 We have a PHP application running with Kubernetes in pods with two dedicated containers – NGINX и PHP-FPM.
We have a PHP application running with Kubernetes in pods with two dedicated containers – NGINX и PHP-FPM.
The problem is that during downscaling clients get 502 errors. E.g. when a pod is stopping, its containers can not correctly close existing connections.
So, in this post, we will take a closer look at the pods’ termination process in general, and NGINX and PHP-FPM containers in particular.
Testing will be performed on the AWS Elastic Kubernetes Service by the Yandex.Tank utility.
Ingress resource will create an AWS Application Load Balancer with the AWS ALB Ingress Controller.
Для управления контейнерами на Kubernetes WorkerNodes испольузется Docker.
Contents
Pod Lifecycle – Termination of Pods
So, let’s take an overview of the pods’ stopping and termination process.
Basically, a pod is a set of processes running on a Kubernetes WorkerNode, which are stopped by standard IPC (Inter-Process Communication) signals.
To give the pod the ability to finish all its operations, a container runtime at first ties softly stop it (graceful shutdown) by sending a SIGTERM signal to a PID 1 in each container of this pod (see docker stop). Also, a cluster starts counting a grace period before force kill this pod by sending a SIGKILL signal.
The SIGTERM can be overridden by using the STOPSIGNAL in an image used to spin up a container.
Thus, the whole flow of the pod’s deleting is (actually, the part below is a kinda copy of the official documentation):
- a user issues a
kubectl delete podorkubectl scale deploymentcommand which triggers the flow and the cluster start countdown of the grace period with the default value set to the 30 second - the API server of the cluster updates the pod’s status – from the Running state, it becomes the Terminating (see Container states). A
kubeleton the WorkerNode where this pod is running, receives this status update and start the pod’s termination process:- if a container(s) in the pod have a
preStophook –kubeletwill run it. If the hook is still running the default 30 seconds on the grace period – another 2 seconds will be added. The grace period can be set with theterminationGracePeriodSeconds - when a
preStophook is finished, akubeletwill send a notification to the Docker runtime to stop containers related to the pod. The Docker daemon will send theSIGTERMsignal to a process with the PID 1 in each container. Containers will get the signal in random order.
- if a container(s) in the pod have a
- simultaneously with the beginning of the graceful shutdown – Kubernetes Control Plane (its
kube-controller-manager) will remove the pod from the endpoints (see Kubernetes – Endpoints) and a corresponding Service will stop sending traffic to this pod - after the grace period countdown is finished, a
kubeletwill start force shutdown – Docker will send theSIGKILLsignal to all remaining processes in all containers of the pod which can not be ignored and those process will be immediately terminated without change to correctly finish their operations kubelettriggers deletion of the pod from the API server- API server deletes a record about this pod from the
etcd
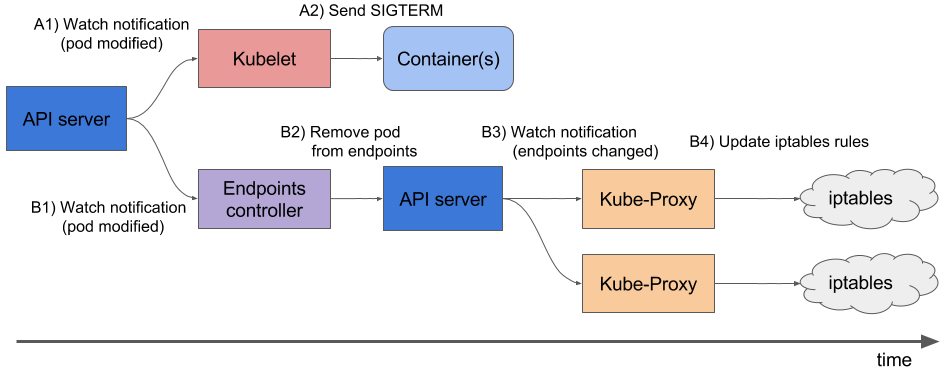
Actually, there are two issues:
- the NGINX and PHP-FPM perceives the
SIGTERMsignal as a force как “brutal murder” and will finish their processes immediately , и завершают работу немедленно, without concern about existing connections (see Controlling nginx and php-fpm(8) – Linux man page) - the 2 and 3 steps – sending the
SIGTERMand an endpoint deletion – are performed at the same time. Still, an Ingress Service will update its data about endpoints not momentarily and a pod can be killed before then an Ingress will stop sending traffic to it causing 502 error for clients as the pod can not accept new connections
E.g. if we have a connection to an NGINX server, the NGINX master process during the fast shutdown will just drop this connection and our client will receive the 502 error, see the Avoiding dropped connections in nginx containers with “STOPSIGNAL SIGQUIT”.
NGINX STOPSIGNAL and 502
Okay, now we got some understanding of how it’s going – let’s try to reproduce the first issue with NGINX.
The example below is taken from the post above and will be deployed to a Kubernetes cluster.
Prepare a Dockerfile:
FROM nginx
RUN echo 'server {\n\
listen 80 default_server;\n\
location / {\n\
proxy_pass http://httpbin.org/delay/10;\n\
}\n\
}' > /etc/nginx/conf.d/default.conf
CMD ["nginx", "-g", "daemon off;"]
Here NGINX will proxy_pass a request to the http://httpbin.org which will respond with a 10 seconds delay to emulate a PHP-backend.
Build an image and push it to a repository:
[simterm]
$ docker build -t setevoy/nginx-sigterm . $ docker push setevoy/nginx-sigterm
[/simterm]
Now, add a Deployment manifest to spin up 10 pods from this image.
Here is the full file with a Namespace, Service, and Ingress, in the following part of this post, will add only updated parts of the manifest:
---
apiVersion: v1
kind: Namespace
metadata:
name: test-namespace
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
namespace: test-namespace
labels:
app: test
spec:
replicas: 10
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: web
image: setevoy/nginx-sigterm
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 100Mi
readinessProbe:
tcpSocket:
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: test-svc
namespace: test-namespace
spec:
type: NodePort
selector:
app: test
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
namespace: test-namespace
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
spec:
rules:
- http:
paths:
- backend:
serviceName: test-svc
servicePort: 80
Deploy it:
[simterm]
$ kubectl apply -f test-deployment.yaml namespace/test-namespace created deployment.apps/test-deployment created service/test-svc created ingress.extensions/test-ingress created
[/simterm]
Check the Ingress:
[simterm]
$ curl -I aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com HTTP/1.1 200 OK
[/simterm]
And we have 10 pods running:
[simterm]
$ kubectl -n test-namespace get pod NAME READY STATUS RESTARTS AGE test-deployment-ccb7ff8b6-2d6gn 1/1 Running 0 26s test-deployment-ccb7ff8b6-4scxc 1/1 Running 0 35s test-deployment-ccb7ff8b6-8b2cj 1/1 Running 0 35s test-deployment-ccb7ff8b6-bvzgz 1/1 Running 0 35s test-deployment-ccb7ff8b6-db6jj 1/1 Running 0 35s test-deployment-ccb7ff8b6-h9zsm 1/1 Running 0 20s test-deployment-ccb7ff8b6-n5rhz 1/1 Running 0 23s test-deployment-ccb7ff8b6-smpjd 1/1 Running 0 23s test-deployment-ccb7ff8b6-x5dc2 1/1 Running 0 35s test-deployment-ccb7ff8b6-zlqxs 1/1 Running 0 25s
[/simterm]
Prepare a load.yaml for the Yandex.Tank:
phantom:
address: aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com
header_http: "1.1"
headers:
- "[Host: aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com]"
uris:
- /
load_profile:
load_type: rps
schedule: const(100,30m)
ssl: false
console:
enabled: true
telegraf:
enabled: false
package: yandextank.plugins.Telegraf
config: monitoring.xml
Here, we will perform 1 request per second to pods behind our Ingress.
Run tests:
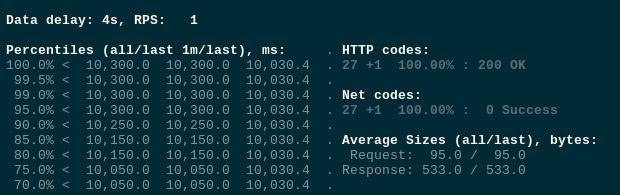
All good so far.
Now, scale down the Deployment to only one pod:
[simterm]
$ kubectl -n test-namespace scale deploy test-deployment --replicas=1 deployment.apps/test-deployment scaled
[/simterm]
Pods became Terminating:
[simterm]
$ kubectl -n test-namespace get pod NAME READY STATUS RESTARTS AGE test-deployment-647ddf455-67gv8 1/1 Terminating 0 4m15s test-deployment-647ddf455-6wmcq 1/1 Terminating 0 4m15s test-deployment-647ddf455-cjvj6 1/1 Terminating 0 4m15s test-deployment-647ddf455-dh7pc 1/1 Terminating 0 4m15s test-deployment-647ddf455-dvh7g 1/1 Terminating 0 4m15s test-deployment-647ddf455-gpwc6 1/1 Terminating 0 4m15s test-deployment-647ddf455-nbgkn 1/1 Terminating 0 4m15s test-deployment-647ddf455-tm27p 1/1 Running 0 26m ...
[/simterm]
And we got our 502 errors:
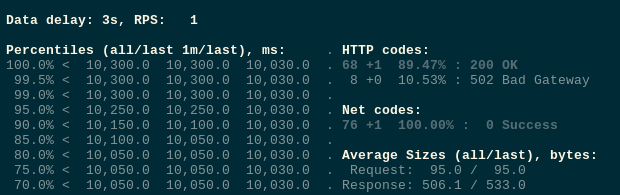
Next, update the Dockerfile – add the STOPSIGNAL SIGQUIT:
FROM nginx
RUN echo 'server {\n\
listen 80 default_server;\n\
location / {\n\
proxy_pass http://httpbin.org/delay/10;\n\
}\n\
}' > /etc/nginx/conf.d/default.conf
STOPSIGNAL SIGQUIT
CMD ["nginx", "-g", "daemon off;"]
Build, push:
[simterm]
$ docker build -t setevoy/nginx-sigquit . $ docker push setevoy/nginx-sigquit
[/simterm]
Update the Deployment with the new image:
...
spec:
containers:
- name: web
image: setevoy/nginx-sigquit
ports:
- containerPort: 80
...
Redeploy, and check again.
Run tests:
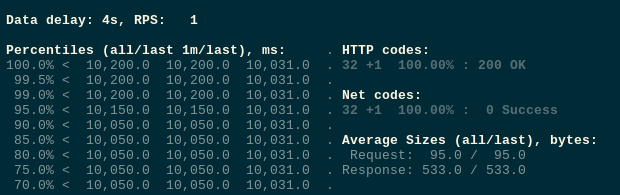
Scale down the deployment again:
[simterm]
$ kubectl -n test-namespace scale deploy test-deployment --replicas=1 deployment.apps/test-deployment scaled
[/simterm]
And no errors this time:

Great!
Traffic, preStop, and sleep
But still, if repeat tests few times we still can get some 502 errors:
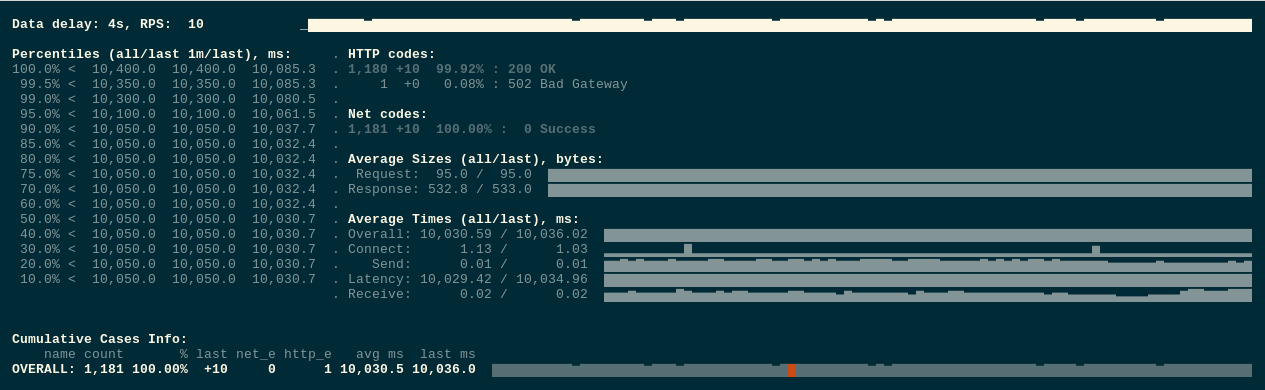
This time most likely we are facing the second issue – endpoints update is performed at the same time when the SIGTERM Is sent.
Let’s add a preStop hook with the sleep to give some time to update endpoints and our Ingress, so after the cluster will receive a request to stop a pod, a kubelet on a WorkerNode will wait for 5 seconds before sending the SIGTERM:
...
spec:
containers:
- name: web
image: setevoy/nginx-sigquit
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: ["/bin/sleep","5"]
...
Repeat tests – and now everything is fine
Our PHP-FPM had no such issue as its image was initially built with the STOPSIGNAL SIGQUIT.
Other possible solutions
And of course, during debugging I’ve tried some other approaches to mitigate the issue.
See links at the end of this post and here I’ll describe them in short terms.
preStop and nginx -s quit
One of the solutions was to add a preStop hook which will send QUIT to NGINX:
lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
Or:
...
lifecycle:
preStop:
exec:
command:
- /bin/sh
- -SIGQUIT
- 1
....
But it didn’t help. Not sure why as the idea seems to be correct – instead of waiting for the TERM from Kubernetes/Docker – we gracefully stopping the NGINX master process by sending QUIT.
You can also run the strace utility check which signal is really received by the NGINX.
NGINX + PHP-FPM, supervisord, and stopsignal
Our application is running in two containers in one pod, but during the debugging, I’ve also tried to use a single container with both NGINX and PHP-FPM, for example, trafex/alpine-nginx-php7.
There I’ve tried to add to stopsignal to the supervisor.conf for both NGINX and PHP-FPM with the QUIT value, but this also didn’t help although the idea also seems to be correct.
Still, one can try this way.
PHP-FPM, and process_control_timeout
In the Graceful shutdown in Kubernetes is not always trivial and on the Stackoveflow in the Nginx / PHP FPM graceful stop (SIGQUIT): not so graceful question is a note that FPM’s master process is killed before its child and this can lead to the 502 as well.
Not our current case, but pay your attention to the process_control_timeout.
NGINX, HTTP, and keep-alive session
Also, it can be a good idea to use the [Connection: close] header – then the client will close its connection right after a request is finished and this can decrease 502 errors count.
But anyway they will persist if NGINX will get the SIGTERM during processing a request.
See the HTTP persistent connection.
Useful links
- Graceful shutdown in Kubernetes is not always trivial (перевод на Хабре)
- Gracefully Shutting Down Pods in a Kubernetes Cluster – the
nginx -s quitin thepreStopsolution, also there is a good description of the issue with the traffic being sent to terminated pods - Kubernetes best practices: terminating with grace
- Termination of Pods
- Kubernetes’ dirty endpoint secret and Ingress
- Avoiding dropped connections in nginx containers with “STOPSIGNAL SIGQUIT” – actually, here I’ve found our solution plus an idea of how to reproduce it
![]()