
We have an API service with Gunicorn in Kubernetes that periodically returns 502, 503, 504 errors.
I started debugging it, and found a weird thing: there were no messages in the logs about the received SIGTERM, so I first went to deal with Kubernetes – why doesn’t it send it?
Contents
The Issue
So, here’s what it looks like.
We have a Kubernetes Pod:
$ kk get pod NAME READY STATUS RESTARTS AGE fastapi-app-89d8c77bc-8qwl7 1/1 Running 0 38m
Read its logs:
$ ktail fastapi-app-59554cddc5-lgj42 ==> Attached to container [fastapi-app-59554cddc5-lgj42:fastapi-app]
Kill it:
$ kk delete pod -l app=fastapi-app pod "fastapi-app-6cb6b46c4b-pffs2" deleted
And what do we see in his logs? Nothing!
... fastapi-app-6cb6b46c4b-9wqpf:fastapi-app [2024-06-22 11:13:27 +0000] [9] [INFO] Application startup complete. ==> Container left (terminated) [fastapi-app-6cb6b46c4b-pffs2:fastapi-app] ==> New container [fastapi-app-6cb6b46c4b-9qtvb:fastapi-app] ==> New container [fastapi-app-6cb6b46c4b-9qtvb:fastapi-app] fastapi-app-6cb6b46c4b-9qtvb:fastapi-app [2024-06-22 11:14:15 +0000] [8] [INFO] Starting gunicorn 22.0.0 ... fastapi-app-6cb6b46c4b-9qtvb:fastapi-app [2024-06-22 11:14:16 +0000] [9] [INFO] Application startup complete.
Here:
- the service has started – “Application startup complete“
- the pod die – “Container left“
- a new Pod is started – “New container” and “Starting gunicorn“
And here is how it should look like in a normal case:
... fastapi-app-59554cddc5-v7xq9:fastapi-app [2024-06-22 11:09:54 +0000] [8] [INFO] Waiting for application shutdown. fastapi-app-59554cddc5-v7xq9:fastapi-app [2024-06-22 11:09:54 +0000] [8] [INFO] Application shutdown complete. fastapi-app-59554cddc5-v7xq9:fastapi-app [2024-06-22 11:09:54 +0000] [8] [INFO] Finished server process [8] fastapi-app-59554cddc5-v7xq9:fastapi-app [2024-06-22 11:09:54 +0000] [1] [ERROR] Worker (pid:8) was sent SIGTERM! fastapi-app-59554cddc5-v7xq9:fastapi-app [2024-06-22 11:09:54 +0000] [1] [INFO] Shutting down: Master ==> Container left (terminated) [fastapi-app-59554cddc5-v7xq9:fastapi-app]
That is, here Gunicorn receives a SIGTERM, and correctly finishes its work.
What the hell?
Let’s look into it.
Kubernetes and the Pod termination process
How does the process of stopping a Pod works?
I wrote more about it in Kubernetes: NGINX/PHP-FPM graceful shutdown – getting rid of 502 errors, here is a very short summary:
- we run
kubectl delete pod - the
kubeleton the corresponding WorkerNode receives a command from the API server to stop the Pod - the
kubeletsends theSIGTERMsignal to the process with PID 1 in the container of the Pod, that is, the first process that was started when the container was created - if the container did not stop within the
terminationGracePeriodSeconds– then theSIGKILLis sent
That is, our Gunicorn process should receive the SIGTERM, write it to the log, and start stopping its worker.
Instead, it receives nothing and just dies.
Why?
PID 1 and SIGTERM in containers
Let’s check what do we have in processes of the container of this Pod:
root@fastapi-app-6cb6b46c4b-9qtvb:/app# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 2576 948 ? Ss 11:14 0:00 /bin/sh -c gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app root 8 0.0 1.3 31360 27192 ? S 11:14 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app root 9 0.2 2.4 287668 49208 ? Sl 11:14 0:04 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
And we see that here is PID 1 is the /bin/sh process, which runs gunicorn through -c.
Now let’s run strace in the Pod to see what signals it receives:
root@fastapi-app-6cb6b46c4b-9pd7r:/app# strace -p 1 strace: Process 1 attached wait4(-1,
Run kubectl delete pod – but add time to measure the time it takes to execute the command:
$ time kk delete pod fastapi-app-6cb6b46c4b-9pd7r pod "fastapi-app-6cb6b46c4b-9pd7r" deleted real 0m32.222s
32 seconds…
What’s in the strace?
root@fastapi-app-6cb6b46c4b-9pd7r:/app# strace -p 1
strace: Process 1 attached
wait4(-1, 0x7ffe7a390a3c, 0, NULL) = ? ERESTARTSYS (To be restarted if SA_RESTART is set)
--- SIGTERM {si_signo=SIGTERM, si_code=SI_USER, si_pid=0, si_uid=0} ---
wait4(-1, <unfinished ...>) = ?
command terminated with exit code 137
So, what was going on here?
- The
kubeletsent aSIGTERMsignal to the process with PID 1 – SIGTERM {si_signo=SIGTERM} – and the PID 1 would have to pass this signal to its children, stop them, and then terminate itself - but the process did not stopped – and
kubeletwaited the default 30 seconds to complete the process’ work correctly – see Pod phase - then
kubeletkilled the container, and the process ended with “terminated with exit code 137“
Usually, the 137 exit code is about OutOfMemory Killer, when a process is killed with SIGKILL, but in our case there was no OOMKill – just a SIGKILL sent because the processes in the Pod did not terminated on time.
Well, where did our SIGTERM go then?
Let’s run the signals directly from the container – first kill -s 15, the SIGTERM, then kill -s 9, the SIGKILL:
root@fastapi-app-6cb6b46c4b-r9fnq:/app# kill -s 15 1 root@fastapi-app-6cb6b46c4b-r9fnq:/app# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 2576 920 ? Ss 12:02 0:00 /bin/sh -c gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app root 7 0.0 1.4 31852 27644 ? S 12:02 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app ... root@fastapi-app-6cb6b46c4b-r9fnq:/app# kill -s 9 1 root@fastapi-app-6cb6b46c4b-r9fnq:/app# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.0 0.0 2576 920 ? Ss 12:02 0:00 /bin/sh -c gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app root 7 0.0 1.4 31852 27644 ? S 12:02 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
What? How? Why?
Why is SIGTERM ignored? And even more so SIGKILL, which should be a “non-ignored signal” – see man signal:
The signals SIGKILL and SIGSTOP cannot be caught, blocked, or ignored.
Linux kill(), and The PID 1
Because the PID 1 in Linux is a special process, because it is the first process to be launched by the system, and it must be protected from an “accidental kill”.
If we look at man kill, it is explicitly stated there, and it also talks about signal handlers to the process:
The only signals that can be sent to process ID 1, the init process, are those for which init has explicitly installed signal handlers. This is done to ensure the system is not brought down accidentally
You can check what handlers our process has – that is, what signals our process can intercept and process – from the file /proc/1/status:
root@fastapi-app-6cb6b46c4b-r9fnq:/app# cat /proc/1/status | grep SigCgt SigCgt: 0000000000010002
The SigCgt signals are the signals that the process can intercept and process itself. The rest will be either ignored or processed with the SIG_DFL handler, and the SIG_DFL handler ignores signals for PID 1, which does not have its own handler.
Let’s ask ChatGPT what exactly these signals are:

(you can actually translate it yourself if you are interested – see, for example How can I check what signals a process is listening to?, or How to read bitmask for the signals)
So here’s what do we have:
- a process
/bin/shwith PID 1 - the PID 1 is a special process
- checking PID 1 shows us that it “recognizes” the only
SIGHUPandSIGCHLDsignals - and both
SIGTERMandSIGKILLwill be ignored by it
But then how does the container stop?
Docker stop and Linux signals
The process of stopping a container in Docker (or Containerd) is no different than in Kubernetes, because in fact kubelet just passes commands to the container runtime. In AWS Kubernetes, this is now containerd.
But for the sake of simplicity, let’s do it locally with Docker.
So, we start the container from the same Docker image that we tested in Kubernetes:
$ docker run --name test-app 492***148.dkr.ecr.us-east-1.amazonaws.com/fastapi-app-test:entry-2 [2024-06-22 14:15:03 +0000] [7] [INFO] Starting gunicorn 22.0.0 [2024-06-22 14:15:03 +0000] [7] [INFO] Listening at: http://0.0.0.0:80 (7) [2024-06-22 14:15:03 +0000] [7] [INFO] Using worker: uvicorn.workers.UvicornWorker [2024-06-22 14:15:03 +0000] [8] [INFO] Booting worker with pid: 8 [2024-06-22 14:15:03 +0000] [8] [INFO] Started server process [8] [2024-06-22 14:15:03 +0000] [8] [INFO] Waiting for application startup. [2024-06-22 14:15:03 +0000] [8] [INFO] Application startup complete.
Try to stop it by sending SIGKILL to the PID 1 – nothing has changed, it ignores the signal:
$ docker exec -ti test-app sh -c "kill -9 1" $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 99bae6d55be2 492***148.dkr.ecr.us-east-1.amazonaws.com/fastapi-app-test:entry-2 "/bin/sh -c 'gunicor…" About a minute ago Up About a minute test-app
Try to stop it with docker stop and look at the time again:
$ time docker stop test-app test-app real 0m10.234s
And the status of the container:
$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES cab29916f6ba 492***148.dkr.ecr.us-east-1.amazonaws.com/fastapi-app-test:entry-2 "/bin/sh -c 'gunicor…" About a minute ago Exited (137) 52 seconds ago
The same code 137, that is, the container stopped with SIGKILL, and the time taken to stop the container was 10 seconds.
But what if the signal is sent to PID 1, which ignores it?
I didn’t find it in the documentation for the docker kill, but we can kill container processes in two ways:
- kill all child processes in the container itself – and then the parent (PID 1) will die itself
- kill the entire group of processes on the host through their SID (Session ID) – which again will lead to PID 1 ignoring the signal, but dying itself, because all its children have died
Let’s take another look at the processes in the container:
root@cddcaa561e1d:/app# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 2576 1408 ? Ss 15:58 0:00 /bin/sh -c gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
root 7 0.1 0.0 31356 26388 ? S 15:58 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
root 8 0.5 0.1 59628 47452 ? S 15:58 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
root@cddcaa561e1d:/app# pstree -a
sh -c gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
└─gunicorn /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
└─gunicorn /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
We can’t kill the PID 1 because it ignores us – but we can kill the PID 7!
Then it will kill PID 8 after itself, because it is its child process, and when the PID 1 finds out that there are no more of its children, it will die itself, and the container will stop:
root@cddcaa561e1d:/app# kill 7
And container logs:
... [2024-06-22 16:02:54 +0000] [7] [INFO] Handling signal: term [2024-06-22 16:02:54 +0000] [8] [INFO] Shutting down [2024-06-22 16:02:54 +0000] [8] [INFO] Error while closing socket [Errno 9] Bad file descriptor [2024-06-22 16:02:54 +0000] [8] [INFO] Waiting for application shutdown. [2024-06-22 16:02:54 +0000] [8] [INFO] Application shutdown complete. [2024-06-22 16:02:54 +0000] [8] [INFO] Finished server process [8] [2024-06-22 16:02:54 +0000] [7] [ERROR] Worker (pid:8) was sent SIGTERM! [2024-06-22 16:02:54 +0000] [7] [INFO] Shutting down: Master
But since Pods/containers die with the exit code 137, they were killed with SIGKILL, because when Docker or other container runtime cannot stop a process with PID 1 with SIGKILL, it sends SIGKILL to all processes in the container.
That is:
- first,
SIGTEMis sent to the PID 1 - after 10 seconds
SIGKILLis sent to the PID 1 - if this did not help, then
SIGKILLis sent to all processes in the container
For example, you can do this by passing the Session ID (SID) to the kill command.
Find the main process of the container:
$ docker inspect --format '{{ .State.Pid }}' test-app
629353
Run ps j -A:
$ ps j -A PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND ... 629333 629353 629353 629353 ? -1 Ss 0 0:00 /bin/sh -c gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app 629353 629374 629353 629353 ? -1 S 0 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app 629374 629375 629353 629353 ? -1 S 0 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
We see our SID – 629353.
And kill the whole group:
$ sudo kill -9 -- -629353
Okay.
This all is very good and very interesting.
But is it possible to do without these crutches?
The “Right way” to launch processes in a container
Finally, let’s take a look at our Dockerfile:
FROM python:3.9-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . ENTRYPOINT gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
See the Docker – Shell and exec form documentation:
INSTRUCTION [“executable”,”param1″,”param2″] (exec form)
INSTRUCTION command param1 param2 (shell form)
So, in our case, the shell form was used – and as a result, we have the /bin/sh as the PID 1, which calls Gunicorn through -c.
If we rewrite it in the exec form:
FROM python:3.9-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . ENTRYPOINT ["gunicorn", "-w", "1", "-k", "uvicorn.workers.UvicornWorker", "--bind", "0.0.0.0:80", "app:app"]
And will run a container from this image, we will have only Gunicorn processes:
root@e6087d52350d:/app# ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.6 0.0 31852 27104 ? Ss 16:13 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app root 7 2.4 0.1 59636 47556 ? S 16:13 0:00 /usr/local/bin/python /usr/local/bin/gunicorn -w 1 -k uvicorn.workers.UvicornWorker --bind 0.0.0.0:80 app:app
Which already can handle SIGTERM signals:
root@e6087d52350d:/app# cat /proc/1/status | grep SigCgt SigCgt: 0000000008314a07
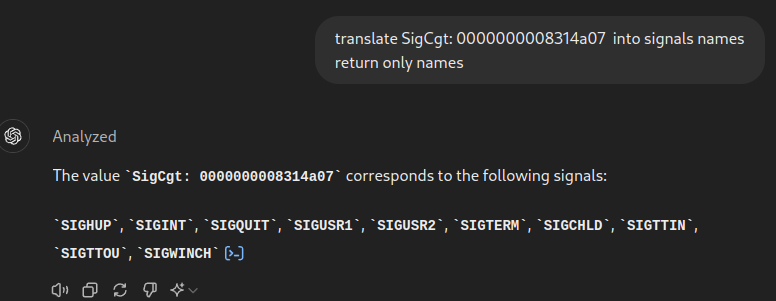
And now, if we send the SIGTERM to the PID 1, the container will finish its work normally:
root@e6087d52350d:/app# kill 1
And logs:
... [2024-06-22 16:17:20 +0000] [1] [INFO] Handling signal: term [2024-06-22 16:17:20 +0000] [7] [INFO] Shutting down [2024-06-22 16:17:20 +0000] [7] [INFO] Error while closing socket [Errno 9] Bad file descriptor [2024-06-22 16:17:20 +0000] [7] [INFO] Waiting for application shutdown. [2024-06-22 16:17:20 +0000] [7] [INFO] Application shutdown complete. [2024-06-22 16:17:20 +0000] [7] [INFO] Finished server process [7] [2024-06-22 16:17:20 +0000] [1] [ERROR] Worker (pid:7) was sent SIGTERM! [2024-06-22 16:17:21 +0000] [1] [INFO] Shutting down: Master
And now Kubernetes Pods will stop normally – and quickly, because they won’t wait for a grace period.
Useful links
- Why Sometimes the PID 1 Process Cannot Be Killed in a Container – a great post on how the
SIGKILLis handled for the PID 1 in the Linux kernel itself - How Signal Works inside the Kernel – and a bit more about the kernel and signals
- Why do you need an init process inside your Docker container (PID 1)
- Killing a process and all of its descendants
![]()