![]() Около 9 вечера мониторинг сообщил, что на одном из production-серверов забивается место. Причём забивалось оно очень быстро, и за пару часов «скушалось» 3 гига из 8 доступных на root-разделе.
Около 9 вечера мониторинг сообщил, что на одном из production-серверов забивается место. Причём забивалось оно очень быстро, и за пару часов «скушалось» 3 гига из 8 доступных на root-разделе.
Забивался диск в каталоге базы RabbitMQ — /var/lib/rabbitmq/mnesia.
Быстрый фикс — перенести его базу на отдельный диск.
Создаём новый каталог:
[simterm]
root@bttrm-prod-console:/home/admin# cd /data/ && mkdir rabbitdb
[/simterm]
Обновляем конфиг реббита /etc/rabbitmq/rabbitmq-env.conf — задаём переменную RABBITMQ_MNESIA_BASE:
... RABBITMQ_MNESIA_BASE=/data/rabbitdb
Останавливаем RabbitMQ:
[simterm]
root@bttrm-prod-console:/data# systemctl stop rabbitmq-server
[/simterm]
Копируем данные из старого каталога и меняем владельца:
[simterm]
root@bttrm-prod-console:/data# cp -r /var/lib/rabbitmq/mnesia/* /data/rabbitdb/ root@bttrm-prod-console:/data# chown -R rabbitmq:rabbitmq rabbitdb/
[/simterm]
Запускаем его:
[simterm]
root@bttrm-prod-console:/data# systemctl start rabbitmq-server
[/simterm]
Проверяем статус:
[simterm]
root@bttrm-prod-console:/data# rabbitmqctl status
Status of node 'rabbit@bttrm-prod-console' ...
[{pid,30368},
{running_applications,
[{rabbitmq_management,"RabbitMQ Management Console","3.6.6"},
{rabbitmq_management_agent,"RabbitMQ Management Agent","3.6.6"},
{rabbitmq_web_dispatch,"RabbitMQ Web Dispatcher","3.6.6"},
...
[/simterm]
Доступное ему место и Database directory path:
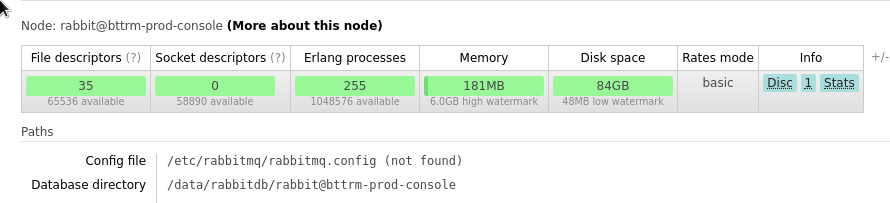
84 гига — окей.
На утром начали проверять — почему же RabbitMQ так засрал диск: оказалось, что в очередях скопилось 2 миллиона сообщений, которые не читались, потому что задачи supervisor-а, которые должны получать их, не были запущены.
Почитать по теме — RabbitMQ, backing stores, databases and disks.
Просмотреть список сообщений в очередях можно с помощью rabbitadmin:
[simterm]
root@bttrm-prod-console:/home/admin# rabbitmqadmin list queues -u adminuser -p p@ssw0rd +------------------------+----------+ | name | messages | +------------------------+----------+ | purchases | 395 | ...
[/simterm]
Ссылки по теме
![]()