![]() Версія v21.0.0 додала підтримку AWS Provider Version 6
Версія v21.0.0 додала підтримку AWS Provider Version 6
Документація – тут>>>.
З основних змін в модулі AWS EKS – це заміна IRSA на EKS Pod Identity для Karpenter sub-module:
Native support for IAM roles for service accounts (IRSA) has been removed; EKS Pod Identity is now enabled by default
Плюс “The `aws-auth` sub-module has been removed” – але особисто я давно вже його випиляв.
Також були перейменовані деякі змінні.
Про апгрейд 19 версії на 20 писав в Terraform: EKS та Karpenter – upgrade версії модуля з 19.21 на 20.0, і цього разу підемо тим жеж шляхом – міняємо версії модулів, і дивимось, що зламається.
В мене для цього є окремий “Testing” environment, який я викатую спочатку з поточними версіями модулів/провайдерів, потім оновлюю код, деплою апгрейд, і коли все пофікшено – то вже роблю апгрейд EKS Production (бо у нас один кластер на dev/staging/prod).
В Helm-чарті самого Karpenter наче без особливих змін, хоча вже вийшла версія 1.6 – можна заодно теж оновити, але це вже іншим разом.
В цілому апгрейд пройшов без пригод, але були два моменти, де довелось подебажити – це проблема з EC2 metadata для AWS Load Balancer Controller під час апгрейду, та з EKS Add-ons при створенні нового кластеру з AWS EKS Terraform module v21.x.
Зміст
Upgrade AWS EKS Terraform module
Upgrade AWS Provider Version 6
Першим міняємо версію AWS Provider – нарешті, бо відкриті пул-реквести від Renovate муляли очі, а закрити не міг.
Тут все просто – міняємо версію на 6:
...
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
...
Використовуємо pessimistic constraint operator – дозволяємо апгрейди всіх мінорних версій.
Це буде враховуватись як Renovate, так і під час виконання terraform init -upgrade.
Upgrade terraform-aws-modules/eks/aws
Апгрейдимо версію модуля EKS – міняємо 20 на 21, теж з “~>“:
...
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> v21.0"
...
І Karpenter теж, в мене він окремим модулем:
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
version = "~> v21.0"
...
Робимо terraform init і ловимо “does not match configured version constraint” – писав в Terraform: “no available releases match the given constraints:
$ terraform init ... registry.terraform.io/hashicorp/aws 5.100.0 does not match configured version constraint >= 4.0.0, >= 4.36.0, >= 4.47.0, >= 5.0.0, ~> 5.14, >= 6.0.0 ...
Бо в .terraform.lock.hcl все ще стара версія провайдеру AWS:
$ cat envs/test-1-33/.terraform.lock.hcl | grep -A 5 5.100 version = "5.100.0" constraints = ">= 4.0.0, >= 4.33.0, >= 4.36.0, >= 4.47.0, >= 5.0.0, ~> 5.14, >= 5.95.0"
Можна дропнути файл і зробити terraform init ще раз, можна зробити terraform init -upgrade аби відразу підтягнути всі апгрейди:
$ terraform init -upgrade
Перевіряємо .terraform.lock.hcl ще раз – тепер все ОК:
$ git diff .terraform.lock.hcl
diff --git a/terraform/envs/test-1-33/.terraform.lock.hcl b/terraform/envs/test-1-33/.terraform.lock.hcl
index bd44714..cb2eace 100644
--- a/terraform/envs/test-1-33/.terraform.lock.hcl
+++ b/terraform/envs/test-1-33/.terraform.lock.hcl
@@ -24,98 +24,85 @@ provider "registry.terraform.io/alekc/kubectl" {
}
provider "registry.terraform.io/hashicorp/aws" {
- version = "5.100.0"
- constraints = ">= 4.0.0, >= 4.33.0, >= 4.36.0, >= 4.47.0, >= 5.0.0, ~> 5.14, >= 5.95.0"
+ version = "6.7.0"
+ constraints = ">= 4.0.0, >= 4.36.0, >= 4.47.0, >= 5.0.0, >= 6.0.0, ~> 6.0"
hashes = [
...
Поїхали робити terraform plan і дивитись що буде “ламатись”.
Renamed variables в terraform-aws-modules/eks/aws
Першим, очікувано, помилки про відсутні змінні, бо вони були перейменовані в модулі:
$ terraform plan -var-file=test-1-33.tfvars
...
│ Error: Unsupported argument
│
│ on ../../modules/atlas-eks/eks.tf line 34, in module "eks":
│ 34: cluster_name = "${var.env_name}-cluster"
│
│ An argument named "cluster_name" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on ../../modules/atlas-eks/eks.tf line 38, in module "eks":
│ 38: cluster_version = var.eks_version
│
│ An argument named "cluster_version" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on ../../modules/atlas-eks/eks.tf line 42, in module "eks":
│ 42: cluster_endpoint_public_access = var.eks_params.cluster_endpoint_public_access
│
│ An argument named "cluster_endpoint_public_access" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on ../../modules/atlas-eks/eks.tf line 46, in module "eks":
│ 46: cluster_enabled_log_types = var.eks_params.cluster_enabled_log_types
│
│ An argument named "cluster_enabled_log_types" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on ../../modules/atlas-eks/eks.tf line 50, in module "eks":
│ 50: cluster_addons = {
│
│ An argument named "cluster_addons" is not expected here.
╵
╷
│ Error: Unsupported argument
│
│ on ../../modules/atlas-eks/eks.tf line 148, in module "eks":
│ 148: cluster_security_group_name = "${var.env_name}-cluster-sg"
│
│ An argument named "cluster_security_group_name" is not expected here.
...
Йдемо в документацію по апгрейду – і по одній знаходимо як тепер називаються змінні:
cluster_name=>namecluster_version=>kubernetes_versioncluster_endpoint_public_access=>endpoint_public_accesscluster_enabled_log_types=>enabled_log_typescluster_addons->addonscluster_security_group_name->security_group_name
Хоча, як на мене – то з префіксом cluster_* було краще, бо у нас є node_security_group_name, і була cluster_security_group_name – чітко видно який параметр для чого.
А тепер є node_security_group_name і “якась” security_group_name.
Removed variables в terraform-aws-modules/eks/aws//modules/karpenter
ОК – редагуємо імена змінних в коді основного модулю, виконуємо terraform plan ще раз – тепер маємо помилки по змінам в модулі karpenter:
... Error: Unsupported argument │ │ on ../../modules/atlas-eks/karpenter.tf line 7, in module "karpenter": │ 7: irsa_oidc_provider_arn = module.eks.oidc_provider_arn │ │ An argument named "irsa_oidc_provider_arn" is not expected here. ╵ ╷ │ Error: Unsupported argument │ │ on ../../modules/atlas-eks/karpenter.tf line 8, in module "karpenter": │ 8: irsa_namespace_service_accounts = ["karpenter:karpenter"] │ │ An argument named "irsa_namespace_service_accounts" is not expected here. ╵ ╷ │ Error: Unsupported argument │ │ on ../../modules/atlas-eks/karpenter.tf line 14, in module "karpenter": │ 14: enable_irsa = true │ │ An argument named "enable_irsa" is not expected here. ...
Вони були видалені, бо більше немає IRSA – тепер для Karpenter буде створено EKS Pod Identity, див. main.tf#L92.
Про EKS Pod Indetity писав в AWS: EKS Pod Identities – заміна IRSA? Спрощуємо менеджмент IAM доступів і в Terraform: менеджмент EKS Access Entries та EKS Pod Identities.
Прибираємо їх:
... #irsa_oidc_provider_arn = module.eks.oidc_provider_arn #irsa_namespace_service_accounts = ["karpenter:karpenter"] #enable_irsa = true ...
Запускаємо terraform plan ще раз.
Important: Karpenter’s EKS Identity Provider Namespace
І ось тут важливий момент:
...
# module.atlas_eks.module.karpenter.aws_eks_pod_identity_association.karpenter[0] will be created
+ resource "aws_eks_pod_identity_association" "karpenter" {
...
+ namespace = "kube-system"
+ region = "us-east-1"
+ role_arn = "arn:aws:iam::492***148:role/KarpenterIRSA-atlas-eks-test-1-33-cluster"
+ service_account = "karpenter"
...
eks_pod_identity_association буде створено для Kubernetes Namespace "kube-system".
Якщо Karpenter в іншому неймспейсі – то треба вказати його явно при виклику модуля:
...
module "karpenter" {
source = "terraform-aws-modules/eks/aws//modules/karpenter"
version = "~> v21.0"
cluster_name = module.eks.cluster_name
namespace = "karpenter"
...
Бо інакше Karpenter “відвалиться”, і апгрейд WorkerNode Group сфейлиться – бо нода буде чекати на под Karpenter, а він буде в CrashLoopbackoff і апгрейд групи сфейлиться.
eks_managed_node_groups: attribute “taints”: map of object required
Тепер помилка з тегами нод-групи:
... │ The given value is not suitable for module.atlas_eks.module.eks.var.eks_managed_node_groups declared at .terraform/modules/atlas_eks.eks/variables.tf:1205,1-35: element "test-1-33-default": attribute "taints": map of object required. ...
Чому – бо:
Variable definitions now contain detailed object types in place of the previously used any type.
Див. diff 20 vs 21:

Тобто тепер це має бути map(object):
...
type = map(object({
key = string
value = optional(string)
effect = string
}))
...
А в мене taints зараз передаються зі змінної з об’єктом set(map(string)):
...
variable "eks_managed_node_group_params" {
description = "EKS Managed NodeGroups setting, one item in the map() per each dedicated NodeGroup"
type = map(object({
min_size = number
max_size = number
desired_size = number
instance_types = list(string)
capacity_type = string
taints = set(map(string))
max_unavailable_percentage = number
}))
}
...
З такими значеннями:
...
eks_managed_node_group_params = {
default_group = {
min_size = 1
max_size = 1
desired_size = 1
instance_types = ["t3.medium"]
capacity_type = "ON_DEMAND"
taints = [
{
key = "CriticalAddonsOnly"
value = "true"
effect = "NO_SCHEDULE"
},
{
key = "CriticalAddonsOnly"
value = "true"
effect = "NO_EXECUTE"
}
]
max_unavailable_percentage = 100
}
}
...
Тож що треба зробити – це змінити declaration змінної в мене:
...
variable "eks_managed_node_group_params" {
description = "EKS Managed NodeGroups setting, one item in the map() per each dedicated NodeGroup"
type = map(object({
min_size = number
max_size = number
desired_size = number
instance_types = list(string)
capacity_type = string
#taints = set(map(string))
taints = optional(map(object({
key = string
value = optional(string)
effect = string
})))
max_unavailable_percentage = number
}))
}
...
І оновити значення – додати ключі для map{}:
...
eks_managed_node_group_params = {
default_group = {
min_size = 1
max_size = 1
desired_size = 1
instance_types = ["t3.medium"]
capacity_type = "ON_DEMAND"
# taints = [
# {
# key = "CriticalAddonsOnly"
# value = "true"
# effect = "NO_SCHEDULE"
# },
# {
# key = "CriticalAddonsOnly"
# value = "true"
# effect = "NO_EXECUTE"
# }
# ]
taints = {
critical_no_sched = {
key = "CriticalAddonsOnly"
value = "true"
effect = "NO_SCHEDULE"
},
critical_no_exec = {
key = "CriticalAddonsOnly"
value = "true"
effect = "NO_EXECUTE"
}
}
max_unavailable_percentage = 100
}
}
...
Виконуємо terraform plan ще раз – і тепер все проходить без помилок.
Деплоїмо апдейти.
Deploying changes
Виконуємо terraform apply, і ось де маємо новий ресурс з EKS Pod Identity Association для Karpenter – module.atlas_eks.module.karpenter.aws_eks_pod_identity_association.karpenter:
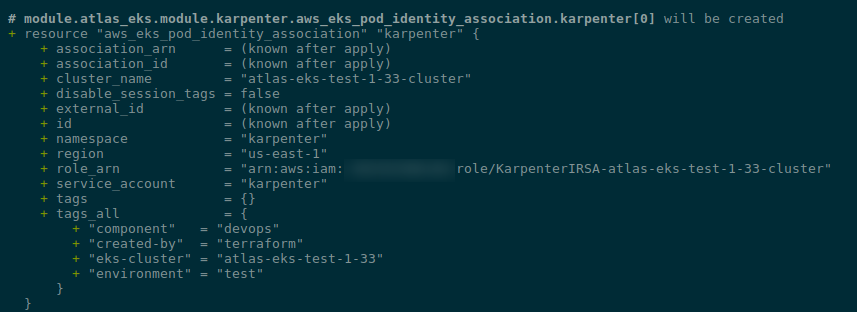
В старому кластері цього нема.
ALB Controller error: “failed to fetch VPC ID from instance metadata”
Ще виникла проблема з AWS Load Balancer Controller, бо після апгрейду він не зміг звернутись до IMDS, мабуть через переключення на v2, див. AWS: Instance Metadata Service v1 vs IMDS v2 та робота з Kubernetes Pod і Docker контейнерів:
...
{"level":"error","ts":"2025-08-06T07:25:40Z","logger":"setup","msg":"unable to initialize AWS cloud","error":"failed to get VPC ID: failed to fetch VPC ID from instance metadata: error in fetching vpc id through ec2 metadata: get mac metadata: operation error ec2imds: GetMetadata, canceled, context deadline exceeded"}
...
Власне, можна не морочити собі голову і просто передати параметри явно, див. документацію Using the Amazon EC2 instance metadata server version 2 (IMDSv2).
Зверніть увагу на --aws-vpc-tag-key:
optional flag –aws-vpc-tag-key if you have a different key for the tag other than “Name”
Спочатку спробуємо задати параметри руками, аби перевірити що воно працює:
Все завелось.
Тепер параметри для Helm-чарту, див його values.yaml#L163 – в мене контролери встановлюються з aws-ia/eks-blueprints-addons/aws в Terraform під час створення кластеру, задаємо тут:
...
values = [
<<-EOT
replicaCount: 1
region: ${var.aws_region}
vpcId: ${var.vpc_id}
tolerations:
- key: CriticalAddonsOnly
operator: Exists
EOT
]
...
Запускаємо деплой:
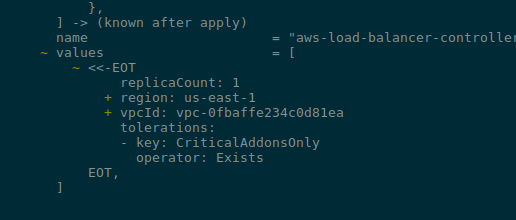
Все працює.
Node Group Status CREATE_FAILED
Тут опишу проблему, яка виникала тільки при створенні нового EKS кластеру з модулем v21 – апгрейд існуючого проходить без цих складностей.
Власне, в чому ця проблема полягає: кластер створився, все наче ОК, але довго висить на створенні Node Group, і потім падає з помилкою “unexpected state ‘CREATE_FAILED’“:
... ╷ │ Error: waiting for EKS Node Group (atlas-eks-test-1-33-cluster:test-1-33-default-20250801112636765600000014) create: unexpected state 'CREATE_FAILED', wanted target 'ACTIVE'. last error: i-03f2c73c7211880f7: NodeCreationFailure: Unhealthy nodes in the kubernetes cluster ...
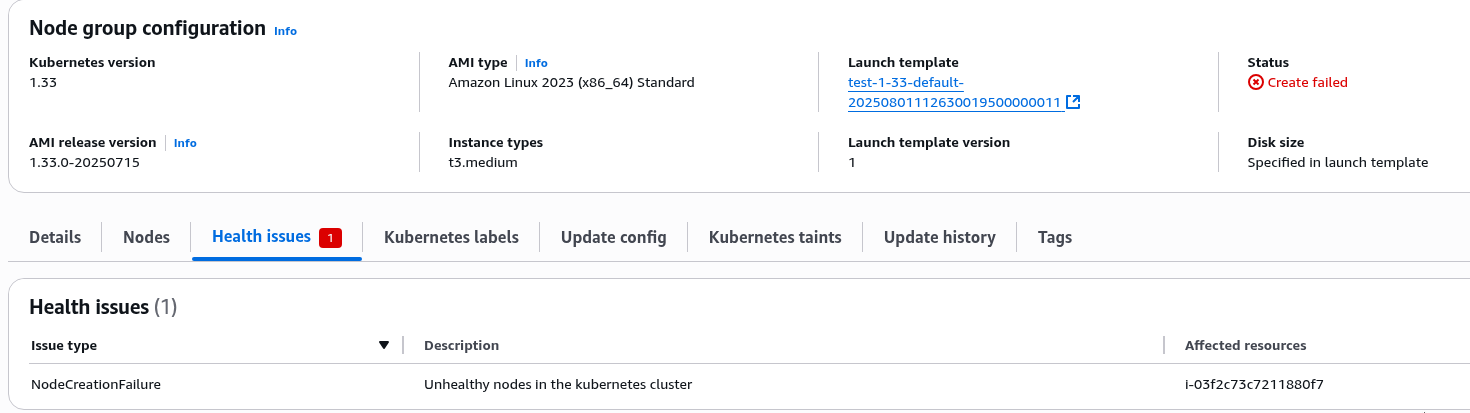
Хоча EC2 Auto Scaling Group є, і EC2 в ній теж.
Чому?
Тобто проблема в тому, що WorkerNode створена, але не може приєднатись до Kubernetes.
Першим про що думається – це перевірити Security Group, але тут наче все правильно – всі правила прописані. Порівнював з поточним EKS кластером, який робився ще з AWS EKS Terraform module v20.x – все аналогічно.
Проблема з IAM? У EC2 нема пермішенів достукатись до кластеру? Аналогічно – порівнюємо зі старим кластером, все ОК.
“Check the logs, Billy!”
Тут ще прикол в тому, що SSH на всі EC2 в мене налаштований – але тільки для Nodes, які створюються з Karpenter, писав в AWS: Karpenter та SSH для Kubernetes WorkerNodes.
А проблема виникла в “дефолтній” NodeGroup, де запускаються різні контролери.
Тому підключаємось через AWS Console – вибираємо Connect:

Потім в EC2 Instance Connect вибираємо “Connect using a Private IP” і вибираємо існуючий або руками швиденько створюємо новий EC2 Instance Connect Endpoint.
Задаємо ім’я юзера – для Amazon Linux це ec2-user:
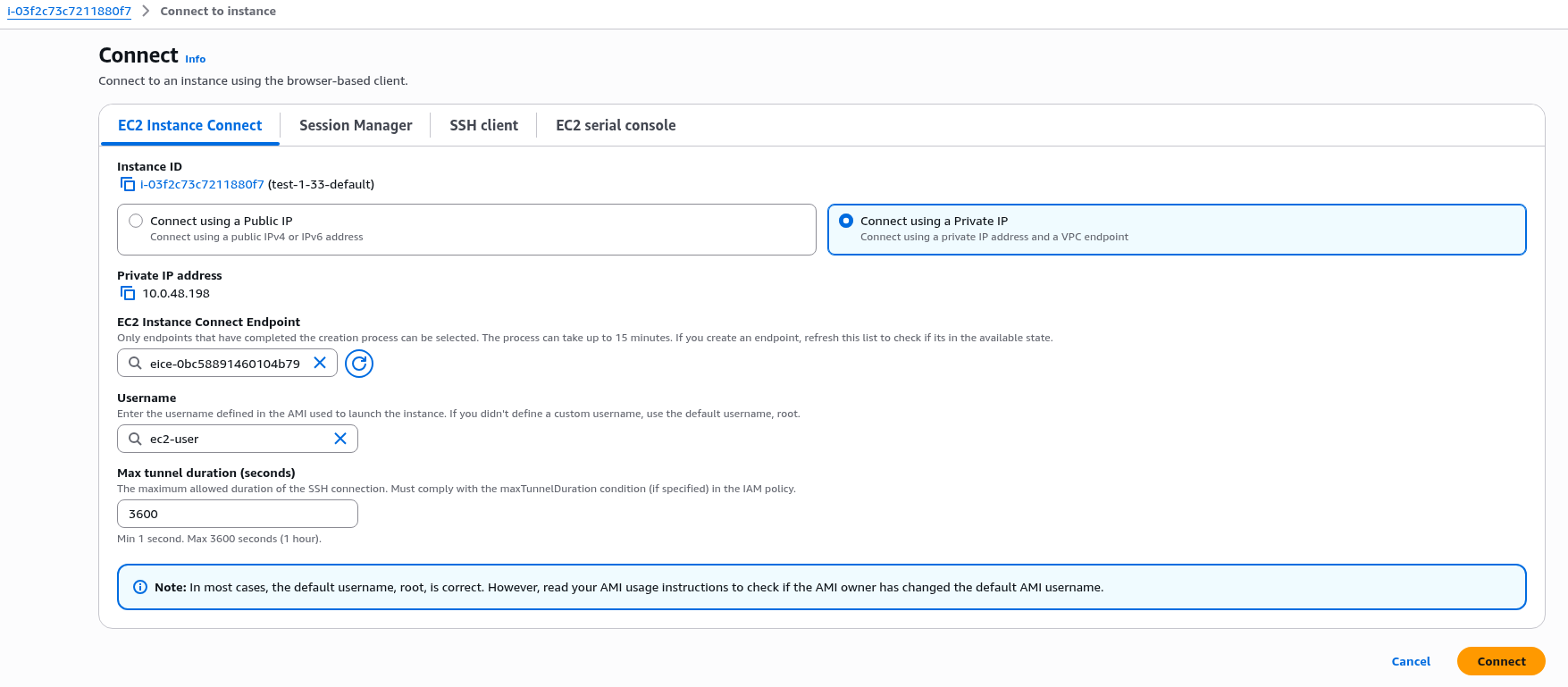
І дивимось логи:

“Container runtime network not ready – cni plugin not initialized”
Власне:
Aug 01 13:26:04 ip-10-0-48-198.ec2.internal kubelet[1619]: E0801 13:26:04.989799 1619 kubelet.go:3126] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized"
Вау…
Окей – а що у нас там з VPC CNI?
Йдемо подивитись EKS Add-ons, і…
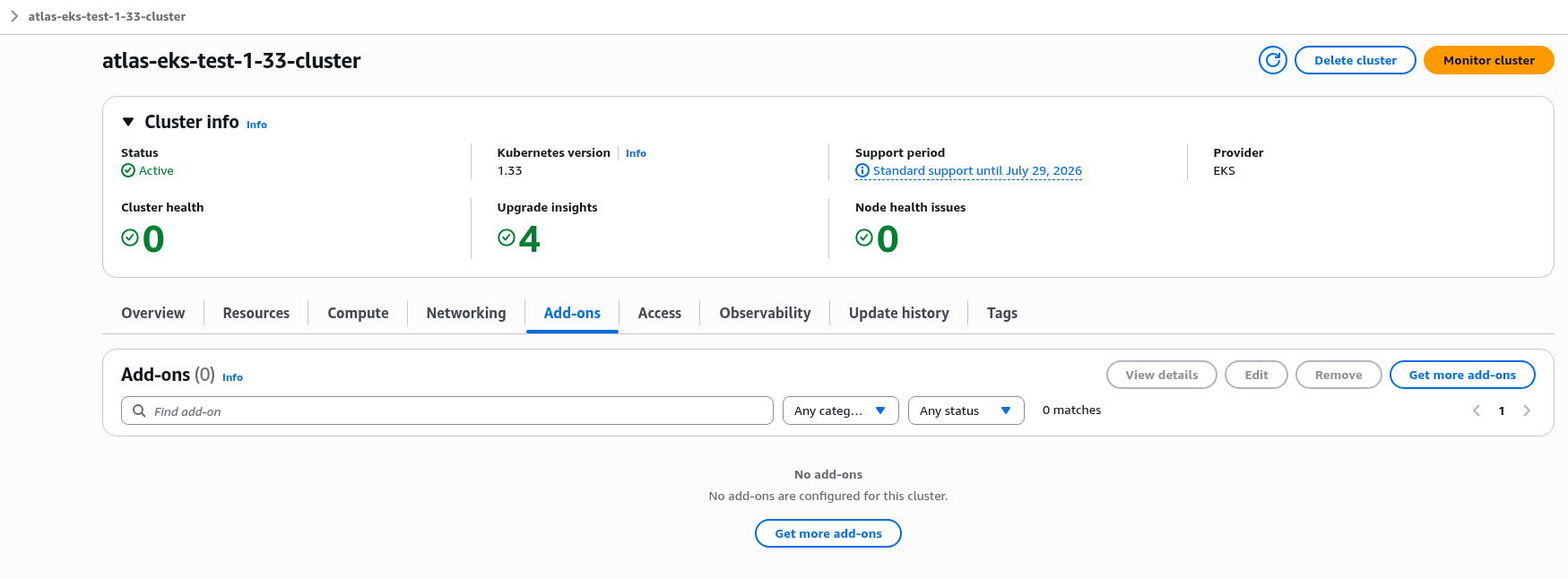
Взагалі пусто.
Дивимось лог terraform apply – і бачимо “Read complete“, але нема “Creating…“:
... module.atlas_eks.module.eks.data.aws_eks_addon_version.this["vpc-cni"]: Read complete after 0s [id=vpc-cni] ...
Давайте ще глянемо чи взагалі є контейнери на ноді – може, там якісь помилки є?

Ще раз вау…
Взагалі нічого.
Вже тоді ще раз поліз в GitHub Issues, і по запиту “addon” знайшов оцю ішью – Managed EKS Node Groups boot without CNI, but addon is added after node group.
Власне, да – проблема виникла через відсутність параметра before_compute.
Хоча трохи дивно, бо він був доданий ще в версії v19.9, я останній раз кластер з нуля деплоїв вже з v20 – і цієї проблеми не було.
Ба більше – створення тестового кластеру з мастер-бранча, де нема описаних тут апдейтів і версія модуля v20 все ще працює без проблем.
І в diff 20 vs 21 значних змін пов’язаних з before_compute не бачу.
Втім, так як це стосується тільки створення нового кластеру – то при просто апгрейді before_compute можна не додавати. Але якщо все ж додавати – то адони будуть перестворені.
Сама before_compute була додана аби дати можливість вказати які адони створювати до WorkerNodes, а які після. Див. main.tf#L797 та коменти до PR #2478.
Додаємо як в прикладах EKS Managed Node Group:
...
vpc-cni = {
addon_version = var.eks_addon_versions.vpc_cni
before_compute = true
configuration_values = jsonencode({
env = {
ENABLE_PREFIX_DELEGATION = "true"
WARM_PREFIX_TARGET = "1"
AWS_VPC_K8S_CNI_EXTERNALSNAT = "true"
}
})
}
aws-ebs-csi-driver = {
addon_version = var.eks_addon_versions.aws_ebs_csi_driver
service_account_role_arn = module.ebs_csi_irsa_role.iam_role_arn
}
eks-pod-identity-agent = {
addon_version = var.eks_addon_versions.eks_pod_identity_agent
before_compute = true
}
...
Виконуємо terraform apply знов – і ось воно:
... module.atlas_eks.module.eks.aws_eks_addon.before_compute["vpc-cni"]: Creating... ... module.atlas_eks.module.eks.aws_eks_addon.before_compute["vpc-cni"]: Creation complete after 46s [id=atlas-eks-test-1-33-cluster:vpc-cni] ...
І в AWS Console:
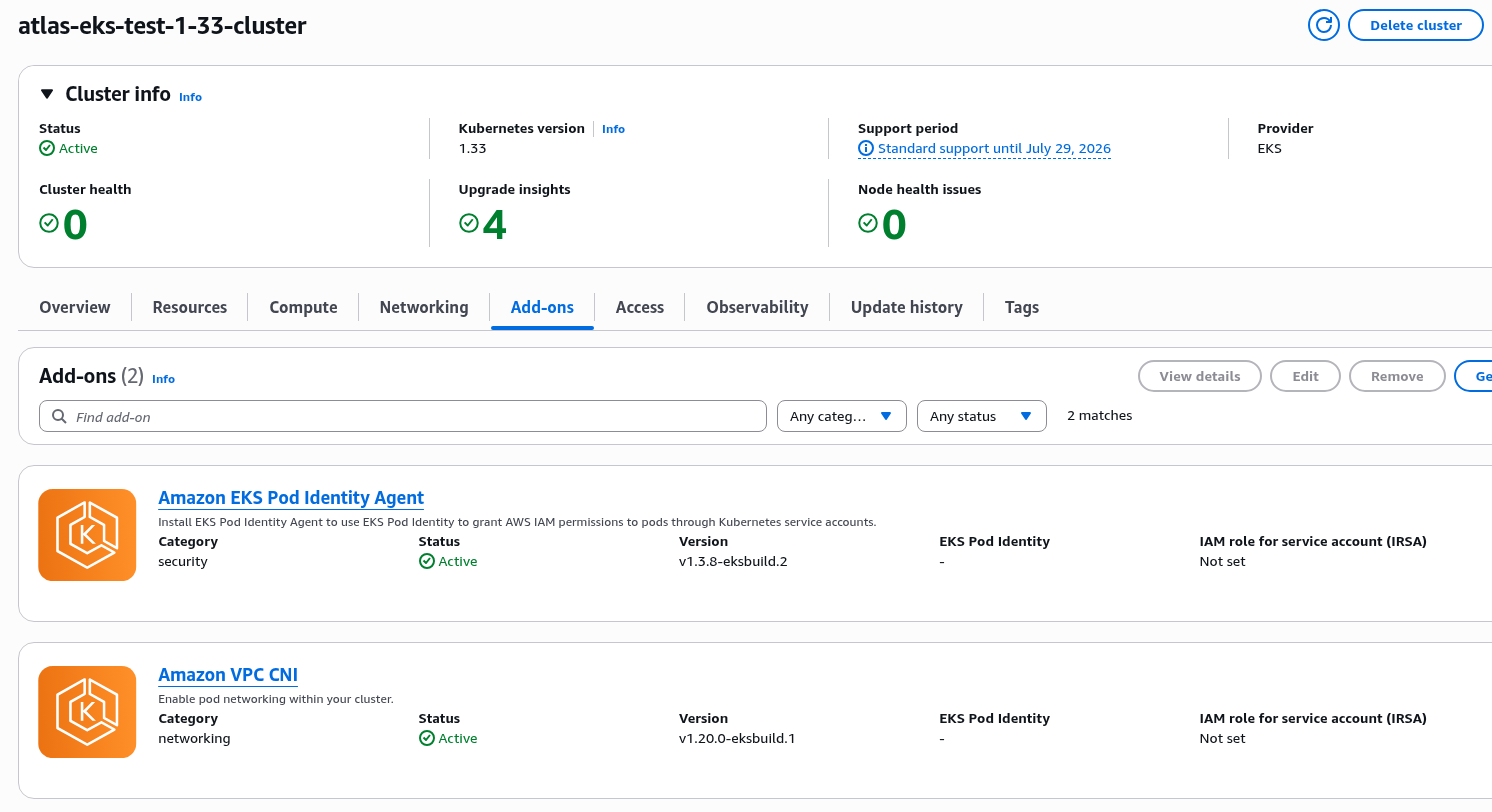
І NodeGroup створена без помилок:
... module.atlas_eks.module.eks.module.eks_managed_node_group["test-1-33-default"].aws_eks_node_group.this[0]: Still creating... [01m40s elapsed] module.atlas_eks.module.eks.module.eks_managed_node_group["test-1-33-default"].aws_eks_node_group.this[0]: Creation complete after 1m49s [id=atlas-eks-test-1-33-cluster:test-1-33-default-20250801142042855800000003] ...
Готово.
![]()