@test-snap
NAME USED AVAIL REFER MOUNTPOINT
nas/data@test-snap 0B - 104K -
Його атрибути:
root@setevoy-nas:/home/setevoy # zfs get creation,used,referenced nas/data@test-snap
NAME PROPERTY VALUE SOURCE
nas/data@test-snap creation Sat Dec 20 15:46 2025 -
nas/data@test-snap used 0B -
nas/data@test-snap referenced 104K -
Відновлення зі snapshot
Снапшоти зберігаються в каталозі .zfs датасета – /nas/data/.zfs/snapshot/:
root@setevoy-nas:/home/setevoy # ll /nas/data/.zfs/snapshot/test-snap/
total 1
-rw-r--r-- 1 root wheel 10 Dec 20 15:45 test-snap.txt
І звідси ми можемо отримати доступ і до нашого тестового файлу:
root@setevoy-nas:/home/setevoy # rm /nas/data/test-snap.txt
root@setevoy-nas:/home/setevoy # file /nas/data/test-snap.txt
/nas/data/test-snap.txt: cannot open `/nas/data/test-snap.txt' (No such file or directory)
Аби відновити зі снапшоту – можна або просто скопіювати з каталога /nas/data/.zfs/snapshot/test-snap/ з cp, або, якщо треба відкотити весь датасет, то використати zfs rollback – але в такому разі всі зміни, які були зроблені після створення снапшоту будуть втрачені:
Ну і ZFS Boot Environments працюють через ті самі снапшоти – під час виконання freebsd-update install автоматично створюється копія даних, на яку можна відкотитись в разі проблем.
Взагалі ZFS Boot Environments дуже цікава штука, може, окремо про неї напишу.
Замість повного rollback – аби не перезаписувати дані на поточному датасеті – можна зробити клонування снапшоту в новий датасет:
root@setevoy-nas:/home/setevoy # cat /usr/local/etc/periodic/daily//402.zfSnap
#!/bin/sh
# If there is a global system configuration file, suck it in.
#
if [ -r /etc/defaults/periodic.conf ]; then
. /etc/defaults/periodic.conf
source_periodic_confs
fi
...
Включити запуск скриптів можна в файлі /etc/periodic.conf (або, краще, /etc/periodic.conf.local):
Запустити виконання всіх daily задач, для яких в /etc/defaults/periodic.conf задано “YES” – з командою periodic:
root@setevoy-nas:/home/setevoy # periodic daily
І тепер нас є новий снапшот:
root@setevoy-nas:/home/setevoy # zfs list -t snapshot
NAME USED AVAIL REFER MOUNTPOINT
...
nas/data@daily-2025-12-21_16.41.03--1w 0B - 104K -
Моніторинг ZFS
Для моніторингу у нас є цілий набір утиліт – як дефолтні від самої файлової системи, так і додаткові, які можна встановити окремо.
Є класний документ Monitoring ZFS, хоча і 2017 року, але все ще актуальний.
З основного, чим можемо користуватись і що бажано моніторити:
SMART: перевірка самих дисків
zpool status: перевірка, що нема проблем на самих ZFS pools
zfs scrub: не зовсім про моніторинг, але може показати проблеми
zpool events: події пулів
arcstats: корисно перевіряти ефективність роботи кешу ZFS
Перевірка S.M.A.R.T. для SSD
Диски зовсім нові, але just in case і на майбутнє – налаштуємо S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology).
Встановлюємо пакет:
root@setevoy-nas:~ # pkg install smartmontools
І перевіряємо стан дисків:
root@setevoy-nas:~ # smartctl -a /dev/ada0
root@setevoy-nas:~ # smartctl -a /dev/ada1
Нам цікаві в основному такі показники:
SMART overall-health self-assessment test result: PASSED: перевірку пройдено (але зазвичай FAILED тут з’являється, коли все зовсім погано)
помилки:
Reallocated_Sector_Ct:
кількість битих секторів, які диск знайшов і замінив резервними
0 – ідеально, зростання цього значення – поганий сигнал
Runtime_Bad_Block:
кількість некоректних блоків, знайдених під час нормальної роботи або деградацію лінка (наприклад, падіння швидкості SATA)
0 – ідеально, зростання цього значення – поганий сигнал
Uncorrectable_Error_Cnt:
кількість помилок читання/запису, які неможливо було виправити
0 – обов’язково має залишатися, зростання – вже серйозна проблема
Wear/Used reserve:
Wear_Leveling_Count:
показує знос елементів памʼяті SSD
0 означає, що диск практично новий або знос мінімальний
Used_Rsvd_Blk_Cnt_Tot:
скільки резервних блоків уже використано для заміни зношених
0 – ідеальний стан
Power_On_Hours:
кількість годин, протягом яких диск був увімкнений
83 години – диски тільки нещодавно купив і підключив
CRC_Error_Count:
кількість помилок передачі даних між диском і контролером (кабель, порт)
0 – норма, зростання часто означає проблеми з кабелем, а не з самим диском
Total_LBAs_Written / Host_Writes / NAND_Writes:
скільки даних реально записано на диск
порівнюємо зі TBW (Total Bytes Written) від виробника
в моєму випадку Total_LBAs_Written = 77982, де LBA – це Logical Block Address, який зазвичай SMART рахує по 512 байт, тобто записано на диск ~40 мегабайт – при заявлених Samsung 2400 TB
Temperature / Temperature_Celsius / Airflow_Temperature_Cel
температура дисків, в мене зараз 28 градусів
SMART Periodic
Для запуска SMART є власні скрипти в /usr/local/etc/periodic.
Аби включити перевірку і репорти – додаємо запуск smartd в автостарт:
І налаштовуємо periodic в /etc/periodic.conf.local.
Аби включити перевірку – треба явно задати диски, по яким цю перевірку робити:
daily_status_smart_devices="/dev/ada0 /dev/ada1"
Результат в репорті:
ZFS Pool Status
zpool status вже запускали вище, тепер додамо запуск по крону і відправку повідомлень.
Скрипти для ZFS /etc/periodic/daily/, наприклад /etc/periodic/daily/404.status-zfs.
Додаємо до /etc/periodic.conf.local:
daily_status_zfs_enable="YES"
Запускаємо скрипти:
root@setevoy-nas:/home/setevoy # periodic daily
Отримуємо листа:
root@setevoy-nas:/home/setevoy # mail -u root
Mail version 8.1 6/6/93. Type ? for help.
"/var/mail/root": 12 messages 4 new 12 unread
...
N 12 root@setevoy-nas Sun Dec 21 17:20 82/3368 "setevoy-nas daily run output"
&
Під час scrub ZFS порівнює checksum кожного блоку зі збереженим значенням і у разі виявлення помилки система фіксує її в логах та, за наявності mirror, автоматично відновлює дані з другої копії.
Оскільки для цього виконується багато I/O операцій, тому не варто запускати scrubbing часто – раз на місяць буде достатньо.
Запускаємо вручну:
root@setevoy-nas:/home/setevoy # zpool scrub nas
І перевіряємо в zpool status:
root@setevoy-nas:/home/setevoy # zpool status
pool: nas
state: ONLINE
scan: scrub repaired 0B in 00:00:00 with 0 errors on Fri Dec 19 16:54:04 2025
config:
NAME STATE READ WRITE CKSUM
nas ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gpt/zfs_disk1 ONLINE 0 0 0
gpt/zfs_disk2 ONLINE 0 0 0
errors: No known data errors
Тепер в scan є “scrub repaired 0B” – все добре.
Скрипт – /etc/periodic/daily/800.scrub-zfs, в якому перевіряється значення daily_scrub_zfs_default_threshold, і, якщо пройшло більше днів, ніж задано в threshold – то запускається zpool scrub.
З daily_scrub_zfs_pools можна вказати, які саме пули перевіряти.
З zpool events можна перевірити всі останні події в пулі:
root@setevoy-nas:/home/setevoy # zpool events
TIME CLASS
Dec 20 2025 16:46:39.702350180 sysevent.fs.zfs.history_event
Dec 20 2025 16:46:39.711350328 ereport.fs.zfs.config_cache_write
Dec 20 2025 16:46:39.711350328 sysevent.fs.zfs.config_sync
Dec 20 2025 16:46:39.711350328 sysevent.fs.zfs.pool_import
Dec 20 2025 16:46:39.712349914 sysevent.fs.zfs.history_event
Dec 20 2025 16:46:39.720349727 sysevent.fs.zfs.config_sync
Dec 20 2025 14:46:44.749348450 sysevent.fs.zfs.config_sync
...
Dec 21 2025 17:26:30.905209986 sysevent.fs.zfs.history_event
Аби побачити деталі – додаємо -z:
root@setevoy-nas:/home/setevoy # zpool events -v
TIME CLASS
Dec 20 2025 16:46:39.702350180 sysevent.fs.zfs.history_event
version = 0x0
class = "sysevent.fs.zfs.history_event"
pool = "nas"
pool_guid = 0x2f9ad6b17a5e8426
pool_state = 0x0
pool_context = 0x0
history_hostname = ""
history_internal_str = "pool version 5000; software version zfs-2.2.7-0-ge269af1b3; uts 14.3-RELEASE 1403000 amd64"
history_internal_name = "open"
history_txg = 0x2d65
history_time = 0x6946b6cf
time = 0x6946b6cf 0x29dd0364
eid = 0x1
...
А з zpool history можна подивитись всі команди, які запускались:
root@setevoy-nas:/home/setevoy # zfs-stats -E
------------------------------------------------------------------------
ZFS Subsystem Report Sun Dec 21 18:07:59 2025
------------------------------------------------------------------------
ARC Efficiency: 104.72 k
Cache Hit Ratio: 99.87% 104.58 k
Cache Miss Ratio: 0.13% 137
Actual Hit Ratio: 99.87% 104.58 k
Data Demand Efficiency: 100.00% 0
CACHE HITS BY CACHE LIST:
Most Recently Used: 23.21% 24.28 k
Most Frequently Used: 76.79% 80.30 k
Most Recently Used Ghost: 0.00% 0
Most Frequently Used Ghost: 0.00% 0
CACHE HITS BY DATA TYPE:
Demand Data: 0.00% 0
Prefetch Data: 0.00% 0
Demand Metadata: 99.96% 104.54 k
Prefetch Metadata: 0.04% 39
CACHE MISSES BY DATA TYPE:
Demand Data: 0.00% 0
Prefetch Data: 0.00% 0
Demand Metadata: 91.24% 125
Prefetch Metadata: 8.76% 12
Або використати zfs-mon:
Ну і по моніторингу ZFS цього, мабуть, вистачить.
Ще окремо будемо говорити вже про повноцінний моніторинг системи – планую з VictoriaMetrics, і тоді можна буде додати якийсь експортер для ZFS, наприклад zfs_exporter.