![]() Последний раз Loki для сбора и наблюдения за логами настраивал аж в феврале этого (см. Grafana Labs: Loki — сбор и просмотр логов), когда Loki была ещё в beta-версии.
Последний раз Loki для сбора и наблюдения за логами настраивал аж в феврале этого (см. Grafana Labs: Loki — сбор и просмотр логов), когда Loki была ещё в beta-версии.
Сейчас возникли проблемы с исходящим трафиком (объём за два месяца вырос в 4 раза), никак не можем найти виновника.
Как один из вариантов поиска этого самого виновника — решили добавить сбор статистики по DNS-запросам, что бы посмотреть к каким URL выполняются обращения и попробовать найти корреляцию между OUT трафиком с хостов в AWS, и запросами к локальному dnsmasq.
Настройка самого dnsmasq описана в посте dnsmasq: ошибки в AWS — «Temporary failure in name resolution», логи, дебаг и размер кеша, а в этом посте попробуем реализовать следующее:
dnsmasqзаписывает все запросы в локальный файл лога- лог тейлится
promtail-ом, который отправляет их на сервер мониторинга в Loki - а Grafana на основании метрик из Loki будет отрисовывать красивенькие дашборды со статистикой
Описанный ниже сетап — больше Proof of Concept, так как и сама Loki ещё активно разрабатывается, и её поддержка в Grafana реализована не полностью.
Чего стоит только добавление Loki как datasource, но… как Prometheus O.o Звучит странно, выглядит ещё интереснее.
Зато, Explore в Grafana теперь поддерживает работу с логами используя функциии агрегации аналогично Prometheus — sum(), rate() и так далее.
Да и promtail за почти год, внезапно, тоже добавил много интересных возможностей, с которыми и ознакомимся сегодня.
Сначала поднимем стек Grafana + Loki + promtail, потом подключим сбор логов с помощью promtail с нашего Production-хоста, и посмотрим как работают функции агрегации, и какие дашборды теперь можно делать.
«Поняслася!»
Содержание
Запуск Loki
Запускать будем из Docker Compose, создаём файл loki-stack.yml:
version: '2.4'
networks:
loki:
services:
loki:
image: grafana/loki:master-2739551
ports:
- "3100:3100"
networks:
- loki
restart: unless-stopped
Запускаем:
[simterm]
root@monitoring-dev:/opt/loki# docker-compose -f loki-stack.yml up
[/simterm]
Проверяем:
[simterm]
root@monitoring-dev:/home/admin# curl localhost:3100/ready Ready
[/simterm]
Loki API документация — тут>>>.
Запуск Grafana
Аналогично делаем с Grafana, используем 6.4.4 (см. доступные версии в Docker Hub):
version: '2.4'
networks:
loki:
services:
loki:
image: grafana/loki:master-2739551
ports:
- "3100:3100"
networks:
- loki
restart: unless-stopped
grafana:
image: grafana/grafana:6.4.4
ports:
- "3000:3000"
networks:
- loki
restart: unless-stopped
Запускаем, проверяем:

Логинимся с admin:admin, переходим в Datasources:

Так как Loki в Docker сети — обращаемся к ней (нему?) по адресу http://loki:

NGINX
Сетап выполняется на уже существующем и настроенном Dev хосте мониторинга, тут уже всё есть.
Конфиг /etc/nginx/conf.d/dev.loki.example.com.conf выглядит так:
upstream grafana-loki {
server 127.0.0.1:3000;
}
server {
listen 80;
server_name dev.loki.example.com;
# Lets Encrypt Webroot
location ~ /.well-known {
root /var/www/html;
allow all;
}
location / {
allow 194.***.***.26/29;
allow 91.***.***.78/32;
allow 188.***.***.94/32;
allow 78.***.***.191/32;
allow 176.***.***.43/32;
allow 10.0.10.0/24;
deny all;
return 301 https://dev.loki.example.com$request_uri;
}
}
server {
listen 443 ssl;
server_name dev.loki.example.com;
# access_log /var/log/nginx/dev.loki.example.com-access.log proxy;
error_log /var/log/nginx/dev.loki.example.com-error.log warn;
# auth_basic_user_file /var/www/dev.loki.example.com/.htpasswd;
# auth_basic "Password-protected Area";
allow 194.***.***.26/29;
allow 91.***.***.78/32;
allow 188.***.***.94/32;
allow 78.***.***.191/32;
allow 176.***.***.43/32;
allow 10.0.10.0/24;
deny all;
ssl_certificate /etc/letsencrypt/live/dev.loki.example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/dev.loki.example.com/privkey.pem;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
ssl_dhparam /etc/nginx/dhparams.pem;
ssl_ciphers "EECDH+AESGCM:EDH+AESGCM:ECDHE-RSA-AES128-GCM-SHA256:AES256+EECDH:DHE-RSA-AES128-GCM-SHA256:AES256+EDH:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA256:ECDHE-RSA-AES256-SHA:ECDHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES128-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES256-GCM-SHA384:AES128-GCM-SHA256:AES256-SHA256:AES128-SHA256:AES256-SHA:AES128-SHA:DES-CBC3-SHA:HIGH:!aNULL:!eNULL:!EXPORT:!DES:!MD5:!PSK:!RC4";
ssl_session_timeout 1d;
ssl_stapling on;
ssl_stapling_verify on;
location / {
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://grafana-loki$request_uri;
}
}
Запуск promtail
Сейчас в Grafana Explore пусто, так как никаких логов в Loki не шлём.
Создаём конфиг для promtail — /opt/loki/promtail.yml:
В client опять-таки указываем URL в виде http://loki:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
client:
url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: messages
static_configs:
- targets:
- localhost
labels:
job: all-logs
env: dev
host: monitoring-dev
__path__: /var/log/*.log
Добавляем запуск promtail в Compose файл, маунтим конфиг и указываем command для promtail, что бы он знал каким файлом настроек ему пользоваться:
...
promtail:
image: grafana/promtail:master-2739551
networks:
- loki
volumes:
- /opt/loki/promtail.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
restart: unless-stopped
Проверяем.
Вывод promtail:
[simterm]
...
promtail_1 | level=info ts=2019-11-16T09:19:57.935528884Z caller=filetargetmanager.go:257 msg="Adding target" key="{env=\"dev\", host=\"monitoring-dev\", job=\"all-logs\"}"
promtail_1 | ts=2019-11-16T09:19:57.936230518Z caller=log.go:124 component=tailer level=info msg="Seeked /var/log/dpkg.log - &{Offset:0 Whence:0}"
promtail_1 | level=info ts=2019-11-16T09:19:57.936292402Z caller=tailer.go:77 component=tailer msg="start tailing file" path=/var/log/dpkg.log
...
[/simterm]
dpkg.log пошёл, окей.
И в Grafana Explore:

Бимба!
promtail и логи dnsmasq
Переходим на Production хост, проверяем доступ к Loki:
[simterm]
root@bttrm-production-console:/home/admin# curl http://dev.logger.example.com:3100/ready Ready
[/simterm]
Создаём конфиг promtail-dev.yml:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
client:
url: http://dev.loki.example.com:3100/loki/api/v1/push
scrape_configs:
- job_name: dnsmasq
static_configs:
- targets:
- localhost
labels:
job: dnsmasq
env: production
host: bttrm-prod-console
__path__: /var/log/dnsmasq.log
Обратите внимание, что ендпоинты Локи обновились со времени последнего поста — /loki/api/v1/push.
См. документацию по Loki API тут>>>.
Запускаем его просто без Docker Compose — у меня там полный стек мониторинга Prometheus, потом добавлю новый promtail нормально, так как сейчас просто смотрим как оно вообще будет работать:
[simterm]
root@bttrm-production-console:/opt/prometheus-client# docker run -ti -v /opt/prometheus-client/promtail-dev.yml:/etc/promtail/promtail.yml grafana/promtail:master-2739551 -config.file=/etc/promtail/promtail.yml
Unable to find image 'grafana/promtail:master-2739551' locally
master-2739551: Pulling from grafana/promtail
...
Status: Downloaded newer image for grafana/promtail:master-2739551
level=warn ts=2019-11-16T09:29:00.668750217Z caller=filetargetmanager.go:98 msg="WARNING!!! entry_parser config is deprecated, please change to pipeline_stages"
level=info ts=2019-11-16T09:29:00.669077956Z caller=server.go:121 http=[::]:9080 grpc=[::]:45421 msg="server listening on addresses"
level=info ts=2019-11-16T09:29:00.66921034Z caller=main.go:65 msg="Starting Promtail" version="(version=, branch=, revision=)"
level=info ts=2019-11-16T09:29:05.669176878Z caller=filetargetmanager.go:257 msg="Adding target" key="{env=\"production\", host=\"bttrm-prod-console\", job=\"dnsmasq\"}"
[/simterm]
Эм…
А почему не пошёл сбор логов? Должна быть строка вида «msg=»start tailing file» path=/var/log/dnsmasq.log«…
И что случилось с Loki?
Что за ошибка «Error connecting to datasource: Data source connected, but no labels received. Verify that Loki and Promtail is configured properly«?

Попробовать пересоздать контейнеры?
[simterm]
root@monitoring-dev:/opt/loki# docker rm loki_grafana_1 loki_promtail_1 loki_grafana_1 loki_promtail_1
[/simterm]
Пересоздал контейнеры — завелось, ок.
А логи не собирались, потому что забыл смонтировать /var/log в запускаемый контейнер — добавляем монтирование -v /var/log:/var/log в запуск promtail:
[simterm]
root@bttrm-production-console:/home/admin# docker run -ti -v /opt/prometheus-client/promtail-dev.yml:/etc/promtail/promtail.yml -v /var/log:/var/log grafana/promtail:master-2739551 -config.file=/etc/promtail/promtail.yml
level=warn ts=2019-11-16T09:48:02.248719806Z caller=filetargetmanager.go:98 msg="WARNING!!! entry_parser config is deprecated, please change to pipeline_stages"
level=info ts=2019-11-16T09:48:02.249227598Z caller=server.go:121 http=[::]:9080 grpc=[::]:39883 msg="server listening on addresses"
level=info ts=2019-11-16T09:48:02.249381673Z caller=main.go:65 msg="Starting Promtail" version="(version=, branch=, revision=)"
level=info ts=2019-11-16T09:48:07.249262647Z caller=filetargetmanager.go:257 msg="Adding target" key="{env=\"production\", host=\"bttrm-prod-console\"}"
level=info ts=2019-11-16T09:48:07.24943453Z caller=tailer.go:77 component=tailer msg="start tailing file" path=/var/log/dnsmasq.log
ts=2019-11-16T09:48:07.249544341Z caller=log.go:124 component=tailer level=info msg="Seeked /var/log/dnsmasq.log - &{Offset:0 Whence:0}"
[/simterm]
Пошли логи:

LogQL — Loki’s logs aggregation and counters
Вот тут уже начинается самое интересное — работа с LogQL и функциями агрегации и подсчёта.
Впрочем, пока получилось завести это — пришлось повозиться (документация Loki и Grafana, как всегда, отстаёт).
Loki «Internal Server Error»
Пробуем выполнить запрос типа count_over_time({job="dnsmasq"}[5m]), и:
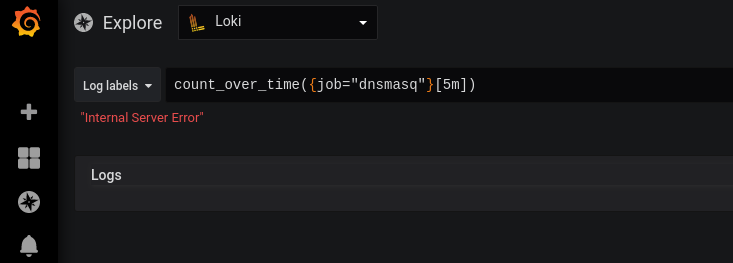
Тут проблема из-за… Пробелов! :facepalm:
Поправляем — добавляем пробелы между скобками, но — теперь Grafana просто ничего не находит:
count_over_time( {job="dnsmasq"}[5m] )

Prometheus как… Loki? О.О
Было очень неожиданно такое увидеть 🙂 Да и в документации ничего не сказано, но подсмотрел в grafana.slack.com.
В Grafana 6.5 вроде должно уже работать нормально, но в 6.5-beta-1 ещё не сделано.
Переходим в Datasource, и добавляем Prometheus — но как Loki.
Или наоборот — добавляем Loki, но как Prometheus?
В общем, выбираем тип Prometheus, а в URL указываем http://loki:310/loki — с /loki в конце:

И проверяем:

Няяяшка!
rate()
Попробуем использование функций, например — rate() + регулярку с выборкой хостов, к которым обращаемся:

Отлично.
Кстати — Grafana сама подставляет функции и сразу их описания:

promtail pipeline stages
Ещё одна интересная плюшка в promtail — раньше её, кажется, не было — pipeline stages.
См. документацию тут>>>.
В оригинале:
A pipeline is used to transform a single log line, its labels, and its timestamp. A pipeline is comprised of a set of stages. There are 4 types of stages:
- Parsing stages parse the current log line and extract data out of it. The extracted data is then available for use by other stages.
- Transform stages transform extracted data from previous stages.
- Action stages take extracted data from previous stages and do something with them. Actions can:
- Add or modify existing labels to the log line
- Change the timestamp of the log line
- Change the content of the log line
- Create a metric based on the extracted data
Filtering stages optionally apply a subset of stages or drop entries based on some condition.
То есть — строим пайплайн, который состоит из стейджев.
Стейджи бывают 4 типов:
- Parsing stages: парсит лог и извлекает данные, которые потом можно передать в дальнейшие стейджи
- Transform stages: трансформирует полученные от предыдущих стейджев данные
- Action stages: получает данные от предыдущих стейдж и делает что-то:
- добавляет или удаляет лейблы
- меняет таймштамп
- меняет содержимое строки лога
- создаёт метрику на основании извлечённых данных
Typical pipelines will start with a parsing stage (such as a regex or json stage) to extract data from the log line. Then, a series of action stages will be present to do something with that extracted data. The most common action stage will be a labels stage to turn extracted data into a label.
Итак, вернёмся к началу — чего мы хотим?
Мы хотим получить от dnsmasq все запросы IN A записей, извлечь из этих запросов имена хостов, и отобразить графиком — к какому доменному имени сколько запросов выполняется.
Значит, надо:
- получить все запросы IN A
- сохранить каждый в label
- и потом подсчитать их
Идём к promtail на Production, и добавляем стейдж в нашу джобу — обновляем конфиг promtail-dev.yml:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
client:
url: http://dev.loki.example.com:3100/loki/api/v1/push
scrape_configs:
- job_name: dnsmasq
static_configs:
- targets:
- localhost
labels:
job: dnsmasq
env: production
host: bttrm-prod-console
__path__: /var/log/dnsmasq.log
pipeline_stages:
- match:
selector: '{job="dnsmasq"}'
stages:
- regex:
expression: ".*query\\[A\\] (?P<query>.*\\s)"
- labels:
query:
В pipeline_stages делаем:
- выбираем джобу
dnsmasq - описываем стейдж regex, в котором выбираем все строки из лога, в которых есть строка query[A]
- далее в запросе создаём регекс группу query, в которую сохраняем строку до первого пробела
оригинал строки:
Nov 16 08:23:33 dnsmasq[17597]: query[A] backend-db3-master.example.com from 127.0.0.1
в группе query получим результат:
backend-db3-master.example.com
- далее в запросе создаём регекс группу query, в которую сохраняем строку до первого пробела
- описываем стейдж
labels, в котором добавляем label query со значением backend-db3-master.example.com
Запускаем promtail:
[simterm]
root@bttrm-production-console:/home/admin# docker run -ti -v /opt/prometheus-client/promtail-dev.yml:/etc/promtail/promtail.yml -v /var/log:/var/log grafana/promtail:master-2739551 -config.file=/etc/promtail/promtail.yml
level=info ts=2019-11-16T11:56:29.760425279Z caller=server.go:121 http=[::]:9080 grpc=[::]:32945 msg="server listening on addresses"
level=info ts=2019-11-16T11:56:29.760565845Z caller=main.go:65 msg="Starting Promtail" version="(version=, branch=, revision=)"
level=info ts=2019-11-16T11:56:34.760567558Z caller=filetargetmanager.go:257 msg="Adding target" key="{env=\"production\", host=\"bttrm-prod-console\", job=\"dnsmasq\"}"
level=info ts=2019-11-16T11:56:34.760752715Z caller=tailer.go:77 component=tailer msg="start tailing file" path=/var/log/dnsmasq.log
ts=2019-11-16T11:56:34.760863031Z caller=log.go:124 component=tailer level=info msg="Seeked /var/log/dnsmasq.log - &{Offset:0 Whence:0}"
[/simterm]
Проверяем борду Grafana:

И теперь попробуем сформировать запрос:
sum (rate( ( {env="production",query=~".*\\..*"} )[5m] )) by (query)
В query=~".*\\..*" я немного накостылял, что бы убрать из вывода метрики в которых query нет, но должен быть более правильный вариант. Пока «И так сойдёт» (с)
Смотрим:

Агонь!
Так…
В именах хостов, например api.amplitude.com from — остаётся from из лога.
Почему?
Используем https://regex101.com, фиксим регулярку, получается:
.*query\[A\] (?P<query>[^\s]+)
Обновляем конфиг promtail:
...
pipeline_stages:
- match:
selector: '{job="dnsmasq"}'
stages:
- regex:
expression: ".*query\\[A\\] (?P<query>[^\\s]+)"
- labels:
query:
И надо бы как-то убрать метрики без лейблы query…
Grafana DNS dashboard
Окей, в целом — всё понятно, давайте попробуем теперь нарисовать дашборду, в которой можно будет выводить статистику по DNS-запросам.
Кликаем Add query:

Задаём наш запрос:
sum (rate( ( {env="production", query=~".*\\..*"} )[5m] )) by (query)
в Legend используем подстановку из {{ query }} , что бы вывести только значение:

Окей, неплохо.
Добавим переменных, что бы можно было выбирать запросы.
Переходим в Dashboard Settings > Variables > Add variable, и…
Template variables ещё не поддерживаются для Loki…
Или я таки не разобрался, как вызвать например label_values() для Loki…
Документация тут>>>.
Хотелось сделать переменную со значениями из лейблы query, что бы была возможность выбирать конкретное доменное имя, но — увы.
Ладно.
Сделаем пока хотя бы возможность самому в дашборде задать фильтр.
Создаём переменную типа Text box:

И для выбора рабочего окружения — переменную типа Custom:

Возвращаемся к запросу, обновляем его:
sum (rate( ( {env="$env", query=~"$include"} )[5m] )) by (query)

Или с фильтром по домену:

В результате получилась такая вот борда с красивыми графиками:

Ссылки по теме
- Grafana Explore
- Using Loki in Grafana
- LogQL: Log Query Language
- Labels from Logs
- Loki’s HTTP API
- Configuring Promtail
- Promtail Pipelines
- Regular Expression Reference: Named Groups and Backreferences
- Grafana Labs: Loki – распределённая система, теги и фильтры
- Grafana Labs: Loki – подключение S3 для данных и DynamoDB для индексов
- Prometheus: мониторинг для RTFM — Grafana, Loki и promtail
![]()