![]() Ми зараз використовуємо AWS OpenSearch Service як vector store для нашого RAG з AWS Bedrock Knowledge Base.
Ми зараз використовуємо AWS OpenSearch Service як vector store для нашого RAG з AWS Bedrock Knowledge Base.
Про RAG і Bedrock детальніше поговоримо іншим разом, а сьогодні давайте подивимось на AWS OpenSearch Service.
Власне, задача – мігрувати наш AWS OpenSearch Service Serverless на Managed, в першу чергу через (сюрпрайз) питання вартості – бо з Serverless у нас постійно неочікувані спайки у використанні OpenSearch Compute Units (OCU – процесор, пам’ять та диск) – навіть коли нема ніяких змін у даних.
Головна задача – це спланувати розмір кластеру: диски, CPU та пам’ять, і підібрати під це типи інстансів.
В другій частині поговоримо про налаштування доступів – AWS: створення OpenSearch Service cluster та налаштування аутентифікації і авторизації.
В третій частині будемо писати Terraform – див. Terraform: створення AWS OpenSearch Service cluster та юзерів.
Зміст
Elasticsearch vs OpenSearch vs AWS OpenSearch Service
Власне, OpenSearch – це по суті той самий Elasticsearch: коли Elasticsearch у, здається, 2021 змінив умови своєї ліцензії – AWS запустила власний форк, назвавши його OpenSearch.
OpenSearch сумісний з Elasticsearch до версії 7.10, але на відміну від Elasticsearch – у OpenSearch повністю вільна ліцензія.
Про запуск Elasticsearch як частину ELK-стеку для логів колись писав тут – Elastic Stack: обзор и установка ELK на Ubuntu, але там більше про self-hosted і взагалі роботу з індексами, а тепер ми подивимось саме на рішення від AWS.
AWS OpenSearch Service – це повністю AWS-managed сервіс: як і у випадку з Kubernetes – AWS бере на себе всі задачі по деплою, апдейтам, бекапам, має тісну інтеграцію з іншими AWS-сервісами – IAM, VPC, S3, ну і Bedrock, з яким ми його і використовуємо.
AWS OpenSearch Service: знайомство
Тут і далі буду говорити в основному за Managed OpenSearch Service.
Основні концепти AWS OpenSearch Service – це домен, ноди, індекси (“бази”) та шарди (shards).
Домен – це сам кластер, який ми налаштовуємо на потрібну кількість і тип Nodes, а індекси – поділені на shards (блоки даних), які розподілені між Nodes:

Самі Nodes в кластері – по суті звичайні EC2 (як і в тому ж RDS чи навіть AWS Load Balancer), де під капотом працюють ті самі звичайні compute-інстанси.
Для кластеру AWS OpenSearch Service як і з Elastic Kubernetes Service створюються окремі control nodes (master nodes), тільки на відміну від EKS тут нам не треба окремо менеджити Data Plane та WorkerNodes.
Як і в RDS – для OpenSearch-кластеру можемо налаштувати автоматичні бекапи.
Для візуалізації даних – AWS предоставляє OpenSearch Dashboards.
Схема даних: документи, індекси та шарди
Для розуміння того, які типи інстансів нам вибрати для нашого кластеру – давайте розберемось з тим, що таке індекси в OpenSearch (або Elasticsearch, бо суть одна).
Отже, індекс – це колекція документів, які мають якісь загальні риси. У кожного індексу є унікальне ім’я – як у бази даних в RDS PostgreSQL чи MariaDB.
Хоча індекс часто порівнюють з базою даних, на практиці зручніше думати про індекс як про таблицю, а “база” – це весь кластер.
Документ – JSON-об’єкт в індексі, і являє собою базовий юніт зберігання даних. Якщо брати аналогію с тими ж базами даних – то це як рядок в таблиці.
Кожен документ має набір key-value полів, де value можуть бути string, integer, date або більш складними структурами типу масивів або object.
Індекси діляться на частини – шарди, задля кращого перформансу, де кожен шард містить частину даних індексу. Кожен документ зберігається тільки в одному шарді, а пошук може виконуватись паралельно в кілько шардах.
Хоча технічно це не дуже коректно, але про шарди можна уявляти собі як окремі міні-індекси, міні-бази.
Shards можуть бути primary, або replica: primary приймає всі write-операції і може обробляти select, а репліка – тільки для read-only операцій.
При цьому репліка завжди створюється на іншій data node – задля fault tolerance, і репліка може стати primary, якщо нода з primary-шардом впала.
Дефолтне значення кількості шард на кожен індексів в AWS OpenSearch Service – 5, але може налаштовуватись окремо (тобто, при 5 primary shards – будемо мати 10 шардів загалом, бо ще будуть репліки). А розмір шардів рекомендується мати від 10 до 50 гігабайт: кожен шард потребує CPU та пам’яті для роботи з ним, тому велика кількість маленьких шардів збільшить потребу в ресурсах, тоді як занадто великі шарди – сповільнять операції над ними.
В Open Source OpenSearch (та Elasticsearch) – primary shards по дефолту 1.
Нові документи розподіляються рівномірно між всіма наявними шардами.
По темі:
Data, Master та Coordinator Nodes
Data Nodes – зберігають дані і шарди, і виконуються запити пошуку і агрегацій. Основні “робочі юніти” кластеру.
Master Nodes – зберігають metadata про індекси, mapping, стан кластеру, керують primary/replica shard-ами, виконують rebalancing – але не займаються обробкою пошукових запитів. Тобто їхня задача – виключно контроль кластера.
Coordinator nodes (client nodes) – не зберігають ніяких даних і не приймають участі в їхній обробці, роль цих нод – такий собі “проксі” між клієнтом та data nodes – приймають запит від клієнта, ділять його на підзапити (scatter), відправляють їх до відповідних data nodes, потім збирають результат (gather) і повертають його клієнту. Але окремі ноди під Coordinators бажано мати на великих кластерах, аби зняти навантаження з Master та Data nodes.
Pricing
Як і з більшістю аналогічних сервісів AWS – платимо за compute-ресурси (CPU, RAM) за диск (EBS), і за трафік – хоча трафік з нюансами (в кращу сторону) – бо для multi-AZ деплойментів ми не платимо за трафік між нодами в різних Availability Zones (в RDS, здається, також), а також не платимо за трафік між UltraWarm/Cold Nodes та AWS S3.
Повна документація по вартості – Amazon OpenSearch Service Pricing, а з основного:
t3.medium.search: 2 vCPU, 4 GB RAM – $0.073 (звичайнийt3.mediumEC2 буде коштувати дешевше – $0.044)- General Purpose SSD (gp3) EBS: $0.122 per GB / month (звичайний EBS для EC2 – $0.08/GB-month)
Аналогічно до AWS EKS – в OpenSearch Service є два типи підтримки оновлень – Standart та Extended, і, звісно, Extended буде дорожчий.
Hot, UltraWarm, Cold storage в OpenSearch Service
Зберігання даних (індексів) в OpenSearch Service може бути організовано або на EBS на самій дата-ноді (Hot), аде закешовано на ноді з “бекендом” в S3 (UltraWarm), або тільки в S3 (Cold):
- Hot storage: звичайні data-nodes на звичайних EC2 з EBS – для найбільш актуальних даних, дає швидкий доступ до даних
- UltraWarm storage: для все ще актуальних, але не часто потрібних даних – дані зберігаються в S3, а на нодах зберігається їхній кеш, при цьому самі ноди – окремий тип інстансів типу
ultrawarm1.medium.search- швидкий доступ до даних, які є в кеші, повільніший до даних, до яких довго не звертались
- самі ноди дорожчі (
ultrawarm1.medium.searchбуде коштувати $0.238), але економія за рахунок збереження даних в S3 замість EBS - дані read-only
- недоступне, якщо в кластері T2 або T3 інстанси 🙁
- Cold storage: ці дані зберігаються виключно в S3, а доступ до них можливий через API OpenSerach Service
- повільний доступ, але тут платимо тільки за S3
- для використання треба мати налаштований Warm storage
- аналогічно – недоступне, якщо в кластері T2 або T3 інстанси 🙁
Непогано описано в Choose the right storage tier for your needs in Amazon OpenSearch Service.
Автоматичні бекапи – безкоштовні, зберігаються 14 днів.
Ручні – платимо за S3, але не платимо за трафік для їх збереження.
Планування AWS OpenSearch Service domain
ОК, з основними деталями наче розібрались – давайте подумаємо про те, як ми будемо робити кластер – його capacity plainning і вибір типів інстансів для Data Nodes.
Storage
Вибір розміру дисків
Дуже важливий момент, з якого треба починати – це визначити скільки місця буде займати ваш індекс чи індекси.
В документації Calculating storage requirements це непогано описано, але давайте ще порахуємо самі.
Наприклад, у нас буде 3 дата-ноди, зберігати будемо якісь логи.
На день записуємо 10 GiB логів, які зберігаємо 30 днів – в результаті отримуємо 300 гігабайт зайнятого місця. Маючи три ноди – це 100 гіг на кожну ноду.
Але при цьому нам треба враховувати:є
- Number of replicas: кожна replica shard – це копія primary shard, відповідно буде займати приблизно стільки ж місця
- OpenSearch indexing overhead: OpenSarch займає додаткове місце під власні індекси: це ще +10% від розміру самих даних
- Operating system reserved space: 5% місця на EBS резервується операційною системою
- OpenSearch Service overhead: і ще 20% – але не більше 20 гігабайт – резервується на кожній ноді самим OpenSearch Service для власної роботи
По останньому пункту в документації є цікаве уточнення:
- якщо маємо 3 ноди, у кожної 500 гіг диск – то разом будемо мати 1.5 терабайти, при цьому загальний максимальний розмір зарезервованого місця для OpenSearch буде 60 ГБ – по 20 на кожну ноду
- якщо маємо 10 нод і у кожної буде 100 гіг диск – то разом буде 1 Терабайт, але при цьому максимальний розмір зарезервованого місця для OpenSearch буде 200 ГБ – по 20 на кожну ноду
Формула розрахунку місця виглядає так:
Source data * (1 + number of replicas) * (1 + indexing overhead) / (1 - Linux reserved space) / (1 - OpenSearch Service overhead) = minimum storage requirement
Тобто, маючи потребу зберігати 300 ГБ логів – рахуємо:
- Source data: 300 GiB
- 1 primary + 1 replica
- 1 + indexing overhead = 1.1 (+10% від 1)
- 1 – Linux reserved space = 0.95 (5%)
- 1 – OpenSearch Service overhead = 0.8 (але це вірно якщо диски менше ніж 100 ГБ)
В такому випадку для наших 300 GiB логів нам потрібно:
300*2*1.1/0.95/0.8 867
867 GiB загального місця.
Або там жеж є простіша формула – просто використати коефіцієнт 1.45:
Source data * (1 + number of replicas) * 1.45 = minimum storage requirement
Тоді виходить:
300*2*1.45 870.00
Майже ті самі 867 гігабайт.
Кількість shards
Другий важливий момент, який теж описаний в документації – Choosing the number of shards.
В чому суть: в AWS OpenSearch Service індекс по дефолту розбивається на 5 primary-шардів без реплік (в self-hosted Elasticsearch/OpenSearch дефолт 1 primary та 1 replica).
Після створення індексу просто так змінити кількість шард не можна, бо роутинг запитів до документів прив’язаний саме до конкретних shards (ось тут непогано описано – Distributing Documents across Shards (Routing)).
При цьому рекомендований розмір шардів – 10-30 GiB для даних, де більше пошуку, і 30-50 – для індексів, де більше wrtie-операцій.
До розміру самого індексу ще треба додавати indexing overhead, про який говорили вище – 10%.
Якщо брати до уваги кейс, де ми пишемо логи (тобто, write intesive workload), і максимальний розмір індексу буде 300 GiB + 10% == 330 GiB.
Якщо ми хочемо мати primary шарди скажімо в 30 гігабайт – то отримуємо 11 primary shards.
Зміна кількості primary shards потребує створення нового індексу і виконання reindex – копіювання даних зі старого індексу в новий, див. Optimize OpenSearch index shard sizes.
Див. також Amazon OpenSearch Service 101: How many shards do I need та Shard strategy.
Але!
Якщо індекс планується маленьким – то краще мати один шард + 1 репліка, інакше кластер буде створювати зайві порожні shard-и, які все одно споживають ресурси.
При цьому все одно рекомендується мати три ноди: на одній буде primary-шард, на другій – replica, а третя буде резервною:
- якщо нода-1 з primary впаде – то нода-2 зробить replica новим primary
- а нода-3 отримає нову replica
Вибір типу Data Nodes
Ще один важливий момент – як вибрати правильний тип data-нод?
Що нам треба розуміти для вибору ноди – це потреби в CPU, в RAM, та диск.
В документації Choosing instance types and testing говориться:
try starting with a configuration closer to 2 vCPU cores and 8 GiB of memory for every 100 GiB of your storage requirement
Але це для “starting’, з якого там жеж рекомендується прогнати якісь лоад-тести, і спостерігати за моніторингом.
Про моніторинг будемо говорити десь окремо, а зараз спробує зробити власний estimate для “заліза”, яке нам потрібно.
Ще корисний матеріал є тут – Operational best practices for Amazon OpenSearch Service.
Типи інстансів
Див. Supported instance types in Amazon OpenSearch Service та Amazon OpenSearch Service Pricing.
Загальні правила тут такі ж, як і при звичайних EC2:
- General Purpose (
t3,m7g,m7i): стандартні сервери зі збалансованим CPU/RAM- добре підходять на master nodes або для data nodes на невеликих кластерах
- Compute Optimized (
c7g,c7i): більше CPU, менше пам’яті- підходять для data nodes, яким треба більше CPU (індексація, складні пошуки і агрегації)
- Memory Optimized (
r7g,r7gd,r7i): навпаки, більше пам’яті, менше CPU- підходять для data nodes, яким треба більше RAM
- Storage Optimized (
i4g,i4i): кращі SSD (NVMe SSD) з високим IOPS- підходять для data nodes, яким треба виконувати багато операцій запису (логи, метрики)
- OpenSearch Optimized (
om2,or2): “затюнені” інстанси від самого AWS з оптимальним співвідношенням CPU/RAM та дисками, простіші в налаштуваннях- це щось на багатому і для великих кластерів 🙂
Індекси тут:
g: Gravitor процесори (ARM64 від AWS) – продуктивні для багатопоточних обчислювань, кращі в плані ціна:ефективність, але можливі питання з сумісністюi: Intel (на базі х86 – класичні, сумісні з усім, кращі для важких однопоточних обчислюваньd: “drive” – має додатковий NVMe SSD
Data Node Storage
З диском ми наче розібрались в Choosing the number of shards:
- 10-30 гігабайт на кожен шард, якщо плануємо більше search операцій
- 30-50 GiB на шард – якщо більше write
Далі підбираємо тип інстансу, аби він мав достатньо storage, бо ще є ліміт на розмір дисків – див. EBS volume size quotas.
Data Node CPU
В частині Shard to CPU ratio є рекомендація планувати “1.5 vCPU per shard“.
Тобто, плануючи мати 4 шарди на кожну дата-ноду – закладаємо 6 vCPU. До них можна додати ще 1 (краще 2) ядро на потреби самої операційної системи.
Хоча, знов-таки, багато залежить від того, як з даними будуть працювати.
Якщо це багато search-heavy операцій – то 1.5 CPU на шард цілком виправдано.
Для write-intesive операцій – можна враховувати 0.5 CPU per shard, а для warm та cold нод – ще менше.
Див. OpenSearch Threadpool.
Data Node RAM
А от тепер саме цікаве – як порахувати потрібну пам’ять?
Тут розрахунки будуть дуже залежати від того, який саме індекс, дані будуть – просто документи у вигляді логів, або, як в нашому випадку, це буде vector store.
Перш ніж будемо рахувати потреби – кратко подивимось як взагалі розподіляється пам’ять на інстансі:
- JVM Heap Size: по дефолту задається у 50% RAM (але не більше 32 гігабайт): в JVM Heap у нас будуть різні власні дані OpenSearch – метадані та керування шардом/індексом (мапінги, routing, стан кластера), об’єкти запитів і відповідей, координація пошуку, різні внутрішні кеши та буфери – тобто, чисто внутрішні потреби самого OpenSeach
- off-heap memory (пам’ять самої операційної системи):
- у випадку використання індексу як vector-store – графи HNSW (k-NN search) + Linux page cache для даних, які з диску завантажуються в пам’ять ОС для швидкого доступу
- у випадку простих логів – тільки Linux page cache для даних, які з диску завантажуються в пам’ять ОС
Розрахунок RAM для логів
Плануємо JVM Heap в 16 гіг, пам’ятаючи, що це буде 50%. Ну, або взяти хоча б 8, і потім прослідкувати за JVMMemoryPressure.
Далі прикидуємо пам’ять під off-heap – Linux буде робити mmap актуальних для обробки запитів даних (зчитувати блоки даних в диску в пам’ять, коли процес їх запросить).
Тут у нас будуть “гарячі дані” – тобто дані, які часто потрібні клієнтам. Наприклад, знаємо, що найчастіше шукати в логах будемо за останні 24 години, і на добу пишемо 10 гігабайт логів разом.
До цих 10 ГБ варто додати 10-50 відсотків на структури самого OpenSearch, тож в результаті індекс буде рости на 11-15 ГБ в день.
З цих 11-12 гігабайт нехай 50% будуть активно використовуватись для результатів пошуку – записуємо собі 5-6 GiB RAM під “гарячий OS page cache”.
Розрахунок RAM для vector store
Якщо ж ми використовуємо OpenSearch як векторну базу, то нам треба враховувати потребу в пам’яті під кожен граф для пошуку даних.
Розмір графа залежить від алгоритму, але візьмемо дефолтний – HNSW (Hierarchical Navigable Small Worlds). Вибір алгоритму добре описаний в Choose the k-NN algorithm for your billion-scale use case with OpenSearch.
Для того, аби прикинути скільки пам’яті буде займати структура HNSW – нам треба знати кількість векторів в індексу, їхній dimension (розмірність ембедінгу), та кількість зв’язків між кожною нодою в графі (скільки сусідів зберігати для кожної точки в цьому графі).
Що взагалі у нас у “векторі”?
- набір чисел, заданий в dimension embedding-моделі (
[0.12, -0.88, ...]) - metadata: різні key_value з інформацію до якого документа цей вектор належить, source, і так далі
- опціонально – сам оригінальний текст (поле
_source– не впливає на граф, але збільшує розмір індексу)
id: "doc1-chunk1"
knn_vector: [0.12, -0.33, ...] // number set by dimension parameter
metadata: {doc_id: "doc1", chunk: 1, text: "some text"}
RAG, AWS Bedrock Knowlege Base, дані, та створення векторів
Сам процес RAG добре описаний на такій діаграмі (див. Implementing Amazon Bedrock Knowledge Bases in support of GDPR (right to be forgotten) requests):
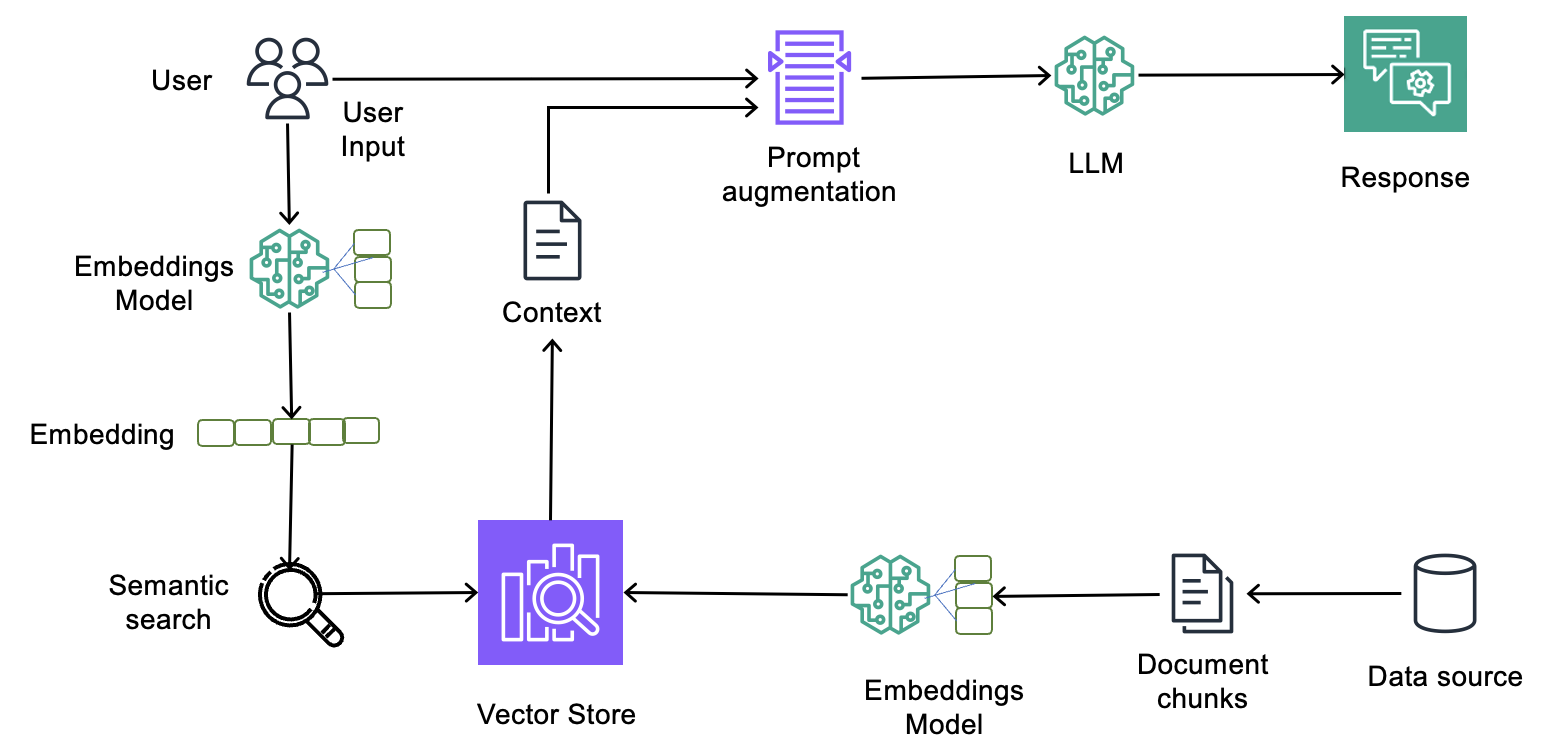
Як виглядає процес роботи RAG в цілому, і місце векторної бази в ньому:
- клієнт (наприклад, мобільна апка) робить запит до нашого Backend API, який працює в Kubernetes
- Backend API отримує його, і генерує запит
RetrieveAndGenerateдо Bedrock, в якому передається Knowledge Base ID та текст запиту від клієнта - Bedrock запускає RAG pipeline, в якому:
- відправляє запит до embedding-моделі, аби перетворити його на вектор(и)
- сам виконує k-NN пошук в OpenSearch-індексі, аби знайти максимально релевантні дані
- формує розширений промпт, який містить в собі оригінальний запит + дані, які йому повернув OpenSearch
- викликає GenAI модель, якій передає цей розширений промпт
- отримує від неї відповідь
- повертає її у вигляді JSON до нашого Backend API
- Backend API відправляє отриманий результат клієнту
Як виглядає процес перетворення тексту у вектори в AWS Bedrock Knowledge Base:
- маємо якийсь source – наприклад, txt-файл в S3
- Bedrock його зчитує, і якщо він великий – ділить його на chunks з розміром, заданим в параметрах Bedrock
- Bedrock кожен чанк тексту передається до embdedding LLM-model, яка перетворює цей чанк у вектор фіксованої довжини (dimension), і повертає до Bedrock pipeline
- Bedrock відправляє цей вектор разом з метаданими до AWS OpenSearch vector store, де він індексується для k-NN пошуку
Кількість векторів
Кількість векторів в індексі в першу чергу залежить від корпусу даних (розмір всіх вхідних даних, з якими ми працюємо), і на скільки чанків вони будуть поділені.
Що варто розуміти: вектори створюються не для окремих токенів, а для частин тексту, для цілих фраз.
У кожної ембедінг-моделі є ліміт на кількість токенів, які вона може обробити за раз (максимальна “довжина входу”).
Якщо текст довгий – то він розбивається на частини (chunks), і для кожного такого чанку створюється власний вектор.
Якщо візьмемо для прикладу ембедінг-модель з лімітом в 512 токенів і розмірністю (dimnestion, d) в 1024 чисел – то:
- фраза “hello, world” – влазить в одне “вікно” для ембедінгу, буде створений 1 вектор
- абзац англійськими текстом в 300 слів дасть приблизно 400 токенів – це теж поміщається у вікно, і теж буде створений 1 ембедінг-вектор
- стаття в 1.000 слів дасть вже приблизно 1300-1400 токенів, а тому вона буде поділена на три чанки, і для них будуть створені окремі вектори:
chunk_1 => [vector_1 with 1024 numbers]chunk_2 => [vector_2 with 1024 numbers]chunk_3 => [vector_3 with 1024 numbers]
d (dimension) – задається embedding-моделлю, яка перетворює дані у вектори для зберігання в vector-store. Наприклад, в Amazon Titan Embeddings dimension=1024. І цей жеж параметр вказується при створенні індексу.
m (Maximum number of bi-directional links) – кількість зв’язків між кожною нодою в графі, це параметр HNSW-графа, задається, коли ми створюємо індекс, наприклад:
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"engine": "faiss",
"parameters": {
"m": 16,
"ef_construction": 512
},
"space_type": "l2"
}
}
Тепер, знаючи всі ці дані – ми можемо порахувати скільки пам’яті буде потрібно для побудови графа в пам’яті, наприклад:
- кількість векторів: 1 000 000
d=1024m=16
Формула:
num_vectors * 1.1 * (4 * d + 8 * m)
Тут:
1.1: додається 10% запасу під службові структури HNSW4: кожна координата (число у векторі) зберігається як float32 = 4 байти8: кількість байт на зберігання id кожного “сусіда” (64-bit int) (кількість яких дається черезm)
Отже, рахуємо:
1.000.000 * 1.1 * (4*1024 + 8*16)
4646400000.0 байт, або 4.64 гігабайт – це обсяг для графа HNSW по всіх векторах (без урахування реплік і шард, про них трохи далі).
Тепер враховуємо розподіл на чанки і дата-ноди:
- якщо у нас весь індекс 100 гігабайт
- поділений на 3 primary shards, і для кожної primary маємо 1 replica shards – разом 6 шардів
- маємо 3 дата-ноди – на кожній ноді буде по 2 шарди
Для кожного шарду буде побудований окремий граф, а тому 4.64 гігабайт множимо на 2.
Але так як індекс розподілений на 3 ноди – то ділимо результат на 3.
Тож розрахунок буде таким:
graph_total: наші 4.64 гігабайти, загальний обсяг для графуgraph_cluster:graph_total* (1 + replicas) (primary + всі репліки)graph_per_node=graph_cluster/ кількість дата-нод в кластері
Формула буде такою:
graph_total * (1 + replicas) / num_data_nodes
Маючи 1 primary shard + 1 replicas shard виходить:
4.64 гігабайт * 2 / 3 data nodes
~ 3.1 GiB пам’яті на кожну ноду чисто під графи.
k-NN-графи зберігаються в off-heap пам’яті, тому вже можемо прикинути:
- 8 (краще 16) гігабайт під JVM Heap для самого OpenSearch
- 3 GiB під графи
Ліміт для k-NN графів задається в knn.memory.circuit_breaker.limit, і зазвичай має значення в 50: off-heap пам’яті – див. k-NN differences, tuning, and limitations.
Метрика в CloudWatch – KNNGraphMemoryUsage, див. k-NN metrics.
Або в API самого OpenSearch – _plugins/_knn/stats та _nodes/stats/indices,os,break (див. Nodes Stats API).
І до цього треба додати OS page cache для “гарячих” даних – векторів/метаданих/тексту, які з диску мапляться в пам’ять для швидкого доступу – як ми це рахували для індексу з логами.
Для OS page cache можемо накинути ще 20-50% від повного розміру індексу на ноді, хоча тут залежить від того, які операції будуть виконуватись. В ідеалі, якщо грошей не жалко – то можна докинути ще 100% від розміру індексу * 2 (на кожну репліку кожного шарду) / кількість нод.
Отже, якщо візьмемо 1 000 000 векторів в базі, і саму базу в умовних 30 гігабайт, 3 primary shards і для кожної 1 репліка, і 3 data-node – то отримуємо:
- 8 (краще 16) гігабайт під JVM Heap для самого OpenSearch
- 3 GB під графи
- 30 * 2 / 3 * 0.5 (50% для OS page cache) == 10 ГБ
І ще додати відсотків 10-15 на роботу самої операційної системи – отримуємо (16 + 3 + 10) * 1.15 == ~34 GB RAM.
Почитати по цій темі:
- Sizing Amazon OpenSearch Service domains: загальна документація від AWS
- k-NN Index: документація OpenSearch по параметрам індексу
- Choose the k-NN algorithm for your billion-scale use case with OpenSearch: алгоритми та підрахунок пам’яті
Ну і, мабуть, на цьому поки все.
В наступних (сподіваюсь, напишу) постах – вже насетапимо кластер, може відразу з Terraform, створимо індекс, подивимось на аутентифікацію та доступ до OpenSearch Dashboard (бо трохи через одне місце), і подумаємо про моніторинг.
Корисні посилання
Elsatissearch/OpenSearch general docs:
- Elasticsearch index management
- Introduction to the Elasticsearch Architecture
- Understanding Sharding in Elasticsearch
- Elasticsearch Shard Optimization
- Optimize OpenSearch index shard sizes
- Reducing Amazon OpenSearch Service Costs: our Journey to over 60% Savings
- Managing indexes in Amazon OpenSearch Service
- OpenSearch Performance
OpenSearch as vector store:
- Cost Optimized Vector Database: Introduction to Amazon OpenSearch Service quantization techniques
- k-Nearest Neighbor (k-NN) search in Amazon OpenSearch Service
![]()