![]() На проекті користуємось двома системами для збору логів – Grafana Loki та VictoriaLogs, в які Promtail одночасно пише всі зібрані логи.
На проекті користуємось двома системами для збору логів – Grafana Loki та VictoriaLogs, в які Promtail одночасно пише всі зібрані логи.
Loki ніяк не випиляємо: хоча девелопери вже давно перейшли на VictoriaLogs, але деякі алерти все ще створюються з метрик, які генерить Loki, тож ще присутня в системі.
І в якийсь момент почались у нас дві проблеми:
- на VictoriaLogs забивається диск – довелось і retenation зменшувати, і диск збільшувати – хоча раніше вистачало
- в Loki почали дропатись логи з помилкою “Ingestion rate limit exceeded“
Давайте копнемо – що саме і чому забиває всі логи, і як це діло помоніторити.
Зміст
The issue: Loki Ingestion rate limit exceeded
Копати почав саме з помилки “Ingestion rate limit exceeded” в Loki, бо зайняте місце на диску VictoriaLogs було з тих самих причин – просто писалось забагато логів.
В алертах для Loki це виглядає так:

Сам алерт генериться з метрики loki_discarded_samples_total:
...
- alert: Loki Logs Dropped
expr: sum by (cluster, job, reason) (increase(loki_discarded_samples_total[5m])) > 0
for: 1s
...
Для VictoriaLogs в мене алерта не було, але в неї є схожа метрика – vl_rows_dropped_total.
Коли Loki почала дропати логи отримані від Promatil – почав перевіряти власні логи Loki, де і знайшов помилки з rate limit:
... path=write msg="write operation failed" details="Ingestion rate limit exceeded for user fake (limit: 4194304 bytes/sec) while attempting to ingest '141' lines totaling '1040783' bytes, reduce log volume or contact your Loki administrator to see if the limit can be increased" org_id=fake ...
Тоді не став копатись, а просто збільшив ліміт через limits_config – див. Rate-Limit Errors:
...
limits_config:
...
ingestion_rate_mb: 8
ingestion_burst_size_mb: 16
...
А для VictoriaLogs просто збільшив диск – Kubernetes: PVC в StatefulSet та помилка “Forbidden updates to statefulset spec”.
На якийсь час це начебто допомогло, але потім помилки з’явились знов – тож довелось таки розбиратись.
Перевірка logs ingestion
Отже, що нам треба – це визначити хто саме пише багато логів.
При цьому нам цікаві два параметри:
- кількість записів на секунду
- кількість байт на секунду
І побачити це ми хочемо з розділенням по сервісам.
Records per second
Отримати рейт логів на секунду в VictoriaLogs можна просто з функцією rate():
{app=~".*"}
| stats by (app) rate() records_per_second
| sort by (records_per_second) desc
| limit 10
Тут:
- групуємо на лейблі
app(sum by (app)в Loki) - з
rate()отримуємо per-second rate нових записів на групіapp, результат зберігаємо в новому поліrecords_per_second - сортуємо по
records_per_secondз descending - і виводимо топ-10 з
limit(абоhead)

Ну і, власне…
Бачимо, що в топі у нас з великим відривом йде сама VictoriaLogs 🙂
До того ж на графіку в VictoriaLogs видно, що найбільше логів саме з Namespace ops-monitoring-ns де і живе VictoriaLogs:

В Loki можна глянути per-second rate з аналогічною функцією rate():
topk(10, sum by (app) (rate({app=~".+"}[1m])))

Bytes per second
Аналогічна картина з рейтом байт на секунду.
В Loki ми це можемо побачити просто з bytes_over_time():
topk(10, sum by (app) (bytes_over_time({app=~".+"}[1m])))

Для VictoriaLogs є block_stats, але “з коробки” воно не дає змоги відобразити статистику по кожному хоча б стріму – див. How to determine which log fields occupy the most of disk space?
Проте є sum_len(), де ми можемо отримати статистику наприклад так:
* | stats by (app) sum_len() as bytes_used | sort (bytes_used) desc | limit 10
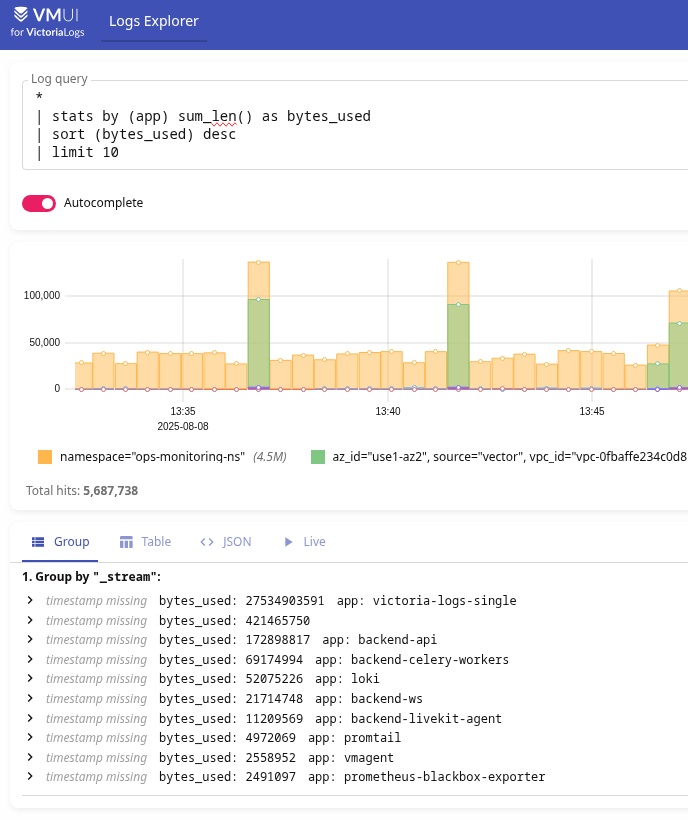
Або per-second rate:
* | stats by (app) sum_len() as rows_len | stats by (app) rate_sum(rows_len) as bytes_used_rate | sort (bytes_used_rate) desc | limit 10

Причина
Тут все виявилось просто.
Достатньо було просто заглянути в логи самої VictoriaLogs, і побачити там що вона логує всі записи, які отримала від Promtail – “new log entry“:

Йдемо дивитись опції для VictoriaLogs в документації List of command-line flags, і там знаходимо “-logIngestedRows“:
-logIngestedRows
Whether to log all the ingested log entries; this can be useful for debugging of data ingestion; see https://docs.victoriametrics.com/victorialogs/data-ingestion/ ; see also -logNewStreams
Дефолтне значення тут не вказане, і я спочатку подумав, що воно просто включене в “true“, тож пішов у values нашого чарту, аби виставити “false“, де і побачив:
...
victoria-logs-single:
server:
...
extraArgs:
logIngestedRows: "true"
...
Ouch…
Для чогось колись включав це логування – і забув.
Власне – переключаємо його в false (або просто видаляємо, бо по дефолту воно і так false), деплоїмо – проблема вирішена.
Заодно можна переключити loggerLevel, який по дефолту має INFO.
І тут, до речі, могла б бути цікава картина: якщо б і Loki і VictoriaLogs писали лог про кожен log record, який вони отримали – то…
- Loki отримує будь-який запис від Promtail
- записує цю подію у власний лог
- Promtail бачить новий запис від контейнеру з Loki, і знов передає його і до Loki, і до VictoriaLogs
- VictoriaLogs записує у свій лог, що отримала цей запис
- Promtail бачить новий запис від контейнеру з VictoriaLogs і передає його і до Loki, і до VictoriaLogs
- Loki отримує цей запис від Promtail
- записує цю подію у власний лог
- …
Такий собі “fork logs bomb”.
Моніторинг логів на майбутнє
Тут теж все просто або користуємось дефолтними метриками від Loki та VictoriaLogs, або генеримо власні.
Метрики Loki
В чарті Loki є опція monitoring.serviceMonitor.enabled, можна просто включити її – тоді VictoriaMetrics Opeartor створить VMServiceScrape і почне збирати метрики.
Для Loki можуть бути цікавими:
loki_log_messages_total: Total number of messages logged by Lokiloki_distributor_bytes_received_total: The total number of uncompressed bytes received per tenantloki_distributor_lines_received_total: The total number of lines received per tenantloki_discarded_samples_total: The total number of samples that were droppedloki_discarded_bytes_total: The total number of bytes that were dropped
Або можемо створити власні метрики з інформацією по кожній app:
kind: ConfigMap
apiVersion: v1
metadata:
name: loki-recording-rules
data:
rules.yaml: |-
...
- name: Loki-Logs-Stats
rules:
- record: loki:logs:ingested_rows:sum:rate:5m
expr: |
topk(10,
sum by (app) (
rate({app=~".+"}[5m])
)
)
- record: loki:logs:ingested_bytes:sum:rate:5m
expr: |
topk(10,
sum by (app) (
bytes_rate({app=~".+"}[5m])
)
)
Деплоїмо, перевіряємо:

І потім вже за цими метриками робити алерти:
...
- alert: Loki Logs Ingested Rows Too High
expr: sum by (app) (loki:logs:ingested_rows:sum:rate:5m) > 100
for: 1s
labels:
severity: warning
component: devops
environment: ops
annotations:
summary: 'Loki Logs Ingested Rows Too High'
description: |-
Grafana Loki ingested too many log rows
*App*: `{{ "{{" }} $labels.app }}`
*Value*: `{{ "{{" }} $value | humanize }}` records per second
tags: devops
- alert: Loki Logs Ingested Bytes Too High
expr: sum by (app) (loki:logs:ingested_bytes:sum:rate:5m) > 50000
for: 1s
labels:
severity: warning
component: devops
environment: ops
annotations:
summary: 'Loki Logs Ingested Bytes Too High'
description: |-
Grafana Loki ingested too many log bytes
*App*: `{{ "{{" }} $labels.app }}`
*Value*: `{{ "{{" }} $value | humanize1024 }}` bytes per second
tags: devops
...
Метрики VictoriaLogs
Додаємо збір метрик з VictoriaLogs:
...
victoria-logs-single:
server:
...
vmServiceScrape:
enabled: true
..
Корисні метрики:
vl_bytes_ingested_total: Cumulative estimated bytes of logs accepted by the ingesters, split by protocol via labelsvl_rows_ingested_total: Cumulative number of log entries successfully accepted by the ingesters, split by ingestion protocol via labels in the raw seriesvl_rows_dropped_total: Cumulative rows dropped by the server during ingestion, with labeled reasons (e.g. debug mode, too many fields, timestamp out of bounds)vl_too_long_lines_skipped_total: Number of over‑size lines skipped because they exceed the configured maximum line sizevl_free_disk_space_bytes: Current free space available on the filesystem hosting the storage path
І додати алерт на кшталт такого:
...
- alert: VictoriaLogs Logs Dropped Rows Too High
expr: sum by (reason) (vl_rows_dropped_total) > 0
for: 1s
labels:
severity: warning
component: devops
environment: ops
annotations:
summary: 'VictoriaLogs Logs Dropped Rows Too High'
description: |-
VictoriaLogs dropped too many log rows
*Reason*: `{{ "{{" }} $labels.app }}`
*Value*: `{{ "{{" }} $value | humanize }}` records dropped
tags: devops
...
Але знов-таки – vl_rows_ingested_total не скаже нам яка саме апка пише забагато логів.
Тому можемо додати RecordingRules – див. VictoriaLogs: створення Recording Rules з VMAlert:
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMRule
metadata:
name: vmlogs-alert-rules
spec:
groups:
- name: VM-Logs-Ingested
# an expressions for the VictoriaLogs datasource
type: vlogs
rules:
- record: vmlogs:logs:ingested_rows:stats:rate
expr: |
{app=~".*"}
| stats by (app) rate() records_per_second
| sort by (records_per_second) desc
| limit 10
Деплоїмо, перевіряємо:

І додаємо алерт:
...
- alert: VictoriaLogs Logs Ingested Rows Too High
expr: sum by (app) (vmlogs:logs:ingested_rows:stats:rate) > 100
for: 1s
labels:
severity: warning
component: devops
environment: ops
annotations:
summary: 'VictoriaLogs Logs Ingested Rows Too High'
description: |-
Grafana Loki ingested too many log rows
*App*: `{{ "{{" }} $labels.app }}`
*Value*: `{{ "{{" }} $value | humanize }}` records per second
tags: devops
...
Результат:

Ну і власне на цьому поки все.
Такий собі базовий моніторинг для VictoriaLogs та Loki.
![]()