 Имеется PHP-приложение, работает в Kubernetes в подах с двумя контейнерами — NGINX и PHP-FPM.
Имеется PHP-приложение, работает в Kubernetes в подах с двумя контейнерами — NGINX и PHP-FPM.
Проблема: во время скейлинга приложения начинают проскакивать 502 ошибки. Т.е. при остановке подов — некорректно отрабатывает завершение подключений.
Рассмотрим процесс остановки подов вообще, и особенности NGINX и PHP-FPM в частности.
Тестировать будем приложение в AWS Elastic Kubernetes Service с помощью Yandex.Tank.
Ingress создаёт AWS Application Load Balancer с помощью AWS ALB Ingress Controller.
Для управления контейнерами на Kubernetes WorkerNodes испольузется Docker.
Содержание
Pod Lifecycle — Termination of Pods
Посмотрим, как вообще происходит процесс остановки и удаления подов.
Итак, под — это процесс(ы), запущенные на WorkerNode, для остановки которых используются стандартные сигналы IPC (Inter Process Communication).
Что бы дать возможность поду (процессу/ам) закончить все его текущие операции — система управления контейнерами (container runtime) пытается мягко завершить его работу (graceful shutdown), отправляя сигнал SIGTERM процессу с PID 1 в каждом контейнере этого пода (см. docker stop). При этом, кластер запускает отсчёт grace period перед тем, как жёстко убить под отправкой сигнала SIGKILL.
При этом, можно переопределить сигнал для мягкой остановки используя STOPSIGNAL в образе, из которого запускался контейнер.
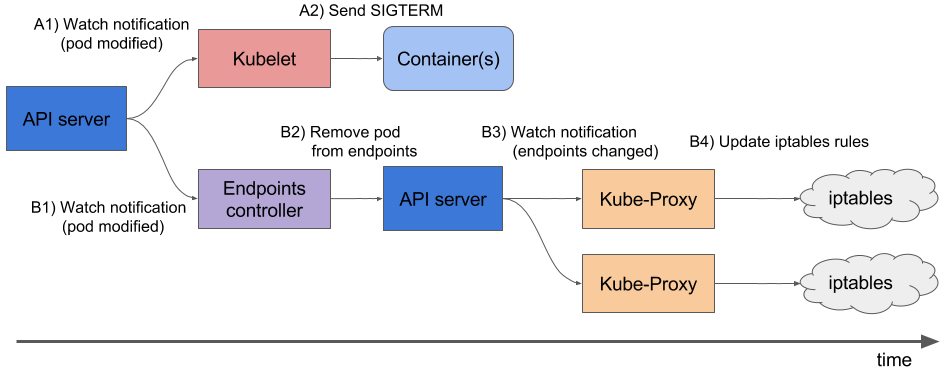
Итак, процесс удаления пода выглядит следующим образом:
- мы выполняем
kubectl delete podилиkubectl scale deployment— запускается процесс удаления подов и стартует таймер отсчёта grace period с дефолтным значением в 30 секунд - API-сервер обновляет статус пода — из Running он становится Terminating (см. Container states). На WorkerNode, на которой этот под запущен,
kubeletполучает обновление статус этого пода и начинает процесс его остановки:- если для контейнера(ов) в поде есть
preStophook —kubeletего выполняет. Если хук продолжает выполнение после истечения grace period — добавляется ещё 2 секунды на его завершение. При необходимости можно изменить дефолтные 30 секунд используяterminationGracePeriodSeconds - после завершения
preStopхука —kubeletотправляет указание Docker на остановку контейнеров, и Docker отправляет сигналSIGTERMпроцессу с PID 1 в каждом контейнере. При этом контейнеры в поде получают сигнал в случайном порядке.
- если для контейнера(ов) в поде есть
- одновременно с началом процесса graceful shutdown — Kubernetes Control Plane (его
kube-controller-manager) удаляет останавливаемый под из списка ендпоинтов (см. Kubernetes – Endpoints), и соответствующий Service перестаёт отправлять новые подключения на останавливаемый под - по завершению grace period,
kubeletтриггерит force shutdown — Docker отправляет сигналSIGKILLвсем оставшимся процесам во всех контейнерах пода, который они проигнорировать не могут, и мгновенно умирают, аварийно завершая все свои операции kubeletтриггерит удаление объекта пода из API-сервера- API-сервер удаляет запись о поде из базы, и под становится недоступен
Наглядная табличка:
Собственно, тут возникает две проблемы:
- сам NGINX и PHP-FPM воспринимают
SIGTERMкак «жестокое убийство», и завершают работу немедленно, не заботясь о корректном завершении текущих подключений (см. Controlling nginx и php-fpm(8) — Linux man page) - шаги 2 и 3 — отправка
SIGTERMи удаление ендпоинта — выполняются одновременно. Однако, обновление данных в Ingress Service происходит не моментально, и под может начать умирать раньше, чем Ingress перестанет на него слать трафик, соотвественно — получим 502, т.к. процесс в поде уже не может принимать подключения
Т.е. в первом случае, если у нас есть подключение к NGINX с keep-alive — то NGINX при выполнении fast shutdown просто обрубит его, а клиент получит 502 ошибку, см. Avoiding dropped connections in nginx containers with «STOPSIGNAL SIGQUIT».
NGINX STOPSIGNAL и 502
Попробуем воспроизвести проблему с NGINX.
Возмём пример из поста по ссылке выше, и задеплоим его в Кубер.
Пишем Dockerfile:
FROM nginx
RUN echo 'server {\n\
listen 80 default_server;\n\
location / {\n\
proxy_pass http://httpbin.org/delay/10;\n\
}\n\
}' > /etc/nginx/conf.d/default.conf
CMD ["nginx", "-g", "daemon off;"]
Тут NGINX выполняет proxy_pass на http://httpbin.org, который отвечает с задержкой в 10 секунд — эмулируем работу PHP-бекенда.
Собираем, пушим в репозиторий:
[simterm]
$ docker build -t setevoy/nginx-sigterm . $ docker push setevoy/nginx-sigterm
[/simterm]
Пишем Deployment с 10 подами из собранного образа.
Тут приведу полный файл, с Namespace, Service и Ingress, далее только те части, которые будут меняться:
---
apiVersion: v1
kind: Namespace
metadata:
name: test-namespace
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-deployment
namespace: test-namespace
labels:
app: test
spec:
replicas: 10
selector:
matchLabels:
app: test
template:
metadata:
labels:
app: test
spec:
containers:
- name: web
image: setevoy/nginx-sigterm
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 100Mi
readinessProbe:
tcpSocket:
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: test-svc
namespace: test-namespace
spec:
type: NodePort
selector:
app: test
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
namespace: test-namespace
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
spec:
rules:
- http:
paths:
- backend:
serviceName: test-svc
servicePort: 80
Деплоим:
[simterm]
$ kubectl apply -f test-deployment.yaml namespace/test-namespace created deployment.apps/test-deployment created service/test-svc created ingress.extensions/test-ingress created
[/simterm]
Проверяем Ingress:
[simterm]
$ curl -I aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com HTTP/1.1 200 OK
[/simterm]
Запущено 10 подов:
[simterm]
$ kubectl -n test-namespace get pod NAME READY STATUS RESTARTS AGE test-deployment-ccb7ff8b6-2d6gn 1/1 Running 0 26s test-deployment-ccb7ff8b6-4scxc 1/1 Running 0 35s test-deployment-ccb7ff8b6-8b2cj 1/1 Running 0 35s test-deployment-ccb7ff8b6-bvzgz 1/1 Running 0 35s test-deployment-ccb7ff8b6-db6jj 1/1 Running 0 35s test-deployment-ccb7ff8b6-h9zsm 1/1 Running 0 20s test-deployment-ccb7ff8b6-n5rhz 1/1 Running 0 23s test-deployment-ccb7ff8b6-smpjd 1/1 Running 0 23s test-deployment-ccb7ff8b6-x5dc2 1/1 Running 0 35s test-deployment-ccb7ff8b6-zlqxs 1/1 Running 0 25s
[/simterm]
Готовим load.yaml для Yandex.Tank:
phantom:
address: aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com
header_http: "1.1"
headers:
- "[Host: aadca942-testnamespace-tes-5874-698012771.us-east-2.elb.amazonaws.com]"
uris:
- /
load_profile:
load_type: rps
schedule: const(100,30m)
ssl: false
console:
enabled: true
telegraf:
enabled: false
package: yandextank.plugins.Telegraf
config: monitoring.xml
Тут выполняем 1 запрос в секунду к подам за нашим Ingress (и NGINX в каждом будет ждать 10 секунд ответа от своего «бекенда» перед тем, как ответить 200 нашему Танку).
Запускаем тесты:
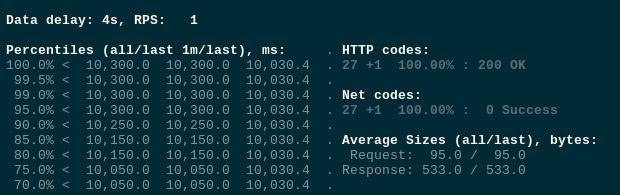
Пока всё хорошо.
Теперь скейлим поды с 10 до 1:
[simterm]
$ kubectl -n test-namespace scale deploy test-deployment --replicas=1 deployment.apps/test-deployment scaled
[/simterm]
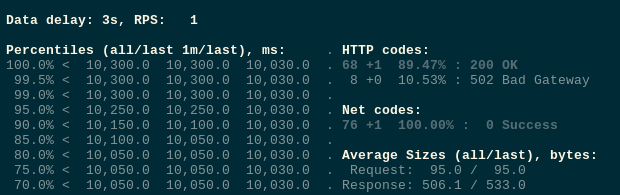
Поды перешли в Terminating:
[simterm]
$ kubectl -n test-namespace get pod NAME READY STATUS RESTARTS AGE test-deployment-647ddf455-67gv8 1/1 Terminating 0 4m15s test-deployment-647ddf455-6wmcq 1/1 Terminating 0 4m15s test-deployment-647ddf455-cjvj6 1/1 Terminating 0 4m15s test-deployment-647ddf455-dh7pc 1/1 Terminating 0 4m15s test-deployment-647ddf455-dvh7g 1/1 Terminating 0 4m15s test-deployment-647ddf455-gpwc6 1/1 Terminating 0 4m15s test-deployment-647ddf455-nbgkn 1/1 Terminating 0 4m15s test-deployment-647ddf455-tm27p 1/1 Running 0 26m ...
[/simterm]
И ловим наши 502 ошибки:
Теперь в Dockerfile добавляем STOPSIGNAL SIGQUIT:
FROM nginx
RUN echo 'server {\n\
listen 80 default_server;\n\
location / {\n\
proxy_pass http://httpbin.org/delay/10;\n\
}\n\
}' > /etc/nginx/conf.d/default.conf
STOPSIGNAL SIGQUIT
CMD ["nginx", "-g", "daemon off;"]
Билдим, пушим:
[simterm]
$ docker build -t setevoy/nginx-sigquit . $ docker push setevoy/nginx-sigquit
[/simterm]
Обновляем деплоймент:
...
spec:
containers:
- name: web
image: setevoy/nginx-sigquit
ports:
- containerPort: 80
...
Передеплоиваем, и проверяем ещё раз.
Запускаем тесты:
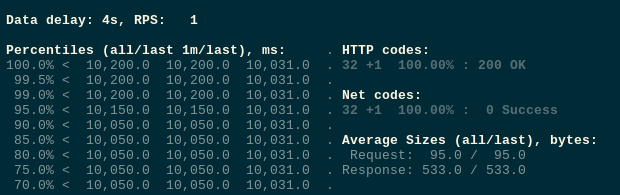
Скейлим деплоймент:
[simterm]
$ kubectl -n test-namespace scale deploy test-deployment --replicas=1 deployment.apps/test-deployment scaled
[/simterm]
А ошибок по-прежнему нет:

Прекрасно.
Трафик, preStop и sleep
И всё-таки, если повторить тесты несколько раз, то иногда 502 ошибки всё-таки проскакивают:
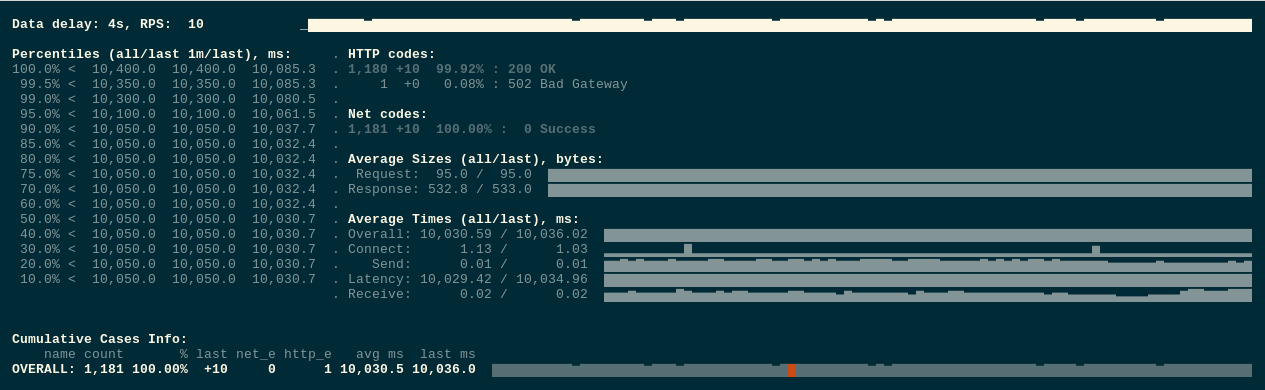
Тут мы уже сталкиваемся со второй проблемой — обновление ендпоинтов выполняется параллельно с отправкой SIGTERM.
Добавим preStop хук со sleep, что бы дать время на обновление ендпоинтов — тогда после получения команды на удаление пода, kubelet выждет 5 секунд перед отправкой SIGTERM, за которые Ingress успеет обновить список ендпоинтов:
...
spec:
containers:
- name: web
image: setevoy/nginx-sigquit
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command: ["/bin/sleep","5"]
...
Повторяем тесты — всё хорошо.
Выкатили фикс в Production — всё работает замечательно, ошибки пропали, автотесты теперь работают без проблем.
С PHP-FPM проблемы, как оказалось, не было вообще, т.к. исходный образ изначально был со STOPSIGNAL SIGQUIT.
Другие варианты решения
Конечно, по ходу поиска решения были переброваны самые разные варианты. См. ссылки на интересные материалы в конце, а тут опишу их кратко.
preStop и nginx -s quit
Одним из вариантов было добавить в preStop хук отправку сигнала QUIT в NGINX:
lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
Но не помогло. Не очень понятно почему, потому как идея вроде бы правильная — вместо того, что бы ожидать TERM от Kubernetes/Docker — мы сами мягко стопаем NGINX, отправляя ему QUIT.
Но можно попробовать.
NGINX + PHP-FPM, supervisord и stopsignal
Наше приложение работает в двух отдельных контейнерах NGINX и PHP-FPM.
Но в процессе поиска решения пробовал использовать образ, в котором оба сервиса собраны в одном образе, например trafex/alpine-nginx-php7.
В нём пробовал добавлять параметр stopsignal и для NGINX, и для PHP-FPM со значением QUIT — но тоже не помогло, хотя идея тоже вроде правильная.
Тем не менее — как вариант на попытку.
PHP-FPM и process_control_timeout
В посте Graceful shutdown in Kubernetes is not always trivial и на Stackoveflow в вопросе Nginx / PHP FPM graceful stop (SIGQUIT): not so graceful есть упоминание о том, что мастер-процесс FPM убивается не дожидаясь своих дочерних процессов, что также может приводить к 502.
Не наш случай, но стоит обратить внимание на параметр process_control_timeout.
NGINX, HTTP и keep-alive session
В принципе, можно было бы указать приложению отправлять заголовок [Connection: close] — тогда клиент по завершении передачи данных закрывал бы соединение, и это уменьшило бы вероятность 502-х. Но они всё равно будут, если NGINX получит SIGTERM в процессе обработки запроса от клиента, а т.к. у нас «сзади» ещё PHP, который ходит в базу — то некоторые запросы могут обрабатываться по 5-10 и более секунд.
См. HTTP persistent connection.
Ссылки по теме
- Graceful shutdown in Kubernetes is not always trivial (перевод на Хабре)
- Gracefully Shutting Down Pods in a Kubernetes Cluster — рассматривается решение с
nginx -s quitвpreStop, и хорошо описан вопрос с трафиком к убиваемым подам - Kubernetes best practices: terminating with grace
- Termination of Pods
- Kubernetes’ dirty endpoint secret and Ingress
- Avoiding dropped connections in nginx containers with “STOPSIGNAL SIGQUIT” — собственно, тут и натолкнулся на решение, которое нам помогло + хороший пример того, как можно воспроизвести проблему, его и использовал в этом посте
- Kubernetes: Ingress, ошибка 502, readinessProbe и livenessProbe — тут немного о другом, но тоже про 502 ошибки в Kubernetes
![]()