![]() В продолжение постов о развёртывании Prometheus для мониторинга проекта в Azure (привет, Azure, давно не виделись! см. Azure: почему никогда).
В продолжение постов о развёртывании Prometheus для мониторинга проекта в Azure (привет, Azure, давно не виделись! см. Azure: почему никогда).
Спустя три месяца — проект решил, что мониторинг им всё-таки нужен, и меня «вернули».
Посты по теме:
Остановился я на добавлении к Prometheus серверу виртуальных машин из VMSS с помощью Prometheus exporter_proxy — пост Prometheus: exporter_proxy – мониторинг сервисов в приватной сети.
Ниже описывается продолжение настройки мониторинга сервисов — теперь к Prometheus серверу добавим мониторинг виртуальных машин из Azure VMSS и Docker Swarm managers и Docker Swarm workers, которые работают в этих VMSS.
Содержание
Описание проекта
Очень кратко — про сам проект, который будет мониторится.
Рабочие окружения состоят из двух Azure VMSS (Virtual Machine Scale Set), на которых работает Docker Swarm: один VMSS для Swarm Manager нод, второй для Swarm Workers нод.
Перед каждым VMSS имеется свой Load Balancer, который разруливает трафик к интансам в этих VMSS.
Собственно само приложение включает в себя 6 контейнеров, которые запущены на Swarm Workers нодах:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker service ls ID NAME MODE REPLICAS IMAGE PORTS rusilcjixgtw jm_website_api_layer replicated 1/1 jm/jm-api-layer:v2.0.3 *:4004->4004/tcp q3ua0haf2vdx jm_website_proxy replicated 1/1 jm/jm-website-proxy:latest *:80->80/tcp,*:443->443/tcp qou735xchcf6 jm_website_transform replicated 1/1 jm/jm-cms-transform-layer:v2.1.1 *:3003->3003/tcp r30zxn2az7xv jm_website_transform_preview replicated 1/1 jm/jm-cms-transform-layer:v2.1.1 *:3004->3004/tcp niy35cv64ftp jm_website_web replicated 1/1 jm/jm-website:v2.3.14 *:8008->8008/tcp r2zhb82wasae jm_website_web_preview replicated 1/1 jm/jm-website:v2.3.14 *:8080->8080/tcp
[/simterm]
Описание Prometheus сервера
Теперь кратко о самом Prometheus сервере.
Prometheus и Grafana запущены на виртуальной машине, в отдельной Azure Resource Group.
К виртуальной машине во время развёртывания Resource Group (с помощью Azure Resource Manager шаблонов, см. пост Azure: provisioning с Resource Manager, Jenkins и Groovy) подключается внешний диск, который монтируется в /data из Ansible-задачи:
[simterm]
root@jm-monitoring-production-vm:~# findmnt /data TARGET SOURCE FSTYPE OPTIONS /data /dev/sdc1 ext4 rw,relatime,data=ordered
[/simterm]
Задачи в Ansible — создание каталога /data и монтирование диска:
...
- name: Create "{{ data_mount_path }}" directory
file:
path: "{{ data_mount_path }}"
owner: root
group: root
mode: 0755
state: directory
- name: Mount volume "{{ data_volume }}"
mount:
path: "{{ data_mount_path }}"
src: "{{ data_volume }}"
state: mounted
fstype: ext4
...
В /data хранятся данные самого Prometheus, Grafana и сертификаты Let’s Ecnrypt:
[simterm]
root@jm-monitoring-production-vm:~# tree -L 2 /data/
/data/
├── grafana
│ ├── grafana.db
│ ├── plugins
│ └── sessions
├── letsencrypt
│ ├── accounts
│ ├── archive
│ ├── csr
│ ├── keys
│ ├── live
│ └── renewal
├── lost+found
└── prometheus
├── 00
├── 01
├── 02
...
[/simterm]
Для доступа к Prometheus и Grafana, а так же для завершения SSL-сессии — перед ними запущен NGINX со следующим конфигом:
upstream prometheus_server {
server 127.0.0.1:9090;
}
upstream grafana_ui {
server 127.0.0.1:3000;
}
server {
server_name www.monitor.domain.tld;
listen 80;
return 301 https://monitor.domain.tld$request_uri;
}
server {
server_name monitor.domain.tld;
listen 80;
root /var/www/monitor.domain.tld;
location ~ /.well-known {
allow all;
}
location / {
allow 194.***.***.45;
allow 37.***.***.130;
deny all;
return 301 https://monitor.domain.tld$request_uri;
}
}
server {
server_name monitor.domain.tld;
listen 443 ssl;
access_log /var/log/nginx/monitor.domain.tld-access.log proxy;
error_log /var/log/nginx/monitor.domain.tld-error.log notice;
ssl on;
ssl_certificate /data/letsencrypt/live/monitor.domain.tld/fullchain.pem;
ssl_certificate_key /data/letsencrypt/live/monitor.domain.tld/privkey.pem;
root /var/www/monitor.domain.tld;
location / {
auth_basic_user_file /var/www/monitor.domain.tld/.htaccess;
auth_basic "Password-protected Area";
allow 194.***.***.45;
allow 37.***.***.130;
deny all;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://grafana_ui$request_uri;
}
location /prometheus {
auth_basic_user_file /var/www/monitor.domain.tld/.htaccess;
auth_basic "Password-protected Area";
allow 194.***.***.45;
allow 37.***.***.130;
deny all;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://prometheus_server$request_uri;
}
}
Добавление мониторинга VMSS
Задача на сегодня — добавить мониторинг виртуальных машин Docker Swarm менеджеров и воркеров, мониторинг Docker engine на них и контейнеров на воркерах, в которых работает само приложение.
Большая часть уже настроена (см. Prometheus: exporter_proxy – мониторинг сервисов в приватной сети), поэтому этот пост больше обзорный и как документация для самого себя — на случай, если проект опять «пропадёт» на три месяца.
Запуск exporter_proxy
Начнём с запуска exporter_proxy сервисов на менеджер-ноде.
Сейчас установка выполняется на QA, у которого 1 Manager нода и 3 workers.
Со Staging и Production будет немного сложнее, т.к. там три менеджера, и придётся обновлять правила Azure Load Balancer, но пока можно обойтись простым Compose файлом.
На manager ноде потребуется запустить exporter_proxy и подключить ему файл настроек.
Файл настроек сейчас выглядит так:
listen: "0.0.0.0:9099"
access_log:
path: "/dev/stdout"
format: "ltsv"
fields: ['time', 'time_nsec', 'status', 'size', 'reqtime_nsec', 'backend', 'path', 'query', 'method']
error_log:
path: "/dev/stderr"
exporters:
master_exporter:
url: "http://10.0.0.4:9100/metrics"
path: "/master_exporter/metrics"
worker_1_exporter:
url: "http://192.168.0.4:9100/metrics"
path: "/worker_1_node_exporter/metrics"
worker_2_exporter:
url: "http://192.168.0.5:9100/metrics"
path: "/worker_2_node_exporter/metrics"
worker_3_exporter:
url: "http://192.168.0.6:9100/metrics"
path: "/worker_3_node_exporter/metrics"
node_exporter-ы пока не запущены нигде, к ним перейдём чуть позже.
Создаём Compose файл для exporter_proxy:
version: '3'
networks:
prometheus:
services:
prometheus-proxy:
image: rrreeeyyy/exporter_proxy
volumes:
- /home/admin/prometheus-proxy-config.yml:/etc/config.yml
ports:
- "9099:9099"
command:
- '-config=/etc/config.yml'
networks:
- prometheus
deploy:
placement:
constraints:
- node.role == manager
Тут в блоке:
...
placement:
constraints:
- node.role == manager
указываем на запуск exporter_proxy только на менеджер-нодах. (см. constraint)
Тут ещё один нюанс, который связан чисто с текущим сетапом — менеджер ноды находятся в статусе drain, что бы не запускать на них сервисы вообще:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ai3040vw51jch7zikcx0mjy5c * hzwzatr7dzxp4000000 Ready Drain Leader b4y0ldkfzyhztmapaw48uqre4 hzwzatr7dzxp4000000 Ready Active ughyd9bhoexkcvcipbg9ewfws hzwzatr7dzxp4000001 Ready Active bd6v85fk6mr0tcam8xu3pmn78 hzwzatr7dzxp4000002 Ready Active
[/simterm]
Что бы Docker Swarm запустил наш прокси — обновляем стаус менеджер-ноды на active:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker node update --availability active ai3040vw51jch7zikcx0mjy5c ai3040vw51jch7zikcx0mjy5c
[/simterm]
Проверяем стеки сейчас:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker stack ls NAME SERVICES jm_website 6
[/simterm]
Создаём новый:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker stack deploy -c prometheus-proxy.yml jm-monitoring-proxy Creating network jm-monitoring-proxy_prometheus Creating service jm-monitoring-proxy_prometheus-proxy
[/simterm]
Проверяем:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker stack ls NAME SERVICES jm-monitoring-proxy 1 jm_website 6
[/simterm]
Проверяем сам сервис:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker service ps jm-monitoring-proxy_prometheus-proxy ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS ud26ch5ekthn jm-monitoring-proxy_prometheus-proxy.1 rrreeeyyy/exporter_proxy:latest hzwzatr7dzxp4000000 Running Running about a minute ago
[/simterm]
Пробуем получить метрики от proxy:
[simterm]
admin@hzwzatr7dzxp4000000:~$ curl -s localhost:9099/master_exporter/metrics 404 page not found
[/simterm]
ОК — т.к. сам node_exporter ещё не запущен.
node_exporter и cAdvisor
Далее создадим сервис, который будет запускать контейнеры с node_exporter и cAdvisor на каждой ноде кластера — и менеджерах, и воркерах.
Созадём Compose файл:
version: '3'
networks:
prometheus:
services:
node-exporter:
image: prom/node-exporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- --collector.filesystem.ignored-mount-points
- "^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)"
ports:
- 9100:9100
networks:
- prometheus
deploy:
mode: global
cadvisor:
image: google/cadvisor
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- 8081:8080
networks:
- prometheus
deploy:
mode: global
В блоке:
...
deploy:
mode: global
указываем на запуск на всех нодах кластера (см. mode).
Создаём новый сервис:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker stack deploy -c prometheus-monitoring.yml jm-monitoring Creating network jm-monitoring_prometheus Creating service jm-monitoring_node-exporter Creating service jm-monitoring_cadvisor
[/simterm]
Проверяем стеки:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker stack ls NAME SERVICES jm-monitoring 2 jm-monitoring-proxy 1 jm_website 6
[/simterm]
Сервисы этого стека:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker stack ps jm-monitoring ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS t8kuno4xtygz jm-monitoring_cadvisor.ughyd9bhoexkcvcipbg9ewfws google/cadvisor:latest hzwzatr7dzxp4000001 Running Running 3 hours ago kf0eei7ah5qs jm-monitoring_cadvisor.bd6v85fk6mr0tcam8xu3pmn78 google/cadvisor:latest hzwzatr7dzxp4000002 Running Running 3 hours ago 85ajf4v2k61o jm-monitoring_cadvisor.b4y0ldkfzyhztmapaw48uqre4 google/cadvisor:latest hzwzatr7dzxp4000000 Running Running 3 hours ago vxo1nadcrlrc jm-monitoring_cadvisor.ai3040vw51jch7zikcx0mjy5c google/cadvisor:latest hzwzatr7dzxp4000000 Running Running 3 hours ago jek7t3qtchvm jm-monitoring_node-exporter.ai3040vw51jch7zikcx0mjy5c prom/node-exporter:latest hzwzatr7dzxp4000000 Running Running 3 hours ago bbvwf2zzakw5 jm-monitoring_node-exporter.ughyd9bhoexkcvcipbg9ewfws prom/node-exporter:latest hzwzatr7dzxp4000001 Running Running 3 hours ago pr25igrd8yua jm-monitoring_node-exporter.bd6v85fk6mr0tcam8xu3pmn78 prom/node-exporter:latest hzwzatr7dzxp4000002 Running Running 3 hours ago nqavzuuh5rhb jm-monitoring_node-exporter.b4y0ldkfzyhztmapaw48uqre4 prom/node-exporter:latest hzwzatr7dzxp4000000 Running Running 3 hours ago
[/simterm]
Всё поднялось, на всех нодах — 1 менеджер + 3 воркера == по 4 контейнера с cAdvisor и node_exporter.
Проверим метрики:
[simterm]
admin@hzwzatr7dzxp4000000:~$ curl -s localhost:9100/metrics | head
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.1599e-05
go_gc_duration_seconds{quantile="0.25"} 3.61e-05
go_gc_duration_seconds{quantile="0.5"} 3.8698e-05
go_gc_duration_seconds{quantile="0.75"} 4.6399e-05
go_gc_duration_seconds{quantile="1"} 0.000280095
go_gc_duration_seconds_sum 0.001616076
go_gc_duration_seconds_count 30
# HELP go_goroutines Number of goroutines that currently exist.
[/simterm]
ОК — node_exporter метрики отдаёт, проверим через exporter_proxy:
[simterm]
admin@hzwzatr7dzxp4000000:~$ curl -s localhost:9099/master_exporter/metrics | head
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.25e-05
go_gc_duration_seconds{quantile="0.25"} 3.67e-05
go_gc_duration_seconds{quantile="0.5"} 4.07e-05
go_gc_duration_seconds{quantile="0.75"} 5.23e-05
go_gc_duration_seconds{quantile="1"} 0.000656404
go_gc_duration_seconds_sum 0.002062908
go_gc_duration_seconds_count 30
# HELP go_goroutines Number of goroutines that currently exist.
[/simterm]
Вернёмся к prometheus-proxy-config.yml и добавим сбор метрик от cAdvisor.
Сначала проверим метрики от него напрямую:
[simterm]
admin@hzwzatr7dzxp4000000:~$ curl -s localhost:8081/metrics | head
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="1e567c2",cadvisorVersion="v0.28.3",dockerVersion="17.09.0-ce",kernelVersion="4.4.0-116-generic",osVersion="Alpine Linux v3.4"} 1
# HELP container_cpu_load_average_10s Value of container cpu load average over the last 10 seconds.
# TYPE container_cpu_load_average_10s gauge
container_cpu_load_average_10s{container_label_com_docker_stack_namespace="",container_label_com_docker_swarm_node_id="",container_label_com_docker_swarm_service_id="",container_label_com_docker_swarm_service_name="",container_label_com_docker_swarm_task="",container_label_com_docker_swarm_task_id="",container_label_com_docker_swarm_task_name="",id="/",image="",name=""} 0
...
[/simterm]
Обновляем конфиг для прокси:
listen: "0.0.0.0:9099"
access_log:
path: "/dev/stdout"
format: "ltsv"
fields: ['time', 'time_nsec', 'status', 'size', 'reqtime_nsec', 'backend', 'path', 'query', 'method']
error_log:
path: "/dev/stderr"
exporters:
manager_exporter:
url: "http://10.0.0.4:9100/metrics"
path: "/manager_exporter/metrics"
worker_1_node_exporter:
url: "http://192.168.0.4:9100/metrics"
path: "/worker_1_node_exporter/metrics"
worker_2_node_exporter:
url: "http://192.168.0.5:9100/metrics"
path: "/worker_2_node_exporter/metrics"
worker_3_node_exporter:
url: "http://192.168.0.6:9100/metrics"
path: "/worker_3_node_exporter/metrics"
worker_1_cadvisor_exporter:
url: "http://192.168.0.4:8081/metrics"
path: "/worker_1_cadvisor_exporter/metrics"
worker_2_cadvisor_exporter:
url: "http://192.168.0.5:8081/metrics"
path: "/worker_2_cadvisor_exporter/metrics"
worker_3_cadvisor_exporter:
url: "http://192.168.0.6:8081/metrics"
path: "/worker_3_cadvisor_exporter/metrics"
Пересоздаём стек прокси:
[simterm]
admin@hzwzatr7dzxp4000000:~$ docker stack rm jm-monitoring-proxy Removing service jm-monitoring-proxy_prometheus-proxy Removing network jm-monitoring-proxy_prometheus admin@hzwzatr7dzxp4000000:~$ docker stack deploy -c prometheus-proxy.yml jm-monitoring-proxy Creating network jm-monitoring-proxy_prometheus Creating service jm-monitoring-proxy_prometheus-proxy
[/simterm]
Проверяем метрики cAdvisor через прокси:
[simterm]
admin@hzwzatr7dzxp4000000:~$ curl -s localhost:9099/worker_1_cadvisor_exporter/metrics | head
...
container_cpu_load_average_10s{container_label_com_docker_stack_namespace="",container_label_com_docker_swarm_node_id="",container_label_com_docker_swarm_service_id="",container_label_com_docker_swarm_service_name="",container_label_com_docker_swarm_task="",container_label_com_docker_swarm_task_id="",container_label_com_docker_swarm_task_name="",id="/",image="",name=""} 0
container_cpu_load_average_10s{container_label_com_docker_stack_namespace="",container_label_com_docker_swarm_node_id="",container_label_com_docker_swarm_service_id="",container_label_com_docker_swarm_service_name="",container_label_com_docker_swarm_task="",container_label_com_docker_swarm_task_id="",container_label_com_docker_swarm_task_name="",id="/docker",image="",name=""} 0
container_cpu_load_average_10s{container_label_com_docker_stack_namespace="",container_label_com_docker_swarm_node_id="",container_label_com_docker_swarm_service_id="",container_label_com_docker_swarm_service_name="",container_label_com_docker_swarm_task="",container_label_com_docker_swarm_task_id="",container_label_com_docker_swarm_task_name="",id="/init.scope",image="",name=""} 0
container_cpu_load_average_10s{container_label_com_docker_stack_namespace="",container_label_com_docker_swarm_node_id="",container_label_com_docker_swarm_service_id="",container_label_com_docker_swarm_service_name="",container_label_com_docker_swarm_task="",container_label_com_docker_swarm_task_id="",container_label_com_docker_swarm_task_name="",id="/system.slice",image="",name=""} 0
container_cpu_load_average_10s{container_label_com_docker_stack_namespace="",container_label_com_docker_swarm_node_id="",container_label_com_docker_swarm_service_id="",container_label_com_docker_swarm_service_name="",container_label_com_docker_swarm_task="",container_label_com_docker_swarm_task_id="",container_label_com_docker_swarm_task_name="",id="/system.slice/accounts-daemon.service",image="",name=""} 0
[/simterm]
ОК — пошли метрики от cAdvisor.
Добавление targets в Prometeus сервер
Последний шаг — это добавить таргеты в Prometheus сервер.
Находим конфиг сервера:
[simterm]
root@jm-monitoring-production-vm:~# cd /etc/prometheus/ root@jm-monitoring-production-vm:/etc/prometheus# ls -l total 8 -rwxrwxr-x 1 prometheus prometheus 583 Dec 26 13:39 alert.rules -rwxrwxr-x 1 prometheus prometheus 1525 Dec 26 13:39 prometheus.yml
[/simterm]
Обновляем его блок scrape_configs, пока используем static_configs:
...
- job_name: 'jm-website-qa'
static_configs:
- targets:
- jm-website-qa-master-ip.westeurope.cloudapp.azure.com:9099
labels:
__metrics_path__: /manager_exporter/metrics
name: jm-website-qa-manager-vm
- targets:
- jm-website-qa-master-ip.westeurope.cloudapp.azure.com:9099
labels:
__metrics_path__: /worker_1_node_exporter/metrics
name: jm-website-qa-worker-1-vm
- targets:
- jm-website-qa-master-ip.westeurope.cloudapp.azure.com:9099
labels:
__metrics_path__: /worker_2_node_exporter/metrics
name: jm-website-qa-worker-2-vm
- targets:
- jm-website-qa-master-ip.westeurope.cloudapp.azure.com:9099
labels:
__metrics_path__: /worker_3_node_exporter/metrics
name: jm-website-qa-worker-3-vm
- targets:
- jm-website-qa-master-ip.westeurope.cloudapp.azure.com:9099
labels:
__metrics_path__: /worker_1_cadvisor_exporter/metrics
name: jm-website-qa-worker-1-docker
- targets:
- jm-website-qa-master-ip.westeurope.cloudapp.azure.com:9099
labels:
__metrics_path__: /worker_2_cadvisor_exporter/metrics
name: jm-website-qa-worker-2-docker
- targets:
- jm-website-qa-master-ip.westeurope.cloudapp.azure.com:9099
labels:
__metrics_path__: /worker_3_cadvisor_exporter/metrics
name: jm-website-qa-worker-3-docker
...
[/simterm]
Проверяем сервисы Prometheus сервера:
[simterm]
root@jm-monitoring-production-vm:/etc/prometheus# cd /opt/prometheus/
root@jm-monitoring-production-vm:/opt/prometheus# docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------------
prometheus_alertmanager_1 /bin/alertmanager -config. ... Up 0.0.0.0:9093->9093/tcp
prometheus_cadvisor_1 /usr/bin/cadvisor -logtostderr Up 0.0.0.0:8080->8080/tcp
prometheus_grafana_1 /run.sh Up 0.0.0.0:3000->3000/tcp
prometheus_node-exporter_1 /bin/node_exporter --path. ... Up 0.0.0.0:9100->9100/tcp
prometheus_prometheus-server_1 /bin/prometheus -config.fi ... Up 0.0.0.0:9090->9090/tcp
[/simterm]
Перезапускаем Prometheus сервер:
[simterm]
root@jm-monitoring-production-vm:/opt/prometheus# docker-compose restart prometheus-server Restarting prometheus_prometheus-server_1 ... done
[/simterm]
И проверяем targets:
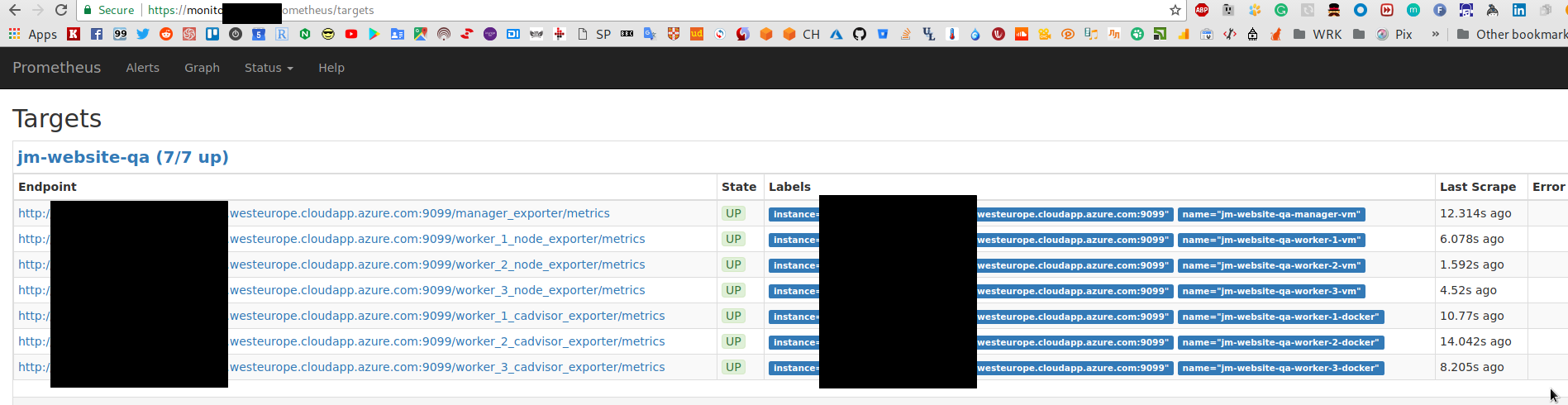
Проверим метрики от cAdvisor, в Prometheus graphs вызываем, например, container_cpu_user_seconds_total, добавляем фильтры:
container_cpu_user_seconds_total{container_label_com_docker_stack_namespace="jm_website",container_label_com_docker_swarm_service_name="jm_website_proxy"}

Grafana dashboard
И по-быстрому — добавим дашборд в Grafana, через импорт, например Docker monitoring:
 Осталось навести порядок в labels.
Осталось навести порядок в labels.
Ну и ещё кучу всего поделать.
![]()