![]() Now that we have Terraform code ready to deploy an AWS Elastic Kubernetes Service cluster (see Terraform: Building EKS, part 1 – VPC, Subnets and Endpoints and subsequent parts), it’s time to think about automation, that is, creating pipelines in CI/CD that would create new environments for testing features, or deploy updates to the Dev/Prod environment of Kubernetes.
Now that we have Terraform code ready to deploy an AWS Elastic Kubernetes Service cluster (see Terraform: Building EKS, part 1 – VPC, Subnets and Endpoints and subsequent parts), it’s time to think about automation, that is, creating pipelines in CI/CD that would create new environments for testing features, or deploy updates to the Dev/Prod environment of Kubernetes.
And here we will talk again about managing Dev/Prod environments with Terraform.
In previous posts, I went through the options with Terraform Workspaces, Git branches, and directory separation (see Terraform: planning a new project with Dev/Prod environments and Terraform: dynamic remote state with AWS S3 and multiple environments by directory), but while writing the Terraform code, I thought about how it is usually done with Helm charts: all the chart’s code is stored in the root of the repository or a separate directory, and the values for Dev/Prod are passed from different values.yaml files.
So why not try a similar approach with Terraform?
In any case, what is described in this post should not be taken as an example of “this is how it has to be done”: here I am experimenting and trying out the capabilities of GitHub Actions and Terraform. And we’ll see what form it will take in production.
However, it turned out to be quite interesting.
Contents
Terraform Dev/Prod – Helm-like “flat” approach
So, the configuration for Terraform can be as follows:
- authentication and authorization are done locally with the
AWS_PROFILEvariable with an IAM ROle and AssumeRole, and in GitHub Actions – through OIDC and AssumeRole, so we can have different parameters for AWS Provider for Dev and Prod environments - all Terraform code is stored in the root of the repository
tfvarsfor Dev/Prod in separate directoriesenvs/devтаenvs/prod- we describe the common parameters of the
backendin thebackend.hclfile, and pass the keys and the Dynamo table through-backend-config
And the development and deployment flow is like this:
- branch from the master branch
- make changes to the code, test it locally or via GitHub Actions, and pass the necessary parameters via
-var(env name, some versions, etc.) - when we finish development and testing, we push it to the repository and make a Pull Request
- when creating a Pull Request, we can specify a special label, and then GitHub Actions perform a deployment to a feature-env, that is, a temporary infrastructure is created in AWS
- after the Pull Request is merged, we can additionally deploy to the Dev environment to check that the changes between the old version and the new one work (a kind of staging environment)
- if you need to deploy on the Production – create a Git Release
- manually or automatically trigger GitHub Actions to deploy with this release
- …
- profit!
What about Terragrunt?
Of course, we could just use Terragrunt to manage environments and backends, but I’m not sure what kind of infrastructure management model we’ll have with Terraform in our project: if it’s going to be done exclusively by the DevOps team, we’ll probably use Terragrunt. If the developers also get involved and want to manage something themselves, then perhaps we will use a solution like Atlantis or Gaia.
So while it’s all just beginning, we’re making everything as simple and “vanilla” Terraform as possible, and then we’ll see what’s best.
Terraform layout for multiple environments
After finishing the setup, described in parts 1-4 of the Terraform: Building EKS series, the structure of files and directories looks like this – in environments/dev all the code for Dev, in environments/prod all the code for Prod (so far empty):
$ tree terraform/
terraform/
└── environments
├── dev
│ ├── backend.tf
│ ├── configs
│ │ └── karpenter-provisioner.yaml.tmpl
│ ├── controllers.tf
│ ├── eks.tf
│ ├── iam.tf
│ ├── karpenter.tf
│ ├── main.tf
│ ├── outputs.tf
│ ├── providers.tf
│ ├── terraform.tfvars
│ ├── variables.tf
│ └── vpc.tf
└── prod
However, since we don’t use modules here, the code is very duplicated, and it will be difficult to manage and, as they say, “error-prone”.
We could create modules, but then there would be modules within modules, because the entire EKS stack is created through modules – VPC, EKS, Subnets, IAM, etc., and I don’t want to complicate the code by putting it into modules yet, because again, we’ll see how the processes go. While this is all at the very beginning, we can quickly rework it in a way that will be better later, depending on which model and environment management system we choose.
So what do we need to do?
- transfer the
.tffiles to the root of theterraformdirectory - update the
providers.tffile – removeassume_rolefrom it and remove--profileinargsof Kubernetes, Helm and kubectl providers - create a
backend.hclfile for common-configuration - in the
backend.tffile leave only thebackend "s3"block environmentsrename to вenvs- inside there will be directories
devandprodwhereterraform.tfvarsfor each env will be stored
- inside there will be directories
Providers
providers.tf now looks like this:
provider "aws" {
region = var.aws_region
assume_role {
role_arn = "arn:aws:iam::492***148:role/tf-admin"
}
default_tags {
tags = {
component = var.component
created-by = "terraform"
environment = var.environment
}
}
}
Remove the assume_role from it:
provider "aws" {
region = var.aws_region
default_tags {
tags = {
component = var.component
created-by = "terraform"
environment = var.environment
}
}
}
In other providers – Kubernetes, Helm, and Kubectl – remove args in --profile:
...
provider "kubernetes" {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
...
Versions
Put the versions in a separate file vesrions.tf:
terraform {
required_version = "~> 1.5"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.14"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = "~> 2.23"
}
helm = {
source = "hashicorp/helm"
version = "~> 2.11"
}
kubectl = {
source = "gavinbunney/kubectl"
version = "~> 1.14"
}
}
}
Move the files, and now the structure looks like this:
$ tree . ├── backend.tf ├── configs │ └── karpenter-provisioner.yaml.tmpl ├── controllers.tf ├── eks.tf ├── iam.tf ├── karpenter.tf ├── main.tf ├── outputs.tf ├── providers.tf ├── variables.tf ├── envs │ ├── dev │ │ └── dev.tfvars │ └── prod ├── versions.tf └── vpc.tf
Backend
Create the backend.hcl file in the root:
bucket = "tf-state-backend-atlas-eks" region = "us-east-1" dynamodb_table = "tf-state-lock-atlas-eks" encrypt = true
In the backend.tf file, leave only s3:
terraform {
backend "s3" {}
}
Okay, all set? Let’s test it.
Testing with terraform init && plan for different environments
We have an AWS Profile in ~/.aws/config:
[profile work] region = us-east-1 output = json [profile tf-assume] role_arn = arn:aws:iam::492***148:role/tf-admin source_profile = work
Check the existing key in an AWS S3 bucket, since we already have a deployed Dev:
$ aws s3 ls tf-state-backend-atlas-eks/dev/ 2023-09-14 15:49:15 450817 atlas-eks.tfstate
Set the AWS_PROFILE variable, and try terraform init with the backend-config:
$ export AWS_PROFILE=tf-admin $ terraform init -backend-config=backend.hcl -backend-config="key=dev/atlas-eks.tfstate" Initializing the backend... Successfully configured the backend "s3"! Terraform will automatically ... Terraform has been successfully initialized!
Looks like everything is OK – the modules loaded, and the existing state file was found.
Try terraform plan – nothing has changed in the code, so nothing should change in AWS:
$ terraform plan -var-file=envs/dev/dev.tfvars
...
Terraform will perform the following actions:
# helm_release.karpenter will be updated in-place
~ resource "helm_release" "karpenter" {
id = "karpenter"
name = "karpenter"
~ repository_password = (sensitive value)
# (28 unchanged attributes hidden)
# (6 unchanged blocks hidden)
}
Plan: 0 to add, 1 to change, 0 to destroy.
...
Nice! It will only change the password for AWS ECR, which is OK because there is a changing token.
Let’s try to do the same thing, but for Prod – copy the file dev.tfvars as prod.tfvars into the directory envs/prod, change the data in it – only VPC CIDR and environment:
project_name = "atlas-eks"
environment = "prod"
component = "devops"
eks_version = "1.27"
vpc_params = {
vpc_cidr = "10.2.0.0/16"
enable_nat_gateway = true
...
And try a new terraform init with the -reconfigure, because we do it all locally. In the backend-config, pass a new key for the state file in S3:
$ terraform init -reconfigure -backend-config=backend.hcl -backend-config="key=prod/atlas-eks.tfstate" Initializing the backend... Successfully configured the backend "s3"! Terraform will automatically ... Terraform has been successfully initialized!
Check with terraform plan:
$ terraform plan -var-file=envs/prod/prod.tfvars ... Plan: 109 to add, 0 to change, 0 to destroy. ...
Good! He’s going to create a bunch of new resources because Prod hasn’t deployed it yet, so everything is as planned.
For feature-envs, everything is the same, only in the -var we’ll pass another environment and in the backend-config we’ll set a new key by the name of the env:
$ terraform init -reconfigure -backend-config=backend.hcl -backend-config="key=feat111/atlas-eks.tfstate" -var="environment=feat111" ...
For the plan and apply we’ll use the parameters from the file dev.tfvars, because feature-envs are more or less ~= to the Dev-environment:
$ terraform plan -var-file=envs/dev/dev.tfvars -var="environment=feat111" ...
If you need to set, for example, a new VPC, we have an object that contains the string vpc_cidr:
...
variable "vpc_params" {
description = "AWS VPC for the EKS cluster parameters. Note, that this VPC will be environment-wide used, e.g. all Dev/Prod AWS resources must be placed here"
type = object({
vpc_cidr = string
enable_nat_gateway = bool
one_nat_gateway_per_az = bool
single_nat_gateway = bool
enable_vpn_gateway = bool
enable_flow_log = bool
})
}
...
So we pass it as -var='vpc_params={vpc_cidr="10.3.0.0/16"}'. But in this case, you need to pass all the values of the vpc_params object, that is:
$ terraform plan -var-file=envs/dev/dev.tfvars -var="environment=feat111" \
> -var='vpc_params={vpc_cidr="10.3.0.0/16",enable_nat_gateway=true,one_nat_gateway_per_az=true,single_nat_gateway=false,enable_vpn_gateway=false,enable_flow_log=false}'
Or set default values in the variables.tf.
Okay, that’s done, now we can move on to GitHub Actions.
Authorization and authentication – OIDC and IAM
To access AWS from GitHub Actions, we are using OpenID Connect – here, GitHub acts as an Identity Provider (IDP) and AWS as a Service Provider (SP), i.e. we authenticate on GitHub, and then GitHub “passes” our user to an AWS account, saying that “this is really John Smith”, and AWS performs the “authorization“, that is, AWS checks whether this John Smith can create new resources.
To authorize to AWS from Terraform, we’ll pass an IAM Role and IAM Role Assume, and on behalf of this Role and the IAM Policy connected to it, we’ll authorize.
To be able to perform the AsuumeRole of this role using GitHub Identity Provider, we’ll need to change its Trusted Policy, because now it allows AssumeRole only for users with an AWS account:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::492***148:root"
},
"Action": "sts:AssumeRole"
}
]
}
Documentation – Configuring the role and trust policy.
Add the token.actions.githubusercontent.com IDP from our AWS AIM:

{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccountAllow",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::492***148:root"
},
"Action": "sts:AssumeRole"
},
{
"Sid": "GitHubAllow",
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::492***148:oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com"
}
}
}
]
}
GitHub Actions: recall the moment!
I already wrote about GitHub Actions in the Github: Github Actions overview and ArgoCD deployment example, but that was a long time ago, and I hardly ever used Actions myself, so let’s recall a bit what’s what there.
See also Understanding GitHub Actions.
So, in GitHub Actions we have:
eventsas triggers forjobs- in the
jobswe havestepswith one or moreactions actionsperform specific actions, andactionsof the samejobshould run on the same GitHub Actions Runner
 And for the Actions you can use ready-made libraries from the GitHub Actions Marketplace.
And for the Actions you can use ready-made libraries from the GitHub Actions Marketplace.
GitHub Environments
GitHub allows you to set up several environments for work, and each has its own set of Variables and Secrets. In addition, you can set up rules for them according to which deployments should take place. For example, you can allow deployments to Prod only from the master branch.
See Using environments for deployment.
So what can we do?
- Dev env with its own variables
- Prod env with its own variables
- and create feature events dynamically during deployment
GitHub Actions Reusable Workflow and Composite Actions
With Reusable Workflows, we can use an already described Workflow in another workflow, and with Composite Actions, we can create our own Action, which we will then include in the steps of our workflow files.
You can read more about the difference between them here – GitHub: Composite Actions vs Reusable Workflows [Updated 2013] and the excellent post Github Not-So-Reusable Actions, but in short:
- when you create a Workflow, you group several Jobs into a single file and use it only in Jobs, while Actions will have only steps that are grouped into a single Action, which can then be used only as a step
- Workflows cannot call other Workflows, while in Actions you can call other Actions
Alternatively, instead of Reusable Workflow, you can use Running a workflow based on the conclusion of another workflow – that is, triggering the launch of a workflow after the completion of another workflow.
Creating a test workflow for Terraform validate && lint
First, let’s create a minimal workflow to see how it all works.
See Quickstart for GitHub Actions, syntax documentation – Workflow syntax for GitHub Actions, and about permissions for our job – Assigning permissions to jobs.
For Terraform, we will use setup-terraform Action.
To log in to AWS – configure-aws-credentials Action.
Create a directory in the repository:
$ mkdir -p .github/workflows
And in it, create a workflow file – testing-terraform.yaml.
Since the Terraform code is located in the terraform directory, we’ll add defaults.run.working-directory and the on.push.paths condition to the workflow, i.e. trigger the build only if changes occurred in the terraform directory, see paths.
Let’s describe the flow:
name: Test Terraform changes
defaults:
run:
working-directory: terraform
on:
workflow_dispatch:
push:
paths:
- terraform/**
env:
ENVIRONMENT : "dev"
AWS_REGION : "us-east-1"
permissions:
id-token: write
contents: read
Here:
- in the
defaultswe set from which directory all steps will be executed - in the
on– conditions, by push and only for theterraformdirectory and additionallyworkflow_dispatchto be able to launch it manually - in the
env– the values of environment variables - in the
permissions– the permissions of the job to create a token.
In jobs, we’ll run the AssumeRole for AWS IAM, so let’s put it in the repository environment variables.
Go to Setting > Secrets and variables > Actions > Variables, and add a new variable:


Next, let’s think about what steps we need to perform in the job:
git checkout- login to AWS
terraform fmt -checkto check the “beauty of the code”(seefmt)terraform initwith the Dev environment – download modules and connect to the state backendterraform validateto check the code syntax (seevalidate)
Add a job with these steps, and now the file will look like this:
name: Test Terraform changes
defaults:
run:
working-directory: terraform
on:
workflow_dispatch:
push:
paths:
- terraform/**
env:
ENVIRONMENT : "dev"
AWS_REGION : "us-east-1"
permissions:
id-token: write
contents: read
jobs:
test-terraform:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: hashicorp/setup-terraform@v2
- name: Terraform fmt
run: terraform fmt -check
continue-on-error: true
- name: "Setup: Configure AWS credentials"
# this step adds `env.AWS_*` variables
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-assume: ${{ vars.TF_AWS_ROLE }}
role-session-name: github-actions-terraform
role-duration-seconds: 7200
aws-region: ${{ env.AWS_REGION }}
- name: Terraform Init
run: terraform init -backend-config=backend.hcl -backend-config="key=${{ env.ENVIRONMENT }}/atlas-eks.tfstate"
- name: Terraform Validate
run: terraform validate
Push the changes to the repository and run them manually because there were no changes to the Terraform code:

And we have our first build:

Note: for the button for manual dispatch (workflow_dispatch) to appear, changes in the workflow file must be merged with the repository’s default branch
GitHub Actions TFLint step
Now let’s add a step with the Terraform linter – TFLint.
First, let’s see how it works locally:
$ yay -S tflint
$ tflint
3 issue(s) found:
Warning: module "ebs_csi_irsa_role" should specify a version (terraform_module_version)
on iam.tf line 1:
1: module "ebs_csi_irsa_role" {
Reference: https://github.com/terraform-linters/tflint-ruleset-terraform/blob/v0.1.1/docs/rules/terraform_module_version.md
Warning: module "karpenter" should specify a version (terraform_module_version)
on karpenter.tf line 1:
1: module "karpenter" {
Reference: https://github.com/terraform-linters/tflint-ruleset-terraform/blob/v0.1.1/docs/rules/terraform_module_version.md
Good point – I forgot to add the module versions, need to fix it.
Next, add it to our workflow – use marketplace/actions/setup-tflint, the version is available on the TFLint release page:
...
- name: Setup TFLint
uses: terraform-linters/setup-tflint@v3
with:
tflint_version: v0.48.0
- name: Terraform lint
run: tflint -f compact
Run it, and we have a failed build:

Good.
Fix the problems and move on to the deployments.
Deployments planning with GitHub Actions
Now we can think about how to build a workflow.
What actions do we have in the GitHub repository, and what actions from Terraform might we need?
With GitHub:
- Push to any branch
- creating a Pull Request for merge to master
- closing Pull Request for merge to master
With Terraform:
- testing:
fmt,validate,lint - deploy:
planandapply. - destroy:
plananddestroy.
And how can we combine all this into different workflows?
- with Push – execute the test
- when creating a PR in the master with the “deploy” label – deploy feature-envs (test + deploy)
- when closing a PR, delete a feature-env (destroy)
- manually have the ability to:
- deploy any branch or release to Dev (test + deploy)
- deploy a release from the master build to Prod (test + deploy)
That is, it looks like five workflows, and almost all of them have repeating actions – the login, init, and test, so it makes sense to move them to separate “functions” – use Reusable Workflow or Composite Actions.
We can combine AWS Login and init, and additionally create a “function” for tests. In addition, we can add the “deploy” and “destroy” functions, and then use them in a “modular” way in our workflows:
- terraform-init:
- AWS Login
- terraform init
- test:
-
terraform validate
-
terraform fmt
-
tflint
-
- deploy:
- terraform plan
- terraform apply
- destroy:
- terraform plan
- terraform destroy
So if plan to have five separate workflows using GitHub Environments and “features”, then it will be:
- test-on-push:
- runs on a push event
- runs from the Dev environment, where we have variables for the Dev environment
- calls the “functions” terraform-init and test
- deploy-dev:
- run manually
- runs from the Dev environment, where we have variables for the Dev environment
- calls the “functions” terraform-init, test and deploy
- deploy-prod:
- run manually
- runs from the Prod environment, where we have variables for the Prod environment and protection rules
- calls the terraform-init, test and deploy “functions”
- deploy-feature-env:
- runs when creating a PR with the “deploy” label
- runs with a dynamic environment (the name is generated from the Pull Request ID and created during deployment)
- calls the terraform-init, test, and deploy “functions”
- deploy-feature-env:
- runs when closing the PR with the “deploy”
- runs with a dynamic environment (the name is generated from the Pull Request ID and during deploy the environment is selected from the existing ones)
- calls the “functions” terraform-init, test and destroy
How exactly do we do these “functions” – with Reusable Workflow or Composite Actions? In this case, there is probably no big difference because we will have one level of nesting, but there is a nuance with GitHub Runners: if you do the “terraform-init”, “test” and “deploy” tasks in different jobs (and Reusable Workflows should be only in jobs, moreover, these jobs cannot have other steps) – then they will most likely be run on different Runners, and in this case, to run terraform plan && apply && destroy we will have to run the step with AWS Login and terraform init several times.
Therefore, it seems more correct to run all tasks within a single job, that is, to create our “functions” using Composite Actions.
The only thing I won’t describe in this post is the deployment of feature envelopes because firstly, the post is already quite long and contains a lot of new (at least for me) information, and secondly, creating additional AWS EKS test clusters will be an exception and will be done by me, and I can do it without additional automation for now. However, I will most likely describe the creation of dynamic environments when I create a GitHub Actions Workflow for Helm chart deployments.
Okay, let’s try the Dev and Prod deployments.
Preparing deployments
Creating Actions secrets and variables
We will have a few variables that will be the same for all environments – AWS_REGION and TF_AWS_PROFILE, so we will set them at the level of the entire repository.
Go to the Settings – Actions secrets and variables > Variables, add Repository variables:

Creating GitHub Environments
Add two environments – Dev and Prod:


Similarly, for Prod.
Creating test-on-push Workflow
Creating Composite Action “terraform-init”
In the .github directory, add the actions directory, and in there create a terraform-init directory with the action.yaml file, in which we describe the Action itself.
See Creating a composite action.
In the inputs, we accept three parameters, which we will then pass from the Workflow:
name: "AWS Login and Terraform Init"
description: "Combining AWS Login && terraform init actions into one"
inputs:
environment:
type: string
required: true
region:
type: string
required: true
iam-role:
type: string
required: true
runs:
using: "composite"
steps:
- uses: hashicorp/setup-terraform@v2
- name: "Setup: Configure AWS credentials"
# this step adds `env.AWS_*` variables
uses: aws-actions/configure-aws-credentials@v2
with:
role-to-assume: ${{ inputs.iam-role }}
role-session-name: github-actions-terraform
role-duration-seconds: 7200
aws-region: ${{ inputs.region }}
- name: Terraform Init
run: terraform init -backend-config=backend.hcl -backend-config="key=${{ inputs.environment }}/atlas-eks.tfstate"
shell: bash
working-directory: terraform
There is a nuance here with working-directory, which in Composite Action must be set separately for each step because the Action itself in a Workflow runs in the root of the repository, and you can’t use defaults as you can do in workflows, although feature request has been around for a long time.
Creating Composite Action “test”
In the actions directory, create another directory – terraform-test with the action.yaml file, in which we describe the second Action:
name: "Test and verify Terraform code"
description: "Combining all test actions into one"
inputs:
environment:
type: string
required: true
region:
type: string
required: true
iam-role:
type: string
required: true
runs:
using: "composite"
steps:
- uses: hashicorp/setup-terraform@v2
- name: Terraform Validate
run: terraform validate
shell: bash
working-directory: terraform
- name: Terraform fmt
run: terraform fmt -check
shell: bash
working-directory: terraform
continue-on-error: false
- name: Setup TFLint
uses: terraform-linters/setup-tflint@v3
with:
tflint_version: v0.48.0
- name: Terraform lint
run: tflint -f compact
shell: bash
working-directory: terraform
Creating workflow
Next, in the .github/workflows directory, create a test-on-push.yaml file with the new flow:
name: Test Terraform code
on:
workflow_dispatch:
push:
paths:
- terraform/**
permissions:
id-token: write
contents: read
jobs:
test-terraform:
environment: 'dev'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: 'Setup: AWS Login and Terraform init'
uses: ./.github/actions/terraform-init
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
- name: 'Test: check and validate'
uses: ./.github/actions/terraform-test
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
In the job: test-terraform, we specify the use of the environment: 'dev' and its variables (we have one there – ENVIRONMENT=dev), and in the steps “AWS Login and Terraform init” and “Test and validate” we call our Actions files, which pass parameters with values from variables through with.
Push the changes to the repository, and we have our build:

We can move on to the deployment.
Creating a deploy-dev Workflow
So, what do we want?
- deploy to the Dev from a branch or tag
- manually deploy to the Prod from the release
Let’s start with the Dev-Deploy.
Creating Composite Action “deploy”
Create another directory for the new Action – actions/terraform-apply, in which we describe the Action itself in the file action.yaml:
name: "Plan and Apply Terraform code"
description: "Combining plan && apply actions into one"
inputs:
environment:
type: string
required: true
region:
type: string
required: true
iam-role:
type: string
required: true
runs:
using: "composite"
steps:
- uses: hashicorp/setup-terraform@v2
- name: Terraform plan
run: terraform plan -var-file=envs/${{ inputs.environment }}/${{ inputs.environment }}.tfvars
shell: bash
working-directory: terraform
- name: Terraform apply
run: terraform apply -var-file=envs/${{ inputs.environment }}/${{ inputs.environment }}.tfvars -auto-approve
shell: bash
working-directory: terraform
Creating Workflow
Add a new workflow file – deploy-dev.yaml:
name: Deploy Dev environment
concurrency:
group: deploy-${{ vars.ENVIRONMENT }}
cancel-in-progress: false
on:
workflow_dispatch:
push:
paths:
- terraform/**
permissions:
id-token: write
contents: read
jobs:
deploy-to-dev:
environment: dev
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: 'Setup: AWS Login and Terraform init'
uses: ./.github/actions/terraform-init
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
- name: 'Test: check and validate'
uses: ./.github/actions/terraform-test
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
- name: 'Deploy: to ${{ vars.ENVIRONMENT }}'
uses: ./.github/actions/terraform-apply
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
In the on.workflow_dispatch conditions we can add more inputs, see on.workflow_dispatch.inputs.
For all the events that can trigger workflows, see Events that trigger workflows.
In the concurrency we set the condition “queue, not execute in parallel, if another job is running that uses the same concurrency.group“, see Using concurrency.
That is, if we do a check on group: deploy-${{ vars.ENVIRONMENT }}, then if you run a deploy on Prod after starting Dev, it will wait until the Dev deploy is complete:

Push the changes, merge to the master so that the “Run workflow” button appears, and check it out:

And after the deployment:

Creating a deploy-prod Workflow and protecting against accidental launch
We already have Composite Action, so there’s no need to create it.
Basically, everything here is similar to the Dev deployments – concurrency, manual launch, jobs, the only thing is that there should be a different launch condition – by tags instead of brunches and tags.
That is, we can deploy any brunch or tag to Dev, and only a tag to Prod.
In general, I’m trying to avoid automatic deployment here because it’s the infrastructure and in our project, we still have work in progress, although if we had GitHub Enterprise, we could use Deployment protection rules and Required reviewers in them, and use release creation in the on condition to trigger the workflow deployment to the Product:
on:
release:
types: [published]
That is, deploy to Prod only when a new GitHub Release is created, and only after, for example, a deploy is committed by someone from the DevOps team.
Another option to ensure the security of the Prod environment deployments is to allow merge to master only from Code Owners in the Branch protection rules:

And describe Code Owners in the file CODEOWNERS, and allow deployment to the Prod only from the master branch:

But here I want to use a flow with deployments only from releases or tags to have something like versioning.
So the only option is to use the if condition in the job itself, see Using conditions to control job execution:
...
jobs:
deploy-to-prod:
if: github.ref_type == 'tag'
environment: prod
...
And you can combine conditions, for example, to additionally check who exactly is triggering the deploy using the github.actor or github.triggering_actor and allow only certain users. See all types in the github context.
As an additional protection against accidental launch, you can add an input, to which you must explicitly specify “yes“:
...
on:
workflow_dispatch:
inputs:
confirm-deploy:
type: boolean
required: true
description: "Set to confirm deploy to the PRODUCTION environment"
...
And then check both conditions in the if condition – the github.ref_type and github.event.inputs.confirm-deploy.
So, for now, the workflow for the Prod will be like this:
name: Deploy Prod environment
concurrency:
group: deploy-${{ vars.ENVIRONMENT }}
cancel-in-progress: false
on:
workflow_dispatch:
inputs:
confirm-deploy:
type: boolean
required: true
description: "Set to confirm deploy to the PRODUCTION environment"
permissions:
id-token: write
contents: read
jobs:
deploy-to-prod:
if: ${{ github.ref_type == 'tag' && github.event.inputs.confirm-deploy == 'true' }}
environment: prod
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: 'Setup: AWS Login and Terraform init'
uses: ./.github/actions/terraform-init
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
- name: 'Test: check and validate'
uses: ./.github/actions/terraform-test
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
- name: 'Deploy: to ${{ vars.ENVIRONMENT }}'
uses: ./.github/actions/terraform-apply
with:
environment: ${{ vars.ENVIRONMENT }}
region: ${{ vars.AWS_REGION }}
iam-role: ${{ vars.TF_AWS_ROLE }}
And when deploying, you need to first select the tag, not a branch, and secondly, check the “Confirm” box:
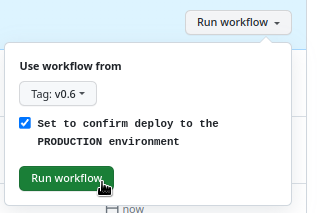
We’ll see how it goes as we go along.
And that’s all for now.
In general, GitHub Actions has done a lot of things, and when I started making this deploys, I didn’t expect so many interesting features.
So there will be more to come.
A couple of things in addition, to be finalized later:
- The
setup-terraformaction accepts theterraform_versioninput, but cannot do it from a versions file; for now, the option is to do it with an additionalstep, see this comment - in
jobsit makes sense to add thetimeout-minutesparameter so that jobs do not hang for a long time in case of problems and do not exhaust Runners time
![]()